【数据库】Redis主从复制、哨兵模式、集群
目录
一、Redis的主从复制
1.1 主从复制的架构
1.2 主从复制的作用
1.3 注意事项
1.4 主从复制用到的命令
1.5 主从复制流程
1.6 主从复制实现
1.7 结束主从复制
1.8 主从复制优化配置
二、哨兵模式
2.1 哨兵模式原理
2.2 哨兵的三个定时任务
2.3 哨兵的结构
2.4 哨兵模式的实现
三、Redis集群cluster
3.1 cluster作用
3.2 cluster特点
3.3 cluster架构
3.4 cluster的部署
一、Redis的主从复制

1.1 主从复制的架构
主从复制,是指将一台 Redis 服务器的数据,复制到其他的 Redis 服务器。前者称为主节点(Master),后者称为从节点(Slave);数据的复制是单向的,只能由主节点到从节点。
默认情况下,每台Redis服务器都是主节点;且一个主节点可以有多个从节点(或没有从节点),但一个从节点只能有一个主节点。
1.2 主从复制的作用
- 数据备份和容灾:通过主从复制可以将主数据库的数据实时同步到从数据库,以实现数据备份和容灾。如果主数据库发生故障,可以快速切换到从数据库,保障数据的可用性。
- 负载均衡:通过主从复制可以将读操作分摊到多个从数据库上,从而降低主数据库的负载,实现读写分离,提高系统的整体性能和并发能力。
- 数据分发:通过主从复制可以将数据分发到不同的地理位置或数据中心,以提高数据访问的速度和稳定性。
1.3 注意事项
导致主从服务器数据全部丢失的操作
1.假设节点A为主服务器,并且关闭了持久化。然后节点B和节点C从节点A复制数据
2.节点A崩溃,然后由自动拉起服务重启了节点A。由于节点A的持久化被关闭了,所以重启之后没有任何数据
3.节点B和节点C将从节点A复制数据,但是A的数据是空的,于是就把自身保存的数据副本删除。
措施:
无论何时,数据安全都是极其重要的,所以应该禁止主服务器关闭持久化的同时自动启动。
1.4 主从复制用到的命令
| 命令 | 解释 |
|---|---|
| info replication | 查看主从状态 |
| repliacaof 或者 ( slaveof ) | 添加主从配置 例子: repliacaof 192.168.91.100 6379 |
| CONFIG SET masterauth 123456 | 临时设置密码 |
| repliacaof masterip masterport | 临时添加主设置 |
| REPLICAOF no one | 取消 主从配置 |
1.5 主从复制流程
-
连接建立:从数据库连接到主数据库,发送 SYNC 命令请求全量复制或 PSYNC 命令请求部分复制。
-
数据同步:主数据库收到同步请求后,将当前的数据快照发送给从数据库,或者根据 PSYNC 命令发送从指定的复制偏移量开始的数据。
-
命令传播:主数据库接收到写命令后,会将这些写操作的命令记录到内存的命令缓冲区中,同时将这些命令同步到所有从数据库,从数据库接收到命令后按顺序执行相同的写操作,保持数据一致性。
-
重新连接:如果从数据库和主数据库之间的连接断开,从数据库会尝试重新连接主数据库,并从断开的位置继续复制数据,以保持同步。
总结:
第一次全同步
1)从服务器连接主服务器,发送[P]SYNC(同步)命令
2)主服务器接收到[P]SYNC命令后,开始执行BGSAVE命令生成RDB快照文件并使用缓冲区记录此后执行的所有写命令
3)主服务器BGSAVE执行完后,向所有从服务器发送RDB快照文件,并在发送期间继续记录被执行的写命令
4)从服务器收到快照文件后丢弃所有旧数据,载入收到的快照至内存
5)主服务器快照发送完毕后,开始向从服务器发送内存缓冲区中的写命令
6)从服务器完成对快照的载入,开始接收命令请求,并执行来自主服务器缓冲区的写命令后期部分同步
7)后期同步会先发送自己slave_repl_offset位置,只同步新增加的数据,不再全量同步

1.6 主从复制实现
环境部署:
版本:Redis-6.2.6
主节点Master:192.168.254.10
从节点Slave1:192.168.254.20
从节点Slave2:192.168.254.30
实验配置:
###############主从服务器##################
systemctl stop firewalld
setenforce 0###############主服务器##################
vim /apps/redis/etc/redis.conf #将监听端口改为任意端口
bind 0.0.0.0
#设置密码
requirepass 123456
#指定日志文件目录
logfile /apps/redis/log/redis.log
#指定PID文件位置
pidfile /apps/redis/run/
#指定工作目录(rdb、aof文件存放位置)
dir /apps/redis/data/
#开启AOF持久化功能
appendonly yes###############从服务器1##################
vim /apps/redis/etc/redis.conf
#将监听端口改为任意端口
bind 0.0.0.0
#设置密码
requirepass 123456
#设置主从配置,连接主服务器的密码
masterauth 123456
#指定日志文件目录
logfile /apps/redis/log/redis.log
#指定PID文件位置
pidfile /apps/redis/run/
#指定工作目录(rdb、aof文件存放位置)
dir /apps/redis/data/
#开启AOF持久化功能
appendonly yes
#开启主从复制,主的IP和端口
replicaof 192.168.254.10 6379###############从服务器2##################
vim /apps/redis/etc/redis.conf
#将监听端口改为任意端口
bind 0.0.0.0
#设置密码
requirepass 123456
#设置主从配置,连接主服务器的密码
masterauth 123456
#指定日志文件目录
logfile /apps/redis/log/redis.log
#指定PID文件位置
pidfile /apps/redis/run/
#指定工作目录(rdb、aof文件存放位置)
dir /apps/redis/data/
#开启AOF持久化功能
appendonly yes
#开启主从复制,主的IP和端口
replicaof 192.168.254.10 63791.7 结束主从复制
在从节点执行 REPLIATOF NO ONE 指令可以取消主从复制
REPLICAOF no one
#取消复制,在slave上执行REPLIATOF NO ONE,会断开和master的连接不再主从复制, 但不会清除slave上已有的数据1.8 主从复制优化配置
1. 复制缓冲区(环形队列)配置参数:
#复制缓冲区大小,建议要设置足够大
repl-backlog-size 1mb #Redis同时也提供了当没有slave需要同步的时候,多久可以释放环形队列:
repl-backlog-ttl 3600 #最长保持时间 3600秒该缓冲区即为在主从复制时,主服务器在发送快照的同时,新的写操作存入内存缓冲区的缓冲区大小,需要设置足够大,否则超过的部分会覆盖掉未发送的数据。
2. 避免全量复制,避免复制风暴
-
第一次全量复制不可避免,后续的全量复制可以利用小主节点(内存小),业务低峰时进行全量
-
节点运行ID不匹配:主节点重启会导致RUNID变化,可能会触发全量复制,可以利用故障转移,例如哨兵或集群,而从节点重启动,不会导致全量复制
-
复制积压缓冲区不足: 当主节点生成的新数据大于缓冲区大小,从节点恢复和主节点连接后,会导致全量复制.解决方法将repl-backlog-size 调大
-
单主节点复制风暴,当主节点重启,多从节点复制
可以采用级联复制,将一台slave服务器设为其他slave服务器的主
3. 性能相关配置
repl-diskless-sync no # 是否使用无盘同步RDB文件,默认为no,no为不使用无盘,需要将RDB文件保存到磁盘后再发送给slave,yes为支持无盘,支持无盘就是RDB文件不需要保存至本地磁盘,而且直接通过socket文件发送给slaverepl-diskless-sync-delay 5 #diskless时复制的服务器等待的延迟时间repl-ping-slave-period 10 #slave端向server端发送ping的时间间隔,默认为10秒repl-timeout 60 #设置主从ping连接超时时间,超过此值无法连接,master_link_status显示为down,并记录错误日志repl-disable-tcp-nodelay no #是否启用TCP_NODELAY,如设置成yes,则redis会合并小的TCP包从而节省带宽, 但会增加同步延迟(40ms),造成master与slave数据不一致,假如设置成no,则redis master会立即发送同步数据,没有延迟,yes关注网络性能,no关注redis服务中的数据一致性repl-backlog-size 1mb #master的写入数据缓冲区,用于记录自上一次同步后到下一次同步过程中间的写入命令,计算公式:repl-backlog-size = 允许从节点最大中断时长 * 主实例offset每秒写入量,比如master每秒最大写入64mb,最大允许60秒,那么就要设置为64mb*60秒=3840MB(3.8G),建议此值是设置的足够大repl-backlog-ttl 3600 #3600秒 如果一段时间后没有slave连接到master,则backlog size的内存将会被释放。如果值为0则 表示永远不释放这部份内存。slave-priority 100 #slave端的优先级设置,值是一个整数,数字越小表示优先级越高。当master故障时将会按照优先级来选择slave端进行恢复,如果值设置为0,则表示该slave永远不会被选择。min-replicas-to-write 1 #设置一个master的可用slave不能少于多少个,否则master无法执行写min-slaves-max-lag 20 #设置至少有上面数量的slave延迟时间都大于多少秒时,master不接收写操作(拒绝写入)二、哨兵模式
哨兵模式是在主从复制的基础上,增加了主节点的故障移除功能。
一个被哨兵故障移除的主节点,在恢复后会变为新的主节点的从节点。
2.1 哨兵模式原理
哨兵(sentinel)是一个分布式系统,用于对主从结构中的每台服务器进行监控,当出现故障时通过投票机制选择新的Master,并将所有Slave 连接到新的Master。所以整个运行哨兵的集群的数量不得少于3个节点。
2.2 哨兵的三个定时任务
-
每10秒每个sentinel对master和slave执行info,发现slave节点,确认主从关系
-
每2秒每个sentinel通过master节点的channel交换信息(pub/sub),通过sentinel__:hello频道交互,交互对节点的“看法”和自身信息
-
每1秒每个sentinel对其他sentinel和redis执行ping
2.3 哨兵的结构
哨兵结构往往由两部分组成:哨兵节点、数据节点
- 数据节点:即主从数据库,用于写入和存储数据的节点
- 哨兵节点:游离于数据节点,哨兵节点不会存储数据,它只负责监控数据节点是否正常
哨兵的启动依赖于主从模式,所以须把主从模式安装好的情况下再去做哨兵模式,所有节点上都需要部署哨兵模式,哨兵模式会监控所有的Redis工作节点是否正常,当Master出现问题的时候,因为其他节点与主节点失去联系,因此会投票,投票过半就认为这个 Master 的确出现问题,然后会通知哨兵间,然后从Slaves中选取一个作为新的 Master。
2.4 哨兵模式的实现
环境配置:
三台数据节点,需要三台哨兵节点,为了节省服务器,直接在每台节点上配置哨兵节点
主数据库Master:192.168.254.10 哨兵节点1
从数据库Slave1:192.168.254.20 哨兵节点2
从数据库Slave2:192.168.254.30 哨兵节点3
配置前提:
!!!基于主从配置已经完成的情况下!!!
配置实现:
################所有主从服务器##################
echo 'requirepass "123456"' >> /apps/redis/etc/redis.conf
echo 'masterauth "123456"' >> /apps/redis/etc/redis.conf
systemctl stop firewalld
setenforce 0
systemctl restart redis#################所有节点Sentinel配置##################
#编译安装时,源码包中有sentinel.conf配置文件
cp /data/redis-6.2.6/sentinel.conf /apps/redis/etc/
#给予权限
chown -R redis.redis /apps/redis#编写配置
vim /apps/redis/etc/redis-sentinel.conf bind 0.0.0.0 #修改监听端口
port 26379 #不用修改默认
daemonize no # 不用修改systemd启动模式, 修改为yes后systemd启动不了
pidfile "/apps/resdis/run/redis-sentinel.pid" #指定pid文件
logfile "/apps/redis/log/sentinel_26379.log" # 指定日志文件
dir "/tmp" #工作目录不用修改
sentinel monitor mymaster 192.168.254.10 6379 2
#mymaster是集群的名称,此行指定当前mymaster集群中master服务器的地址和端口
#2为法定人数限制(quorum),即有几个sentinel认为master down了就进行故障转移,一般此值是所有sentinel节点(一般总数是>=3的 奇数,如:3,5,7等)的一半以上的整数值,比如,总数是3,即3/2=1.5,取整为2,是master的ODOWN客观下线的依据
sentinel auth-pass mymaster 123456
#mymaster集群中master的密码,注意此行要在上面行的下面
sentinel down-after-milliseconds mymaster 3000
#(SDOWN)判断mymaster集群中所有节点的主观下线的时间,单位:毫秒,建议3000(3秒)否则等待时间过长
sentinel parallel-syncs mymaster 1
#发生故障转移后,可以同时向新master同步数据的slave的数量,数字越小总同步时间越长,但可以减轻新master的负载压力
sentinel failover-timeout mymaster 18000
#所有slaves指向新的master所需的超时时间,单位:毫秒准备service文件,开启服务先开启主的再开从的
#################所有节点##################
cat >> /lib/systemd/system/redis-sentinel.service <<eof
[Unit]
Description=Redis Sentinel
After=network.target
[Service]
ExecStart=/apps/redis/bin/redis-sentinel /apps/redis/etc/sentinel.conf --supervised systemd
ExecStop=/bin/kill -s QUIT $MAINPID
User=redis
Group=redis
RuntimeDirectory=redis
RuntimeDirectoryMode=0755
[Install]
WantedBy=multi-user.target
eofsystemctl daemon-reload#################主节点###################
systemctl start redis-sentinel.service
#先开启主的#################从节点###################
systemctl start redis-sentinel.service验证:
##############所有节点###############
tail -f /apps/redis/log/sentinel.log###############主节点##################
systemctl stop redis
#关闭主节点,观察日志变化三、Redis集群cluster
3.1 cluster作用
在哨兵sentinel机制中,可以解决redis高可用问题,即当master故障后可以自动将slave提升为master,从而可以保证redis服务的正常使用,但是无法解决redis单机写入的瓶颈问题,即单机redis写入性能受限于单机的内存大小、并发数量、网卡速率等因素。
3.2 cluster特点
-
所有Redis节点使用(PING机制)互联
-
集群中某个节点的是否失效,是由整个集群中超过半数的节点监测都失效,才能算真正的失效
-
客户端不需要proxy即可直接连接redis,应用程序中需要配置有全部的redis服务器IP
-
redis cluster把所有的redis node 平均映射到 0-16383个槽位(slot)上,读写需要到指定的redis node上进行操作,因此有多少个redis node相当于redis 并发扩展了多少倍,每个redis node 承担16384/N个槽位
-
Redis cluster预先分配16384个(slot)槽位,当需要在redis集群中写入一个key -value的时候,会使用CRC16(key) 取模 16384之后的值,决定将key写入值哪一个槽位从而决定写入哪一个Redis节点上,从而有效解决单机瓶颈。

3.3 cluster架构
假如三个主节点分别是:M1,M2,M3 三个节点,采用哈希槽 (hash slot)的方式来分配16384个slot 的话它们三个节点分别承担的slot 区间可以是:
节点M1覆盖 0-5460 从节点S1
当M1损坏,S1会接替,M1和S1都坏了则0-5460槽位不可用
节点M2覆盖 5461-10922 从节点S2当M2损坏,S2会接替,M2和S2都坏了则5461-10922槽位不可用
节点M3覆盖 10923-16383 从节点S3当M3损坏,S3会接替,M3和S3都坏了则10923-16383槽位不可用
3.4 cluster的部署
环境配置:
一般cluster集群最起码需要6台服务器,3个主节点,3个从节点
方便起见,这里使用一台服务器分出6个实例来完成
节点1:192.168.254.10:6001
节点2:192.168.254.10:6002
节点3:192.168.254.10:6003
节点4:192.168.254.10:6004
节点5:192.168.254.10:6005
节点6:192.168.254.10:6006
配置演示:
#进入redis目录
cd /apps/redis
#创建集群文件目录
mkdir -p redis-cluster/redis600{1..6}#准备执行文件到每个实例文件
for i in {1..6}
do
cp /data/redis-6.2.6/redis.conf /apps/redis/redis-cluster/redis600$i
cp /data/redis-6.2.6/src/redis-cli /data/redis-6.2.6/src/redis-server /apps/redis/redis-cluster/redis600$i
donechown -R redis.redis /apps/redis#进入6001端口实例配置文件
cd /apps/redis/redis-cluster/redis6001/
vim redis.conf#bind 127.0.0.1 #69行,注释掉bind 项,默认监听所有网卡
protected-mode no #88行,修改,关闭保护模式
port 6001 #92行,修改,redis监听端口,
daemonize yes #136行,开启守护进程,以独立进程启动 如果是systemd 启动不需要修改,这里修改为yes,不使用systemd启动
cluster-enabled yes #832行,取消注释,开启群集功能
cluster-config-file nodes-6001.conf #840行,取消注释,群集名称文件设置
cluster-node-timeout 15000 #846行,取消注释群集超时时间设置
appendonly yes #700行,修改,开启AOF持久化#将此配置文件复制给每个实例下
for i in {2..6}
do
\cp -f ./redis.conf /apps/redis/redis-cluster/redis600${i}
done#############################分隔符#########################################这里提供一个快捷更改实例中配置的sed命令参考,进入不同实例目录中修改
cd /apps/redis/redis-cluster/redis6002
sed -i.bak -e 's/bind 127.0.0.1/bind 0.0.0.0/' -e 's/protected-mode yes/protected-mode no/' -e 's/^port .*/port 6002/' -e 's/^daemonize .*/daemonize yes/' -e 's/^# cluster-enabled .*/cluster-enabled yes/' -e 's/^# cluster-config-file .*/cluster-config-file nodes-6002.conf/' -e 's/^# cluster-node-timeout .*/cluster-node-timeout 15000/' -e 's/appendonly no/appendonly yes/' redis.conf#6003、6004、6005、6006如上,只需要修改端口即可#############################分隔符#########################################先暂停redis服务
systemctl stop redis#进入实例文件夹,执行命令
for d in {1..6}
do
cd /apps/redis/redis-cluster/redis600$d
redis-server redis.conf
done#检查进程是否全部开启
ss -natp |grep "\b600[1-6]\b"
#若看见6001~6006进程全部开启则成功#开启集群
redis-cli --cluster create 127.0.0.1:6001 127.0.0.1:6002 127.0.0.1:6003 127.0.0.1:6004 127.0.0.1:6005 127.0.0.1:6006 --cluster-replicas 1
#六个实例分为三组,每组一主一从,前面的做主节点,后面的做从节点。
#--replicas 1 表示每个主节点有1个从节点。
#下面交互的时候 需要输入 yes 才可以创建。#注意,要是您使用了六台服务器进行操作,这里的127.0.0.1需要改为各自服务器的IP#看到OK后即为成功验证:
#加-c参数,节点之间就可以互相跳转
redis-cli -p 6001 -c
127.0.0.1:6001> cluster slots #查看节点的哈希槽编号范围
1) 1) (integer) 54612) (integer) 10922 #哈希槽编号范围3) 1) "127.0.0.1"2) (integer) 6003 #主节点IP和端口号3) "fdca661922216dd69a63a7c9d3c4540cd6baef44"4) 1) "127.0.0.1"2) (integer) 6004 #从节点IP和端口号3) "a2c0c32aff0f38980accd2b63d6d952812e44740"
2) 1) (integer) 02) (integer) 54603) 1) "127.0.0.1"2) (integer) 60013) "0e5873747a2e26bdc935bc76c2bafb19d0a54b11"4) 1) "127.0.0.1"2) (integer) 60063) "8842ef5584a85005e135fd0ee59e5a0d67b0cf8e"
3) 1) (integer) 109232) (integer) 163833) 1) "127.0.0.1"2) (integer) 60023) "816ddaa3d1469540b2ffbcaaf9aa867646846b30"4) 1) "127.0.0.1"2) (integer) 60053) "f847077bfe6722466e96178ae8cbb09dc8b4d5eb"127.0.0.1:6001>set name zzh
# 对name这个键进行算法 得出值为5789 跳到对应的主节点存储,并且从节点也会复制
-> Redirected to slot [5798] located at 127.0.0.1:6002
OK
127.0.0.1:6002>get name
"zzh"#查看name键的槽编号
cluster keyslot name #查看name键的槽编号#查看节点信息
cluster nodes#遍历关闭cluster
for i in {1..6}
do
kill -9 $(ss -natp | grep 600$i | tr -s " " | cut -d= -f2 | cut -d, -f1 | uniq)
done
相关文章:

【数据库】Redis主从复制、哨兵模式、集群
目录 一、Redis的主从复制 1.1 主从复制的架构 1.2 主从复制的作用 1.3 注意事项 1.4 主从复制用到的命令 1.5 主从复制流程 1.6 主从复制实现 1.7 结束主从复制 1.8 主从复制优化配置 二、哨兵模式 2.1 哨兵模式原理 2.2 哨兵的三个定时任务 2.3 哨兵的结构 2.4 哨…...

C基础day8
一、思维导图 二、课后习题 #include<myhead.h> #define Max_Stu 100 //函数声明 //学生信息录入函数 void Enter_stu(int *Num_Stu,char Stu_name[][50],int Stu_score[]); //查看学生信息 void Print_stu(int Num_Stu,char Stu_name[][50],int Stu_score[]); //求出成绩…...
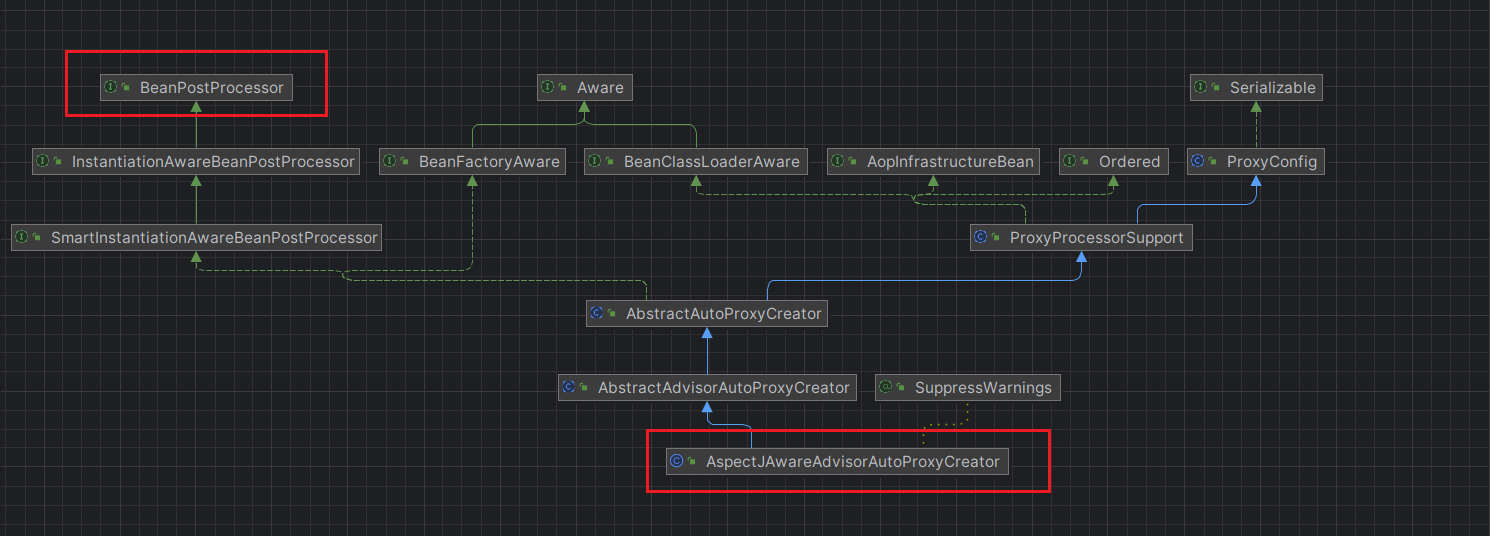
【Spring成神之路】老兄,来一杯Spring AOP源码吗?
文章目录 一、引言二、Spring AOP的使用三、Spring AOP的组件3.1 Pointcut源码3.2 Advice源码3.3 Advisor源码3.4 Aspect源码 四、Spring AOP源码刨析4.1 configureAutoProxyCreator源码解析4.2 parsePointcut源码解析4.3 parseAdvisor源码解析4.4 parseAspect源码解析4.5 小总…...

轻松理解c++17的string_view
文章目录 轻松理解c17的string_view设计初衷常见用法构造 std::string_view常用操作作为函数参数 注意事项总结 轻松理解c17的string_view std::string_view 是 C17 引入的一个轻量级、不拥有(non-owning)的字符串视图类。它的设计初衷是提供一种高效、…...
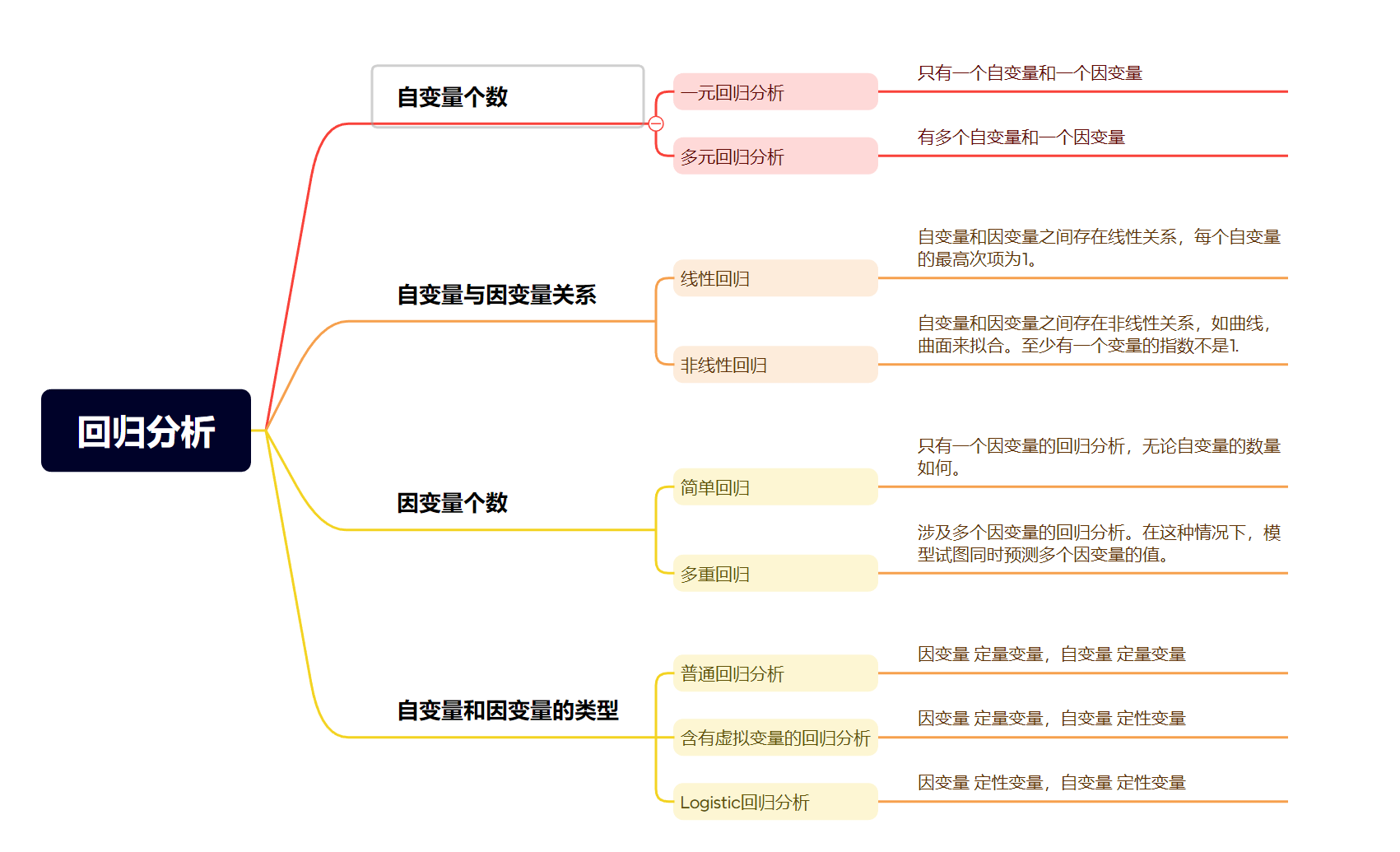
【机器学习理论基础】回归模型定义和分类
定义 回归分析是研究自变量与因变量之间数量变化关系的一种分析方法,它主要是通过因变量 Y Y Y与影响它的自变量 X i X_i Xi 之间的回归模型,衡量自变量 X i X_i Xi 对因变量 Y Y Y 的影响能力的,进而可以用来预测因变量Y的发展趋势。…...

探讨4层代理和7层代理行为以及如何获取真实客户端IP
准备工作 实验环境 IP角色192.168.1.100客户端请求IP192.168.1.100python 启动的HTTP服务192.168.1.102nginx服务192.168.1.103haproxy 服务 HTTP服务 这是一个简单的HTTP服务,主要打印HTTP报文用于分析客户端IP #!/usr/bin/env python # coding: utf-8import …...

java算法day11
二叉树的递归遍历二叉树的非递归遍历写法层序遍历 递归怎么写? 按照三要素可以保证写出正确的递归算法: 1.确定递归函数的参数和返回值: 确定哪些参数是递归的过程中需要处理的,那么就在递归函数里加上这个参数, 并且…...

linux下安装cutecom串口助手;centos安装cutecom串口助手;rpm安装包安装cutecom串口助手
在支持apt-get的系统下安装 在终端命令行中输入: sudo apt-get install cutecom 安装好后输入 sudo cutecom 就可以了 关于如何使用,可以看这个https://www.cnblogs.com/xingboy/p/14388610.html 如果你的电脑不支持apt-get。 那我们就通过安装包…...

2024年信息系统项目管理师2批次上午客观题参考答案及解析(1)
1、关于收集需求管理过程及相关技术的描述,正确的是() A.需求跟踪矩阵是把产品需求从其来源链接到能满足需求的可交付成果的一种表格 B.原型法是一种结构化的头脑风暴形式,通过投票排列最有用的创意 C&am…...

Xinstall揭秘:APP推广数据背后的真相,让你的营销更精准!
在这个移动互联网时代,APP如同雨后春笋般涌现,但如何在这片红海中脱颖而出,成为每一个开发者与运营者面临的共同难题。其中,APP推广统计作为衡量营销效果、优化推广策略的关键环节,更是不可忽视的一环。今天࿰…...

科研绘图系列:R语言小提琴图(Violin Plot)
介绍 小提琴图(Violin Plot)是一种结合了箱线图和密度图的图表,它能够展示数据的分布密度和分布形状。以下是对小提琴图的详细解释: 小提琴图能表达: 数据分布:小提琴图通过在箱线图的两侧绘制曲线来展示数据的分布密度,曲线的宽度表示数据点的密度。集中趋势:箱线图部…...

【Vite】修改构建后的 index.html 文件名
在 Vite 项目中,默认构建 index.html 。但有时候我们需要修改 index.html 为其他文件名,比如 index-{时间戳}.html 。 我们可以这样配置 vite.config.js: import { defineConfig } from vite; import type { PluginOption } from vite;// 自…...

解决IDEA每次新建项目都需要重新配置maven的问题
每次打开IDEA都要重新配置maven,这是因为在DEA中分为项目设置和全局设置,这个时候我们就需要去到全局中设置maven了。我用的是IntelliJ IDEA 2023.3.4 (Ultimate Edition),以此为例。 第一步:打开一个空的IDEA,选择左…...

论文学习_Getafix: learning to fix bugs automatically
1. 引言 研究背景:现代生产代码库极其复杂并且不断更新。静态分析器可以帮助开发人员发现代码中的潜在问题(在本文的其余部分中称为错误),这对于在这些大型代码库中保持高代码质量是必要的。虽然通过静态分析尽早发现错误是有帮助的,但修复这些错误的问题在实践中仍然主要…...

Xilinx FPGA:vivado关于真双端口的串口传输数据的实验
一、实验内容 用一个真双端RAM,端口A和端口B同时向RAM里写入数据0-99,A端口读出单数并存入单端口RAM1中,B端口读出双数并存入但端口RAM2中,当检测到按键1到来时将RAM1中的单数读出显示到PC端,当检测到按键2到来时&…...

RedisTemplate 中序列化方式辨析
在Spring Data Redis中,RedisTemplate 是操作Redis的核心类,它提供了丰富的API来与Redis进行交互。由于Redis是一个键值存储系统,它存储的是字节序列,因此在使用RedisTemplate时,需要指定键(Key)…...

数据结构与算法基础篇--二分查找
必要前提:有序数组 算法简述:通过不断取中间值和目标target值进行比较(中间值:mid (left right) / 2) 如果目标值等于中间位置的值,则找到目标,返回中间位置如果目标值小于中间位置的值&…...

python xlsx 导出表格超链接
该Python脚本用于从Excel文件中的第一列提取所有超链接并保存到一个文本文件中。首先,脚本导入必要的库并定义输入和输出文件的路径。然后,它确保输出文件的目录存在。接着,脚本加载Excel文件并选择活动工作表。通过遍历第一列的所有单元格&a…...

Data Guard高级玩法:failover备库后,通过闪回恢复DG备库
作者介绍:老苏,10余年DBA工作运维经验,擅长Oracle、MySQL、PG、Mongodb数据库运维(如安装迁移,性能优化、故障应急处理等) 公众号:老苏畅谈运维 欢迎关注本人公众号,更多精彩与您分享…...

【Unity2D 2022:NPC】制作任务系统
一、接受任务 1. 编辑NPC对话脚本: (1)创建静态布尔变量用来判断ruby是否接受到任务 public class NPCDialog : MonoBehaviour {// 创建全局变量用来判断ruby是否接到任务public static bool receiveTask false; } (2ÿ…...

Phi-4-Reasoning-Vision部署案例:基于torch.bfloat16的双卡显存优化实操
Phi-4-Reasoning-Vision部署案例:基于torch.bfloat16的双卡显存优化实操 1. 项目背景与核心价值 Phi-4-Reasoning-Vision是基于微软Phi-4-reasoning-vision-15B多模态大模型开发的高性能推理工具,专为双卡RTX 4090环境优化。这个工具解决了大模型部署中…...
)
告别卡顿!GSYVideoPlayer的ExoPlayer内核配置全攻略(支持HLS/m3u8直播流)
GSYVideoPlayer的ExoPlayer内核深度调优:打造极致流畅的HLS直播体验 去年接手一个海外直播项目时,遇到最头疼的问题就是m3u8流媒体的卡顿和延迟。测试了各种方案后,最终通过GSYVideoPlayer的ExoPlayer内核解决了这个难题。今天就把这些实战经…...
)
人体关键点检测实战:如何用OKS和AP评估模型性能(附Python代码示例)
人体关键点检测实战:OKS与AP指标深度解析与Python实现 在计算机视觉领域,人体姿态估计一直是热门研究方向,而准确评估模型性能则是项目落地的关键环节。不同于常规的目标检测任务,人体关键点检测需要更精细的评估体系——这正是OK…...

Llama-3.2V-11B-cot高效部署:双卡4090下11B模型加载时间缩短至92s
Llama-3.2V-11B-cot高效部署:双卡4090下11B模型加载时间缩短至92s 1. 项目概述 Llama-3.2V-11B-cot是基于Meta Llama-3.2V-11B-cot多模态大模型开发的高性能视觉推理工具。该工具针对双卡RTX 4090环境进行了深度优化,通过一系列技术创新将11B大模型的加…...

Fun-ASR-MLT-Nano-2512快速上手:Web界面操作,无需代码基础
Fun-ASR-MLT-Nano-2512快速上手:Web界面操作,无需代码基础 1. 语音识别新选择:Fun-ASR-MLT-Nano-2512 1.1 模型简介 Fun-ASR-MLT-Nano-2512是阿里通义实验室推出的轻量级多语言语音识别模型,经过开发者by113小贝的二次开发优化…...

SPIRAN ART SUMMONER跨平台适配:Windows/macOS/Linux下Streamlit祭坛兼容性
SPIRAN ART SUMMONER跨平台适配:Windows/macOS/Linux下Streamlit祭坛兼容性 1. 引言:当幻光祭坛遇见不同操作系统 想象一下,你刚刚在网络上看到了一个令人惊叹的AI图像生成工具——SPIRAN ART SUMMONER。它那充满《最终幻想10》风格的“幻光…...

PHP 数组 vs SPL 数据结构:队列与栈场景下的性能对决
PHP 数组 vs SPL 数据结构:队列与栈场景下的性能对决在 PHP 开发中,我们常常面临一个经典的选择:是使用灵活的原生数组(Array)模拟队列/栈,还是使用标准库(SPL)提供的 SplQueue 和 S…...

WSABuilds vs 官方WSA:性能测试与功能对比,谁才是安卓模拟器之王?
WSABuilds vs 官方WSA:性能测试与功能对比,谁才是安卓模拟器之王? 【免费下载链接】WSABuilds Run Windows Subsystem For Android on your Windows 10 and Windows 11 PC using prebuilt binaries with Google Play Store (MindTheGapps) an…...
5大理由让你立即选择Argos Translate:开源离线翻译的终极解决方案
5大理由让你立即选择Argos Translate:开源离线翻译的终极解决方案 【免费下载链接】argos-translate Open-source offline translation library written in Python 项目地址: https://gitcode.com/GitHub_Trending/ar/argos-translate Argos Translate是一款…...
)
手把手教你用ThinkPHP6和Uniapp从零搭建一个物业设备巡检小程序(附完整源码)
从零构建物业设备巡检系统:ThinkPHP6与Uniapp全栈实战指南 物业设备巡检是保障设施安全运行的关键环节,传统纸质记录方式效率低下且难以追溯。本教程将带您从零开始,基于ThinkPHP6后端框架与Uniapp跨端方案,构建一个功能完整的移动…...