python----线程、进程、协程的区别及多线程详解
文章目录
- 一、线程、进程、协程区别
- 二、创建线程
- 1、函数创建
- 2、类创建
- 三、线程锁
- 1、Lock
- 2、死锁
- 2.1加锁之后处理业务逻辑,在释放锁之前抛出异常,这时的锁没有正常释放,当前的线程因为异常终止了,就会产生死锁。
- 2.2开启两个或两个以上的线程,不同的线程得到了不同的锁,都在等待对方释放锁,但是都在阻塞,所以产生了死锁
- 2.3在同一线程里,多次取获得锁,第一次获取锁后,还未释放,再次获得锁
- 3、RLock
- 四、线程通信
- 1、condition
- 2、semaphore
一、线程、进程、协程区别
1. 进程是资源分配的独立单位,是应用程序的载体, 进程之间是相互独立(资源不共享),一个进程由多个线程构成2.线程是资源分配的最小单位,线程共享进程的资源3.协程是用户态执行的轻量级编程模型,由单一线程内部发出控制信号进行调度,协程允许不同入口点在不同的位置暂停或开始程序,协程本质就是一个小线程多线程适合于 I/O 密集型任务,如网络请求、文件读写等,可以提高并发性和响应性。
多进程适用于 CPU 密集型任务,如大量计算、图像处理等,可以利用多核处理器加速运算。
二、创建线程
在Python中创建线程主要依靠内置的threading模块。线程类Thread的常用方法如下表:
| 序号 | 方法 | 含义 |
|---|---|---|
| 1 | start() | 创建一个Thread子线程实例并执行该实例的run()方法 |
| 2 | run() | 子线程需要执行的目标任务 |
| 3 | join() | 主进程阻塞等待子线程直到子线程结束才继续执行,可以设置等待超时时间timeout |
| 4 | is_alive() | 判断子线程是否终止 |
| 5 | daemon() | 设置子线程是否随主进程退出而退出,默认是False |
threading.current_thread():获取到当前线程。
获取线程后可以得到两个比较重要的属性:name和ident,分别是线程名称和id。
创建线程可以使用两种方法:使用函数或类创建。
1、函数创建
import threading
import timedef myThread(i):start = time.time()my_thread_name = threading.current_thread().name # 当前线程的名字time.sleep(i)my_thread_id = threading.current_thread().ident # 当前线程idprint('当前线程为:{},线程ID:{},所在进程为:{}'.format(my_thread_name, my_thread_id, os.getpid()))print('%s线程运行时间结束,耗时%s...' % (my_thread_name, time.time() - start))# 创建三个线程
def fun():t1 = time.time()thread = []for i in range(1, 4):t = threading.Thread(target=myThread,name='线程%s' % i, args=(i,))t.start()thread.append(t)for i in thread:i.join() # 阻塞主线程if __name__ == '__main__':fun()
threading.Thread(group=None,target=None,name='',args=(),kwargs={},daemon=False)
group:预留参数,不需要传递
target:目标代码(要执行的内容)
name:线程名称:字符串
args:是target的参数,可迭代对象
kwargs:是target的参数,是一个字典
daemon:设置线程为守护线程
2、类创建
class myThread(threading.Thread):def __init__(self,name=None):super().__init__()self.name = namedef run(self):start = time.time()my_thread_name = threading.current_thread().name # 当前线程的名字time.sleep(3)my_thread_id = threading.current_thread().ident # 当前线程idprint('当前线程为:{},线程ID:{},所在进程为:{}'.format(my_thread_name, my_thread_id, os.getpid()))print('%s线程运行时间结束,耗时%s...' % (my_thread_name, time.time() - start))# 创建三个线程
def fun():t1 = time.time()thread = []for i in range(1, 4):t = myThread(name='线程%s' % i)t.start()thread.append(t)for i in thread:i.join() # 阻塞主线程,直到子线程执行完毕再运行主线程if __name__ == '__main__':fun()
三、线程锁
多线程一个很大的问题是数据不安全,因为线程之间的数据是共享的。多线程可以通过线程锁来进行数据同步,可用于保护共享资源同时被多个线程读写引起冲突导致错误
import threading
x = 0
# lock = threading.RLock()
def increment():global xname = threading.current_thread().namefor _ in range(1000000):x += 1print(name, x)
threads = []
for _ in range(3):t = threading.Thread(target=increment)threads.append(t)t.start()
for t in threads:t.join()
print("Final value of x:", x)#Thread-2 1435674
#Thread-1 1423093
#Thread-3 1727936
#;Final value of x: 1727936
可以看出开启三个线程在0的基础上每次加1000000得到的结果应该是3000000.但不是这样的
1、Lock
线程同步能够保证多个线程安全访问竞争资源,最简单的同步机制是引入互斥锁。互斥锁为资源设置一个状态:锁定和非锁定。某个线程要更改共享数据时,先将其锁定,此时资源的状态为“锁定”,其他线程不能更改;直到该线程释放资源,将资源的状态变成“非锁定”,其他的线程才能再次锁定该资源。互斥锁保证了每次只有一个线程进行写入操作,从而保证了多线程情况下数据的正确性。
import threading
x = 0
lock = threading.Lock()
def increment():global xname = threading.current_thread().namelock.acquire()try:for _ in range(1000000):x += 1print(name, x)finally:lock.release()
threads = []
for _ in range(3):t = threading.Thread(target=increment)threads.append(t)t.start()for t in threads:t.join()
print("Final value of x:", x)#Thread-1 1000000
#Thread-2 2000000
#Thread-3 3000000
#Final value of x: 3000000
使用了锁之后,代码运行速度明显降低,这是因为线程由原来的并发执行变成了串行,不过数据安全性得到保证。
还可以使用with lock这种上下文格式,自动管理上锁和释放锁。
import threading
x = 0
lock = threading.Lock()
def increment():global xname = threading.current_thread().namewith lock:for _ in range(1000000):x += 1print(name, x)
threads = []
for _ in range(3):t = threading.Thread(target=increment)threads.append(t)t.start()
for t in threads:t.join()
print("Final value of x:", x)#Thread-1 1000000
#Thread-2 2000000
#Thread-3 3000000
#Final value of x: 3000000
一般来说加锁以后还要有一些功能实现,在释放之前还有可能抛异常,一旦抛出异常,锁是无法释放,但是当前线程可能因为这个异常被终止了,这就产生了死锁。死锁解决办法:
1、使用 try..except..finally 语句处理异常、保证锁的释放2、with 语句上下文管理,锁对象支持上下文管理。只要实现了__enter__和__exit__魔术方法的对象都支持上下文管理。另一种是
锁的应用场景:独占锁: 锁适用于访问和修改同一个共享资源的时候,即读写同一个资源的时候。共享锁: 如果共享资源是不可变的值时,所有线程每一次读取它都是同一样的值,这样的情况就不需要锁。使用锁的注意事项:少用锁,必要时用锁。使用了锁,多线程访问被锁的资源时,就变成了串行,要么排队执行,要么争抢执行。
加锁时间越短越好,不需要就立即释放锁。
一定要避免死锁。
不使用锁时,有了效率,但是结果是错的。使用了锁,变成了串行,效率地下,但是结果是对的。
2、死锁
2.1加锁之后处理业务逻辑,在释放锁之前抛出异常,这时的锁没有正常释放,当前的线程因为异常终止了,就会产生死锁。
解决方案:
1、使用 try..except..finally 语句处理异常、保证锁的释放2、with 语句上下文管理,锁对象支持上下文管理。只要实现了__enter__和__exit__魔术方法的对象都支持上下文管理。
2.2开启两个或两个以上的线程,不同的线程得到了不同的锁,都在等待对方释放锁,但是都在阻塞,所以产生了死锁
解决方案:
1、不同线程中获得锁的顺序一致,不能乱2、使用递归锁:RLock。
2.3在同一线程里,多次取获得锁,第一次获取锁后,还未释放,再次获得锁
解决方案:
1、使用递归锁:RLock。
3、RLock
递归锁也被称为“锁中锁”,指一个线程可以多次申请同一把锁,但是不会造成死锁,这就可以用来解决上面的死锁问题。
import threading
x = 0
lock = threading.RLock()
def increment():global xname = threading.current_thread().namelock.acquire()lock.acquire()try:for _ in range(1000000):x += 1print(name, x)finally:lock.release()lock.release()
threads = []
for _ in range(3):t = threading.Thread(target=increment)threads.append(t)t.start()
for t in threads:t.join()
print("Final value of x:", x)#Thread-1 1000000
#Thread-2 2000000
#Thread-3 3000000
#Final value of x: 3000000
RLock内部维护着一个Lock和一个counter变量,counter记录了acquire的次数,从而使得资源可以被多次acquire。直到一个线程所有的acquire都被release,其他的线程才能获得资源。
四、线程通信
1、condition
Condition可以认为是一把比Lock和RLOK更加高级的锁,其在内部维护一个琐对象(默认是RLock),可以在创建Condigtion对象的时候把琐对象作为参数传入。Condition也提供了acquire, release方法,其含义与琐的acquire, release方法一致,其实它只是简单的调用内部琐对象的对应的方法而已。
运行原理:可以认为Condition对象维护了一个锁(Lock/RLock)和一个waiting池。线程通过acquire获得Condition对象,当调用wait方法时,线程会释放Condition内部的锁并进入blocked状态,同时在waiting池中记录这个线程。当调用notify方法时,Condition对象会从waiting池中挑选一个线程,通知其调用acquire方法尝试取到锁。Condition对象的构造函数可以接受一个Lock/RLock对象作为参数,如果没有指定,则Condition对象会在内部自行创建一个RLock。除了notify方法外,Condition对象还提供了notifyAll方法,可以通知waiting池中的所有线程尝试acquire内部锁。由于上述机制,处于waiting状态的线程只能通过notify方法唤醒,所以notifyAll的作用在于防止有的线程永远处于沉默状态。
import threading
import time
from queue import Queueclass Producer(threading.Thread):# 生产者函数def run(self):global countwhile True:if con.acquire():# 当count 小于等于1000 的时候进行生产if count > 1000:con.wait()else:count = count + 100msg = self.name + ' produce 100, count=' + str(count)print(msg)# 完成生成后唤醒waiting状态的线程,# 从waiting池中挑选一个线程,通知其调用acquire方法尝试取到锁con.notify()con.release()time.sleep(1)class Consumer(threading.Thread):# 消费者函数def run(self):global countwhile True:# 当count 大于等于100的时候进行消费if con.acquire():if count < 100:con.wait()else:count = count - 5msg = self.name + ' consume 5, count=' + str(count)print(msg)con.notify()# 完成生成后唤醒waiting状态的线程,# 从waiting池中挑选一个线程,通知其调用acquire方法尝试取到锁con.release()time.sleep(1)count = 0
con = threading.Condition()def test():for i in range(2):p = Producer()p.start()for i in range(5):c = Consumer()c.start()
if __name__ == '__main__':test()#Thread-1 produce 100, count=100
#Thread-2 produce 100, count=200
#Thread-3 consume 5, count=195
#Thread-4 consume 5, count=190
#Thread-5 consume 5, count=185
#Thread-6 consume 5, count=180
#Thread-7 consume 5, count=175
#Thread-2 produce 100, count=275
#Thread-3 consume 5, count=270
2、semaphore
semaphore是python中的一个内置的计数器,内部使用了Condition对象,多线程同时运行,能提高程序的运行效率,但是并非线程越多越好,而 semaphore 信号量可以通过内置计数器来控制同时运行线程的数量,启动线程(消耗信号量)内置计数器会自动减一,线程结束(释放信号量)内置计数器会自动加一;内置计数器为零,启动线程会阻塞,直到有本线程结束或者其他线程结束为止;
创建多个线程,同一时间运行三个线程
import threading
# 导入时间模块
import time# 添加一个计数器,最大并发线程数量5(最多同时运行5个线程)
semaphore = threading.Semaphore(2)def foo():semaphore.acquire() #计数器获得锁time.sleep(2) #程序休眠2秒print("当前时间:",time.ctime()) # 打印当前系统时间semaphore.release() #计数器释放锁if __name__ == "__main__":thread_list= list()for i in range(6):t=threading.Thread(target=foo,args=()) #创建线程thread_list.append(t)t.start() #启动线程for t in thread_list:t.join()print("程序结束!")#当前时间: Tue Jul 30 11:18:38 2024
#当前时间: Tue Jul 30 11:18:38 2024
#当前时间: Tue Jul 30 11:18:40 2024
#当前时间: Tue Jul 30 11:18:40 2024
#当前时间: Tue Jul 30 11:18:42 2024
#当前时间: Tue Jul 30 11:18:42 2024
#程序结束!
因为Semaphore使用了Condition,线程之间仍然有锁保证线程数据安全
相关文章:

python----线程、进程、协程的区别及多线程详解
文章目录 一、线程、进程、协程区别二、创建线程1、函数创建2、类创建 三、线程锁1、Lock2、死锁2.1加锁之后处理业务逻辑,在释放锁之前抛出异常,这时的锁没有正常释放,当前的线程因为异常终止了,就会产生死锁。2.2开启两个或两个…...

将 magma example 改写成 cusolver example eqrf
1,简单安装Magma 1.1 下载编译 OpenBLAS $ git clone https://github.com/OpenMathLib/OpenBLAS.git $ cd OpenBLAS/ $ make -j DEBUG1 $ make install PREFIX/home/hipper/ex_magma/local_d/OpenBLAS/1.2 下载编译 magma $ git clone https://bitbucket.org/icl…...

微信小程序教程007:数据绑定
文章目录 数据绑定1、数据绑定原则2、在data中定义页面数据3、Mustache语法的格式4、Mustache应用场景5、绑定属性6、三元运算8、算数运算数据绑定 1、数据绑定原则 在data中定义数据在WXML中使用数据2、在data中定义页面数据 在页面对应的.js文件中,把数据定义到data对象中…...

Git -- git stash 暂存
使用 git 或多或少都会了解到 git stash 命令,但是可能未曾经常使用,下面简单介绍两种使用场景。 场景一:分支A开发,分支B解决bug 我们遇到最常见的例子就是,在当前分支 A 上开发写需求,但是 B 分支上有…...

基于YOLO的植物病害识别系统:从训练到部署全攻略
基于深度学习的植物叶片病害识别系统(UI界面YOLOv8/v7/v6/v5代码训练数据集) 1. 引言 在农业生产中,植物叶片病害是影响作物产量和质量的主要因素之一。传统的病害检测方法依赖于人工识别,效率低且易受主观因素影响。随着深度学…...

数据库开发:MySQL基础(二)
MySQL基础(二) 一、表的关联关系 在关系型数据库中,表之间可以通过关联关系进行连接和查询。关联关系是指两个或多个表之间的关系,通过共享相同的列或键来建立连接。常见的关联关系有三种类型:一对多关系,…...

实现物理数据库迁移到云上
实现物理数据库迁移到云上 以下是一个PHP脚本,用于实现物理数据库迁移到云上的步骤: <?php// 评估和规划 $databaseSize "100GB"; $performanceRequirements "high"; $dataComplexity "medium";$cloudProvider &…...

[Spring] MyBatis操作数据库(进阶)
🌸个人主页:https://blog.csdn.net/2301_80050796?spm1000.2115.3001.5343 🏵️热门专栏: 🧊 Java基本语法(97平均质量分)https://blog.csdn.net/2301_80050796/category_12615970.html?spm1001.2014.3001.5482 🍕 Collection与…...

【Websim.ai】一句话让AI帮你生成一个网页
【Websim.ai】一句话让AI帮你生成一个网页 网站链接 websim.ai 简介 websim.ai接入了Claude Sonnet 3.5,GPT-4o等常用的LLM,只需要在websim.ai的官网指令栏中编写相关指令,有点类似大模型的Prompt,指令的好坏决定了网页生成的…...

云计算实训16——关于web,http协议,https协议,apache,nginx的学习与认知
一、web基本概念和常识 1.Web Web 服务是动态的、可交互的、跨平台的和图形化的为⽤户提供的⼀种在互联⽹上浏览信息的服务。 2.web服务器(web server) 也称HTTP服务器(HTTP server),主要有 Nginx、Apache、Tomcat 等。…...
2024年必备技能:小红书笔记评论自动采集,零基础也能学会的方法
摘要: 面对信息爆炸的2024年,小红书作为热门社交平台,其笔记评论成为市场洞察的金矿。本文将手把手教你,即便编程零基础,也能轻松学会利用Python自动化采集小红书笔记评论,解锁营销新策略,提升…...

【Gitlab】SSH配置和克隆仓库
生成SSH Key ssh-keygen -t rsa -b 4096 私钥文件: id_rsa 公钥文件:id_rsa.pub 复制生成的ssh公钥到此处 克隆仓库 git clone repo-address 需要进行推送和同步来更新本地和服务器的文件 推送更新内容 git push <remote><branch> 拉取更新内容 git pull &…...

[Day 35] 區塊鏈與人工智能的聯動應用:理論、技術與實踐
區塊鏈的分布式存儲技術 區塊鏈技術自2008年比特幣白皮書發表以來,已經成為一種革命性的技術,帶來了許多創新。區塊鏈本質上是一個去中心化的分布式賬本,每個節點都持有賬本的副本,並參與記錄和驗證交易。分布式存儲是區塊鏈的重…...

Vue 3 中使用 inMap.js 实现蜂窝热力图的可视化
本文由ScriptEcho平台提供技术支持 项目地址:传送门 Vue 3 中使用 inMap.js 实现蜂窝热力图的可视化 应用场景介绍 蜂窝热力图是一种可视化技术,用于在地图上显示数据的分布情况。它将数据点划分为六边形单元格,并根据单元格内数据的密度…...

nginx隐藏server及版本号
1、背景 为了提高nginx服务器的安全性,降低被攻击的风险,需要隐藏nginx的server和版本号。 2、隐藏nginx版本号 在 http {—}里加上 server_tokens off; 如: http {……省略sendfile on;tcp_nopush on;keepalive_timeout 60;tcp_nodelay o…...

Oracle DBMS_XPLAN包
DBMS_XPLAN 包的解释和关键点 DBMS_XPLAN 包是 Oracle 数据库中一个重要的工具,它允许数据库管理员和开发人员以各种方式显示 SQL 语句的执行计划,这对于 SQL 优化和性能诊断至关重要。以下是主要函数及其描述: 用于显示执行计划的主要函数…...

【ffmpeg命令入门】分离音视频流
文章目录 前言音视频交错存储概念为什么要进行音视频交错存储:为什么要分离音视频流: 去除音频去除视频 总结 前言 FFmpeg 是一款强大的多媒体处理工具,广泛应用于音视频的录制、转换和流媒体处理等领域。它支持几乎所有的音频和视频格式&am…...
小红书笔记评论采集全攻略:三种高效方法教你批量导出
摘要: 本文将深入探讨如何利用Python高效采集小红书平台上的笔记评论,通过三种实战策略,手把手教你实现批量数据导出。无论是市场分析、竞品监测还是用户反馈收集,这些技巧都将为你解锁新效率。 一、引言:小红书数据…...
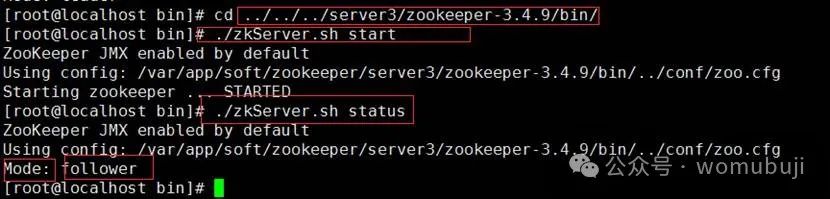
实战:ZooKeeper 操作命令和集群部署
ZooKeeper 操作命令 ZooKeeper的操作命令主要用于对ZooKeeper服务中的节点进行创建、查看、修改和删除等操作。以下是一些常用的ZooKeeper操作命令及其说明: 一、启动与连接 启动ZooKeeper服务器: ./zkServer.sh start这个命令用于启动ZooKeeper服务器…...

linux运维一天一个shell命令之 top详解
概念: top 命令是 Unix 和类 Unix 操作系统(如 Linux、macOS)中一个常用的系统监控工具,它提供了一个动态的实时视图,显示系统的整体性能信息,如 CPU 使用率、内存使用情况、进程列表等。 基本用法 root…...
)
uniapp 对接腾讯云IM群组成员管理(增删改查)
UniApp 实战:腾讯云IM群组成员管理(增删改查) 一、前言 在社交类App开发中,群组成员管理是核心功能之一。本文将基于UniApp框架,结合腾讯云IM SDK,详细讲解如何实现群组成员的增删改查全流程。 权限校验…...

什么是EULA和DPA
文章目录 EULA(End User License Agreement)DPA(Data Protection Agreement)一、定义与背景二、核心内容三、法律效力与责任四、实际应用与意义 EULA(End User License Agreement) 定义: EULA即…...

力扣-35.搜索插入位置
题目描述 给定一个排序数组和一个目标值,在数组中找到目标值,并返回其索引。如果目标值不存在于数组中,返回它将会被按顺序插入的位置。 请必须使用时间复杂度为 O(log n) 的算法。 class Solution {public int searchInsert(int[] nums, …...

Windows安装Miniconda
一、下载 https://www.anaconda.com/download/success 二、安装 三、配置镜像源 Anaconda/Miniconda pip 配置清华镜像源_anaconda配置清华源-CSDN博客 四、常用操作命令 Anaconda/Miniconda 基本操作命令_miniconda创建环境命令-CSDN博客...

Vue ③-生命周期 || 脚手架
生命周期 思考:什么时候可以发送初始化渲染请求?(越早越好) 什么时候可以开始操作dom?(至少dom得渲染出来) Vue生命周期: 一个Vue实例从 创建 到 销毁 的整个过程。 生命周期四个…...

【Kafka】Kafka从入门到实战:构建高吞吐量分布式消息系统
Kafka从入门到实战:构建高吞吐量分布式消息系统 一、Kafka概述 Apache Kafka是一个分布式流处理平台,最初由LinkedIn开发,后成为Apache顶级项目。它被设计用于高吞吐量、低延迟的消息处理,能够处理来自多个生产者的海量数据,并将这些数据实时传递给消费者。 Kafka核心特…...
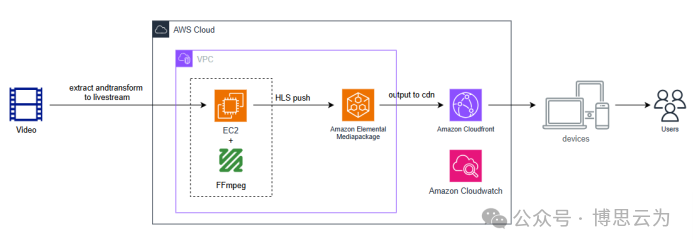
客户案例 | 短视频点播企业海外视频加速与成本优化:MediaPackage+Cloudfront 技术重构实践
01技术背景与业务挑战 某短视频点播企业深耕国内用户市场,但其后台应用系统部署于东南亚印尼 IDC 机房。 随着业务规模扩大,传统架构已较难满足当前企业发展的需求,企业面临着三重挑战: ① 业务:国内用户访问海外服…...

嵌入式面试常问问题
以下内容面向嵌入式/系统方向的初学者与面试备考者,全面梳理了以下几大板块,并在每个板块末尾列出常见的面试问答思路,帮助你既能夯实基础,又能应对面试挑战。 一、TCP/IP 协议 1.1 TCP/IP 五层模型概述 链路层(Link Layer) 包括网卡驱动、以太网、Wi‑Fi、PPP 等。负责…...

[QMT量化交易小白入门]-六十二、ETF轮动中简单的评分算法如何获取历史年化收益32.7%
本专栏主要是介绍QMT的基础用法,常见函数,写策略的方法,也会分享一些量化交易的思路,大概会写100篇左右。 QMT的相关资料较少,在使用过程中不断的摸索,遇到了一些问题,记录下来和大家一起沟通,共同进步。 文章目录 相关阅读1. 策略概述2. 趋势评分模块3 代码解析4 木头…...
)
Docker环境下安装 Elasticsearch + IK 分词器 + Pinyin插件 + Kibana(适配7.10.1)
做RAG自己打算使用esmilvus自己开发一个,安装时好像网上没有比较新的安装方法,然后找了个旧的方法对应试试: 🚀 本文将手把手教你在 Docker 环境中部署 Elasticsearch 7.10.1 IK分词器 拼音插件 Kibana,适配中文搜索…...