AI算法24-决策树C4.5算法
目录
决策树C4.5算法概述
决策树C4.5算法简介
决策树C4.5算法发展历史
决策树C4.5算法原理
信息熵(Information Entropy)
信息增益(Information Gain)
信息增益比(Gain Ratio)
决策树C4.5算法改进
决策树C4.5算法流程
步骤1:数据准备
步骤2:计算信息熵
步骤3:选择最优特征
步骤4:递归构建决策树
步骤5:决策树剪枝(可选)
决策树C4.5算法代码实现
决策树C4.5算法的优缺点
优点
缺点
决策树C4.5算法的应用场景
金融领域
医疗领域
电商领域
数据挖掘
机器学习研究
教育领域
环境监测
决策树C4.5算法概述
决策树C4.5算法简介
C4.5算法是由Ross Quinlan开发的用于产生决策树的算法。该算法是对Ross Quinlan之前开发的ID3算法的一个扩展。C4.5算法产生的决策树可以被用作分类目的,因此该算法也可以用于统计分类。 C4.5算法与ID3算法一样使用了信息熵的概念,并和ID3一样通过学习数据来建立决策树

C4.5算法是数据挖掘十大算法之一,它是对ID3算法的改进,相对于ID3算法主要有以下几个改进
- 用信息增益比来选择属性
- 在决策树的构造过程中对树进行剪枝
- 对非离散数据也能处理
- 能够对不完整数据进行处理
决策树C4.5算法发展历史
最早的决策树算法是由Hunt等人于1966年提出的CLS。当前最有影响的决策树算法是由Quinlan于1986年提出的ID3和1993年提出的C4.5.其他早期算法还包括CART,FACT,CHAID算法。后期的算法主要有SLIQ, SPRINT, PUBLIC等。
传统的决策树分类算法主要是针对小数据集的,大都要求训练集常驻内存,这使得在处理数据挖掘任务时,传统决策树算法在可伸展性,精度和效率方面受到了很大的限制。而在实际的数据挖掘应用中我们面临的数据集往往是容量巨大的数据库或者数据仓库,在构造决策树时需要将庞大的数据在主存和缓存中不停地导入导出,使得运算效率大大降低。针对以上问题,许多学者提出了处理大型数据集的决策树算法。
| A | B | C | |
| 1 | 年份 | 事件 | 相关论文 |
| 2 | 1993 | Ross Quinlan对ID3算法扩展,发明了C4.5算法 | C4.5: Programs for Machine Learning. Morgan Kaufmann Publishers.ISBN1-55860-238-0 |
| 3 | 2002 | 讲解了离散类数据挖掘的标杆属性选择技术,其中讲解了C4.5在大数据挖掘的应用。 | Hall M A, Holmes G. Benchmarking Attribute Selection Techniques for Discrete Class Data Mining[J]. IEEE Transactions on Knowledge & Data Engineering, 2002, 15(6):1437-1447. |
决策树C4.5算法原理
在深入了解C4.5算法之前,有必要明确几个核心概念和度量指标。本节将重点介绍信息熵、信息增益、以及信息增益比,这些都是C4.5算法决策树构建中的关键因素。
信息熵(Information Entropy)
信息熵是用来度量一组数据的不确定性或混乱程度的。它是基于概率论的一个概念,通常用以下数学公式来定义:

信息增益(Information Gain)
信息增益表示通过某个特征进行分裂后,数据集不确定性(即信息熵)下降的程度。信息增益通常用以下数学公式来定义:

信息增益比(Gain Ratio)
信息增益比是信息增益与该特征导致的数据集分裂复杂度(Split Information)的比值。用数学公式表示为:

决策树C4.5算法改进
在ID3中:
信息增益
按属性A划分数据集S的信息增益Gain(S,A)为样本集S的熵减去按属性A划分S后的样本子集的熵,即

在此基础上,C4.5计算如下:
分裂信息
利用引入属性的分裂信息来调节信息增益

信息增益率

信息增益率将分裂信息作为分母,属性取值数目越大,分裂信息值越大,从而部分抵消了属性取值数目所带来的影响。
相比ID3直接使用信息熵的增益选取最佳属性,避免因某属性有较多分类取值因而有较大的信息熵,从而更容易被选中作为划分属性的情况。
决策树C4.5算法流程
在这一部分中,我们将深入探讨C4.5算法的核心流程。流程通常可以分为几个主要步骤,从数据预处理到决策树的生成,以及后续的决策树剪枝。下面是更详细的解释:
步骤1:数据准备
在决策树的构建过程中,首先需要准备一个训练数据集。这个数据集应该包含多个特征(或属性)和一个目标变量(或标签)。数据准备阶段也可能包括数据清洗和转换。
步骤2:计算信息熵
信息熵是一个用于衡量数据不确定性的度量。在C4.5算法中,使用信息熵来评估如何分割数据。
步骤3:选择最优特征
在决策树的每一个节点,算法需要选择一个特征来分割数据。选择哪个特征取决于哪个特征会导致信息熵最大的下降(或信息增益最大)。
步骤4:递归构建决策树
一旦选择了最优特征并根据该特征分割了数据,算法将在每个分割后的子集上递归地执行同样的过程,直到满足某个停止条件(如,所有数据都属于同一类别或达到预设的最大深度等)。
步骤5:决策树剪枝(可选)
决策树剪枝是一种优化手段,用于去除决策树中不必要的节点,以防止过拟合。
决策树C4.5算法代码实现
import numpy as npclass Node:def __init__(self, gini, num_samples, num_samples_per_class, predicted_class):self.gini = giniself.num_samples = num_samplesself.num_samples_per_class = num_samples_per_classself.predicted_class = predicted_classself.feature_index = 0self.threshold = 0self.left = Noneself.right = Nonedef split(nodeX, nodeY, nodeX_col, split_index, split_value):left_indices = nodeX[:, nodeX_col] < split_valueright_indices = nodeX[:, nodeX_col] >= split_valuenodeY_left = nodeY[left_indices]nodeX_left = nodeX[left_indices]nodeY_right = nodeY[right_indices]nodeX_right = nodeX[right_indices]return nodeX_left, nodeY_left, nodeX_right, nodeY_rightdef calculate_gini(groups, classes):gini = 0.0n_instances = float(sum([len(group) for group in groups]))for group in groups:size = float(len(group))if size == 0:continuescore = 0.0group_classes = [row[-1] for row in group]for class_val in classes:p = group_classes.count(class_val) / sizescore += p * pgini += (1.0 - score) * (size / n_instances)return ginidef get_split(dataset, labels):class_values = list(set(labels))b_index, b_value, b_score, b_groups = 999, 999, 999, Nonefor index in range(len(dataset[0])-1):for row in dataset:groups = [row[index] < value for value in row[index]]score = calculate_gini(groups, class_values)if score < b_score:b_index, b_value, b_score, b_groups = index, row[index], score, groupsreturn {'index': b_index, 'value': b_value, 'groups': b_groups}def to_terminal(group):outcomes = [row[-1] for row in group]return outcomes.index(max(set(outcomes), key=outcomes.count))def split_dataset(dataset, labels, index, value):left, right = list(), list()for row, label in zip(dataset, labels):if row[index] < value:left.append(row)else:right.append(row)return left, rightdef grow_tree(dataset, labels, depth=0):labels = [label[-1] for label in labels]dataset, labels = shuffle(dataset, labels)best问答, groups = get_split(dataset, labels)left, right = split_dataset(dataset, labels, best问答['index'], best问答['value'])del (best问答['groups'])# 判断是否终止if not left or not right:return to_terminal(dataset)# 递归生成子树node = Node(gini=best问答['score'], num_samples=len(dataset), num_samples_per_class=[len(l) for l in labels], predicted_class=best问答['value'])if len(left) > 0:node.left = grow_tree(left, labels, depth+1)if len(right) > 0:node.right = grow_tree(right, labels, depth+1)return nodedef print_tree(node, depth=0):if isinstance(node, tuple):print("\n" + depth*" " + str(node))else:print("L:" + str(node.feature_index) + " <= " + str(node.threshold))print("\n" + depth*" " + "Predict: " + str(node.predicted_class))if node.left:print_tree(node.left, depth+1)if node.right:print("L:" + str(node.feature_index) + " > " + str(node.threshold))print("\n" + depth*" " + "Predict: " + str(node.predicted_class))print_tree(node.right, depth+1)def predict(node, row):if row[node.feature_index] <= node.threshold:if node.left:return predict(node.left, row)return node.predicted_classelse:if node.right:return predict(node.right, row)return node.predicted_classdef shuffle(dataset, labels):combined = list(zip(dataset, labels))np.random.shuffle(combined)dataset, labels = zip(*combined)return list(dataset), list(labels)def decision_tree_classifier(train_file_path):train_data = np.loadtxt(train_file_path, delimiter=',')train_data = np.array(train_data, dtype=np.float)train_dataset = train_data[:, :-1]train_labels = train_data[:, -1]tree = grow_tree(train_dataset, train_labels)print_tree(tree)test_data = np.loadtxt("test_data.txt", delimiter=',')test_dataset = test_data[:, :-1]test_labels = test_data[:, -1]predictions = list()for row in test_dataset:prediction = predict(tree, row)predictions.append(prediction)accuracy = sum([predictions[i] == test_labels[i] for i in range(len(test_labels))]) / float(len(test_labels))print("Accuracy: " + str(accuracy))if __name__ == "__main__":decision_tree_classifier("train_data.txt")这段代码实现了C4.5算法的基本功能,包括数据的读取、决策树的生成、预测和准确率计算。你可以将训练数据和测试数据分别保存在train_data.txt和test_data.txt文件中,然后运行代码进行训练和测试。
决策树C4.5算法的优缺点
优点
- 易于理解和解释:决策树是白盒模型,每个节点的决策逻辑清晰,易于理解和解释。例如,银行可以轻易地解释给客户为什么他们的贷款申请被拒绝 。
- 能够处理非线性关系:C4.5算法能很好地处理特征与目标变量之间的非线性关系。例如,在电子商务网站中,用户年龄和购买意愿之间可能存在非线性关系,C4.5算法能捕捉到这种关系 。
- 对缺失值有较好的容忍性:C4.5算法可以容忍输入数据的缺失值,使其在医疗诊断等场景中仍然有效 。
- 处理连续属性:C5算法能够处理连续属性,通过单点离散化的方法选择最优的划分属性 。
- 剪枝优化:C4.5算法通过引入剪枝技术,能够有效地提升模型的泛化能力,减少过拟合的风险 。
缺点
- 容易过拟合:C4.5算法非常容易产生过拟合,尤其是当决策树很深的时候。例如,如果一个决策树模型在股票市场预测问题上表现得异常好,那很可能是该模型已经过拟合了 。
- 对噪声和异常值敏感:由于决策树模型在构建时对数据分布的微小变化非常敏感,因此噪声和异常值可能会极大地影响模型性能。例如,在识别垃圾邮件的应用中,如果训练数据包含由于标注错误而导致的噪声,C4.5算法可能会误将合法邮件分类为垃圾邮件 。
- 计算复杂度较高:C4.5算法在特征维度非常高时可能会有较高的计算成本。例如,在基因表达数据集上,由于特征数可能达到数千或更多,使用C4.5算法可能会导致计算成本增加 。
- 时间耗费大:C5算法在处理连续值时,需要计算所有可能的切分点,这使得算法的时间复杂度较高 。
- 未解决回归问题:C4.5算法主要用于分类问题,并未解决回归问题 。
决策树C4.5算法的应用场景
金融领域
- 信用评分:C4.5算法可以用于评估客户的信用风险,帮助银行和金融机构决定是否批准贷款或信用卡申请。通过构建决策树模型,可以对客户进行分类,从而为贷款审批提供依据。
- 风险评估:在金融风控中,C4.5算法可以分析客户的财务状况、信用评分等特征,评估贷款违约风险。
医疗领域
- 疾病诊断:C4.5算法可以用于辅助医生进行疾病诊断。通过对病人的特征进行分类,可以辅助医生做出更准确的诊断和治疗方案。
- 治疗方案选择:在医疗领域,C4.5算法还可以用于选择最佳的治疗方案,通过对病人的病情和治疗反应进行分析,提供个性化的治疗建议。
电商领域
- 商品推荐:在电商领域,C4.5算法可以分析用户的购买历史和行为特征,构建决策树模型,为用户推荐合适的商品。
- 用户细分:通过分析用户的行为数据,C4.5算法可以帮助电商平台进行用户细分,提供个性化的服务和营销策略。
数据挖掘
- 数据分类:C4.5算法在数据挖掘中用于将数据集分类,通过递归地将数据集划分成更小的子集,形成树状结构,以便进行决策。
- 特征选择:C4.5算法通过信息增益比(Gain Ratio)来选择最优的划分属性,构建决策树,从而在数据挖掘中实现高效的特征选择。
机器学习研究
- 算法比较:C4.5算法常与其他决策树算法(如ID3、CART和Random Forests)进行比较,研究其在不同应用场景下的适用性和性能表现。
- 模型优化:在机器学习研究中,C4.5算法的剪枝策略和对连续属性的处理机制被广泛研究,以提高模型的泛化能力和计算效率。
教育领域
- 学生评估:C4.5算法可以用于教育领域,通过分析学生的学习表现、行为特征等,预测学生的学业成绩或学习习惯。
环境监测
- 污染预测:在环境科学中,C4.5算法可以用于预测空气质量或水污染情况,通过对环境数据的分析,提供污染控制的建议。
相关文章:
AI算法24-决策树C4.5算法
目录 决策树C4.5算法概述 决策树C4.5算法简介 决策树C4.5算法发展历史 决策树C4.5算法原理 信息熵(Information Entropy) 信息增益(Information Gain) 信息增益比(Gain Ratio) 决策树C4.5算法改进 …...
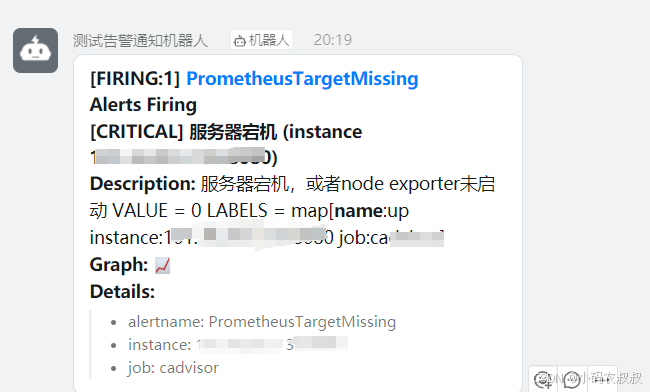
【云原生】Prometheus整合Alertmanager告警规则使用详解
目录 一、前言 二、Altermanager概述 2.1 什么是Altermanager 2.2 Altermanager使用场景 三、Altermanager架构与原理 3.1 Altermanager使用步骤 3.2 Altermanager工作机制 3.3 Altermanager在Prometheus中的位置 四、Altermanager部署与接入Prometheus 4.1 Altermana…...

C++ :友元类
友元类的概念和使用 (1)将类A声明为B中的friend class后,则A中所有成员函数都成为类B的友元函数了 (2)代码实战:友元类的定义和使用友元类是单向的 (3)友元类是单向的,代码实战验证 互为友元类 (1)2个类可以互为友元类,代码实战…...

【整理了一些关于使用swoole使用的解决方案】
目录 如何监控和分析 Swoole 服务器的性能瓶颈? 在进行 Swoole 服务器性能优化时,有哪些常见的错误和陷阱需要避免? 除了 Swoole,还有哪些 PHP 框架或技术可以用于构建高并发的 Web 应用? Swoole 同步请求在高并发…...

python selenium4 EdgeDriver动态页面爬取
截止至2024.7.16 chrome浏览器最新版本为126.0.6478.127 但对应的chromeDriver版本都低于此版本,因此,转用Edge浏览器 说明:仅记录自己使用过程中用到的一些代码和感受,看具体情况不定期更新。 selenium官方文档 1、安装selen…...

【一次记一句:SQL】从 information_schema.TABLES中查询数据库表中记录数据量
有时候,一张千万数据量的表,使用 count(*) 统计记录数,查不动。可以使用下述SQL来试试: SELECT CONCAT(table_schema, ., table_name) AS "Table Name", table_rows AS "Number of Rows", CONCAT(ROUND(data…...

NXP i.MX8系列平台开发讲解 - 3.19 Linux TTY子系统(二)
专栏文章目录传送门:返回专栏目录 Hi, 我是你们的老朋友,主要专注于嵌入式软件开发,有兴趣不要忘记点击关注【码思途远】 目录 1. Linux 串口驱动 1.1 Uart 驱动注册流程 1.2 uart 操作函数 1.3 line discipline 2. Linux tty应用层使用…...

FPGA资源容量
Kintex™ 7 https://www.amd.com/zh-tw/products/adaptive-socs-and-fpgas/fpga/kintex-7.html#product-table AMD Zynq™ 7000 SoC https://www.amd.com/en/products/adaptive-socs-and-fpgas/soc/zynq-7000.html#product-table AMD Zynq™ UltraScale™ RFSoC 第一代 AMD Z…...

Zabbix介绍和架构
目录 一.Zabbix简介 1.为什么需要监控 2.需要监控什么 3.常见的监控工具 4.Zabbix使用场景及系统概述 5.Zabbix 架构 6.Zabbix工作流程 7.Zabbix 术语 二. 部署安装zabbix 三.zabbix 配置文件 一.Zabbix简介 1.为什么需要监控 运维行业有句话:“无监控、不运维”&am…...
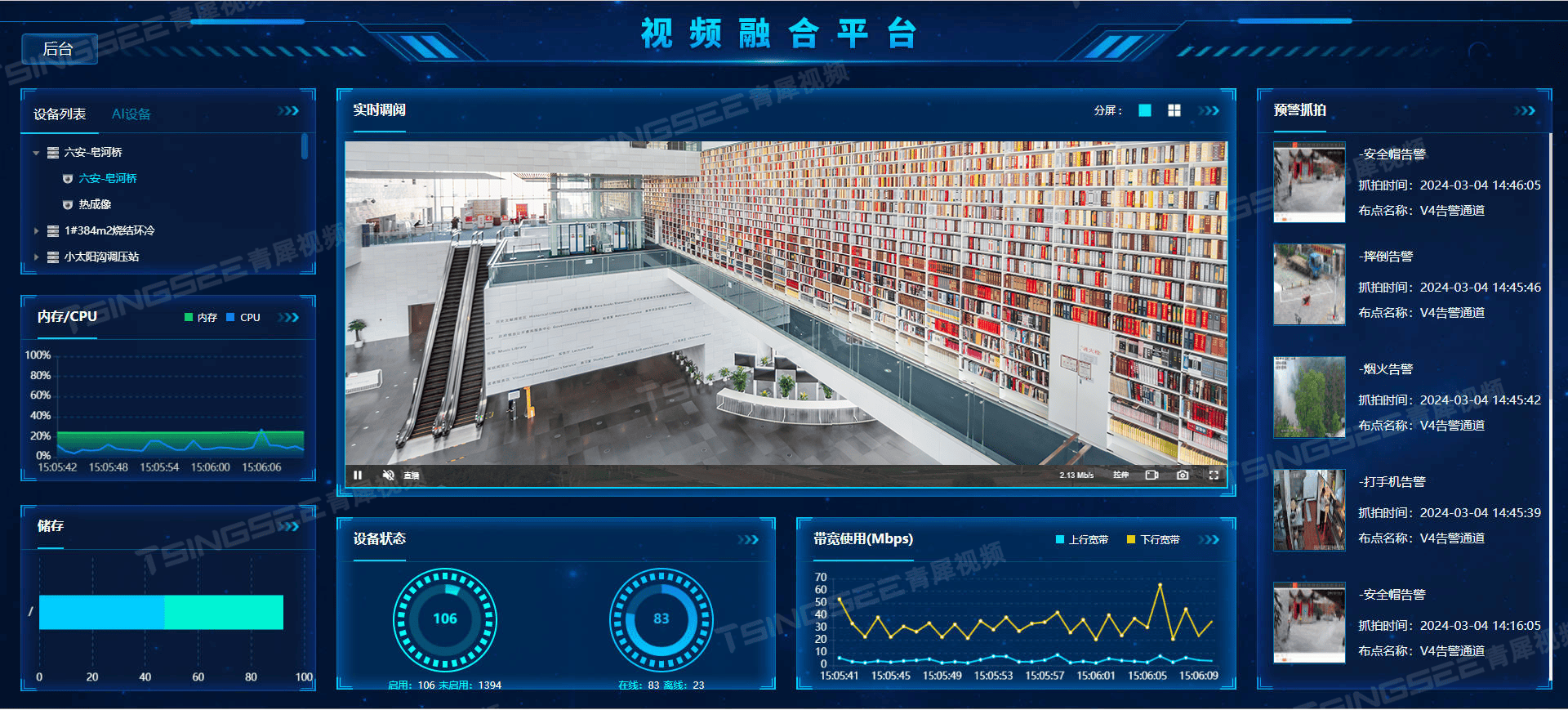
打造智慧图书馆:AI视频技术助力图书馆安全与秩序管理
一、背景需求 随着信息技术的飞速发展,图书馆作为重要的知识传播场所,其安全管理也面临着新的挑战。为了确保图书馆内书籍的安全、维护读者的阅读环境以及应对突发事件,TSINGSEE青犀旭帆科技基于EasyCVR视频监控汇聚平台技术与AI视频智能分析…...

Go的数据结构与实现【LinkedList】
介绍 所谓链表(Linked List),就是按线性次序排列的一组数据节点。每个节点都是一个对象,它通过一个引用指向对应的数据元素,同时还通过一个引用next指向下一节点。 实现 逻辑方法 我们定义链表的结构体:…...
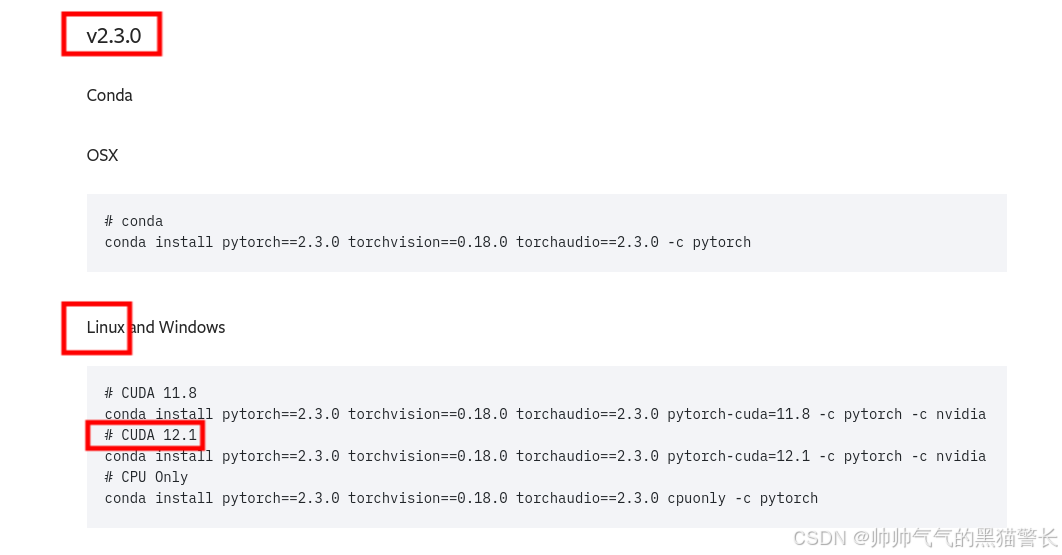
Ubuntu22.04安装CUDA+CUDNN+Conda+PyTorch
步骤: 1、安装显卡驱动; 2、安装CUDA; 3、安装CUDNN; 4、安装Conda; 5、安装Pytorch。 一、系统和硬件信息 1、Ubuntu 22.04 2、显卡:4060Ti 二、安装显卡驱动 (已经安装的可以跳过&a…...
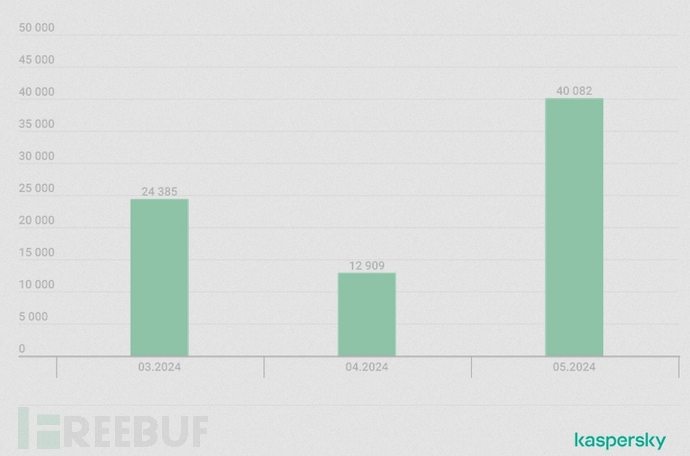
当“广撒网”遇上“精准定点”的鱼叉式网络钓鱼
批量网络钓鱼电子邮件活动倾向于针对大量受众,它们通常使用笼统的措辞和简单的格式,其中不乏各种拼写错误。而有针对性的攻击往往需要付出更大的努力,攻击者会伪装成雇主或客户向目标发送包含个人详细信息的个性化消息。在更大范围内采用这种…...

svn ldap认证临时切换到本地认证
当前的svn是在CentOS 7 下 SVN、 Apache 对接 LDAP 服务实现用户账号管理和权限认证,本文模拟ldap数据丢失如何恢复svn,方法是临时将认证切换到本地认证 编辑subversion.conf文件 vi /etc/httpd/conf.d/subversion.conf 注释ldap-status #<Locati…...

极狐GitLab如何配置使用独立数据库?
GitLab 是一个全球知名的一体化 DevOps 平台,很多人都通过私有化部署 GitLab 来进行源代码托管。极狐GitLab :https://gitlab.cn/install?channelcontent&utm_sourcecsdn 是 GitLab 在中国的发行版,专门为中国程序员服务。可以一键式部署…...

TCP状态转换详解
1.什么是TCP的状态转换 TCP(Transmission Control Protocol,传输控制协议)是一种面向连接的、可靠的、基于字节流的传输层协议。在 TCP 连接的生命周期中,连接的状态会随着不同阶段的通信而发生变化,这些变化被称为状…...

SimMIM:一个类BERT的计算机视觉的预训练框架
1、前言 呃…好久没有写博客了,主要是最近时间比较少。今天来做一期视频博客的内容。本文主要讲SimMIM,它是一个将计算机视觉(图像)进行自监督训练的框架。 原论文:SimMIM:用于掩码图像建模的简单框架 (a…...

数据精度丢失
js数据精度丢失 最近看面试题想到了之前在开发钟遇到过的问题,现总结一下 在开发过程中,发现从后台返回的数据结构中的id字段在前端显示为不正确的值。经过排查,怀疑是JavaScript中Number类型精度丢失的问题。通过将id字段的类型从Number改为…...

Element UI DatePicker选择日期范围区间默认显示前一个月和本月
要求:点击el-date-picker选择时间范围时,默认展开当月和上个月。 但是Element UI的组件默认展开的是本月和下一个月,如下图所示: 改为 <span click"changeInitCalendarRange"><el-date-picker v-model"r…...

C++:聚合类、嵌套类、局部类、union类详细介绍与分析
聚合类 (1)What(什么是聚合类) 本质是一个自定义类型的数据结构(结构体或类),但聚合类有以下特性: 所有的成员都是public没有任何构造函数没有基类类内部没有初始值 (2)Why(聚合类的作用&…...

业务系统对接大模型的基础方案:架构设计与关键步骤
业务系统对接大模型:架构设计与关键步骤 在当今数字化转型的浪潮中,大语言模型(LLM)已成为企业提升业务效率和创新能力的关键技术之一。将大模型集成到业务系统中,不仅可以优化用户体验,还能为业务决策提供…...

调用支付宝接口响应40004 SYSTEM_ERROR问题排查
在对接支付宝API的时候,遇到了一些问题,记录一下排查过程。 Body:{"datadigital_fincloud_generalsaas_face_certify_initialize_response":{"msg":"Business Failed","code":"40004","sub_msg…...
)
论文解读:交大港大上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架(二)
HoST框架核心实现方法详解 - 论文深度解读(第二部分) 《Learning Humanoid Standing-up Control across Diverse Postures》 系列文章: 论文深度解读 + 算法与代码分析(二) 作者机构: 上海AI Lab, 上海交通大学, 香港大学, 浙江大学, 香港中文大学 论文主题: 人形机器人…...

Python:操作 Excel 折叠
💖亲爱的技术爱好者们,热烈欢迎来到 Kant2048 的博客!我是 Thomas Kant,很开心能在CSDN上与你们相遇~💖 本博客的精华专栏: 【自动化测试】 【测试经验】 【人工智能】 【Python】 Python 操作 Excel 系列 读取单元格数据按行写入设置行高和列宽自动调整行高和列宽水平…...

转转集团旗下首家二手多品类循环仓店“超级转转”开业
6月9日,国内领先的循环经济企业转转集团旗下首家二手多品类循环仓店“超级转转”正式开业。 转转集团创始人兼CEO黄炜、转转循环时尚发起人朱珠、转转集团COO兼红布林CEO胡伟琨、王府井集团副总裁祝捷等出席了开业剪彩仪式。 据「TMT星球」了解,“超级…...

多模态商品数据接口:融合图像、语音与文字的下一代商品详情体验
一、多模态商品数据接口的技术架构 (一)多模态数据融合引擎 跨模态语义对齐 通过Transformer架构实现图像、语音、文字的语义关联。例如,当用户上传一张“蓝色连衣裙”的图片时,接口可自动提取图像中的颜色(RGB值&…...
)
【RockeMQ】第2节|RocketMQ快速实战以及核⼼概念详解(二)
升级Dledger高可用集群 一、主从架构的不足与Dledger的定位 主从架构缺陷 数据备份依赖Slave节点,但无自动故障转移能力,Master宕机后需人工切换,期间消息可能无法读取。Slave仅存储数据,无法主动升级为Master响应请求ÿ…...

SpringTask-03.入门案例
一.入门案例 启动类: package com.sky;import lombok.extern.slf4j.Slf4j; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; import org.springframework.cache.annotation.EnableCach…...

MySQL用户和授权
开放MySQL白名单 可以通过iptables-save命令确认对应客户端ip是否可以访问MySQL服务: test: # iptables-save | grep 3306 -A mp_srv_whitelist -s 172.16.14.102/32 -p tcp -m tcp --dport 3306 -j ACCEPT -A mp_srv_whitelist -s 172.16.4.16/32 -p tcp -m tcp -…...

Linux --进程控制
本文从以下五个方面来初步认识进程控制: 目录 进程创建 进程终止 进程等待 进程替换 模拟实现一个微型shell 进程创建 在Linux系统中我们可以在一个进程使用系统调用fork()来创建子进程,创建出来的进程就是子进程,原来的进程为父进程。…...