Hive——UDF函数:高德地图API逆地理编码,实现离线解析经纬度转换省市区(离线地址库,非调用高德API)
文章目录
- 1. 需求背景
- 数据现状
- 业务需求
- 面临技术问题
- 寻求其他方案
- 2. 运行环境
- 软件版本
- Maven依赖
- 3. 获取离线地址库
- 4. Hive UDF函数实现
- 5. 创建Hive UDF函数
- 6. 参考
1. 需求背景
数据现状
目前业务系统某数据库表中记录了约3亿条用户行为数据,其中两列记录了用户触发某个业务动作时所在的经度和纬度数值,但是没有记录经纬度对应的省市区编码和名称信息。
业务需求
现在业务方提出一个数据需求,想要统计省市区对应的用户数等相关指标。
面临技术问题
因为历史数据量较大,如果通过调用高德API把所有历史数据中的经纬度对应的省市区请求回来,会面临一个个问题:在查看公司的高德API账户后,发现每天提供的最大调用量是300W次,那么要把历史3亿数据初始化调用完,需要30000W/300w=100天,要3个多月,这完全是不可接受的。
寻求其他方案
既然不能通过调用高德API的方式获取省市区,那有没有一个离线的地址库,然后从这个地址库获取历史数据的省市区呢。然后通过搜索引擎还真的找到了某个大神写的一个第三方库,可以从一个地址库文件来获取经纬度对应的省市区。
这个第三方库的Github地址:https://github.com/hsp8712/addrparser
2. 运行环境
软件版本
- Java 1.8
- Hive 3.1.0
- Hadoop 3.1.1
Maven依赖
<dependency><groupId>tech.spiro</groupId><artifactId>addrparser</artifactId><version>1.1</version></dependency><dependency><groupId>org.apache.hive</groupId><artifactId>hive-exec</artifactId><version>3.1.0</version><scope>provided</scope></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-common</artifactId><version>3.1.1</version><scope>provided</scope></dependency>
3. 获取离线地址库
这个第三方库的作者提供了一个2019年9月份的离线地址库文件,考虑到这个文件的数据已经比较旧了,然后去翻看作者的源码文件,发现提供了爬取地址库的源码,直接拿来改改就可以用了(但前提是你要有请求高德API的API Key)。
下面是本人调整后并经过测试后可以正常请求地址库的代码(这个类中还引用了作者编写的其他类/接口,请参考作业的Github):
import org.apache.commons.cli.*;
import tech.spiro.addrparser.crawler.GetRegionException;
import tech.spiro.addrparser.crawler.RegionDataCrawler;
import tech.spiro.addrparser.io.RegionDataOutput;
import tech.spiro.addrparser.io.file.JSONFileRegionDataOutput;import java.io.IOException;
import java.util.Arrays;/*
*
* A command-line tool to crawl region data.
* */
public class CrawlerServer {private static Options options = new Options();static {options.addOption("k", "key", true, "Amap enterprise dev key");options.addOption("l", "level", true, "Root region level: 0-country, 1-province, 2-city");options.addOption("c", "code", true, "Root region code");options.addOption("o", "out", true, "Output file.");}private static void printHelp() {HelpFormatter formatter = new HelpFormatter();formatter.printHelp("CrawlerServer", options );}public static void main(String[] args) throws IOException, GetRegionException {CommandLineParser parser = new BasicParser();try {CommandLine cmd = parser.parse(options, args);
// String key = cmd.getOptionValue("k");
// String level = cmd.getOptionValue('l');
// String code = cmd.getOptionValue('c');
// String outputFile = cmd.getOptionValue('o');String key = "xxxxxxxxxxxxxxxxxxx";String level = "0";String code = "100000";String outputFile = "/Users/name/Desktop/china-region.json";if (!Arrays.asList("0", "1", "2").contains(level)) {throw new ParseException("option:level invalid.");}int _code = 0;try {_code = Integer.parseInt(code);} catch (NumberFormatException e) {throw new ParseException("code must be numeric.");}execute(key, level, _code, outputFile);} catch (ParseException e) {System.out.println(e.getMessage());printHelp();System.exit(-1);}}private static void execute(String amapKey, String level, int code, String out) throws IOException, GetRegionException {try (RegionDataOutput regionOutput = new JSONFileRegionDataOutput(out)) {RegionDataCrawler infoLoader = new RegionDataCrawler(regionOutput, amapKey);if ("0".equals(level)) {infoLoader.loadCountry();} else if ("1".equals(level)) {infoLoader.loadProv(code);} else if ("2".equals(level)) {infoLoader.loadCity(code);}}}
}
运行上面这段代码获取全国省市区地址库实践会比较久,大概要30分钟左右,生产的json文件china-region.json大小约160M。
4. Hive UDF函数实现
在获取到地址库数据之后,为了实现输入经度、维度输出省市区编码和名称的UDF函数,我们需要先把这个地址库文件china-region.json上传到一个指定的HDFS目录下面,这样在Hive中使用UDF函数的时候可以从HDFS目录下直接查询这个文件。
下面代码就是UDF函数的实现逻辑:输入经度、维度数值,然后查询离线地址库文件china-region.json,最终输出对应的省市区信息的json字符串。
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hive.ql.exec.Description;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
import org.apache.hadoop.io.Text;
import tech.spiro.addrparser.common.RegionInfo;
import tech.spiro.addrparser.io.RegionDataInput;
import tech.spiro.addrparser.io.file.JSONFileRegionDataInput;
import tech.spiro.addrparser.parser.Location;
import tech.spiro.addrparser.parser.LocationParserEngine;
import tech.spiro.addrparser.parser.ParserEngineException;import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.nio.charset.StandardCharsets;
import java.util.Arrays;@Description(name = "GetRegionInfo",value = "_FUNC_(latitude, longitude) - Returns the province, city, and district names and codes based on latitude and longitude"
)
public class LgtLttUDF extends GenericUDF {// 经纬度-省市区基础库文件private static final String RESOURCE_FILE = "hdfs://nameservice/user/username/udf/china-region.json";// 位置解析引擎private static volatile LocationParserEngine sharedEngine;private static final Object lock = new Object();/*** 1. UDF函数入参校验* 2. 创建并初始化位置解析引擎* 3. 设置UDF函数返回值数据类型* @param arguments* @return ObjectInspector* @throws UDFArgumentException*/@Overridepublic ObjectInspector initialize(ObjectInspector[] arguments) throws UDFArgumentException {// 参数数量校验if (arguments.length != 2) {throw new UDFArgumentException("The function requires two arguments.");}// 参数类型校验if (!arguments[0].getCategory().equals(ObjectInspector.Category.PRIMITIVE) ||!arguments[1].getCategory().equals(ObjectInspector.Category.PRIMITIVE)) {throw new UDFArgumentException("GetRegionInfoUDF only accepts primitive types as arguments.");}// 创建并初始化位置解析引擎initializeSharedEngine();// 返回值return ObjectInspectorFactory.getStandardStructObjectInspector(Arrays.asList("province_name", "province_code", "city_name", "city_code", "district_name", "district_code"),Arrays.asList(PrimitiveObjectInspectorFactory.javaStringObjectInspector,PrimitiveObjectInspectorFactory.javaStringObjectInspector,PrimitiveObjectInspectorFactory.javaStringObjectInspector,PrimitiveObjectInspectorFactory.javaStringObjectInspector,PrimitiveObjectInspectorFactory.javaStringObjectInspector,PrimitiveObjectInspectorFactory.javaStringObjectInspector));}/*** 初始化位置解析引擎* @throws UDFArgumentException*/private void initializeSharedEngine() throws UDFArgumentException {if (sharedEngine == null) {synchronized (lock) {if (sharedEngine == null) {try {// china-region.json文件作为基础数据InputStreamReader reader = getJsonFileInputStreamFromHDFS(RESOURCE_FILE);RegionDataInput regionDataInput = new JSONFileRegionDataInput(reader);// 创建位置解析引擎sharedEngine = new LocationParserEngine(regionDataInput);// 初始化,加载数据,比较耗时sharedEngine.init();} catch (ParserEngineException | IOException e) {throw new UDFArgumentException("Failed to initialize LocationParserEngine: " + e.getMessage());}}}}}/*** 从HDFS路径读取JSON文件并返回InputStreamReader。** @param hdfsPath HDFS上的JSON文件路径* @return 文件的InputStreamReader对象,用于进一步读取内容* @throws IOException 如果发生I/O错误*/public static InputStreamReader getJsonFileInputStreamFromHDFS(String hdfsPath) throws IOException {// 创建Hadoop配置对象Configuration conf = new Configuration();// 根据配置获取文件系统实例FileSystem fs = FileSystem.get(conf);// 构建HDFS路径对象Path path = new Path(hdfsPath);// 检查文件是否存在if (!fs.exists(path)) {throw new IOException("File " + hdfsPath + " does not exist on HDFS.");}// 打开文件并获取输入流return new InputStreamReader(fs.open(path), "UTF-8");}/*** 通过经度、维度获取对应省市区的编码和名称* @param args* @return* @throws HiveException*/@Overridepublic Object evaluate(DeferredObject[] args) throws HiveException {if (args == null || args.length != 2) {return null;}try {// 经度double longitude = Double.parseDouble(args[1].get().toString());// 纬度double latitude = Double.parseDouble(args[0].get().toString());// 位置信息Location location = sharedEngine.parse(latitude, longitude);// 省市区信息RegionInfo provInfo = location.getProv();RegionInfo cityInfo = location.getCity();RegionInfo districtInfo = location.getDistrict();// 返回省市区编码、名称return new Object[]{new Text(provInfo.getName()),new Text(String.valueOf(provInfo.getCode())),new Text(cityInfo.getName()),new Text(String.valueOf(cityInfo.getCode())),new Text(districtInfo.getName()),new Text(String.valueOf(districtInfo.getCode()))};} catch (Exception e) {throw new HiveException("Error processing coordinates", e);}}@Overridepublic String getDisplayString(String[] children) {return "ltt_lgt_region(" + children[0] + ", " + children[1] + ")";}
}
5. 创建Hive UDF函数
将第四步的UDF实现代码打jar包:china_region.jar,Hive和Hadoop依赖不需要打进去,因为集群上都是有的,只需要把这个第三方的addrparser打进去就可以了。
-
将jar包china_region.jar上传到HDFS指定目录下
-
将jar包添加到hive的classpath。在Hive的cli中执行如下命令
hive> add jar china_region.jar -
创建UDF函数(永久性UDF函数)
hive> create function ltt_lgt as 'com.hive.udf.LgtLttUDF ' using jar 'hdfs://nameservice/user/username/udf/china_region.jar'; -
测试UDF函数
hive> select ltt_lgt(100.750934, 26.038634)
6. 参考
- https://github.com/hsp8712/addrparser
相关文章:
)
Hive——UDF函数:高德地图API逆地理编码,实现离线解析经纬度转换省市区(离线地址库,非调用高德API)
文章目录 1. 需求背景数据现状业务需求面临技术问题寻求其他方案 2. 运行环境软件版本Maven依赖 3. 获取离线地址库4. Hive UDF函数实现5. 创建Hive UDF函数6. 参考 1. 需求背景 数据现状 目前业务系统某数据库表中记录了约3亿条用户行为数据,其中两列记录了用户触…...

深入解析PHP框架:Symfony框架的魅力与优势
嘿,PHP开发者们!今天我们要聊一聊PHP世界中的一颗闪亮明星——Symfony框架。无论是初学者还是经验丰富的开发者,Symfony都为大家提供了强大的工具和灵活的特性。那就跟着我一起,来探索这个强大的PHP框架吧! 一、什么是…...

Go语言实战:基于Go1.19的站点模板爬虫技术解析与应用
一、引言 1.1 爬虫技术的背景与意义 在互联网高速发展的时代,数据已经成为新的石油,而爬虫技术则是获取这种“石油”的重要工具。爬虫,又称网络蜘蛛、网络机器人,是一种自动化获取网络上信息的程序。它广泛应用于搜索引擎、数据分…...
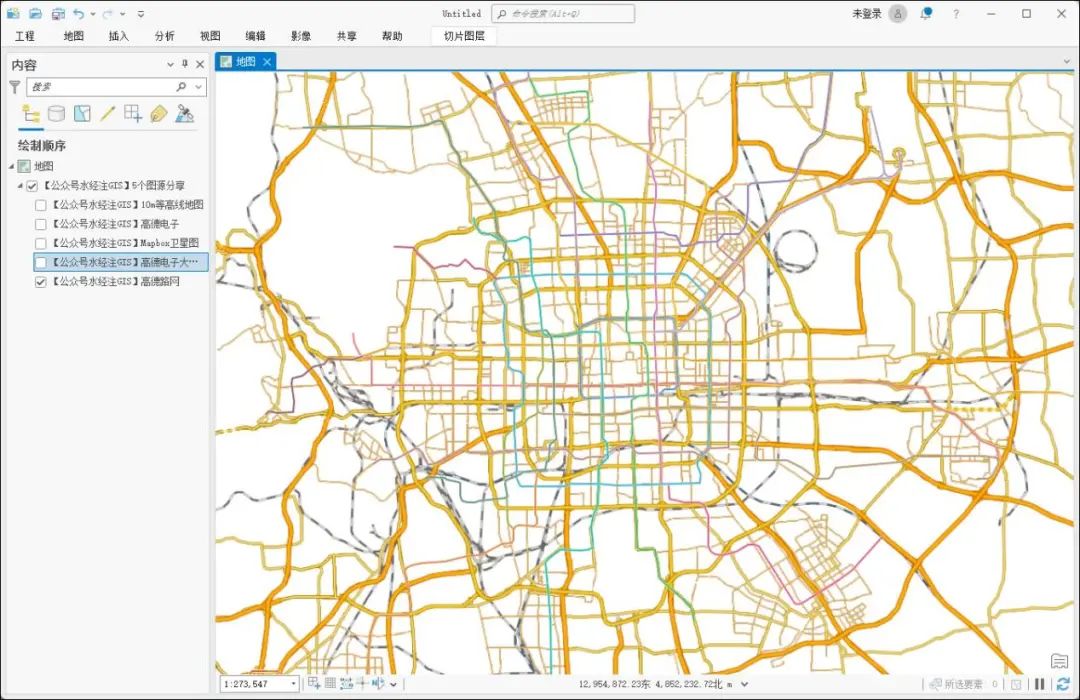
5个ArcGIS图源分享
数据是GIS的血液。 我们在《15个在线地图瓦片URL分享》一文中为你分享了15个地图瓦片URL链接,现在再为你分享5个能做ArcGIS中直接加载的图源! 并提供了能直接在ArcMAP和ArcGIS Pro的文件,如果你需要这些ArcGIS图源,请在文末查看…...
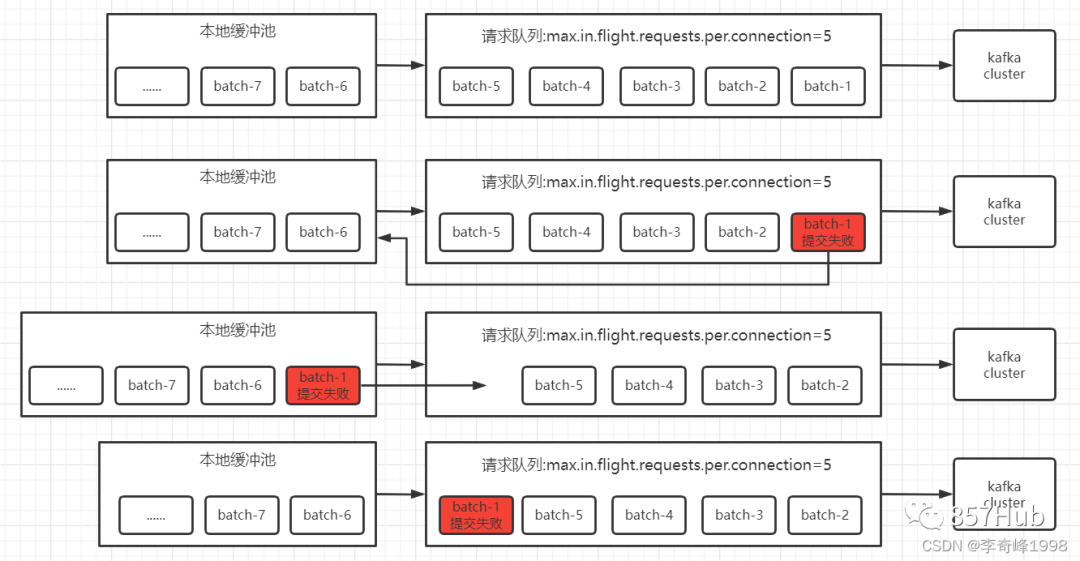
科普文:万字梳理31个Kafka问题
1、 kafka 是什么,有什么作用 2、Kafka为什么这么快 3、Kafka架构及名词解释 4、Kafka中的AR、ISR、OSR代表什么 5、HW、LEO代表什么 6、ISR收缩性 7、kafka follower如何与leader同步数据 8、Zookeeper 在 Kafka 中的作用(早期) 9、Kafka如何快…...

Unity UGUI 实战学习笔记(4)
仅作学习,不做任何商业用途 不是源码,不是源码! 是我通过"照虎画猫"写的,可能有些小修改 不提供素材,所以应该不算是盗版资源,侵权删 登录面板UI 登录数据逻辑 这是初始化的数据变量脚本 using System.…...

Python学习和面试中的常见问题及答案
整理了一些关于Python和机器学习算法的高级问题及其详细答案。这些问题涵盖了多个方面,包括数据处理、模型训练、评估、优化和实际应用。 一、Python 编程问题 解释Python中的装饰器(Decorators)是什么?它们的作用是什么…...

Mysql-索引视图
目录 1.视图 1.1什么是视图 1.2为什么需要视图 1.3视图的作用和优点 1.4创建视图 1.5更新视图 1.6视图使用规则 1.7修改视图 1.8删除视图 2.索引 2.1什么是索引 2.2索引特点 2.3索引分类 2.4索引优缺点 2.5创建索引 2.6查看索引 2.7删除索引 1.视图 1.1什么是…...

电子签章-开放签应用
开放签电子签章系统开源工具版旨在将电子签章、电子合同系统开发中的前后端核心技术开源开放,适合有技术能力的个人 / 团队学习或自建电子签章 \ 电子合同功能或应用,避免研发同仁在工作过程中重复造轮子,降低电子签章技术研发要求࿰…...

Ubuntu下设置文件和文件夹用户组和权限
在 Ubuntu 上,你可以使用 chmod 和 chown 命令来设置当前文件夹下所有文件的权限和所有者。 设置权限: 使用 chmod 命令可以更改文件和目录的权限。例如,要为当前文件夹下的所有文件和子目录设置特定权限,可以使用以下命令&#x…...

JavaSE从零开始到精通(九) - 双列集合
1.前言 Java 中的双列集合主要指的是可以存储键值对的集合类型,其中最常用的包括 Map 接口及其实现类。这些集合允许你以键值对的形式存储和管理数据,提供了便捷的按键访问值的方式。 2. HashMap HashMap 是基于哈希表实现的 Map 接口的类,…...

探索 OpenAI GPT-4o Mini:开发者的高效创新工具
探索 OpenAI GPT-4o Mini:开发者的高效创新工具 最近,OpenAI 推出了全新的 GPT-4o Mini 模型,以其出色的性能和极具吸引力的价格,引起了开发者们的广泛关注。作为开发者,你是否已经开始探索这个“迄今为止最具成本效益…...
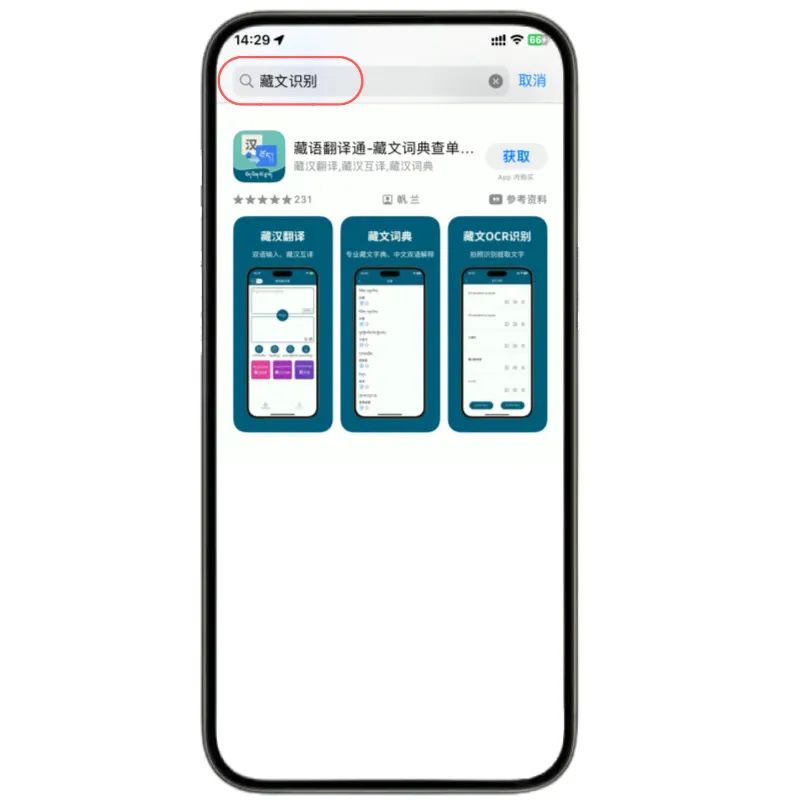
藏文词典查单词,藏汉双语解释,推荐使用《藏语翻译通》App
《藏语翻译通》App推出了藏文词典、藏汉大词典、新术语等全新在线查单词功能。 藏汉互译 《藏语翻译通》App的核心功能之一是藏汉互译。用户只需输入中文或藏文,即可获得翻译结果。 藏文词典查单词 掌握一门语言,词汇是基础。《藏语翻译通》App内置藏…...

【机器学习基础】初探机器学习
【作者主页】Francek Chen 【专栏介绍】⌈Python机器学习⌋ 机器学习是一门人工智能的分支学科,通过算法和模型让计算机从数据中学习,进行模型训练和优化,做出预测、分类和决策支持。Python成为机器学习的首选语言,依赖于强大的开…...

SpringBoot轻松实现多数据源切换
一.需求背景 项目需要实现在多个数据源之间读写数据,例如在 A 数据源和 B 数据源读取数据,然后在 C 数据源写入数据 或者 部分业务数据从 A 数据源中读取、部分从B数据源中读取诸如此类需求。本文将简单模拟在SpringBoot项目中实现不同数据源之间读取数…...

Qt 5 当类的信号函数和成员函数,函数名相同时,连接信号和槽的写法。
前言:因为项目需要,软件要在windows7上运行,然后项目目前是qt6写的,然后搜索资料,需要qt5.15.2或之前的版本才能在win7上运行,于是下载了qt5.15.2,将qt6的代码在qt5编译时,很多错误&…...

Vuex 介绍及示例
Vuex 是 Vue.js 的一个状态管理模式和库,用于管理 Vue 应用中的全局状态。它是专门为 Vue.js 应用设计的,充分利用了 Vue 的细粒度响应系统来高效地更新状态。以下是对 Vuex 的一些介绍和它的基本使用方法: 主要概念 State(状态&…...

【elementui】记录如何重命名elementui组件名称
在main.js中,就是引入elementui的文件中 import ElementUI from element-ui import { Tree } from element-uiVue.use(ElementUI) Vue.component(el-tree-rename, Tree)...

MySQL面试篇章—MySQL锁机制
文章目录 MySQL的锁机制表级锁 & 行级锁排它锁和共享锁InnoDB行级锁行级锁间隙锁意向共享锁和意向排它锁 InnoDB表级锁死锁锁的优化建议MVCC多版本并发控制MyISAM表级锁表级锁并发插入优化锁调度优化 MySQL的锁机制 表级锁 & 行级锁 表级锁:对整张表加锁&…...

OAK相机支持的图像传感器有哪些?
相机支持的传感器 在 RVC2 上,固件必须具有传感器配置才能支持给定的相机传感器。目前,我们支持下面列出的相机传感器的开箱即用(固件中)传感器配置。 名称 分辨率 传感器类型 尺寸 最大 帧率 IMX378 40563040 彩色 1/2.…...

国防科技大学计算机基础课程笔记02信息编码
1.机内码和国标码 国标码就是我们非常熟悉的这个GB2312,但是因为都是16进制,因此这个了16进制的数据既可以翻译成为这个机器码,也可以翻译成为这个国标码,所以这个时候很容易会出现这个歧义的情况; 因此,我们的这个国…...

Flask RESTful 示例
目录 1. 环境准备2. 安装依赖3. 修改main.py4. 运行应用5. API使用示例获取所有任务获取单个任务创建新任务更新任务删除任务 中文乱码问题: 下面创建一个简单的Flask RESTful API示例。首先,我们需要创建环境,安装必要的依赖,然后…...

.Net框架,除了EF还有很多很多......
文章目录 1. 引言2. Dapper2.1 概述与设计原理2.2 核心功能与代码示例基本查询多映射查询存储过程调用 2.3 性能优化原理2.4 适用场景 3. NHibernate3.1 概述与架构设计3.2 映射配置示例Fluent映射XML映射 3.3 查询示例HQL查询Criteria APILINQ提供程序 3.4 高级特性3.5 适用场…...
` 方法)
深入浅出:JavaScript 中的 `window.crypto.getRandomValues()` 方法
深入浅出:JavaScript 中的 window.crypto.getRandomValues() 方法 在现代 Web 开发中,随机数的生成看似简单,却隐藏着许多玄机。无论是生成密码、加密密钥,还是创建安全令牌,随机数的质量直接关系到系统的安全性。Jav…...

visual studio 2022更改主题为深色
visual studio 2022更改主题为深色 点击visual studio 上方的 工具-> 选项 在选项窗口中,选择 环境 -> 常规 ,将其中的颜色主题改成深色 点击确定,更改完成...

鸿蒙中用HarmonyOS SDK应用服务 HarmonyOS5开发一个医院查看报告小程序
一、开发环境准备 工具安装: 下载安装DevEco Studio 4.0(支持HarmonyOS 5)配置HarmonyOS SDK 5.0确保Node.js版本≥14 项目初始化: ohpm init harmony/hospital-report-app 二、核心功能模块实现 1. 报告列表…...

数据库分批入库
今天在工作中,遇到一个问题,就是分批查询的时候,由于批次过大导致出现了一些问题,一下是问题描述和解决方案: 示例: // 假设已有数据列表 dataList 和 PreparedStatement pstmt int batchSize 1000; // …...

Unit 1 深度强化学习简介
Deep RL Course ——Unit 1 Introduction 从理论和实践层面深入学习深度强化学习。学会使用知名的深度强化学习库,例如 Stable Baselines3、RL Baselines3 Zoo、Sample Factory 和 CleanRL。在独特的环境中训练智能体,比如 SnowballFight、Huggy the Do…...

浅谈不同二分算法的查找情况
二分算法原理比较简单,但是实际的算法模板却有很多,这一切都源于二分查找问题中的复杂情况和二分算法的边界处理,以下是博主对一些二分算法查找的情况分析。 需要说明的是,以下二分算法都是基于有序序列为升序有序的情况…...

DeepSeek 技术赋能无人农场协同作业:用 AI 重构农田管理 “神经网”
目录 一、引言二、DeepSeek 技术大揭秘2.1 核心架构解析2.2 关键技术剖析 三、智能农业无人农场协同作业现状3.1 发展现状概述3.2 协同作业模式介绍 四、DeepSeek 的 “农场奇妙游”4.1 数据处理与分析4.2 作物生长监测与预测4.3 病虫害防治4.4 农机协同作业调度 五、实际案例大…...