PDF公式转Latex
文章目录
- 摘要
- 数据集 UniMER
- 介绍
- 下载链接
- LaTeX-OCR
- UniMERNet
- 安装
- UniMER 用的数据集
- 介绍
- 下载链接
- PDF-Extract-Kit
- 整体介绍
- 效果展示
- 评测指标
- 布局检测
- 公式检测
- 公式识别
- 使用教程
- 环境安装
- 参考[模型下载](models/README.md)下载所需模型权重
- 在Windows上运行
- 在macOS上运行
- 运行提取脚本
摘要
记录一下,找到两个PDF公式转Latex的开源项目和一个数据集
数据集 UniMER
介绍
UniMER数据集是一个专为推动数学表达式识别(MER)领域进步而精心策划的专业集合。它包括全面的UniMER-1M训练集,该训练集包含超过一百万个实例,代表了一系列多样且复杂的数学表达式,以及精心设计的UniMER测试集,用于在现实世界场景下对MER模型进行基准测试。数据集的详细信息如下:
UniMER-1M训练集:
- 总样本数:1,061,791个LaTeX-图像对
- 组成:简洁与复杂、扩展公式表达式的均衡混合
- 目标:训练出稳健、高精度的MER模型,提高识别精度和泛化能力
UniMER测试集:
- 总样本数:23,757个,分为四种类型的表达式:
- 简单打印表达式(SPE):6,762个样本
- 复杂打印表达式(CPE):5,921个样本
- 屏幕截图表达式(SCE):4,742个样本
- 手写表达式(HWE):6,332个样本
- 目的:在各种现实世界条件下对MER模型进行全面评估
下载链接
您可以从OpenDataLab(推荐中国用户使用)或HuggingFace下载该数据集。
找到一个非常不错的公式转化开源项目。将论文中的公式转为Latex。
LaTeX-OCR
github链接:
https://github.com/lukas-blecher/LaTeX-OCR
包含训练测试等,
安装简单非常,
安装 pix2tex:
pip install "pix2tex[gui]"
然后,下载权重到安装位置。

权重链接:
https://github.com/lukas-blecher/LaTeX-OCR/releases

注意:Weight release,别选错了。
然后,运行命令:
latexocr
就可以运行了。
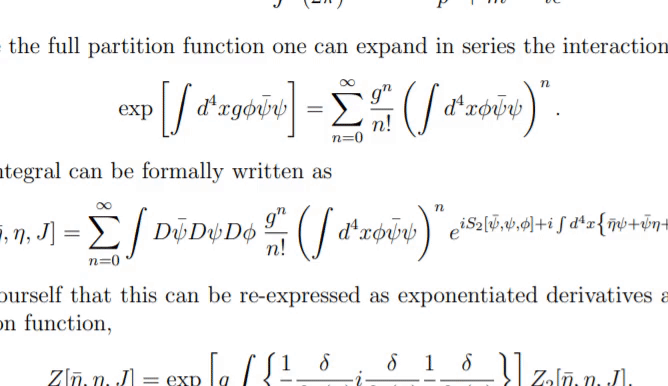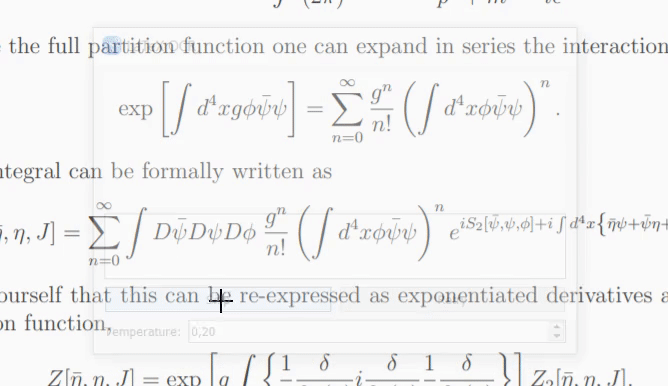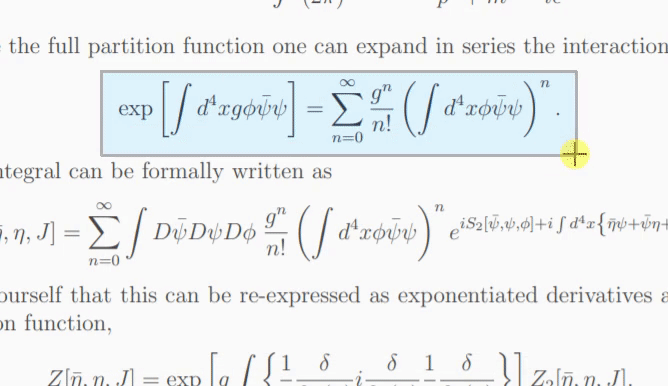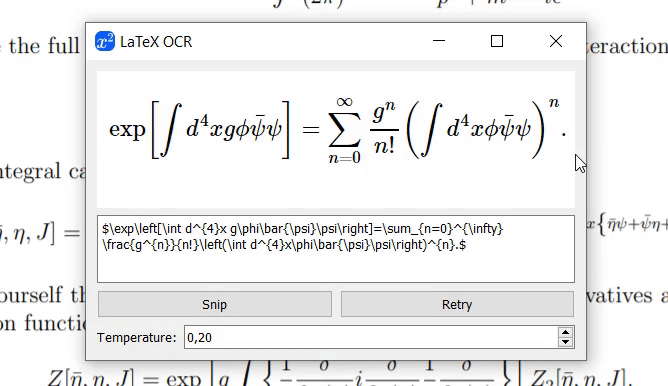
UniMERNet
github链接:
https://github.com/opendatalab/UniMERNet。
没有训练,只有测试。
安装
建议创建虚拟环境,我在base环境上安装没有成功,安装了python3.10的虚拟环境后才没有问题。
conda create -n unimernet python=3.10conda activate unimernetpip install --upgrade unimernet
下载项目和模型命令如下:
git clone https://github.com/opendatalab/UniMERNet.git
cd UniMERNet/models
# Download the model and tokenizer individually or use git-lfs
git lfs install
git clone https://huggingface.co/wanderkid/unimernet
如果没有git,也可以手动去huggingface上下载模型,将模型下载到本地的models下,路径要正确!

运行demo.py,
python demo.py
运行UI界面,执行命令
bash unimernet_gui
UniMERNet
UniMER 用的数据集
介绍
UniMER数据集是一个专为推动数学表达式识别(MER)领域进步而精心策划的专业集合。它包括全面的UniMER-1M训练集,该训练集包含超过一百万个实例,代表了一系列多样且复杂的数学表达式,以及精心设计的UniMER测试集,用于在现实世界场景下对MER模型进行基准测试。数据集的详细信息如下:
UniMER-1M训练集:
- 总样本数:1,061,791个LaTeX-图像对
- 组成:简洁与复杂、扩展公式表达式的均衡混合
- 目标:训练出稳健、高精度的MER模型,提高识别精度和泛化能力
UniMER测试集:
- 总样本数:23,757个,分为四种类型的表达式:
- 简单打印表达式(SPE):6,762个样本
- 复杂打印表达式(CPE):5,921个样本
- 屏幕截图表达式(SCE):4,742个样本
- 手写表达式(HWE):6,332个样本
- 目的:在各种现实世界条件下对MER模型进行全面评估
下载链接
您可以从OpenDataLab(推荐中国用户使用)或HuggingFace下载该数据集。
PDF-Extract-Kit
这个还没有调通。
github链接:
https://github.com/opendatalab/PDF-Extract-Kit
一个完整的工作流,支持PDF的分析,将PDF的论文内容识别出来。
整体介绍
PDF文档中包含大量知识信息,然而提取高质量的PDF内容并非易事。为此,我们将PDF内容提取工作进行拆解:
- 布局检测:使用LayoutLMv3模型进行区域检测,如
图像,表格,标题,文本等; - 公式检测:使用YOLOv8进行公式检测,包含
行内公式和行间公式; - 公式识别:使用UniMERNet进行公式识别;
- 光学字符识别:使用PaddleOCR进行文本识别;
注意: 由于文档类型的多样性,现有开源的布局检测和公式检测很难处理多样性的PDF文档,为此我们内容采集多样性数据进行标注和训练,使得在各类文档上取得精准的检测效果,细节参考布局检测和公式检测部分。对于公式识别,UniMERNet方法可以媲美商业软件,在各种类型公式识别上均匀很高的质量。对于OCR,我们采用PaddleOCR,对中英文OCR效果不错。
PDF内容提取框架如下图所示

{"layout_dets": [ # 页中的元素{"category_id": 0, # 类别编号, 0~9,13~15"poly": [136.0, # 坐标为图片坐标,需要转换回pdf坐标, 顺序是 左上-右上-右下-左下的x,y坐标781.0,340.0,781.0,340.0,806.0,136.0,806.0],"score": 0.69, # 置信度"latex": '' # 公式识别的结果,只有13,14有内容,其他为空,另外15是ocr的结果,这个key会换成text},...],"page_info": { # 页信息:提取bbox时的分辨率大小,如果有缩放可以基于该信息进行对齐"page_no": 0, # 页数"height": 1684, # 页高"width": 1200 # 页宽}
}
其中category_id包含的类型如下:
{0: 'title', # 标题1: 'plain text', # 文本2: 'abandon', # 包括页眉页脚页码和页面注释3: 'figure', # 图片4: 'figure_caption', # 图片描述5: 'table', # 表格6: 'table_caption', # 表格描述7: 'table_footnote', # 表格注释8: 'isolate_formula', # 行间公式(这个是layout的行间公式,优先级低于14)9: 'formula_caption', # 行间公式的标号13: 'inline_formula', # 行内公式14: 'isolated_formula', # 行间公式15: 'ocr_text'} # ocr识别结果
效果展示
结合多样性PDF文档标注,我们训练了鲁棒的布局检测和公式检测模型。在论文、教材、研报、财报等多样性的PDF文档上,我们的pipeline都能得到准确的提取结果,对于扫描模糊、水印等情况也有较高鲁棒性。

评测指标
现有开源模型多基于Arxiv论文类型数据进行训练,面对多样性的PDF文档,提前质量远不能达到实用需求。相比之下,我们的模型经过多样化数据训练,可以适应各种类型文档提取。
布局检测
我们与现有的开源Layout检测模型做了对比,包括DocXchain、Surya、360LayoutAnalysis的两个模型。而LayoutLMv3-SFT指的是我们在LayoutLMv3-base-chinese预训练权重的基础上进一步做了SFT训练后的模型。论文验证集由402张论文页面构成,教材验证集由587张不同来源的教材页面构成。
| 模型 | 论文验证集 | 教材验证集 | ||||
|---|---|---|---|---|---|---|
| mAP | AP50 | AR50 | mAP | AP50 | AR50 | |
| DocXchain | 52.8 | 69.5 | 77.3 | 34.9 | 50.1 | 63.5 |
| Surya | 24.2 | 39.4 | 66.1 | 13.9 | 23.3 | 49.9 |
| 360LayoutAnalysis-Paper | 37.7 | 53.6 | 59.8 | 20.7 | 31.3 | 43.6 |
| 360LayoutAnalysis-Report | 35.1 | 46.9 | 55.9 | 25.4 | 33.7 | 45.1 |
| LayoutLMv3-SFT | 77.6 | 93.3 | 95.5 | 67.9 | 82.7 | 87.9 |
公式检测
我们与开源的模型Pix2Text-MFD做了对比。另外,YOLOv8-Trained是我们在YOLOv8l模型的基础上训练后的权重。论文验证集由255张论文页面构成,多源验证集由789张不同来源的页面构成,包括教材、书籍等。
| 模型 | 论文验证集 | 多源验证集 | ||
|---|---|---|---|---|
| AP50 | AR50 | AP50 | AR50 | |
| Pix2Text-MFD | 60.1 | 64.6 | 58.9 | 62.8 |
| YOLOv8-Trained | 87.7 | 89.9 | 82.4 | 87.3 |
公式识别
公式识别我们使用的是Unimernet的权重,没有进一步的SFT训练,其精度验证结果可以在其GitHub页面获取。
使用教程
环境安装
conda create -n pipeline python=3.10pip install -r requirements.txtpip install --extra-index-url https://miropsota.github.io/torch_packages_builder detectron2==0.6+pt2.3.1cu121
安装完环境后,可能会遇到一些版本冲突导致版本变更,如果遇到了版本相关的报错,可以尝试下面的命令重新安装指定版本的库。
pip install pillow==8.4.0
除了版本冲突外,可能还会遇到torch无法调用的错误,可以先把下面的库卸载,然后重新安装cuda12和cudnn。
pip uninstall nvidia-cusparse-cu12
参考模型下载下载所需模型权重
在Windows上运行
如需要在Windows上运行本项目,请参考在Windows环境下使用PDF-Extract-Kit。
在macOS上运行
如需要在macOS上运行本项目,请参考在macOS系统使用PDF-Extract-Kit。
运行提取脚本
python pdf_extract.py --pdf data/pdfs/ocr_1.pdf
相关参数解释:
--pdf待处理的pdf文件,如果传入一个文件夹,则会处理文件夹下的所有pdf文件。--output处理结果保存的路径,默认是"output"--vis是否对结果可视化,是则会把检测的结果可视化出来,主要是检测框和类别--render是否把识别得的结果渲染出来,包括公式的latex代码,以及普通文本,都会渲染出来放在检测框中。注意:此过程非常耗时,另外也需要提前安装xelatex和imagemagic。
相关文章:
PDF公式转Latex
文章目录 摘要数据集 UniMER介绍下载链接 LaTeX-OCRUniMERNet安装UniMER 用的数据集介绍下载链接 PDF-Extract-Kit整体介绍效果展示评测指标布局检测公式检测公式识别 使用教程环境安装参考[模型下载](models/README.md)下载所需模型权重 在Windows上运行在macOS上运行运行提取…...

excel 百分位函数 学习
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、函数说明PERCENTILE 函数PERCENTILE.inc 函数PERCENTILE.exc 函数QUARTILE.EXC 函数 二、使用步骤总结 前言 excel 百分位函数 Excel提供了几个函数用于…...

(十一) Docker compose 部署 Mysql 和 其它容器
文章目录 1、前言1.1、部署 MySQL 容器的 3 种类型1.2、M2芯片类型问题 2、具体实现2.1、单独部署 mysql 供宿主机访问2.1.1、文件夹结构2.1.2、docker-compose.yml 内容2.1.3、运行 2.2、单独部署 mysql 容器供其它容器访问(以 apollo 为例)2.2.1、文件…...
提高项目透明度:有效的跟踪软件
国内外主流的10款项目进度跟踪软件对比:PingCode、Worktile、Teambition、Tower、Asana、Trello、Jira、ClickUp、Notion、Liquid Planner。 在项目管理中,确保进度跟踪的准确性与效率是每位项目经理面临的主要挑战之一。选用合适的项目进度跟踪软件不仅…...

大模型生成人物关系思维导图的实战教程
大家好,我是herosunly。985院校硕士毕业,现担任算法研究员一职,热衷于机器学习算法研究与应用。曾获得阿里云天池比赛第一名,CCF比赛第二名,科大讯飞比赛第三名。拥有多项发明专利。对机器学习和深度学习拥有自己独到的见解。曾经辅导过若干个非计算机专业的学生进入到算法…...

精通 mysqldumpslow:深度分析 MySQL 慢查询日志
引言 在数据库管理与优化的领域中,慢查询日志是识别性能瓶颈的金矿。mysqldumpslow 工具是挖掘这座金矿的利器,它帮助我们分析 MySQL 慢查询日志并提取关键信息。本文将详细介绍 mysqldumpslow 的核心选项,并通过实例展示如何使用这些选项来…...

C# Winform之propertyGrid控件分组后排序功能
在 WinForms 的 PropertyGrid 控件中,你可以通过多种方式对属性进行排序,包括按类别(Category)排序以及按属性名称排序。默认情况下,PropertyGrid 控件会根据 [Category] 和 [DisplayName] 属性装饰器对属性进行分组和…...
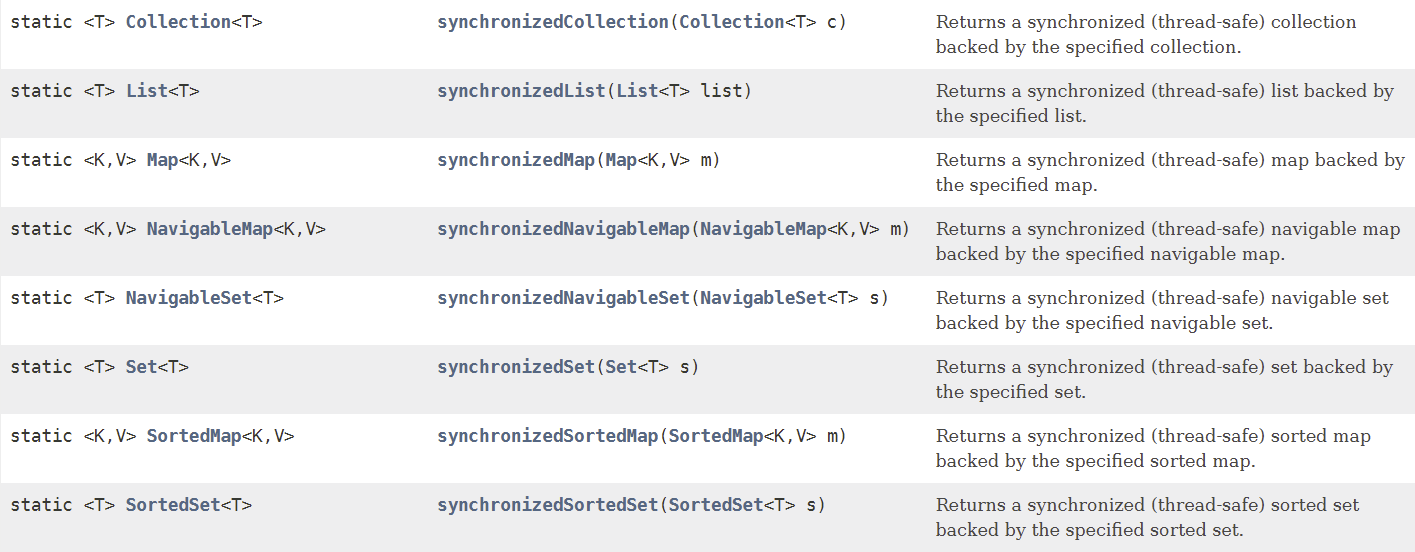
Java基础(十九):集合框架
目录 一、Java集合框架体系二、Collection接口及方法1、添加2、判断3、删除4、其它 三、Iterator(迭代器)接口1、Iterator接口2、迭代器的执行原理3、foreach循环 四、Collection子接口1:List1、List接口特点2、List接口方法3、List接口主要实现类:Array…...

execute_script与JS
JavaScript简称JS,有的测试场景需要JS脚本辅助完成Selenium无法做到的测试工作。webdriver提供了execute_script()方法调用JS代码。execute_script()可以在当前窗口/框架中执行JS脚本,并返回结果。可以使用它操作DOM元素、获取元素属性、执行异步操作等。…...

访问 Postman OAuth 2.0 授权的最佳实践
OAuth 2.0 代表了 web 安全协议的发展,便于在多个平台上进行授权服务,同时避免暴露用户凭据。它提供了一种安全的方式,让用户可以授权应用程序访问服务。 在 Postman 中开始使用 OAuth 2.0 Postman 是一个流行的API客户端,支持 …...

《BASeg: Boundary aware semantic segmentation for autonomous driving》论文解读
期刊:Neural Networks | Journal | ScienceDirect.com by Elsevier 年份:2023 代码:https://github.com/Lature-Yang/BASeg 摘要 语义分割是自动驾驶领域街道理解任务的重要组成部分。现有的各种方法要么专注于通过聚合全局或多尺度上下文…...

高效利用iCloud指南
高效利用iCloud的指南主要包括以下几个方面: 一、注册与登录 创建Apple ID: 如果尚未拥有Apple ID,可以在苹果官网或iOS设备的设置中创建。Apple ID是访问iCloud服务的前提。登录iCloud: 在苹果设备上,进入“设置”应…...

【MySQL】常见的MySQL日志都有什么用?
MySQL日志的内容非常重要,面试中经常会被问到。同时,掌握日志相关的知识也有利于我们理解MySQL 底层原理,必要时帮助我们排查解决问题。 MySQL中常见的日志类型主要有下面几类(针对的是InnoDB 存储引擎): 错误日志(error log):对 MySQL 的启…...

IDEA社区版使用Maven archetype 创建Spring boot 项目
1.新建new project 2.选择Maven Archetype 3.命名name 4.选择存储地址 5.选择jdk版本 6.Archetype使用webapp 7.create创建项目 创建好长这样。 检查一下自己的Maven是否是自己的。 没问题的话就开始增添java包。 [有的人连resources包也没有,那就需要自己添…...
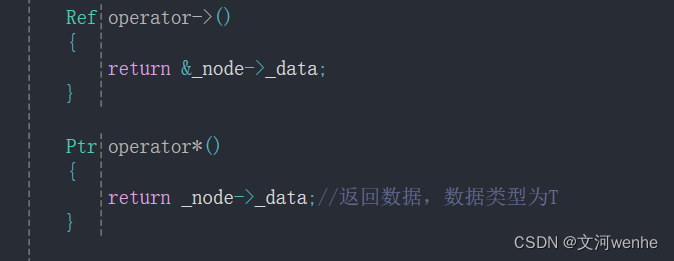
C/C++ list模拟
模拟准备 避免和库冲突,自己定义一个命名空间 namespace yx {template<class T>struct ListNode{ListNode<T>* _next;ListNode<T>* _prev;T _data;};template<class T>class list{typedef ListNode<T> Node;public:private:Node* _…...

android studio开发
Kotlin 编程简介 | Android Basics Compose - First Android app | Android Developers (google.cn) 这是官网的教程,实现试一下。 之后进入课程 您的第一个 Kotlin 程序 (google.cn) 程序可以被视为一系列指示计算机或设备执行某项操作的指令,...

PostgreSQl 物化视图
物化视图(Materialized View)是 PostgreSQL 提供的一个扩展功能,它是介于视图和表之间的一种对象。 物化视图和视图的最大区别是它不仅存储定义中的查询语句,而且可以像表一样存储数据。物化视图和表的最大区别是它不支持 INSERT…...

Win10工具:批量word转png图片
首先声明这个小工具是小编本人开发的,无任何广告,会员收费机制等,永久使用。允许公司或个人使用,不允许倒卖,否则发现后会追究法律责任,毕竟开发不易。工具是用python开发的。 功能非常单一,就…...

期货量化交易客户端开源教学第八节——TCP通信服务类
private FReciveStr: AnsiString; {接收到的数据} IsConErr: Boolean; {网络连接是否失败} FSocket_LB: Integer; {TCP连接类别,0为交易,1为行情,2为查询} FRetryCount: Integer; {网络连接重试次数} FLoginErrEvent: TLoginErrEvent; {…...

bi项目笔记
1.bi是什么 bi项目就是商业智能系统,也就是数据可视画、报表可视化系统,如下图的就是bi项目了 2.技术栈...

web vue 项目 Docker化部署
Web 项目 Docker 化部署详细教程 目录 Web 项目 Docker 化部署概述Dockerfile 详解 构建阶段生产阶段 构建和运行 Docker 镜像 1. Web 项目 Docker 化部署概述 Docker 化部署的主要步骤分为以下几个阶段: 构建阶段(Build Stage):…...

使用VSCode开发Django指南
使用VSCode开发Django指南 一、概述 Django 是一个高级 Python 框架,专为快速、安全和可扩展的 Web 开发而设计。Django 包含对 URL 路由、页面模板和数据处理的丰富支持。 本文将创建一个简单的 Django 应用,其中包含三个使用通用基本模板的页面。在此…...

CVPR 2025 MIMO: 支持视觉指代和像素grounding 的医学视觉语言模型
CVPR 2025 | MIMO:支持视觉指代和像素对齐的医学视觉语言模型 论文信息 标题:MIMO: A medical vision language model with visual referring multimodal input and pixel grounding multimodal output作者:Yanyuan Chen, Dexuan Xu, Yu Hu…...

iPhone密码忘记了办?iPhoneUnlocker,iPhone解锁工具Aiseesoft iPhone Unlocker 高级注册版分享
平时用 iPhone 的时候,难免会碰到解锁的麻烦事。比如密码忘了、人脸识别 / 指纹识别突然不灵,或者买了二手 iPhone 却被原来的 iCloud 账号锁住,这时候就需要靠谱的解锁工具来帮忙了。Aiseesoft iPhone Unlocker 就是专门解决这些问题的软件&…...

《通信之道——从微积分到 5G》读书总结
第1章 绪 论 1.1 这是一本什么样的书 通信技术,说到底就是数学。 那些最基础、最本质的部分。 1.2 什么是通信 通信 发送方 接收方 承载信息的信号 解调出其中承载的信息 信息在发送方那里被加工成信号(调制) 把信息从信号中抽取出来&am…...

Mysql中select查询语句的执行过程
目录 1、介绍 1.1、组件介绍 1.2、Sql执行顺序 2、执行流程 2.1. 连接与认证 2.2. 查询缓存 2.3. 语法解析(Parser) 2.4、执行sql 1. 预处理(Preprocessor) 2. 查询优化器(Optimizer) 3. 执行器…...

基于SpringBoot在线拍卖系统的设计和实现
摘 要 随着社会的发展,社会的各行各业都在利用信息化时代的优势。计算机的优势和普及使得各种信息系统的开发成为必需。 在线拍卖系统,主要的模块包括管理员;首页、个人中心、用户管理、商品类型管理、拍卖商品管理、历史竞拍管理、竞拍订单…...

FFmpeg:Windows系统小白安装及其使用
一、安装 1.访问官网 Download FFmpeg 2.点击版本目录 3.选择版本点击安装 注意这里选择的是【release buids】,注意左上角标题 例如我安装在目录 F:\FFmpeg 4.解压 5.添加环境变量 把你解压后的bin目录(即exe所在文件夹)加入系统变量…...

2025年- H71-Lc179--39.组合总和(回溯,组合)--Java版
1.题目描述 2.思路 当前的元素可以重复使用。 (1)确定回溯算法函数的参数和返回值(一般是void类型) (2)因为是用递归实现的,所以我们要确定终止条件 (3)单层搜索逻辑 二…...

起重机起升机构的安全装置有哪些?
起重机起升机构的安全装置是保障吊装作业安全的关键部件,主要用于防止超载、失控、断绳等危险情况。以下是常见的安全装置及其功能和原理: 一、超载保护装置(核心安全装置) 1. 起重量限制器 功能:实时监测起升载荷&a…...