LLM——10个大型语言模型(LLM)常见面试题以及答案解析
今天我们来总结以下大型语言模型面试中常问的问题

1、哪种技术有助于减轻基于提示的学习中的偏见?
A.微调 Fine-tuning
B.数据增强 Data augmentation
C.提示校准 Prompt calibration
D.梯度裁剪 Gradient clipping
答案:C
提示校准包括调整提示,尽量减少产生的输出中的偏差。微调修改模型本身,而数据增强扩展训练数据。梯度裁剪防止在训练期间爆炸梯度。
2、是否需要为所有基于文本的LLM用例提供矢量存储?
答案:不需要
向量存储用于存储单词或句子的向量表示。这些向量表示捕获单词或句子的语义,并用于各种NLP任务。
并非所有基于文本的LLM用例都需要矢量存储。有些任务,如情感分析和翻译,不需要RAG也就不需要矢量存储。
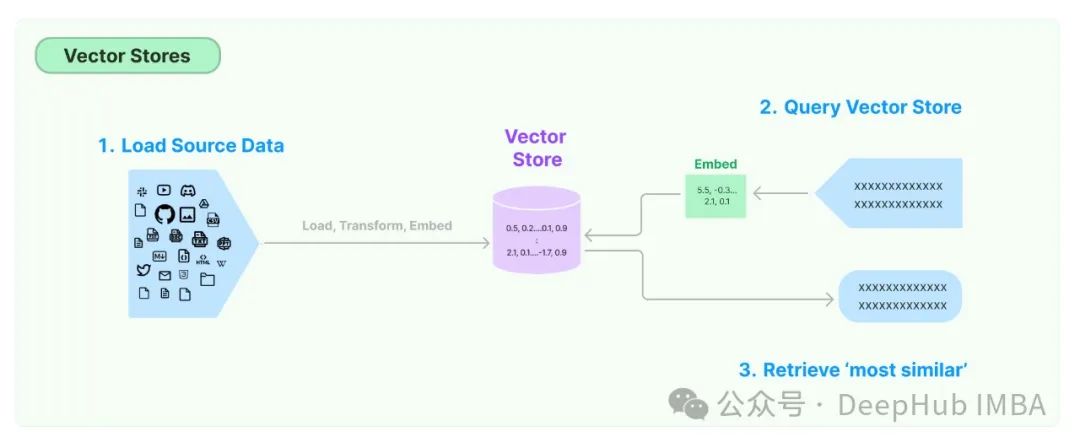
最常见的不需要矢量存储的:
1、情感分析:这项任务包括确定一段文本中表达的情感(积极、消极、中性)。它通常基于文本本身而不需要额外的上下文。
2、这项任务包括将文本从一种语言翻译成另一种语言。上下文通常由句子本身和它所属的更广泛的文档提供,而不是单独的向量存储。
3、以下哪一项不是专门用于将大型语言模型(llm)与人类价值观和偏好对齐的技术?
A.RLHF
B.Direct Preference Optimization
C.Data Augmentation
答案:C
数据增强Data Augmentation是一种通用的机器学习技术,它涉及使用现有数据的变化或修改来扩展训练数据。虽然它可以通过影响模型的学习模式间接影响LLM一致性,但它并不是专门为人类价值一致性而设计的。
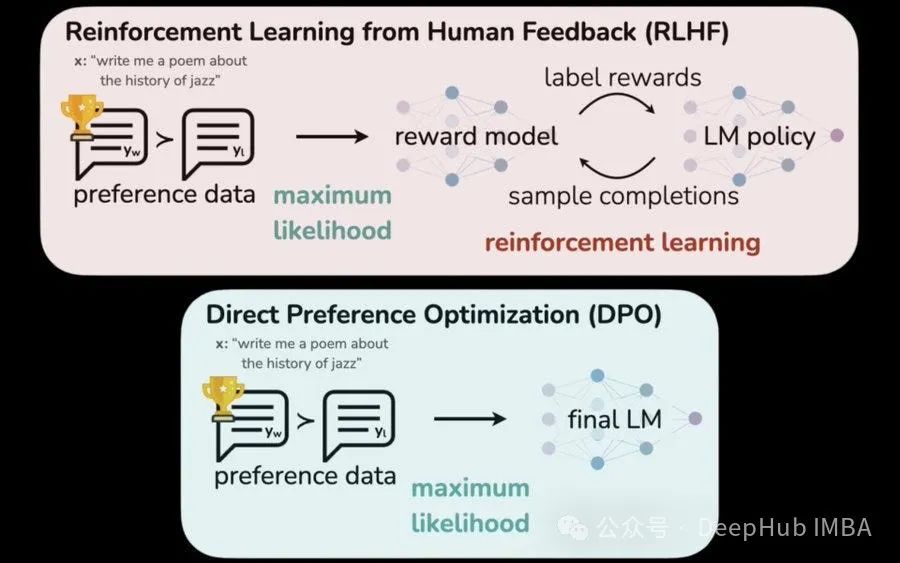
A)从人类反馈中强化学习(RLHF)是一种技术,其中人类反馈用于改进LLM的奖励函数,引导其产生与人类偏好一致的输出。
B)直接偏好优化(DPO)是另一种基于人类偏好直接比较不同LLM输出以指导学习过程的技术。
4、在RLHF中,如何描述“reward hacking”?
A.优化所期望的行为
B.利用奖励函数漏洞
答案:B
reward hacking是指在RLHF中,agent发现奖励函数中存在意想不到的漏洞或偏差,从而在没有实际遵循预期行为的情况下获得高奖励的情况,也就是说,在奖励函数设计不有漏洞的情况下才会出现reward hacking的问题。
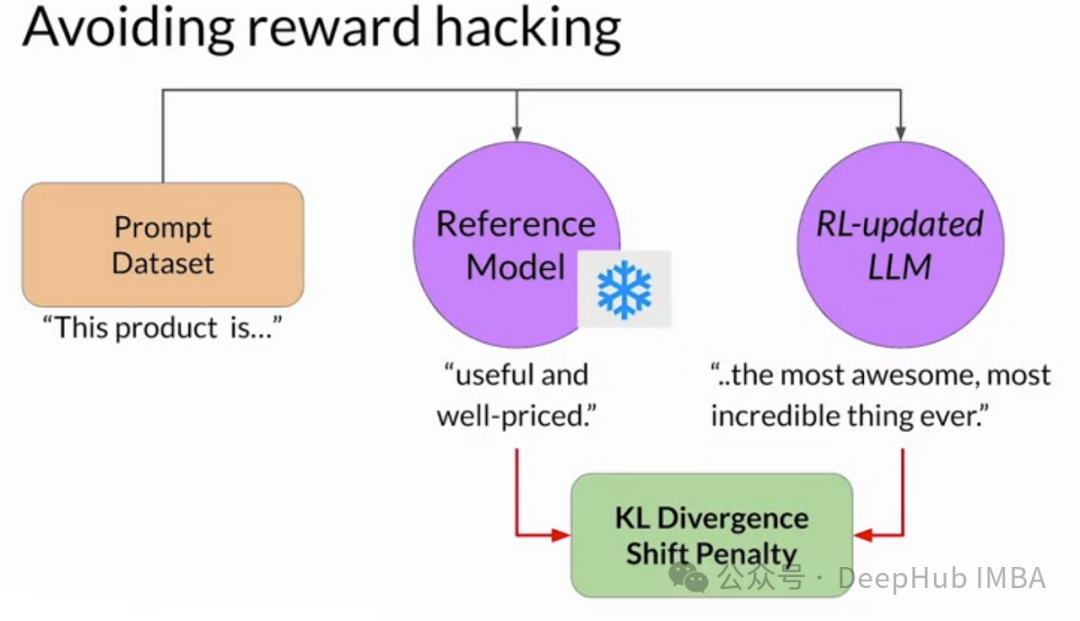
虽然优化期望行为是RLHF的预期结果,但它并不代表reward hacking。选项A描述了一个成功的训练过程。在reward hacking中,代理偏离期望的行为,找到一种意想不到的方式(或者漏洞)来最大化奖励。
5、对任务的模型进行微调(创造性写作),哪个因素显著影响模型适应目标任务的能力?
A.微调数据集的大小
B.预训练的模型架构和大小
答案:B
预训练模型的体系结构作为微调的基础。像大型模型(例如GPT-3)中使用的复杂而通用的架构允许更大程度地适应不同的任务。微调数据集的大小发挥了作用,但它是次要的。一个架构良好的预训练模型可以从相对较小的数据集中学习,并有效地推广到目标任务。
虽然微调数据集的大小可以提高性能,但它并不是最关键的因素。即使是庞大的数据集也无法弥补预训练模型架构的局限性。设计良好的预训练模型可以从较小的数据集中提取相关模式,并且优于具有较大数据集的不太复杂的模型。
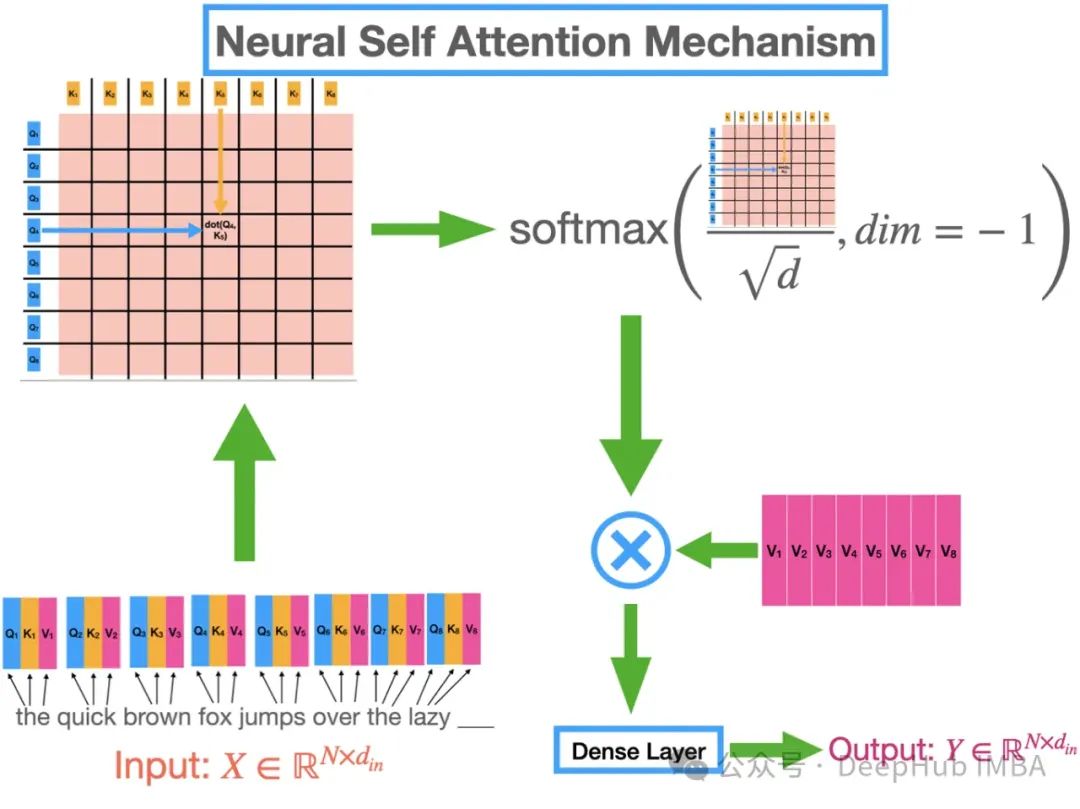
6、transformer 结构中的自注意力机制在模型主要起到了什么作用?
A.衡量单词的重要性
B.预测下一个单词
C.自动总结
答案:A
transformer 的自注意力机制会对句子中单词的相对重要性进行总结。根据当前正在处理的单词动态调整关注点。相似度得分高的单词贡献更显著,这样会对单词重要性和句子结构的理解更丰富。这为各种严重依赖上下文感知分析的NLP任务提供了支持。
7、在大型语言模型(llm)中使用子词算法(如BPE或WordPiece)的优点是什么?
A.限制词汇量
B.减少训练数据量
C.提高计算效率
答案:A
llm处理大量的文本,如果考虑每一个单词,就会导致一个非常大的词表。像字节对编码(BPE)和WordPiece这样的子词算法将单词分解成更小的有意义的单位(子词),然后用作词汇表。这大大减少了词汇量,同时仍然捕获了大多数单词的含义,使模型更有效地训练和使用。
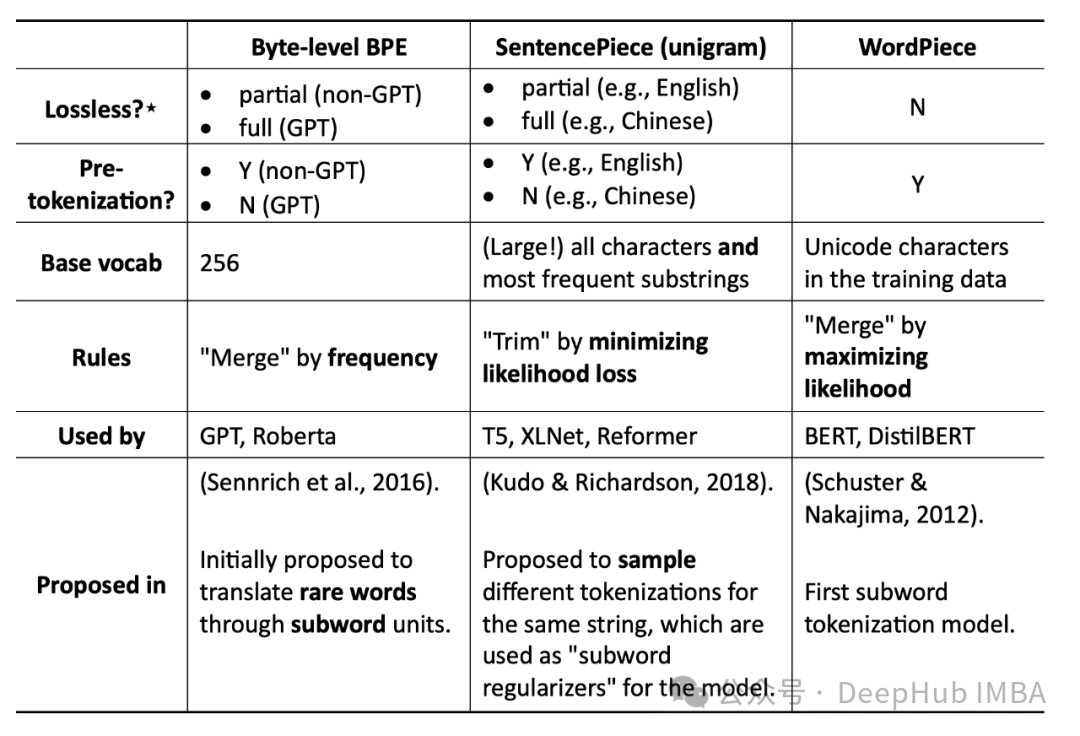
子词算法不直接减少训练数据量。数据大小保持不变。虽然限制词汇表大小可以提高计算效率,但这并不是子词算法的主要目的。它们的主要优点在于用较小的单位集有效地表示较大的词汇表。
8、与Softmax相比,Adaptive Softmax如何提高大型语言模型的速度?
A.稀疏单词表示
B.Zipf定律
C.预训练嵌入
答案:B
标准Softmax需要对每个单词进行昂贵的计算,Softmax为词表中的每个单词进行大量矩阵计算,导致数十亿次操作,而Adaptive Softmax利用Zipf定律(常用词频繁,罕见词不频繁)按频率对单词进行分组。经常出现的单词在较小的组中得到精确的计算,而罕见的单词被分组在一起以获得更有效的计算。这大大降低了训练大型语言模型的成本。

虽然稀疏表示可以改善内存使用,但它们并不能直接解决Softmax在大型词汇表中的计算瓶颈。预训练嵌入增强了模型性能,但没有解决Softmax计算复杂性的核心问题。
9、可以调整哪些推理配置参数来增加或减少模型输出层中的随机性?
A.最大新令牌数
B. Top-k
C.Temperature
答案:C
在文本生成过程中,大型语言模型(llm)依赖于softmax层来为潜在的下一个单词分配概率。温度Temperature是影响这些概率分布随机性的关键参数。
当温度设置为低时,softmax层根据当前上下文为具有最高可能性的单个单词分配显着更高的概率。更高的温度“软化”了概率分布,使其他不太可能出现的单词更具竞争力。
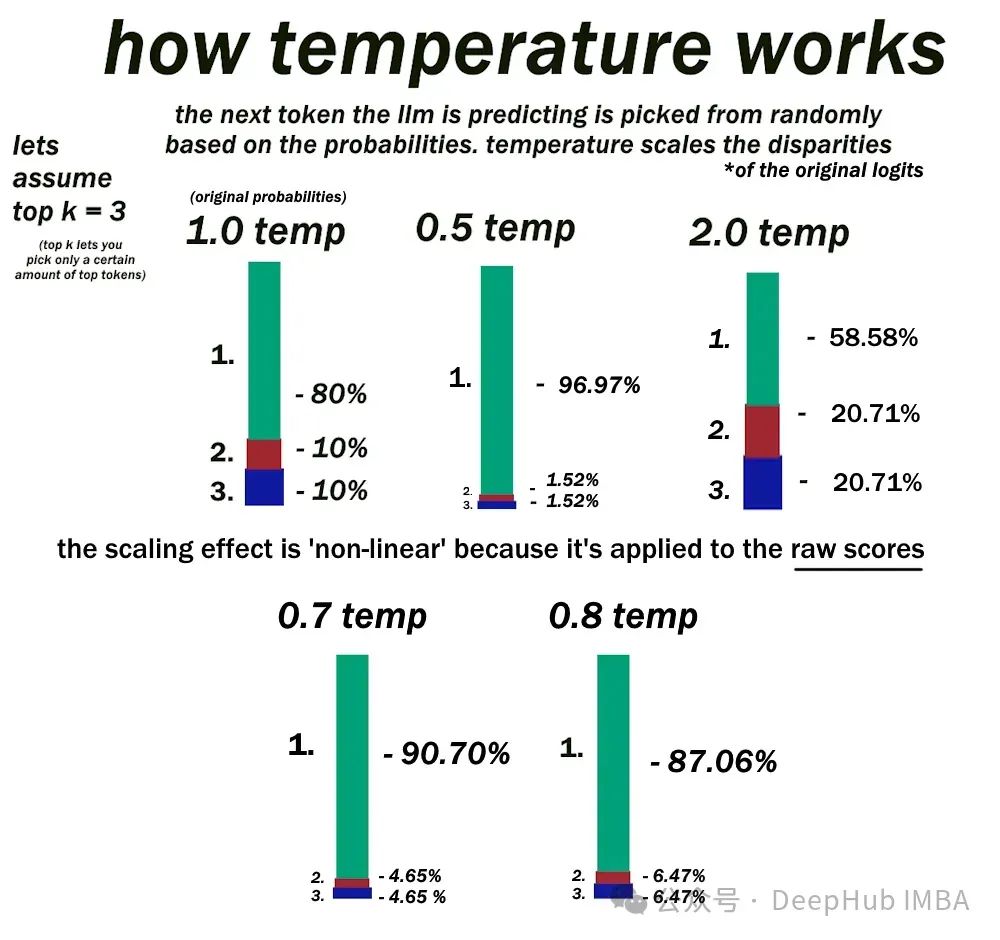
最大新令牌数仅定义LLM在单个序列中可以生成的最大单词数。top -k采样限制softmax层只考虑下一个预测最可能的前k个单词。
10、当模型不能在单个GPU加载时,什么技术可以跨GPU扩展模型训练?
A. DDP
B. FSDP
答案:B
FSDP(Fully Sharded Data Parallel)是一种技术,当模型太大而无法容纳在单个芯片的内存时,它允许跨GPU缩放模型训练。FSDP可以将模型参数,梯度和优化器进行分片操作,并且将状态跨gpu传递,实现高效的训练。
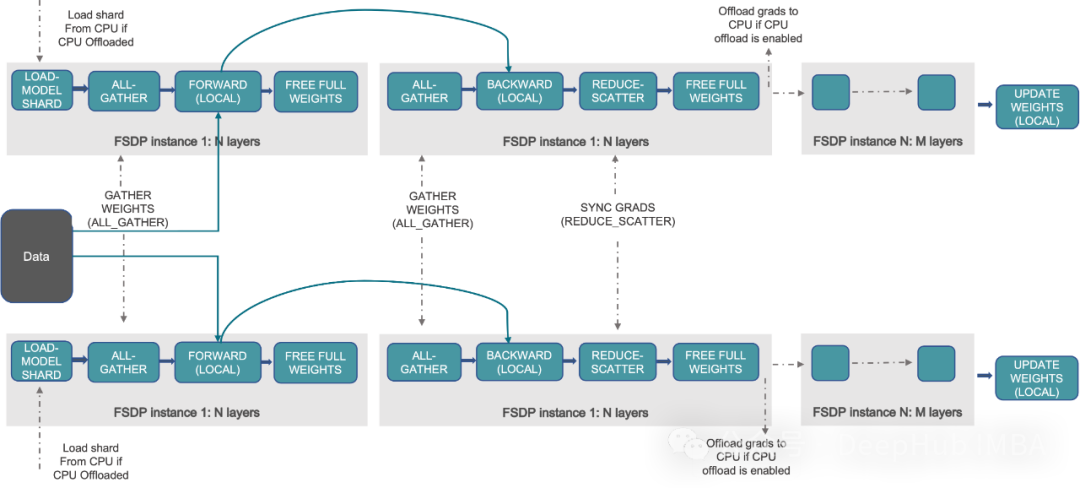
DDP(分布式数据并行)是一种跨多个GPU并行分发数据和处理批量的技术,但它要求模型适合单个GPU,或者更直接的说法是DDP要求单个GPU可以容纳下模型的所有参数。
如何系统的去学习大模型LLM ?
作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。
但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的 AI大模型资料 包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
😝有需要的小伙伴,可以V扫描下方二维码免费领取🆓

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。


四、AI大模型商业化落地方案

阶段1:AI大模型时代的基础理解
- 目标:了解AI大模型的基本概念、发展历程和核心原理。
- 内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践 - L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
- 目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
- 内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例 - L2.2 Prompt框架
- L2.2.1 什么是Prompt
- L2.2.2 Prompt框架应用现状
- L2.2.3 基于GPTAS的Prompt框架
- L2.2.4 Prompt框架与Thought
- L2.2.5 Prompt框架与提示词 - L2.3 流水线工程
- L2.3.1 流水线工程的概念
- L2.3.2 流水线工程的优点
- L2.3.3 流水线工程的应用 - L2.4 总结与展望
- L2.1 API接口
阶段3:AI大模型应用架构实践
- 目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
- 内容:
- L3.1 Agent模型框架
- L3.1.1 Agent模型框架的设计理念
- L3.1.2 Agent模型框架的核心组件
- L3.1.3 Agent模型框架的实现细节 - L3.2 MetaGPT
- L3.2.1 MetaGPT的基本概念
- L3.2.2 MetaGPT的工作原理
- L3.2.3 MetaGPT的应用场景 - L3.3 ChatGLM
- L3.3.1 ChatGLM的特点
- L3.3.2 ChatGLM的开发环境
- L3.3.3 ChatGLM的使用示例 - L3.4 LLAMA
- L3.4.1 LLAMA的特点
- L3.4.2 LLAMA的开发环境
- L3.4.3 LLAMA的使用示例 - L3.5 其他大模型介绍
- L3.1 Agent模型框架
阶段4:AI大模型私有化部署
- 目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
- 内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
学习计划:
- 阶段1:1-2个月,建立AI大模型的基础知识体系。
- 阶段2:2-3个月,专注于API应用开发能力的提升。
- 阶段3:3-4个月,深入实践AI大模型的应用架构和私有化部署。
- 阶段4:4-5个月,专注于高级模型的应用和部署。
这份完整版的大模型 LLM 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
😝有需要的小伙伴,可以Vx扫描下方二维码免费领取🆓
相关文章:
LLM——10个大型语言模型(LLM)常见面试题以及答案解析
今天我们来总结以下大型语言模型面试中常问的问题 1、哪种技术有助于减轻基于提示的学习中的偏见? A.微调 Fine-tuning B.数据增强 Data augmentation C.提示校准 Prompt calibration D.梯度裁剪 Gradient clipping 答案:C 提示校准包括调整提示,尽量减少产生…...

MongoDB - 聚合阶段 $count、$skip、$project
文章目录 1. $count 聚合阶段2. $skip 聚合阶段3. $project 聚合阶段1. 包含指定字段2. 排除_id字段3. 排除指定字段4. 不能同时指定包含字段和排除字段5. 排除嵌入式文档中的指定字段6. 包含嵌入式文档中的指定字段7. 添加新字段8. 重命名字段 1. $count 聚合阶段 计算匹配到…...
)
如何获取文件缩略图(C#和C++实现)
在C中,可以有以下两种办法 使用COM接口IThumbnailCache 文档链接:IThumbnailCache (thumbcache.h) - Win32 apps | Microsoft Learn 示例代码如下: VOID GetFileThumbnail(PCWSTR path) {HRESULT hr CoInitialize(nullptr);IShellItem* i…...

create-vue项目的README中文版
使用方法 要使用 create-vue 创建一个新的 Vue 项目,只需在终端中运行以下命令: npm create vuelatest[!注意] (latest 或 legacy) 不能省略,否则 npm 可能会解析到缓存中过时版本的包。 或者,如果你需要支持 IE11,你…...
Centos 7系统(最小化安装)安装Git 、git-man帮助、补全git命令-详细文章
安装之前由于是最小化安装centos7安装一些开发环境和工具包 文章使用国内阿里源 cd /etc/yum.repos.d/ && mkdir myrepo && mv * myrepo&&lscurl -O https://mirrors.aliyun.com/repo/epel-7.repo;curl -O https://mirrors.aliyun.com/repo/Centos-7…...
Golang零基础入门课_20240726 课程笔记
视频课程 最近发现越来越多的公司在用Golang了,所以精心整理了一套视频教程给大家,这个只是其中的第一部,后续还会有很多。 视频已经录制完成,完整目录截图如下: 课程目录 01 第一个Go程序.mp402 定义变量.mp403 …...

杂记-镜像
-i https://pypi.tuna.tsinghua.edu.cn/simple 清华 pip intall 出现 error: subprocess-exited-with-error 错误的解决办法———————————pip install --upgrade pip setuptools57.5.0 ————————————————————————————————————…...

如何将WordPress文章中的外链图片批量导入到本地
在使用采集软件进行内容创作时,很多文章中的图片都是远程链接,这不仅会导致前端加载速度慢,还会在微信小程序和抖音小程序中添加各种域名,造成管理上的麻烦。特别是遇到没有备案的外链,更是让人头疼。因此,…...

primetime如何合并不同modes的libs到一个lib文件
首先,用primetime 抽 timing model 的指令如下。 代码如下(示例): #抽lib时留一些margin, setup -max/hold -min set_extract_model_margin -port [get_ports -filter "!defined(clocks)"] -max 0.1 #抽lib extract_mod…...
【运维笔记】数据库无法启动,数据库炸后备份恢复数据
事情起因 在做docker作业的时候,把卷映射到了宿主机原来的mysql数据库目录上,宿主机原来的mysql版本为8.0,docker容器版本为5.6,导致翻车。 具体操作 备份目录 将/var/lib/mysql备份到~/mysql_backup:cp /var/lib/…...
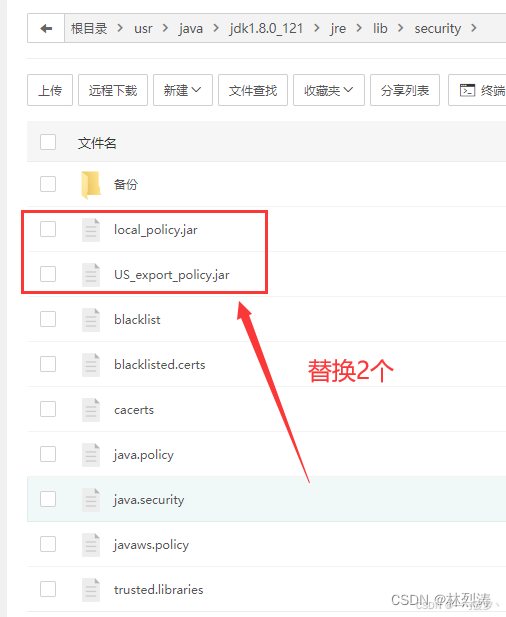
成功解决:java.security.InvalidKeyException: Illegal key size
在集成微信支付到Spring Boot项目时,可能会遇到启动报错 java.security.InvalidKeyException: Illegal key size 的问题。这是由于Java加密扩展(JCE)限制了密钥的长度。幸运的是,我们可以通过简单的替换文件来解决这个问题。 解决…...
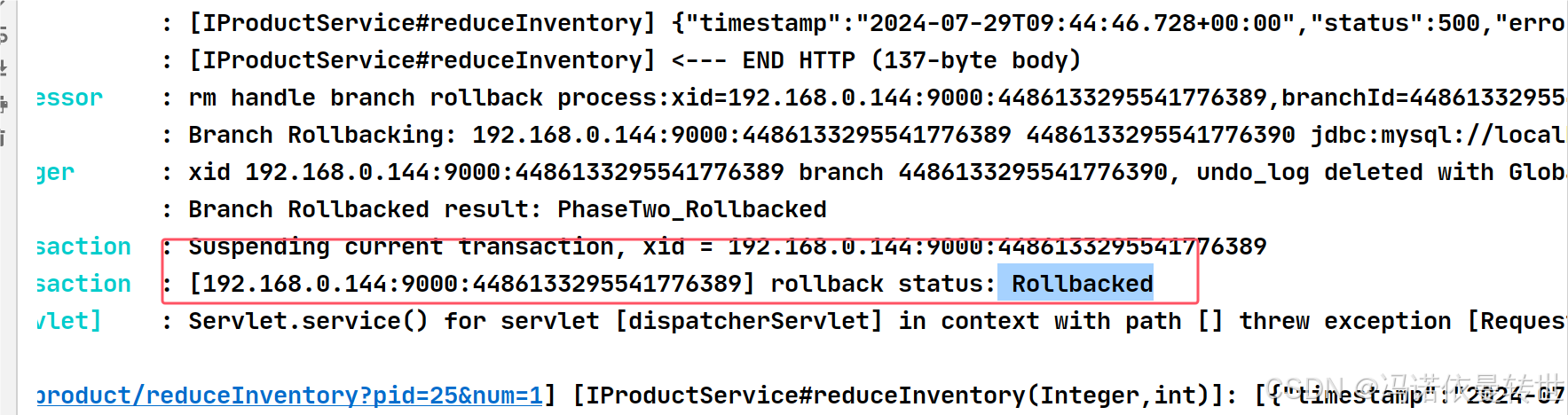
微服务事务管理(分布式事务问题 理论基础 初识Seata XA模式 AT模式 )
目录 一、分布式事务问题 1. 本地事务 2. 分布式事务 3. 演示分布式事务问题 二、理论基础 1. CAP定理 1.1 ⼀致性 1.2 可⽤性 1.3 分区容错 1.4 ⽭盾 2. BASE理论 3. 解决分布式事务的思路 三、初识Seata 1. Seata的架构 2. 部署TC服务 3. 微服务集成Se…...
—— fiddler的工作原理)
测试面试宝典(三十五)—— fiddler的工作原理
Fiddler 是一款强大的 Web 调试工具,其工作原理主要基于代理服务器的机制。 首先,当您在计算机上配置 Fiddler 为系统代理时,客户端(如浏览器)发出的所有 HTTP 和 HTTPS 请求都会被导向 Fiddler。 Fiddler 接收到这些…...

旷野之间32 - OpenAI 拉开了人工智能竞赛的序幕,而Meta 将会赢得胜利
他们通过故事做到了这一点(Snapchat 是第一个)他们用 Reels 实现了这个功能(TikTok 是第一个实现这个功能的)他们正在利用人工智能来实现这一点。 在人工智能竞赛开始时,Meta 的人工智能平台的表现并没有什么特别值得…...
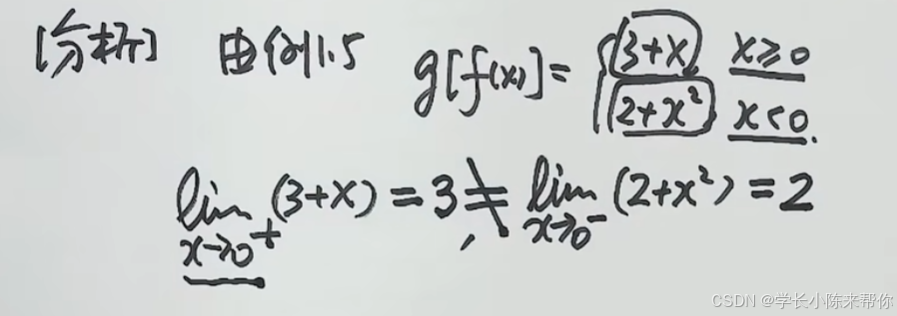
机械学习—零基础学习日志(高数15——函数极限性质)
零基础为了学人工智能,真的开始复习高数 这里我们将会学习函数极限的性质。 唯一性 来一个练习题: 再来一个练习: 这里我问了一下ChatGPT,如果一个值两侧分别趋近于正无穷,以及负无穷。理论上这个极限值应该说是不存…...

树 形 DP (dnf序)
二叉搜索子树的最大键值 /*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(null…...

React的生命周期?
React的生命周期分为三个主要阶段:挂载(Mounting)、更新(Updating)和卸载(Unmounting)。 1、挂载(Mounting) 当组件实例被创建并插入 DOM 时调用的生命周期方法&#x…...
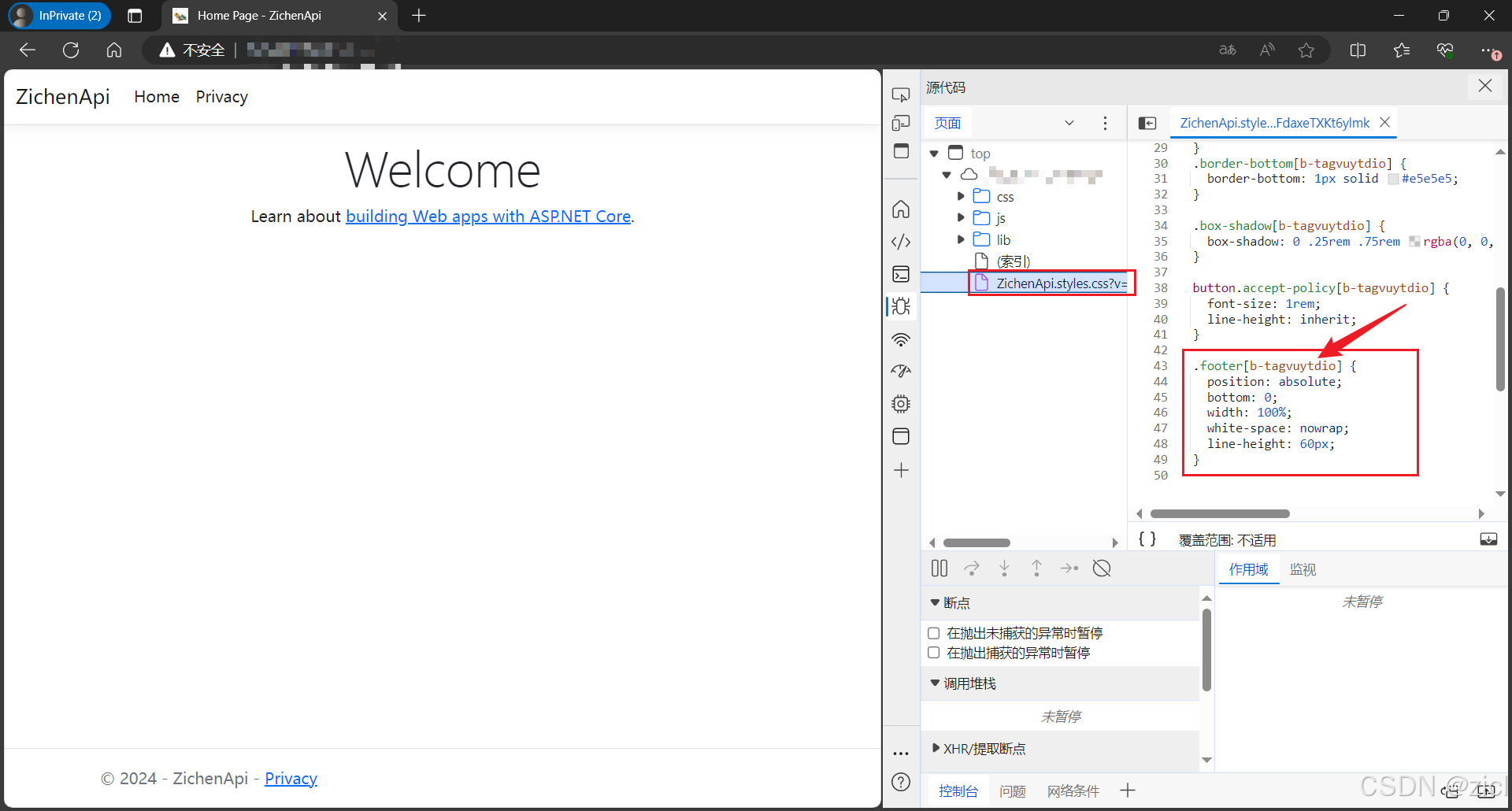
c# - - - ASP.NET Core 网页样式丢失,样式不对
c# - - - ASP.NET Core 网页样式丢失,样式不对 问题 正常样式是这样的。 修改项目名后,样式就变成这样了。底部的内容跑到中间了。 解决 重新生成解决方案,然后发布网站。 原因: 修改项目名之前的 div 上有个这个自定义属…...

Cannot find module ‘html-webpack-plugin
当你在使用Webpack构建项目时遇到Cannot find module html-webpack-plugin这样的错误,这意味着Webpack在构建过程中找不到html-webpack-plugin模块。要解决这个问题,你需要确保已经正确安装了html-webpack-plugin模块,并且在Webpack配置文件中…...

vue、react部署项目的 hashRouter 和 historyRouter模式
Vue 项目 使用 hashRouter 如果你使用的是 hashRouter,通常不需要修改 base,因为 hashRouter 使用 URL 的哈希部分来管理路由,这部分不会被服务器处理。你只需要确保 publicPath 设置正确即可。 使用 historyRouter 如果你使用的是 histo…...

LeetCode - 394. 字符串解码
题目 394. 字符串解码 - 力扣(LeetCode) 思路 使用两个栈:一个存储重复次数,一个存储字符串 遍历输入字符串: 数字处理:遇到数字时,累积计算重复次数左括号处理:保存当前状态&a…...

关于iview组件中使用 table , 绑定序号分页后序号从1开始的解决方案
问题描述:iview使用table 中type: "index",分页之后 ,索引还是从1开始,试过绑定后台返回数据的id, 这种方法可行,就是后台返回数据的每个页面id都不完全是按照从1开始的升序,因此百度了下,找到了…...

MMaDA: Multimodal Large Diffusion Language Models
CODE : https://github.com/Gen-Verse/MMaDA Abstract 我们介绍了一种新型的多模态扩散基础模型MMaDA,它被设计用于在文本推理、多模态理解和文本到图像生成等不同领域实现卓越的性能。该方法的特点是三个关键创新:(i) MMaDA采用统一的扩散架构…...

【2025年】解决Burpsuite抓不到https包的问题
环境:windows11 burpsuite:2025.5 在抓取https网站时,burpsuite抓取不到https数据包,只显示: 解决该问题只需如下三个步骤: 1、浏览器中访问 http://burp 2、下载 CA certificate 证书 3、在设置--隐私与安全--…...

Spring Cloud Gateway 中自定义验证码接口返回 404 的排查与解决
Spring Cloud Gateway 中自定义验证码接口返回 404 的排查与解决 问题背景 在一个基于 Spring Cloud Gateway WebFlux 构建的微服务项目中,新增了一个本地验证码接口 /code,使用函数式路由(RouterFunction)和 Hutool 的 Circle…...

在Ubuntu24上采用Wine打开SourceInsight
1. 安装wine sudo apt install wine 2. 安装32位库支持,SourceInsight是32位程序 sudo dpkg --add-architecture i386 sudo apt update sudo apt install wine32:i386 3. 验证安装 wine --version 4. 安装必要的字体和库(解决显示问题) sudo apt install fonts-wqy…...

JVM 内存结构 详解
内存结构 运行时数据区: Java虚拟机在运行Java程序过程中管理的内存区域。 程序计数器: 线程私有,程序控制流的指示器,分支、循环、跳转、异常处理、线程恢复等基础功能都依赖这个计数器完成。 每个线程都有一个程序计数…...
)
C#学习第29天:表达式树(Expression Trees)
目录 什么是表达式树? 核心概念 1.表达式树的构建 2. 表达式树与Lambda表达式 3.解析和访问表达式树 4.动态条件查询 表达式树的优势 1.动态构建查询 2.LINQ 提供程序支持: 3.性能优化 4.元数据处理 5.代码转换和重写 适用场景 代码复杂性…...
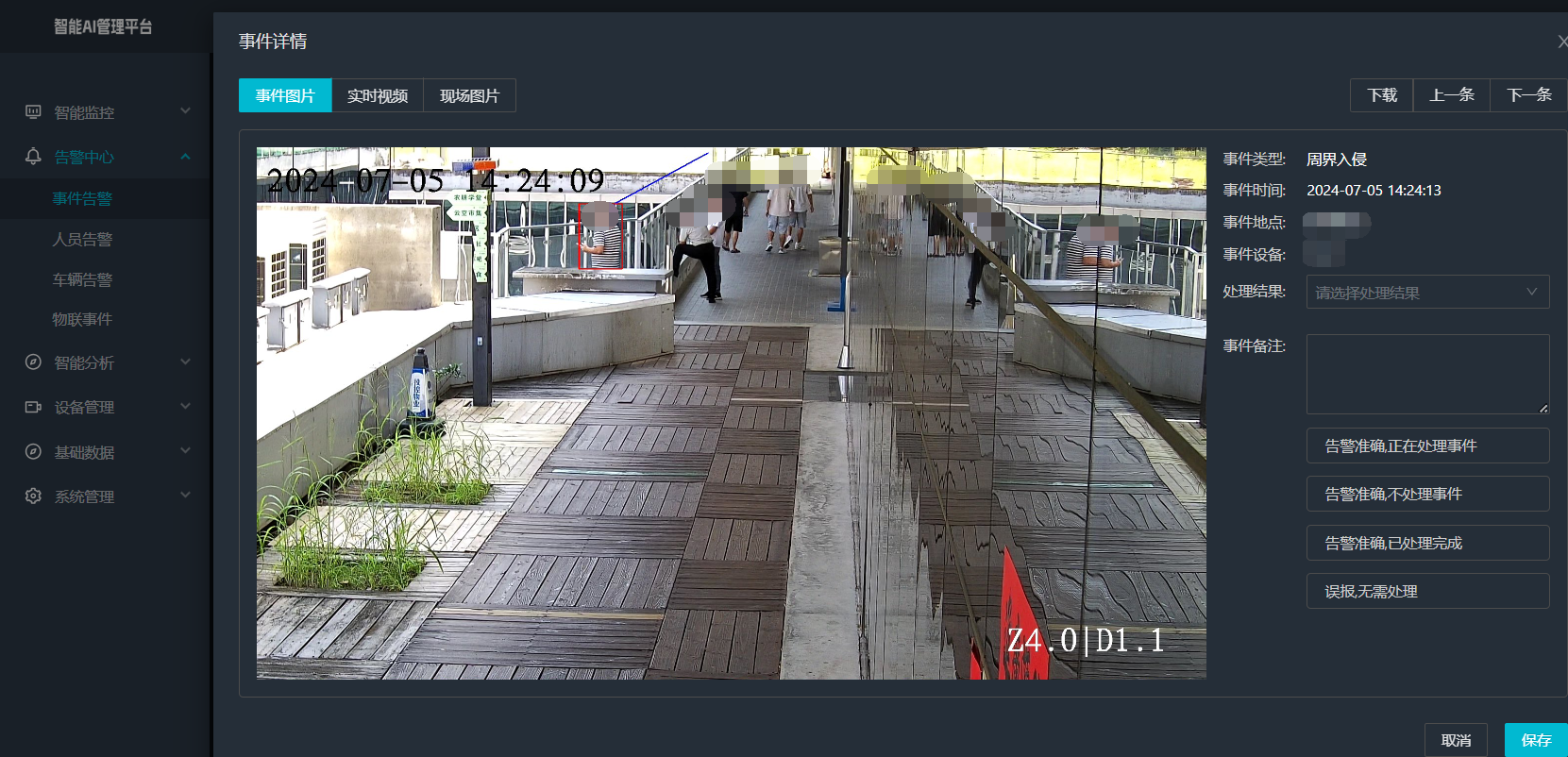
打手机检测算法AI智能分析网关V4守护公共/工业/医疗等多场景安全应用
一、方案背景 在现代生产与生活场景中,如工厂高危作业区、医院手术室、公共场景等,人员违规打手机的行为潜藏着巨大风险。传统依靠人工巡查的监管方式,存在效率低、覆盖面不足、判断主观性强等问题,难以满足对人员打手机行为精…...

Git常用命令完全指南:从入门到精通
Git常用命令完全指南:从入门到精通 一、基础配置命令 1. 用户信息配置 # 设置全局用户名 git config --global user.name "你的名字"# 设置全局邮箱 git config --global user.email "你的邮箱example.com"# 查看所有配置 git config --list…...