基础IO【Linux】
文章目录:
- 文件相关知识
- C语言文件IO
- stdin & stdout & stderr
- 系统文件 IO
- open
- close
- write
- read
- 文件描述符
- 文件描述符的分配规则
- 重定向
- dup2系统调用
- FILE
- FILE中的文件描述符
- FILE中的缓冲区理解
文件相关知识
- 文件 = 文件内容 + 文件属性(每一个已经存在的文件都有其相应的属性来标识该文件,空文件也有)。
- 文件的操作 = 文件内容的操作 | 文件属性的操作(在对文件的内容进行操作时,文件的属性也可能会改变)。
- 文件分为两类:内存文件和磁盘文件。
- 通常打开文件、访问文件、关闭文件,都是由谁了进行相关操控的呢?fopen、fwrite、fclose 操控程序,当执行程序,进程运行起来的时候,才是对文件进行真正的操作
- 文件操作的本质是:进程和被打开文件之间的关系。
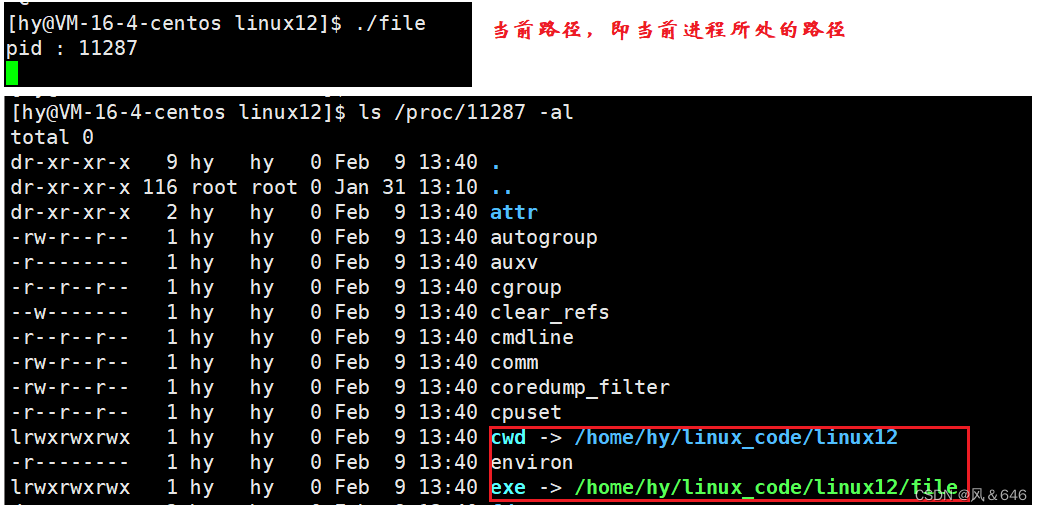
- 什么是当前路径?如下所示:cwd(curren work directory)所指向的路径就是当前路径。当前路径不是指可执行程序所处的路径,而是指该可执行程序运行时所处的路径。
C语言文件IO
在之前,我们对文件进行了简单的介绍,具体可看:C语言文件操作
下面来回顾一下C语言文件的基本操作:
#include<stdio.h>
#include<sys/types.h>
#include<unistd.h>int main()
{// 不更改文件路径情况下,文件默认在当前路径下形成chdir("/home/hy/linux_code"); //更改当前进程的工作路径,生成的文件就在已更改的路径下FILE* fp = fopen("log.txt","w"); //文件以w的方式打开,文件不存在则创建一个,若文件存在则先对文件进行清空if(fp == NULL) {perror("fopen");return 1;}const char* msg = "hello file";int cnt = 1;while(cnt <= 10){fprintf(fp,"%s : %d\n",msg,cnt++);}fclose(fp);return 0;
}
打开文件的方式:

用文件操作实现简单的 cat 功能:
#include<stdio.h>
#include<sys/types.h>
#include<unistd.h>// myfile filename
int main(int argc,char* argv[])
{if(argc != 2) //判断输入格式是否正确{printf("usage: %s filename\n",argv[0]); //提示正确的使用方法return 1;}// 将输入的第二个参数的内容读入文件中FILE* fp = fopen(argv[1],"r");if(fp == NULL){perror("fopen");return 1;}char buffer[64];while(fgets(buffer,sizeof(buffer),fp)!=NULL) //将文件中的内容读到buffer中{printf("%s",buffer);}return 0;
}
stdin & stdout & stderr
在 Linux 下,一切皆文件。所以显示器和输入键盘也看作是文件。我们能看到显示器上的数据,是因为我们向显示器文件中写入了对应的数据。电脑能够从键盘中读取我们输入的数据。那为什么我们向显示器文件写入数据以及从键盘文件读取数据前,不需要打开这两个文件呢?
任何进程运行时都会默认的打开三个数据流(stdin、stdout、stderr)。
- stdin -> 标准输入流 -> 通常对应终端的键盘
- stdout -> 标准输出流 -> 终端显示器
- stderr -> 标准错误流 -> 终端显示器
查询 man 手册,可以发现:stdin、stdout、stderr 这三个流的类型都是 FILE* 。

进程从标准输入文件中得到输入数据,将正常输出数据输出到标准输出文件,而将错误信息送到标准错误文件中。
输出信息到显示器的方法:
#include<stdio.h>
#include<string.h>int main()
{const char* msg = "hello fwrite!\n";fwrite(msg,strlen(msg),1,stdout);printf("hello printf\n");fprintf(stdout,"hello fprintf\n");return 0;
}
系统文件 IO
操作系统除了语言级层面的函数接口(c/c++语言,Java语言接口等)外,还有一套系统接口来进行文件的访问及操作。
- write :写入数据
- read :读取数据
- open :打开文件
- close :关闭文件
以上接口都是用于系统层面而非用户层面的。
C语言中的函数,如 fopen、fwrite、fclose 等,我们都比较熟悉,而系统层面的接口,如 open、write、close 等接口,都比较少用。相比于库函数而言,系统接口更接近底层。但实际上语言层面的库函数就是对系统接口进行了封装:🎯
🎯从开发角度看,操作系统对外表现为一个整体,会提供部分接口,以供上层用户的调用 (系统调用)。但是系统接口相对而言比较复杂,使用成本很高,不利于上层开发人员的使用。所以我们对一些系统接口进行了适当的封装,封装后的接口就是各个语言的库函数。

简单而言,fwrite 函数是使用系统接口 write 进行封装的,系统调用 write 只有一个,相关的库函数都是建立在 write 等接口进行封装的。这样使得语言具有了跨平台性,便于进行二次开发。
接下来,简单介绍一下系统接口,便于从底层更深入的了解IO。
open
操作系统中打开文件的接口是 open , open 的头文件和函数定义如下:
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>int open(const char *pathname,int flags);
int open(const char *pathname,int flags,mode_t mode);
参数说明:
pathname:
要打开或创建的目标文件。
- 若 pathname 传入的是特定的路径,则就在 pathname 所给出的路径下创建目标文件。
- 若 pathname 传入的是文件名,则就在当前路径下创建目标文件。
flags:
表示打开文件的方式。打开文件时,可以传入多个参数选项,用下面的一个或者多个常量进行 “或” 运算,构成 flags。以 | 进行分割。
常用选项如下所示:
| 参数选项 | 说明 |
|---|---|
| O_RDONLY | 以只读的方式打开文件 |
| O_WRONLY | 以只写的方式打开文件 |
| O_RDWR | 以读写的方式打开文件 |
| O_CREAT | 当文件不存在时,创建该文件 |
| O_APPEND | 以追加的方式写入文件 |
| O_TRUNC | 如果文件存在且该文件运行写入就将文件进行清空 |
mode:
open 函数具体使用哪一个,和具体应用场景有关,若目标文件不存在,需要使用 open 进行创建,则第三个参数表示创建文件的默认权限,否则,就使用两个参数的 open 函数。使用 open 创建新文件时,若不传入默认的权限,则权限是乱的。
例如:将 0666 传入 mode 参数,则创建出来的文件权限为:-rw-rw-rw-,但是创建出来的文件的实际权限还受默认权限掩码 umask 的限制,实际上文件创建出来的权限为:mode&(~umask)。umask 在普通用户下一般为 0002 ,因此将 0666 传入 mode 参数时,创建的新文件的实际权限为:-rw-rw-r--。这并不是我们想要的。
🪁若想要创建出来的新文件不受默认权限掩码 umask 的影响,我们可以在调用 open 接口前,将 umask 在程序中设置为 0。
umask(0); //将文件的默认权限设置为0
返回值:
- 成功:返回新打开的文件描述符
- 失败:返回 -1
open 的第二个参数传入的是宏,那么宏的实现基本原理是什么呢?第二个参数的类型是 int ,有 32 个比特位,实际上一个比特位可以作为一个标志位。flags 的每一个选项都是以宏的方式定义的。
接下来看一个例子,理解一下宏实现的基本原理:
#include<stdio.h>// 可以用比特位标志不同的宏定义,如下所示:
#define PRINT_A 0x1 //0000 0001
#define PRINT_B 0x2 //0000 0010
#define PRINT_C 0x4 //0000 0100
#define PRINT_D 0x8 //0000 1000
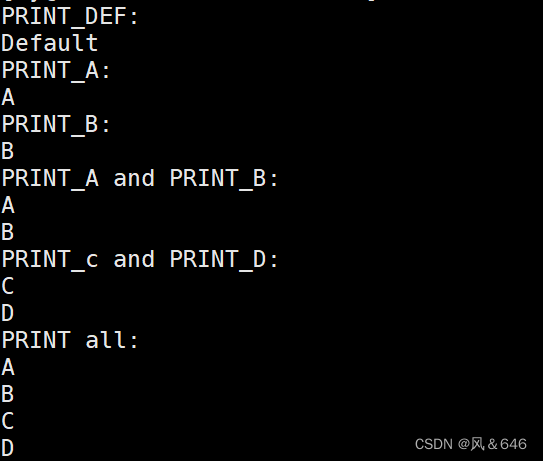
#define PRINT_DEF 0x0 void Show(int flags)
{if(flags & PRINT_A) printf("A\n");if(flags & PRINT_B) printf("B\n");if(flags & PRINT_C) printf("C\n");if(flags & PRINT_D) printf("D\n");if(flags == PRINT_DEF) printf("Default\n");
}int main()
{printf("PRINT_DEF:\n");Show(PRINT_DEF);printf("PRINT_A:\n");Show(PRINT_A);printf("PRINT_B:\n");Show(PRINT_B);printf("PRINT_A and PRINT_B:\n");Show(PRINT_A | PRINT_B);printf("PRINT_c and PRINT_D:\n");Show(PRINT_C | PRINT_D);printf("PRINT all:\n");Show(PRINT_A | PRINT_B | PRINT_C | PRINT_D);return 0;
}
运行结果如下所示:
close
系统接口 close 用于关闭文件。close 接口的定义和头文件如下:
#include<unistd.h>int close(int fd); // fd(文件描述符)是打开文件时的返回值
返回值:
close 关闭文件成功则返回 0 。若出现错误,则返回 -1,并适当的设置 errno。
write
系统接口 write 用于向文件中写入数据,write 接口的定义和头文件如下:
#include<unistd.h>ssize_t write(int fd,const void* buf,size_t count);
// 使用write接口将buf中count字节的数据写入文件描述符为fd的文件中
返回值:
- 数据写入成功时,返回写入的字节数(零表示没有写入任何字节)。
- 数据写入出错时,则返回 -1,并适当的设置 errno。
示例:
#include<stdio.h>
#include<fcntl.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<string.h>
#include<unistd.h>int main()
{umask(0);//设置默认权限掩码为0int fd = open("log.txt",O_WRONLY | O_CREAT | O_TRUNC,0666);//int fd = open("log.txt",O_WRONLY | O_CREAT | O_APPEND,0666);if(fd < 0){perror("open");return 1;}const char* msg = "hello file\n";int count = 0;while(count < 5){write(fd,msg,strlen(msg)); // msg:缓冲区首地址;len:本次读取,期望写入多少个字节的数据;返回值:实际写了多少字节数据count++;}close(fd);return 0;
}
运行结果如下:

❗注意:向文件中写入数据时,不需要写入 ‘\0’。它是C语言规定的字符串结束标志,系统IO没有规定。因此只要将有效字符写入即可。write 的第二个参数类型为 void* ,意味着系统不在意写入的类型,我们需要什么类型数据就转换为什么类型再写入/
read
系统接口 read 用于从文件中读取数据,read 接口的定义和头文件如下:
#include<unistd.h>ssize_t read(int fd,void *buf,size_t count);
// 从文件描述符为fd的文件中读取count字节数据到buf中
返回值:
- 如果读取数据成功,将返回读取的字节数(0表示文件结束),如果count大于文件的数据字节数,则不是错误,直接读取完文件。
- 如果读取数据错误,则返回 -1,并适当设置 errno。
示例:
#include<stdio.h>
#include<fcntl.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<string.h>
#include<unistd.h>int main()
{int fd = open("log.txt",O_RDONLY); //读取文件的前提是文件已经存在,所以不涉及权限和创建文件的问题if(fd < 0){perror("open");return 1;}char buffer[128];ssize_t s = read(fd,buffer,sizeof(buffer)-1);if(s > 0){buffer[s] = '\0'; printf("%s",buffer);}close(fd);return 0;
}
运行结果如下:
文件描述符
文件描述符是操作系统内核中,用于标识一个进程正在访问的文件或其它输入/输出资源的正整数。在 unix/linux 系统中,文件、管道、套接字、块、设备等资源都被视为文件,每一个打开的文件都会被分配一个唯一的文件描述符。
文件是由进程运行时打开的,一个进程可以打开多个文件,而系统中存在着大量的进程,因此,系统中可能存在大量被打开的文件。如此多的文件,操作系统是怎样对它们进行管理的呢?操作系统会给每个打开的文件分配一个 struct file(表示文件的结构体) 结构体对象,用于记录该文件的各种属性和状态信息。然后将这些结构体对象用双链表组织起来,将对文件结构体的操作转换为对双链表的操作。
struct file 结构体通常包括以下成员:
- struct file_operations *f_op:指向用于操作该文件的函数指针表;
- mode_t f_mode:表示该文件的访问权限;
- loff_t f_pos:表示当前读写位置的偏移量;-
- unsigned int f_flags:表示文件打开时的标志位;
- struct address_space *f_mapping:表示该文件的内存映射关系;
- struct inode *f_inode:表示该文件所关联的索引节点(inode)。
除上述成员外,struct file 结构体还包含一些其它的成员变量,如文件描述符、私有数据等。通过 struct file 结构体,内核可以对打开的文件进行管理和控制,如:读取文件内容、修改文件属性、更改文件状态等。🎯
计算机通常会运行多个进程,而每个进程都可能打开其特定的文件,那么计算机是如何识别文件分别对应哪一个进程呢?当一个进程运行时,操作系统会将该进程的代码和数据加载到内存中,然后创建对应的 task_struct、mm_struct、页表等相关的数据结构和进程信息,在 task_struct 中有一个特定的指针指向 file_struct 的结构体,用该结构体来维护进程与文件之间的关系,该结构体中包含了一个名为 struct file* fd_array[] 的结构体指针数组,进程打开的文件地址就会填入此数组中,这个指针数组中存储的下标就是所谓的文件描述符。
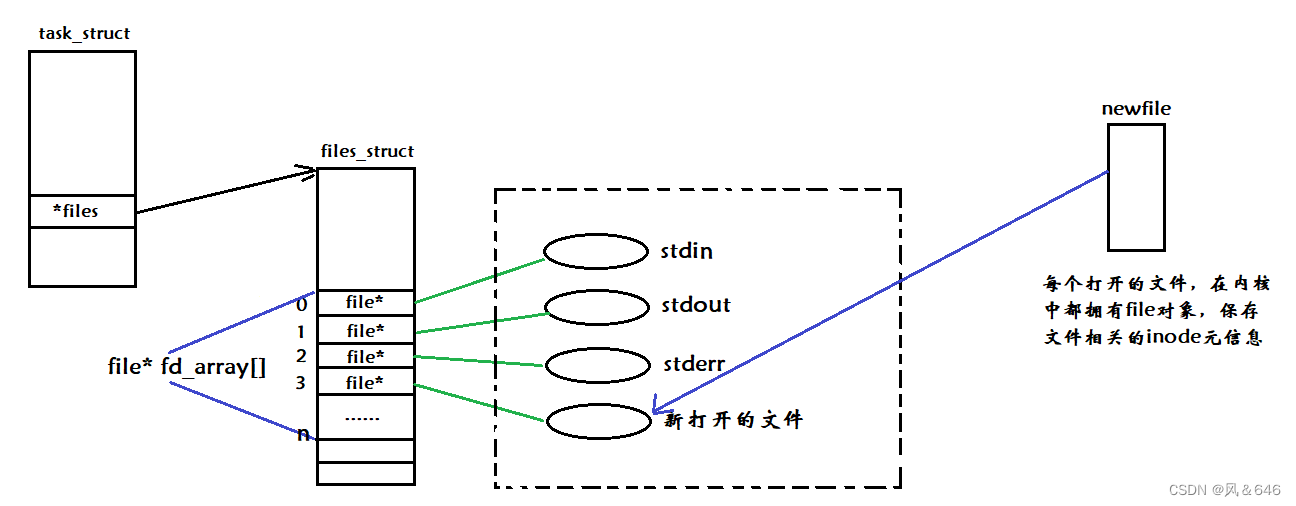
当我们需要对文件进行操作的时候,可以利用文件对应的文件描述符找到相应的文件,然后对文件进行操作。
当调用open函数时的返回值是 fd,这个 fd 就是该文件的文件描述符,如下所示:
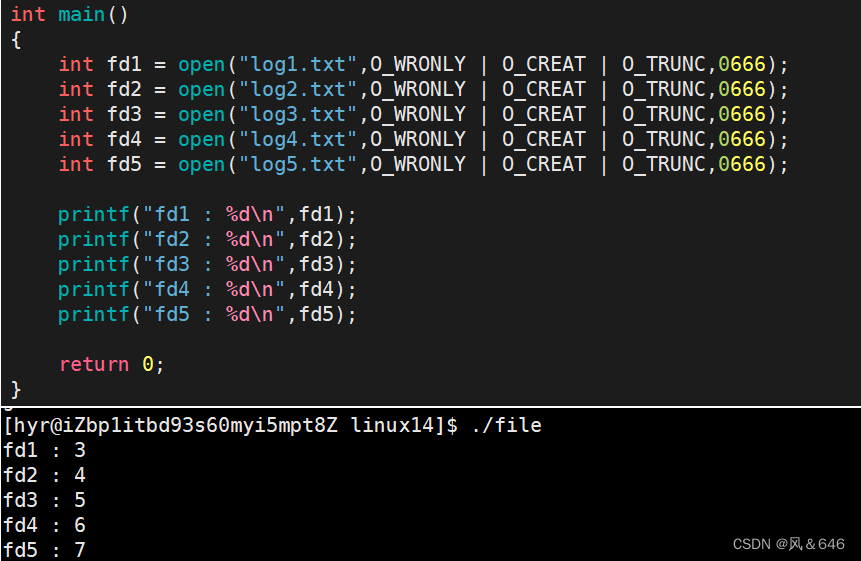
观察该程序的运行结果发现,这些已打开文件的文件描述符是一些从 3 开始的连续整数,与数组下标非常类似,但是没有 0、1、2 这三个数字。
实际上,系统运行之后,系统会默认打开三个标准输入/输出/错误流,其中 0 号文件描述符表示标准输入(stdin),1 号文件描述符表示标准输出(stdout),2 号文件描述符表示标准错误(stderr)。程序可以通过重定向来改变这些默认的行为,将它们指向其它的文件或者设备。
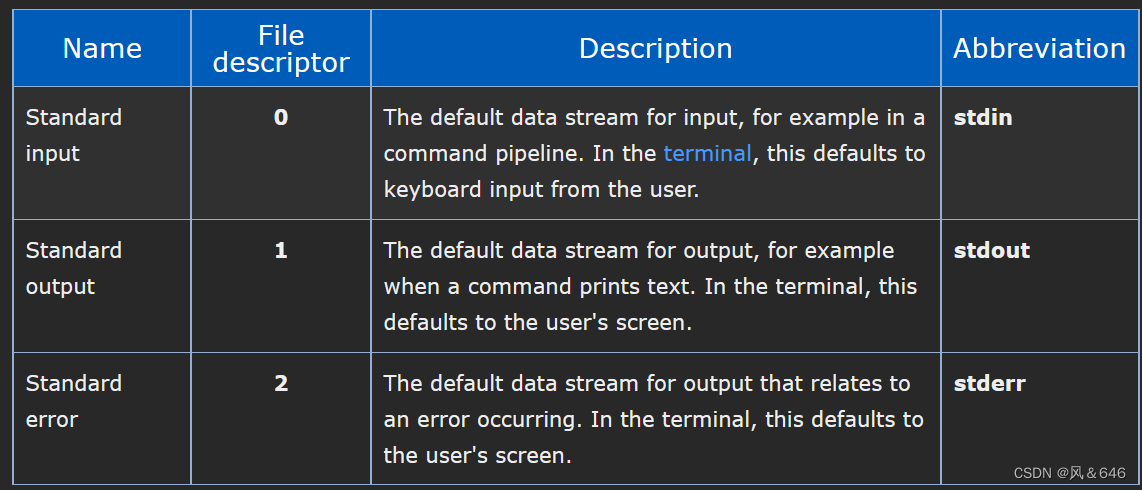
文件描述符就是从 0 开始的小整数。当我们打开文件时,操作系统在内存中要创建相应的数据结构来描述目标文件。于是就有了 file 结构体。表示一个已经打开的文件对象。而进程执行 open 系统调用,所以必须让进程和文件关联起来。每个进程都有一个指针 *files,指向一张表 file_struct,该表包含一个指针数组,每个元素都是一个指向打开文件的指针!本质上,文件描述符就是该数组的下标。因此可通过文件描述符找到对应的文件。
文件描述符的分配规则
如下所示,连续打开五个文件,查看这5个文件对应的文件描述符:
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int main()
{int fd1 = open("log1.txt",O_WRONLY | O_CREAT | O_TRUNC,0666);int fd2 = open("log2.txt",O_WRONLY | O_CREAT | O_TRUNC,0666);int fd3 = open("log3.txt",O_WRONLY | O_CREAT | O_TRUNC,0666);int fd4 = open("log4.txt",O_WRONLY | O_CREAT | O_TRUNC,0666);int fd5 = open("log5.txt",O_WRONLY | O_CREAT | O_TRUNC,0666);printf("fd1 : %d\n",fd1);printf("fd2 : %d\n",fd2);printf("fd3 : %d\n",fd3);printf("fd4 : %d\n",fd4);printf("fd5 : %d\n",fd5);return 0;
}
运行结果如下所示,文件描述符通常是从小到大顺序分配的,即先分配的文件描述符数值较小,后分配的文件描述符数值较大。因为文件描述符的本质上是数组的下标:

接下来,我们将我们描述符的 0 和 2 关闭(不要将 1 号文件描述符关闭,因为 1 号文件描述符对应的是显示器文件(stdout),若关闭 1 号文件,则程序运行的输出无法显示):
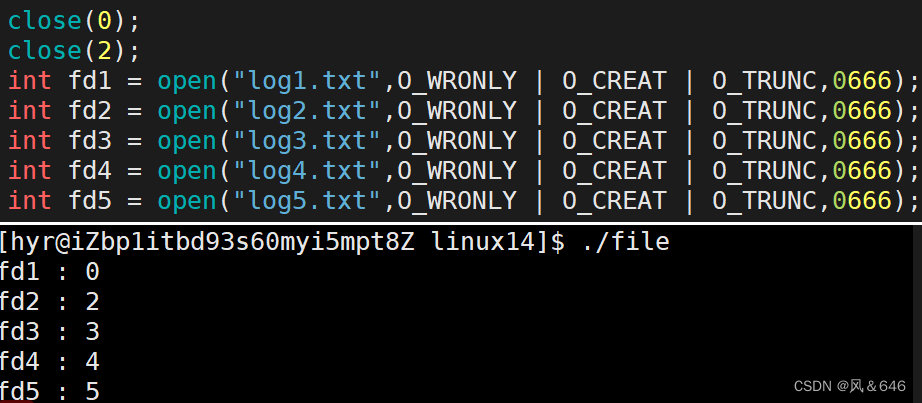
由上面两个例子可以看出,文件描述符的分配规则:在 fd_array 数组中,从 0 开始找一个没有使用过的下标分配给新打开的文件,作为该文件的文件描述符。
重定向
什么是重定向呢?接下来看一个例子,了解一下重定向的基本原理。
例:让原本输出到 “显示器文件” 的数据输出到文件 log.txt 中,因此在程序运行起来先将文件描述符为 1 号的文件关闭,然后打开 log.txt 文件,那么这个文件所分配到的文件描述符就是 1 :
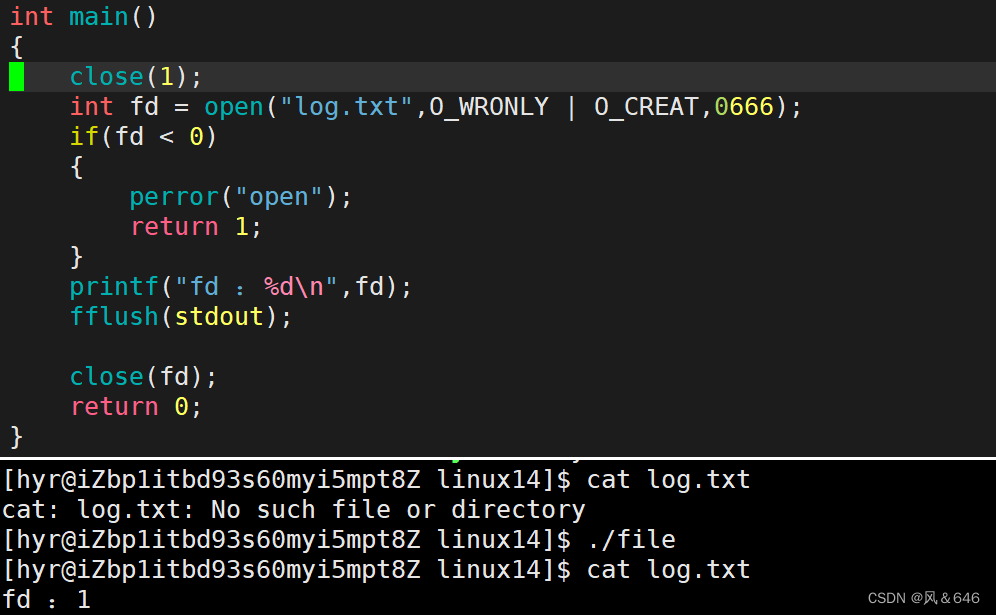
由程序运行结果发现,本应该输出到显示器的数据输出到了 log.txt 文件中。这种现象就叫做输出重定向。即这段代码的主要作用就是将程序的标准输出(stdout)关闭,并将其重定向到 “log.txt” 文件中。
输出重定向的基本原理:
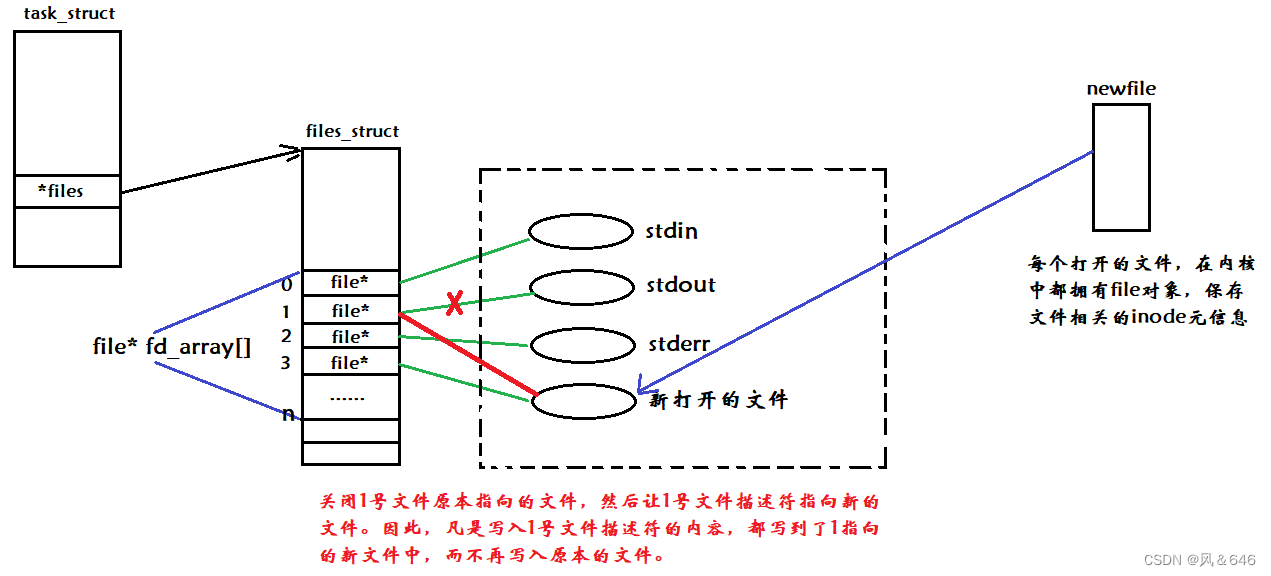
在默认情况下,程序的标准输出会被直接发送到显示器终端上。当使用 “>” 符号将其输出重定向到文件时,操作系统会创建一个新的与该文件相关联的文件描述符,并将原本与标准输出相关联的文件描述符重定向到该文件描述符上。这样程序输入的内容就写入到了指定的文件中。
在上述示意图中,可以看到程序在执行过程中并没有改变它的标准输出方式,而是将标准输出和文件描述符关联起来进行了重定向。这种方式可以让程序在不需要知道输出目标位置的情况下,将输出信息写入到不同文件中,提高了程序的灵活性和可扩展性。
注意:输入重定向和追加重定向的原理也类似,这里就不展开说了。
下面观察一个这个代码的运行结果:
#include<iostream>
#include<cstdio>
#include<errno.h>
#include<cstring>int main()
{//stdoutprintf("hello printf 1\n");fprintf(stdout,"hello fprintf 1\n");fputs("hello fputs 1\n",stdout);//stderrfprintf(stderr,"hello fprintf 2\n");fputs("hello fputs 2\n",stderr);perror("hello perror 2");//coutstd::cout<<"hello cout 1"<<std::endl;//cerrstd::cerr<<"hello cerr 2"<<std::endl;return 0;
}
运行结果如下所示;
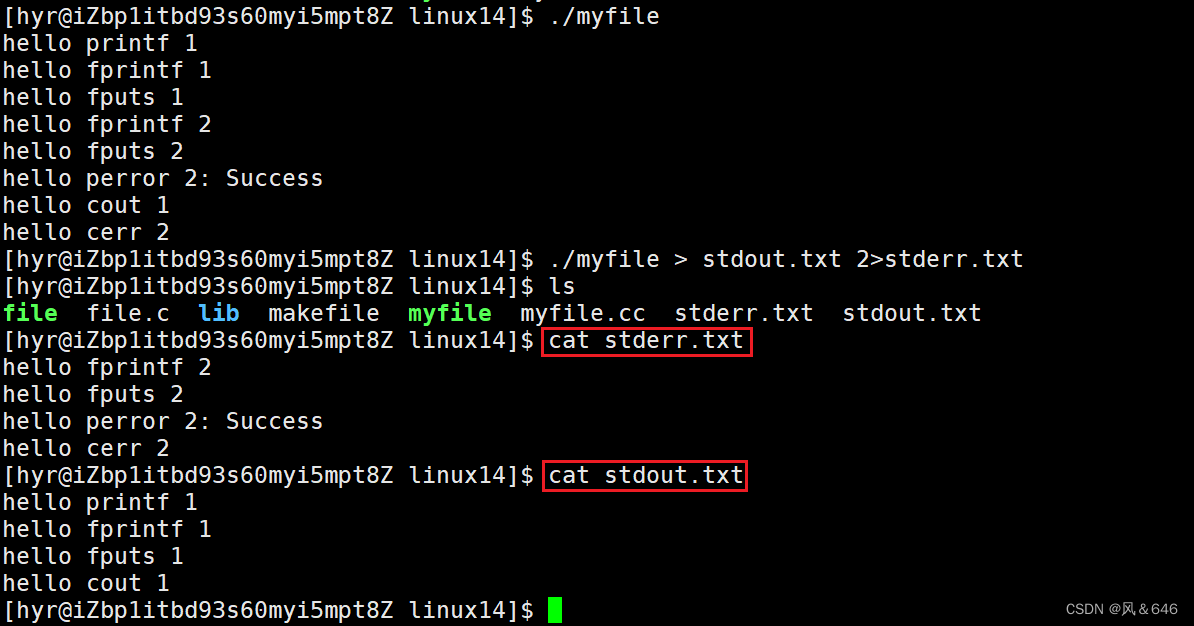
标准输出和标准错误都是向显示器输出数据,但可以将 stdout 输出的数据和 stderr 输出的数据分别重定向到对应的文件中。在终端环境下,使用 ">" 符号将标准输出重定向到文件中,使用 "2>" 符号将标准错误重定向到文件中。目的是将程序的正常输出与程序的异常输出分别放在不同的文件中,便于分析程序。
❓那么 stdout 和 stderr 的主要区别在哪里呢?为什么输出数据重定向到不同文件中?
- 标准输出(stdout)是程序向用户提供反馈信息的一种方式。一般情况下,stdout 被认为是程序的正常输出流,用于输出普通信息、结果和警告等内容。
- 标准错误(stderr)也是程序向用户提供反馈信息的一种方式。不同的是,stderr 一般被认为是程序的异常输出流,用于输出错误信息、调试信息和非正常信息。
若一个程序需要输出有用的信息给用户,那么会将这些信息写入到标准输出中,若程序出现异常的报错,那么会将这些信息写入到标准错误中。这样,用户就可以容易的分辨出哪些是正常的输出,哪些是异常的输出,从而更好的了解程序的运行情况。
dup2系统调用
dup2 是一个 unix/linux 系统调用,用于复制一份已存在的文件描述符(oldfd)到另一个文件描述符(newfd)上,这样它们就共享一个表项(file table entry)。这个新的文件描述符指向原有的文件,但是它有一个不同的文件描述符号码(file descriptor number)。使用 dup2 系统调用可以实现输入输出重定向、管道通信等功能。
✴️函数原型:
#include<unistd.h>int dup2(int oldfd,int newfd);
✴️函数返回值:
若 dup2() 调用成功,则返回 newfd ,否则返回 -1,并设置 errno 变量。
✴️说明:

dup2() 使 newfd 成为 oldfd 的一份拷贝,如有必要需首先关闭 newfd ,但是需要注意以下事项:
- 如果 oldfd 不是有效的文件描述符,则调用失败,newfd 不会关闭。
- 如果 oldfd 是一个有效的文件描述符,而 newfd 和 oldfd 具有相同的值,则 dup2() 不做任何事情,并返回 newfd。
示例:
#include<stdio.h>
#include<fcntl.h>
#include<unistd.h>int main()
{int fd = open("file.txt",O_WRONLY | O_CREAT | O_TRUNC,0644);if(fd == -1){perror("open");return 1;}int new_fd = dup2(fd,1); //拷贝到标准输出if(new_fd == -1){perror("dup2");return 1;}printf("This is redirected to file.txt!\n"); //输出到文件中close(fd);return 0;
}
运行结果如下所示:

FILE
FILE中的文件描述符
因为 IO 相关函数与系统调用接口对应,并且库函数封装系统调用,所以本质上,访问文件都是通过 fd 访问的。因此 C 库当中的 FILE 结构体内部,必定封装了 fd。
在 /usr/include/stdio.h 头文件中可以看到 FILE 结构体,FILE 结构体是 struct _IO_FILE 结构体的一个引用:

struct _IO_FILE 是C语言标准 I/O 库中用于描述文件流的结构体。其中包含了一些与文件操作相关的信息,如:文件指针、缓冲区、状态位等。struct _IO_FILE 通常被实现为一个指向缓冲区的指针,其中缓冲区可以是输入缓冲区和输出缓冲区,也可以是二者兼备。其常见的成员变量及解释如下:
- _flags:文件流的状态标志,包括打开/关闭、读/写、是否出错、是否需要缓冲等信息。
- _IO_buf_base 和 _IO_buf_end:指向输入/输出缓冲区的起始地址和结束地址。
- _fileno:文件描述符(file descriptor),用于操作系统级别的文件接口。
- _IO_read_ptr 和 _IO_read_end:指向输入缓冲区中已读数据和剩余未读数据的指针。
- _IO_write_ptr 和 _IO_write_end:指向输出缓冲区中已写数据和剩余可写空间的指针。
- _IO_save_base 和 _IO_backup_base:用于缓存当前位置的指针,在遇到错误时可以回滚到之前的位置。
- _IO_lock 和 _lockcount:用于多线程环境下的同步锁。
注意:struct _IO_FILE 是标准库内部的实现细节,不同的编译器可能会有所不同,因此不要直接访问该结构体的成员变量。我们应该使用标准库提供的函数(fopen、fclose、fread、fwrite等)来对文件进行操作。
❓在C语言中使用 fopen 函数时,究竟发生了什么?
当在C语言中使用标准 I/O 库函数 fopen 打开一个文件时,该函数会返回一个指向 FILE 类型的指针。这个指针实际上是一个 FILE 结构体变量的地址,在底层通过系统接口 fopen 打开对应的文件,该文件被分配一个文件描述符(fd),然后将 fd 填到 FILE 结构体中的 _fileno 变量中,然后完成文件的打开操作。
FILE中的缓冲区理解
首先来看看以下代码及其运行结果,然后来理解缓冲区。
#include <stdio.h>
#include <unistd.h>int main()
{const char *str1 = "hello printf\n";const char *str2 = "hello fprintf\n";const char *str3 = "hello fputs\n";const char *str4 = "hello write\n";//c库函数printf(str1);fprintf(stdout,str2);fputs(str3,stdout);//系统接口write(1,str4,strlen(str4));//调用完上面,指执行forkfork(); return 0;
}
运行程序时,每一个函数对应的结果都输出在了显示器上。但是,当将程序执行的结果重定向到 file.txt 文件中时,结果发生了变化,如下所示:
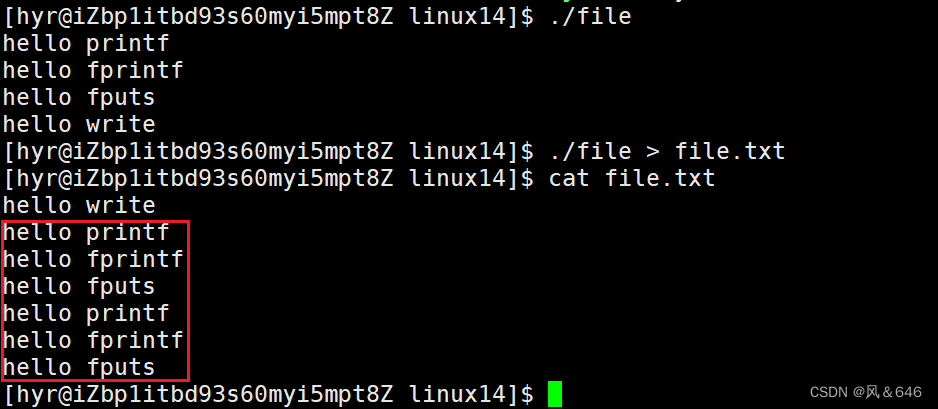
在 file.txt 文件中,C库函数打印的内容重定向到文件变为了两份,而系统接口 write 输出的内容重定向到文件中也只有一份。这是为什么呢?这里猜测可能与 fork 有关!
分析:在程序执行时,每一个字符串后面都带有 ‘\n’,因此数据打印到显示器所采用的是行缓冲的方式。因此,当执行程序时,数据被立即刷新到了显示器上。将运行结果重定向到普通文件时,数据的缓冲方式由行缓冲变成了全缓冲。此时 fprintf、fputs、printf 函数打印的数据都先存储在了缓冲区中,fork 之后,父子数据会发生写时拷贝,所以当父进程数据准备刷新时,子进程也就有了同样的一份数据,因此重定向到 file.txt 文件时,fprintf、fputs、printf 函数输出的数据就有了两份。而 write 是系统调用,库函数在系统调用的 “上层” ,是对系统调用的 “封装” ,但是 write 没有缓冲区,因此 write 调用打印的数据只有一份。
什么是缓冲区❓
缓冲区是内存空间的一部分。也就是说,在内存中预留了一定的存储空间,这些存储空间用缓冲输入或输出数据,这部分预留的空间叫做缓冲区。缓冲区根据其对应的是输入设备还是输出设备,分为输入缓冲区和输出缓冲区。
有几种类型的缓冲区❓
缓冲区分为三种类型:全缓冲、行缓冲和不带缓冲。
全缓冲:当填满标准 I/O 缓冲后才进行实际 I/O 操作。全缓冲的典型代表是对磁盘文件的读写。
行缓冲:当在输入和输出中遇到换行符时,执行真正的 I/O 操作。这时,输入的字符先存放在缓冲区,等按下回车键换行时才进行真正的 I/O 操作。典型代表是键盘输入数据。
不带缓冲:不进行缓冲,标准出错情况 stderr 是典型代表,让输出的数据立即显示出来。
为什么要有缓冲区❓
- 缓和 CPU 与 I/O 设备将速度不匹配的矛盾
- 减少中断 CPU 的频率,放宽对 CPU 中断响应时间的限制。
- 集中处理数据刷新,减少 I/O 次数,从而达到提高整机效率的目的。
- 提高 CPU 和 I/O 设备之间的并行性。
这个缓冲区在哪里❓
由以上代码及运行结果知,write 系统调用接口是立即刷新的,而C库函数是最后程序退出时刷新的。由此可知,缓冲区不在系统内部,而C 库函数输出的数据存放到了缓冲区。说明:缓冲区是由C语言提供的,在 FILE 结构体当中进行维护,FILE 结构体中保存了程序缓冲区的相关信息。
相关文章:
基础IO【Linux】
文章目录:文件相关知识C语言文件IOstdin & stdout & stderr系统文件 IOopenclosewriteread文件描述符文件描述符的分配规则重定向dup2系统调用FILEFILE中的文件描述符FILE中的缓冲区理解文件相关知识 文件 文件内容 文件属性(每一个已经存在的…...
Vue3——自定义封装上传图片样式
自定义封装上传图片样式 一、首先需要新建一个自组建完善基础的结构,我这里起名为ImgUpload.vue <el-upload name"file" :show-file-list"false" accept".png,.PNG,.jpg,.JPG,.jpeg,.JPEG,.gif,.GIF,.bmp,.BMP" :multiple"…...
ChatGLM-6B (介绍以及本地部署)
中文ChatGPT平替——ChatGLM-6BChatGLM-6B简介官方实例本地部署1.下载代码2.通过conda创建虚拟环境3.修改代码4.模型量化5.详细代码调用示例ChatGLM-6B 简介 ChatGLM-6B 是一个开源的、支持中英双语问答的对话语言模型,基于 General Language Model (GLM) 架构&…...
react的基础使用
react中为什么使用jsxReact 认为渲染逻辑本质上与其他 UI 逻辑内在耦合,比如,在 UI 中需要绑定处理事件、在某些时刻状态发生变化时需要通知到 UI,以及需要在 UI 中展示准备好的数据。react认为将业务代码和数据以及事件等等 需要和UI高度耦合…...

letcode 4.寻找两个正序数组的中位数(官方题解笔记)
题目描述 给定两个大小分别为 m 和 n 的正序(从小到大)数组 nums1 和 nums2。请你找出并返回这两个正序数组的 中位数 。 算法的时间复杂度应该为 O(log (mn)) 。 1.二分查找 1.1思路 时间复杂度:O(log(mn)) 空间复杂度:O(1) 给定…...
【面试题系列】K8S常见面试题
目录 序言 问题 1. 简单说一下k8s集群内外网络如何互通的吧 2.描述一下pod的创建过程 3. 描述一下k8s pod的终止过程 4.Kubernetes 中的自动伸缩有哪些方式? 5.Kubernetes 中的故障检测有哪些方式? 6.Kubernetes 中的资源调度有哪些方式ÿ…...

字符函数和字符串函数(上)-C语言详解
CSDN的各位友友们你们好,今天千泽为大家带来的是C语言中字符函数和字符串函数的详解,掌握了这些内容能够让我们更加灵活的运用字符串,接下来让我们一起走进今天的内容吧!写这篇文章需要在cplusplus.com上大量截图,十分不易!如果对您有帮助的话希望能够得到您的支持和帮助,我会持…...
全连接神经网络
目录 1.全连接神经网络简介 2.MLP分类模型 2.1 数据准备与探索 2.2 搭建网络并可视化 2.3 使用未预处理的数据训练模型 2.4 使用预处理后的数据进行模型训练 3. MLP回归模型 3.1 数据准备 3.2 搭建回归预测网络 1.全连接神经网络简介 全连接神经网络(Multi-Layer Percep…...
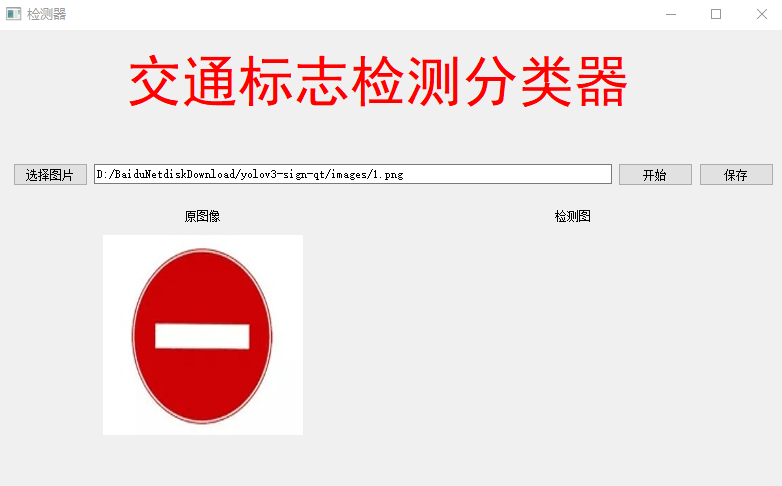
深度学习目标检测ui界面-交通标志检测识别
深度学习目标检测ui界面-交通标志检测识别 为了将算法封装起来,博主尝试了实验pyqt5的上位机界面进行封装,其中遇到了一些坑举给大家避开。这里加载的训练模型参考之前写的博客: 自动驾驶目标检测项目实战(一)—基于深度学习框架yolov的交通…...

ubuntu不同版本的源(换源)(镜像源)(lsb_release -c命令,显示当前系统的发行版代号(Codename))
文章目录查看unbuntu版本名(lsb_release -c命令)各个版本源代号(仅供参考,具体代号用上面命令查)各版本软件源Ubuntu20.10阿里源:清华源:Ubuntu20.04阿里源:清华源:Ubunt…...

linux入门---程序翻译的过程
我们在vs编译器中写的代码按下ctrl f5就可以直接运行起来,并且会将运行的结果显示到显示器上,这里看上去只有一个步骤但实际上这里会存在很多的细节,比如说生成结果在这里插入代码片之前我们的代码会经过预处理,编译,汇…...
springboot复习(黑马)
学习目标基于SpringBoot框架的程序开发步骤熟练使用SpringBoot配置信息修改服务器配置基于SpringBoot的完成SSM整合项目开发一、SpringBoot简介1. 入门案例问题导入SpringMVC的HelloWord程序大家还记得吗?SpringBoot是由Pivotal团队提供的全新框架,其设计…...

C++指针详解
旧文更新:两三年的旧文了,一直放在电脑里,现在直接传上CSDN 一、指针的概念 1.1 指针 程序运行时每个变量都会有一块内存空间,变量的值就存放在这块空间中。程序可以通过变量名直接访问这块空间内的数据,这种访问方…...
tauri+vite+vue3开发环境下创建、启动运行和打包发布
目录 1.创建项目 2.安装依赖 3.启动项目 4.打包生成windows安装包 5.安装打包生成的安装包 1.创建项目 运行下面命令创建一个tauri项目 pnpm create tauri-app 我创建该项目时的node版本为16.15.0 兼容性注意 Vite 需要 Node.js 版本 14.18,16。然而&#x…...

安卓进阶系列-系统基础
文章目录计算机结构冯诺依曼结构哈弗结构冯诺依曼结构与哈弗结构对比安卓采用的架构安卓操作系统进程间通讯(IPC)内存共享linux内存共享安卓内存共享管道Unix Domain Socket同步常见同步机制信号量Mutex管程安卓同步机制安卓中的Mutex安卓中的ConditionB…...
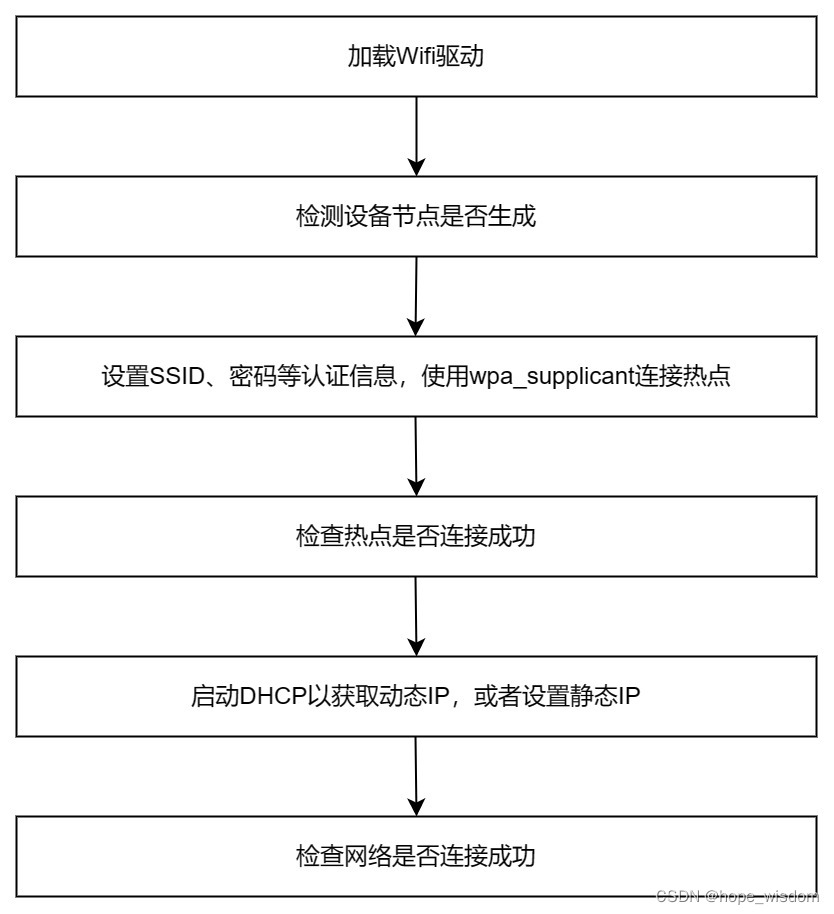
10 Wifi网络的封装
概述 Wifi有多种工作模式,比如:STA模式、AccessPoint模式、Monitor模式、Ad-hoc模式、Mesh模式等。但在IPC设备上,主要使用STA和AccessPoint这两种模式。下面分别进行介绍。 STA模式:任何一种无线网卡都可以运行在此模式,这种模式也是无线网卡的默认模式。在此模式下,无线…...
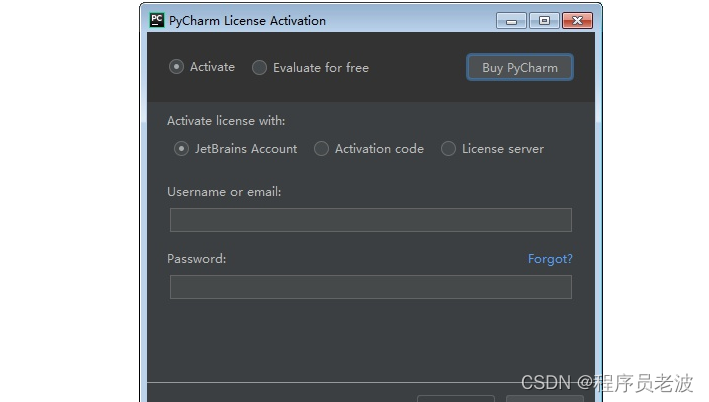
手把手的教你安装PyCharm --Pycharm安装详细教程(一)(非常详细,非常实用)
简介 Jetbrains家族和Pycharm版本划分: pycharm是Jetbrains家族中的一个明星产品,Jetbrains开发了许多好用的编辑器,包括Java编辑器(IntelliJ IDEA)、JavaScript编辑器(WebStorm)、PHP编辑器&…...

开发板与ubantu文件传送
接下来的所以实验都通过下面这种方式发送APP文件到开发板运行 目录 1、在ubantu配置 ①在虚拟机上添加一个桥接模式的虚拟网卡 ②设定网卡 ③在网卡上配置静态地址 2、开发板设置 ①查看网卡 ②配置网卡静态ip 3、 测试 ①ping ②文件传送 传送报错情况 配置环境&#…...
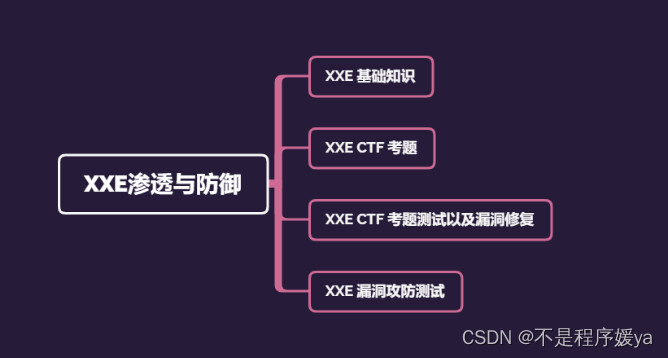
如何成为一名优秀的网络安全工程师?
前言 这是我的建议如何成为网络安全工程师,你应该按照下面顺序学习。 简要说明 第一件事你应该学习如何编程,我建议首先学python,然后是java。 (非必须)接下来学习一些算法和数据结构是很有帮助的,它将…...

面试问题之高并发内存池项目
项目部分 1.这个项目是什么? 高并发内存池的原型是谷歌一个开源项目,tcmalloc,而这个项目,就是tcmalloc中最核心的框架和部分拿出来进行模拟。他的作用就是在去代替原型的内存分配函数malloc和free。这个项目涉及的技术有,c&…...

使用VSCode开发Django指南
使用VSCode开发Django指南 一、概述 Django 是一个高级 Python 框架,专为快速、安全和可扩展的 Web 开发而设计。Django 包含对 URL 路由、页面模板和数据处理的丰富支持。 本文将创建一个简单的 Django 应用,其中包含三个使用通用基本模板的页面。在此…...

Spark 之 入门讲解详细版(1)
1、简介 1.1 Spark简介 Spark是加州大学伯克利分校AMP实验室(Algorithms, Machines, and People Lab)开发通用内存并行计算框架。Spark在2013年6月进入Apache成为孵化项目,8个月后成为Apache顶级项目,速度之快足见过人之处&…...

MySQL 隔离级别:脏读、幻读及不可重复读的原理与示例
一、MySQL 隔离级别 MySQL 提供了四种隔离级别,用于控制事务之间的并发访问以及数据的可见性,不同隔离级别对脏读、幻读、不可重复读这几种并发数据问题有着不同的处理方式,具体如下: 隔离级别脏读不可重复读幻读性能特点及锁机制读未提交(READ UNCOMMITTED)允许出现允许…...

智慧工地云平台源码,基于微服务架构+Java+Spring Cloud +UniApp +MySql
智慧工地管理云平台系统,智慧工地全套源码,java版智慧工地源码,支持PC端、大屏端、移动端。 智慧工地聚焦建筑行业的市场需求,提供“平台网络终端”的整体解决方案,提供劳务管理、视频管理、智能监测、绿色施工、安全管…...

【Linux】C语言执行shell指令
在C语言中执行Shell指令 在C语言中,有几种方法可以执行Shell指令: 1. 使用system()函数 这是最简单的方法,包含在stdlib.h头文件中: #include <stdlib.h>int main() {system("ls -l"); // 执行ls -l命令retu…...

解决Ubuntu22.04 VMware失败的问题 ubuntu入门之二十八
现象1 打开VMware失败 Ubuntu升级之后打开VMware上报需要安装vmmon和vmnet,点击确认后如下提示 最终上报fail 解决方法 内核升级导致,需要在新内核下重新下载编译安装 查看版本 $ vmware -v VMware Workstation 17.5.1 build-23298084$ lsb_release…...

【快手拥抱开源】通过快手团队开源的 KwaiCoder-AutoThink-preview 解锁大语言模型的潜力
引言: 在人工智能快速发展的浪潮中,快手Kwaipilot团队推出的 KwaiCoder-AutoThink-preview 具有里程碑意义——这是首个公开的AutoThink大语言模型(LLM)。该模型代表着该领域的重大突破,通过独特方式融合思考与非思考…...

工程地质软件市场:发展现状、趋势与策略建议
一、引言 在工程建设领域,准确把握地质条件是确保项目顺利推进和安全运营的关键。工程地质软件作为处理、分析、模拟和展示工程地质数据的重要工具,正发挥着日益重要的作用。它凭借强大的数据处理能力、三维建模功能、空间分析工具和可视化展示手段&…...
:滤镜命令)
ffmpeg(四):滤镜命令
FFmpeg 的滤镜命令是用于音视频处理中的强大工具,可以完成剪裁、缩放、加水印、调色、合成、旋转、模糊、叠加字幕等复杂的操作。其核心语法格式一般如下: ffmpeg -i input.mp4 -vf "滤镜参数" output.mp4或者带音频滤镜: ffmpeg…...

2025盘古石杯决赛【手机取证】
前言 第三届盘古石杯国际电子数据取证大赛决赛 最后一题没有解出来,实在找不到,希望有大佬教一下我。 还有就会议时间,我感觉不是图片时间,因为在电脑看到是其他时间用老会议系统开的会。 手机取证 1、分析鸿蒙手机检材&#x…...