数据驱动未来:构建下一代湖仓一体电商数据分析平台,引领实时商业智能革命
1.1 项目背景
本项目是一个创新的湖仓一体实时电商数据分析平台,旨在为电商平台提供深度的数据洞察和业务分析。技术层面,项目涵盖了从基础架构搭建到大数据技术组件的集成,采用了湖仓一体的设计理念,实现了数据仓库与数据湖的有效融合。这一架构创新旨在打通数据流通的壁垒,支持企业级项目的离线与实时数据指标分析,确保数据分析的全面性和时效性。
在业务应用方面,项目初期重点关注会员和商品两大核心主题。通过精细化的数据分析,我们提供了一系列关键指标,包括但不限于用户实时登录行为、页面浏览量(PV)与独立访客(UV)的实时统计、商品浏览信息的动态分析,以及用户积分体系的深度挖掘。这些分析指标将为平台运营提供数据支撑,优化用户体验,并驱动业务增长。展望未来,我们计划进一步扩展业务分析的广度与深度,增加更多业务指标,并不断完善技术架构,以适应不断变化的市场需求。我们致力于通过该项目,为客户提供一个可靠、灵活且功能强大的数据分析解决方案,帮助他们在电商领域中捕捉机遇,实现价值最大化。
1.2 项目架构
1.2.1实时数仓现状
目前,基于Hive构建的离线数据仓库技术已经达到了高度成熟的状态。然而,随着实时计算引擎技术的飞速进步以及业务领域对实时报表生成需求的日益增长,业界近年来一直在紧密关注并积极投身于实时数据仓库的构建与优化。在数据仓库架构的演进历程中,Lambda架构作为一个标志性的阶段,它融合了离线处理和实时处理两种数据处理途径,为满足多样化的数据处理需求提供了有效的解决方案。这种架构通过精心设计的数据处理流程,确保了数据处理的高效率和高可靠性,同时也为实时数仓的进一步发展奠定了坚实的基础,其架构图如下:

正是由于在Lambda架构中存在离线和实时两条数据处理链路,这种双重路径有时会引发数据一致性问题。为了解决这些问题并简化数据处理流程,Kappa架构应运而生。

Kappa架构以其简洁和高效的特点,被誉为实现真正实时数仓的理想架构。在业界,Flink与Kafka的结合是实现Kappa架构的典型方式。然而,即便如此强大的组合也并非完美无缺。以下是Kappa架构的一些显著缺陷:
-
数据存储限制:Kafka在处理海量数据存储方面存在局限。对于数据量巨大的业务场景,Kafka通常只能保留短期内的数据,如最近一周或甚至仅一天。
-
OLAP查询效率:Kafka并不擅长支持高效的OLAP(在线分析处理)查询。许多业务场景需要在DWD(数据仓库详细层)和DWS(数据仓库服务层)进行即时查询,而Kafka在这方面的支持并不尽如人意。
-
数据管理和血缘:Kappa架构难以复用现有的、成熟的离线数仓数据血缘和数据质量管理机制。企业可能需要重新构建一套完整的数据血缘和数据质量管理系统。
-
数据更新限制:Kafka目前不支持update或upsert操作,仅支持数据的追加。在DWS层,可能需要对数据进行更新,尤其是在数据聚合和时间窗口处理时,Kafka无法满足这些需求。
因此,在实时数仓的构建中,许多企业并没有完全采用Kappa架构,而是选择了混合架构,以兼顾实时性和离线数据处理的需求。尽管Kappa架构在提高数据报表的时效性方面取得了一定进展,但它依然面临诸多挑战。除了上述问题,对于那些实时业务需求密集的公司,Kappa架构可能还需要针对特定层的Kafka数据重新编写实时处理程序,这无疑增加了操作的复杂性和不便。
随着数据湖技术的发展,Kappa架构在实现批量数据和实时数据的统一计算方面展现出了巨大的潜力。这一趋势催生了“批流一体”的概念,它指的是在数据处理的不同层面上实现批量和流式数据的无缝集成。
在业界,对“批流一体”的理解存在两种主要视角:
-
开发层面的统一:一些观点认为,当批量处理和流处理的逻辑能够通过相同的SQL语句来实现时,就达到了批流一体。这种方式简化了开发流程,使得开发者能够用统一的逻辑来处理不同类型的数据。
-
计算引擎层面的集成:另一些观点则强调计算引擎层面的统一。例如,Spark及其相关组件(如Spark Streaming、Structured Streaming)和Flink等框架,已经在计算引擎层面实现了批处理和流处理的集成。这种集成使得同一引擎能够同时处理批量作业和实时数据流。
无论从哪个角度来看,批流一体的核心都在于存储层面的统一。数据湖技术提供了一个统一的存储解决方案,使得批量数据和实时数据能够共存于同一环境中,实现统一的处理和计算。
通过将离线数仓和实时数仓的数据统一存储在数据湖中,我们能够构建起“湖仓一体”的架构。这种架构不仅简化了数据管理,还提高了数据处理的灵活性和效率。例如,使用Iceberg作为数据湖的存储解决方案,可以解决Kappa架构中的许多挑战,使得Kappa架构更加完善和高效。
在这种“湖仓一体”的架构下,Kappa架构的实现变得更加简洁和强大。数据湖技术的应用使得数据的存储、处理和分析更加一体化,为企业提供了一个更加灵活和高效的数据处理平台。这种架构的构建已经成为许多大型公司在处理离线和实时数据时的首选方案,它代表了数据处理领域的未来趋势。

在现代数据处理架构中,数据湖技术尤其是Iceberg的引入,为Kappa架构带来了革新性的改进。这一架构的演进,通过将数据存储统一到数据湖Iceberg上,无论是流处理还是批处理,都实现了存储层面的高效整合。以下是该架构解决Kappa架构痛点的几个关键方面:
-
数据存储容量:数据湖Iceberg建立在HDFS之上,提供了一个可扩展的文件管理系统,有效解决了Kafka在数据存储量上的限制,能够处理大规模数据集。
-
OLAP查询支持:数据湖架构允许DW层数据继续支持高效的OLAP查询。通过适配现有的OLAP查询引擎,可以无缝地进行交互式分析和即席查询。
-
数据管理和治理:统一的存储基础使得可以复用一套数据血缘和数据质量管理工具和流程,简化了数据治理工作,提高了数据的可管理性和可追溯性。
-
实时数据更新:数据湖技术提供了对实时数据更新的支持,这对于需要动态调整和维护数据准确性的场景至关重要。
此外,该架构可以被视为Kappa架构的优化版本,它保留了两条数据链路的设计模式:
- 离线数据链路:基于Spark的批处理能力,适用于数据的全量处理和修正,以及其他非实时数据处理需求。
- 实时数据链路:基于Flink的流处理能力,用于处理实时数据流,确保数据的实时性和动态性。
这种混合链路架构不仅提高了数据处理的灵活性,还增强了数据的准确性和可靠性。在数据修正和非常规场景下,离线链路发挥着重要作用,而实时链路则保障了日常业务的连续性和报表的即时生成。
综上所述,这一架构通过巧妙地融合了数据湖技术和现代计算引擎,不仅解决了Kappa架构的多项挑战,还为构建一个可落地的实时数仓方案提供了坚实的基础,实现了实时报表的快速产出,满足了企业对实时数据分析的迫切需求。
1.2.2 项目架构及数据分层
在本项目中,我们采用了前沿的数据湖技术——Apache Iceberg,来构建一个创新的“湖仓一体”架构。这一架构的核心优势在于其能够无缝地整合实时和离线分析能力,专门针对电商业务指标进行优化。

在本项目中,我们采用了先进的数据湖技术——Apache Iceberg,来构建一个创新的“湖仓一体”架构,旨在实现对电商业务指标的实时和离线分析。以下是我们项目数据处理流程的详细描述:
-
数据采集:
- 我们的项目涉及两类主要数据源:一是来自MySQL的业务数据库数据,二是用户行为日志数据。
- 这两类数据通过特定的数据采集工具,被实时地收集并发送到Kafka的不同topic中。
-
数据摄入与处理:
- 使用Flink作为数据处理引擎,从Kafka的相应topic中读取业务和日志数据。
- Flink对数据进行必要的清洗、转换和聚合操作,以适应后续的分析需求。
-
数据存储与Iceberg-ODS层:
- 处理后的数据首先存储在Iceberg的ODS(操作数据存储)层中。
- 由于Flink在处理Iceberg时可能存在的数据消费位置信息保存问题,我们同时将数据写入Kafka,利用Flink的offset维护机制确保程序在停止和重启后能正确地继续消费数据。
-
数据仓库分层:
- 我们的架构基于Iceberg构建了多层数据仓库模型,每一层都针对不同的数据处理和分析需求。
-
实时数据分析:
- 实时分析的数据结果被存储在Clickhouse中,利用其优异的查询性能来支持快速的实时数据分析。
-
离线数据分析:
- 离线数据分析结果则从Iceberg的DWS(数据仓库服务层)中获取,确保了数据分析的深度和广度。
-
数据存储与展示:
- 分析结果最终存储在MySQL数据库中,用于长期的业务回顾和决策支持。
- 通过先进的数据可视化工具,我们将Clickhouse和MySQL中的分析结果以直观、易理解的形式展现出来。
-
架构优势:
- 整个架构的优势在于其灵活性和扩展性,能够适应不断变化的业务需求和数据量增长。
- 同时,它还能够保证数据处理的实时性和准确性,为业务决策提供强有力的数据支持。
通过这种综合运用多种数据处理技术的方式,我们的项目能够高效地处理和分析大规模数据,为电商业务提供深刻的洞察和实时的决策支持。
1.2.3项目可视化效果

1.3项目使用技术及版本
在项目中,使用了多种大数据技术组件来构建一个高效、可靠的数据处理和分析平台。以下是项目中使用的技术组件及其版本概览:
| 使用技术 | 版本 |
|---|---|
| Zookeeper | 3.4.13 |
| HDFS | 3.1.4/3.2.2 |
| Hive | 3.1.2 |
| (MySQL 5.7.32) | |
| Iceberg | 0.11.1 |
| HBase | 2.2.6 |
| Phoenix | 5.0.0 |
| Kafka | 0.11.0.3 |
| Redis | 2.8.18 |
| Flink | 1.11.6 |
| Flume | 1.9.0 |
| Maxwell | 1.28.2 |
| ClickHouse | 21.9.4.35 |
1.4 项目基础环境的准备
基础环境的准备是确保大数据组件顺利安装和运行的关键步骤
考虑到容器化部署的便利性,也可以使用Docker安装相应的组件。但在本项目中,为了更好地理解各个组件和流程,选择使用二进制部署方式。
基础环境:
在 windows 上 安装 VMware 并安装,centos7 。
节点配置:
每台节点配置了4GB内存和4个CPU核心,这为运行大数据组件提供了基本的硬件支持。
网络设置:
关闭了每台节点的防火墙,确保网络通信不受限制。
配置了每台节点的主机名,便于管理和识别。
配置了YUM源,确保软件包能够顺利下载和更新。
时间同步:
确保了所有节点之间的时间同步,这对于分布式系统的一致性和日志记录非常重要。
SSH设置:
实现了各个节点之间的SSH密钥认证,使得节点间可以免密码登录,方便管理和维护。
实现各个节点之间的SSH密钥认证是一个重要的步骤,它允许无密码登录到远程服务器,从而简化了管理和维护过程。以下是实现这一目标的步骤:
-
生成SSH密钥对:
在主节点上(例如node1),生成SSH密钥对。如果不指定,SSH将自动生成一个默认的RSA密钥对。ssh-keygen -t rsa -
复制公钥到其他节点:
将公钥复制到所有其他节点的~/.ssh/authorized_keys文件中。这可以通过SSH-copy-id命令完成:ssh-copy-id node2 ssh-copy-id node3 ssh-copy-id node4 ssh-copy-id node5 -
验证SSH密钥认证:
测试从主节点到其他节点的SSH连接,看是否能够无密码登录:ssh node2 ssh node3 ssh node4 ssh node5 -
配置SSH免密登录:
在~/.ssh/config文件中为每个节点配置免密登录,这样SSH客户端就会自动使用正确的密钥进行认证:Host node2HostName 192.168.179.5User your_usernameIdentityFile ~/.ssh/id_rsaHost node3HostName 192.168.179.6User your_usernameIdentityFile ~/.ssh/id_rsa# 为其他节点重复上述配置 -
确保SSH服务配置正确:
在所有节点上,编辑/etc/ssh/sshd_config文件,确保以下配置项正确:PubkeyAuthentication yes AuthorizedKeysFile .ssh/authorized_keys -
重启SSH服务:
在所有节点上,重启SSH服务以应用配置更改:sudo systemctl restart sshd -
确保防火墙规则允许SSH:
如果您的防火墙在稍后重新启用,确保防火墙规则允许SSH端口(默认为22):sudo firewall-cmd --permanent --add-service=ssh sudo firewall-cmd --reload
通过这些步骤,您可以在多个节点之间实现SSH密钥认证,从而无需每次手动输入密码即可登录到远程服务器。这对于自动化任务和批量管理非常有用。
JDK安装:
安装了Java开发工具包(JDK),为运行Java编写的大数据应用程序提供了环境支持。
| 节点IP | 节点名称 |
|---|---|
| 192.168.179.4 | node1 |
| 192.168.179.5 | node2 |
| 192.168.179.6 | node3 |
| 192.168.179.7 | node4 |
| 192.168.179.8 | node5 |
1.4.1搭建Zookeeper
以下展示了Zookeeper集群的节点IP、节点名称以及对应的角色分布:
| 节点IP | 节点名称 | Zookeeper |
| --------------- | -------- | --------- |
| 192.168.179.4 | node1 | |
| 192.168.179.5 | node2 | |
| 192.168.179.6 | node3 | ★ |
| 192.168.179.7 | node4 | ★ |
| 192.168.179.8 | node5 | ★ |
在这个表格中,★ 表示该节点将作为Zookeeper服务的实例运行。
以下是搭建Zookeeper集群的具体步骤:
1. 准备环境
- 在所有节点(node1, node2, node3, node4, node5)创建
/software目录,用于后续安装技术组件。mkdir -p /software
2. 上传并解压Zookeeper
- 将Zookeeper安装包上传至
node3的/software目录,并解压。tar -zxvf zookeeper-3.4.13.tar.gz -C /software
3. 配置环境变量
- 在
node3配置Zookeeper环境变量。echo 'export ZOOKEEPER_HOME=/software/zookeeper-3.4.13' >> /etc/profile echo 'export PATH=$PATH:$ZOOKEEPER_HOME/bin' >> /etc/profile source /etc/profile
4. 配置Zookeeper
- 在
node3编辑Zookeeper配置文件。mv /software/zookeeper-3.4.13/conf/zoo_sample.cfg /software/zookeeper-3.4.13/conf/zoo.cfg - 修改
zoo.cfg文件,设置集群配置:tickTime=2000 initLimit=10 syncLimit=5 dataDir=/opt/data/zookeeper clientPort=2181 server.1=node3:2888:3888 server.2=node4:2888:3888 server.3=node5:2888:3888
5. 分发Zookeeper配置
- 将配置好的Zookeeper发送至
node4和node5。scp -r /software/zookeeper-3.4.13 node4:/software/ scp -r /software/zookeeper-3.4.13 node5:/software/
6. 创建数据目录并配置环境变量
- 在
node3,node4,node5创建数据目录。mkdir -p /opt/data/zookeeper - 在
node4和node5配置Zookeeper环境变量。echo 'export ZOOKEEPER_HOME=/software/zookeeper-3.4.13' >> /etc/profile echo 'export PATH=$PATH:$ZOOKEEPER_HOME/bin' >> /etc/profile source /etc/profile
7. 创建节点ID文件
- 在
node3,node4,node5的/opt/data/zookeeper路径中添加myid文件,并分别写入1, 2, 3。echo 1 > /opt/data/zookeeper/myid echo 2 > /opt/data/zookeeper/myid echo 3 > /opt/data/zookeeper/myid
8. 启动Zookeeper并检查状态
- 在各个节点启动Zookeeper。
zkServer.sh start - 检查Zookeeper进程状态。
zkServer.sh status
通过这些步骤,您可以在node3, node4, node5上搭建一个Zookeeper集群,为后续的大数据组件提供服务。确保在每个节点上重复相应的配置和启动步骤,以确保集群的一致性和稳定性。
以下是搭建HDFS集群的具体步骤,以及对应的角色分布表格,使用Markdown格式编写:
1.4.2搭建HDFS
HDFS集群角色分布
| 节点IP | 节点名称 | NN | DN | ZKFC | JN | RM | NM |
|---|---|---|---|---|---|---|---|
| 192.168.179.4 | node1 | ★ | ★ | ★ | ★ | ||
| 192.168.179.5 | node2 | ★ | ★ | ★ | ★ | ||
| 192.168.179.6 | node3 | ★ | ★ | ★ | |||
| 192.168.179.7 | node4 | ★ | ★ | ★ | |||
| 192.168.179.8 | node5 | ★ | ★ | ★ |
搭建HDFS集群步骤
-
安装依赖:在所有节点安装HDFS HA自动切换必须的依赖。
yum -y install psmisc -
上传并解压Hadoop:将Hadoop安装包上传至
node1并解压。tar -zxvf hadoop-3.1.4.tar.gz -C /software -
配置环境变量:在
node1配置Hadoop环境变量。echo 'export HADOOP_HOME=/software/hadoop-3.1.4/' >> /etc/profile echo 'export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:' >> /etc/profile source /etc/profile -
配置
hadoop-env.sh:设置JAVA_HOME。
在$HADOOP_HOME/etc/hadoop目录下,编辑hadoop-env.sh文件,添加以下内容:export JAVA_HOME=/usr/java/jdk1.8.0_181-amd64/ -
配置
hdfs-site.xml:编辑配置项,包括逻辑名称、权限禁用、NameNode名称、编辑日志目录等。
配置路径:$HADOOP_HOME/etc/hadoop下的hdfs-site.xml文件
<configuration><property><!--这里配置逻辑名称,可以随意写 --><name>dfs.nameservices</name><value>mycluster</value></property><property><!-- 禁用权限 --><name>dfs.permissions.enabled</name><value>false</value></property><property><!-- 配置namenode 的名称,多个用逗号分割 --><name>dfs.ha.namenodes.mycluster</name><value>nn1,nn2</value></property><property><!-- dfs.namenode.rpc-address.[nameservice ID].[name node ID] namenode 所在服务器名称和RPC监听端口号 --><name>dfs.namenode.rpc-address.mycluster.nn1</name><value>node1:8020</value></property><property><!-- dfs.namenode.rpc-address.[nameservice ID].[name node ID] namenode 所在服务器名称和RPC监听端口号 --><name>dfs.namenode.rpc-address.mycluster.nn2</name><value>node2:8020</value></property><property><!-- dfs.namenode.http-address.[nameservice ID].[name node ID] namenode 监听的HTTP协议端口 --><name>dfs.namenode.http-address.mycluster.nn1</name><value>node1:50070</value></property><property><!-- dfs.namenode.http-address.[nameservice ID].[name node ID] namenode 监听的HTTP协议端口 --><name>dfs.namenode.http-address.mycluster.nn2</name><value>node2:50070</value></property><property><!-- namenode 共享的编辑目录, journalnode 所在服务器名称和监听的端口 --><name>dfs.namenode.shared.edits.dir</name><value>qjournal://node3:8485;node4:8485;node5:8485/mycluster</value></property><property><!-- namenode高可用代理类 --><name>dfs.client.failover.proxy.provider.mycluster</name><value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value></property><property><!-- 使用ssh 免密码自动登录 --><name>dfs.ha.fencing.methods</name><value>sshfence</value></property><property><name>dfs.ha.fencing.ssh.private-key-files</name><value>/root/.ssh/id_rsa</value></property><property><!-- journalnode 存储数据的地方 --><name>dfs.journalnode.edits.dir</name><value>/opt/data/journal/node/local/data</value></property><property><!-- 配置namenode自动切换 --><name>dfs.ha.automatic-failover.enabled</name><value>true</value></property></configuration>
- 配置
core-site.xml:设置Hadoop客户端默认路径、Hadoop临时目录、Zookeeper集群地址。
配置路径:$HADOOP_HOME/ect/hadoop/core-site.xml
<configuration><property><!-- 为Hadoop 客户端配置默认的高可用路径 --><name>fs.defaultFS</name><value>hdfs://mycluster</value></property><property><!-- Hadoop 数据存放的路径,namenode,datanode 数据存放路径都依赖本路径,不要使用 file:/ 开头,使用绝对路径即可namenode 默认存放路径 :file://${hadoop.tmp.dir}/dfs/namedatanode 默认存放路径 :file://${hadoop.tmp.dir}/dfs/data--><name>hadoop.tmp.dir</name><value>/opt/data/hadoop/</value></property><property><!-- 指定zookeeper所在的节点 --><name>ha.zookeeper.quorum</name><value>node3:2181,node4:2181,node5:2181</value></property></configuration>
- 配置
yarn-site.xml:设置YARN辅助服务、环境变量白名单、YARN ResourceManager高可用配置。
配置路径:$HADOOP_HOME/etc/hadoop/yarn-site.xml
<configuration><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.nodemanager.env-whitelist</name><value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value></property><property><!-- 配置yarn为高可用 --><name>yarn.resourcemanager.ha.enabled</name><value>true</value></property><property><!-- 集群的唯一标识 --><name>yarn.resourcemanager.cluster-id</name><value>mycluster</value></property><property><!-- ResourceManager ID --><name>yarn.resourcemanager.ha.rm-ids</name><value>rm1,rm2</value></property><property><!-- 指定ResourceManager 所在的节点 --><name>yarn.resourcemanager.hostname.rm1</name><value>node1</value></property><property><!-- 指定ResourceManager 所在的节点 --><name>yarn.resourcemanager.hostname.rm2</name><value>node2</value></property><property><!-- 指定ResourceManager Http监听的节点 --><name>yarn.resourcemanager.webapp.address.rm1</name><value>node1:8088</value></property><property><!-- 指定ResourceManager Http监听的节点 --><name>yarn.resourcemanager.webapp.address.rm2</name><value>node2:8088</value></property><property><!-- 指定zookeeper所在的节点 --><name>yarn.resourcemanager.zk-address</name><value>node3:2181,node4:2181,node5:2181</value>
</property>
<property><!-- 关闭虚拟内存检查 --><name>yarn.nodemanager.vmem-check-enabled</name><value>false</value>
</property><!-- 启用节点的内容和CPU自动检测,最小内存为1G --><!--<property><name>yarn.nodemanager.resource.detect-hardware-capabilities</name><value>true</value></property>-->
</configuration>
- 配置
mapred-site.xml:设置MapReduce框架名称。
配置路径:$HADOOP_HOME/etc/hadoop/mapred-site.xml
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property>
</configuration>
- 配置
workers文件:列出所有工作节点。
配置路径:$HADOOP_HOME/etc/hadoop/workers
[root@node1 ~]# vim /software/hadoop-3.1.4/etc/hadoop/workers
node3
node4
node5
- 添加用户参数:在启动脚本中添加用户参数,防止启动错误。
配置路径:$HADOOP_HOME/sbin/start-dfs.sh 和stop-dfs.sh
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_JOURNALNODE_USER=root
HDFS_ZKFC_USER=root
配置路径:$HADOOP_HOME/sbin/start-yarn.sh和stop-yarn.sh
YARN_RESOURCEMANAGER_USER=root
YARN_NODEMANAGER_USER=root
- 分发Hadoop安装包:将Hadoop安装包发送到其他4个节点。
[root@node1 ~]# scp -r /software/hadoop-3.1.4 node2:/software/
[root@node1 ~]# scp -r /software/hadoop-3.1.4 node3:/software/
[root@node1 ~]# scp -r /software/hadoop-3.1.4 node4:/software/
[root@node1 ~]# scp -r /software/hadoop-3.1.4 node5:/software/
- 配置其他节点的环境变量:在node2、node3、node4、node5节点配置HADOOP_HOME。
#分别在node2、node3、node4、node5节点上配置HADOOP_HOME
vim /etc/profile
export HADOOP_HOME=/software/hadoop-3.1.4/
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:#最后记得Source
source /etc/profile
- 启动HDFS和YARN服务:格式化Zookeeper、启动JournalNode、格式化NameNode、同步Standby NameNode、启动HDFS和YARN。
#在node3,node4,node5节点上启动zookeeper
zkServer.sh start#在node1上格式化zookeeper
[root@node1 ~]# hdfs zkfc -formatZK#在每台journalnode中启动所有的journalnode,这里就是node3,node4,node5节点上启动
hdfs --daemon start journalnode#在node1中格式化namenode
[root@node1 ~]# hdfs namenode -format#在node1中启动namenode,以便同步其他namenode
[root@node1 ~]# hdfs --daemon start namenode#高可用模式配置namenode,使用下列命令来同步namenode(在需要同步的namenode中执行,这里就是在node2上执行):
[root@node2 software]# hdfs namenode -bootstrapStandby#node1上启动HDFS,启动Yarn
[root@node1 sbin]# start-dfs.sh
[root@node1 sbin]# start-yarn.sh
注意以上也可以使用start-all.sh命令启动Hadoop集群。
- 访问WebUI:通过Web界面访问HDFS和YARN的状态。

#访问Yarn WebUI :http://node1:8088

- 停止集群:使用相应命令停止Hadoop集群服务。
#停止集群
[root@node1 ~]# stop-dfs.sh
[root@node1 ~]# stop-yarn.sh
注意:以上也可以使用 stop-all.sh 停止集群。
1.4.3搭建Hive
搭建Hive的版本为3.1.2,下图展示了Hive搭建的节点IP、节点名称以及对应的角色分布:
| 节点IP | 节点名称 | Hive服务器 | Hive客户端 | MySQL |
|---|---|---|---|---|
| 192.168.179.4 | node1 | ★ | ||
| 192.168.179.5 | node2 | ★ | ★ (已搭建) | |
| 192.168.179.6 | node3 | ★ |
以下是搭建Hive集群的具体步骤,包括您已经开始的步骤:
1. 上传并解压Hive安装包到node1节点
- 切换到
/software目录,上传并解压Hive安装包。cd /software/ tar -zxvf ./apache-hive-3.1.2-bin.tar.gz mv apache-hive-3.1.2-bin hive-3.1.2
2. 发送Hive安装包到其他节点
- 将Hive安装包发送到
node3节点。scp -r /software/hive-3.1.2/ node3:/software/
3. 配置Hive环境变量
- 在
node1和node3上设置Hive的环境变量。echo 'export HIVE_HOME=/software/hive-3.1.2' >> /etc/profile echo 'export PATH=$PATH:$HIVE_HOME/bin' >> /etc/profile source /etc/profile
4. 配置Hive的配置文件
- 编辑Hive的配置文件
hive-site.xml来设置Hive的运行环境,在node1节点$HIVE_HOME/conf下创建hive-site.xml并配置。
<configuration><property><name>hive.metastore.warehouse.dir</name><value>/user/hive/warehouse</value></property><property><name>javax.jdo.option.ConnectionURL</name><value>jdbc:mysql://node2:3306/hive?createDatabaseIfNotExist=true&useSSL=false</value></property><property><name>javax.jdo.option.ConnectionDriverName</name><value>com.mysql.jdbc.Driver</value></property><property><name>javax.jdo.option.ConnectionUserName</name><value>root</value></property><property><name>javax.jdo.option.ConnectionPassword</name><value>123456</value></property>
</configuration>
5. 在node3节点 配置Hive的配置文件
<configuration><property><name>hive.metastore.warehouse.dir</name><value>/user/hive/warehouse</value></property><property><name>hive.metastore.local</name><value>false</value></property><property><name>hive.metastore.uris</name><value>thrift://node1:9083</value></property>
</configuration>
6. node1、node3节点删除$HIVE_HOME/lib下“guava”包,使用Hadoop下的包替换
#删除Hive lib目录下“guava-19.0.jar ”包
[root@node1 ~]# rm -rf /software/hive-3.1.2/lib/guava-19.0.jar
[root@node3 ~]# rm -rf /software/hive-3.1.2/lib/guava-19.0.jar #将Hadoop lib下的“guava”包拷贝到Hive lib目录下
[root@node1 ~]# cp /software/hadoop-3.1.4/share/hadoop/common/lib/guava-27.0-jre.jar /software/hive-3.1.2/lib/[root@node3 ~]# cp /software/hadoop-3.1.4/share/hadoop/common/lib/guava-27.0-jre.jar /software/hive-3.1.2/lib/
7.将“mysql-connector-java-5.1.47.jar”驱动包上传到node1节点的$HIVE_HOME/lib目录下
上传后,需要将mysql驱动包传入$HIVE_HOME/lib/目录下,这里node1,node3节点都需要传入。
8.在node1节点中初始化Hive
#初始化hive,hive2.x版本后都需要初始化
[root@node1 ~]# schematool -dbType mysql -initSchema
9.在服务端和客户端操作Hive
#在node1中登录Hive ,创建表test
[root@node1 conf]# hive
hive> create table test (id int,name string,age int ) row format delimited fields terminated by '\t';#向表test中插入数据
hive> insert into test values(1,"zs",18);#在node1启动Hive metastore
[root@node1 hadoop]# hive --service metastore &#在node3上登录Hive客户端查看表数据
[root@node3 lib]# hive
hive> select * from test;
OK
1 zs 18
1.4.4Hive与Iceberg整合
以下展示了Hive 2.x与Hive 3.1.2版本对Iceberg表格式支持的操作:
| 操作 | Hive 2.x | Hive 3.1.2 |
|------------------|-----------|------------|
| CREATE EXTERNAL TABLE | √ | √ |
| CREATE TABLE | √ | √ |
| DROP TABLE | √ | √ |
| SELECT | √ | √ |
| INSERT INTO | √ | √ |
在这个表格中,"√"表示对应的Hive版本支持该操作。
1.4.4.1开启Hive支持Iceberg
1.下载iceberg-hive-runtime.jar
要实现Hive对Iceberg表的查询支持,首先需要下载“iceberg-hive-runtime.jar”,Hive通过该Jar可以加载Hive或者更新Iceberg表元数据信息。下载地址

将以上jar包下载后,上传到Hive服务端和客户端对应的HIVE_HOME/lib目录下。另外在向Hive中Iceberg格式表插入数据时需要到“libfb303-0.9.3.jar”包(jar可以自行maven下载),将此包也上传到Hive服务端和客户端对应的$HIVE_HOME/lib目录下。
2.配置hive-site.xml
在Hive客户端$HIVE_HOME/conf/hive-site.xml中追加如下配置:
<property><name>iceberg.engine.hive.enabled</name><value>true</value>
</property>
1.4.4.2 Hive中操作Iceberg格式表
从Hive引擎的视角来看,Catalog扮演着关键角色,它主要负责描述数据集的位置信息,即存储元数据。在Hive与Iceberg的整合过程中,Iceberg展现了对多种Catalog类型的支持,包括Hive原生的Catalog、Hadoop,以及第三方服务如AWS Glue,还有自定义Catalog的可能性。这种多样性使得Hive在实际应用中可以灵活地使用不同的Catalog类型,甚至能够实现跨Catalog类型的数据连接。
为了支持Hive对Iceberg表的读写操作,Hive引入了org.apache.iceberg.mr.hive.HiveIcebergStorageHandler类(包含在iceberg-hive-runtime.jar包中)。这个类允许Hive通过设置Hive配置属性iceberg.catalog.<catalog_name>.type来决定如何加载Iceberg表,这里的<catalog_name>是用户自定义的名称,用于在Hive中创建Iceberg格式的表,并配置Iceberg的Catalog属性。
以下是Hive中创建Iceberg格式表时的三种加载方式,这取决于是否在创建表时指定了iceberg.catalog属性值:
- 指定Catalog类型:如果在创建表时明确指定了
iceberg.catalog属性值,Hive将根据这个属性来确定Iceberg表的加载方式和数据存储位置。
这种情况就是说在Hive中创建Iceberg格式表时,如果指定了iceberg.catalog属性值,那么数据存储在指定的catalog名称对应配置的目录下。
在Hive客户端node3节点进入Hive,操作如下:
#注册一个HiveCatalog叫another_hive
hive> set iceberg.catalog.another_hive.type=hive;#在Hive中创建iceberg格式表
create table test_iceberg_tbl2(
id int,
name string,
age int
)
partitioned by (dt string)
stored by 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler'
tblproperties ('iceberg.catalog'='another_hive');#在Hive中加载如下两个包,在向Hive中插入数据时执行MR程序时需要使用到
hive> add jar /software/hive-3.1.2/lib/iceberg-hive-runtime-0.12.1.jar;
hive> add jar /software/hive-3.1.2/lib/libfb303-0.9.3.jar;#插入数据,并查询
hive> insert into test_iceberg_tbl2 values (2,"ls",20,"20211212");
hive> select * from test_iceberg_tbl2;
OK
2 ls 20 20211212
以上方式指定“iceberg.catalog.another_hive.type=hive”后,实际上就是使用的hive的catalog,这种方式与默认不设置效果一样,创建后的表存储在hive默认的warehouse目录下。也可以在建表时指定location 写上路径,将数据存储在自定义对应路径上。

除了可以将catalog类型指定成hive之外,还可以指定成hadoop,在Hive中创建对应的iceberg格式表时需要指定location来指定iceberg数据存储的具体位置,这个位置是具有一定格式规范的自定义路径。在Hive客户端node3节点进入Hive,操作如下:
#注册一个HadoopCatalog叫hadoop
hive> set iceberg.catalog.hadoop.type=hadoop;#使用HadoopCatalog时,必须设置“iceberg.catalog.<catalog_name>.warehouse”指定warehouse路径
hive> set iceberg.catalog.hadoop.warehouse=hdfs://mycluster/iceberg_data;#在Hive中创建iceberg格式表,这里创建成外表
create external table test_iceberg_tbl3(
id int,
name string,
age int
)
partitioned by (dt string)
stored by 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler'
location 'hdfs://mycluster/iceberg_data/default/test_iceberg_tbl3'
tblproperties ('iceberg.catalog'='hadoop');注意:以上location指定的路径必须是“iceberg.catalog.hadoop.warehouse”指定路径的子路径,格式必须是${iceberg.catalog.hadoop.warehouse}/${当前建表使用的hive库}/${创建的当前iceberg表名}#在Hive中加载如下两个包,在向Hive中插入数据时执行MR程序时需要使用到
hive> add jar /software/hive-3.1.2/lib/iceberg-hive-runtime-0.12.1.jar;
hive> add jar /software/hive-3.1.2/lib/libfb303-0.9.3.jar;#插入数据,并查询
hive> insert into test_iceberg_tbl3 values (3,"ww",20,"20211213");
hive> select * from test_iceberg_tbl3;
OK
3 ww 20 20211213
在指定的“iceberg.catalog.hadoop.warehouse”路径下可以看到创建的表目录:

- 使用默认Catalog:如果没有指定
iceberg.catalog属性,Hive将采用默认的Catalog配置来加载Iceberg表。
这种方式就是说如果在Hive中创建Iceberg格式表时,不指定iceberg.catalog属性,那么数据存储在对应的hive warehouse路径下。
在Hive客户端node3节点进入Hive,操作如下:
#在Hive中创建iceberg格式表
create table test_iceberg_tbl1(
id int ,
name string,
age int)
partitioned by (dt string)
stored by 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler';#在Hive中加载如下两个包,在向Hive中插入数据时执行MR程序时需要使用到
hive> add jar /software/hive-3.1.2/lib/iceberg-hive-runtime-0.12.1.jar;
hive> add jar /software/hive-3.1.2/lib/libfb303-0.9.3.jar;#向表中插入数据
hive> insert into test_iceberg_tbl1 values (1,"zs",18,"20211212");#查询表中的数据
hive> select * from test_iceberg_tbl1;
OK
1 zs 18 20211212
在Hive默认的warehouse目录下可以看到创建的表目录:

- 跨Catalog类型连接:如果iceberg.catalog属性设置为“location_based_table”,可以从指定的根路径下加载Iceberg 表
这种情况就是说如果HDFS中已经存在iceberg格式表,我们可以通过在Hive中创建Icerberg格式表指定对应的location路径映射数据。,在Hive客户端中操作如下:
CREATE TABLE test_iceberg_tbl4 (id int, name string,age int,dt string
)STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler'
LOCATION 'hdfs://mycluster/spark/person'
TBLPROPERTIES ('iceberg.catalog'='location_based_table');注意:指定的location路径下必须是iceberg格式表数据,并且需要有元数据目录才可以。不能将其他数据映射到Hive iceberg格式表。
注意:由于Hive建表语句分区语法“Partitioned by”的限制,如果使用Hive创建Iceberg格式表,目前只能按照Hive语法来写,底层转换成Iceberg标识分区,这种情况下不能使用Iceberge的分区转换,例如:days(timestamp),如果想要使用Iceberg格式表的分区转换标识分区,需要使用Spark或者Flink引擎创建表。
通过这种灵活的配置方式,Hive能够更好地与Iceberg集成,为用户提供了强大的数据管理和分析能力,同时也保持了对不同存储和元数据解决方案的兼容性。
1.4.5搭建HBase
HBase集群的节点IP、节点名称以及对应的HBase角色分布:
| 节点IP | 节点名称 | HBase服务 |
| --------------- | -------- | ---------------- |
| 192.168.179.6 | node3 | RegionServer |
| 192.168.179.7 | node4 | HMaster, RegionServer |
| 192.168.179.8 | node5 | RegionServer |
在这个表格中,HBase服务列列出了每个节点上运行的HBase服务角色。例如,node4同时运行了HMaster和RegionServer角色。
具体搭建步骤如下:
1.将下载好的安装包发送到node4节点上,并解压,配置环境变量
#将下载好的HBase安装包上传至node4节点/software下,并解压
[root@node4 software]# tar -zxvf ./hbase-2.2.6-bin.tar.gz
当前节点配置HBase环境变量
#配置HBase环境变量
[root@node4 software]# vim /etc/profile
export HBASE_HOME=/software/hbase-2.2.6/
export PATH=$PATH:$HBASE_HOME/bin#使环境变量生效
[root@node4 software]# source /etc/profile
2.配置$HBASE_HOME/conf/hbase-env.sh
#配置HBase JDK
export JAVA_HOME=/usr/java/jdk1.8.0_181-amd64/#配置 HBase不使用自带的zookeeper
export HBASE_MANAGES_ZK=false
3.配置$HBASE_HOME/conf/hbase-site.xml
<configuration><property><name>hbase.rootdir</name><value>hdfs://mycluster/hbase</value></property><property><name>hbase.cluster.distributed</name><value>true</value></property><property><name>hbase.zookeeper.quorum</name><value>node3,node4,node5</value></property><property><name>hbase.unsafe.stream.capability.enforce</name><value>false</value></property>
</configuration>
4.配置$HBASE_HOME/conf/regionservers,配置RegionServer节点
node3
node4
node5
5.配置backup-masters文件
手动创建$HBASE_HOME/conf/backup-masters文件,指定备用的HMaster,需要手动创建文件,这里写入node5,在HBase任意节点都可以启动HMaster,都可以成为备用Master ,可以使用命令:hbase-daemon.sh start master启动。
#创建 $HBASE_HOME/conf/backup-masters 文件,写入node5
[root@node4 conf]# vim backup-masters
node5
6.复制hdfs-site.xml到$HBASE_HOME/conf/下
[root@node4conf]# scp /software/hadoop-3.1.4/etc/hadoop/hdfs-site.xml /software/hbase-2.2.6/conf/7.将HBase安装包发送到node3,node5节点上,并在node3,node5节点上配置HBase环境变量
[root@node4 software]# cd /software
[root@node4 software]# scp -r ./hbase-2.2.6 node3:/software/
[root@node4 software]# scp -r ./hbase-2.2.6 node5:/software/注意:在node3、node5上配置HBase环境变量。
vim /etc/profile
export HBASE_HOME=/software/hbase-2.2.6/
export PATH=$PATH:$HBASE_HOME/bin#使环境变量生效
source /etc/profile
8.重启Zookeeper、重启HDFS及启动HBase集群
#注意:一定要重启Zookeeper,重启HDFS,在node4节点上启动HBase集群
[root@node4 software]# start-hbase.sh #访问WebUI,http://node4:16010。
停止集群:在任意一台节点上stop-hbase.sh

9.测试HBase集群
在Hbase中创建表test,指定’cf1’,'cf2’两个列族,并向表test中插入几条数据:
#进入hbase
[root@node4 ~]# hbase shell#创建表test
create 'test','cf1','cf2'#查看创建的表
list#向表test中插入数据
put 'test','row1','cf1:id','1'
put 'test','row1','cf1:name','zhangsan'
put 'test','row1','cf1:age',18#查询表test中rowkey为row1的数据
get 'test','row1'
1.4.6搭建Phoenix
以下展示了Phoenix的节点IP、节点名称以及Phoenix服务的分布情况:
| 节点IP | 节点名称 | Phoenix服务 |
| --------------- | --------- | ------------- |
| 192.168.179.7 | node4 | Phoenix Client |
在这个表格中,Phoenix服务列指明了在特定节点上安装的Phoenix组件。
1.下载Phoenix
Phoenix对应的HBase有版本之分,可以从官网:http://phoenix.apache.org/download.html来下载,要对应自己安装的HBase版本下载。我们这里安装的HBase版本为2.2.6,这里下载Phoenix5.0.0版本。下载地址如下:
http://archive.apache.org/dist/phoenix/apache-phoenix-5.0.0-HBase-2.0/bin/


2.上传解压
[root@node4 ~]# cd /software/
[root@node4 software]# tar -zxvf ./apache-phoenix-5.0.0-HBase-2.0-bin.tar.gz
3.拷贝Phoenix整合HBase需要的jar包
将前面解压好安装包下的phoenix开头的包发送到每个HBase节点下的lib目录下。
[root@node4 ~]# cd /software/apache-phoenix-5.0.0-HBase-2.0-bin#直接复制到node4节点对应的HBase目录下
[root@node4 apache-phoenix-5.0.0-HBase-2.0-bin]# cp ./phoenix-*.jar /software/hbase-2.2.6/lib/#发送到node3,node5两台HBase节点
[root@node4 apache-phoenix-5.0.0-HBase-2.0-bin]# scp ./phoenix-*.jar node3:/software/hbase-2.2.6/lib/[root@node4 apache-phoenix-5.0.0-HBase-2.0-bin]# scp ./phoenix-*.jar node5:/software/hbase-2.2.6/lib/
4.复制core-site.xml、hdfs-site.xml、hbase-site.xml到Phoenix
将HDFS中的core-site.xml、hdfs-site.xml、hbase-site.xml复制到Phoenix bin目录下。
[root@node4 ~]# cp /software/hadoop-3.1.4/etc/hadoop/core-site.xml /software/apache-phoenix-5.0.0-HBase-2.0-bin/bin[root@node4 ~]# cp /software/hadoop-3.1.4/etc/hadoop/hdfs-site.xml /software/apache-phoenix-5.0.0-HBase-2.0-bin/bin#输入yes,覆盖Phoenix目录下的hbase-site.xml
[root@node4 ~]# cp /software/hbase-2.2.6/conf/hbase-site.xml /software/apache-phoenix-5.0.0-HBase-2.0-bin/bin/
5.启动HDFS,Hbase集群,启动Phoenix
[root@node1 ~]# start-all.sh[root@node4 ~]# start-hbase.sh (如果已经启动Hbase,一定要重启HBase)#启动Phoenix
[root@node4 ~]# cd /software/apache-phoenix-5.0.0-HBase-2.0-bin/bin/#启动时可以不指定后面的zookeeper,默认连接当前节点的zookeeper,多个zookeeper节点逗号隔开,最后一个写端口2181[root@node4 bin]# ./sqlline.py node3,node4,node5:2181#退出Phoenix,使用!quit或者!exit
0: jdbc:phoenix:node3,node4,node5:2181> !quit
Closing: org.apache.phoenix.jdbc.PhoenixConnection
6.测试Phoenix
#查看Phoenix表
0: jdbc:phoenix:node3,node4,node5:2181> !tables#Phoenix中创建表 test,指定映射到HBase的列族为f1
0: jdbc:phoenix:node3,node4,node5:2181> create table test(id varchar primary key ,f1.name varchar,f1.age integer);#向表 test中插入数据
upsert into test values ('1','zs',18);#查询插入的数据
0: jdbc:phoenix:node3,node4,node5:2181> select * from test;
+-----+-------+------+
| ID | NAME | AGE |
+-----+-------+------+
| 1 | zs | 18 |
+-----+-------+------+#在HBase中查看对应的数据,hbase中将非String类型的value数据全部转为了16进制
hbase(main):013:0> scan 'TEST'注意:在Phoenix中创建的表,插入数据时,在HBase中查看发现对应的数据都进行了16进制编码,这里默认Phoenix中对数据进行的编码,我们在Phoenix中建表时可以指定“column_encoded_bytes=0”参数,不让 Phoenix对column family进行编码。例如以下建表语句,在Phoenix中插入数据后,在HBase中可以查看到正常格式数据:create table mytable ("id" varchar primary key ,"cf1"."name" varchar,"cf1"."age" varchar) column_encoded_bytes=0;upsert into mytable values ('1','zs','18');
#以上再次在HBase中查看,显示数据正常
1.4.7 搭建Kafka
以下展示了Kafka集群的节点IP、节点名称以及Kafka服务的分布情况:
| 节点IP | 节点名称 | Kafka服务 |
| --------------- | -------- | ------------- |
| 192.168.179.4 | node1 | kafka broker |
| 192.168.179.5 | node2 | kafka broker |
| 192.168.179.6 | node3 | kafka broker |
搭建详细步骤如下:
1.上传解压
[root@node1 software]# tar -zxvf ./kafka_2.11-0.11.0.3.tgz
2.配置Kafka
在node3节点上配置Kafka,进入/software/kafka_2.11-0.11.0.3/config/中修改server.properties,修改内容如下:
broker.id=0 #注意:这里要唯一的Integer类型
port=9092 #kafka写入数据的端口
log.dirs=/kafka-logs #真实数据存储的位置
zookeeper.connect=node3:2181,node4:2181,node5:2181 #zookeeper集群
3.将以上配置发送到node2,node3节点上
[root@node1 software]# scp -r /software/kafka_2.11-0.11.0.3 node2:/software/[root@node1 software]# scp -r /software/kafka_2.11-0.11.0.3 node3:/software/
4.修改node2,node3节点上的server.properties文件
node2、node3节点修改$KAFKA_HOME/config/server.properties文件中的broker.id,node2中修改为1,node3节点修改为2。
5.创建Kafka启动脚本
在node1,node2,node3节点/software/kafka_2.11-0.11.0.3路径中编写Kafka启动脚本“startKafka.sh”,内容如下:
nohup bin/kafka-server-start.sh config/server.properties > kafkalog.txt 2>&1 &
node1,node2,node3节点配置完成后修改“startKafka.sh”脚本执行权限:
chmod +x ./startKafka.sh
6.启动Kafka集群
在node1,node2,node3三台节点上分别执行/software/kafka/startKafka.sh脚本,启动Kafka:
[root@node1 kafka_2.11-0.11.0.3]# ./startKafka.sh
[root@node2 kafka_2.11-0.11.0.3]# ./startKafka.sh
[root@node3 kafka_2.11-0.11.0.3]# ./startKafka.sh
7.Kafka 命令测试
#创建topic
./kafka-topics.sh --zookeeper node3:2181,node4:2181,node5:2181 --create --topic testtopic --partitions 3 --replication-factor 3#console控制台向topic 中生产数据
./kafka-console-producer.sh --broker-list node1:9092,node2:9092,node3:9092 --topic testtopic#console控制台消费topic中的数据
./kafka-console-consumer.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --topic testtopic
1.4.8搭建Redis
| 节点IP | 节点名称 | Redis服务 |
|---|---|---|
| 192.168.179.7 | node4 | client |
具体搭建步骤如下:
1.将redis安装包上传到node4节点,并解压
[root@node4 ~]# cd /software/
[root@node4 software]# tar -zxvf ./redis-2.8.18.tar.gz2.node4安装需要的C插件
[root@node4 ~]# yum -y install gcc tcl3.编译Redis
进入/software/redis-2.8.18目录中,编译redis。
[root@node4 ~]# cd /software/redis-2.8.18
[root@node4 redis-2.8.18]# make
4.创建安装目录安装Redis
#创建安装目录
[root@node4 ~]# mkdir -p /software/redis#进入redis编译目录,安装redis
[root@node4 ~]# cd /software/redis-2.8.18
[root@node4 redis-2.8.18]# make PREFIX=/software/redis install
注意:现在就可以使用redis了,进入/software/redis/bin下,就可以执行redis命令。
5.将Redis加入环境变量,加入系统服务,设置开机启动
#将redis-server链接到/usr/local/bin/目录下,后期加入系统服务时避免报错
[root@node4 ~]# ln -sf /software/redis-2.8.18/src/redis-server /usr/local/bin/#执行如下命令,配置redis Server,一直回车即可
[root@node4 ~]# cd /software/redis-2.8.18/utils/
[root@node4 utils]# ./install_server.sh#执行完以上安装,在/etc/init.d下会修改redis_6379名称并加入系统服务
[root@node4 utils]# cd /etc/init.d/
[root@node4 init.d]# mv redis_6379 redisd
[root@node4 init.d]# chkconfig --add redisd#检查加入系统状态,3,4,5为开,就是开机自动启动
[root@node4 init.d]# chkconfig --list
**6.配置Redis环境变量**```bash
# 在node4节点上编辑profile文件,vim /etc/profile
export REDIS_HOME=/software/redis
export PATH=$PATH:$REDIS_HOME/bin#使环境变量生效
source /etc/profile
7.启动|停止 Redis服务
后期每次开机启动都会自动启动Redis,也可以使用以下命令手动启动|停止redis
#启动redis
[root@node4 init.d]# service redisd start#停止redis
[root@node4 init.d]# redis-cli shutdown8)测试redis
#进入redis客户端
[root@node4 ~]# redis-cli#切换1号库,并插入key
127.0.0.1:6379> select 1
127.0.0.1:6379[1]> hset rediskey zhagnsan 100#查看所有key并获取key值
127.0.0.1:6379[1]> keys *
127.0.0.1:6379[1]> hgetall rediskey#删除指定key
127.0.0.1:6379[1]> del 'rediskey'
1.4.9搭建Flink
这里选择Flink的版本为1.11.6,原因是1.11.6与Iceberg的整合比较稳定。Flink搭建节点分布如下:
以下是使用Markdown格式编写的表格,展示了Flink集群的节点IP、节点名称以及对应的Flink服务分布情况:
| 节点IP | 节点名称 | Flink服务 |
| --------------- | -------- | ----------------- |
| 192.168.179.4 | node1 | JobManager, TaskManager |
| 192.168.179.5 | node2 | TaskManager |
| 192.168.179.6 | node3 | TaskManager |
| 192.168.179.7 | node4 | client |
在这个表格中,Flink服务列列出了每个节点上运行的Flink组件。例如,node1运行了JobManager和TaskManager角色。
具体搭建步骤如下:
1.上传压缩包解压
将Flink的安装包上传到node1节点/software下并解压:
[root@node1 software]# tar -zxvf ./flink-1.11.6-bin-scala_2.11.tgz2.修改配置文件
在node1节点上进入到Flink conf 目录下,配置flink-conf.yaml文件,内容如下:
#进入flink-conf.yaml目录
[root@node1 conf]# cd /software/flink-1.11.6/conf/#vim编辑flink-conf.yaml文件,配置修改内容如下
jobmanager.rpc.address: node1
taskmanager.numberOfTaskSlots: 3其中:taskmanager.numberOfTaskSlot参数默认值为1,修改成3。表示数每一个TaskManager上有3个Slot。
3.配置TaskManager节点
在node1节点上配置$FLINK_HOME/conf/workers文件,内容如下:
node1
node2
node3
4.分发安装包到node2,node3,node4节点
[root@node1 software]# scp -r ./flink-1.11.6 node2:/software/
[root@node1 software]# scp -r ./flink-1.11.6 node3:/software/#注意,这里发送到node4,node4只是客户端
[root@node1 software]# scp -r ./flink-1.11.6 node4:/software/
5.启动Flink集群
#在node1节点中,启动Flink集群
[root@node1 ~]# cd /software/flink-1.11.6/bin/
[root@node1 bin]# ./start-cluster.sh
6.访问flink Webui
https://node1:8081,进入页面如下:

7.准备“flink-shaded-hadoop-2-uber-2.8.3-10.0.jar”包
在基于Yarn提交Flink任务时需要将Hadoop依赖包“flink-shaded-hadoop-2-uber-2.8.3-10.0.jar”放入flink各个节点的lib目录中(包括客户端)。
1.4.10搭建Flume
以下展示了Flume服务在指定节点上的分布情况:
| 节点IP | 节点名称 | Flume服务 |
| --------------- | -------- | -------- |
| 192.168.179.8 | node5 | flume |
在这个表格中,Flume服务列指明了在特定节点上运行的Flume组件。
Flume的搭建配置步骤如下:
1.首先将Flume上传到Mynode5节点/software/路径下,并解压,命令如下:
[root@ node5 software]# tar -zxvf ./apache-flume-1.9.0-bin.tar.gz2.其次配置Flume的环境变量,配置命令如下:
#修改 /etc/profile文件,在最后追加写入如下内容,配置环境变量:
[root@node5 software]# vim /etc/profile
export FLUME_HOME=/software/apache-flume-1.9.0-bin
export PATH=$FLUME_HOME/bin:$PATH#保存以上配置文件并使用source命令使配置文件生效
[root@node5 software]# source /etc/profile
经过以上两个步骤,Flume的搭建已经完成,至此,Flume的搭建完成,我们可以使用Flume进行数据采集。
1.4.11搭建maxwell
1.4.11.1开启MySQL binlog日志
本项目主要使用Maxwell来监控业务库MySQL中的数据到Kafka,Maxwell原理是通过同步MySQL binlog日志数据达到同步MySQL数据的目的。Maxwell不支持高可用搭建,但是支持断点还原,可以在执行失败时重新启动继续上次位置读取数据,此外安装Maxwell前需要开启MySQL binlog日志,步骤如下:
1.登录mysql查看MySQL是否开启binlog日志
[root@node2 ~]# mysql -u root -p123456
mysql> show variables like 'log_%';

2.开启MySQL binlog日志
在/etc/my.cnf文件中[mysqld]下写入以下内容:
[mysqld]
# 随机指定一个不能和其他集群中机器重名的字符串,配置 MySQL replaction 需要定义
server-id=123 #配置binlog日志目录,配置后会自动开启binlog日志,并写入该目录
log-bin=/var/lib/mysql/mysql-bin# 选择 ROW 模式
binlog-format=ROW
3.重启mysql 服务,重新查看binlog日志情况
[root@node2 ~]# service mysqld restart
[root@node2 ~]# mysql -u root -p123456
mysql> show variables like 'log_%';
1.4.11.2安装Maxwell
这里maxwell安装版本选择1.28.2,选择node3节点安装,安装maxwell步骤如下:
1.将下载好的安装包上传到node3并解压
[root@node3 ~]# cd /software/
[root@node3 software]# tar -zxvf ./maxwell-1.28.2.tar.gz
2.在MySQL中创建Maxwell的用户及赋权
Maxwell同步mysql数据到Kafka中需要将读取的binlog位置文件及位置信息等数据存入MySQL,所以这里创建maxwell数据库,及给maxwell用户赋权访问其他所有数据库。
mysql> CREATE database maxwell;
mysql> CREATE USER 'maxwell'@'%' IDENTIFIED BY 'maxwell';
mysql> GRANT ALL ON maxwell.* TO 'maxwell'@'%';
mysql> GRANT SELECT, REPLICATION CLIENT, REPLICATION SLAVE ON *.* TO 'maxwell'@'%';
mysql> flush privileges;
3.修改配置“config.properties”文件
node3节点进入“/software/maxwell-1.28.2”,修改“config.properties.example”为“config.properties”并配置:
producer=kafka
kafka.bootstrap.servers=node1:9092,node2:9092,node3:9092
kafka_topic=test-topic
#设置根据表将binlog写入Kafka不同分区,还可指定:[database, table, primary_key, transaction_id, thread_id, column]
producer_partition_by=table#mysql 节点
host=node2
#连接mysql用户名和密码
user=maxwell
password=maxwell#指定maxwell 当前连接mysql的实例id,这里用于全量同步表数据使用
client_id=maxwell_first
注意:以上参数也可以在后期启动maxwell时指定参数方式来设置。
4.启动zookeeper及Kafka,创建对应test-topic
[root@node1 bin]# ./kafka-topics.sh --zookeeper node3:2181,node4:2181,node5:2181 --create --topic test-topic --partitions 3 --replication-factor 3
5.在Kafka中监控test-topic
[root@node2 bin]# cd /software/kafka_2.11-0.11/
[root@node2 bin]# ./kafka-console-consumer.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --topic test-topic
6.启动Maxwell
[root@node3 ~]# cd /software/maxwell-1.28.2/bin
[root@node3 bin]# maxwell --config ../config.properties.注意以上启动也可以编写脚本:
#startMaxwell.sh 脚本内容:
/software/maxwell-1.28.2/bin/maxwell --config /software/maxwell-1.28.2/config.properties > ./log.txt 2>&1 &
修改执行权限:
chmod +x ./start_maxwell.sh
注意:这里我们可以通过Maxwell将MySQL业务库中所有binlog变化数据监控到Kafka test-topic中,在此项目中我们将MySQL binlog数据监控到Kafka中然后通过Flink读取对应topic数据进行处理。
7.在mysql中创建库testdb,并创建表person插入数据
mysql> create database testdb;
mysql> use testdb;
mysql> create table person(id int,name varchar(255),age int);
mysql> insert into person values (1,'zs',18);
mysql> insert into person values (2,'ls',19);
mysql> insert into person values (3,'ww',20);可以看到在监控的kafka test-topic中有对应的数据被同步到topic中:

8.全量同步mysql数据到kafka
这里以MySQL 表testdb.person为例将全量数据导入到Kafka中,可以通过配置Maxwell,使用Maxwell bootstrap功能全量将已经存在MySQL testdb.person表中的数据导入到Kafka,操作步骤如下:
#启动Maxwell
[root@node3 ~]# cd /software/maxwell-1.28.2/bin
[root@node3 bin]# maxwell --config ../config.properties#启动maxwell-bootstrap全量同步数据
[root@node3 ~]# cd /software/maxwell-1.28.2/bin
[root@node3 bin]# ./maxwell-bootstrap --database testdb --table person --host node2 --user maxwell --password maxwell --client_id maxwell_first --where "id>0"执行之后可以看到对应的Kafka test-topic中将表testdb.person中的数据全部导入一遍:

1.4.12搭建clickhouse
以下是展示了ClickHouse服务在指定节点上的分布情况:
这里clickhouse的版本选择21.9.4.35,clickhouse选择分布式安装,clickhouse节点分布如下:
| 节点IP | 节点名称 | ClickHouse服务 |
| --------------- | -------- | -------------- |
| 192.168.179.4 | node1 | clickhouse |
| 192.168.179.5 | node2 | clickhouse |
| 192.168.179.6 | node3 | clickhouse |
在这个表格中,ClickHouse服务列指明了在特定节点上运行的ClickHouse服务实例。
clickhouse详细安装步骤如下:
1.选择三台clickhouse节点,在每台节点上安装clickhouse需要的安装包
这里选择node1、node2,node3三台节点,上传安装包,分别在每台节点上执行如下命令安装clickhouse:
rpm -ivh ./clickhosue-common-static-21.9.4.35-2.x86_64.rpm
#注意在安装以下rpm包时,让输入密码,可以直接回车跳过
rpm -ivh ./clickhouse-server-21.9.4.35-2.noarch.rpm
rpm -ivh ./clickhouse-client-21.9.4.35-2.noarch.rpm
2.安装zookeeper集群并启动。
搭建clickhouse集群时,需要使用Zookeeper去实现集群副本之间的同步,所以这里需要zookeeper集群,zookeeper集群安装后可忽略此步骤。
3.配置外网可访问
在每台clickhouse节点中配置/etc/clickhouse-server/config.xml文件第164行<listen_host>,把以下对应配置注释去掉,如下:
<listen_host>::1</listen_host>
#注意每台节点监听的host名称配置当前节点host,需要强制保存wq!
<listen_host>node1</listen_host>
4.在每台节点创建metrika.xml文件,写入以下内容
在node1、node2、node3节点上/etc/clickhouse-server/config.d路径下下配置metrika.xml文件,默认clickhouse会在/etc路径下查找metrika.xml文件,但是必须要求metrika.xml上级目录拥有者权限为clickhouse ,所以这里我们将metrika.xml创建在/etc/clickhouse-server/config.d路径下,config.d目录的拥有者权限为clickhouse。
在metrika.xml中我们配置后期使用的clickhouse集群中创建分布式表时使用3个分片,每个分片有1个副本,配置如下:
vim /etc/clickhouse-server/config.d/metrika.xml:
<yandex><remote_servers><clickhouse_cluster_3shards_1replicas><shard><internal_replication>true</internal_replication><replica><host>node1</host><port>9000</port></replica></shard><shard><internal_replication>true</internal_replication><replica><host>node2</host><port>9000</port></replica></shard><shard><internal_replication>true</internal_replication><replica><host>node3</host><port>9000</port></replica></shard></clickhouse_cluster_3shards_1replicas></remote_servers><zookeeper><node index="1"><host>node3</host><port>2181</port></node><node index="2"><host>node4</host><port>2181</port></node><node index="3"><host>node5</host><port>2181</port></node></zookeeper><macros><shard>01</shard> <replica>node1</replica></macros><networks><ip>::/0</ip></networks><clickhouse_compression><case><min_part_size>10000000000</min_part_size><min_part_size_ratio>0.01</min_part_size_ratio><method>lz4</method></case></clickhouse_compression>
</yandex>
在ClickHouse分布式集群配置中,以下是对配置文件中各项配置项的解释:
-
remote_servers:
这是ClickHouse集群配置的标签,用于标识集群配置。新版本的ClickHouse不再要求以"clickhouse"作为前缀。 -
clickhouse_cluster_3shards_1replicas:
这是集群的名称,代表集群由3个分片组成,每个分片有1个副本。分片是存储数据的部分,副本是分片数据的备份。 -
shard:
分片是指集群中的一个数据存储单元。一个ClickHouse集群可以包含多个分片,每个分片可以存储一部分数据。分片对应于集群中的每个服务节点。 -
replica:
副本是分片数据的备份,用于提高数据的可用性。每个分片可以配置一个或多个副本。副本的数量取决于ClickHouse节点的总数。 -
internal_replication:
默认为false。如果设置为true,写操作将只写入一个副本,而其他副本的数据同步在后台自动完成。 -
zookeeper:
用于配置ZooKeeper集群信息,ZooKeeper用于ClickHouse副本之间的协调。 -
macros:
用于区分每个ClickHouse节点的宏配置。<shard>和<replica>是宏的标签,可以在创建副本表时动态使用。每台ClickHouse节点需要配置不同的宏名称。 -
networks:
配置允许访问的IP地址范围。"::/0"代表允许任意IP访问,包括IPv4和IPv6地址。如果需要允许外网访问,还需要在/etc/clickhouse-server/config.xml中进行相应配置。 -
clickhouse_compression:
这是MergeTree引擎表的数据压缩设置。min_part_size定义了数据部分的最小大小,min_part_size_ratio定义了数据部分大小与表大小的比率,method定义了数据压缩的格式。
请注意,为了实现数据压缩,需要在每台ClickHouse节点上配置metrika.xml文件,并修改每个节点的macros配置名称,以确保正确应用压缩设置。
#node2节点修改metrika.xml中的宏变量如下:<macros><shard>02</replica> <replica>node2</replica></macros>#node3节点修改metrika.xml中的宏变量如下:
<macros><shard>03</replica> <replica>node3</replica></macros>
这些配置项共同定义了ClickHouse集群的拓扑结构和行为,确保了数据的分布式存储、高可用性和可扩展性。在配置ClickHouse集群时,应根据实际业务需求和硬件资源来合理规划分片和副本的数量。
5.在每台节点上启动/查看/重启/停止clickhouse服务
首先启动zookeeper集群,然后分别在node1、node2、node3节点上启动clickhouse服务,这里每台节点和单节点启动一样。启动之后,clickhouse集群配置完成。
#每台节点启动Clickchouse服务
service clickhouse-server start#每台节点查看clickhouse服务状态
service clickhouse-server status#每台节点重启clickhouse服务
service clickhouse-server restart#每台节点关闭Clikchouse服务
service clickhouse-server stop
6,检查集群配置是否完成
在node1、node2、node3任意一台节点进入clickhouse客户端,查询集群配置:
#选择三台clickhouse任意一台节点,进入客户端
clickhouse-client
#查询集群信息,看到下图所示即代表集群配置成功。
node1 :) select * from system.clusters;

#查询集群信息,也可以使用如下命令
node1 :) select cluster,host_name from system.clusters;

7.测试clickhouse
#在clickhouse node1节点创建mergeTree表 mt
create table mt(id UInt8,name String,age UInt8) engine = MergeTree() order by (id);#向表 mt 中插入数据
insert into table mt values(1,'zs',18),(2,'ls',19),(3,'ww',20);#查询表mt中的数据
select * from mt;
1.5项目数据种类与采集
实时数仓项目中的数据分为两类,一类是业务系统产生的业务数据,这部分数据存储在MySQL数据库中,另一类是实时用户日志行为数据,这部分数据是用户登录系统产生的日志数据。
针对MySQL日志数据我们采用maxwell全量或者增量实时采集到大数据平台中,针对用户日志数据,通过log4j日志将数据采集到目录中,再通过Flume实时同步到大数据平台,总体数据采集思路如下图所示:

针对MySQL业务数据和用户日志数据构建离线+实时湖仓一体数据分析平台,我们暂时划分为会员主题和商品主题。下面了解下主题各类表情况。
1.5.1MySQL业务数据
1.5.1.1配置MySQL支持UTF8编码
在node2节点上配“/etc/my.cnf”文件,在对应的标签下加入如下配置,更改mysql数据库编码格式为utf-8:
[mysqld]
character-set-server=utf8[client]
default-character-set = utf8
修改完成之后重启mysql即可。
1.5.1.2MySQL数据表
MySQL业务数据存储在库“lakehousedb”中,此数据库中的业务数据表如下:
1.会员基本信息表 : mc_member_info

2.会员收货地址表 : mc_member_address

3.用户登录数据表 : mc_user_login

4.商品分类表 : pc_product_category

5.商品基本信息表 : pc_product

1.5.1.3MySQL业务数据采集
我们通过maxwell数据同步工具监控MySQL binlog日志将MySQL日志数据同步到Kafka topic “KAFKA-DB-BUSSINESS-DATA”中,详细步骤如下:
1.配置maxwell config.properties文件
进入node3“/software/maxwell-1.28.2”目录,配置config.properties文件,主要是配置监控mysql日志数据对应的Kafka topic,配置详细内容如下:
producer=kafka
kafka.bootstrap.servers=node1:9092,node2:9092,node3:9092
kafka_topic=KAFKA-DB-BUSSINESS-DATA
#设置根据表将binlog写入Kafka不同分区,还可指定:[database, table, primary_key, transaction_id, thread_id, column]
producer_partition_by=table#mysql 节点
host=node2
#连接mysql用户名和密码
user=maxwell
password=maxwell#指定maxwell 当前连接mysql的实例id,这里用于全量同步表数据使用
client_id=maxwell_first
2.启动kafka,创建Kafka topic,并监控Kafka topic
启动Zookeeper集群、Kafka 集群,创建topic“KAFKA-DB-BUSSINESS-DATA” topic:
#进入Kafka路径,创建对应topic
[root@node1 ~]# cd /software/kafka_2.11-0.11.0.3/bin/
[root@node1 bin]# ./kafka-topics.sh --zookeeper node3:2181,node4:2181,node5:2181 --create --topic KAFKA-DB-BUSSINESS-DATA --partitions 3 --replication-factor 3#监控Kafak topic 中的数据
[root@node1 bin]# ./kafka-console-consumer.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --topic KAFKA-DB-BUSSINESS-DATA
3.启动maxwell
#在node3节点上启动maxwell
[root@node3 ~]# cd /software/maxwell-1.28.2/bin/
[root@node3 bin]# maxwell --config ../config.properties
4.在mysql中创建“lakehousedb”并导入数据
#进入mysql ,创建数据库lakehousedb
[root@node2 ~]# mysql -u root -p123456
mysql> create database lakehousedb;
打开“Navicat”工具,将资料中(*资料获取方式:待定)*的“lakehousedb.sql”文件导入到MySQL数据库“lakehousedb”中,我们可以看到在对应的kafka topic “KAFKA-DB-BUSSINESS-DATA”中会有数据被采集过来。

1.5.2用户日志数据
1.5.2.1用户日志数据
目前用户日志数据只有“会员浏览商品日志数据”,其详细信息如下:
接口地址:/collector/common/browselog
请求方式:post
请求数据类型:application/json
接口描述:用户登录系统后,会有当前登录时间信息及当前用户登录后浏览商品,跳转链接、浏览所获积分等信息
请求示例:
{"logTime": 1646393162044,"userId": "uid529497","userIp": "216.36.11.233","frontProductUrl": "https://fo0z7oZj/rInb/ui","browseProductUrl": "https://2/5Rx/SqqOUsK4","browseProductTpCode": "202","browseProductCode": "q6HCcpxd2I","obtainPoints": 14,
}
请求参数解释如下:
| 参数名称 | 参数说明 |
|----------------|------------------------------------------------|
| logTime | 浏览日志时间 |
| userId | 用户编号 |
| userIp | 浏览Ip地址 |
| frontProductUrl| 跳转前URL地址,有为null,有的不为null |
| browseProductUrl| 浏览商品URL |
| browseProductTpCode| 浏览商品二级分类 |
| browseProductCode| 浏览商品编号 |
| obtainPoints | 浏览商品所获积分 |
1.5.2.2用户日志数据采集
日志数据采集是通过log4j日志配置来将用户的日志数据集中获取,编写日志采集接口在项目“LogCollector”中来采集用户日志数据。(该项目也在资料中)
当用户浏览网站触发对应的接口时,日志采集接口根据配合的log4j将用户浏览信息写入对应的目录中,然后通过Flume监控对应的日志目录,将用户日志数据采集到Kafka topic “KAFKA-USER-LOG-DATA”中。
模拟用户浏览日志数据,将用户浏览日志数据采集到Kafka中,详细步骤如下:
骤如下:
1.将日志采集接口项目打包,上传到node5节点
将日志采集接口项目“LogCollector”项目配置成生产环境prod,打包,上传到node5节点目录/software下。
相关文章:
数据驱动未来:构建下一代湖仓一体电商数据分析平台,引领实时商业智能革命
1.1 项目背景 本项目是一个创新的湖仓一体实时电商数据分析平台,旨在为电商平台提供深度的数据洞察和业务分析。技术层面,项目涵盖了从基础架构搭建到大数据技术组件的集成,采用了湖仓一体的设计理念,实现了数据仓库与数据湖的有…...

学习JavaScript第五天
文章目录 1.HTML DOM1.1 表单相关元素① form 元素② 文本输入框类和文本域(input 和 textarea)③ select 元素 1.2 表格相关元素① table 元素② tableRow 元素(tr 元素)③ tableCell 元素 (td 或 th) 1.3…...

pythonGame-实现简单的坦克大战
通过python简单复现坦克大战游戏。 使用到的库函数: import turtle import math import random import time 游戏源码: import turtle import math import random import time# 设置屏幕 screen turtle.Screen() screen.setup(800, 600) screen.tit…...

不太常见的asmnet诊断
asm侦听 [griddb1-[ASM1]-/home/grid]$ srvctl config asm ASM home: <CRS home> Password file: OCR/orapwASM Backup of Password file: OCRDG/orapwASM_backup ASM listener: LISTENER ASM instance count: 3 Cluster ASM listener: ASMNET1LSNR_ASM[rootdb1:/root]# …...
双指针-【3,4,5,6,7,8】
第三题:快乐数 . - 力扣(LeetCode). - 备战技术面试?力扣提供海量技术面试资源,帮助你高效提升编程技能,轻松拿下世界 IT 名企 Dream Offer。https://leetcode.cn/problems/happy-number/算法思想: 1.每个…...

react Vant中如何获取步进器的值
在React中使用Vant(一个轻量、可靠的移动端Vue组件库,虽然原生是为Vue设计的,但如果你在使用的是React版本的Vant,比如通过某些库或框架桥接Vue组件到React,或者是一个类似命名的React UI库),获…...

Windows下Git Bash乱码问题解决
Windows下Git Bash乱码问题解决 缘起 个人用的电脑是Mac OS,系统和终端编码都是UTF-8,但公司给配发的电脑是Windows,装上Git Bash在使用 git commit -m "中文"时会乱码 解决 确认有以下配置 # 输入 git config --global --lis…...

HTML5 + CSS3
HTML 基础 准备开发环境 1.vscode 使用 新建文件夹 ---> 左键拖入 vscode 中 2.安装插件 扩展 → 搜索插件 → 安装打开网页插件:open in browser汉化菜单插件:Chinese 3.缩放代码字号 放大,缩小:Ctrl 加号,减号 4.设…...
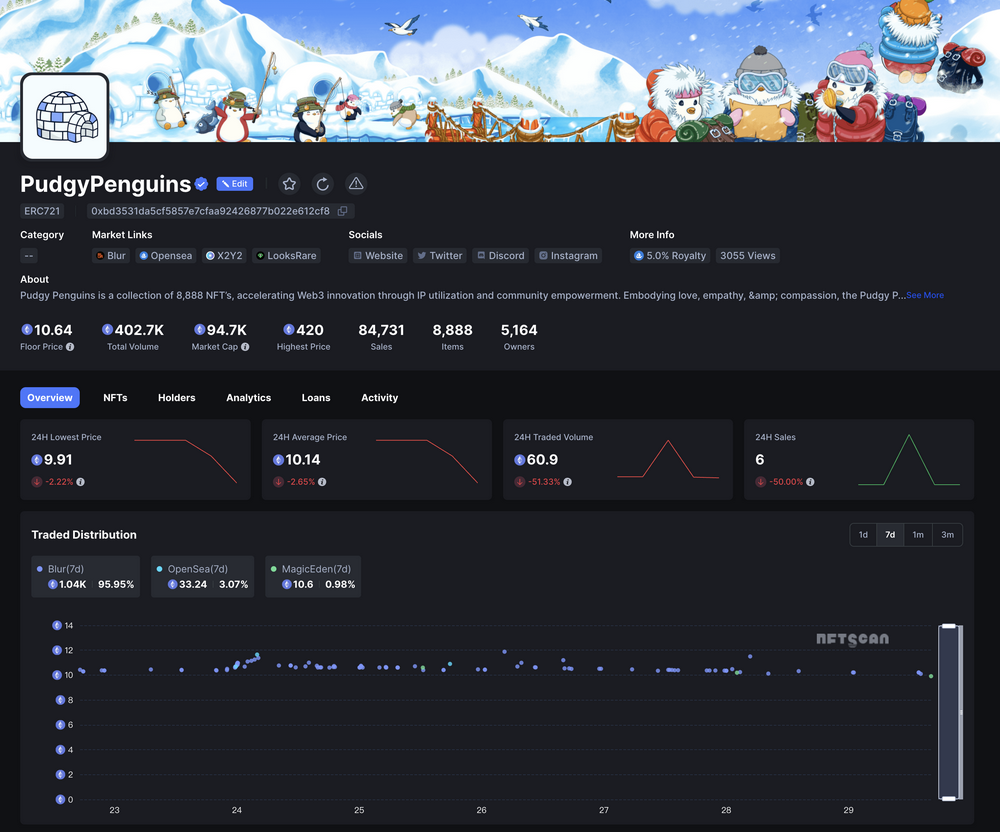
NFTScan | 07.22~07.28 NFT 市场热点汇总
欢迎来到由 NFT 基础设施 NFTScan 出品的 NFT 生态热点事件每周汇总。 周期:2024.07.22~ 2024.07.28 NFT Hot News 01/ 数据:NFT 系列 Liberty Cats 地板价突破 70000 MATIC 7 月 22 日,据 Magic Eden 数据,NFT 系列 Liberty C…...


探索分布式光伏运维系统的组成 需要几步呢?
前言 随着光伏发电的不断发展,对于光伏发电监控系统的需求也日益迫切,“互联网”时代,“互联网”的理念已经转化为科技生产的动力,促进了产业的升级发展,本文结合“互联网”技术提出了一种针对分散光伏发电站运行数据…...
做知识付费项目还能做吗?知识付费副业项目如何做?能挣多少钱?
hello,我是阿磊,一个20年的码农,6年前代码写不动了,转型专职做副业项目研究,为劳苦大众深度挖掘互联网副业项目,共同富裕。 现在做知识付费项目还能做吗? 互联网虚拟资源项目我一直在做,做了有…...

K210视觉识别模块学习笔记7:多线程多模型编程识别
今日开始学习K210视觉识别模块: 图形化操作函数 亚博智能 K210视觉识别模块...... 固件库: canmv_yahboom_v2.1.1.bin 训练网站: 嘉楠开发者社区 今日学习使用多线程、多模型来识别各种物体 这里先提前说一下本文这次测试实验的结果吧:结果是不太成…...
Go语言教程(一看就会)
全篇文章 7000 字左右, 建议阅读时长 1h 以上。 Go语言是一门开源的编程语言,目的在于降低构建简单、可靠、高效软件的门槛。Go平衡了底层系统语言的能力,以及在现代语言中所见到的高级特性。它是快速的、静态类型编译语言。 第一个GO程序…...

【Golang 面试 - 基础题】每日 5 题(十)
✍个人博客:Pandaconda-CSDN博客 📣专栏地址:http://t.csdnimg.cn/UWz06 📚专栏简介:在这个专栏中,我将会分享 Golang 面试中常见的面试题给大家~ ❤️如果有收获的话,欢迎点赞👍收藏…...

OD C卷 - 密码输入检测
密码输入检测 (100) 给定一个密码,‘<’ 表示删除前一个字符,输出最终得到的密码,并判断是否满足密码安全要求: 密码长度>8;至少包含一个大写字母;至少包含一个小写字母;至少…...

【每日一题】【逆推法 + 贪心】【数学】造数 河南萌新联赛2024第(一)场:河南农业大学 A题 C++
河南萌新联赛2024第(一)场:河南农业大学 A题 造数 题目描述 样例 #1 样例输入 #1 2样例输出 #1 1样例 #2 样例输入 #2 5样例输出 #2 3做题思路 本题可以用逆推法 将三种操作反过来变为 − 1 , − 2 , / 2 -1 , -2 , /2 −1,−2,/2 …...

刷题计划 day4 【双指针、快慢指针、环形链表】链表下
⚡刷题计划day4继续,可以点个免费的赞哦~ 下一期将会开启哈希表刷题专题,往期可看专栏,关注不迷路, 您的支持是我的最大动力🌹~ 目录 ⚡刷题计划day4继续,可以点个免费的赞哦~ 下一期将会开启哈希表刷题…...

最高200万!苏州成都杭州的这些AI政策补贴,你拿到了吗?
随着全球人工智能技术的迅猛发展,地方政府纷纷出台相关政策以抢占未来科技的制高点。苏州 成都 杭州这三个城市更是推出了一系列AI政策补贴,旨在通过多方面支持,推动本地AI产业的发展。本文将带你了解目前不完全统计到的苏州 成都 杭州三地AI…...

使用两台虚拟机分别部署前端和后端项目
使用两台虚拟机分别部署前端和后端项目 1 部署方案2 准备两台虚拟机,并配置网络环境3 部署后端项目3.1 打包服务3.2 上传jar包到服务器3.3 集成Systemd3.3.1 移动端服务集成Systemd3.3.2 后台管理系统集成Systemd 4 配置域名映射5 部署前端项目5.1 移动端5.1.1 打包…...

在HarmonyOS ArkTS ArkUI-X 5.0及以上版本中,手势开发全攻略:
在 HarmonyOS 应用开发中,手势交互是连接用户与设备的核心纽带。ArkTS 框架提供了丰富的手势处理能力,既支持点击、长按、拖拽等基础单一手势的精细控制,也能通过多种绑定策略解决父子组件的手势竞争问题。本文将结合官方开发文档,…...

无法与IP建立连接,未能下载VSCode服务器
如题,在远程连接服务器的时候突然遇到了这个提示。 查阅了一圈,发现是VSCode版本自动更新惹的祸!!! 在VSCode的帮助->关于这里发现前几天VSCode自动更新了,我的版本号变成了1.100.3 才导致了远程连接出…...

【大模型RAG】Docker 一键部署 Milvus 完整攻略
本文概要 Milvus 2.5 Stand-alone 版可通过 Docker 在几分钟内完成安装;只需暴露 19530(gRPC)与 9091(HTTP/WebUI)两个端口,即可让本地电脑通过 PyMilvus 或浏览器访问远程 Linux 服务器上的 Milvus。下面…...

Java 加密常用的各种算法及其选择
在数字化时代,数据安全至关重要,Java 作为广泛应用的编程语言,提供了丰富的加密算法来保障数据的保密性、完整性和真实性。了解这些常用加密算法及其适用场景,有助于开发者在不同的业务需求中做出正确的选择。 一、对称加密算法…...

Android15默认授权浮窗权限
我们经常有那种需求,客户需要定制的apk集成在ROM中,并且默认授予其【显示在其他应用的上层】权限,也就是我们常说的浮窗权限,那么我们就可以通过以下方法在wms、ams等系统服务的systemReady()方法中调用即可实现预置应用默认授权浮…...

华为云Flexus+DeepSeek征文|DeepSeek-V3/R1 商用服务开通全流程与本地部署搭建
华为云FlexusDeepSeek征文|DeepSeek-V3/R1 商用服务开通全流程与本地部署搭建 前言 如今大模型其性能出色,华为云 ModelArts Studio_MaaS大模型即服务平台华为云内置了大模型,能助力我们轻松驾驭 DeepSeek-V3/R1,本文中将分享如何…...

管理学院权限管理系统开发总结
文章目录 🎓 管理学院权限管理系统开发总结 - 现代化Web应用实践之路📝 项目概述🏗️ 技术架构设计后端技术栈前端技术栈 💡 核心功能特性1. 用户管理模块2. 权限管理系统3. 统计报表功能4. 用户体验优化 🗄️ 数据库设…...

视频行为标注工具BehaviLabel(源码+使用介绍+Windows.Exe版本)
前言: 最近在做行为检测相关的模型,用的是时空图卷积网络(STGCN),但原有kinetic-400数据集数据质量较低,需要进行细粒度的标注,同时粗略搜了下已有开源工具基本都集中于图像分割这块,…...

QT3D学习笔记——圆台、圆锥
类名作用Qt3DWindow3D渲染窗口容器QEntity场景中的实体(对象或容器)QCamera控制观察视角QPointLight点光源QConeMesh圆锥几何网格QTransform控制实体的位置/旋转/缩放QPhongMaterialPhong光照材质(定义颜色、反光等)QFirstPersonC…...

mac 安装homebrew (nvm 及git)
mac 安装nvm 及git 万恶之源 mac 安装这些东西离不开Xcode。及homebrew 一、先说安装git步骤 通用: 方法一:使用 Homebrew 安装 Git(推荐) 步骤如下:打开终端(Terminal.app) 1.安装 Homebrew…...