BERT模型
BERT模型是由谷歌团队于2019年提出的 Encoder-only 的 语言模型,发表于NLP顶会ACL上。原文题目为:《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》链接
在前大模型时代,BERT模型可以算是一个参数量比较大的预训练语言模型。在如今的大模型时代,LLM大多遵循GPT提出的Decoder-only的模型范式。BERT也可以算是时代的眼泪了。这篇文章以BERT原文为基础,回顾BERT模型的相关细节。
1 Introduction
BERT 全称为 Bidirectional Encoder Representations from Transformers。
BERT作为一个在大规模预料上预训练的语言模型,可以通过在后面只增加一层输出层并微调,就可以活动广泛下游任务上的SOTA模型
文中作者将NLP的任务分为两类:
- Sentence-Level tasks
- 通过对句子的整体分析来预测句子之间的关系
- 代表:自然语言推理 以及 转述
- Token-Level tasks
- 模型需要在 Token 层面产生细粒度的输出
- 代表:命名实体识别(Named entity recognition)、问答(question answering)
将预训练的语言表征(语言模型)用于下游任务的两种方法:feature-based 以及 fine-tuning
- feature-based approach: ELMo
- 使用包含预训练表征的任务特定架构做为额外特征
- Fine-tuning approach: OpenAI提出的GPT
- 引入最小任务特定参数,通过简单微调所有预训练参数,在下游任务上进行训练
文中提出,标准的语言模型是单向的,这限制了在预训练期间可以使用的架构的选择。例如:GPT 从左向右的架构:每个Token只能与之前的Token进行运算(通过引入casual mask,这也是Decoder模型的通常做法)
文章中指出:对于自然语言处理的任务:集成双向上下文至关重要。在Decoder-only大模型大行其道的今天,这个论断的有效性……
因此,BERT的预训练任务包括以下两部分,以捕获双向上下文:
- Masked language model
- 完形填空:mask输入中的一些Token,根据上下文预测原来的词
- Next Sentence Prediction
- 联合预训练文本对表示
2 Related Work
回顾了Transformer模型:

这里推荐一篇博客,把Transformer模型讲解得很清晰,而且结合了代码,名为:annotated-transformer
3 BERT
![![[Pasted image 20240421185749.png]]](https://i-blog.csdnimg.cn/direct/27c57e6b40be468493c279f22b51e094.png)
BERT模型分为两个阶段:
Pre-training:在不同的预训练任务上对无标签数据进行训练
Fine-tuning:首先使用预训练的参数进行初始化,并使用下游任务的标记数据对所有参数进行微调。每个下游任务都有单独的微调模型
两种规模的BERT模型,其配置以及总体的参数量
BERT-base:L 12,H 768,A 12,110M
BERT-large:L 24,H 1024,A 16,340M
在当年,参数量都还是M级,就已经决定模型很大了,现在都是B级的参数量了,汗-_-||
Input/Output Representations
输入表示:在一个Token序列里既可以表示一对句子,也可以表示单独一个句子
Token embeddings 采用 WordPiece技术
每个序列的第一个标记总是一个特殊的分类标记([CLS])。
该令牌对应的最终隐藏状态作为分类任务的聚合序列表示。
当句子对被打包到一个序列中时,区分句子的方法:
- 引入 [SEP] Token作为句子的分隔
- 为每个Token添加一个学习到的嵌入,指示它是属于句子A还是句子B

每个Token的输入表示 = Token Embeddings + segment Embeddings + position Embeddings
emdedding包含三部分
BERT的激活函数采用 GeLU 替代原始 Transformer 中的 ReLU
G E L U ( x ) = 0.5 × x × ( 1 + T a n h ( 2 / π × ( x + 0.044715 × x 3 ) ) ) GELU(x)=0.5\times x \times (1+Tanh(\sqrt{2/\pi}\times (x+0.044715\times x^3))) GELU(x)=0.5×x×(1+Tanh(2/π×(x+0.044715×x3)))
其函数图像如下图所示,与 ReLU不同,GeLU并不是将负数置为0,而是将其置为较小的负数,某种意义上是使得数据更平滑。
![![[Pasted image 20240421185915.png]]](https://i-blog.csdnimg.cn/direct/a198df0382204d54be03680f35f8b6d4.png)
3.1 Pre-training BERT
Task #1: Masked LM
简单地随机掩盖输入 Token 的某些百分比,然后预测那些被掩盖的 Token
mask Token 对应的最终隐藏向量被输入到词汇表上的输出 softmax 中,就像在标准LM中一样
文中,在每个序列中随机掩码所有 WordPiece Token 的15%
Mask Token的引入会使得 Pre-train 和 fine-tuning 之间存在不匹配的问题,因为 fine-tuning 过程中不会出现 [MASK] Token
缓解措施:并不总是用 [MASK] Token 来代替要被 “masked” 的词
训练数据生成器随机选择 15% 的 Token 位置进行预测。如果选择第 i 个Token,我们将第 i 个Token替换为
- 80%情况下,[MASK] Token
- 10%情况下,随机Token
- 10%情况下,不变
具体如下图:

该部分的 Loss 为:每个 Token 的最终隐藏向量 T i T_i Ti 将与原始 Token 的 交叉熵
Task #2: Next Sentence Prediction (NSP)
二值化的下一个句子预测任务
为每个预训练例子选择句子A和B,B有 50% 的可能性是 A (标记为 IsNext )之后的实际下一个句子,50% 的可能是从语料库中随机抽取的句子(标记为 NotNext)
![![[Pasted image 20240421185904.png]]](https://i-blog.csdnimg.cn/direct/53e50de2be9e436790a4a5601db67762.png)
损失函数为:
Training loss 是 平均掩蔽LM似然(Mean Masked LM likelihood) 和 平均下一个句子预测似然(Mean Next Sentence Prediction likelihood) 之和
预训练数据
BooksCorpus 以及 English Wikipedia
3.2 Fine-tuning BERT
FineTuning时,BERT传输所有参数来初始化下游任务模型参数,而无所谓下游任务是否需要 [CLS] Token
对于涉及文本对的应用,一种常见的模式是在应用双向交叉注意力之前对文本对进行独立编码
BERT使用自注意力机制将这两个阶段统一起来,因为编码一个具有自注意力的串联文本对有效地包含了两个句子之间的双向交叉注意力(按照 training 数据的处理方法,如果输入为文本对,通过 [SEP] Token 以及 Segment embedding 区别两个句子)
对于每个下游任务,我们只需将特定于任务的输入和输出 plug in BERT,并端到端地微调所有参数
对于Token级的NLP任务,需要将Token的隐层表示被输入到一个输出层,用于得到Token级别的任务输出
对于分类任务,只需将 [CLS] 表示送入输出层进行分类,得到分类结果
在GLEU任务上的微调结构:


4 Experiments
省略
看到这里啦,点赞关注不迷路哦~
O(∩_∩)O
相关文章:
BERT模型
BERT模型是由谷歌团队于2019年提出的 Encoder-only 的 语言模型,发表于NLP顶会ACL上。原文题目为:《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》链接 在前大模型时代,BERT模型可以算是一个参数量比…...
技术的优势和挑战)
举例说明计算机视觉(CV)技术的优势和挑战
计算机视觉(CV)技术是通过计算机模拟和处理图像与视频数据来模拟人类视觉的能力。它可以带来许多优势,也面临一些挑战。 优势: 自动化:CV技术可以自动处理大量的图像和视频数据,从而提高工作效率和准确性。…...
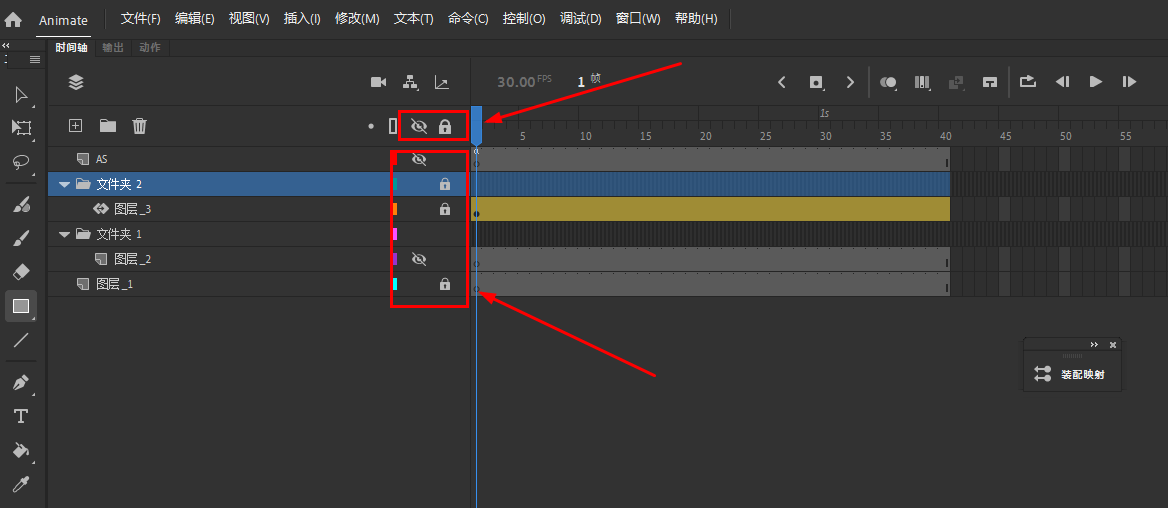
Animate软件基础:关于补间动画中的图层
Animate 文档中的每一个场景都可以包含任意数量的时间轴图层。使用图层和图层文件夹可组织动画序列的内容和分隔动画对象。在图层和文件夹中组织它们可防止它们在重叠时相互擦除、连接或分段。若要创建一次包含多个元件或文本字段的补间移动的动画,请将每个对象放置…...

mac|安装hashcat(压缩包密码p解)
一、安装Macports(如果有brew就不用这一步) 根据官网文档:The MacPorts Project -- Download & Installation,安装步骤如下 1、下载MacPorts,这里我用的是tar.gz ,可以通过keka(keka安装在…...

【保姆级系列:锐捷模拟器的下载安装使用全套教程】
保姆级系列:锐捷模拟器的下载安装使用全套教程 1.介绍2.下载3.安装4.实践教程5.验证 1.介绍 锐捷目前可以通过EVE-NG来模拟自己家的路由器,交换机,防火墙。实现方式是把自己家的镜像导入到EVE-ng里面来运行。下面主要就是介绍如何下载镜像和…...

virtualbox7安装centos7.9配置静态ip
1.背景 我大概在一年之前安装virtualbox7centos7.9的环境,但看视频说用vagrant启动的窗口可以不用第三方工具(比如xshell、secure等)连接centos7.9,于是尝鲜试了下还可以,导致系统文件格式是vmdk了(网上有vmdk转vdi的方法…...

结构型设计模式:桥接/组合/装饰/外观/享元
结构型设计模式:适配器/代理 (qq.com)...

vLLM初识(一)
vLLM初识(一) 前言 在LLM推理优化——KV Cache篇(百倍提速)中,我们已经介绍了KV Cache技术的原理,从中我们可以知道,KV Cache本质是空间换时间的技术,对于大型模型和长序列…...

【Apache Doris】周FAQ集锦:第 18 期
【Apache Doris】周FAQ集锦:第 18 期 SQL问题数据操作问题运维常见问题其它问题关于社区 欢迎查阅本周的 Apache Doris 社区 FAQ 栏目! 在这个栏目中,每周将筛选社区反馈的热门问题和话题,重点回答并进行深入探讨。旨在为广大用户…...

docker部署可执行的jar
1.将项目打包,上传到服务器的指定目录 2.在该目录下创建Dockerfile文件 3.Dockerfile写入如下指令 # 基于哪个镜像 FROM java:8 # 拷贝文件到容器,也可以直接写成ADD xxxxx.jar /app.jar ADD springboot-file-0.0.1.jar file.jar RUN bash -c touch /…...

OpenCV||超详细的图像处理模块
一、颜色变换cvtColor dst cv2.cvtColor(src, code[, dstCn[, dst]]) src: 输入图像,即要进行颜色空间转换的原始图像。code: 转换代码,指定要执行的颜色空间转换类型。这是一个必需的参数,决定了源颜色空间到目标颜色空间的转换方式。dst…...

java面向对象期末总结
子类父类方法执行顺序?多态中和子类打印不一样; 子类在实现父类方法的时候没有用super关键字进行调用也会先执行父类的构造方法吗? 是的,当子类实例化时,先执行父类的构造方法,再执行子类的构造方法。即使在…...

文件搜索 36
删除文件 文件搜索 package File;import java.io.File;public class file3 {public static void main(String[] args) {search(new File("D :/"), "qq");}/*** 去目录搜索文件* param dir 目录* param filename 要搜索的文件名称*/public static void sear…...

IO多路转接
文章目录 五种IO模型fcntl多路转接selectpollepollepoll的工作模式 五种IO模型 阻塞IO: 在内核将数据准备好之前, 系统调用会一直等待. 所有的套接字, 默认都是阻塞方式.阻塞IO是最常见的IO模型。非阻塞IO: 如果内核还未将数据准备好, 系统调用仍然会直接返回, 并且返回EWOULD…...

基于深度学习的面部表情分类识别系统
:温馨提示:文末有 CSDN 平台官方提供的学长 QQ 名片 :) 1. 项目简介 面部表情识别是计算机视觉领域的一个重要研究方向, 它在人机交互、心理健康评估、安全监控等领域具有广泛的应用。近年来,随着深度学习技术的快速发展…...

日志远程同步实验
目录 一.实验环境 二.实验配置 1.node1发送方配置 (1)node1写udp协议 (2)重启服务并清空日志 2.node2接收方配置 (1)node2打开接受日志的插件,指定插件用的端口 (2ÿ…...

数据结构之《二叉树》(中)
在数据结构之《二叉树》(上)中学习了树的相关概念,还了解的树中的二叉树的顺序结构和链式结构,在本篇中我们将重点学习二叉树中的堆的相关概念与性质,同时试着实现堆中的相关方法,一起加油吧! 1.实现顺序结构二叉树 在…...
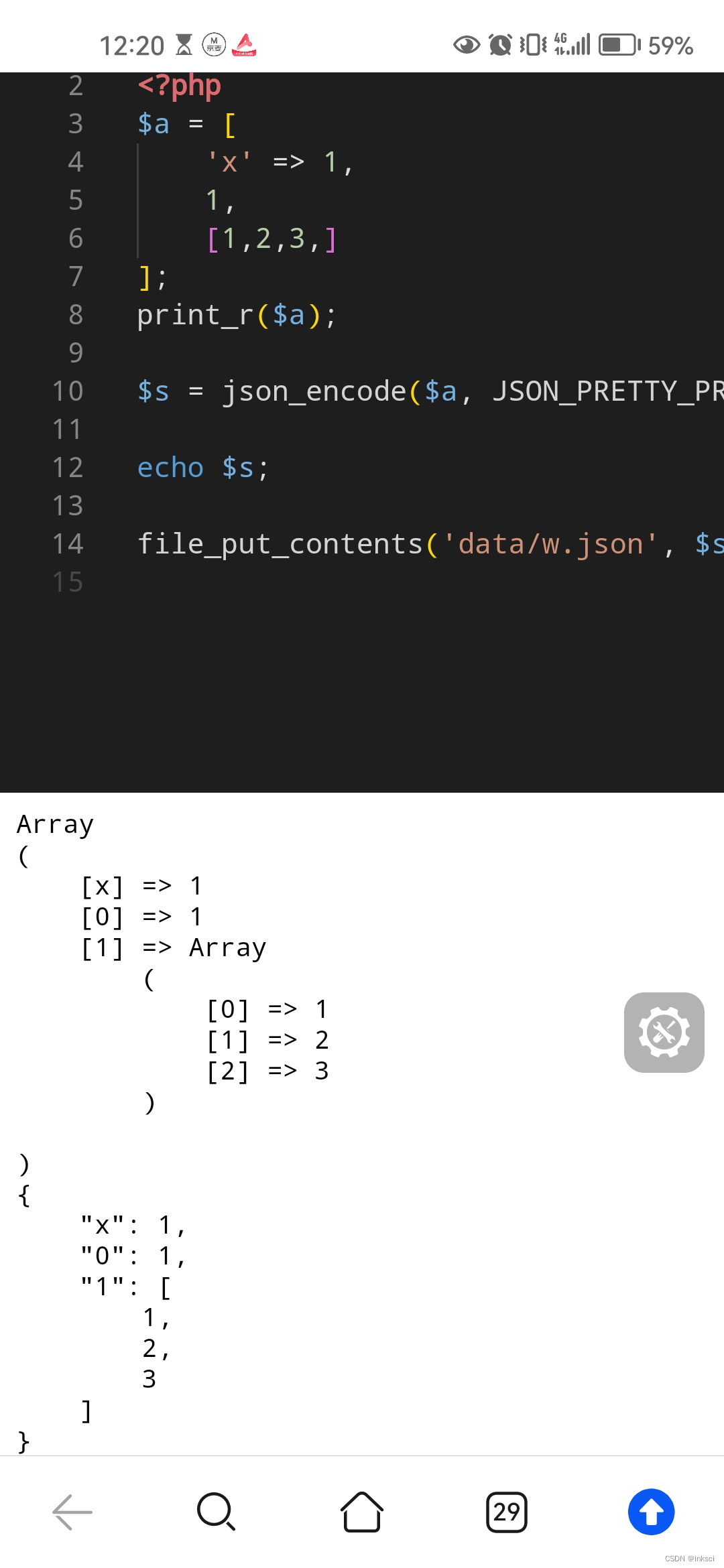
php json_encode 参数 JSON_PRETTY_PRINT
https://andi.cn/page/621642.html...

【UE 网络】Gameplay框架在DS架构中的扮演的角色
目录 0 引言1 核心内容1.1 Gameplay各部分创建的流程1.2 Gameplay框架在DS和客户端的存在情况1.3 数据是独立存在于DS和客户端的 2 Gameplay框架各自负责的功能2.1 GameMode2.2 GameState2.3 PlayerController2.4 PlayerState2.5 Pawn2.6 AIController2.7 Actor2.8 HUD2.9 UI &…...

【云原生】StatefulSet控制器详解
StatefulSet 文章目录 StatefulSet一、介绍与特点1.1、介绍1.2、特点1.3、组成部分1.4、为什么需要无头服务1.5、为什么需要volumeClaimTemplate 二、教程2.1、创建StatefulSet2.2、查看部署资源 三、StatefulSet中的Pod3.1、检查Pod的顺序索引3.2、使用稳定的网络身份标识3.3、…...

日语AI面试高效通关秘籍:专业解读与青柚面试智能助攻
在如今就业市场竞争日益激烈的背景下,越来越多的求职者将目光投向了日本及中日双语岗位。但是,一场日语面试往往让许多人感到步履维艰。你是否也曾因为面试官抛出的“刁钻问题”而心生畏惧?面对生疏的日语交流环境,即便提前恶补了…...

HTML 语义化
目录 HTML 语义化HTML5 新特性HTML 语义化的好处语义化标签的使用场景最佳实践 HTML 语义化 HTML5 新特性 标准答案: 语义化标签: <header>:页头<nav>:导航<main>:主要内容<article>&#x…...
` 方法)
深入浅出:JavaScript 中的 `window.crypto.getRandomValues()` 方法
深入浅出:JavaScript 中的 window.crypto.getRandomValues() 方法 在现代 Web 开发中,随机数的生成看似简单,却隐藏着许多玄机。无论是生成密码、加密密钥,还是创建安全令牌,随机数的质量直接关系到系统的安全性。Jav…...

基于服务器使用 apt 安装、配置 Nginx
🧾 一、查看可安装的 Nginx 版本 首先,你可以运行以下命令查看可用版本: apt-cache madison nginx-core输出示例: nginx-core | 1.18.0-6ubuntu14.6 | http://archive.ubuntu.com/ubuntu focal-updates/main amd64 Packages ng…...

2.Vue编写一个app
1.src中重要的组成 1.1main.ts // 引入createApp用于创建应用 import { createApp } from "vue"; // 引用App根组件 import App from ./App.vue;createApp(App).mount(#app)1.2 App.vue 其中要写三种标签 <template> <!--html--> </template>…...

代码随想录刷题day30
1、零钱兑换II 给你一个整数数组 coins 表示不同面额的硬币,另给一个整数 amount 表示总金额。 请你计算并返回可以凑成总金额的硬币组合数。如果任何硬币组合都无法凑出总金额,返回 0 。 假设每一种面额的硬币有无限个。 题目数据保证结果符合 32 位带…...

Kafka入门-生产者
生产者 生产者发送流程: 延迟时间为0ms时,也就意味着每当有数据就会直接发送 异步发送API 异步发送和同步发送的不同在于:异步发送不需要等待结果,同步发送必须等待结果才能进行下一步发送。 普通异步发送 首先导入所需的k…...

深度学习水论文:mamba+图像增强
🧀当前视觉领域对高效长序列建模需求激增,对Mamba图像增强这方向的研究自然也逐渐火热。原因在于其高效长程建模,以及动态计算优势,在图像质量提升和细节恢复方面有难以替代的作用。 🧀因此短时间内,就有不…...

【MATLAB代码】基于最大相关熵准则(MCC)的三维鲁棒卡尔曼滤波算法(MCC-KF),附源代码|订阅专栏后可直接查看
文章所述的代码实现了基于最大相关熵准则(MCC)的三维鲁棒卡尔曼滤波算法(MCC-KF),针对传感器观测数据中存在的脉冲型异常噪声问题,通过非线性加权机制提升滤波器的抗干扰能力。代码通过对比传统KF与MCC-KF在含异常值场景下的表现,验证了后者在状态估计鲁棒性方面的显著优…...

探索Selenium:自动化测试的神奇钥匙
目录 一、Selenium 是什么1.1 定义与概念1.2 发展历程1.3 功能概述 二、Selenium 工作原理剖析2.1 架构组成2.2 工作流程2.3 通信机制 三、Selenium 的优势3.1 跨浏览器与平台支持3.2 丰富的语言支持3.3 强大的社区支持 四、Selenium 的应用场景4.1 Web 应用自动化测试4.2 数据…...