数据结构实验报告-树与二叉树
桂 林 理 工 大 学
实 验 报 告
一、实验名称:
实验6 树和二叉树
二、实验内容:
1.编写二叉树的递归遍历算法,实现:给定一棵二叉树的“扩展先序遍历序列”,创建这棵二叉树。
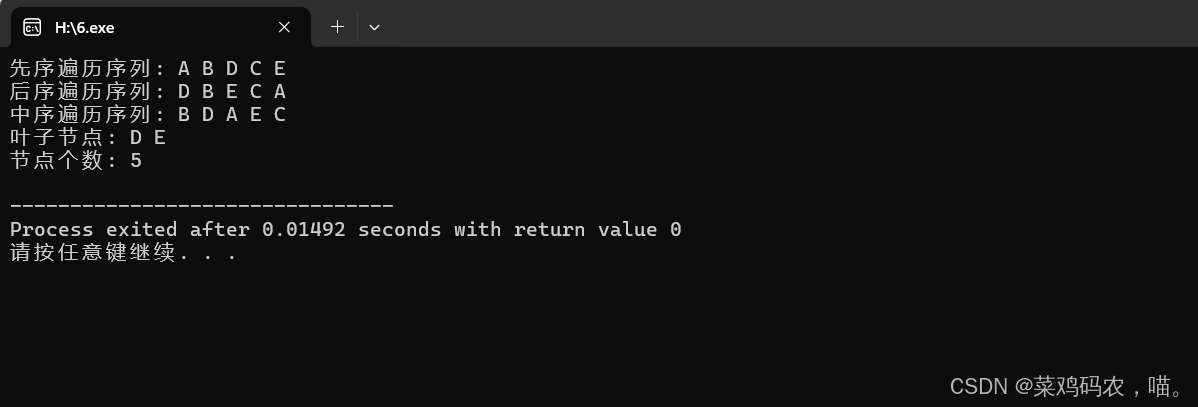
(1)输出二叉树的先序遍历的结点序列。
(2)输出二叉树的后序遍历的结点序列。
(3)输出二叉树的中序遍历的结点序列。
(4)输出二叉树的叶子结点。
(5)统计二叉树的结点个数。
源码:
#include <stdio.h>
#include <stdlib.h>
typedef struct TreeNode {
char data;
struct TreeNode *left;
struct TreeNode *right;
} TreeNode;
// 创建二叉树
TreeNode* createBinaryTree(char *str, int *index) {
if (str[*index] == '\0') {
return NULL;
}
if (str[*index] == '#') {
(*index)++;
return NULL;
}
TreeNode *root = (TreeNode*)malloc(sizeof(TreeNode));
root->data = str[*index];
(*index)++;
root->left = createBinaryTree(str, index);
root->right = createBinaryTree(str, index);
return root;
}
// 先序遍历
void preorder(TreeNode *root) {
if (root != NULL) {
printf("%c ", root->data);
preorder(root->left);
preorder(root->right);
}
}
// 后序遍历
void postorder(TreeNode *root) {
if (root != NULL) {
postorder(root->left);
postorder(root->right);
printf("%c ", root->data);
}
}
// 中序遍历
void inorder(TreeNode *root) {
if (root != NULL) {
inorder(root->left);
printf("%c ", root->data);
inorder(root->right);
}
}
// 输出叶子节点
void printLeaves(TreeNode *root) {
if (root != NULL) {
if (root->left == NULL && root->right == NULL) {
printf("%c ", root->data);
}
printLeaves(root->left);
printLeaves(root->right);
}
}
// 统计节点个数
int countNodes(TreeNode *root) {
if (root == NULL) {
return 0;
}
return 1 + countNodes(root->left) + countNodes(root->right);
}
int main() {
char str[] = "AB#D##CE##"; // 示例扩展先序遍历序列
int index = 0;
TreeNode *root = createBinaryTree(str, &index);
printf("先序遍历序列: ");
preorder(root);
printf("\n");
printf("后序遍历序列: ");
postorder(root);
printf("\n");
printf("中序遍历序列: ");
inorder(root);
printf("\n");
printf("叶子节点: ");
printLeaves(root);
printf("\n");
printf("节点个数: %d\n", countNodes(root));
return 0;
}
2.编写非递归遍历算法,实现:给定一棵二又树的先序 遍历序列和中序通历序列,创建这棵二叉树。
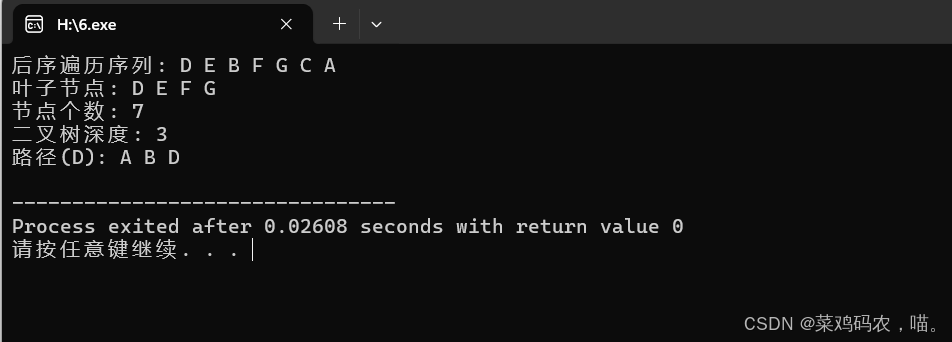
(1)输出二叉树的后序遍历的结点序列。
(2)输出二叉树的叶子结点。
(3)统计二叉树的结点个数。
(4)求二叉树的深度。
(5)输出二叉树指定结点的路径。
源码:
#include <iostream>
#include <stack>
#include <vector>
#include <unordered_map>
using namespace std;
struct TreeNode {
char data;
TreeNode* left;
TreeNode* right;
TreeNode(char val) : data(val), left(NULL), right(NULL) {}
};
TreeNode* buildTree(vector<char>& preorder, vector<char>& inorder) {
if (preorder.empty() || inorder.empty()) return NULL;
unordered_map<char, int> inorder_map;
for (int i = 0; i < inorder.size(); ++i) {
inorder_map[inorder[i]] = i;
}
stack<TreeNode*> stk;
TreeNode* root = new TreeNode(preorder[0]);
stk.push(root);
for (int i = 1; i < preorder.size(); ++i) {
TreeNode* node = new TreeNode(preorder[i]);
TreeNode* top = stk.top();
if (inorder_map[node->data] < inorder_map[top->data]) {
top->left = node;
} else {
TreeNode* parent = NULL;
while (!stk.empty() && inorder_map[node->data] > inorder_map[stk.top()->data]) {
parent = stk.top();
stk.pop();
}
parent->right = node;
}
stk.push(node);
}
return root;
}
void postorderTraversal(TreeNode* root) {
if (root == NULL) return;
stack<TreeNode*> stk;
vector<char> result;
stk.push(root);
while (!stk.empty()) {
TreeNode* node = stk.top();
stk.pop();
result.insert(result.begin(), node->data);
if (node->left) stk.push(node->left);
if (node->right) stk.push(node->right);
}
for (char ch : result) {
cout << ch << " ";
}
}
void printLeaves(TreeNode* root) {
if (root == NULL) return;
if (root->left == NULL && root->right == NULL) {
cout << root->data << " ";
}
printLeaves(root->left);
printLeaves(root->right);
}
int countNodes(TreeNode* root) {
if (root == NULL) return 0;
return 1 + countNodes(root->left) + countNodes(root->right);
}
int maxDepth(TreeNode* root) {
if (root == NULL) return 0;
return 1 + max(maxDepth(root->left), maxDepth(root->right));
}
void findPath(TreeNode* root, char target, vector<char>& path) {
if (root == NULL) return;
path.push_back(root->data);
if (root->data == target) {
for (char ch : path) {
cout << ch << " ";
}
cout << endl;
}
findPath(root->left, target, path);
findPath(root->right, target, path);
path.pop_back();
}
int main() {
vector<char> preorder = {'A', 'B', 'D', 'E', 'C', 'F', 'G'};
vector<char> inorder = {'D', 'B', 'E', 'A', 'F', 'C', 'G'};
TreeNode* root = buildTree(preorder, inorder);
cout << "后序遍历序列: ";
postorderTraversal(root);
cout << endl;
cout << "叶子节点: ";
printLeaves(root);
cout << endl;
cout << "节点个数: " << countNodes(root) << endl;
cout << "二叉树深度: " << maxDepth(root) << endl;
char target = 'D';
cout << "路径(" << target << "): ";
vector<char> path;
findPath(root, target, path);
return 0;
}
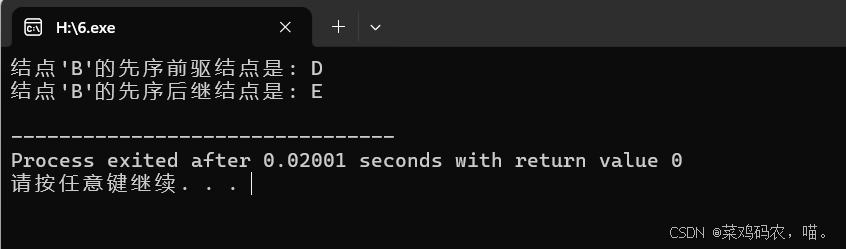
3.接1题,编写算法实现二叉树的先序线索化,并查找结点p的先序前驱结点和先序后继结点。
源码:
#include <iostream>
#include <stack>
using namespace std;
struct TreeNode {
char data;
TreeNode *left;
TreeNode *right;
bool isThreaded; // 线索化标记
TreeNode(char val) : data(val), left(NULL), right(NULL), isThreaded(false) {}
};
void preorderThreading(TreeNode* root, TreeNode*& prev) {
if (root == NULL) return;
if (root->left == NULL) {
root->left = prev;
root->isThreaded = true;
}
if (prev != NULL && prev->right == NULL) {
prev->right = root;
prev->isThreaded = true;
}
prev = root;
if (!root->isThreaded) {
preorderThreading(root->left, prev);
}
preorderThreading(root->right, prev);
}
TreeNode* preorderSuccessor(TreeNode* node) {
if (node->isThreaded) {
return node->right;
} else {
TreeNode* curr = node->right;
while (curr != NULL && !curr->isThreaded) {
curr = curr->left;
}
return curr;
}
}
TreeNode* preorderPredecessor(TreeNode* node) {
if (node->left != NULL) {
TreeNode* curr = node->left;
while (curr->right != NULL && !curr->right->isThreaded) {
curr = curr->right;
}
return curr;
} else {
return node->right;
}
}
int main() {
TreeNode *root = new TreeNode('A');
root->left = new TreeNode('B');
root->right = new TreeNode('C');
root->left->left = new TreeNode('D');
root->left->right = new TreeNode('E');
root->right->left = new TreeNode('F');
root->right->right = new TreeNode('G');
TreeNode *prev = NULL;
preorderThreading(root, prev);
TreeNode *target = root->left; // 以结点'B'为例
TreeNode *predecessor = preorderPredecessor(target);
TreeNode *successor = preorderSuccessor(target);
if (predecessor) {
cout << "结点'" << target->data << "'的先序前驱结点是: " << predecessor->data << endl;
} else {
cout << "结点'" << target->data << "'没有先序前驱结点" << endl;
}
if (successor) {
cout << "结点'" << target->data << "'的先序后继结点是: " << successor->data << endl;
} else {
cout << "结点'" << target->data << "'没有先序后继结点" << endl;
}
return 0;
}
四、心得体会:
通过实现二叉树的先序线索化算法,并查找指定结点的先序前驱和后继结点,我深刻体会到了树结构的复杂和线索化的重要性。在操作过程中,我学会了如何处理线索化和利用前序遍历进行结点的查找,进一步加深了对二叉树数据结构的理解。通过这一实践,我意识到了算法设计的精妙之处,同时也深感数据结构对于解决复杂问题的重要性。在编写代码的过程中,我不断思考优化方案,增强了自己的编程能力和逻辑思维能力。总的来说,这次实践让我收获颇丰,同时也更加坚定了我对算法与数据结构学习的重要性,激发了我对计算机科学领域的无限热情。
相关文章:
数据结构实验报告-树与二叉树
桂 林 理 工 大 学 实 验 报 告 一、实验名称: 实验6 树和二叉树 二、实验内容: 1.编写二叉树的递归遍历算法,实现:给定一棵二叉树的“扩展先序遍历序列”,创建这棵二叉树。 (1)输出二叉树的先序遍历的结点序列。 (2)输出二…...

基于Django+MySQL球馆场地预约系统的设计与实现(源码+论文+部署讲解等)
博主介绍:✌全网粉丝10W,csdn特邀作者、博客专家、CSDN新星计划导师、Java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和学生毕业项目实战,高校老师/讲师/同行前辈交流✌ 技术栈介绍:我是程序员阿龙ÿ…...

8 MQTT
8 MQTT 1、相关概念2、MQTT的操作过程3、MQTT协议3.1 固定报文3.2 连接报文3.3 确认连接请求3.4 构造订阅报文3.5 订阅确认报文3.6 发布报文3.7 其他报文 1、相关概念 MQTT [1] 全名为Message Queuing Telemetry Transport,是一种基于TCP/IP协议上传输的轻量级通信…...

【文件系统】抽象磁盘的存储结构 CHS寻址法 | sector数组 | LAB数组
目录 1.为什么要抽象 2.逻辑抽象_版本1 2.1sector数组 2.2index转化CHS 3.逻辑抽象_版本2 3.1LBA数组 3.2LAB下标转化sector下标 文件其实就是在磁盘中占有几个扇区的问题❗文件是很多个sector的数组下标❗文件是有很多块构成的❗❗文件由很多扇区构成------>文件…...

基于python旅游推荐系统(源码+论文+部署讲解等)
博主介绍:✌全网粉丝10W,csdn特邀作者、博客专家、CSDN新星计划导师、Java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和学生毕业项目实战,高校老师/讲师/同行前辈交流✌ 技术栈介绍:我是程序员阿龙ÿ…...

Mysql大单表JSON优化
优化方案 MySQL 8.0.32 中,有几种方法可以优化存储 JSON 字符串的数据表。以下是一些建议,可以帮助您减少存储空间: 使用压缩: MySQL 8.0 支持表级压缩,可以通过修改表来启用压缩。 ALTER TABLE your_table ROW_FORMATCOMPRESS…...

电脑开机启动项管理小工具,绿色免安装
HiBit Startup Manager 是一款功能强大的启动项管理工具,旨在帮助用户管理和优化计算机的自动启动程序。该软件通过添加或删除应用程序、编辑它们的属性以及管理流程、服务、任务调度程序和上下文菜单来实现这一目标。 HiBit Startup Manager 提供了以下主要功能&a…...
一例AutoHotkey语言生成的文件夹病毒分析
概述 这是一个使用AutoHotkey语言编写的文件夹病毒,使用ftp服务器来当作C2,通过U盘传播,样本很古老,原理也很简单,这种语言的样本还是第一次见到,记录一下。 样本的基本信息 PE32库: AutoIt(3.XX)[-]编译…...

【机器学习第7章——贝叶斯分类器】
机器学习第7章——贝叶斯分类器 7.贝叶斯分类器7.1贝叶斯决策论7.2 朴素贝叶斯分类器条件概率的m估计 7.3 极大似然估计优点基本原理 7.4 贝叶斯网络7.5 半朴素贝叶斯分类器7.6 EM算法7.7 EM算法实现 7.贝叶斯分类器 7.1贝叶斯决策论 一个医疗判断问题 有两个可选的假设&#…...

C++ QT开发 学习笔记(3)
C QT开发 学习笔记(3) - WPS项目 标准对话框 对话框类说明静态函数函数说明QFileDialog文件对话框getOpenFileName()选择打开一个文件getOpenFileNames()选择打开多个文件getSaveFileName()选择保存一个文件getExistingDirectory()选择一个己有的目录getOpenFileUrl()选择打幵…...

【Python实战】如何优雅地实现文字 二维码检测?
前几篇,和大家分享了如何通过 Python 和相关库,自动化处理 PDF 文档,提高办公效率。 【Python实战】自动化处理 PDF 文档,完美实现 WPS 会员功能【Python实战】如何优雅地实现 PDF 去水印?【Python实战】一键生成 PDF…...

行为型设计模式3:模板方法/备忘录/解释器/迭代器
设计模式:模板方法/备忘录/解释器/迭代器 (qq.com)...
思源笔记软件的优缺点分析
在过去一年里,我用了很多款笔记,从word文档到onenote到语雀再到思源,最后坚定的选择了思源笔记 使用感受 首先是用word文档来记笔记,主要是开始时不知道笔记软件怎么好用,等到笔记越来越膨胀的时候我发现,…...

追问试面试系列:Dubbo
欢迎来到Dubbo系列,在面试中被问到Dubbo相关的问题时,大部分都是简历上写了Dubbo,或者面试官想尝试问问你对Dubbo是否了解。 本系列主要是针对面试官通过一个点就使劲儿往下问的情况。 面试官:说说你们项目亮点 好的面试官 我们这个项目的技术亮点在于采用了Spring Cloud…...

动手学深度学习V2每日笔记(卷积层)
本文主要参考沐神的视频教程 https://www.bilibili.com/video/BV1L64y1m7Nh/p2&spm_id_from333.1007.top_right_bar_window_history.content.click&vd_sourcec7bfc6ce0ea0cbe43aa288ba2713e56d 文档教程 https://zh-v2.d2l.ai/ 本文的主要内容对沐神提供的代码中个人不…...

qcom ucsi probe
ucsi glink 注册一个ucsi 设备,和pmic glink进行通信,ucsi作为pmic glink的一个client。 lkml的patch https://lkml.org/lkml/2023/1/30/233 dtsi中一般会定义 qcom,ucsi-glink 信息,用于和驱动进行匹配 static const struct of_device_id …...

flask和redis配合
对于涉及数据提交的场景,比如更新用户信息,你可能会使用POST或PUT请求。但是,这些操作通常与直接从Redis缓存中检索数据不同,因为它们可能涉及到对后端数据库或其他存储系统的修改。并且可能需要将更新后的数据同步回Redis缓存&am…...

深度学习中的早停法
早停法(Early Stopping)是一种用于防止模型过拟合的技术,在训练过程中监视验证集(或者测试集)上的损失值。具体设立早停的限制包括两个主要参数: Patience(耐心):这是指验…...

科普文:JUC系列之多线程门闩同步器CountDownLatch的使用和源码
CountDownLatch类位于java.util.concurrent包下,利用它可以实现类似计数器的功能。比如有一个任务A,它要等待其他10个线程的任务执行完毕之后才能执行,此时就可以利用CountDownLatch来实现这种功能了。 CountDownLatch是通过一个计数器来实现…...

foreach循环和for循环在PHP中各有什么优势
在PHP中,foreach循环和for循环都是用来遍历数组的常用结构,但它们各有其优势和使用场景。 foreach循环的优势 简化代码:foreach循环提供了一种更简洁的方式来遍历数组,不需要手动控制索引或指针。易于阅读:对于简单的…...

Redis相关知识总结(缓存雪崩,缓存穿透,缓存击穿,Redis实现分布式锁,如何保持数据库和缓存一致)
文章目录 1.什么是Redis?2.为什么要使用redis作为mysql的缓存?3.什么是缓存雪崩、缓存穿透、缓存击穿?3.1缓存雪崩3.1.1 大量缓存同时过期3.1.2 Redis宕机 3.2 缓存击穿3.3 缓存穿透3.4 总结 4. 数据库和缓存如何保持一致性5. Redis实现分布式…...

Cesium1.95中高性能加载1500个点
一、基本方式: 图标使用.png比.svg性能要好 <template><div id"cesiumContainer"></div><div class"toolbar"><button id"resetButton">重新生成点</button><span id"countDisplay&qu…...

为什么需要建设工程项目管理?工程项目管理有哪些亮点功能?
在建筑行业,项目管理的重要性不言而喻。随着工程规模的扩大、技术复杂度的提升,传统的管理模式已经难以满足现代工程的需求。过去,许多企业依赖手工记录、口头沟通和分散的信息管理,导致效率低下、成本失控、风险频发。例如&#…...

2024年赣州旅游投资集团社会招聘笔试真
2024年赣州旅游投资集团社会招聘笔试真 题 ( 满 分 1 0 0 分 时 间 1 2 0 分 钟 ) 一、单选题(每题只有一个正确答案,答错、不答或多答均不得分) 1.纪要的特点不包括()。 A.概括重点 B.指导传达 C. 客观纪实 D.有言必录 【答案】: D 2.1864年,()预言了电磁波的存在,并指出…...

HBuilderX安装(uni-app和小程序开发)
下载HBuilderX 访问官方网站:https://www.dcloud.io/hbuilderx.html 根据您的操作系统选择合适版本: Windows版(推荐下载标准版) Windows系统安装步骤 运行安装程序: 双击下载的.exe安装文件 如果出现安全提示&…...

多种风格导航菜单 HTML 实现(附源码)
下面我将为您展示 6 种不同风格的导航菜单实现,每种都包含完整 HTML、CSS 和 JavaScript 代码。 1. 简约水平导航栏 <!DOCTYPE html> <html lang"zh-CN"> <head><meta charset"UTF-8"><meta name"viewport&qu…...

什么?连接服务器也能可视化显示界面?:基于X11 Forwarding + CentOS + MobaXterm实战指南
文章目录 什么是X11?环境准备实战步骤1️⃣ 服务器端配置(CentOS)2️⃣ 客户端配置(MobaXterm)3️⃣ 验证X11 Forwarding4️⃣ 运行自定义GUI程序(Python示例)5️⃣ 成功效果
什么是Ansible Jinja2
理解 Ansible Jinja2 模板 Ansible 是一款功能强大的开源自动化工具,可让您无缝地管理和配置系统。Ansible 的一大亮点是它使用 Jinja2 模板,允许您根据变量数据动态生成文件、配置设置和脚本。本文将向您介绍 Ansible 中的 Jinja2 模板,并通…...

【笔记】WSL 中 Rust 安装与测试完整记录
#工作记录 WSL 中 Rust 安装与测试完整记录 1. 运行环境 系统:Ubuntu 24.04 LTS (WSL2)架构:x86_64 (GNU/Linux)Rust 版本:rustc 1.87.0 (2025-05-09)Cargo 版本:cargo 1.87.0 (2025-05-06) 2. 安装 Rust 2.1 使用 Rust 官方安…...

MyBatis中关于缓存的理解
MyBatis缓存 MyBatis系统当中默认定义两级缓存:一级缓存、二级缓存 默认情况下,只有一级缓存开启(sqlSession级别的缓存)二级缓存需要手动开启配置,需要局域namespace级别的缓存 一级缓存(本地缓存&#…...