Hive第三天
1. 后台启动HIVE的JDBC连接
0 表示标准输入
1 表示标准输出
2 表示标准错误输出
nohup 表示挂起
最后的 & 表示 后台启动
nohup hive -service hiveserver2 > /usr/local/soft/hive-3.1.2/log/hiveserver2.log 2>&1 &
jps 查看 Runjob
关闭后台的JDBC : kill -9 关闭 RunJob对应的PID
1.HIVE WORDCOUNT
CREATE TABLE learn3.wordcount(
word STRING COMMENT "单词"
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS TEXTFILE;
INSERT INTO TABLE learn3.wordcount (word) VALUES ("hello,word"),("hello,java"),("hive,hello");
-- 统计WORDCOUNT
SELECT
T1.col
, sum(num)
FROM (
SELECT
col2 as col,
count(*) as num
FROM (
SELECT
split(word,",")[0] as col1,
split(word,",")[1] as col2
FROM learn3.wordcount
)T GROUP BY T.col2
UNION ALL
SELECT
col1 as col,
count(*) as num
FROM (
SELECT
split(word,",")[0] as col1,
split(word,",")[1] as col2
FROM learn3.wordcount
)T GROUP BY T.col1
)T1 GROUP BY T1.col
2. WITH AS 用法
格式:
WITH table1 AS (
SELECT 查询语句1
)
, table2 AS (
SELECT 查询语句2
)
[INSERT INTO TABLE] SELECT FROM
--WORDCOUNT的 WITH AS 用法
WITH split_res AS (
SELECT
split(word,",")[0] as col1,
split(word,",")[1] as col2
FROM learn3.wordcount
)
, col1_count AS(
SELECT
col1 as col
,count(*) as num
FROM split_res
GROUP BY col1
)
, col2_count AS(
SELECT
col2 as col
,count(*) as num
FROM split_res
GROUP BY col2
)
SELECT
T.col,
sum(T.num)
FROM (
SELECT * FROM col1_count
UNION ALL
SELECT * FROM col2_count
)T GROUP BY T.col
3. 集合函数
COLLECT_LIST(column2)
需要跟 GROUP BY column1 配合使用,将column1中相同的组column2数据放至一个集合中
COLLECT_SET()
需要跟GROUP BY column1 配合使用,将column1中相同的组column2数据放至一个集合中,并对集合中的数据进行去重操作
--需求:
将一列中相同的内容放至一组数据中
将 word列中所有相同的单词对应的num 放至一个数组中
CREATE TABLE learn1.wordcount2(
word STRING COMMENT "单词",
num int COMMENT "数量"
)
STORED AS TEXTFILE;
INSERT INTO TABLE learn1.wordcount2 (word,num) VALUES ("hello",1),("hello",2),("hive",3);
SELECT
word
,COLLECT_LIST(num)
FROM learn3.wordcount2
GROUP BY word
+--------+------------+
| word | _c1 |
+--------+------------+
| hello | [1,2,1,2] |
| hive | [3,3] |
SELECT
word
,COLLECT_SET(num)
FROM learn3.wordcount2
GROUP BY word
| hello | [1,2] |
| hive | [3] |
CREATE EXTERNAL TABLE IF NOT EXISTS learn3.student20(
id STRING COMMENT "学生ID",
name STRING COMMENT "学生姓名",
age int COMMENT "年龄",
gender STRING COMMENT "性别",
subject STRING COMMENT "学科"
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ","
STORED AS TEXTFILE;
load data local inpath "/usr/local/soft/hive-3.1.2/data/student_20.txt" INTO TABLE learn3.student20;
理科|男 1500100020|杭振凯,1500100019|娄曦之
① 将两列数据进行拼接
WITH concat_stu AS(
SELECT
CONCAT(subject,"|",gender) as subject_gender
,CONCAT_WS("|",id,name) as id_name
FROM learn3.student20
)
SELECT
subject_gender
,CONCAT_WS(",",COLLECT_LIST(id_name))
FROM concat_stu
GROUP BY subject_gender
| 文科|女 | ["1500100001|施笑槐","1500100007|尚孤风","1500100016|潘访烟","1500100018|骆怜雪"] |
| 文科|男 | ["1500100002|吕金鹏","1500100013|逯君昊"] |
| 理科|女 | ["1500100003|单乐蕊","1500100005|宣谷芹","1500100008|符半双","1500100012|梁易槐","1500100015|宦怀绿","1500100017|高芷天"] |
| 理科|男 | ["1500100004|葛德曜","1500100006|边昂雄","1500100009|沈德昌","1500100010|羿彦昌","1500100011|宰运华","1500100014|羿旭炎","1500100019|娄曦之","1500100020|杭振凯"] |
| concat_ws(separator, [string | array(string)]+) - returns the concatenation of the strings separated by the separator. |
4.行列互换
+-----------------+-----------------+
| subject_gender | id_name |
+-----------------+-----------------+
| 文科|女 | 1500100001|施笑槐 |
| 文科|男 | 1500100002|吕金鹏 |
| 理科|女 | 1500100003|单乐蕊 |
| 理科|男 | 1500100004|葛德曜 |
| 理科|女 | 1500100005|宣谷芹 |
| 理科|男 | 1500100006|边昂雄 |
| 文科|女 | 1500100007|尚孤风 |
| 理科|女 | 1500100008|符半双 |
| 理科|男 | 1500100009|沈德昌 |
| 理科|男 | 1500100010|羿彦昌 |
| 理科|男 | 1500100011|宰运华 |
| 理科|女 | 1500100012|梁易槐 |
| 文科|男 | 1500100013|逯君昊 |
| 理科|男 | 1500100014|羿旭炎 |
| 理科|女 | 1500100015|宦怀绿 |
| 文科|女 | 1500100016|潘访烟 |
| 理科|女 | 1500100017|高芷天 |
| 文科|女 | 1500100018|骆怜雪 |
| 理科|男 | 1500100019|娄曦之 |
| 理科|男 | 1500100020|杭振凯 |
| 文科|女 | 1500100001|施笑槐,1500100007|尚孤风,1500100016|潘访烟,1500100018|骆怜雪 |
| 文科|男 | 1500100002|吕金鹏,1500100013|逯君昊 |
| 理科|女 | 1500100003|单乐蕊,1500100005|宣谷芹,1500100008|符半双,1500100012|梁易槐,1500100015|宦怀绿,1500100017|高芷天 |
| 理科|男 | 1500100004|葛德曜,1500100006|边昂雄,1500100009|沈德昌,1500100010|羿彦昌,1500100011|宰运华,1500100014|羿旭炎,1500100019|娄曦之,1500100020|杭振凯 |
行转列:
将原先多行数据转成一行
转换方式:
通过COLLECT_SET() 或者 COLLECT_LIST() 和 GROUP BY 进行配合使用
将GROUP BY 分组的数据进行存放于一个集合当中
列传行:
将一行数据转换为多行数据
转换:
案例:
| wordcount.word |
+-----------------+
| hello,word,hive |
| hello,java |
| hello,hive |
| hello,word |
| hello,java |
| hive,hello |
结果:
+----------+
| _u1.col |
+----------+
| hello |
| hive |
| java |
| word |
| hello |
| hive |
+----------+
INSERT INTO TABLE learn3.wordcount (word) VALUES ("hello,word,hello,java,hello,spark");
EXPLODE() 函数
将集合中的一行数据转换为多行
SELECT
EXPLODE(split(word,",")) as word
FROM learn3.wordcount
CREATE TABLE learn3.movie(
movie_name STRING COMMENT "电影名",
types STRING COMMENT "电影类型"
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
STORED AS TEXTFILE;
load data local inpath "/usr/local/soft/hive-3.1.2/data/moive.txt" INTO TABLE learn3.movie;
-- 将types列中的电影类型进行分隔,并且与电影名进行对应
由 |肖申克的救赎 | 犯罪/剧情 |
转换为:
肖申克的救赎 犯罪
肖申克的救赎 剧情
SELECT
movie_name,EXPLODE(split(types,"/")) as type
FROM learn3.movie
SELECT
movie_name,type
FROM learn3.movie LATERAL VIEW EXPLODE(split(types,"/")) view as type
| movie.movie_name | movie.types |
+-------------------+--------------+
| 肖申克的救赎 | 犯罪/剧情 |
| 霸王别姬 | 剧情/爱情/同性 |
| 阿甘正传 | 剧情/爱情 |
| 泰坦尼克号 | 剧情/爱情/灾难 |
| 这个杀手不太冷 | 剧情/动作/犯罪 |
| movie_name | type |
+-------------+-------+
| 肖申克的救赎 | 犯罪 |
| 肖申克的救赎 | 剧情 |
| 霸王别姬 | 剧情 |
| 霸王别姬 | 爱情 |
| 霸王别姬 | 同性 |
| 阿甘正传 | 剧情 |
| 阿甘正传 | 爱情 |
| 泰坦尼克号 | 剧情 |
| 泰坦尼克号 | 爱情 |
| 泰坦尼克号 | 灾难 |
| 这个杀手不太冷 | 剧情 |
| 这个杀手不太冷 | 动作 |
| 这个杀手不太冷 | 犯罪 |
LATERAL VIEW EXPLODE(split(types,"/")) view as type
解析:
① 通过split方法将types中的字符串切分为数组
② 通过EXPLODE方法将数组由一行数据转换为多行
③ 通过LATERAL VIEW 将EXPLODE转换的结果包装成一个名为view的一个侧写表,并且列名为type
④ 通过全连接将侧写表中的数据与原表 learn3.movie 中的一行数据进行全连接
5.
CREATE EXTERNAL TABLE IF NOT EXISTS learn3.student1(
id STRING COMMENT "学生ID",
name STRING COMMENT "学生姓名",
age int COMMENT "年龄",
gender STRING COMMENT "性别",
clazz STRING COMMENT "班级"
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ",";
load data local inpath "/usr/local/soft/hive-3.1.2/data/students.txt" INTO TABLE learn3.student1;
CREATE EXTERNAL TABLE IF NOT EXISTS learn3.score1(
id STRING COMMENT "学生ID",
subject_id STRING COMMENT "科目ID",
score int COMMENT "成绩"
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ","
load data local inpath "/usr/local/soft/hive-3.1.2/data/score.txt" INTO TABLE learn3.score1;
需求:
1.统计各性别年龄前三
-- HIVE 原先老版本 不支持这种写法
SELECT
s1.*
FROM learn3.student1 as s1
WHERE 3 > (SELECT count(*) FROM learn3.student1 as s2
WHERE s1.gender = s2.gender and s1.age < s2.age
)
2.统计各班级学生总成绩前三名
①算出学生总成绩
WITH score_sum AS (
SELECT
id
,sum(score) as total_score
FROM learn3.score1
GROUP BY id
)
, studen_score AS (
SELECT
T1.name
,T2.total_score
,T1.clazz
FROM learn3.student1 T1
JOIN score_sum T2 ON T1.id = T2.id
)
--② 排序获取前三名
SELECT
TT.*
FROM (
SELECT
T.name
,T.total_score
,T.clazz
, ROW_NUMBER() OVER(PARTITION BY T.clazz ORDER BY T.total_score DESC) as row_pm
FROM studen_score T
) TT
WHERE TT.row_pm <= 3
SELECT
T.name
,T.total_score
,T.clazz
, ROW_NUMBER() OVER(PARTITION BY T.clazz ORDER BY T.total_score DESC) as row_pm
, dense_rank() OVER(PARTITION BY T.clazz ORDER BY T.total_score DESC) as dense_pm
, rank() OVER(PARTITION BY T.clazz ORDER BY T.total_score DESC) as rank_pm
, percent_rank() OVER(PARTITION BY T.clazz ORDER BY T.total_score DESC) as percent_rank_pm
, cume_dist() OVER(PARTITION BY T.clazz ORDER BY T.total_score DESC) as cume_dist_pm
FROM studen_score T
##### row_number :无并列排名
* 用法: select xxxx, row_number() over(partition by 分组字段 order by 排序字段 desc) as rn from tb group by xxxx
##### dense_rank :有并列排名,并且依次递增
* 用法: select xxxx, dense_rank() over(partition by 分组字段 order by 排序字段 desc) as rn from tb group by xxxx
##### rank :有并列排名,不依次递增
* 用法: select xxxx, rank() over(partition by 分区字段 order by 排序字段 desc) as rn from tb group by xxxx
##### percent_rank:(rank的结果-1)/(分区内数据的个数-1)
* 用法: select xxxx, percent_rank() over(partition by 分组字段 order by 排序字段 desc) as rn from tb group by xxxx
需求1:
取每个班级总分最大的同学
CREATE TABLE learn3.student_score(
name STRING COMMENT "",
total_score int COMMENT "",
clazz STRING COMMENT ""
);
WITH score_sum AS (
SELECT
id
,sum(score) as total_score
FROM learn3.score1
GROUP BY id
)
INSERT INTO TABLE learn3.student_score
SELECT
T1.name
,T2.total_score
,T1.clazz
FROM learn3.student1 T1
JOIN score_sum T2 ON T1.id = T2.id
-- 通过max方法取出每个班级分区中的学生成绩最大值
SELECT
TT.*
FROM (
SELECT
T1.*
,max(T1.total_score) OVER(PARTITION BY T1.clazz ORDER BY T1.total_score DESC) as max_score
FROM learn3.student_score T1
) TT WHERE TT.total_score = TT.max_score
-- 如果max() OVER() 中的窗口over()没有给定分区,那么当前的窗口表示整个学校,得到的数据是整个学校的最高的分数
SELECT
TT.*
FROM (
SELECT
T1.*
,max(T1.total_score) OVER() as max_score
FROM learn3.student_score T1
) TT WHERE TT.total_score = TT.max_score
max
用法:
① max(T1.total_score) OVER(PARTITION BY T1.clazz ORDER BY T1.total_score DESC)
基于每个partition分区内数据取最大值
② max(T1.total_score) OVER()
基于整个数据集取最大值
min、avg、count、sum:与max方法使用一致
6. 《《《《 卡口流量需求分析 》》》》
CREATE TABLE learn3.veh_pass(
id STRING COMMENT "卡口编号",
pass_time STRING COMMENT "进过时间",
pass_num int COMMENT "过车数"
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ","
STORED AS TEXTFILE;
load data local inpath "/usr/local/soft/hive-3.1.2/data/veh_pass.txt" INTO TABLE learn3.veh_pass;
需求1:查询当月的设备及其总数
-- 写法1
SELECT
T.id
,count(*) OVER()
FROM (
SELECT
id
,pass_time
FROM learn3.veh_pass
WHERE substr(pass_time,1,7) = substr(current_date,1,7)
) T GROUP BY T.id
-- 错误写法
SELECT
DISTINCT id
,count(*) OVER()
FROM (
SELECT
id
,pass_time
FROM learn3.veh_pass
WHERE substr(pass_time,1,7) = substr(current_date,1,7)
)T
-- 写法2:
SELECT
T1.id
,count(*) OVER()
FROM (
SELECT
DISTINCT id
FROM (
SELECT
id
,pass_time
FROM learn3.veh_pass
WHERE substr(pass_time,1,7) = substr(current_date,1,7)
)T )T1
+---------------------+-----------------+
| t1.id | count_window_0 |
+---------------------+-----------------+
| 451000000000071117 | 5 |
| 451000000000071116 | 5 |
| 451000000000071115 | 5 |
| 451000000000071114 | 5 |
| 451000000000071113 | 5 |
+---------------------+-----------------+
+---------------------+
| id |
+---------------------+
| 451000000000071113 |
| 451000000000071114 |
| 451000000000071115 |
| 451000000000071116 |
| 451000000000071117 |
+---------------------+
-- 需求2:查询所有流量明细及所有设备月流量总额
SELECT
T1.id
,T1.pass_time
,T1.pass_num
,SUM(T1.pass_num) OVER(PARTITION BY SUBSTRING(T1.pass_time,1,7)) as total_pass
FROM learn3.veh_pass T1
需求3:按设备编号日期顺序展示明细 并求
1)从第一天开始到当前天数 对流量进行累加
2)昨天与当前天流量累加
3)当前天数的前一天与后一天流量累加
4)当前天与下一天的累加和
5)当前天数与之后所有天流量累加和
1)从第一天开始到当前天数 对流量进行累加
SELECT
T1.*
,SUM(T1.pass_num) OVER(ORDER BY T1.pass_time ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)
FROM (
SELECT
*
FROM learn3.veh_pass ORDER BY pass_time
) T1
2)昨天与当前天流量累加
SELECT
T1.*
,SUM(T1.pass_num) OVER(ORDER BY T1.pass_time ROWS BETWEEN 1 PRECEDING AND CURRENT ROW)
FROM (
SELECT
*
FROM learn3.veh_pass ORDER BY pass_time
) T1
3)当前天数的前一天与后一天流量累加
SELECT
T1.*
,SUM(T1.pass_num) OVER(ORDER BY T1.pass_time ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING)
FROM (
SELECT
*
FROM learn3.veh_pass ORDER BY pass_time
) T1
4)当前天与下一天的累加和
SELECT
T1.*
,SUM(T1.pass_num) OVER(ORDER BY T1.pass_time ROWS BETWEEN CURRENT ROW AND 1 FOLLOWING)
FROM (
SELECT
*
FROM learn3.veh_pass ORDER BY pass_time
) T1
5)当前天数与之后所有天流量累加和
SELECT
T1.*
,SUM(T1.pass_num) OVER(ORDER BY T1.pass_time ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING)
FROM (
SELECT
*
FROM learn3.veh_pass ORDER BY pass_time
) T1
需求4:查询每个设备编号上次有数据日期和下一次有数据日期
SELECT
T1.*
, LAG(T1.pass_time,1,"2022-01-01") OVER(PARTITION BY T1.id ORDER BY T1.pass_time) as before_time
, LEAD(T1.pass_time,1,"2022-12-31") OVER(PARTITION BY T1.id ORDER BY T1.pass_time) as after_time
FROM learn3.veh_pass T1
总结:
OVER(): 会为每条数据都开启一个窗口,默认窗口大小就是当前数据集的大小
OVER(PARTITION BY) 会按照指定的字段进行分区,在获取一条数据时,窗口大小为整个分区的大小,之后根据分区中的数据进行计算
OVER(PARTITION BY ... ORDER BY ...) 根据给定的分区,在获取一条数据时,窗口大小为整个分区的大小,并且对分区中的数据进行排序
OVER中的取数据格式
(ROWS | RANGE) BETWEEN (UNBOUNDED | [num]) PRECEDING AND ([num] PRECEDING | CURRENT ROW | (UNBOUNDED | [num]) FOLLOWING)
(ROWS | RANGE) BETWEEN CURRENT ROW AND (CURRENT ROW | (UNBOUNDED | [num]) FOLLOWING)
(ROWS | RANGE) BETWEEN [num] FOLLOWING AND (UNBOUNDED | [num]) FOLLOWING
OVER():指定分析函数工作的数据窗口大小,这个数据窗口大小可能会随着行的改变而变化。
CURRENT ROW:当前行
n PRECEDING:往前n行数据
n FOLLOWING:往后n行数据
UNBOUNDED :起点,
UNBOUNDED PRECEDING 表示从前面的起点,
UNBOUNDED FOLLOWING 表示到后面的终点
LAG(col,n,default_val):往前第n行数据
LEAD(col,n, default_val):往后第n行数据
NTILE(n):把有序窗口的行分发到指定数据的组中,各个组有编号,编号从1开始,对于每一行,NTILE返回此行所属的组的编号。
-- 自定义UDF函数
老版本UDF 不推荐使用:
① 创建自定义类继承UDF 注意 自定义函数名必须使用 evaluate 不然识别不到
public class MyUDFAddString extends UDF {
/**
* 定义函数名 evaluate
* 实现将传入的String 增加后缀 ###
*
* @param col HIVE中使用函数时传入的数据
* @return 一行数据
*/
public String evaluate(String col) {
return col + "###";
}
}
② 将代码打包,添加jar包至HIVE中
add jar /usr/local/soft/test/HiveCode15-1.0-SNAPSHOT.jar;
③ 创建临时自定义函数
CREATE TEMPORARY FUNCTION my_udf as "com.shujia.udf.MyUDFAddString";
my_udf(col)
相关文章:

Hive第三天
1. 后台启动HIVE的JDBC连接 0 表示标准输入 1 表示标准输出 2 表示标准错误输出 nohup 表示挂起 最后的 & 表示 后台启动 nohup hive -service hiveserver2 > /usr/local/soft/hive-3.1.2/log/hiveserver2.log 2>&1 & jps 查看 Runj…...

【C++】模版初阶以及STL的简介
个人主页~ 模版及STL 一、模版初阶1、泛型编程2、函数模版(1)概念(2)函数模版格式(3)函数模版的原理(4)函数模版的实例化①显式实例化②隐式实例化 (5)模版参…...

51单片机学习(4)
一、串口通信 1.串口通信介绍 写完串口函数时进行模块化编程,模块化编程之后要对其进行注释,以便之后使用模块化函数,对模块化.c文件中的每一个函数进行注释。 注意:一个函数不能既在主函数又在中断函数中 模式1最常用…...
3D问界—MAYA制作铁丝栅栏(透明贴图法)
当然,如果想通过建立模型法来实现铁丝栅栏的效果,也不是不行,可以找一下栅栏建模教程。本篇文章主要是记录一下如何使用透明贴图来实现创建铁丝栅栏,主要应用于场景建模,比如游戏场景、建筑场景等大环境,不…...
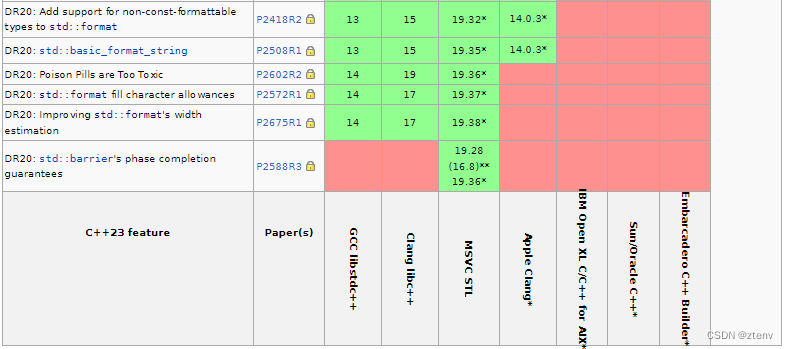
编译器对C++23的支持程度
详见这里...

k8s核心操作_存储抽象_K8S中使用Secret功能来存储密码_使用免密拉取镜像_k8s核心实战总结---分布式云原生部署架构搭建033
注意在看的时候一定要把 dxxxx中的xxxx换成--o----c----k----e----r 然后我们再来看一个k8s中的secret的功能,这个功能 用来存储密码的,configMap是用来存配置的 比如我们有个pod,他的镜像,如果是需要密码的,那么 我们现在是从公共仓库拉取的,如果我们从私有仓库拉取,有密码…...

21集 ESP32-IDF开发教程-《MCU嵌入式AI开发笔记》
21集 ESP32-IDF开发教程-《MCU嵌入式AI开发笔记》 之前我们用了windows系统搭建了ESP-IDF的开发环境, 我们还是参考这个官方文档https://docs.espressif.com/projects/esp-idf/zh_CN/release-v5.1/esp32s3/get-started/index.html 同时我们也参考之前讲到的&#…...

《大数据基础》相关知识点及考点,例题
1.6大数据计算模式 1、MapReduce可以并行执行大规模数据处理任务,用于大规模数据集(大于1TB)的并行运算。MapReduce 极大地方便了分布式编程工作,它将复杂的、运行于大规模集群上的并行计算过程高度地抽象为两个函数一一Map和Redu…...

网络通信介绍
一、 简介 网络通信,简而言之,就是通过各种物理链路和协议,实现不同地理位置的计算机或其他电子设备之间信息交换的过程。这些信息可以是文本、图像、音频、视频等多种格式,通过网络传输至目标设备,从而实现远程通信、…...

16、Python之容器:元组与列表、推导式与生成式,差之毫厘谬以千里
引言 从上一篇文章开始了对Python中容器的介绍,已经对列表的简单使用做了一些介绍,今天这篇文章,打算首先简单介绍一下元组,同时比较一下元组、列表的异同,然后就列表、元组的一些比较实用的用法,做一些补…...

HTTP协议——请求头和请求体详情
HTTP协议-请求头和请求体 请求头 请求头(Request Header)是在HTTP协议中用于描述一个HTTP请求的元数据。它是客户端发送给服务器的一部分请求信息,包含了客户端的相关配置和要求。 请求头通常包含以下几个部分: 1. 请求方法(Req…...

编程中的智慧之设计模式二
设计模式:深度解析与实战应用 在上一篇文章中,我们探讨了创建型模式、结构型模式和行为模式中的一些常用模式及其Java实现。本篇将继续深入探讨设计模式,重点介绍更多的行为模式以及架构模式在实际开发中的应用。 行为模式 责任链模式&…...

基于python的百度资讯爬虫的设计与实现
研究背景 随着互联网和信息技术的飞速发展,网络已经成为人们获取信息的主要来源之一。特别是搜索引擎,作为信息检索的核心工具,极大地改变了人们获取信息的方式。其中,百度作为中国最受欢迎的搜索引擎之一,其新闻搜索…...
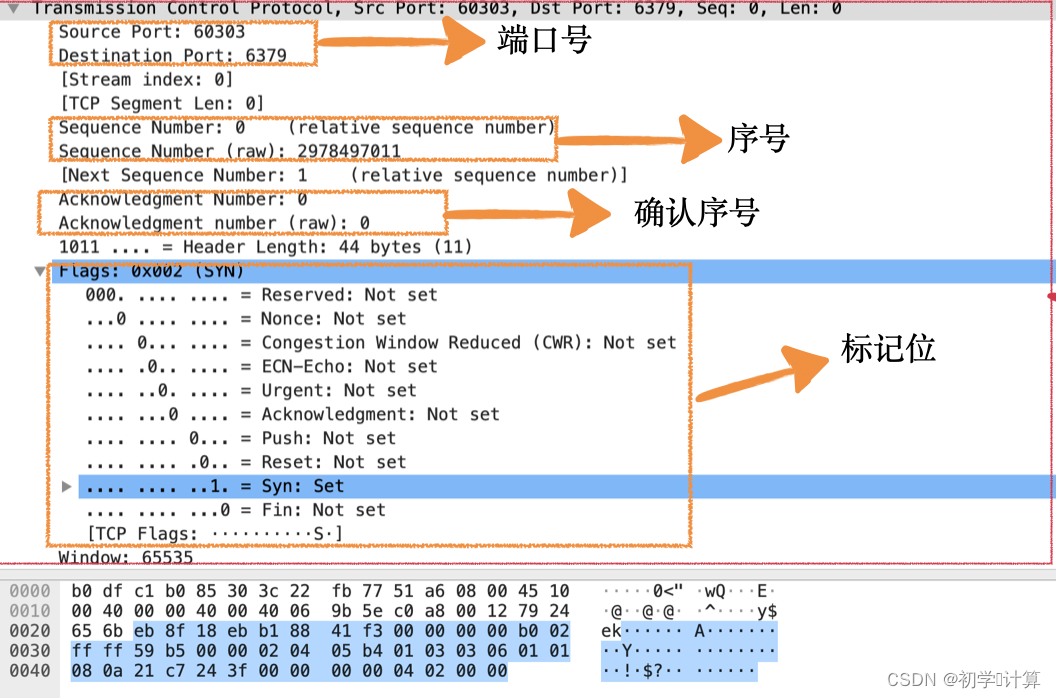
用 WireShark 抓住 TCP
Wireshark 是帮助我们分析网络请求的利器,建议每个同学都装一个。我们先用 Wireshark 抓取一个完整的连接建立、发送数据、断开连接的过程。 简单的介绍一下操作流程。 1、首先打开 Wireshark,在欢迎界面会列出当前机器上的所有网口、虚机网口等可以抓取…...
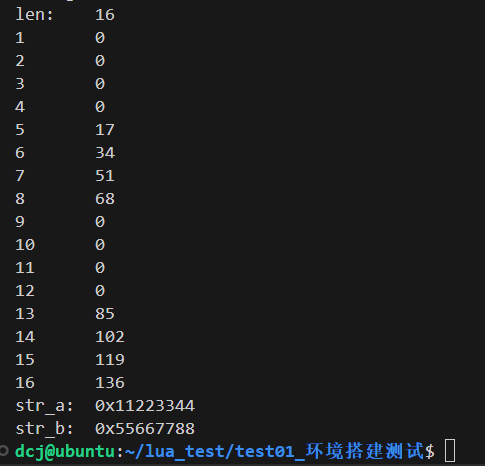
Lua基础知识入门
1 基础知识 标识符:标识符的定义和 C语言相同:字母和下划线_ 开头, 下划线_ 大写字母一般是lua保留字, 如_VERSION 全局变量:默认情况下,变量总是认为是全局的,不需要申明,给一个变…...

【机器学习实战】Datawhale夏令营2:深度学习回顾
#DataWhale夏令营 #ai夏令营 文章目录 1. 深度学习的定义1.1 深度学习&图神经网络1.2 机器学习和深度学习的关系 2. 深度学习的训练流程2.1 数学基础2.1.1 梯度下降法基本原理数学表达步骤学习率 α梯度下降的变体 2.1.2 神经网络与矩阵网络结构表示前向传播激活函数…...

开发扫地机器人系统时无法兼容手机解决方案
在开发扫地机器人系统时,遇到无法兼容手机的问题,可以从以下几个方面寻求解决方案: 一、了解兼容性问题根源 ① 操作系统差异:不同手机可能运行不同的操作系统(如iOS、Android),且即使是同一操…...

Elasticsearch 角色和权限管理
在大数据和云计算日益普及的今天,Elasticsearch 作为一款强大的开源搜索引擎和数据分析引擎,被广泛应用于日志分析、全文搜索、实时监控等领域。随着业务规模的扩大和数据敏感性的增加,对 Elasticsearch 的访问控制和权限管理也变得越来越重要…...

华为HCIP Datacom H12-821 卷42
42.填空题 如图所示,MSTP网络中SW1为总根,请将以下交换机与IST域根和主桥配对。 参考答案:主桥1468 既是IST域根又是主桥468 既不是又不是就是25 解析: 主桥1468 既是IST域根又是主桥468 既不是又不是就是25 43.填空题 网络有…...

【精品资料】物业行业BI大数据解决方案(43页PPT)
引言:物业行业BI(Business Intelligence,商业智能)大数据解决方案是专为物业管理公司设计的一套综合性数据分析与决策支持系统。该解决方案旨在通过集成、处理、分析及可视化海量数据,帮助物业企业提升运营效率、优化资…...

Linux应用开发之网络套接字编程(实例篇)
服务端与客户端单连接 服务端代码 #include <sys/socket.h> #include <sys/types.h> #include <netinet/in.h> #include <stdio.h> #include <stdlib.h> #include <string.h> #include <arpa/inet.h> #include <pthread.h> …...

谷歌浏览器插件
项目中有时候会用到插件 sync-cookie-extension1.0.0:开发环境同步测试 cookie 至 localhost,便于本地请求服务携带 cookie 参考地址:https://juejin.cn/post/7139354571712757767 里面有源码下载下来,加在到扩展即可使用FeHelp…...

UDP(Echoserver)
网络命令 Ping 命令 检测网络是否连通 使用方法: ping -c 次数 网址ping -c 3 www.baidu.comnetstat 命令 netstat 是一个用来查看网络状态的重要工具. 语法:netstat [选项] 功能:查看网络状态 常用选项: n 拒绝显示别名&#…...

BCS 2025|百度副总裁陈洋:智能体在安全领域的应用实践
6月5日,2025全球数字经济大会数字安全主论坛暨北京网络安全大会在国家会议中心隆重开幕。百度副总裁陈洋受邀出席,并作《智能体在安全领域的应用实践》主题演讲,分享了在智能体在安全领域的突破性实践。他指出,百度通过将安全能力…...

拉力测试cuda pytorch 把 4070显卡拉满
import torch import timedef stress_test_gpu(matrix_size16384, duration300):"""对GPU进行压力测试,通过持续的矩阵乘法来最大化GPU利用率参数:matrix_size: 矩阵维度大小,增大可提高计算复杂度duration: 测试持续时间(秒&…...

Docker 本地安装 mysql 数据库
Docker: Accelerated Container Application Development 下载对应操作系统版本的 docker ;并安装。 基础操作不再赘述。 打开 macOS 终端,开始 docker 安装mysql之旅 第一步 docker search mysql 》〉docker search mysql NAME DE…...

解读《网络安全法》最新修订,把握网络安全新趋势
《网络安全法》自2017年施行以来,在维护网络空间安全方面发挥了重要作用。但随着网络环境的日益复杂,网络攻击、数据泄露等事件频发,现行法律已难以完全适应新的风险挑战。 2025年3月28日,国家网信办会同相关部门起草了《网络安全…...

逻辑回归暴力训练预测金融欺诈
简述 「使用逻辑回归暴力预测金融欺诈,并不断增加特征维度持续测试」的做法,体现了一种逐步建模与迭代验证的实验思路,在金融欺诈检测中非常有价值,本文作为一篇回顾性记录了早年间公司给某行做反欺诈预测用到的技术和思路。百度…...
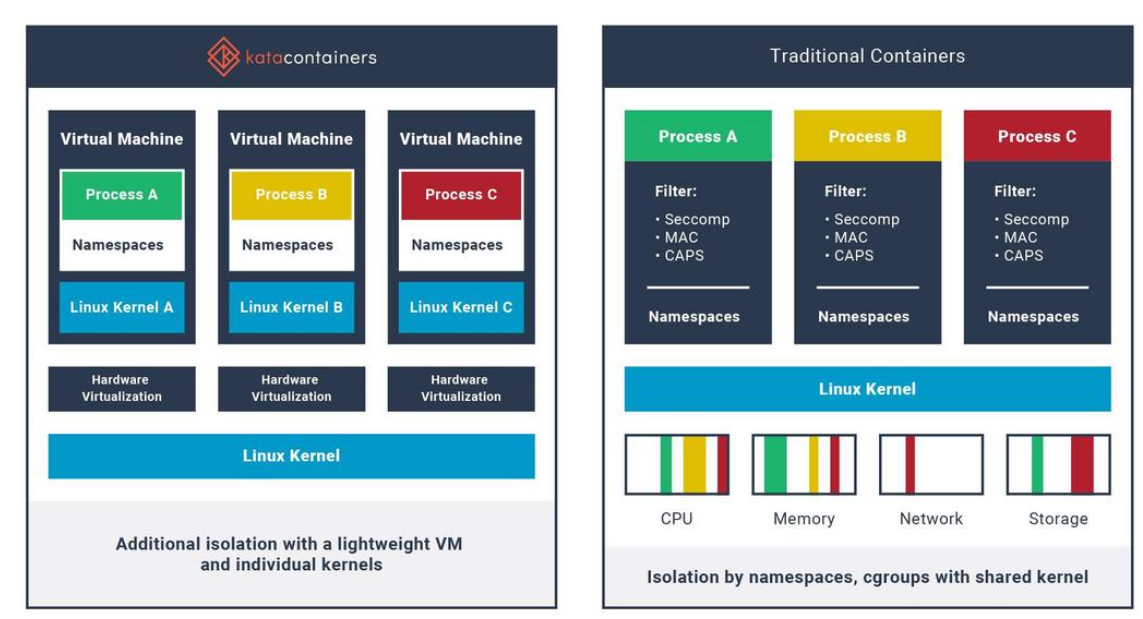
沙箱虚拟化技术虚拟机容器之间的关系详解
问题 沙箱、虚拟化、容器三者分开一一介绍的话我知道他们各自都是什么东西,但是如果把三者放在一起,它们之间到底什么关系?又有什么联系呢?我不是很明白!!! 就比如说: 沙箱&#…...

使用SSE解决获取状态不一致问题
使用SSE解决获取状态不一致问题 1. 问题描述2. SSE介绍2.1 SSE 的工作原理2.2 SSE 的事件格式规范2.3 SSE与其他技术对比2.4 SSE 的优缺点 3. 实战代码 1. 问题描述 目前做的一个功能是上传多个文件,这个上传文件是整体功能的一部分,文件在上传的过程中…...