基于前馈神经网络 FNN 实现股票单变量时间序列预测(PyTorch版)

前言
系列专栏:【深度学习:算法项目实战】✨︎
涉及医疗健康、财经金融、商业零售、食品饮料、运动健身、交通运输、环境科学、社交媒体以及文本和图像处理等诸多领域,讨论了各种复杂的深度神经网络思想,如卷积神经网络、循环神经网络、生成对抗网络、门控循环单元、长短期记忆、自然语言处理、深度强化学习、大型语言模型和迁移学习。
前馈神经网络(Feedforward Neural Network, FNN)作为深度学习中的一种基本网络结构,以其强大的非线性拟合能力和自适应性,在金融时间序列预测中展现出巨大的潜力。前馈神经网络通过模拟人脑神经元的连接方式,构建了一个多层次的计算模型,能够自动学习和提取数据中的复杂特征和规律,从而对未来的市场走势进行预测。
本文旨在探讨基于前馈神经网络实现股票单变量时间序列预测的方法。首先,我们将介绍前馈神经网络的基本原理和网络结构,为后续的研究提供理论基础。接着,我们将详细阐述如何使用前馈神经网络对股票时间序列数据进行建模和预测,包括数据的预处理、模型的构建、训练和优化等关键步骤。此外,我们还将探讨一些改进策略,如集成学习、特征选择等,以提高预测模型的准确性和鲁棒性。
FNN 单变量时间序列预测
- 1. 前馈神经网络(FNN)
- 1.1 前馈神经网络的基本原理和网络结构
- 1.2 FNN在金融时间序列预测中的应用
- 2. 数据预处理与特征工程
- 2.1 数据预处理
- 2.2 构造序列数据
- 2.3 特征缩放(归一化)
- 2.4 数据集划分(TimeSeriesSplit)
- 2.5 数据集张量(TensorDataset)
- 3. 构建时间序列模型(FNN)
- 3.1 构建 FNN 模型
- 3.2 定义模型、损失函数与优化器
- 4. 模型训练与 Loss 可视化
- 5. 模型评估与可视化
- 5.1 均方误差
- 5.2 反归一化
- 5.3 结果可视化
- 6. 模型预测
- 6.1 转换最新时间步收盘价的数组为张量
- 6.2 预测下一个时间点的收盘价格
1. 前馈神经网络(FNN)
1.1 前馈神经网络的基本原理和网络结构
前馈神经网络(Feedforward Neural Network)是一种常见的人工神经网络模型,它是由多个神经元组成的,这些神经元按照层次结构排列,并且不包含循环连接。
前馈神经网络的基本原理是将输入信号从输入层经过一系列的隐藏层传递到输出层,每个神经元将接受来自上一层神经元的输入,并通过激活函数将这些输入转化为输出。每个神经元的输出又作为下一层神经元的输入。
前馈神经网络的网络结构通常由输入层、隐藏层和输出层组成。输入层接受外部输入信号,并将其传递给隐藏层。隐藏层根据输入信号进行加权处理,并通过激活函数产生输出信号,这些输出信号又作为下一层隐藏层的输入。最后,输出层接受隐藏层的输出信号,并产生最终的输出结果。
每个神经元之间的连接权重决定了输入信号对输出信号的影响程度,这些权重可以通过训练过程不断调整以优化网络的性能。常见的训练方法包括反向传播算法(Backpropagation)和梯度下降算法(Gradient Descent)。
前馈神经网络可用于多种任务,如分类、回归和模式识别等。它在图像处理、语音识别、自然语言处理等领域有广泛的应用。由于神经网络的层次结构和权重调整能力,前馈神经网络可以学习复杂的非线性关系,并具有较强的泛化能力。
1.2 FNN在金融时间序列预测中的应用
FNN(Fuzzy Neural Network)是一种将模糊逻辑和神经网络相结合的方法,可以用于金融时间序列预测。它基于模糊逻辑的模糊推理和神经网络的学习能力,可以处理模糊和不确定的时间序列数据,提高预测的准确性。
在金融时间序列预测中,FNN可以用于以下方面的应用:
-
股价预测:FNN可以根据历史股价数据和相关指标,预测未来股价的走势。通过学习历史数据的模式和趋势,FNN可以捕捉到股价的复杂性和非线性关系,提供更准确的预测结果。
-
汇率预测:FNN可以根据过去的汇率数据和相关经济指标,预测未来的汇率变动趋势。通过将经济因素和技术指标考虑在内,FNN可以更好地分析汇率的影响因素,提高预测的精度。
-
利率预测:FNN可以根据历史利率数据和宏观经济指标,预测未来的利率变动。通过学习历史数据中的模式和趋势,FNN可以提供更准确的利率预测,为投资者和决策者提供参考。
-
量化交易策略:FNN可以用于开发量化交易策略,根据历史市场数据和技术指标,预测未来的市场走势,并制定相应的交易策略。通过结合模糊逻辑和神经网络的优势,FNN可以更好地捕捉市场的非线性动态,提高交易的准确性和效果。
总之,FNN在金融时间序列预测中的应用非常广泛,可以提供更准确和可靠的预测结果,对投资和决策具有重要的指导意义。
首先让我们导入所需模块
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as snsfrom sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import TimeSeriesSplitimport torch
import torch.nn as nn
from torch.utils.data import DataLoader, TensorDataset
from torchinfo import summary
from tqdm import tqdm
2. 数据预处理与特征工程
2.1 数据预处理
pandas.to_datetime 函数将标量、数组、Series 或 DataFrame/dict-like 转换为 pandas datetime 对象。
AAPL = pd.read_csv('AAPL.csv')
print(type(AAPL['Close'].iloc[0]),type(AAPL['Date'].iloc[0]))
# Let's convert the data type of timestamp column to datatime format
AAPL['Date'] = pd.to_datetime(AAPL['Date'])
print(type(AAPL['Close'].iloc[0]),type(AAPL['Date'].iloc[0]))# Selecting subset
cond_1 = AAPL['Date'] >= '2021-04-23 00:00:00'
cond_2 = AAPL['Date'] <= '2024-04-23 00:00:00'
AAPL = AAPL[cond_1 & cond_2].set_index('Date')
print(AAPL.shape)
<class 'numpy.float64'> <class 'str'>
<class 'numpy.float64'> <class 'pandas._libs.tslibs.timestamps.Timestamp'>
(755, 6)
2.2 构造序列数据
该函数需要两个参数:dataset 和 lookback,前者是要转换成数据集的 NumPy 数组,后者是用作预测下一个时间段的输入变量的前一时间步数,默认设为 1。
# 构造序列数据函数
def create_dataset(dataset, lookback=1):"""Transform a time series into a prediction datasetArgs:dataset: A numpy array of time series, first dimension is the time stepslookback: Size of window for prediction"""X, y = [], []for i in range(len(dataset)-lookback): feature = dataset[i:(i+lookback), 0]target = dataset[i + lookback, 0]X.append(feature)y.append(target)return np.array(X), np.array(y)
2.3 特征缩放(归一化)
MinMaxScaler() 函数主要用于将特征数据按比例缩放到指定的范围。默认情况下,它将数据缩放到[0, 1]区间内,但也可以通过参数设置将数据缩放到其他范围。在机器学习中,MinMaxScaler()函数常用于不同尺度特征数据的标准化,以提高模型的泛化能力。
# 选取AAPL['Close']作为特征, 归一化数据
scaler = MinMaxScaler(feature_range=(0, 1))
scaled_data = scaler.fit_transform(AAPL['Close'].values.reshape(-1, 1))
在时间序列分析中,时间窗口通常用于描述在训练模型时考虑的连续时间步 time steps 的数量。这个时间窗口的大小,即 window_size,对于模型预测的准确性至关重要。
具体来说,window_size 决定了模型在做出预测时所使用的历史数据的长度。例如,如果我们想要用前60天的股票数据来预测未来7天的收盘价,那么window_size 就是60。
# 设置时间窗口大小
window_size = 60
# 创建数据集
X, y = create_dataset(scaled_data, lookback=window_size)
# 重塑输入数据为[samples, time steps, features]
X = np.reshape(X, (X.shape[0], X.shape[1], 1))
2.4 数据集划分(TimeSeriesSplit)
TimeSeriesSplit() 函数与传统的交叉验证方法不同,TimeSeriesSplit 特别适用于需要考虑时间顺序的数据集,因为它确保测试集中的所有数据点都在训练集数据点之后,并且可以分割多个训练集和测试集。
# 使用TimeSeriesSplit划分数据集,根据需要调整n_splits
tscv = TimeSeriesSplit(n_splits=3, test_size=90)
# 遍历所有划分进行交叉验证
for i, (train_index, test_index) in enumerate(tscv.split(X)):X_train, X_test = X[train_index], X[test_index]y_train, y_test = y[train_index], y[test_index]# print(f"Fold {i}:")# print(f" Train: index={train_index}")# print(f" Test: index={test_index}")# 查看最后一个 fold 数据帧的维度
print(X_train.shape, X_test.shape, y_train.shape, y_test.shape)
(605, 60, 1) (90, 60, 1) (605,) (90,)
2.5 数据集张量(TensorDataset)
张量是一个多维数组或矩阵的数学对象,可以看作是向量和矩阵的推广。在深度学习中,张量通常用于表示输入数据、模型参数以及输出数据
# 将 NumPy数组转换为 tensor张量
X_train_tensor = torch.from_numpy(X_train).type(torch.Tensor).squeeze(dim=-1) # dim=-1 表示移除最后一个维度
X_test_tensor = torch.from_numpy(X_test).type(torch.Tensor).squeeze(dim=-1) # dim=-1 表示移除最后一个维度
y_train_tensor = torch.from_numpy(y_train).type(torch.Tensor).view(-1, 1)
y_test_tensor = torch.from_numpy(y_test).type(torch.Tensor).view(-1, 1)print(X_train_tensor.shape, X_test_tensor.shape, y_train_tensor.shape, y_test_tensor.shape)
torch.Size([605, 60]) torch.Size([90, 60]) torch.Size([605, 1]) torch.Size([90, 1])
在PyTorch中,squeeze() 函数的作用是从张量(tensor)的形状中删除所有大小为1的维度,或者根据指定的维度索引删除该维度上大小为1的维度, view() 函数用于重塑张量对象。它等同于 NumPy 中的 reshape() 函数,允许我们重组数据,以匹配 FNN 模型所需的输入形状。以这种方式重塑数据可确保 FNN 模型以预期格式接收数据。这对于模型能否有效模拟时间序列数据中的时间依赖关系至关重要。
接下来,使用 TensorDataset 和 DataLoader创建数据集和数据加载器
train_dataset = TensorDataset(X_train_tensor, y_train_tensor)
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
test_dataset = TensorDataset(X_test_tensor, y_test_tensor)
test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False)
shuffle=True 表示在每个epoch开始时,数据集将被随机打乱,这有助于防止模型在训练时过拟合。与训练数据加载器类似,shuffle=False 表示在测试时不需要打乱数据集。因为测试集通常用于评估模型的性能,而不是用于训练,所以不需要打乱。
3. 构建时间序列模型(FNN)
3.1 构建 FNN 模型
首先,我们使用 PyTorch 创建一个只有一个隐藏层的简单前馈神经网络。input_dim 表示滞后期的数量,也就是通常所说的回溯窗口。hidden_dim 是神经网络隐藏层中隐藏单元的数量。最后,output_dim 是预测范围,在下面的例子中设置为 1。最后,我们使用 R e L U ( ) ReLU() ReLU() 激活函数。
class FeedForwardNN(nn.Module):def __init__(self, input_dim, hidden_dim, output_dim):# input_dim 是时间回溯窗口,# output_dim 是输出维度# hidden_dim 是隐藏层神经单元维度或称为隐藏状态的大小,super(FeedForwardNN, self).__init__()# 通过调用 super(FeedForwardNN, self).__init__() 初始化父类 nn.Moduleself.fc1 = nn.Linear(input_dim, hidden_dim)# 定义全连接层fc1,将输入维度为input_dim的向量映射到维度为hidden_dim的向量self.fc2 = nn.Linear(hidden_dim, output_dim)# 定义全连接层fc2,将维度为 hidden_dim的向量映射到维度为 output_dim 的向量self.activation = nn.ReLU() # 定义 ReLU激活函数def forward(self, x):# 定义了前馈神经网络的前向传播方法,输入 x(通常是一个batch的数据)out = self.activation(self.fc1(x))out = self.fc2(out)return out
3.2 定义模型、损失函数与优化器
在神经网络中,模型通常指的是神经网络的架构,它定义了输入数据如何通过网络进行转换和计算,从而得到输出。在本案例中我们可以通过调用 FeedForwardNN 类来定义 FNN。
损失函数(又称代价函数)是衡量模型预测值与真实值之间不一致性的指标。在训练神经网络时,我们的目标是找到一组网络参数,它使得损失函数的值最小化。损失函数的选择取决于问题的类型,例如,对于回归问题,常用的损失函数包括均方误差(MSE);对于分类问题,则常使用交叉熵损失等。在PyTorch中,可以使用torch.nn模块中的损失函数类,如nn.MSELoss用于回归问题,nn.CrossEntropyLoss用于分类问题
优化器的任务是通过更新网络的权重和偏置来最小化损失函数。这通常是通过反向传播算法完成的,该算法计算损失相对于每个参数的梯度,并使用梯度下降或其变体来更新参数。在PyTorch中,torch.optim模块提供了多种优化器实现,如随机梯度下降(SGD)、带动量的SGD(Momentum)、RMSProp、Adam等。这些优化器都是基于梯度下降算法进行改进的,旨在更有效地更新模型参数。
model = FeedForwardNN(input_dim= X_train_tensor.shape[1], # 即时间回溯窗口 window_size,hidden_dim= 32,output_dim= 1)
criterion = torch.nn.MSELoss() # 定义均方误差损失函数
optimizer = torch.optim.Adam(model.parameters(), lr=0.001) # 定义优化器
summary(model, (32, 60, X_train_tensor.shape[1])) # batch_size, seq_len(time_steps), input_dim
==========================================================================================
Layer (type:depth-idx) Output Shape Param #
==========================================================================================
FeedForwardNN [32, 60, 1] --
├─Linear: 1-1 [32, 60, 32] 1,952
├─ReLU: 1-2 [32, 60, 32] --
├─Linear: 1-3 [32, 60, 1] 33
==========================================================================================
Total params: 1,985
Trainable params: 1,985
Non-trainable params: 0
Total mult-adds (Units.MEGABYTES): 0.06
==========================================================================================
Input size (MB): 0.46
Forward/backward pass size (MB): 0.51
Params size (MB): 0.01
Estimated Total Size (MB): 0.98
==========================================================================================
4. 模型训练与 Loss 可视化
train_loss = []
num_epochs = 200for epoch in range(num_epochs):model.train() # 初始化训练进程pbar = tqdm(train_loader, desc=f"Epoch {epoch+1}/{num_epochs}")for batch_idx, (data, target) in enumerate(pbar):# 前向传播outputs = model(data) # 每个批次的预测值loss = criterion(outputs, target)# 反向传播和优化optimizer.zero_grad()loss.backward()optimizer.step()# 记录损失值train_loss.append(loss.item())# 更新进度条pbar.update()# 这里只用于显示当前批次的损失,不是平均损失pbar.set_postfix({'Train loss': f'{loss.item():.4f}'})
Epoch 1/200: 100%|█████████████████████████████████████████████████| 19/19 [00:00<00:00, 606.82it/s, Train loss=0.0479]
Epoch 2/200: 100%|█████████████████████████████████████████████████| 19/19 [00:00<00:00, 608.82it/s, Train loss=0.0303]
Epoch 3/200: 100%|█████████████████████████████████████████████████| 19/19 [00:00<00:00, 608.25it/s, Train loss=0.0238]
Epoch 4/200: 100%|█████████████████████████████████████████████████| 19/19 [00:00<00:00, 608.91it/s, Train loss=0.0138]
Epoch 5/200: 100%|█████████████████████████████████████████████████| 19/19 [00:00<00:00, 607.99it/s, Train loss=0.0145]
Epoch 6/200: 100%|█████████████████████████████████████████████████| 19/19 [00:00<00:00, 404.97it/s, Train loss=0.0124]
Epoch 7/200: 100%|█████████████████████████████████████████████████| 19/19 [00:00<00:00, 607.82it/s, Train loss=0.0111]
Epoch 8/200: 100%|█████████████████████████████████████████████████| 19/19 [00:00<00:00, 608.29it/s, Train loss=0.0104]
Epoch 9/200: 100%|█████████████████████████████████████████████████| 19/19 [00:00<00:00, 607.65it/s, Train loss=0.0088]
Epoch 10/200: 100%|████████████████████████████████████████████████| 19/19 [00:00<00:00, 608.07it/s, Train loss=0.0082]
plt.plot(train_loss)

5. 模型评估与可视化
5.1 均方误差
model.eval() # 将模型设置为评估模式
test_loss = [] # 初始化损失
pbar = tqdm(test_loader, desc="Evaluating")
with torch.no_grad():for data, target in pbar:test_pred = model(data)loss = criterion(test_pred, target)test_loss.append(loss.item())# 计算当前批次的平均损失batch_avg_loss = sum(test_loss)/len(test_loss)pbar.set_postfix({'Test Loss': f'{batch_avg_loss:.4f}'})pbar.update() # 更新进度条pbar.close() # 关闭进度条
Evaluating: 100%|█████████████████████████████████████████████████████| 3/3 [00:00<00:00, 397.26it/s, Test Loss=0.0014]
5.2 反归一化
.inverse_transform 将经过转换或缩放的数据转换回其原始形式或接近原始形式
# 反归一化预测结果
train_pred = scaler.inverse_transform(model(X_train_tensor).detach().numpy())
y_train = scaler.inverse_transform(y_train_tensor.detach().numpy())
test_pred = scaler.inverse_transform(model(X_test_tensor).detach().numpy())
y_test = scaler.inverse_transform(y_test_tensor.detach().numpy())print(train_pred.shape, y_train.shape, test_pred.shape, y_test.shape)
5.3 结果可视化
计算训练预测与测试预测的绘图数据
# shift train predictions for plotting
trainPredict = AAPL[window_size:X_train.shape[0]+X_train.shape[1]]
trainPredictPlot = trainPredict.assign(TrainPrediction=train_pred)testPredict = AAPL[X_train.shape[0]+X_train.shape[1]:]
testPredictPlot = testPredict.assign(TestPrediction=test_pred)
绘制模型收盘价格的原始数据与预测数据
# Visualize the data
plt.figure(figsize=(18,6))
plt.title('FNN Close Price Validation')
plt.plot(AAPL['Close'], color='blue', label='original')
plt.plot(trainPredictPlot['TrainPrediction'], color='orange',label='Train Prediction')
plt.plot(testPredictPlot['TestPrediction'], color='red', label='Test Prediction')
plt.legend()
plt.show()

6. 模型预测
6.1 转换最新时间步收盘价的数组为张量
# 假设latest_closes是一个包含最新window_size个收盘价的列表或数组
latest_closes = AAPL['Close'][-window_size:].values
latest_closes = latest_closes.reshape(-1, 1)
scaled_latest_closes = scaler.fit_transform(latest_closes)
tensor_latest_closes = torch.from_numpy(scaled_latest_closes).type(torch.Tensor).view(1, window_size)
print(tensor_latest_closes.shape)
torch.Size([1, 60])
6.2 预测下一个时间点的收盘价格
# 使用模型预测下一个时间点的收盘价
next_close_pred = model(tensor_latest_closes)
next_close_pred = scaler.inverse_transform(next_close_pred.detach().numpy())
next_close_pred
array([[168.87936]], dtype=float32)
相关文章:
基于前馈神经网络 FNN 实现股票单变量时间序列预测(PyTorch版)
前言 系列专栏:【深度学习:算法项目实战】✨︎ 涉及医疗健康、财经金融、商业零售、食品饮料、运动健身、交通运输、环境科学、社交媒体以及文本和图像处理等诸多领域,讨论了各种复杂的深度神经网络思想,如卷积神经网络、循环神经网络、生成对…...

Scikit Learn - 建模手册(02)--- 数据表示、估算器
Scikit Learn - 数据表示 文章目录 一、说明二、数据表格2.1 数据作为特征矩阵2.2 数据作为目标数组 三、什么是 Estimator API四、Estimator API 的使用五、指导原则六、使用 Estimator API 的步骤七、监督学习示例八、无监督学习示例 一、说明 众所周知,机器学习…...

【鸿蒙学习笔记】通过用户首选项实现数据持久化
官方文档:通过用户首选项实现数据持久化 目录标题 使用场景第1步:源码第2步:启动模拟器第3步:启动entry第6步:操作样例2 使用场景 Preferences会将该数据缓存在内存中,当用户读取的时候,能够快…...

LabVIEW航空发动机试验器数据监测分析
1. 概述 为了适应航空发动机试验器的智能化发展,本文基于图形化编程工具LabVIEW为平台,结合航空发动机试验器原有的软硬件设备,设计开发了一套数据监测分析功能模块。主要阐述了数据监测分析功能设计中的设计思路和主要功能,以及…...

快速上手:前后端分离开发(Vue+Element+Spring Boot+MyBatis+MySQL)
文章目录 前言项目简介环境准备第一步:初始化前端项目登录页面任务管理页面 第二步:初始化后端项目数据库配置数据库表结构实体类和Mapper服务层和控制器 第三步:连接前后端总结 🎉欢迎来到架构设计专栏~探索Java中的静态变量与实…...
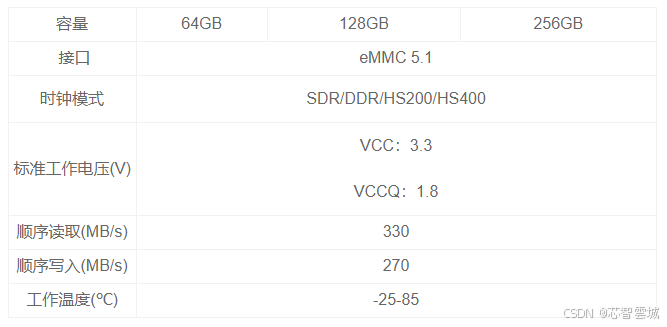
产品推荐| 长江存储eMMC嵌入式储存 YMTC EC230
产品详情 EC230是基于长江存储晶栈Xtacking3.0三维闪存架构打造的新一代eMMC 5.1嵌入式存储产品。EC230的最大顺序读取速度达330MB/s,支持动态SLC缓存,为终端设备提供稳定高性能;支持自动后台/自动节能等操作,减少设备延迟&#…...

【Linux】IP地址与主机名
文章目录 1.IP地址2.特殊IP地址3.主机名4.域名解析 1.IP地址 每一台联网的电脑都会有一个地址,用于和其它计算机进行通讯 IP地址主要有2个版本,V4版本和V6版本 IPv4版本的地址格式是:a.b.c.d,其中abcd表示0~255的数字,如192.168.…...

ros2--colcon
colcon ros2的编译工具,用于编译ros2项目; 需要在工作空间,也就是src上一级目录colcon build; 很明显colcon作为构建工具,通过调用CMake、Python setuptools完成构建。 小鱼文档 构建参数 --packages-select 仅构…...

PyCharm 2023.3.2 关闭时一直显示正在关闭项目
文章目录 一、问题描述二、问题原因三、解决方法 一、问题描述 PyCharm 2023.3.2 关闭时一直显示正在关闭项目 二、问题原因 因为PyCharm还没有加载完索引导致的 三、解决方法 方法一: 先使用任务管理器强制关闭,下次关闭时注意要等待PyCharm加载完索…...

VS2022 git拉取/推送代码错误
第一步:打开VS2022 第二步:工具->选项->源代码管理->Git 全局设置 第三步:加密网络提供程序设置为:OpenSSL 完结:...

【Vue】vue3中使用swipe竖直方向上滚动
安装 npm install swipe使用 import swiper/css; import swiper/css/mousewheel; import { Swiper, SwiperSlide } from swiper/vue; import { Mousewheel } from swiper/modules;containerHeight 是容器的高度,一定要设置竖直方向上滚动高度,不然会非…...

搭建基于 ChatGPT 的问答系统
搭建基于 ChatGPT 的问答系统 📣1.简介📣2.模型,范式和 token📣3.检查输入-分类📣4.检查输入-监督📣5.思维链推理📣6.提示链📣7.检查输入📣8.评估(端到端系统…...

C++运行时类型识别
目录 C运行时类型识别A.What(什么是运行时类型识别RTTI)B.Why(为什么需要RTTI)C.dynamic_cast运算符Why(dynamic_cast运算符的作用)How(如何使用dynamic_cast运算符) D.typeid运算符…...

在微信上怎么制作一个商城链接
在这个快节奏的时代,每一分每一秒都显得尤为珍贵。随着移动互联网的飞速发展,我们的生活方式正经历着前所未有的变革,其中,微信作为国民级社交应用,早已超越了简单的聊天功能,成为了集社交、支付、生活服务…...

怎么搭建微信商城
在当今这个数字化时代,微信已成为人们日常生活中不可或缺的一部分,它不仅改变了我们的社交方式,更引领了商业营销的新潮流。微信商城作为微信生态内的一个重要组成部分,正以其独特的优势助力商家们实现线上销售的突破。本文将带您…...

【每日一练】python的类.对象.成员.行为.方法传参综合实例(保姆式教学)
运行结果: 本节课程内容:类的使用 1.掌握类的定义和使用方法 2.掌握类的成员的方法使用 3.掌握self关键字的作用 4.定义在类里的函数是类的一种行为,叫方法 5.带传参的行为使用方法 类基本分两部分组成:1.属性,2.方法 类的使用语法…...

Windows 如何打开表情符号面板并使用?
打开面板的方法 想要打开表情符号面板其实非常简单,只需要使用快捷键“Win.”或者“Win;”即可。按下快捷键之后就可以调用出表情符号键盘。 在面板中我们可以看见顶部的三个选项,分别是表情符号、颜文字和符号,表情符号就是上面…...

编程语言里的双斜杠:深入解析其神秘面纱
编程语言里的双斜杠:深入解析其神秘面纱 在编程语言的广阔天地中,双斜杠(//)这一看似简单的符号,实则蕴含着丰富的内涵和用途。它既是注释的标识,又是特定语法结构的组成部分,甚至在某些情况下…...
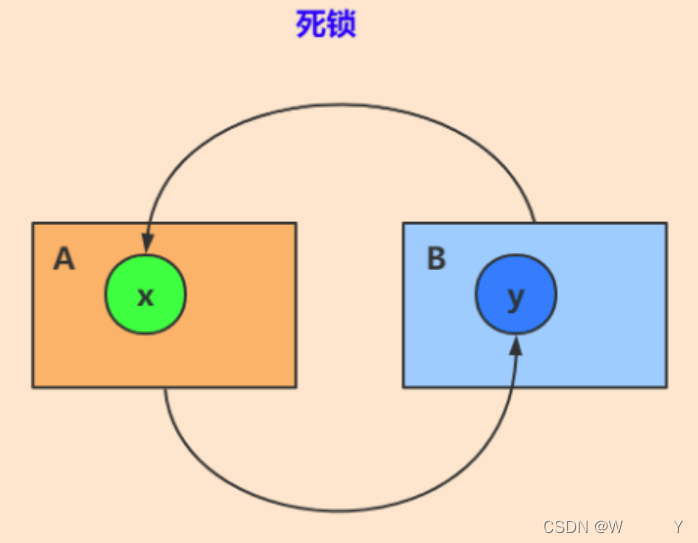
【架构-20】死锁
什么是死锁? 死锁(Deadlock)是指两个或多个线程/进程在执行过程中,由于资源的互相占用和等待,而陷入一种互相等待的僵局,无法继续往下执行的情况。 产生死锁的四个必要条件: (1)互斥条件(Mutual Exclusion):至少有一个资源是非共享…...

Chat2DB:AI引领下的全链路数据库管理新纪元
一、引言 随着数据驱动决策成为现代企业和组织的核心竞争力,数据库管理工具的重要性日益凸显。然而,传统的数据库管理工具往往存在操作复杂、功能单一、不支持多类型数据库管理等问题,限制了数据的有效利用。为了打破这一局面,Ch…...

日语AI面试高效通关秘籍:专业解读与青柚面试智能助攻
在如今就业市场竞争日益激烈的背景下,越来越多的求职者将目光投向了日本及中日双语岗位。但是,一场日语面试往往让许多人感到步履维艰。你是否也曾因为面试官抛出的“刁钻问题”而心生畏惧?面对生疏的日语交流环境,即便提前恶补了…...

超短脉冲激光自聚焦效应
前言与目录 强激光引起自聚焦效应机理 超短脉冲激光在脆性材料内部加工时引起的自聚焦效应,这是一种非线性光学现象,主要涉及光学克尔效应和材料的非线性光学特性。 自聚焦效应可以产生局部的强光场,对材料产生非线性响应,可能…...

Xshell远程连接Kali(默认 | 私钥)Note版
前言:xshell远程连接,私钥连接和常规默认连接 任务一 开启ssh服务 service ssh status //查看ssh服务状态 service ssh start //开启ssh服务 update-rc.d ssh enable //开启自启动ssh服务 任务二 修改配置文件 vi /etc/ssh/ssh_config //第一…...

JavaScript 中的 ES|QL:利用 Apache Arrow 工具
作者:来自 Elastic Jeffrey Rengifo 学习如何将 ES|QL 与 JavaScript 的 Apache Arrow 客户端工具一起使用。 想获得 Elastic 认证吗?了解下一期 Elasticsearch Engineer 培训的时间吧! Elasticsearch 拥有众多新功能,助你为自己…...

渗透实战PortSwigger靶场-XSS Lab 14:大多数标签和属性被阻止
<script>标签被拦截 我们需要把全部可用的 tag 和 event 进行暴力破解 XSS cheat sheet: https://portswigger.net/web-security/cross-site-scripting/cheat-sheet 通过爆破发现body可以用 再把全部 events 放进去爆破 这些 event 全部可用 <body onres…...

Map相关知识
数据结构 二叉树 二叉树,顾名思义,每个节点最多有两个“叉”,也就是两个子节点,分别是左子 节点和右子节点。不过,二叉树并不要求每个节点都有两个子节点,有的节点只 有左子节点,有的节点只有…...

Unity | AmplifyShaderEditor插件基础(第七集:平面波动shader)
目录 一、👋🏻前言 二、😈sinx波动的基本原理 三、😈波动起来 1.sinx节点介绍 2.vertexPosition 3.集成Vector3 a.节点Append b.连起来 4.波动起来 a.波动的原理 b.时间节点 c.sinx的处理 四、🌊波动优化…...
多光源(Multiple Lights))
C++.OpenGL (14/64)多光源(Multiple Lights)
多光源(Multiple Lights) 多光源渲染技术概览 #mermaid-svg-3L5e5gGn76TNh7Lq {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-3L5e5gGn76TNh7Lq .error-icon{fill:#552222;}#mermaid-svg-3L5e5gGn76TNh7Lq .erro…...
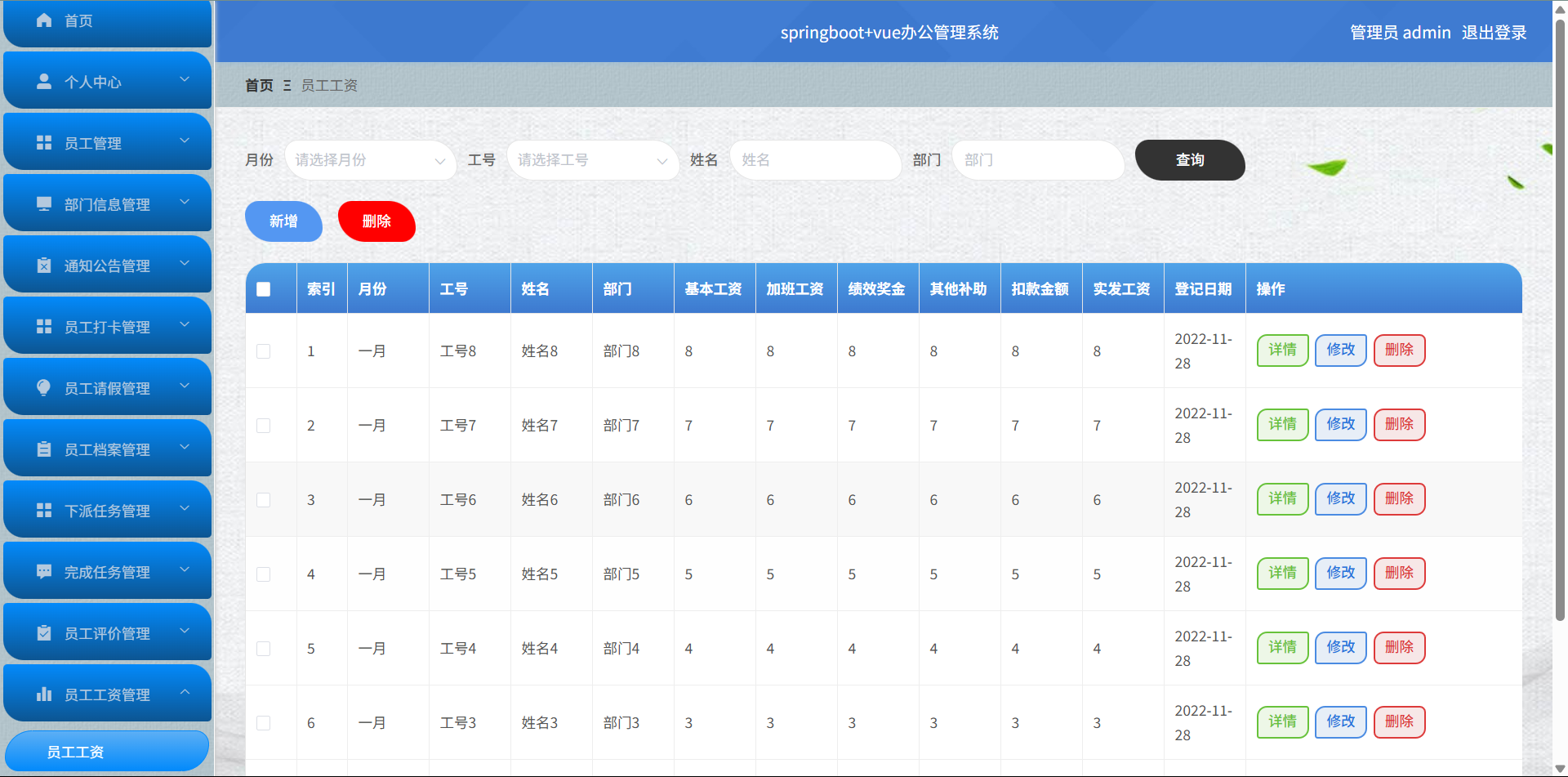
基于Springboot+Vue的办公管理系统
角色: 管理员、员工 技术: 后端: SpringBoot, Vue2, MySQL, Mybatis-Plus 前端: Vue2, Element-UI, Axios, Echarts, Vue-Router 核心功能: 该办公管理系统是一个综合性的企业内部管理平台,旨在提升企业运营效率和员工管理水…...

R 语言科研绘图第 55 期 --- 网络图-聚类
在发表科研论文的过程中,科研绘图是必不可少的,一张好看的图形会是文章很大的加分项。 为了便于使用,本系列文章介绍的所有绘图都已收录到了 sciRplot 项目中,获取方式: R 语言科研绘图模板 --- sciRplothttps://mp.…...