apache.commons.pool2 使用指南
apache.commons.pool2 使用指南
为什么要使用池
创建对象耗时较长,多线程频繁调用等因素限制了我们不能每次使用时都重新创建对象,使用池化思想将对象放进池内,不同线程使用同一个池来获取对象,极大的减少每次业务的调用时间。
一个线程内多次使用这个对象所建立的连接。
使用场景
- 数据库连接池:HikariCP、Druid
- 自定义业务连接池:耗时的客户端连接远程服务端
如何使用
1、创建对象客户端
package com.ncst.client.mcc;import lombok.extern.slf4j.Slf4j;
import java.util.Objects;/*** @Author: Lisy* @Description: MCC 操作工具类*/
@Slf4j
public class MccClient {public MccClient() {}public void putMc(String key, String value) {if (Objects.isNull(key)) {throw new IllegalArgumentException("The key argument cannot be null");}log.info("{}=={}", key, value);}public String getMc(String key) {if (Objects.isNull(key)) {throw new IllegalArgumentException("The " + key + " argument cannot be null");}return "";}}2、创建池工厂类
package com.ncst.client.mcc;import org.apache.commons.pool2.PooledObject;
import org.apache.commons.pool2.PooledObjectFactory;
import org.apache.commons.pool2.impl.DefaultPooledObject;/*** @Author: Lisy* @Description: 对象池工厂*/
public class MccClientFactory implements PooledObjectFactory<MccClient> {public MccClientFactory() {}@Overridepublic PooledObject<MccClient> makeObject() {MccClient dccClient = new MccClient();return new DefaultPooledObject<>(dccClient);}@Overridepublic void destroyObject(PooledObject<MccClient> p) {MccClient object = p.getObject();object.close();}@Overridepublic boolean validateObject(PooledObject<MccClient> p) {// 验证对象是否可用的逻辑,如果需要return true;}@Overridepublic void activateObject(PooledObject<MccClient> p) {// 激活对象的逻辑,如果需要}@Overridepublic void passivateObject(PooledObject<MccClient> p) {// 钝化对象的逻辑,如果需要}}
3、对象池管理类
用于管理保存的池对象,单例模式
shutdown 方法在不使用时关闭掉对应任务的所有池连接
package com.ncst.client;import com.ncst.client.mcc.MccClient;
import com.ncst.client.mcc.MccClientFactory;
import org.apache.commons.pool2.impl.GenericObjectPool;
import org.apache.commons.pool2.impl.GenericObjectPoolConfig;import java.util.Objects;
import java.util.concurrent.ConcurrentHashMap;/*** @Author: Lisy* @Description: 对象池管理*/
public class MccClientPoolManager {private static volatile MccClientPoolManager INSTANCE;private MccClientPoolManager() {}public static MccClientPoolManager getInstance() {if (Objects.isNull(INSTANCE)) {synchronized (MccClientPoolManager.class) {if (Objects.isNull(INSTANCE)) {INSTANCE = new MccClientPoolManager();}}}return INSTANCE;}/*** key-jobUuid, value-每一个任务池*/private final ConcurrentHashMap<String, GenericObjectPool<MccClient>> POOL_MAP = new ConcurrentHashMap<>();public GenericObjectPool<MccClient> getPool(String jobId, GenericObjectPoolConfig<MccClient> poolConfig) {return POOL_MAP.computeIfAbsent(jobId, k -> new GenericObjectPool<>(new MccClientFactory(), poolConfig));}public void shutdown(String jobId) {GenericObjectPool<MccClient> dccClientGenericObjectPool = POOL_MAP.get(jobId);if (Objects.nonNull(dccClientGenericObjectPool)) {dccClientGenericObjectPool.close();}}
}
4、使用
通过多线程来模拟实际使用场景,如果使用默认poolConfig,那么最大池大小为8个,最多创建8个对象。
通过CountDownLatch 来等待所有任务完成
通过 MccClientPoolManager.getInstance().shutdown(“key”); 来关闭池
“key” 可根据业务逻辑自行定义
public static void main(String[] args) throws InterruptedException {int num = 20;CountDownLatch latch = new CountDownLatch(num);for (int i = 0; i < num; i++) {int finalI = i;CompletableFuture.runAsync(() -> {try {GenericObjectPool<MccClient> pool2 = MccClientPoolManager.getInstance().getPool("key", new GenericObjectPoolConfig<>());MccClient mccClient = null;try {mccClient = pool2.borrowObject();mccClient.putMc("" + finalI, "value" + finalI);} finally {if (Objects.nonNull(mccClient)) {pool2.returnObject(mccClient);}}} catch (Exception e) {logger.error(e.getMessage(), e);} finally {latch.countDown();}});}latch.await();MccClientPoolManager.getInstance().shutdown("key");}
源码解析-create()
510:private PooledObject<T> create() throws Exception
创建对象时锁住makeObjectCountLock,判断当前已创建对象是否大于设置的池大小,如果未超过则create==true超过则判断已有的池大小是否为0,如果为0返回create==false,
不为0等待正在创建的对象,执行makeObjectCountLock.waitcreate 为true则创建对象,执行 public PooledObject<T> makeObject()创建完对象后判断是否为空,如果为空将已创建对象 cretaeCount--,并抛出异常验证对象是否可用,如果不可用返回null,并cretaeCount--在finally 中锁住 makeObjectCount lock,将makeObjectCount--,唤醒锁中所有等待的对象将对象放入allObjects map中
相关文章:

apache.commons.pool2 使用指南
apache.commons.pool2 使用指南 为什么要使用池 创建对象耗时较长,多线程频繁调用等因素限制了我们不能每次使用时都重新创建对象,使用池化思想将对象放进池内,不同线程使用同一个池来获取对象,极大的减少每次业务的调用时间。 …...
【Python面试题收录】Python编程基础练习题②(数据类型+文件操作+时间操作)
本文所有代码打包在Gitee仓库中https://gitee.com/wx114/Python-Interview-Questions 一、数据类型 第一题 编写一个函数,实现:先去除左右空白符,自动检测输入的数据类型,如果是整数就转换成二进制形式并返回出结果;…...

typescript 定义类型
type infoType string; let name: infoType "全易"; let location: infoType "北京"; // let age: infoType 18; // 报错 infoType string|number 就不报错了 let job: infoType "开发"; let love: infoType "吃喝玩乐&q…...
基于Java+SpringBoot+Vue的的课程作业管理系统
前言 ✌全网粉丝20W,csdn特邀作者、博客专家、CSDN[新星计划]导师、java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取项目下载方式🍅 哈喽兄弟们,好久不见哦࿵…...

分布式日志分析系统--ELK
文章目录 ELK概述ELK主要特点ELK应用架构 Elasticsearch原理JSON格式倒排索引 ES与关系型数据库ES相关概念ES安装说明1.环境初始化2.优化系统资源限制配置3.编辑ES服务文件elasticsearch. yml 优化ELK集群安装脚本scp的使用集群安装成功 Shell命令API使用创建索引创建Type创建分…...

Linux初学基本命令
linux文件目录 1、bin->usr/bin binary存放命令 所有账户可以使用 Linux可以执行的文件,我们称之为命令command 2、boot 存放系统启动文件 3、dev device存放设备文件 4、etc 存放配置文件的目录 configration files 5、home home家目录 存…...
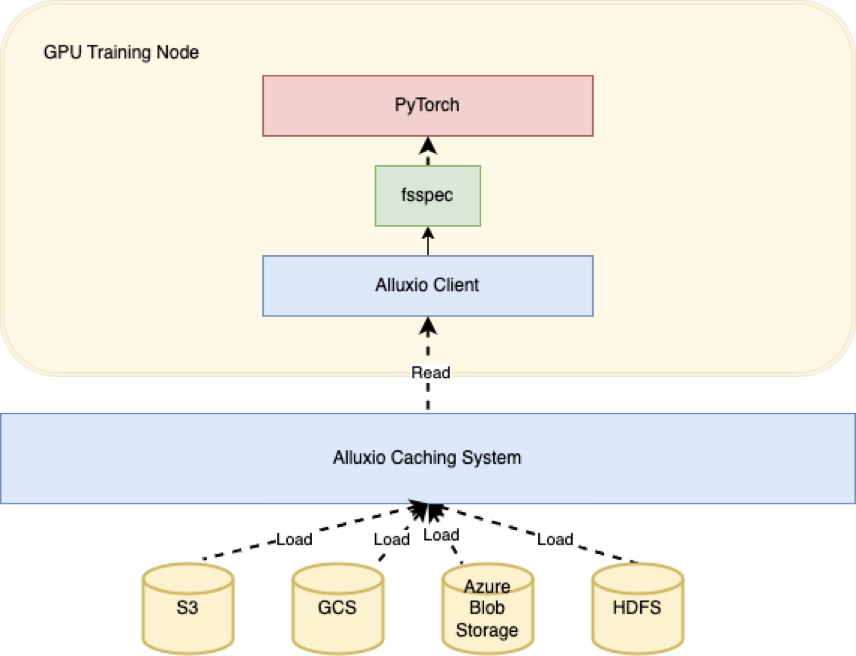
如何优化PyTorch以加快模型训练速度?
PyTorch是当今生产环境中最流行的深度学习框架之一。随着模型变得日益复杂、数据集日益庞大,优化模型训练性能对于缩短训练时间和提高生产力变得至关重要。 本文将分享几个最新的性能调优技巧,以加速跨领域的机器学习模型的训练。这些技巧对任何想要使用…...
)
用最简单的方法对大数据进行处理 vs spark(不需要安装大数据处理工具)
一、大文件处理策略 (一)、难点 内存管理: 大文件无法一次性加载到内存中,因为这可能会导致内存溢出(OutOfMemoryError)。 因此,需要使用流(Stream)或缓冲区(…...

非线性校正算法在红外测温中的应用
非线性校正算法在红外测温中用于修正传感器输出与实际温度之间的非线性关系。红外传感器的输出信号(通常是电压或电流)与温度的关系理论上是线性的,但在实际应用中,由于传感器特性的限制,这种关系往往呈现出非线性。非…...

python----线程、进程、协程的区别及多线程详解
文章目录 一、线程、进程、协程区别二、创建线程1、函数创建2、类创建 三、线程锁1、Lock2、死锁2.1加锁之后处理业务逻辑,在释放锁之前抛出异常,这时的锁没有正常释放,当前的线程因为异常终止了,就会产生死锁。2.2开启两个或两个…...

将 magma example 改写成 cusolver example eqrf
1,简单安装Magma 1.1 下载编译 OpenBLAS $ git clone https://github.com/OpenMathLib/OpenBLAS.git $ cd OpenBLAS/ $ make -j DEBUG1 $ make install PREFIX/home/hipper/ex_magma/local_d/OpenBLAS/1.2 下载编译 magma $ git clone https://bitbucket.org/icl…...

微信小程序教程007:数据绑定
文章目录 数据绑定1、数据绑定原则2、在data中定义页面数据3、Mustache语法的格式4、Mustache应用场景5、绑定属性6、三元运算8、算数运算数据绑定 1、数据绑定原则 在data中定义数据在WXML中使用数据2、在data中定义页面数据 在页面对应的.js文件中,把数据定义到data对象中…...

Git -- git stash 暂存
使用 git 或多或少都会了解到 git stash 命令,但是可能未曾经常使用,下面简单介绍两种使用场景。 场景一:分支A开发,分支B解决bug 我们遇到最常见的例子就是,在当前分支 A 上开发写需求,但是 B 分支上有…...

基于YOLO的植物病害识别系统:从训练到部署全攻略
基于深度学习的植物叶片病害识别系统(UI界面YOLOv8/v7/v6/v5代码训练数据集) 1. 引言 在农业生产中,植物叶片病害是影响作物产量和质量的主要因素之一。传统的病害检测方法依赖于人工识别,效率低且易受主观因素影响。随着深度学…...

数据库开发:MySQL基础(二)
MySQL基础(二) 一、表的关联关系 在关系型数据库中,表之间可以通过关联关系进行连接和查询。关联关系是指两个或多个表之间的关系,通过共享相同的列或键来建立连接。常见的关联关系有三种类型:一对多关系,…...

实现物理数据库迁移到云上
实现物理数据库迁移到云上 以下是一个PHP脚本,用于实现物理数据库迁移到云上的步骤: <?php// 评估和规划 $databaseSize "100GB"; $performanceRequirements "high"; $dataComplexity "medium";$cloudProvider &…...

[Spring] MyBatis操作数据库(进阶)
🌸个人主页:https://blog.csdn.net/2301_80050796?spm1000.2115.3001.5343 🏵️热门专栏: 🧊 Java基本语法(97平均质量分)https://blog.csdn.net/2301_80050796/category_12615970.html?spm1001.2014.3001.5482 🍕 Collection与…...

【Websim.ai】一句话让AI帮你生成一个网页
【Websim.ai】一句话让AI帮你生成一个网页 网站链接 websim.ai 简介 websim.ai接入了Claude Sonnet 3.5,GPT-4o等常用的LLM,只需要在websim.ai的官网指令栏中编写相关指令,有点类似大模型的Prompt,指令的好坏决定了网页生成的…...

云计算实训16——关于web,http协议,https协议,apache,nginx的学习与认知
一、web基本概念和常识 1.Web Web 服务是动态的、可交互的、跨平台的和图形化的为⽤户提供的⼀种在互联⽹上浏览信息的服务。 2.web服务器(web server) 也称HTTP服务器(HTTP server),主要有 Nginx、Apache、Tomcat 等。…...
2024年必备技能:小红书笔记评论自动采集,零基础也能学会的方法
摘要: 面对信息爆炸的2024年,小红书作为热门社交平台,其笔记评论成为市场洞察的金矿。本文将手把手教你,即便编程零基础,也能轻松学会利用Python自动化采集小红书笔记评论,解锁营销新策略,提升…...

手游刚开服就被攻击怎么办?如何防御DDoS?
开服初期是手游最脆弱的阶段,极易成为DDoS攻击的目标。一旦遭遇攻击,可能导致服务器瘫痪、玩家流失,甚至造成巨大经济损失。本文为开发者提供一套简洁有效的应急与防御方案,帮助快速应对并构建长期防护体系。 一、遭遇攻击的紧急应…...

Prompt Tuning、P-Tuning、Prefix Tuning的区别
一、Prompt Tuning、P-Tuning、Prefix Tuning的区别 1. Prompt Tuning(提示调优) 核心思想:固定预训练模型参数,仅学习额外的连续提示向量(通常是嵌入层的一部分)。实现方式:在输入文本前添加可训练的连续向量(软提示),模型只更新这些提示参数。优势:参数量少(仅提…...

华为OD机试-食堂供餐-二分法
import java.util.Arrays; import java.util.Scanner;public class DemoTest3 {public static void main(String[] args) {Scanner in new Scanner(System.in);// 注意 hasNext 和 hasNextLine 的区别while (in.hasNextLine()) { // 注意 while 处理多个 caseint a in.nextIn…...

2025盘古石杯决赛【手机取证】
前言 第三届盘古石杯国际电子数据取证大赛决赛 最后一题没有解出来,实在找不到,希望有大佬教一下我。 还有就会议时间,我感觉不是图片时间,因为在电脑看到是其他时间用老会议系统开的会。 手机取证 1、分析鸿蒙手机检材&#x…...

CMake 从 GitHub 下载第三方库并使用
有时我们希望直接使用 GitHub 上的开源库,而不想手动下载、编译和安装。 可以利用 CMake 提供的 FetchContent 模块来实现自动下载、构建和链接第三方库。 FetchContent 命令官方文档✅ 示例代码 我们将以 fmt 这个流行的格式化库为例,演示如何: 使用 FetchContent 从 GitH…...

Android 之 kotlin 语言学习笔记三(Kotlin-Java 互操作)
参考官方文档:https://developer.android.google.cn/kotlin/interop?hlzh-cn 一、Java(供 Kotlin 使用) 1、不得使用硬关键字 不要使用 Kotlin 的任何硬关键字作为方法的名称 或字段。允许使用 Kotlin 的软关键字、修饰符关键字和特殊标识…...

听写流程自动化实践,轻量级教育辅助
随着智能教育工具的发展,越来越多的传统学习方式正在被数字化、自动化所优化。听写作为语文、英语等学科中重要的基础训练形式,也迎来了更高效的解决方案。 这是一款轻量但功能强大的听写辅助工具。它是基于本地词库与可选在线语音引擎构建,…...

springboot整合VUE之在线教育管理系统简介
可以学习到的技能 学会常用技术栈的使用 独立开发项目 学会前端的开发流程 学会后端的开发流程 学会数据库的设计 学会前后端接口调用方式 学会多模块之间的关联 学会数据的处理 适用人群 在校学生,小白用户,想学习知识的 有点基础,想要通过项…...

R 语言科研绘图第 55 期 --- 网络图-聚类
在发表科研论文的过程中,科研绘图是必不可少的,一张好看的图形会是文章很大的加分项。 为了便于使用,本系列文章介绍的所有绘图都已收录到了 sciRplot 项目中,获取方式: R 语言科研绘图模板 --- sciRplothttps://mp.…...
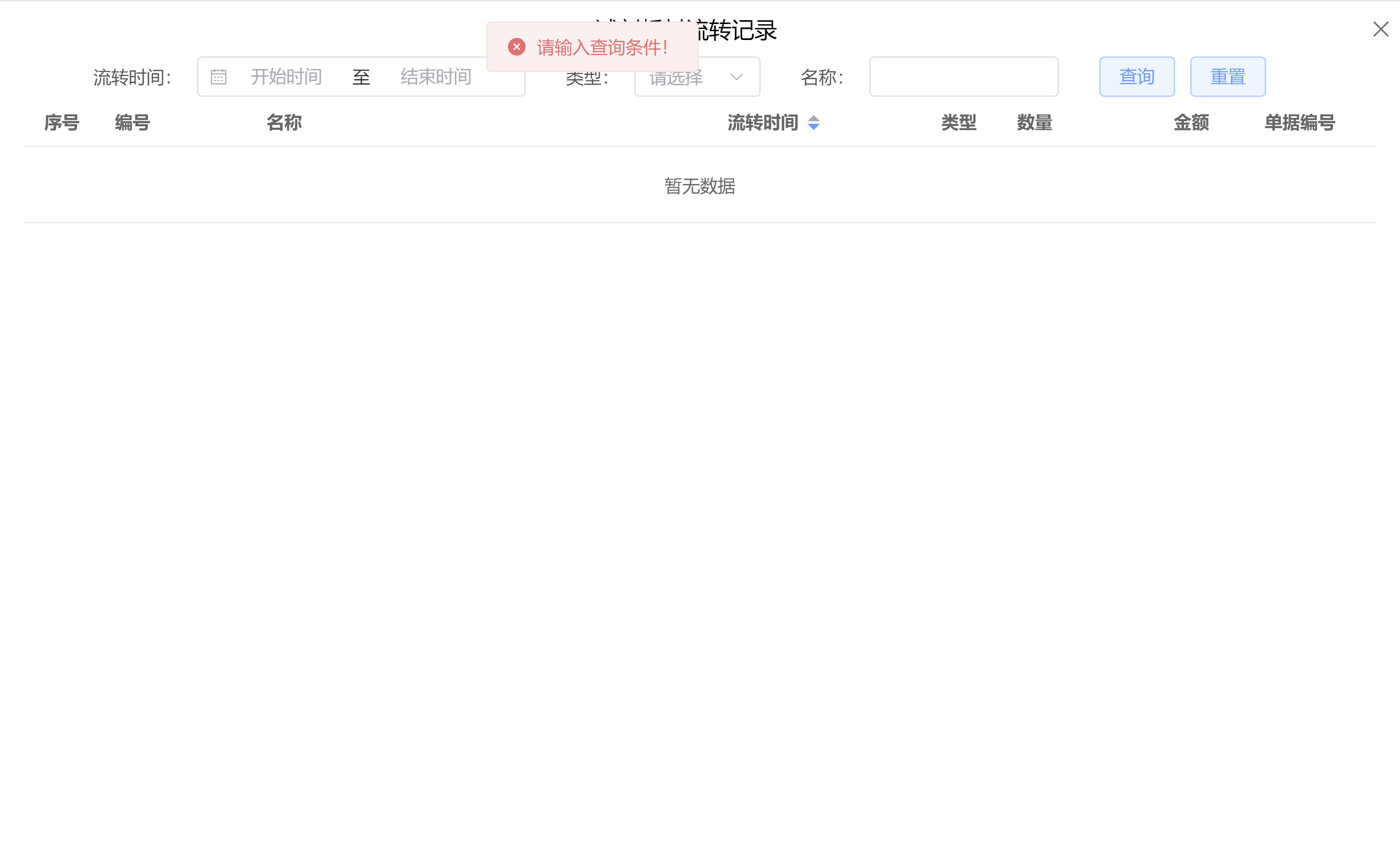
Java后端检查空条件查询
通过抛出运行异常:throw new RuntimeException("请输入查询条件!");BranchWarehouseServiceImpl.java // 查询试剂交易(入库/出库)记录Overridepublic List<BranchWarehouseTransactions> queryForReagent(Branch…...