C++:哈希表
哈希表概念
哈希表可以简单理解为:把数据转化为数组的下标,然后用数组的下标对应的值来表示这个数据。如果我们想要搜索这个数据,直接计算出这个数据的下标,然后就可以直接访问数组对应的位置,所以可以用O(1)的复杂度直接找到数据。
其中,这个数据对应的数字叫做关键码(Key),这个把关键码转化为下标的规则,叫做哈希函数(Hash)。
要注意的是,有一些数据并不是整型,比如字符串,对象等等。对于这种数据,我们要先用一套规则把它们转化为整数(关键码),然后再通过哈希函数映射为数组下标。
哈希函数
哈希函数原则:
- 哈希函数转换后,生成的地址(下标)必须小于哈希表的最大地址(下标)
- 哈希函数计算出来的地址(下标)必须均匀地分布
- 哈希函数尽可能简单
直接定址法
取关键字的某个线性函数为哈希表的地址:

除留余数法
假设哈希表的地址数目为
m,取Key对m取模后得到的值作为下标

闭散列 - 开放定址法
闭散列,也叫做开放定址法,当发生哈希冲突时,如果哈希表没有被装满,说明哈希表中还有空位置,那么我们可以把发生冲突的数据放到下一个空位置去。
基本结构
首先我们需要一个枚举,来标识哈希表的不同状态:
enum State
{EMPTY,EXIST,DELETE
};
EMPTY:空节点EXIST:数值存在DELETE:数值被删除
哈希表的基本结构:
enum State
{EMPTY,EXIST,DELETE
};template<class K, class V>
struct HashData
{pair<K, V> _kv;State _state = EMPTY;//标记状态
};template<class K, class V>
class HashTable
{
public:HashTable(size_t size = 10){_tables.resize(size);}private:vector<HashData<K, V>> _tables;//哈希表size_t _n = 0;//元素个数
};
HashTable构造函数:
HashTable(size_t size = 10)
{_tables.resize(size);
}查找
想要在哈希表中查找数据,无非就遵顼以下规则:
通过哈希函数计算出数据对应的地址
去地址处查找,如果地址处不是目标值,往后继续查找
遇到EMPTY还没有找到,说明数据不存在哈希表中
遇到DELETE和EXIST,继续往后查找
代码如下:
HashData<K, V>* Find(const K& key)
{size_t hashi = key % _tables.size();while (_tables[hashi]._state != EMPTY){if (_tables[hashi]._kv.first == key&& _tables[hashi]._state == EXIST)return &_tables[hashi];hashi++;hashi %= _tables.size();}return nullptr;
}
但是当前的代码存在一个问题:哈希表作用于泛型,key % _tables.size()有可能是违法的行为,因为key可能不是一个数字。
对此我们可以在模板中多加一个仿函数的参数,用户可以在仿函数中自定义数据 -> 整型的转换规则,然后我们在对这个整型使用除留余数法获取地址。
在那之前,我们可以先写一个仿函数,用于处理整型 -> 整型的转化:
struct HashFunc
{size_t operator()(const K& key){return (size_t)key;}
};
在STL中,整型-> 整型转化的函数,被写为了一个模板,而这个string -> 整型被写为了一个模板特化:
template<class K>
struct HashFunc
{size_t operator()(const K& key){return (size_t)key;}
};template<>
struct HashFunc<string>
{size_t operator()(const string& s){size_t hash = 0;for (auto& e : s)//把字符串的每一个字符ASCII码值加起来{hash += e;hash *= 131; // 31, 131313(任意由1,3间断排列的数字)}return hash;}
};
我们将这个HashFunc<K>仿函数作为哈希表的第三个模板参数的默认值:
template<class K, class V, class Hash = HashFunc<K>>
class HashTable
{};通过仿函数来统一获得整型,再进行除留余数操作:
Hash hs;
size_t hashi = hs(key) % _tables.size();插入
插入的基本逻辑如下:
- 先通过Find接口,查找目标值在不在哈希表中,如果目标值已经存在,返回flse,表示插入失败
- 通过哈希函数计算出目标值对应的下标
- 向下标中插入数据:如果下标对应的位置已经有数据,往后查找,直到某一个位置为
EMPTY或者DELETE.如果下标对应的位置没有数据,直接插入- 插入后,把对应位置的状态转化为
EXIST
代码如下:
bool Insert(const pair<K, V>& kv)
{if (Find(kv.first))return false;Hash hs;//仿函数实例化出的对象size_t hashi = hs(kv.first) % _tables.size();//获得目标值对应的下标while (_tables[hashi]._state == EXIST)//往后查找合适的位置插入{hashi++;hashi %= _tables.size();}_tables[hashi]._kv = kv;//插入_tables[hashi]._state = EXIST;//改变状态_n++;//哈希表中的元素个数+1return true;
}
当这个哈希表越满,我们查找数据的效率就越低,甚至说:如果查找一个不存在的数据,我们可能要用O(N)的复杂度遍历整个哈希表.因此我们因该把哈希表的负载率控制在一定值,当超过一定值,我们就要进行扩容操作。
if ((double)_n / _tables.size() >= 0.7)
{size_t newSize = _tables.size() * 2;HashTable<K, V, Hash> newHT(newSize);for (auto& e : _tables){if (e._state == EXIST)newHT.Insert(e._kv);}_tables.swap(newHT._tables);
}
插入总代码:
bool Insert(const pair<K, V>& kv)
{if (Find(kv.first))return false;if ((double)_n / _tables.size() >= 0.7){size_t newSize = _tables.size() * 2;HashTable<K, V, Hash> newHT(newSize);for (auto& e : _tables){if (e._state == EXIST)newHT.Insert(e._kv);}_tables.swap(newHT._tables);}Hash hs;size_t hashi = hs(kv.first) % _tables.size();while (_tables[hashi]._state == EXIST){hashi++;hashi %= _tables.size();}_tables[hashi]._kv = kv;_tables[hashi]._state = EXIST;_n++;return true;
}
删除
先通过Find接口找到要删除的值
- 如果没找到,返回false,表示删除失败
- 如果找到,把对应节点的状态改为
DELETE最后再把哈希表的
_n - 1,表示存在的节点数少了一个。
代码如下:
bool Erase(const K& key)
{HashData<K, V>* ret = Find(key);if (ret){ret->_state = DELETE;_n--;return true;}return false;
}
总代码展示
template<class K>
struct HashFunc
{size_t operator()(const K& key){return (size_t)key;}
};template<>
struct HashFunc<string>
{size_t operator()(const string& s){size_t hash = 0;for (auto& e : s)//把字符串的每一个字符ASCII码值加起来{hash += e;hash *= 131; // 31, 131313(任意由1,3间断排列的数字)}return hash;}
};enum State
{EMPTY,EXIST,DELETE
};template<class K, class V>
struct HashData
{pair<K, V> _kv;State _state = EMPTY;//标记状态
};template<class K, class V, class Hash = HashFunc<K>>
class HashTable
{
public:HashTable(size_t size = 10){_tables.resize(size);}HashData<K, V>* Find(const K& key){Hash hs;size_t hashi = hs(key) % _tables.size();while (_tables[hashi]._state != EMPTY){if (_tables[hashi]._kv.first == key&& _tables[hashi]._state == EXIST)return &_tables[hashi];hashi++;hashi %= _tables.size();}return nullptr;}bool Insert(const pair<K, V>& kv){if (Find(kv.first))return false;if ((double)_n / _tables.size() >= 0.7){size_t newSize = _tables.size() * 2;HashTable<K, V, Hash> newHT(newSize);for (auto& e : _tables){if (e._state == EXIST)newHT.Insert(e._kv);}_tables.swap(newHT._tables);}Hash hs;size_t hashi = hs(kv.first) % _tables.size();while (_tables[hashi]._state == EXIST){hashi++;hashi %= _tables.size();}_tables[hashi]._kv = kv;_tables[hashi]._state = EXIST;_n++;return true;}bool Erase(const K& key){HashData<K, V>* ret = Find(key);if (ret){ret->_state = DELETE;_n--;return true;}return false;}private:vector<HashData<K, V>> _tables;size_t _n = 0;//元素个数
};
开散列 - 哈希桶
在STL库中,采用的是更加优秀的开散列方案。
哈希表的数组vector中,不再直接存储数据,而是存储一个链表的指针。当一个数值映射到对应的下标后,就插入到这个链表中。其中每一个链表称为一个哈希桶,每个哈希桶中,存放着哈希冲突的元素.
基本结构
对于每一个节点,其要存储当前节点的值,也要存储下一个节点的指针,基本结构如下:
template<class K, class V>
struct HashNode
{HashNode<K, V>* _next;pair<K, V> _kv;HashNode(const pair<K, V>& kv):_kv(kv),_next(nullptr){}
};
哈希表:
template<class K, class V, class Hash = HashFunc<K>>
class HashTable
{typedef HashNode<K, V> Node;
public:HashTable(size_t size = 10){_tables.resize(size);}private:vector<Node*> _tables; //链表指针数组size_t _n = 0;//元素个数
};
析构函数,防止内存泄漏:
~HashTable()
{for (size_t i = 0; i < _tables.size(); i++){Node* cur = _tables[i];while (cur){Node* next = cur->_next;delete cur;cur = next;}_tables[i] = nullptr;}
}
查找
查找的基本逻辑如下:
- 先通过哈希函数计算出数据对应的下标
- 通过下标找到对应的链表
- 遍历链表,找数据:如果某个节点的数据匹配上了,返回该节点指针,如果遍历到了nullptr,返回空指针表示没找到
代码如下:
Node* Find(const K& key)
{Hash hs;size_t hashi = hs(key) % _tables.size();Node* cur = _tables[hashi];while (cur){if (cur->_kv.first == key)return cur;cur = cur->_next;}return nullptr;
}
插入
插入的基本逻辑如下:
- 先通过Find接口,查找目标值在不在哈希表中,如果目标值已经存在,返回flse,表示插入失败
- 通过哈希函数计算出目标值对应的下标
- 向下标中插入数据
代码如下:
bool Insert(const pair<K, V>& kv)
{if (Find(kv.first))return false;Hash hs;size_t hashi = hs(kv.first) % _tables.size();//计算下标Node* newNode = new Node(kv);//创建节点newNode->_next = _tables[hashi];//头插_tables[hashi] = newNode;++_n;//更新元素个数return true;
}
关于扩容:如果我们单纯的进行插入,就要把原先的所有节点释放掉,再创建新的节点。这样会浪费很多时间。我们最好把原先创建的节点利用起来,因此我们要重写一个逻辑,把原先的节点进行迁移。
if (_n == _tables.size())
{vector<Node*> newTables(_tables.size() * 2, nullptr);for (size_t i = 0; i < _tables.size(); i++){Node* cur = _tables[i];while (cur){Node* next = cur->_next;size_t hashi = hs(cur->_kv.first) % newTables.size();cur->_next = newTables[hashi];newTables[hashi] = cur;cur = next;}_tables[i] = nullptr; //防止移交的节点被析构}_tables.swap(newTables);
}
删除
删除逻辑:
- 通过哈希函数计算出对应的下标
- 到对应的哈希桶中查找目标值
- 如果找到,删除对应的节点
- 如果没找到,返回false表示删除失败
_n - 1表示删除了一个元素
代码如下:
bool Erase(const K& key)
{Hash hs;size_t hashi = hs(key) % _tables.size();Node* prev = nullptr;Node* cur = _tables[hashi];while (cur){if (cur->_kv.first == key){if (prev)prev->_next = cur->_next;else_tables[hashi] = cur->_next;delete cur;--_n;return true;}prev = cur;cur = cur->_next;}return false;
}
代码展示
template<class K>
struct HashFunc
{size_t operator()(const K& key){return (size_t)key;}
};template<>
struct HashFunc<string>
{size_t operator()(const string& s){size_t hash = 0;for (auto& e : s)//把字符串的每一个字符ASCII码值加起来{hash += e;hash *= 131; // 31, 131313(任意由1,3间断排列的数字)}return hash;}
};template<class K, class V>
struct HashNode
{HashNode<K, V>* _next;pair<K, V> _kv;HashNode(const pair<K, V>& kv):_kv(kv),_next(nullptr){}
};template<class K, class V, class Hash = HashFunc<K>>
class HashTable
{typedef HashNode<K, V> Node;
public:HashTable(size_t size = 10){_tables.resize(size);}~HashTable(){for (size_t i = 0; i < _tables.size(); i++){Node* cur = _tables[i];while (cur){Node* next = cur->_next;delete cur;cur = next;}_tables[i] = nullptr;}}Node* Find(const K& key){Hash hs;size_t hashi = hs(key) % _tables.size();Node* cur = _tables[hashi];while (cur){if (cur->_kv.first == key)return cur;cur = cur->_next;}return nullptr;}bool Insert(const pair<K, V>& kv){if (Find(kv.first))return false;Hash hs;//哈希桶情况下,负载因子到1才扩容if (_n == _tables.size()){vector<Node*> newTables(_tables.size() * 2, nullptr);for (size_t i = 0; i < _tables.size(); i++){Node* cur = _tables[i];while (cur){Node* next = cur->_next;size_t hashi = hs(cur->_kv.first) % newTables.size();cur->_next = newTables[hashi];newTables[hashi] = cur;cur = next;}_tables[i] = nullptr; //防止移交的节点被析构}_tables.swap(newTables);}size_t hashi = hs(kv.first) % _tables.size();Node* newNode = new Node(kv);newNode->_next = _tables[hashi];_tables[hashi] = newNode;++_n;return true;}bool Erase(const K& key){Hash hs;size_t hashi = hs(key) % _tables.size();Node* prev = nullptr;Node* cur = _tables[hashi];while (cur){if (cur->_kv.first == key){if (prev)prev->_next = cur->_next;else_tables[hashi] = cur->_next;delete cur;--_n;return true;}prev = cur;cur = cur->_next;}return false;}private:vector<Node*> _tables; //链表指针数组size_t _n = 0;//元素个数
};
相关文章:
C++:哈希表
哈希表概念 哈希表可以简单理解为:把数据转化为数组的下标,然后用数组的下标对应的值来表示这个数据。如果我们想要搜索这个数据,直接计算出这个数据的下标,然后就可以直接访问数组对应的位置,所以可以用O(1)的复杂度…...

自己动手写一个滑动验证码组件(后端为Spring Boot项目)
近期参加的项目,主管丢给我一个任务,说要支持滑动验证码。我身为50岁的软件攻城狮,当时正背着双手,好像一个受训的保安似的,中规中矩地参加每日站会,心想滑动验证码在今时今日已经是标配了,司空…...

keepalive脑裂
keepalive脑裂 调度器的高可用 vip地址主备之间的切换,主在工作时,p地址只在主上,主停止工作,ip飘移到备服务器。 在主备的优先级不变的情况下,主恢复工作,vip会飘回到主服务器。 1、配优先级 2、配置…...

STM32Cubemx配置生成 Keil AC6支持代码
文章目录 一、前言二、AC 6配置2.1 ARM ComPiler 选择AC62.2 AC6 UTF-8的编译命令会报错 三、STM32Cubemx 配置3.1 找到stm32cubemx的模板位置3.2 替换文件内核文件3.3 修改 cmsis_os.c文件3.4 修改本地 四、编译对比 一、前言 使用keil ARM compiler V5的时候,编译…...

Perl基础入门指南:从零开始掌握Perl编程
Perl是一种功能强大且灵活的编程语言,广泛应用于系统管理、Web开发、网络编程和文本处理等领域。如果你是编程新手或者想学习一种新的编程语言,Perl是一个不错的选择。本文将带你了解Perl的基础知识,并通过简单的示例代码帮助你快速入门。 什…...

Mybatis SQL注解使用场景
MyBatis 提供了几种常用的注解,主要用于简化 XML 映射文件的编写,使得 SQL 查询和操作可以直接在 Java 接口中定义。下面列出了主要的注解以及它们在被调用时的写法示例: 1. Select Select 注解用于执行查询操作,并将查询结果映…...

Dataset for Stable Diffusion
1.Dataset for Stable Diffusion 笔记来源: 1.Flickr8k数据集处理 2.处理Flickr8k数据集 3.Github:pytorch-stable-diffusion 4.Flickr 8k Dataset 5.dataset_flickr8k.json 1.1 Dataset 采用Flicker8k数据集,该数据集有两个文件ÿ…...

近期matlab学习笔记,学习是一个记录,反复的过程
近期matlab学习笔记,学习是一个记录,反复的过程 matlab的mlx文件在运行的时候,不需要在文件夹路径下,也能运行,但是需要调用子函数时,就需要在文件所在路径下运行 那就先运行子函数,把路径换过来…...

Elasticsearch7.5.2 常用rest api与elasticsearch库
目录 一、rest api 1. 新建索引 2. 删除索引 3. 插入单条数据 4. 更新单条数据 5. 删除单条数据 6. 查询数据 二、python elasticsearch库 1. 新建索引 一、rest api 1. 新建索引 请求方式:PUT 请求URL:http://ip/(your_index_nam…...
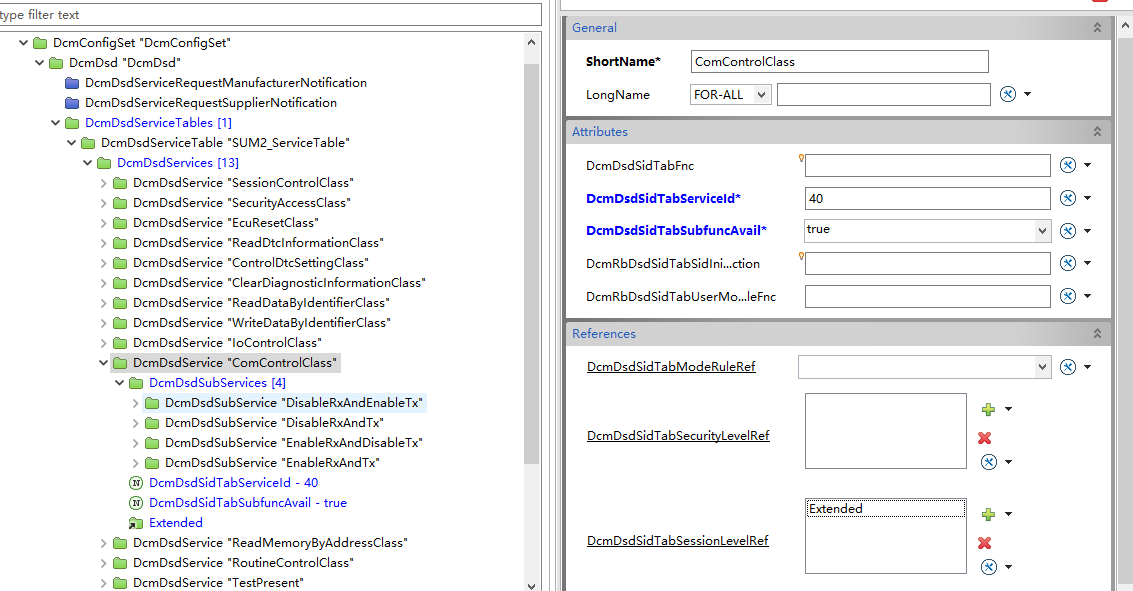
Autosar Dcm配置-0x28服务ComControl-基于ETAS软件
文章目录 前言DcmDcmDsdDcmDspBswMBswMModeRequestPortBswMModeConditionBswMLogicalExpressionBswMActionBswMActionListBswMRule总结前言 0x28服务主要用来控制非诊断报文的通讯,一般在刷写预编程过程中,用来禁止APP的通信报文,可以减少总线负载率,提高刷写成功率。本文…...

平安养老险厦门分公司:提升金融服务,发挥金融力量
为向社会公众普及金融保险知识,传递消费者权益保护理念,平安养老保险股份有限公司厦门分公司(以下简称“分公司”)积极开展“78保险公众宣传日”系列教育宣传活动。分公司紧扣“保险,让每一步前行更有底气”主题&#…...
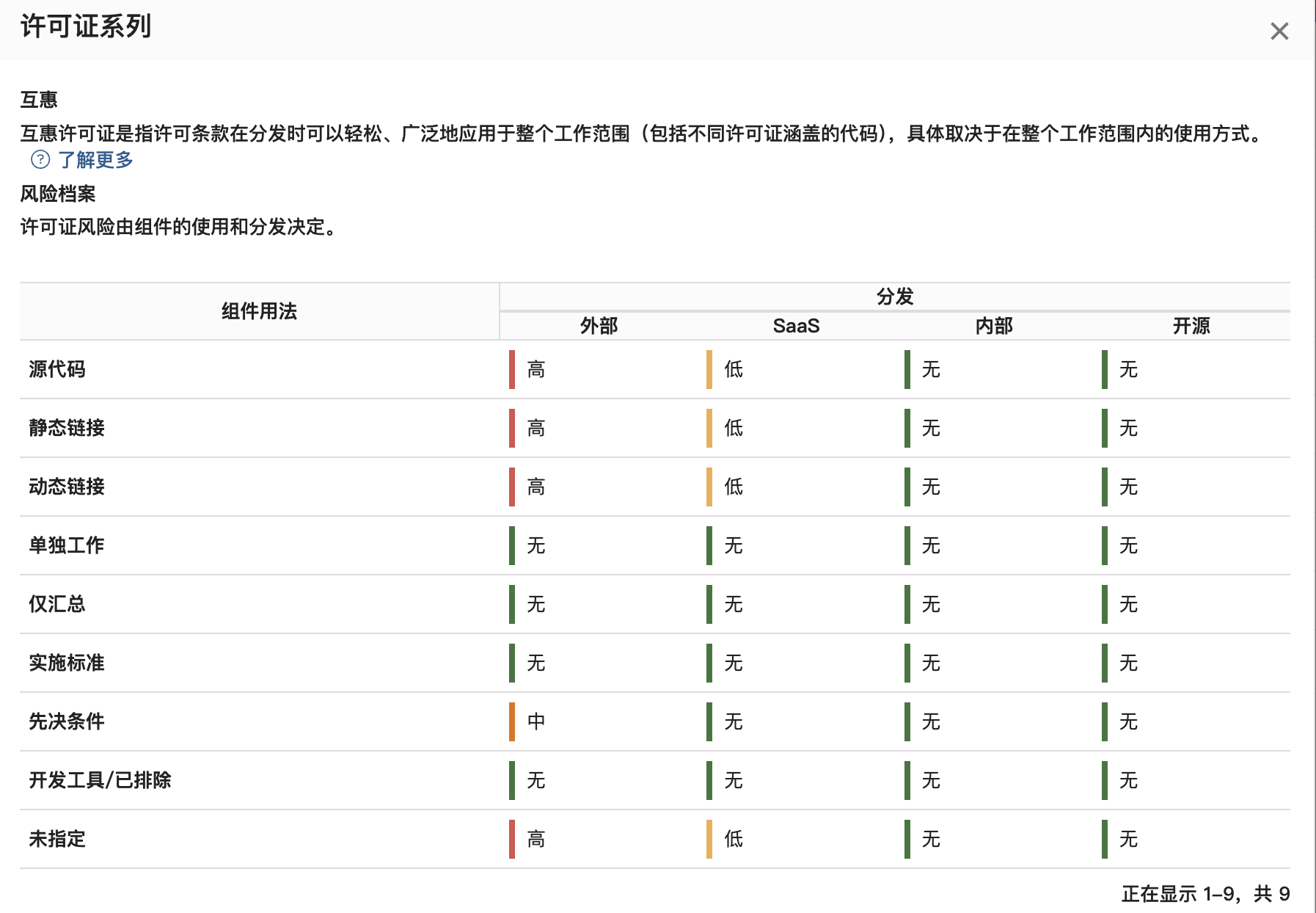
【开源合规】开源许可证风险场景详细解读
文章目录 前言关于BlackDuck许可证风险对比图弱互惠型许可证举个例子具体示例LGPL系列LGPL-2.0-onlyLGPL-2.0-or-laterLGPL-2.1-onlyLGPL-2.1-or-laterLGPL-3.0-onlyLGPL-3.0-or-laterMPL系列MPL-1.0MPL-1.1MPL-2.0EPL系列EPL-1.0EPL-2.0互惠型许可证GPL系列GPL-1.0GPL-2.0GPL-…...
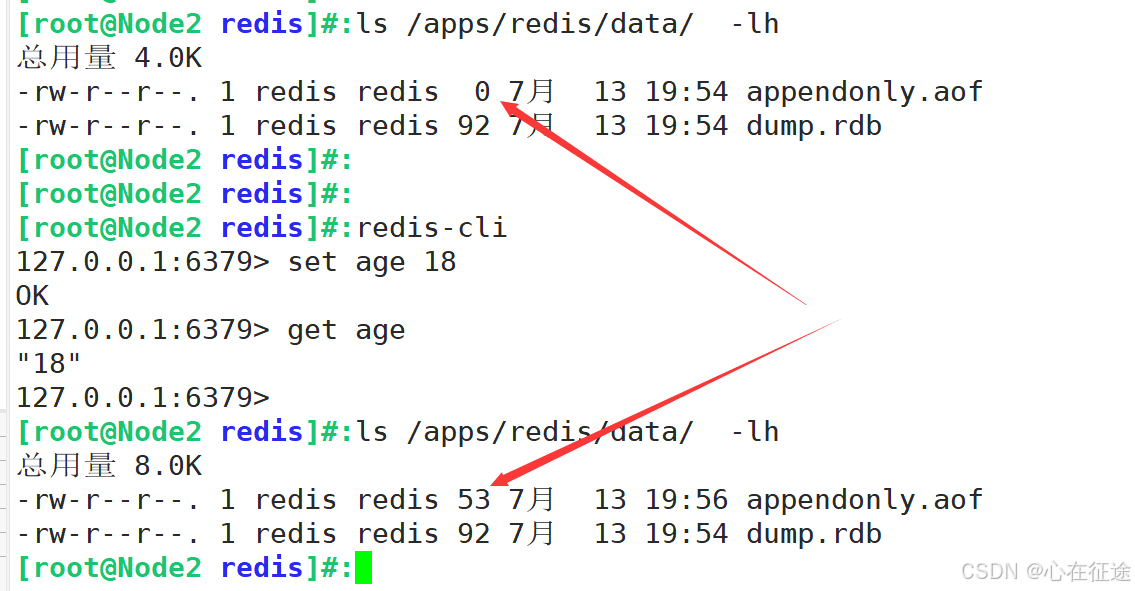
Redis持久化RDB,AOF
目 录 CONFIG动态修改配置 慢查询 持久化 在上一篇主要对redis的了解入门,安装,以及基础配置,多实例的实现:redis的安装看我上一篇: Redis安装部署与使用,多实例 redis是挡在MySQL前面的,运行在内存…...
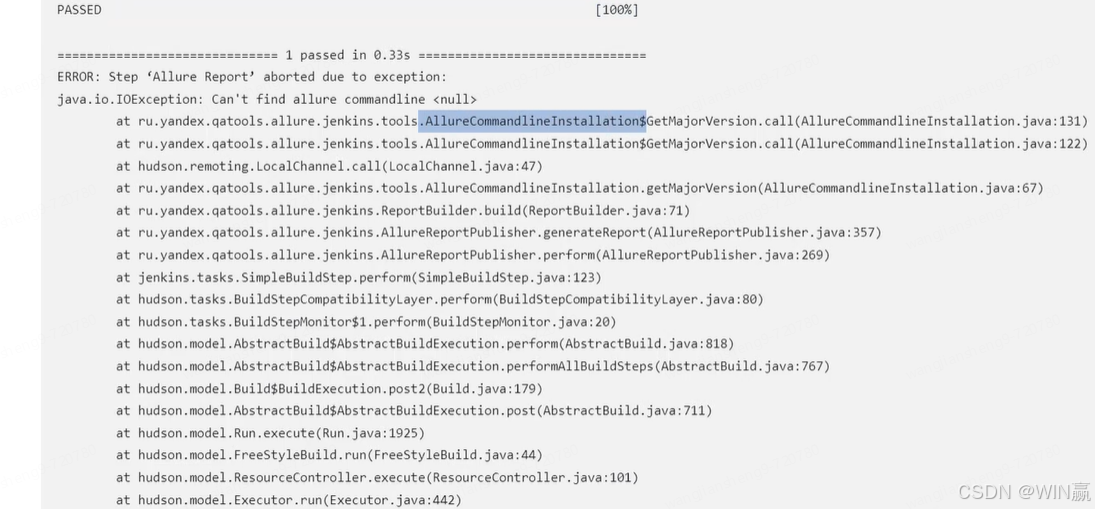
【持续集成_03课_Linux部署Sonar+Gogs+Jenkins】
一、通过虚拟机搭建Linux环境-CnetOS 1、安装virtualbox,和Vmware是一样的,只是box更轻量级 1)需要注意内存选择,4G 2、启动完成后,需要获取服务器IP地址 命令 ip add 服务器IP地址 通过本地的工具,进…...

mvcc 速读
MVCC(Multi-Version Concurrency Control,多版本并发控制)是MySQL中一种用于实现数据库并发控制的方法,尤其在InnoDB存储引擎中得到了广泛应用。它的主要作用是提高数据库在高并发场景下的性能,并确保数据的一致性。 …...

美容仪维修过程记录
近期维修的家用射频美容仪,发一些维修过程的拆机图片...
STM32入门开发操作记录(一)——新建工程
目录 一、课程准备1. 课程资料2. 配件清单3. 根目录 二、环境搭建三、新建工程1. 载入器件支持包2. 添加模块3. ST配置4. 外观设置5. 主函数文件 一、课程准备 1. 课程资料 本记录操作流程参考自b站视频BV1th411z7snSTM32入门教程-2023版 细致讲解 中文字幕,课程资…...

QT实现自定义带有提示信息的透明环形进度条
1. 概述 做界面开发的童鞋可能都会遇到这样的需求,就是有一些界面点击了之后比较耗时的操作,需要界面给出一个环形进度条的进度反馈信息. 如何来实现这样的需求呢,话不多说,上效果 透明进度条 2. 代码实现 waitfeedbackprogressba…...

金币程序题
昨天,小孩问了我一个python编程竞赛题,我看了一下题目,是一个数列编程的问题,我在想,小学五年级的学生能搞得懂吗?反正我家小孩是没有搞懂,不知道别人家的小孩能不能搞明白。所以我花了一点时间…...
《Windows API每日一练》9.13资源-鼠标位图和字符串
鼠标指针位图(Mouse Cursor Bitmap)是用于表示鼠标指针外观的图像。在 Windows 窗口编程中,可以使用自定义的鼠标指针位图来改变鼠标的外观,并提供更加个性化的用户体验。 ■以下是一些与鼠标指针位图相关的要点: ●…...

Flask RESTful 示例
目录 1. 环境准备2. 安装依赖3. 修改main.py4. 运行应用5. API使用示例获取所有任务获取单个任务创建新任务更新任务删除任务 中文乱码问题: 下面创建一个简单的Flask RESTful API示例。首先,我们需要创建环境,安装必要的依赖,然后…...

调用支付宝接口响应40004 SYSTEM_ERROR问题排查
在对接支付宝API的时候,遇到了一些问题,记录一下排查过程。 Body:{"datadigital_fincloud_generalsaas_face_certify_initialize_response":{"msg":"Business Failed","code":"40004","sub_msg…...

相机Camera日志实例分析之二:相机Camx【专业模式开启直方图拍照】单帧流程日志详解
【关注我,后续持续新增专题博文,谢谢!!!】 上一篇我们讲了: 这一篇我们开始讲: 目录 一、场景操作步骤 二、日志基础关键字分级如下 三、场景日志如下: 一、场景操作步骤 操作步…...

[ICLR 2022]How Much Can CLIP Benefit Vision-and-Language Tasks?
论文网址:pdf 英文是纯手打的!论文原文的summarizing and paraphrasing。可能会出现难以避免的拼写错误和语法错误,若有发现欢迎评论指正!文章偏向于笔记,谨慎食用 目录 1. 心得 2. 论文逐段精读 2.1. Abstract 2…...

ServerTrust 并非唯一
NSURLAuthenticationMethodServerTrust 只是 authenticationMethod 的冰山一角 要理解 NSURLAuthenticationMethodServerTrust, 首先要明白它只是 authenticationMethod 的选项之一, 并非唯一 1 先厘清概念 点说明authenticationMethodURLAuthenticationChallenge.protectionS…...

Springcloud:Eureka 高可用集群搭建实战(服务注册与发现的底层原理与避坑指南)
引言:为什么 Eureka 依然是存量系统的核心? 尽管 Nacos 等新注册中心崛起,但金融、电力等保守行业仍有大量系统运行在 Eureka 上。理解其高可用设计与自我保护机制,是保障分布式系统稳定的必修课。本文将手把手带你搭建生产级 Eur…...

【Zephyr 系列 10】实战项目:打造一个蓝牙传感器终端 + 网关系统(完整架构与全栈实现)
🧠关键词:Zephyr、BLE、终端、网关、广播、连接、传感器、数据采集、低功耗、系统集成 📌目标读者:希望基于 Zephyr 构建 BLE 系统架构、实现终端与网关协作、具备产品交付能力的开发者 📊篇幅字数:约 5200 字 ✨ 项目总览 在物联网实际项目中,**“终端 + 网关”**是…...

《基于Apache Flink的流处理》笔记
思维导图 1-3 章 4-7章 8-11 章 参考资料 源码: https://github.com/streaming-with-flink 博客 https://flink.apache.org/bloghttps://www.ververica.com/blog 聚会及会议 https://flink-forward.orghttps://www.meetup.com/topics/apache-flink https://n…...

前端开发面试题总结-JavaScript篇(一)
文章目录 JavaScript高频问答一、作用域与闭包1.什么是闭包(Closure)?闭包有什么应用场景和潜在问题?2.解释 JavaScript 的作用域链(Scope Chain) 二、原型与继承3.原型链是什么?如何实现继承&a…...

NLP学习路线图(二十三):长短期记忆网络(LSTM)
在自然语言处理(NLP)领域,我们时刻面临着处理序列数据的核心挑战。无论是理解句子的结构、分析文本的情感,还是实现语言的翻译,都需要模型能够捕捉词语之间依时序产生的复杂依赖关系。传统的神经网络结构在处理这种序列依赖时显得力不从心,而循环神经网络(RNN) 曾被视为…...