Python——Pandas(第三讲)
文章目录
- 修改替换变量值
- 对应数值的替换
- 指定数值范围的替换
- 虚拟变量变换
- 数值变量分段
- 数据分组
- 基于拆分进行筛选
- 分组汇总
- 使用 agg 函数进行汇总
- 引用自定义函数
- 长宽格式转换
- 转换为最简格式
- 长宽型格式的自由互转
- 多个数据源的合并
- 数据的横向合并
- concat 命令
- 处理缺失值
- 认识缺失值
- 缺失值查看
- 填充缺失值
- 删除缺失值
- 数据查重
- 标识出重复的行
- 直接删除重复的行
修改替换变量值
本质上是如何直接指定单元格的问题,只要能准确定位单元地址,就能够做到准确替换。
# 判断哪一行是我们要的数据 先定位再给值
df.体重[1] = 78
df['体重'][1] = 68
df.loc[1,
'体重'] = 78
df.开设.isin(['不清楚'])
df.开设[df.开设.isin(['不清楚'])] = '可以'
对应数值的替换
df.replace(
to_replace = None :将被替换的原数值,所有严格匹配的数值
将被用 value 替换,可以是 str/regex/list/dict/Series/numeric/None
value = None :希望填充的新数值
inplace = False
)
df.开设.replace('可以','不清楚',inplace = True)
df.性别.replace(['女','男'],[0,1],inplace =True)
df.性别.replace({0:'女',1:'男'},inplace =True)
指定数值范围的替换
方法一:使用正则表达式完成替换
df.replace(regex, newvalue)
方法二:使用行筛选方式完成替换
用行筛选方式得到行索引,然后用 loc 命令定位替换目前也支持直接筛选出单元格进行数值替换
# 使用正则匹配数据
df.开设.replace(regex = '不.+',value = '可以',inplace = True)
#iloc loc
df.支出.iloc[0:3] = 20
df.支出.loc[0:2] =30
#条件筛选替换
df.体重[df.体重>70] =70
df[df.体重==70].体重 = 80 # 注意引用问题
#query()的使用
df.query('性别 == "女" and 体重 > 60 ').体重 =50
df.loc[df.query('性别 == "女" and 体重 > 60').体重.index,'体重'] = 50
虚拟变量变换
pd.get_dummies(
data :希望转换的数据框/变量列
prefix = None :哑变量名称前缀
prefix_sep = 11 :前缀和序号之间的连接字符,设定有prefix 或列名时生效
dummy_na = False :是否为 NaNs 专门设定一个哑变量列
columns = None :希望转换的原始列名,如果不设定,则转换所有符合条件的列
drop_first = False :是否返回 k-l 个哑变量,而不是 k 个哑变量
)
返回值为数据框
df2.head()
pd.get_dummies(df2.类型,prefix = '_' )
pd.get_dummies(df2 , columns= [ '类型' ])
数值变量分段
pd.cut(
X :希望逬行分段的变量列名称
bins :具体的分段设定
int :被等距等分的段数
sequence of scalars :具体的每一个分段起点,必须包括最值,可不等距
right = True :每段是否包括右侧界值
labels = None :为每个分段提供自定义标签
include_lowest = False :第一段是否包括最左侧界值,需要和right 参数配合
)
- 分段结果是数值类型为 Categories 的序列
- pd.qcut ——按均值取值范围进行等分
#按均值取值范围进行等分
df['cut1'] = pd.qcut(df.身高,q=5)
#自定义分段
df['cut2'] = pd.cut(df.身高,bins=[150,160,170,180,190],right=False)
数据分组
df.groupby(
by :用于分组的变量名/函数
level = None :相应的轴存在多重索引时,指定用于分组的级别
as_index = True :在结果中将组标签作为索引
sort = True :结果是否按照分组关键字逬行排序
)
- 生成的是分组索引标记,而不是新的 df
dfg = df.groupby ('开设')
#查看dfg里面的数据
dfg.groups
#查看具体描述
dfg.describe( )
#按多列分组
dfg2 = df.groupby(['性别','开设'])
dfg2.mean ()
基于拆分进行筛选
筛选出其中一组
dfgroup.get_group()
dfg.get_group ('不必要').mean ()
dfg.get_group ('不必要').std ()
筛选出所需的列
该操作也适用于希望对不同的变量列进行不同操作时
dfg['身高'].max()
分组汇总
在使用 groupby 完成数据分组后,就可以按照需求进行分组信息汇总,此时可以使用其它专门的汇总命令,如 agg 来完成汇总操作。
使用 agg 函数进行汇总
df.aggregate( )
- 名称可以直接简写为 agg
- 可以用 axis 指定汇总维度
可以直接使用的汇总函数
| 名称 | 含义 |
|---|---|
| count () | Nuniber of non-null observations size () group sizes |
| sum() | Sum of values29 |
| mean() | Mean of values |
| median() | Arithmetic median of values |
| min () | Minimum |
| max() | Maximum |
| std() | Unbiased standard deviation |
| var () | Unbiased variance |
| skew() | Unbiased skewness(3rd moment) |
| kurt() | Unbiased kurtosis (4th moment) |
| quantile () | Sample quantile (value at %) apply() Generic apply |
| cov() | Unbiased covariance (binary) |
| corr() | Correlation (binary) |
dfg.agg( 'count')
dfg.agg('median')
dfg.agg(['mean', 'median'])
dfg.agg(['mean', 'median'])
#引用非内置函数
import numpy as np
df2.身高.agg (np. sum)
dfg.身高.agg (np. sum)
引用自定义函数
# 使用自定义函数
def mynum(x:int) ->int:return x.min()
df2.身高.agg (mymean)
dfg.agg(mymean)
长宽格式转换
基于多重索引,Pandas 可以很容易地完成长型、宽型数据格式的相互转换。
转换为最简格式
df.stack(
level = -1 :需要处理的索引级别,默认为全部,int/string/list
dropna = True :是否删除为缺失值的行
)
- 转换后的结果可能为 Series
用法:
df =pd.read_excel('person.xlsx')
dfs = df.stack()
长宽型格式的自由互转
df.unstack(
level = -1 :需要处理的索引级别,默认为全部,int/string/list
fill_value :用于填充缺失值的数值
)
dfs.unstack (1)
dfs.unstack([0,1])
数据转置: df.T
多个数据源的合并
数据的横向合并
merge 命令使用像 SQL 的连接方式
pd.merge(
需要合并的 DF
left :需要合并的左侧 DF
right :需要合并的右侧 DF
how = ’ inner’:具体的连接类型
{left、right 、outer 、 inner、)
两个 DF 的连接方式
on :用于连接两个 DF 的关键变量(多个时为列表),必须在两侧都出现
left_on :左侧 DF 用于连接的关键变量(多个时为列表)
right_on :右侧 DF 用于连接的关键变量(多个时为列表)
left_index = False :是否将左侧 DF 的索引用于连接
right_index = False :是否将右侧 DF 的索引用于连接
)
left=pd.DataFrame({'key':['k0','k1','k2','k3'],'A':['A0','A1','A2','A3'],'B':['B0','B1','B2','B3'],})
right=pd.DataFrame({'key':['k0','k1','k2','k4'],'C':['C0','C1','C2','C3'],'D':['D0','D1','D2','D3'],})
left
'''key A B
0 k0 A0 B0
1 k1 A1 B1
2 k2 A2 B2
3 k3 A3 B3
'''
right
'''key C D
0 k0 C0 D0
1 k1 C1 D1
2 k2 C2 D2
3 k4 C3 D3
'''
# inner left right
# 内连接 只保留相同key的值
# 外连接 left 以左边的df为基准 保留所有的左边的所有同列名的值
# 全连接 outer 全连接
pd.merge(left,right,how='inner')
'''key A B C D
0 k0 A0 B0 C0 D0
1 k1 A1 B1 C1 D1
2 k2 A2 B2 C2 D2
'''
pd.merge(left,right,how='left')
'''key A B C D
0 k0 A0 B0 C0 D0
1 k1 A1 B1 C1 D1
2 k2 A2 B2 C2 D2
3 k3 A3 B3 NaN NaN
'''
pd.merge(left,right,how='right')
'''key A B C D
0 k0 A0 B0 C0 D0
1 k1 A1 B1 C1 D1
2 k2 A2 B2 C2 D2
3 k4 NaN NaN C3 D3
'''
pd.merge(left,right,how='outer')
'''key A B C D
0 k0 A0 B0 C0 D0
1 k1 A1 B1 C1 D1
2 k2 A2 B2 C2 D2
3 k3 A3 B3 NaN NaN
4 k4 NaN NaN C3 D3
'''
concat 命令
同时支持横向合并与纵向合并
pd.concat(
objs :需要合并的对象,列表形式提供
axis = 0 :对行还是对列方向逬行合并(0 index 、 1 columns )
join = outer :对另一个轴向的索引值如何进行处理(inner 、outer )
ignore_index = False
keys = None :为不同数据源的提供合并后的索引值
verify_integrity = False : 是否检查索引值的唯一性,有重复时报错
copy = True
)
【示例】一维的Series拼接
ser1=pd.Series([1,2,3],index=list('ABC'))
ser2=pd.Series([4,5,6],index=list('DEF'))
pd.concat([ser1,ser2])
'''
A 1
B 2
C 3
D 4
E 5
F 6
dtype: int64
'''
【示例】df对象拼接
def make_df(cols,index):data={c:[str(c)+str(i) for i in index] for c in cols}return pd.DataFrame(data,index=index)
df1=make_df('AB',[1,2])
df2=make_df('AB',[3,4])
df1
'''A B
1 A1 B1
2 A2 B2
'''
df2
'''A B
3 A3 B3
4 A4 B4
'''
pd.concat([df1,df2])
'''A B
1 A1 B1
2 A2 B2
3 A3 B3
4 A4 B4
'''
【示例】两个df对象拼接,如果索引重复
x=make_df('AB',[1,2])
y=make_df('AB',[1,2])
x
'''A B
1 A1 B1
2 A2 B2
'''
y
'''A B
1 A1 B1
2 A2 B2
'''
pd.concat([x,y])
'''A B
1 A1 B1
2 A2 B2
1 A1 B1
2 A2 B2
'''
pd.concat([x,y],ignore_index=True)
'''A B
0 A1 B1
1 A2 B2
2 A1 B1
3 A2 B2
'''
pd.concat([x,y],keys=list('xy'))
'''A B
x 1 A1 B12 A2 B2
y 1 A1 B12 A2 B2
'''
【示例】两个df对象拼接,join参数的使用
a=make_df('ABC',[1,2,3,4])
b=make_df('BCD',[3,4,5])
a
'''A B C
1 A1 B1 C1
2 A2 B2 C2
3 A3 B3 C3
4 A4 B4 C4
'''
b
'''B C D
3 B3 C3 D3
4 B4 C4 D4
5 B5 C5 D5
'''
pd.concat([a,b],join='outer',axis=1)
'''A B C B C D
1 A1 B1 C1 NaN NaN NaN
2 A2 B2 C2 NaN NaN NaN
3 A3 B3 C3 B3 C3 D3
4 A4 B4 C4 B4 C4 D4
5 NaN NaN NaN B5 C5 D5
'''
a=make_df('ABC',[1,2])
b=make_df('BCD',[3,4])
pd.concat([a,b],join='inner')
'''B C
1 B1 C1
2 B2 C2
3 B3 C3
4 B4 C4
'''
处理缺失值

认识缺失值
系统默认的缺失值 None 和 np. nan
data=pd.Series([3,4,np.nan,1,5,None])
df=pd.DataFrame([[1,2,None],[4,np.nan,6],[5,6,7]])
'''0 1 2
0 1 2.0 NaN
1 4 NaN 6.0
2 5 6.0 7.0
'''
缺失值查看
直接调用info()方法就会返回每一列的缺失情况。
df.info()
'''
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 3 entries, 0 to 2
Data columns (total 3 columns):# Column Non-Null Count Dtype
--- ------ -------------- ----- 0 0 3 non-null int64 1 1 2 non-null float642 2 2 non-null float64
dtypes: float64(2), int64(1)
memory usage: 200.0 bytes
'''
Pandas中缺失值用NaN表示,从用info()方法的结果来看,索引1这一列是1 2 non-null float64,表示这一列有2个非空值,而应该是3个非空值,说明这一列有1个空值。
还可以用isnull()方法来判断哪个值是缺失值,如果是缺失值则返回True,如果不是缺失值返回False。
- df.isna(): 检查相应的数据是否为缺失值 同 df.isnull()。
- df.notna()等同于notnull()
【示例】获取所有缺失值
data=pd.Series([3,4,np.nan,1,5,None])
print('isnull()方法判断是否是缺值:')
print(data.isnull())
print(data.isna())
print('获取缺值:')
print(data[data.isnull()])
print('获取非空值')
print(data[data.notnull()])
填充缺失值
调用fillna()方法对数据表中的所有缺失值进行填充,在fillna()方法
中输入要填充的值。还可以通过method参数使用前一个数和后一
个数来进行填充。
df.fillna(
value :用于填充缺失值的数值,也可以提供dict/Series/DataFrame 以进—步指明
哪些索引/列会被替换 不能使用 list
method = None :有索引时具体的填充方法,向前填充,向后填充等
limit = None :指定了 method 后设定具体的最大填充步长,此步长不能填充
axis : index (0), columns (1)
inplace = False
)
【示例】Series对象缺失值填充
data=pd.Series([3,4,np.nan,1,5,None])
print('以0进行填充:')
print(data.fillna(0))
print('以前一个数进行填充:')
print(data.fillna(method='ffill'))
print('以后一个数进行填充:')
print(data.fillna(method='bfill'))
print('先按前一个,再按后一个')
print(data.fillna(method='bfill').fillna(method='ffill'))
【示例】DataFrame对象缺失值填充
df=pd.DataFrame([[1,2,np.nan],[4,np.nan,6],
[5,6,7]])
print('使用数值0来填充:')
print(df.fillna(0))
print('使用行的前一个数来填充:')
print(df.fillna(method='ffill'))
print('使用列的后一个数来填充:')
print(df.fillna(method='bfill' ,axis=1))
【示例】列的平均值来填充
df=pd.DataFrame([[1,2,np.nan],[4,np.nan,6],
[5,6,7]])
for i in df.columns:df[i]=df[i].fillna(np.nanmean(df[i]))
df
删除缺失值
调用dropna()方法删除缺失值,dropna()方法默认删除含有缺失值的行,也就是只要某一行有缺失值就把这一行删除。如果想按列为单位删除缺失值,需要传入参数axis=’columns’。
df.dropna(
axis = 0 : index (0), columns (1)
how = any : any、all
any :任何一个为 NA 就删除
all :所有的都是 NA 删除
thresh = None :删除的数量阈值,int
subset :希望在处理中包括的行/列子集
inplace = False
)
【示例】删除缺失值
df=pd.DataFrame([[1,2,np.nan],[4,np.nan,6],[5,6,7]])
print('默认为以行为单位剔除:')
print(df.dropna())
print('以列为单位剔除:')
df.dropna(axis='columns')
【示例】删除空白行
df=pd.DataFrame([[1,2,np.nan],[4,np.nan,6],[5,6,7]])
print('所有为nan时候才剔除:')
print(df.dropna(how='all'))
print('默认情况,只要有就剔除')
print(df.dropna(how='any'))
数据查重
标识出重复的行
标识出重复行的意义在于进一步检査重复原因,以便将可能的错误数据加以修改。
Duplicated
df['dup' ] = df.duplicated( ['课程','开设'])
利用索引进行重复行标识
df.index.duplicated()
df2 = df.set_index ( ['课程','开设'] )
df2.index.duplicated ()
直接删除重复的行
drop_duplicates (
subset=“ ”按照指定的行逬行去重
keep=‘first’ 、 ‘last’ 、 False 是否直接删除有重复的所有记录
)
df. drop_duplicates ( ['课程', '开设' ] )
df. drop_duplicates ( ['课程', '开设' ] , keep= False )
利用査重标识结果直接删除
df[~df.duplicated( )]
df[~df . duplicated ( ['课程', '开设' ] )]
相关文章:
Python——Pandas(第三讲)
文章目录 修改替换变量值对应数值的替换指定数值范围的替换 虚拟变量变换数值变量分段数据分组基于拆分进行筛选 分组汇总使用 agg 函数进行汇总引用自定义函数 长宽格式转换转换为最简格式长宽型格式的自由互转 多个数据源的合并数据的横向合并concat 命令 处理缺失值认识缺失…...

性能测试中qps 一直上不去的原因
QPS:Queries Per Second意思是“每秒查询率”,是一台服务器每秒能够相应的查询次数,是对一个特定的查询服务器在规定时间内所处理流量多少的衡量标准。 在性能测试中,QPS(每秒查询率)一直上不去可能由以下…...
、Redis 的 Pool 对象池、钩子函数、依赖注入)
学习笔记14:CNAME 记录值、TTL (Time to Live)、Redis 的 Pool 对象池、钩子函数、依赖注入
CNAME 记录值 CNAME 记录是一种DNS记录类型,它将一个域名映射到另一个域名。这通常用于将一个子域名指向另一个域名,或者将一个域名指向一个不同的顶级域。 用途:用于域名别名,负载均衡,或者在更换域名时保持服务的连…...

springboot集成mybatis时,dao层的mapper类需要添加@Repository注解吗?
在Spring Boot项目中,当你使用MyBatis作为ORM框架时,关于DAO层的Mapper类是否需要添加Repository注解,这主要取决于你的项目需求和配置。 Repository注解的作用Repository注解是Spring框架中用于声明持久层(DAO层)的组…...

一文总结代理:代理模式、代理服务器
概述 代理在计算机编程领域,是一个很通用的概念,包括:代理设计模式,代理服务器等。 代理类持有具体实现类的实例,将在代理类上的操作转化为实例上方法的调用。为某个对象提供一个代理,以控制对这个对象的…...
探索 Kubernetes 持久化存储之 Longhorn 初窥门径
作者:运维有术星主 在 Kubernetes 生态系统中,持久化存储扮演着至关重要的角色,它是支撑业务应用稳定运行的基石。对于那些选择自建 Kubernetes 集群的运维架构师而言,选择合适的后端持久化存储解决方案是一项至关重要的选型决策。…...

全国区块链职业技能大赛样题第9套智能合约+数据库表设计
后端源码地址:https://blog.csdn.net/Qhx20040819/article/details/140746050 前端源码地址:https://blog.csdn.net/Qhx20040819/article/details/140746216 智能合约+数据库表设计:https://blog.csdn.net/Qhx20040819/article/details/140746646 nice.sql /* Navicat MySQ…...

常见OVS网桥及其链接接口详解
目录 引言OVS简介常见OVS网桥 QBR(qbr)PLY网桥br-intbr-tunbr-routerbrcps常见网桥链接接口 QVOQVIQVMPatch网桥和接口的工作原理应用场景 虚拟化环境数据中心网络云计算平台 1. 引言 开放虚拟交换机(Open vSwitch,简称OVS&…...

创建最最最纯净 Windows 11/10 系统镜像!| 全网独一份
前期准备工作 1.配置系统应答文件:【点击前往】 2.系统镜像编辑器: 【点击下载】 3.Windows 系统镜像官方下载: 【Windows 11】、【Windows 10】【官方密钥】 4.翻译工具 【GitHub】 5.详细的设置教程 5.1先打开配置系统应答文件&#…...
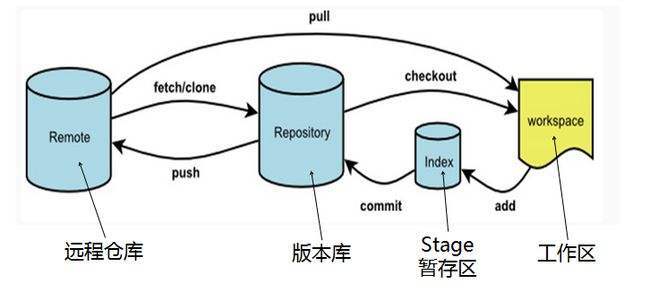
带你学会Git必会操作
文章目录 带你学会Git必会操作1Git的安装2.Git基本操作2.1本地仓库的创建2.2配置本地仓库 3.认识一些Git的基本概念3.1操作流程: 4.一些使用场景4.1添加文件场景一4.2查看git文件4.3修改文件4.4Git版本回退4.5git撤销修改 5.分支管理5.1查看分支5.2创建本地分支5.3切…...

clickhouse处理readonly报错
1,clickhouse执行 SYSTEM RESTORE REPLICA db_com.dwd_com_t_judge_result_local; SYSTEM RESTORE REPLICA db_com.dwd_com_t_judge_result_local Query id: 70669be0-eef8-41da-b761-4980ce48ece2 0 rows in set. Elapsed: 0.001 sec. Received exception fro…...

使用git命令行的方式,将本地项目上传到远程仓库
在国内的开发环境中,git的使用是必不可少的。Git 是一款分布式版本控制系统,用于有效管理和追踪文件的变更历史及协作开发。本片文章就来介绍一下怎样使用git命令行的方式,将本地项目上传到远程仓库,虽然现在的IDE中基本都配置了g…...

jetbrains InterlliJ IDEA 2024.1 版本最新特性一览: Java 相关内容
简简单单 Online zuozuo:欢迎商业合作 简简单单 Online zuozuo 简简单单 Online zuozuo 简简单单 Online zuozuo 简简单单 Online zuozuo :本心、输入输出、结果 简简单单 Online zuozuo :联系我们:VX :tja6288 / EMAIL: 347969164@qq.com 文章目录 jetbrains InterlliJ …...

百日筑基第三十四天-JAVA中的强/软/弱/虚引用
百日筑基第三十四天-JAVA中的强/软/弱/虚引用 Java对象的引用被划分为4种级别,分别为强引用、软引用、弱引用以及虚引用。帮助程序更加灵活地控制对象的生命周期和JVM进行垃圾回收。 强引用 强引用是最普遍的引用,一般把一个对象赋给一个引用变量&…...
)
C语言100基础拔高题(3)
1.利用递归函数调用方式,将所输入的5个字符,以相反顺序打印出来。 解题思路:通过反复调用一个打印最后一个元素的函数,来实现此功能。源代码如下: #include<stdio.h> void oposize(char str[], int len); int main() {//利…...
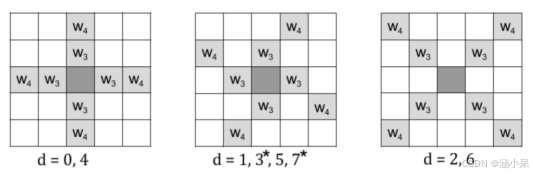
AV1技术学习:Constrained Directional Enhancement Filter
CDEF允许编解码器沿某些(可能是倾斜的)方向应用非线性消阶滤波器。它以88为单位进行。如下图所示,通过旋转和反射所示的三个模板来定义八个预设方向。 Templates of preset directions and their associated directions. The templates correspond to directions of…...

C++的STL简介(一)
目录 1.什么是STL 2.STL的版本 3.STL的六大组件 4.string类 4.1为什么学习string类? 4.2string常见接口 4.2.1默认构造 编辑 4.2.2析构函数 Element access: 4.2.3 [] 4.2.4迭代器 编辑 auto 4.2.4.1 begin和end 4.2.4.2.regin和rend Capacity: 4.2.5…...

DNS劫持
目录 一、DNS的基本概念 二、DNS劫持的工作原理 三、DNS劫持的影响 四、DNS劫持的防范措施 DNS劫持:一种网络安全威胁的深入分析 在当今网络日益发达的时代,互联网已经成为了人们日常生活中不可或缺的一部分。然而,随着网络技术的进步&am…...
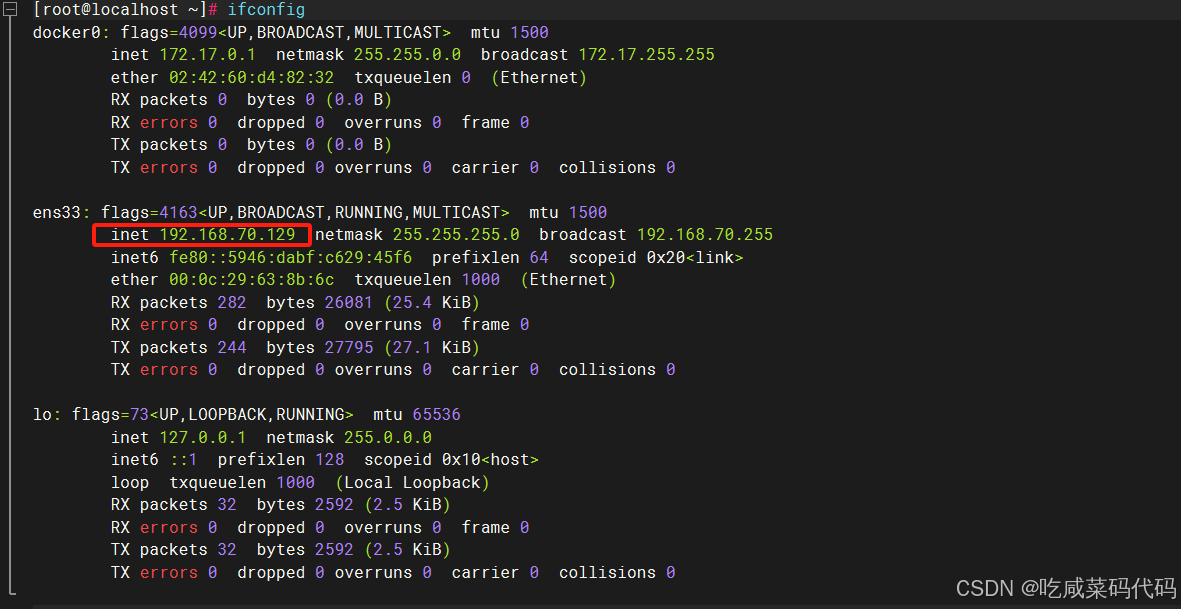
Centos7解决网关ens33的静态地址配置
原因复现: 我登录一段时间之后我ens33的网关ip地址发生了改变 原ip地址配置 现有地址: 根据文心一言提示 修改配置文件 sudo vi /etc/sysconfig/network-scripts/ifcfg-ens33 我的原配置 [rootlocalhost ~]# sudo vi /etc/sysconfig/network-scripts/ifcfg-ens33 TYPE"…...

python中常用于构建cnn的库有哪些
在Python中,有多种库可用于构建卷积神经网络(CNN)。以下是几种常用的库: 1. TensorFlow TensorFlow是一个开源深度学习框架,由Google Brain团队开发。它支持构建和训练各种神经网络模型,包括卷积神经网络。…...

Vim 调用外部命令学习笔记
Vim 外部命令集成完全指南 文章目录 Vim 外部命令集成完全指南核心概念理解命令语法解析语法对比 常用外部命令详解文本排序与去重文本筛选与搜索高级 grep 搜索技巧文本替换与编辑字符处理高级文本处理编程语言处理其他实用命令 范围操作示例指定行范围处理复合命令示例 实用技…...

Android Wi-Fi 连接失败日志分析
1. Android wifi 关键日志总结 (1) Wi-Fi 断开 (CTRL-EVENT-DISCONNECTED reason3) 日志相关部分: 06-05 10:48:40.987 943 943 I wpa_supplicant: wlan0: CTRL-EVENT-DISCONNECTED bssid44:9b:c1:57:a8:90 reason3 locally_generated1解析: CTR…...

Redis相关知识总结(缓存雪崩,缓存穿透,缓存击穿,Redis实现分布式锁,如何保持数据库和缓存一致)
文章目录 1.什么是Redis?2.为什么要使用redis作为mysql的缓存?3.什么是缓存雪崩、缓存穿透、缓存击穿?3.1缓存雪崩3.1.1 大量缓存同时过期3.1.2 Redis宕机 3.2 缓存击穿3.3 缓存穿透3.4 总结 4. 数据库和缓存如何保持一致性5. Redis实现分布式…...

基于Flask实现的医疗保险欺诈识别监测模型
基于Flask实现的医疗保险欺诈识别监测模型 项目截图 项目简介 社会医疗保险是国家通过立法形式强制实施,由雇主和个人按一定比例缴纳保险费,建立社会医疗保险基金,支付雇员医疗费用的一种医疗保险制度, 它是促进社会文明和进步的…...

1688商品列表API与其他数据源的对接思路
将1688商品列表API与其他数据源对接时,需结合业务场景设计数据流转链路,重点关注数据格式兼容性、接口调用频率控制及数据一致性维护。以下是具体对接思路及关键技术点: 一、核心对接场景与目标 商品数据同步 场景:将1688商品信息…...

LLM基础1_语言模型如何处理文本
基于GitHub项目:https://github.com/datawhalechina/llms-from-scratch-cn 工具介绍 tiktoken:OpenAI开发的专业"分词器" torch:Facebook开发的强力计算引擎,相当于超级计算器 理解词嵌入:给词语画"…...

【JavaWeb】Docker项目部署
引言 之前学习了Linux操作系统的常见命令,在Linux上安装软件,以及如何在Linux上部署一个单体项目,大多数同学都会有相同的感受,那就是麻烦。 核心体现在三点: 命令太多了,记不住 软件安装包名字复杂&…...

C++ Visual Studio 2017厂商给的源码没有.sln文件 易兆微芯片下载工具加开机动画下载。
1.先用Visual Studio 2017打开Yichip YC31xx loader.vcxproj,再用Visual Studio 2022打开。再保侟就有.sln文件了。 易兆微芯片下载工具加开机动画下载 ExtraDownloadFile1Info.\logo.bin|0|0|10D2000|0 MFC应用兼容CMD 在BOOL CYichipYC31xxloaderDlg::OnIni…...

SiFli 52把Imagie图片,Font字体资源放在指定位置,编译成指定img.bin和font.bin的问题
分区配置 (ptab.json) img 属性介绍: img 属性指定分区存放的 image 名称,指定的 image 名称必须是当前工程生成的 binary 。 如果 binary 有多个文件,则以 proj_name:binary_name 格式指定文件名, proj_name 为工程 名&…...

保姆级教程:在无网络无显卡的Windows电脑的vscode本地部署deepseek
文章目录 1 前言2 部署流程2.1 准备工作2.2 Ollama2.2.1 使用有网络的电脑下载Ollama2.2.2 安装Ollama(有网络的电脑)2.2.3 安装Ollama(无网络的电脑)2.2.4 安装验证2.2.5 修改大模型安装位置2.2.6 下载Deepseek模型 2.3 将deepse…...