政安晨【零基础玩转各类开源AI项目】基于Ubuntu系统部署Hallo :针对肖像图像动画的分层音频驱动视觉合成
政安晨的个人主页:政安晨
欢迎 👍点赞✍评论⭐收藏
收录专栏: 零基础玩转各类开源AI项目
希望政安晨的博客能够对您有所裨益,如有不足之处,欢迎在评论区提出指正!
本文目标:在Ubuntu系统上部署Hallo,实现训练和推理
背景介绍

由语音音频输入驱动的肖像图像动画领域在生成逼真的动态肖像方面取得了重大进展。
这项研究深入探讨了同步面部运动的复杂性,以及在基于扩散的方法框架内创建视觉上吸引人、时间上一致的动画。
我们的创新方法摒弃了依赖参数模型进行中间面部表征的传统模式,采用了端到端扩散模式,并引入了分层音频驱动视觉合成模块,以提高音频输入和视觉输出(包括嘴唇、表情和姿势运动)之间的对齐精度。 我们提出的网络架构无缝集成了基于扩散的生成模型、基于 UNet 的去噪器、时序对齐技术和参考网络。 所提出的分层音频驱动视觉合成技术可对表情和姿势多样性进行自适应控制,从而更有效地实现针对不同身份的个性化定制。
通过结合定性和定量分析的综合评估,我们的方法在图像和视频质量、嘴唇同步精度和动作多样性方面都有明显的提升。
项目地址为:
https://github.com/fudan-generative-vision/hallo![]() https://github.com/fudan-generative-vision/hallo
https://github.com/fudan-generative-vision/hallo

本方法所提议的流程概览如下:
具体而言,我们将包含肖像的参考图像与相应的音频输入整合,并用于驱动肖像动画。
可选的视觉合成权重可用于平衡嘴唇、表情和姿势权重。
ReferenceNet编码全局视觉纹理信息,用于实现一致且可控的角色动画。
人脸和音频编码器分别生成高保真的肖像身份特征和将音频编码为动作信息。
层次化音频驱动的视觉合成模块建立了音频和视觉组件(嘴唇、表情、姿势)之间的关系,并在扩散过程中使用UNet降噪器。

音频驱动的层次视觉合成的可视化及原始全方法与我们提出的层次音频-视觉交叉注意力之间的比较分析。
训练与推理
训练
训练过程包括两个不同的阶段:
(1) 在第一阶段的训练中,利用参考图像和目标视频帧对生成单个视频帧。
VAE编码器和解码器的参数以及面部图像编码器被固定,同时允许优化ReferenceNet和去噪UNet的空间交叉注意力模块的权重,以提高单帧生成能力。提取包含14帧的视频片段作为输入数据,从面部视频片段中随机选择一帧作为参考帧,从同一个视频中选择另一帧作为目标图像。
(2) 在第二阶段的训练中,使用参考图像、输入音频和目标视频数据进行视频序列训练。
ReferenceNet和去噪UNet的空间模块保持静态,专注于增强视频序列生成能力。这个阶段主要侧重于训练层次化的音频-视觉交叉注意力,建立音频作为运动指导和嘴唇、表情和姿势的视觉信息之间的关系。
此外,引入运动模块来改善模型的时间连贯性和平滑性,该模块使用来自AnimateDiff 的预设权重进行初始化。在这个阶段,从视频剪辑中随机选择一个帧作为参考图像。

与现有的肖像图像动画方法在HDTF数据集上的定量比较。本框架提出的方法在生成高质量、时间上连贯的说话头像动画以及优越的嘴唇同步性能方面表现出色。

上图为:在HDTF数据集上与现有方法的定性比较。
推理
在推理阶段,网络以一张参考图像和驾驶音频作为输入,根据相应的音频生成一个动画化的视频序列。为了产生视觉上一致的长视频,我们利用上一个视频片段的最后2帧作为下一个片段的初始k帧,实现逐步递增的视频片段生成。
开始部署
1. 把项目源码下载到本地
git clone git@github.com:fudan-generative-vision/hallo.git2. 创建 conda 环境
conda create -n hallo python=3.10conda activate hallo

3. 使用 pip 安装软件包



(此外,还需要 ffmpeg:sudo apt-get install ffmpeg, 如果没有安装的话可以在系统中安装一下)
4. 下载预训练模型
您可以从该项目的 HuggingFace 软件仓库轻松获取推理所需的所有预训练模型。
通过下面的 cmd 将预训练模型克隆到 ${PROJECT_ROOT}/pretrained_models 目录中:
git lfs install
git clone https://huggingface.co/fudan-generative-ai/hallo pretrained_models 



最后,这些预训练模型的组织结构如下:
./pretrained_models/
|-- audio_separator/
| |-- download_checks.json
| |-- mdx_model_data.json
| |-- vr_model_data.json
| `-- Kim_Vocal_2.onnx
|-- face_analysis/
| `-- models/
| |-- face_landmarker_v2_with_blendshapes.task # face landmarker model from mediapipe
| |-- 1k3d68.onnx
| |-- 2d106det.onnx
| |-- genderage.onnx
| |-- glintr100.onnx
| `-- scrfd_10g_bnkps.onnx
|-- motion_module/
| `-- mm_sd_v15_v2.ckpt
|-- sd-vae-ft-mse/
| |-- config.json
| `-- diffusion_pytorch_model.safetensors
|-- stable-diffusion-v1-5/
| `-- unet/
| |-- config.json
| `-- diffusion_pytorch_model.safetensors
`-- wav2vec/`-- wav2vec2-base-960h/|-- config.json|-- feature_extractor_config.json|-- model.safetensors|-- preprocessor_config.json|-- special_tokens_map.json|-- tokenizer_config.json`-- vocab.json5. 准备推理数据
Hallo 对输入数据有几个简单的要求:
源图像:
1. 应裁剪成正方形。
2. 人脸应是主要焦点,占图像的 50%-70%。
3. 人脸应朝向前方,旋转角度小于 30°(无侧面轮廓)。
驱动音频:
1. 必须是 WAV 格式。
2. 必须是英语,因为我们的训练数据集仅使用英语。
3. 确保人声清晰,背景音乐也可接受。
项目提供了一些样本供您参考(文件在项目源码中,小伙伴们自行获取 -- 政安晨)。
6. 运行推理
只需运行 scripts/inference.py,并将 source_image 和 driving_audio 作为输入即可:
python scripts/inference.py --source_image examples/reference_images/1.jpg --driving_audio examples/driving_audios/1.wav动画结果默认保存为 ${PROJECT_ROOT}/.cache/output.mp4。 你可以通过 --output 来指定输出文件名。 您可以在 examples 文件夹中找到更多推理示例。
在使用推理的过程中,您可能会遇到问题,比如提示xformers不可用,重新安装xformers等。
按照提示地址打开xformers官网重新安装:
conda install xformers -c xformers
之后,再重新按照上述方式在miniconda虚拟环境中重装依赖。
接下来,就可以正常操作了,我的示例如下:
python scripts/inference.py --source_image examples/YDBaba/2.jpg --driving_audio examples/YDBaba/1.wav
更多操作说明如下:
usage: inference.py [-h] [-c CONFIG] [--source_image SOURCE_IMAGE] [--driving_audio DRIVING_AUDIO] [--output OUTPUT] [--pose_weight POSE_WEIGHT][--face_weight FACE_WEIGHT] [--lip_weight LIP_WEIGHT] [--face_expand_ratio FACE_EXPAND_RATIO]options:-h, --help show this help message and exit-c CONFIG, --config CONFIG--source_image SOURCE_IMAGEsource image--driving_audio DRIVING_AUDIOdriving audio--output OUTPUT output video file name--pose_weight POSE_WEIGHTweight of pose--face_weight FACE_WEIGHTweight of face--lip_weight LIP_WEIGHTweight of lip--face_expand_ratio FACE_EXPAND_RATIOface region关于训练
为训练准备数据
训练数据使用了一些与推理所用源图像类似的会说话的人脸视频,也需要满足以下要求:
1. 照片应裁剪成正方形。
2. 面部应是主要焦点,占画面的 50%-70%。
3. 面部应朝向前方,旋转角度小于 30°(无侧面轮廓)。
将原始视频整理到以下目录结构中:
dataset_name/
|-- videos/
| |-- 0001.mp4
| |-- 0002.mp4
| |-- 0003.mp4
| `-- 0004.mp4
您可以使用任何数据集名称,但要确保视频目录的名称如上所示。
接下来,使用以下命令处理视频:
python -m scripts.data_preprocess --input_dir dataset_name/videos --step 1
python -m scripts.data_preprocess --input_dir dataset_name/videos --step 2
注:由于步骤 1 和步骤 2 执行不同的任务,因此应按顺序执行。
步骤 1 将视频转换为帧,从每个视频中提取音频,并生成必要的掩码。
步骤 2 使用 InsightFace 生成人脸嵌入,使用 Wav2Vec 生成音频嵌入,需要 GPU。 要进行并行处理,可使用 -p 和 -r 参数。 -p参数指定要启动的实例总数,将数据分成 p 部分。 -r参数指定当前进程应处理的部分。 您需要使用不同的 -r 值手动启动多个实例。
使用以下命令生成元数据 JSON 文件:
python scripts/extract_meta_info_stage1.py -r path/to/dataset -n dataset_name
python scripts/extract_meta_info_stage2.py -r path/to/dataset -n dataset_name
将 path/to/dataset 替换为视频父目录的路径,例如上例中的 dataset_name。 这将在 ./data 目录中生成 dataset_name_stage1.json 和 dataset_name_stage2.json。
训练
更新配置 YAML 文件 configs/train/stage1.yaml 和 configs/train/stage2.yaml 中的数据元路径设置:
#stage1.yaml
data:
meta_paths:
- ./data/dataset_name_stage1.json#stage2.yaml
data:
meta_paths:
- ./data/dataset_name_stage2.json
使用以下命令开始训练:
accelerate launch -m \
--config_file accelerate_config.yaml \
--machine_rank 0 \
--main_process_ip 0.0.0.0 \
--main_process_port 20055 \
--num_machines 1 \
--num_processes 8 \
scripts.train_stage1 --config ./configs/train/stage1.yaml
加速使用说明
加速启动命令用于以分布式设置启动训练过程。
accelerate launch [arguments] {training_script} --{training_script-argument-1} --{training_script-argument-2} ...支持加速的理由
-m, --module: 将启动脚本解释为 Python 模块。--config_file: 抱脸加速的配置文件。--machine_rank: 多节点设置中当前机器的等级。--main_process_ip: 主节点的 IP 地址。--main_process_port: 主节点的端口。--num_machines: 参与训练的节点总数。--num_processes: 训练进程总数,与所有机器的 GPU 总数相匹配。
训练论据
{training_script}: The training script, such asscripts.train_stage1orscripts.train_stage2.--{training_script-argument-1}: Arguments specific to the training script. Our training scripts accept one argument,--config, to specify the training configuration file.
对于多节点训练,需要在每个节点上分别手动运行不同机器等级的命令。
训练细节后续会继续为大家展示。—— 政安晨
相关文章:
政安晨【零基础玩转各类开源AI项目】基于Ubuntu系统部署Hallo :针对肖像图像动画的分层音频驱动视觉合成
政安晨的个人主页:政安晨 欢迎 👍点赞✍评论⭐收藏 收录专栏: 零基础玩转各类开源AI项目 希望政安晨的博客能够对您有所裨益,如有不足之处,欢迎在评论区提出指正! 本文目标:在Ubuntu系统上部署Hallo&#x…...

Spring Boot1(概要 入门 Spring Boot 核心配置 YAML JSR303数据校验 )
目录 一、Spring Boot概要 1. SpringBoot优点 2. SpringBoot缺点 二、Spring Boot入门开发 1. 第一个SpringBoot项目 项目创建方式一:使用 IDEA 直接创建项目 项目创建方式二:使用Spring Initializr 的 Web页面创建项目 (了解&#…...

电脑屏幕录制怎么弄?分享3个简单的电脑录屏方法
在信息爆炸的时代,屏幕上的每一个画面都可能成为我们生活中不可或缺的记忆。作为一名年轻男性,我对于录屏软件的需求可以说是既挑剔又实际。今天,我就为大家分享一下我近期体验的三款录屏软件:福昕录屏大师、转转大师录屏大师和OB…...

idea双击没有反应,打不开
问题描述 Error opening zip file or JAR manifest missing : /home/IntelliJ-IDEA/bin/jetbrains-agent.jar解决方案...

关于UniApp使用的个人笔记
UniApp 开发者中心 用于注册应用以及申请对应证书 https://dev.dcloud.net.cn/pages/app/list https://blog.csdn.net/fred_kang/article/details/124988303 下载证书后,获取SHA1关键cmd keytool -list -v -keystore test.keystore Enter keystore password…...
--perception:object_range_splitter)
autoware.universe源码略读(3.16)--perception:object_range_splitter
autoware.universe源码略读3.16--perception:object_range_splitter Overviewnode(Class Constructor)ObjectRangeSplitterNode::ObjectRangeSplitterNode(mFunc)ObjectRangeSplitterNode::objectCallback Overview 这里处理的依…...

深度学习落地实战:人脸五官定位检测
前言 大家好,我是机长 本专栏将持续收集整理市场上深度学习的相关项目,旨在为准备从事深度学习工作或相关科研活动的伙伴,储备、提升更多的实际开发经验,每个项目实例都可作为实际开发项目写入简历,且都附带完整的代码与数据集。可通过百度云盘进行获取,实现开箱即用 …...

270-VC709E 基于FMC接口的Virtex7 XC7VX690T PCIeX8 接口卡
一、板卡概述 本板卡基于Xilinx公司的FPGA XC7VX690T-FFG1761 芯片,支持PCIeX8、两组 64bit DDR3容量8GByte,HPC的FMC连接器,板卡支持各种FMC子卡扩展。软件支持windows,Linux操作系统。 二、功能和技术指标: 板卡功…...

【go】Excelize处理excel表 带合并单元格、自动换行与固定列宽的文件导出
文章目录 1 简介2 相关需求与实现2.1 导出带单元格合并的excel文件2.2 导出增加自动换行和固定列宽的excel文件 1 简介 之前整理过使用Excelize导出原始excel文件与增加数据校验的excel导出。【go】Excelize处理excel表 带数据校验的文件导出 本文整理使用Excelize导出带单元…...

uniapp自定义tabBar
uniapp自定义tabBar 1、在登录页中获取该用户所有的权限 getAppFrontMenu().then(res>{if(res.length > 0){// 把所有权限存入缓存中let firstPath res.reverse()[0].path;uni.setStorageSync(qx_data, res);uni.switchTab({url: firstPath,})// 方法二 通过uni.setTabB…...

IDEA2023版本创建JavaWeb项目及配置Tomcat详细步骤!
一、创建JavaWeb项目 第一步 之前的版本能够在创建时直接选成Web项目,但是2023版本在创建项目时没有该选项,需要在创建项目之后才能配置,首先先创建一个项目。 第二步 在创建好的项目中选中项目后(一定要注意选中项目名称然后继…...

WPF中MVVM常用的框架
在WPF开发中,MVVM(Model-View-ViewModel)是一种广泛使用的设计模式,它有助于分离应用程序的用户界面(View)、业务逻辑(Model)和数据表现层(ViewModel)。以下是…...

Mysql----内置函数
前言 提示:以下是本篇文章正文内容,下面案例可供参考 一、日期函数 日期:年月日 时间:时分秒 查询:当前时间,只显示当前日期 注意:如果类型为date或者datetime。表中数据类型为date,你插入时…...

去除重复字母
题目链接 去除重复字母 题目描述 注意点 s 由小写英文字母组成1 < s.length < 10^4需保证 返回结果的字典序最小(要求不能打乱其他字符的相对位置) 解答思路 本题与移掉 K 位数字类似,需要注意的是,并不是每个字母都能…...

Xcode进行真机测试时总是断连,如何解决?
嗨。大家好,我是兰若姐姐。最近我在用真机进行app自动化测试的时候,经常会遇到xcode和手机断连,每次断连之后需要重新连接,每次断开都会出现以下截图的报错 当这种情况出现时,之前执行的用例就相当于白执行了ÿ…...

Redis的使用(五)常见使用场景-分布式锁实现原理
1.绪论 为了解决并发问题,我们可以通过加锁的方式来保证数据的一致性,比如java中的synchronize关键字或者ReentrantLock,但是他们只能在同一jvm进程上加锁。现在的项目基本上都是分布式系统,如何对多个java实例进行加锁ÿ…...

AppML 案例:Products
AppML 案例:Products AppML(Application Markup Language)是一种创新的、基于XML的标记语言,旨在简化Web应用程序的开发。它允许开发者通过声明性的方式定义应用程序的界面和数据绑定,从而提高开发效率和减少代码量。…...
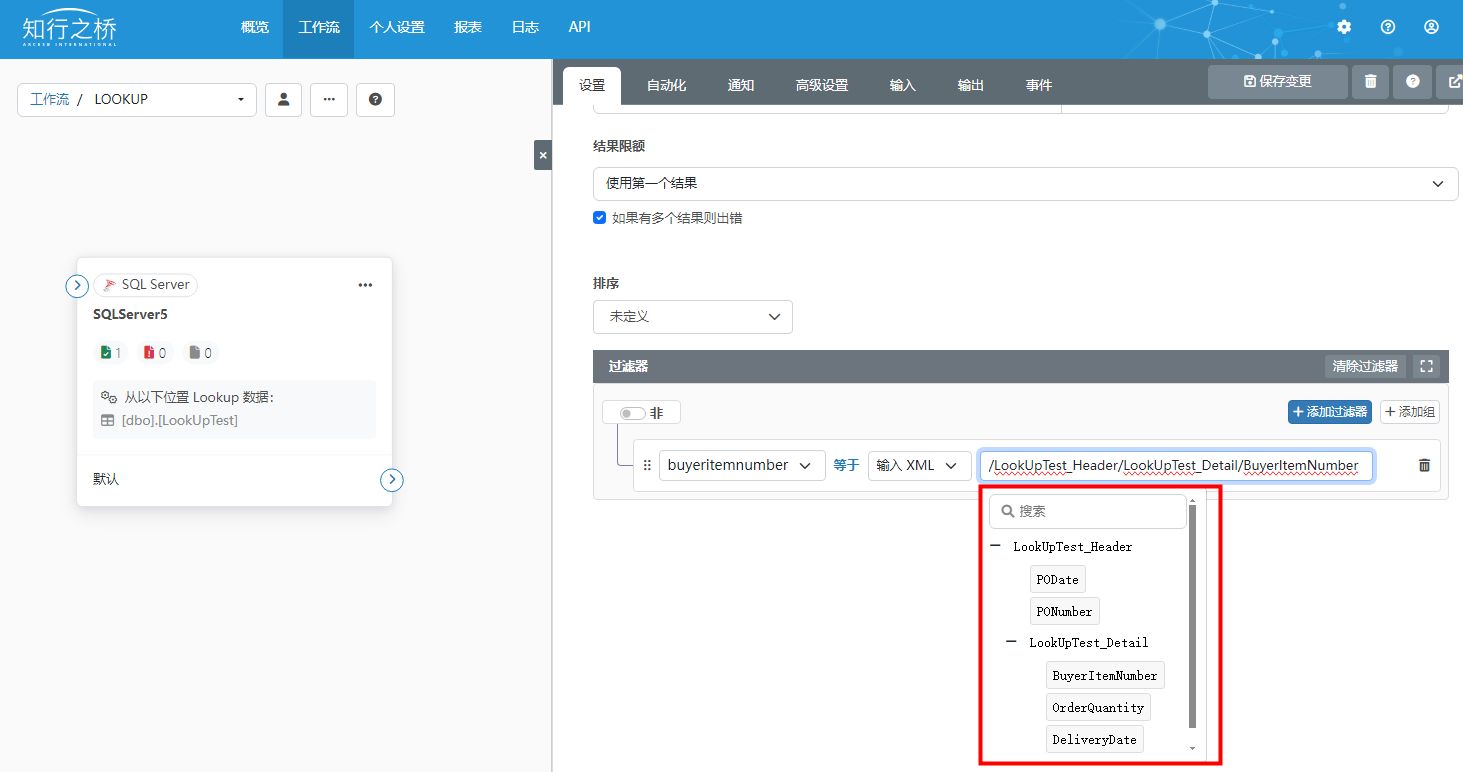
数据库端口LookUp功能:从数据库中获取并添加数据到XML
本文将为大家介绍如何使用知行之桥EDI系统数据库端口的Lookup功能,从数据库中获取数据,并添加进输入的XML中。 使用场景:期待以输入xml中的值为判断条件从数据库中获取数据,并添加进输入xml中。 例如:接收到包含采购…...

视频联网共享平台LntonCVS视频监控汇聚平台视频云解决方案
LntonCVS流媒体平台是一款遵循国家GB28181标准协议的先进视频监控与云服务平台。该平台设计独特,能够同时接入并处理多路设备的视频流,支持包括RTSP、RTMP、FLV、HLS、WebRTC在内的多种视频流格式的分发。其功能丰富多样,涵盖了视频直播监控、…...

深入探索Python中的`__slots__`类属性:优化内存与限制灵活性
深入探索Python中的__slots__类属性:优化内存与限制灵活性 在Python编程的广阔领域中,性能优化总是开发者们关注的焦点之一。特别是在处理大量对象或资源受限的环境中,减少内存占用和提高访问速度显得尤为重要。Python的__slots__类属性正是…...

java_网络服务相关_gateway_nacos_feign区别联系
1. spring-cloud-starter-gateway 作用:作为微服务架构的网关,统一入口,处理所有外部请求。 核心能力: 路由转发(基于路径、服务名等)过滤器(鉴权、限流、日志、Header 处理)支持负…...

基于距离变化能量开销动态调整的WSN低功耗拓扑控制开销算法matlab仿真
目录 1.程序功能描述 2.测试软件版本以及运行结果展示 3.核心程序 4.算法仿真参数 5.算法理论概述 6.参考文献 7.完整程序 1.程序功能描述 通过动态调整节点通信的能量开销,平衡网络负载,延长WSN生命周期。具体通过建立基于距离的能量消耗模型&am…...

Appium+python自动化(十六)- ADB命令
简介 Android 调试桥(adb)是多种用途的工具,该工具可以帮助你你管理设备或模拟器 的状态。 adb ( Android Debug Bridge)是一个通用命令行工具,其允许您与模拟器实例或连接的 Android 设备进行通信。它可为各种设备操作提供便利,如安装和调试…...

定时器任务——若依源码分析
分析util包下面的工具类schedule utils: ScheduleUtils 是若依中用于与 Quartz 框架交互的工具类,封装了定时任务的 创建、更新、暂停、删除等核心逻辑。 createScheduleJob createScheduleJob 用于将任务注册到 Quartz,先构建任务的 JobD…...
:滤镜命令)
ffmpeg(四):滤镜命令
FFmpeg 的滤镜命令是用于音视频处理中的强大工具,可以完成剪裁、缩放、加水印、调色、合成、旋转、模糊、叠加字幕等复杂的操作。其核心语法格式一般如下: ffmpeg -i input.mp4 -vf "滤镜参数" output.mp4或者带音频滤镜: ffmpeg…...

MySQL用户和授权
开放MySQL白名单 可以通过iptables-save命令确认对应客户端ip是否可以访问MySQL服务: test: # iptables-save | grep 3306 -A mp_srv_whitelist -s 172.16.14.102/32 -p tcp -m tcp --dport 3306 -j ACCEPT -A mp_srv_whitelist -s 172.16.4.16/32 -p tcp -m tcp -…...

企业如何增强终端安全?
在数字化转型加速的今天,企业的业务运行越来越依赖于终端设备。从员工的笔记本电脑、智能手机,到工厂里的物联网设备、智能传感器,这些终端构成了企业与外部世界连接的 “神经末梢”。然而,随着远程办公的常态化和设备接入的爆炸式…...

中医有效性探讨
文章目录 西医是如何发展到以生物化学为药理基础的现代医学?传统医学奠基期(远古 - 17 世纪)近代医学转型期(17 世纪 - 19 世纪末)现代医学成熟期(20世纪至今) 中医的源远流长和一脉相承远古至…...

C/C++ 中附加包含目录、附加库目录与附加依赖项详解
在 C/C 编程的编译和链接过程中,附加包含目录、附加库目录和附加依赖项是三个至关重要的设置,它们相互配合,确保程序能够正确引用外部资源并顺利构建。虽然在学习过程中,这些概念容易让人混淆,但深入理解它们的作用和联…...

怎么让Comfyui导出的图像不包含工作流信息,
为了数据安全,让Comfyui导出的图像不包含工作流信息,导出的图像就不会拖到comfyui中加载出来工作流。 ComfyUI的目录下node.py 直接移除 pnginfo(推荐) 在 save_images 方法中,删除或注释掉所有与 metadata …...