Tensorflow训练视觉模型(CPU)
目录
零、模型下载
一、清理C盘
二、 配置环境
三、运行项目前提操作
(1)根据自己的项目设置路径。每次激活虚拟环境(tensorflow115)都得重设一次
(2)执行setup
这个项目的路径移动了位置也需要重设一次
四、制作训练集
(1)设计一个文件夹。总体相片分布可以用80%train,20%test
(2)使用labelImg获得xml文件
(3)xml转csv
(4)csv转tfrecord
(5)在object_detection路径下创建training,在training文件夹建一个labelmap.pbtxt
五、模型配置
1.修改num个数,根据你class的个数写
2.batch_size根据你电脑的性能填,最低填1
3.训练最高步数限制
4.路径修改
编辑六、模型开始训练
七、观察训练
八、生成模型
九、测试模型
十、寻找别人训练好的模型
零、模型下载
GitHub - tensorflow/models: Models and examples built with TensorFlow
Detection/faster_rcnn_inception_v2_coco_2018_01_28 at master · librahfacebook/Detection · GitHub
一、清理C盘
修改conda默认envs_dirs和pkgs_dirs
推荐博文(若侵权告知必删):http://t.csdnimg.cn/Ki52N
二、 配置环境
(1)用anaconda创建虚拟环境
win+R进入cmd 或者 进入Anaconda Prompt应用(这里是cpu,如果你用GPU推荐Anaconda Prompt,会帮你安装跑GPU要用的驱动)

conda create -n tensorflow115 python=3.6(2)创建完环境后,一一输入下面的指令
conda activate tensorflow115conda install tensorflow=1.15.0conda install -c anaconda protobuf如果这个指令报错404尝试换源
找到的.condarc文件打开。
拷贝以下镜像源到该文件
channels:- https://mirrors.sjtug.sjtu.edu.cn/anaconda/pkgs/main/- https://mirrors.sjtug.sjtu.edu.cn/anaconda/pkgs/free/- defaults
ssl_verify: true
show_channel_urls: truepip install pillow
pip install lxml
pip install jupyter
pip install matplotlib
pip install pandas
pip install opencv-python==4.3.0.38
三、运行项目前提操作
(1)根据自己的项目设置路径。每次激活虚拟环境(tensorflow115)都得重设一次
set PYTHONPATH=G:\BaiduNetdiskDownload\Tensorflow+FasterRCNN+KITTI\models;G:\BaiduNetdiskDownload\Tensorflow+FasterRCNN+KITTI\models\research;G:\BaiduNetdiskDownload\Tensorflow+FasterRCNN+KITTI\models\research\slim(2)执行setup
这个项目的路径移动了位置也需要重设一次
命令端进入research路径

输入指令
python setup.py buildpython setup.py install四、制作训练集
(1)设计一个文件夹。总体相片分布可以用80%train,20%test

(2)使用labelImg获得xml文件
pip install labelimg使用labelimg指令
labelimg
快捷键操作
Ctrl + u 选择要标注的文件目录;
Ctrl + r 选择标注好的标签存放的目录;
Ctrl + s 保存标注好的标签(自动保存模式下会自动保存);
Ctrl + d 复制当前标签和矩形框;
Ctrl + Shift + d 删除当前图片;
Space 将当前图像标记为已验证;
w 开始创建矩形框;
d 切换到下一张图;
a 切换到上一张图;
del 删除选中的标注矩形框;
Ctrl++ 放大图片;
Ctrl-- 缩小图片;
↑→↓← 移动选中的矩形框的位置;
(3)xml转csv
路径根据实际情况修改
import os
import glob
import pandas as pd
import xml.etree.ElementTree as ETdef xml_to_csv(path):xml_list = []for xml_file in glob.glob(path + '/*.xml'):tree = ET.parse(xml_file)root = tree.getroot()for member in root.findall('object'):value = (root.find('filename').text,int(root.find('size')[0].text),int(root.find('size')[1].text),member[0].text,int(member[4][0].text),int(member[4][1].text),int(member[4][2].text),int(member[4][3].text))xml_list.append(value)column_name = ['filename', 'width', 'height', 'class', 'xmin', 'ymin', 'xmax', 'ymax']xml_df = pd.DataFrame(xml_list, columns=column_name)return xml_dfdef main():for folder in ['train','test']:image_path = os.path.join(os.getcwd(), ('images/' + folder))xml_df = xml_to_csv(image_path)xml_df.to_csv(('images/' + folder + '_labels.csv'), index=None)print('Successfully converted xml to csv.')main()
(4)csv转tfrecord
"""
Usage:# From tensorflow/models/# Create train data:python generate_tfrecord.py --csv_input=images/train_labels.csv --image_dir=images/train --output_path=train.record# Create test data:python generate_tfrecord.py --csv_input=images/test_labels.csv --image_dir=images/test --output_path=test.record
"""
from __future__ import division
from __future__ import print_function
from __future__ import absolute_importimport os
import io
import pandas as pd
import tensorflow as tffrom PIL import Image
from object_detection.utils import dataset_util
from collections import namedtuple, OrderedDictos.environ['TF_CPP_MIN_LOG_LEVEL']='2'flags = tf.app.flags
flags.DEFINE_string('csv_input', '', 'Path to the CSV input')
flags.DEFINE_string('image_dir', '', 'Path to the image directory')
flags.DEFINE_string('output_path', '', 'Path to output TFRecord')
FLAGS = flags.FLAGS# TO-DO replace this with label map
def class_text_to_int(row_label):if row_label == 'Car':return 1if row_label == 'Van':return 2if row_label == 'Truck':return 3if row_label == 'Pedestrian':return 4if row_label == 'Person_sitting':return 5if row_label == 'Cyclist':return 6if row_label == 'Tram':return 7if row_label == 'Misc':return 8else:return 0def split(df, group):data = namedtuple('data', ['filename', 'object'])gb = df.groupby(group)return [data(filename, gb.get_group(x)) for filename, x in zip(gb.groups.keys(), gb.groups)]def create_tf_example(group, path):with tf.gfile.GFile(os.path.join(path, '{}'.format(group.filename)), 'rb') as fid:encoded_jpg = fid.read()encoded_jpg_io = io.BytesIO(encoded_jpg)image = Image.open(encoded_jpg_io)width, height = image.sizefilename = group.filename.encode('utf8')image_format = b'jpg'xmins = []xmaxs = []ymins = []ymaxs = []classes_text = []classes = []for index, row in group.object.iterrows():xmins.append(row['xmin'] / width)xmaxs.append(row['xmax'] / width)ymins.append(row['ymin'] / height)ymaxs.append(row['ymax'] / height)classes_text.append(row['class'].encode('utf8'))classes.append(class_text_to_int(row['class']))tf_example = tf.train.Example(features=tf.train.Features(feature={'image/height': dataset_util.int64_feature(height),'image/width': dataset_util.int64_feature(width),'image/filename': dataset_util.bytes_feature(filename),'image/source_id': dataset_util.bytes_feature(filename),'image/encoded': dataset_util.bytes_feature(encoded_jpg),'image/format': dataset_util.bytes_feature(image_format),'image/object/bbox/xmin': dataset_util.float_list_feature(xmins),'image/object/bbox/xmax': dataset_util.float_list_feature(xmaxs),'image/object/bbox/ymin': dataset_util.float_list_feature(ymins),'image/object/bbox/ymax': dataset_util.float_list_feature(ymaxs),'image/object/class/text': dataset_util.bytes_list_feature(classes_text),'image/object/class/label': dataset_util.int64_list_feature(classes),}))return tf_exampledef main(_):writer = tf.python_io.TFRecordWriter(FLAGS.output_path)path = os.path.join(os.getcwd(), FLAGS.image_dir)examples = pd.read_csv(FLAGS.csv_input)grouped = split(examples, 'filename')for group in grouped:tf_example = create_tf_example(group, path)writer.write(tf_example.SerializeToString())writer.close()output_path = os.path.join(os.getcwd(), FLAGS.output_path)print('Successfully created the TFRecords: {}'.format(output_path))if __name__ == '__main__':tf.app.run()

这里根据你的label修改
修改完后使用下面的指令
python generate_tfrecord.py --csv_input=images/train_labels.csv --image_dir=images/train --output_path=train.record python generate_tfrecord.py --csv_input=images/test_labels.csv --image_dir=images/test --output_path=test.record(5)在object_detection路径下创建training,在training文件夹建一个labelmap.pbtxt
labelmap.pbtxt的格式

五、模型配置
在object_detection\samples\configs 文件夹下找到对应的.config文件然后将该config文件复制到刚刚创建的training文件中
拿faster_rcnn_inception_v2_coco_2018_01_28模型举例 ,复制faster_rcnn_inception_v2_coco.config到 training 文件夹下
1.修改num个数,根据你class的个数写

2.batch_size根据你电脑的性能填,最低填1

3.训练最高步数限制

4.路径修改

 六、模型开始训练
六、模型开始训练
因为我们用的CPU,所以需要修改一处地方使用CPU
开始训练
python train.py --logtostderr --train_dir=training/ --pipeline_config_path=training/faster_rcnn_inception_v2_pets.config 出现报错
 解决办法
解决办法
pip install tensorflow-estimator==1.15.0七、观察训练
开一个命令窗口,在object_detection 下运行
tensorboard --logdir=my_obgect/training
八、生成模型
python export_inference_graph.py \ --input_type image_tensor \ --pipeline_config_path training/faster_rcnn_inception_v2_pets.config \ --trained_checkpoint_prefix training/model.ckpt-4446 \ --output_directory my_detection_v1
my_detection_v1是自己在当前路径下建的空白文件夹
如果报错
Current thread 0x000045d8 (most recent call first):
解决方法
pip install tensorflow=1.15.0再重复第三、运行项目前提操作
九、测试模型
打开Object_detection_image.py(该python文件在object_detection中)
修改下面的内容,一一对应

 最后输入下面指令
最后输入下面指令
python Object_detection_image.py十、寻找别人训练好的模型
models/research/object_detection/g3doc/tf1_detection_zoo.md at master · tensorflow/models · GitHub
相关文章:
Tensorflow训练视觉模型(CPU)
目录 零、模型下载 一、清理C盘 二、 配置环境 三、运行项目前提操作 (1)根据自己的项目设置路径。每次激活虚拟环境(tensorflow115)都得重设一次 (2)执行setup 这个项目的路径移动了位置也需要重设一…...

从根儿上学习spring 十 之run方法启动第四段(4)
我们接着上一节已经准备开始分析AbstractAutowireCapableBeanFactory#doCreateBean方法,该方法是spring真正开始创建bean实例并初始化bean的入口方法,属于核心逻辑,所以我们新开一节开始分析。 图12 图12-530到536行 这几行的主要就是创建b…...
如果我的发明有修改,需要如何处理?
如果我的发明有修改,需要如何处理?...

java:File与MultipartFile互转
1 概述 当我们在处理文件上传的功能时,通常会使用MultipartFile对象来表示上传的文件数据。然而,有时候我们可能已经有了一个File对象,而不是MultipartFile对象,需要将File对象转换为MultipartFile对象进行进一步处理。 在Java中…...

高级java每日一道面试题-2024年8月04日-web篇-如果客户端禁止cookie能实现session还能用吗?
如果有遗漏,评论区告诉我进行补充 面试官: 如果客户端禁止cookie能实现session还能用吗? 我回答: 当客户端禁用了Cookie时,传统的基于Cookie的Session机制会受到影响,因为Session ID通常是通过Cookie在客户端和服务器之间传递的。然而,尽…...

leetcode 107.二叉树的层序遍||
1.题目要求: 给你二叉树的根节点 root ,返回其节点值 自底向上的层序遍历 。 (即按从叶子节点所在层到根节点所在的层,逐层从左向右遍历)2.此题步骤: 1.先创建好队列,出队和入队函数: //创建队列 typedef struct que…...

C++在网络安全领域的应用
前言: 在当今的数字化时代,网络安全已经成为一个至关重要的领域。随着网络威胁和攻击手段的不断演变,开发高效、安全的系统和工具变得尤为重要。C作为一种功能强大且高性能的编程语言,在网络安全领域发挥着不可替代的作用。本文简…...

Chapter 26 Python魔术方法
欢迎大家订阅【Python从入门到精通】专栏,一起探索Python的无限可能! 文章目录 前言一、什么是魔术方法?二、常见的魔术方法① __init__构造方法② __str__字符串方法③ __lt__比较方法④ __le__比较方法⑤ __eq__比较方法 前言 本章将详细讲…...

基于Transformer的语音识别与音频分类
重磅推荐专栏: 《大模型AIGC》 《课程大纲》 《知识星球》 本专栏致力于探索和讨论当今最前沿的技术趋势和应用领域,包括但不限于ChatGPT和Stable Diffusion等。我们将深入研究大型模型的开发和应用,以及与之相关的人工智能生成内容(AIGC)技术。通过深入的技术解析和实践经…...
)
leetcode数论(1362. 最接近的因数)
前言 经过前期的基础训练以及部分实战练习,粗略掌握了各种题型的解题思路。现阶段开始专项练习。 数论包含最大公约数(>2个数)、最大公约数性质、最小公倍数、区间范围质因素计数(最下间隔)、质因素分解、判断质数、平方根、立方根、互质、同余等等。 描述 给…...

sqli-labs-master less1-less6
目录 通关前必看 1、判断是否存在sql注入以及是字符型还是数值型: 2、各种注入方式以及方法 有回显型: 报错注入(只有ok和no的提示以及报错提示): 详细思路,后面的题都可以这样去思考 关卡实操 less…...

力扣287【寻找重复数】
给定一个包含 n 1 个整数的数组 nums ,其数字都在 [1, n] 范围内(包括 1 和 n),可知至少存在一个重复的整数。 假设 nums 只有 一个重复的整数 ,返回 这个重复的数 。 你设计的解决方案必须 不修改 数组 nums 且只用常…...
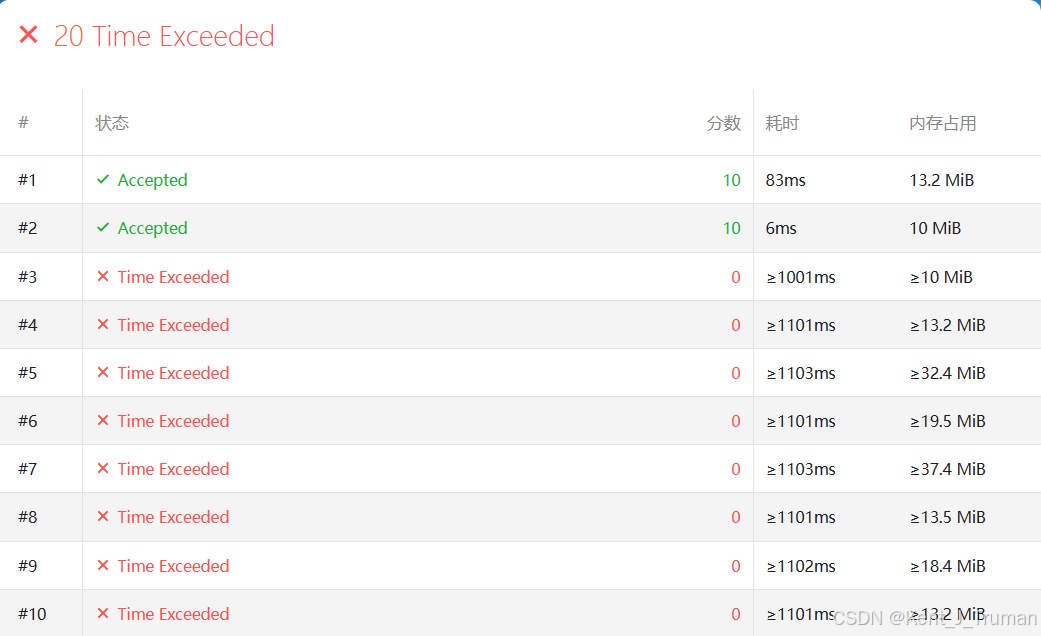
【2024蓝桥杯/C++/B组/传送阵】
题目 问题代码 #include<bits/stdc.h> using namespace std;const int N 1e610; int n; int porter[N]; int ans; int sign[N]; bool used;void dfs(int now, int cnt) {if(sign[now] && used){ans max(ans, cnt);return;}if(!sign[now]){cnt, sign[now] 1; …...

(四十一)大数据实战——spark的yarn模式生产环境部署
前言 Spark 是一个开源的分布式计算系统。它提供了高效的数据处理能力,支持复杂的数据分析和处理任务,是一种基于内存的快速、通用、可扩展的大数据分析计算引擎。Spark Core:实现了Spark的基本功能,包含任务调度、内存管理、错误…...

【深度学习实战(53)】classification_report()
classification_report()是python在机器学习中常用的输出模型评估报告的方法。 classification_report()函数介绍 classification_report()语法如下:classification_report( y_true, y_pred, labelsNone, …...

计算机网络基础之网络套接字socket编程(初步认识UDP、TCP协议)
绪论 “宿命论是那些缺乏意志力的弱者的借口。 ——罗曼.罗兰”,本章是为应用层打基础,因为在写应用层时将直接通过文本和代码的形式来更加可视化的理解网络,本章主要写的是如何使用网络套接字和udp、tcp初步认识。 话不多说安…...

手撕Python!模块、包、库,傻傻分不清?一分钟带你弄明白!
哈喽,各位小伙伴们!今天咱们来聊聊Python中的模块、包和库,很多新手小白经常搞混,别担心,看完这篇,保证你一分钟就能搞定! 打个比方: 模块 (Module): 就好比是一块块乐高积木&#…...

Linux--序列化与反序列化
序列化 序列化是指将数据结构或对象状态转换成可以存储或传输的格式的过程。在序列化过程中,对象的状态信息被转换为可以保持或传输的格式(如二进制、XML、JSON等)。序列化后的数据可以被写入到文件、数据库、内存缓冲区中,或者通…...
,并生成新的pdf导出到指定路径)
使用C#和 aspose.total 实现替换pdf中的文字(外语:捷克语言的pdf),并生成新的pdf导出到指定路径
程序主入口: Program.cs using System; using System.Collections.Generic; using System.Configuration; using System.Diagnostics; using System.Linq; using System.Text; using System.Threading.Tasks;namespace PdfEditor {public class Progra…...

【Material-UI】Autocomplete中的高亮功能(Highlights)详解
文章目录 一、简介二、实现高亮功能示例代码代码解释 三、实际应用场景1. 搜索功能2. 表单自动完成 四、总结 在现代Web开发中,提供清晰的用户反馈是提升用户体验的重要组成部分。Material-UI的Autocomplete组件通过高亮功能,帮助用户快速识别搜索结果中…...

网络六边形受到攻击
大家读完觉得有帮助记得关注和点赞!!! 抽象 现代智能交通系统 (ITS) 的一个关键要求是能够以安全、可靠和匿名的方式从互联车辆和移动设备收集地理参考数据。Nexagon 协议建立在 IETF 定位器/ID 分离协议 (…...

在软件开发中正确使用MySQL日期时间类型的深度解析
在日常软件开发场景中,时间信息的存储是底层且核心的需求。从金融交易的精确记账时间、用户操作的行为日志,到供应链系统的物流节点时间戳,时间数据的准确性直接决定业务逻辑的可靠性。MySQL作为主流关系型数据库,其日期时间类型的…...

业务系统对接大模型的基础方案:架构设计与关键步骤
业务系统对接大模型:架构设计与关键步骤 在当今数字化转型的浪潮中,大语言模型(LLM)已成为企业提升业务效率和创新能力的关键技术之一。将大模型集成到业务系统中,不仅可以优化用户体验,还能为业务决策提供…...

Mybatis逆向工程,动态创建实体类、条件扩展类、Mapper接口、Mapper.xml映射文件
今天呢,博主的学习进度也是步入了Java Mybatis 框架,目前正在逐步杨帆旗航。 那么接下来就给大家出一期有关 Mybatis 逆向工程的教学,希望能对大家有所帮助,也特别欢迎大家指点不足之处,小生很乐意接受正确的建议&…...

《Playwright:微软的自动化测试工具详解》
Playwright 简介:声明内容来自网络,将内容拼接整理出来的文档 Playwright 是微软开发的自动化测试工具,支持 Chrome、Firefox、Safari 等主流浏览器,提供多语言 API(Python、JavaScript、Java、.NET)。它的特点包括&a…...

django filter 统计数量 按属性去重
在Django中,如果你想要根据某个属性对查询集进行去重并统计数量,你可以使用values()方法配合annotate()方法来实现。这里有两种常见的方法来完成这个需求: 方法1:使用annotate()和Count 假设你有一个模型Item,并且你想…...

Cloudflare 从 Nginx 到 Pingora:性能、效率与安全的全面升级
在互联网的快速发展中,高性能、高效率和高安全性的网络服务成为了各大互联网基础设施提供商的核心追求。Cloudflare 作为全球领先的互联网安全和基础设施公司,近期做出了一个重大技术决策:弃用长期使用的 Nginx,转而采用其内部开发…...

Maven 概述、安装、配置、仓库、私服详解
目录 1、Maven 概述 1.1 Maven 的定义 1.2 Maven 解决的问题 1.3 Maven 的核心特性与优势 2、Maven 安装 2.1 下载 Maven 2.2 安装配置 Maven 2.3 测试安装 2.4 修改 Maven 本地仓库的默认路径 3、Maven 配置 3.1 配置本地仓库 3.2 配置 JDK 3.3 IDEA 配置本地 Ma…...

微软PowerBI考试 PL300-在 Power BI 中清理、转换和加载数据
微软PowerBI考试 PL300-在 Power BI 中清理、转换和加载数据 Power Query 具有大量专门帮助您清理和准备数据以供分析的功能。 您将了解如何简化复杂模型、更改数据类型、重命名对象和透视数据。 您还将了解如何分析列,以便知晓哪些列包含有价值的数据,…...

九天毕昇深度学习平台 | 如何安装库?
pip install 库名 -i https://pypi.tuna.tsinghua.edu.cn/simple --user 举个例子: 报错 ModuleNotFoundError: No module named torch 那么我需要安装 torch pip install torch -i https://pypi.tuna.tsinghua.edu.cn/simple --user pip install 库名&#x…...