新闻文本分类任务:使用Transformer实现

新闻文本分类任务:使用Transformer实现
自然语言处理(NLP)领域中的新闻文本分类任务旨在将一段文本自动分类到某个预定义的类别中,例如体育、政治、科技、娱乐等等。这是一个重要的任务,因为在日常生活中,我们需要处理各种类型的文本,并且需要在其中找到特定的信息。新闻文本分类任务的自动化可以帮助我们更快地了解大量的文本,并提供更好的搜索和推荐服务。在本文中,我们将介绍一些新闻文本分类任务的最新研究,并探讨它们的优势和劣势。
1. 传统机器学习方法
在过去,传统的机器学习方法被广泛应用于新闻文本分类任务。这些方法通常涉及手动选择和提取文本特征,例如词袋模型和tf-idf算法,以及使用一些分类器模型,例如朴素贝叶斯(Naive Bayes)、支持向量机(Support Vector Machine,SVM)和决策树等等。在这些方法中,分类器通常被训练为通过特征集将输入文本映射到其相应的类别。
然而,这些传统的机器学习方法存在一些缺点。例如,手动提取的特征可能不足以捕捉输入文本中的所有信息,并且在实际应用中,需要对特征进行精细的调整和优化。此外,在处理大规模数据集时,这些方法的计算效率可能会受到限制。下面是一个使用传统机器学习方法进行新闻文本分类的示例。
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import MultinomialNB
from sklearn.metrics import accuracy_score# 定义文本和标签列表
X = ['This is a positive statement.', 'I am happy today.', 'I am sad today.', 'This is a negative statement.']
y = ['Positive', 'Positive', 'Negative', 'Negative']# 创建特征提取器
vectorizer = CountVectorizer()# 将文本转换为特征向量
X_vec = vectorizer.fit_transform(X)# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X_vec, y, test_size=0.2, random_state=42)# 训练朴素贝叶斯分类器
clf = MultinomialNB()
clf.fit(X_train, y_train)# 在测试集上进行预测
y_pred = clf.predict(X_test)# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print('Accuracy:', accuracy)
2. 深度学习方法
近年来,深度学习方法已经成为新闻文本分类任务的热门技术。与传统机器学习方法不同,深度学习方法可以自动从原始数据中学习有意义的特征表示,并且可以应对更复杂的模式和关系。以下是一些深度学习方法的示例。
2.1 卷积神经网络
卷积神经网络(Convolutional Neural Networks,CNN)是一种广泛应用于图像识别和自然语言处理等领域的深度学习模型。在新闻文本分类任务中,CNN可以通过一系列卷积和池化操作来提取文本中的局部特征,并将其组合成更全局的特征表示。CNN的优点在于其可以处理不同长度的输入文本,并且可以避免手动设计特征。下面是一个使用CNN进行新闻文本分类的示例。
代码示例:
import numpy as np
import tensorflow as tf
from tensorflow.keras.layers import Input, Embedding, Conv1D, GlobalMaxPooling1D, Dense
from tensorflow.keras.models import Model
from tensorflow.keras.preprocessing.sequence import pad_sequences
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score# 定义文本和标签列表
X = ['This is a positive statement.', 'I am happy today.', 'I am sad today.', 'This is a negative statement.']
y = ['Positive', 'Positive', 'Negative', 'Negative']# 对标签进行编码
label_encoder = LabelEncoder()
y = label_encoder.fit_transform(y)# 将文本转换为序列
vocab_size = 10000
max_length = 20
tokenizer = tf.keras.preprocessing.text.Tokenizer(num_words=vocab_size)
tokenizer.fit_on_texts(X)
X_seq = tokenizer.texts_to_sequences(X)
X_pad = pad_sequences(X_seq, maxlen=max_length)# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X_pad, y, test_size=0.2, random_state=42)# 定义CNN模型
inputs = Input(shape=(max_length,))
x = Embedding(vocab_size, 128)(inputs)
x = Conv1D(128, 5, activation='relu')(x)
x = GlobalMaxPooling1D()(x)
x = Dense(128, activation='relu')(x)
outputs = Dense(1, activation='sigmoid')(x)
model = Model(inputs=inputs, outputs=outputs)# 编译模型并训练
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
model.fit(X_train, y_train, epochs=10, validation_data=(X_test, y_test))# 在测试集上进行预测
y_pred = model.predict(X_test)
y_pred = np.round(y_pred).flatten()# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print('Accuracy:', accuracy)
2.2 递归神经网络
递归神经网络(Recurrent Neural Networks,RNN)是一种能够处理序列数据的深度学习模型。在新闻文本分类任务中,RNN可以自动处理变长的输入文本,并且可以捕捉到文本中的时序信息。例如,在分析一篇新闻报道时,先前提到的事件可能会对后面的内容产生影响。因此,RNN在处理这种情况时可能会更加有效。
import numpy as np
import tensorflow as tf
from tensorflow.keras.layers import Input, Embedding, SimpleRNN, Dense
from tensorflow.keras.models import Model
from tensorflow.keras.preprocessing.sequence import pad_sequences
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score# 定义文本和标签列表
X = ['This is a positive statement.', 'I am happy today.', 'I am sad today.', 'This is a negative statement.']
y = ['Positive', 'Positive', 'Negative', 'Negative']# 对标签进行编码
label_encoder = LabelEncoder()
y = label_encoder.fit_transform(y)# 将文本转换为序列
vocab_size = 10000
max_length = 20
tokenizer = tf.keras.preprocessing.text.Tokenizer(num_words=vocab_size)
tokenizer.fit_on_texts(X)
X_seq = tokenizer.texts_to_sequences(X)
X_pad = pad_sequences(X_seq, maxlen=max_length)# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X_pad, y, test_size=0.2, random_state=42)# 定义RNN模型
inputs = Input(shape=(max_length,))
x = Embedding(vocab_size, 128)(inputs)
x = SimpleRNN(128)(x)
x = Dense(128, activation='relu')(x)
outputs = Dense(1, activation='sigmoid')(x)
model = Model(inputs=inputs, outputs=outputs)# 编译模型并训练
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
model.fit(X_train, y_train, epochs=10, validation_data=(X_test, y_test))# 在测试集上进行预测
y_pred = model.predict(X_test)
y_pred = np.round(y_pred).flatten()# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print('Accuracy:', accuracy)
2.3 注意力机制
注意力机制(Attention Mechanism)是一种可以为深度学习模型提供更好的上下文感知能力的技术。在新闻文本分类任务中,注意力机制可以帮助模型更好地理解文本中的关键信息,从而提高分类准确率。下面是一个使用注意力机制进行新闻文本分类的示例。
import numpy as np
import tensorflow as tf
from tensorflow.keras.layers import Input, Embedding, Bidirectional, LSTM, Dense, Attention
from tensorflow.keras.models import Model
from tensorflow.keras.preprocessing.sequence import pad_sequences
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score# 定义注意力层
attention = Attention()# 定义模型
inputs = Input(shape=(max_length,))
x = Embedding(vocab_size, 128)(inputs)
x = Bidirectional(LSTM(128, return_sequences=True))(x)
x = attention(x)
x = Dense(128, activation='relu')(x)
outputs = Dense(1, activation='sigmoid')(x)
model = Model(inputs=inputs, outputs=outputs)# 编译模型并训练
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
model.fit(X_train, y_train, epochs=10, validation_data=(X_test, y_test))# 在测试集上进行预测
y_pred = model.predict(X_test)
y_pred = np.round(y_pred).flatten()# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print('Accuracy:', accuracy)
3. 模型对比和总结
在本文中,我们介绍了传统机器学习方法和深度学习方法在新闻文本分类任务中的应用。传统机器学习方法需要手动设计特征,并且可能无法捕捉到文本中的所有信息,但是在小数据集上的表现相对较好。深度学习方法可以自动学习特征表示,并且可以处理不同长度的输入文本,但是需要更多的数据和计算资源。在具体的应用中,需要根据数据集规模、任务复杂度和计算资源等因素选择合适的方法。
在深度学习方法中,卷积神经网络、递归神经网络和注意力机制都可以用于新闻文本分类任务。卷积神经网络适用于处理局部特征,递归神经网络适用于处理时序信息,而注意力机制可以帮助模型更好地理解文本中的关键信息。在具体的应用中,需要根据任务需求选择合适的模型。
4. 结论
新闻文本分类任务是自然语言处理领域中的重要任务之一。传统机器学习方法和深度学习方法都可以用于解决该任务,但是需要根据具体的应用需求选择合适的方法和模型。深度学习方法中的卷积神经网络、递归神经网络和注意力机制都可以用于新闻文本分类任务,并且在不同的任务中有着各自的优劣势。新闻文本分类任务的自动化可以帮助我们更快地了解大量的文本,并提供更好的搜索和推荐服务,因此在未来,这个任务还有着广阔的应用前景。
相关文章:
新闻文本分类任务:使用Transformer实现
❤️觉得内容不错的话,欢迎点赞收藏加关注😊😊😊,后续会继续输入更多优质内容❤️👉有问题欢迎大家加关注私戳或者评论(包括但不限于NLP算法相关,linux学习相关,读研读博…...

如何在 Vue 中使用 防抖 和 节流
大厂面试题分享 面试题库前后端面试题库 (面试必备) 推荐:★★★★★地址:前端面试题库 https://mp.weixin.qq.com/s?__bizMzU5NzA0NzQyNg&mid2247485824&idx3&sn70cd26a7c0c683de64802f6cb9835003&scene21#wech…...

美国Linux服务器系统增强安全的配置
美国Linux服务器系统可能出现的安全漏洞中,更多是由于不当的系统配置所造成的,用户们可以通过一些适当的安全配置来防止问题的发生。美国Linux服务器系统上运行的服务越多,不当配置的概率也就越高,那么系统出现安全问题的可能性也…...

【史上最全面esp32教程】oled显示篇
文章目录前言介绍及库下载基础使用引脚的连接使用函数总结前言 本节课主要讲的是OLED的基础使用。使用的oled为0.96寸,128*64。 大家的其他型号也是可以用的。 提示:以下是本篇文章正文内容,下面案例可供参考 介绍及库下载 oled的简介&…...
第十四届蓝桥杯三月真题刷题训练——第 21 天
目录 第 1 题:灭鼠先锋 问题描述 运行限制 代码: 思路: 第 2 题:小蓝与钥匙 问题描述 答案提交 运行限制 代码: 思路 : 第 3 题:李白打酒加强版 第 4 题:机房 第 1 题࿱…...

css绘制一个Pinia小菠萝
效果如下: pinia小菠萝分为头部和身体,头部三片叶子,菠萝为身体 头部 先绘制头部的盒子,将三片叶子至于头部盒子中 先绘制中间的叶子,利用border-radius实现叶子的效果,可以借助工具来快速实现圆角的预想…...
OpenCV入门(二十)快速学会OpenCV 19 对象测量
OpenCV入门(二十)快速学会OpenCV 19 对象测量1.对象测量2.多边形拟合3.计算对象中心作者:Xiou 1.对象测量 opencv 中对象测量包括: 如面积,周长,质心,边界框等。 弧长与面积测量; …...
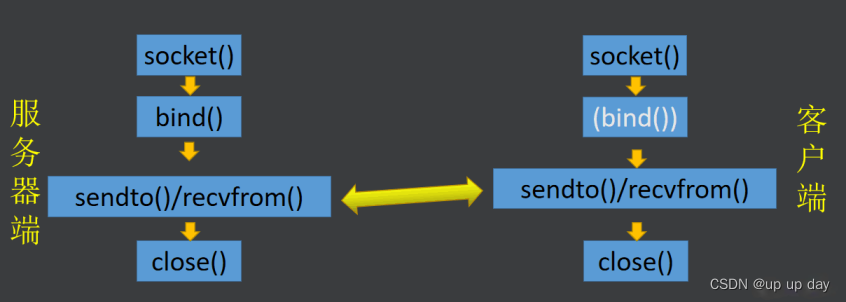
TCP和UDP协议的区别?
是否面向连接: TCP 是面向连接的传输,UDP 是面向无连接的传输。 是否是可靠传输:TCP是可靠的传输服务,在传递数据之前,会有三次握手来建立连接;在数据传递时,有确认、窗口、重传、拥塞控制机制…...
【C语言蓝桥杯每日一题】——排序
【C语言蓝桥杯每日一题】—— 排序😎前言🙌排序🙌总结撒花💞😎博客昵称:博客小梦 😊最喜欢的座右铭:全神贯注的上吧!!! 😊作者简介&am…...

学校官网的制作
学校官网 代码 <!DOCTYPE html> <html><head><meta charset"utf-8"><title></title><style>*{margin: 0;padding: 0;}.top{background-color: #3D3BB8;width: 100%;position: fixed;padding: 20px 0 12px 0;}.box{width…...

【云原生】k8s集群命令行工具kubectl之故障排除和调试命令
kubectl之故障排除和调试命令一、describe二、logs三、attach四、exec五、port-forward六、proxy七、cp八、debug8.1、案例1:共享进程空间8.2、案例2:更改启动命令、容器镜像8.3、案例3:调试节点8.4、其他一、describe 显示某个资源或某组资…...
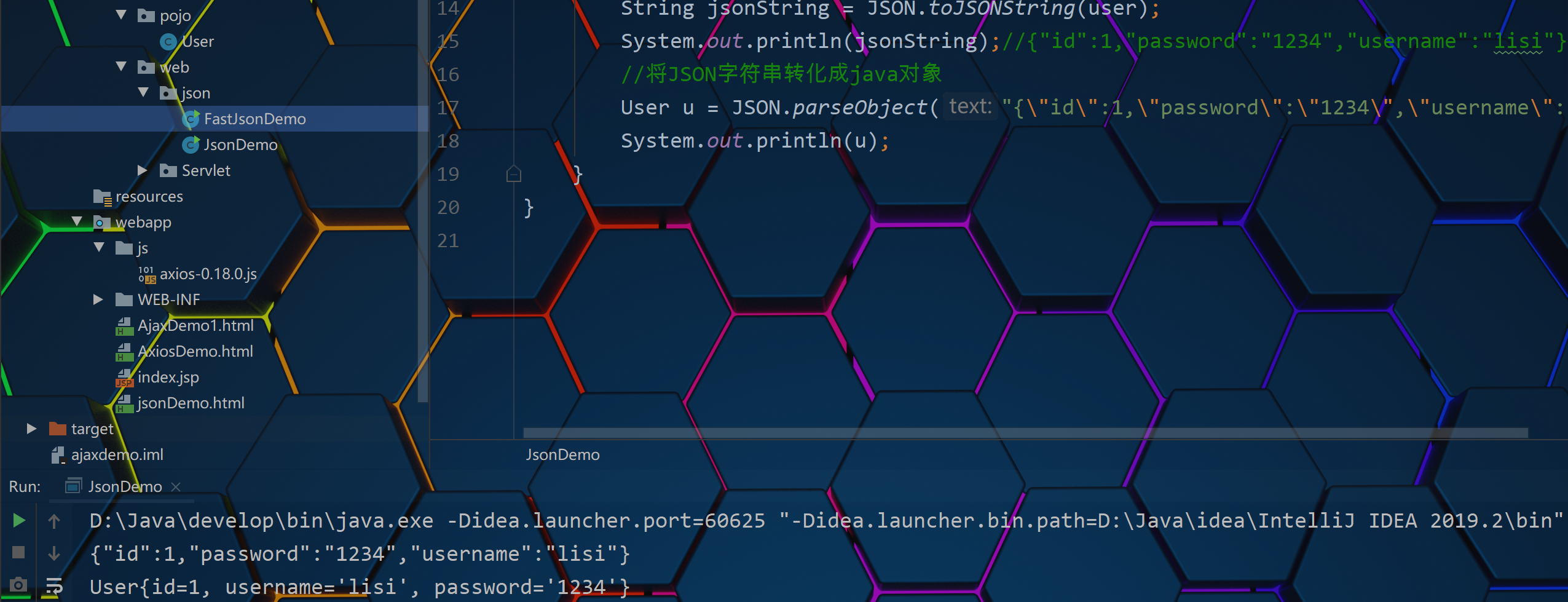
AJAX,Axios,JSON简单了解
一. AJAX简介概念: AJAX(Asynchronous JavaScript And XML): 异步的JavaScript 和XMLAJAX作用:1.与服务器进行数据交换: 通过AJAX可以给服务器发送请求,并获取服务器响应的数据使用了AJAX和服务器进行通信,就可以使用 HTMLAJAX来替换JSP页面了2.异步交互…...

私域流量该如何打造?这套模式直接借鉴
梦龙商业案例分析,带你了解商业背后的秘密 古往今来,消费方与购买方的地位似乎就没有变过,消费者始终是处在被动接受的地位。 但到了现在,其实消费地位早已经不知不觉产生了改变。 就比如以前都是厂家有什么消费者买什么&#…...
【jenkins部署】一文弄懂自动打包部署(前后台)
这里写目录标题序言软件安装jdkmaven配置maven阿里镜像以及本地库位置git安装安装jenkins插件安装环境配置创建项目配置gitee生成gitee WebHookmaven打包验证是否打包成功连接远程服务器并重启服务远程服务器生成私钥配置ssh项目配置ssh脚本vue项目打包nodejs安装下载配置环境变…...

应届生投腾讯,被面试官问了8个和 ThreadLocal 相关的问题。
问:谈一谈ThreadLocal的结构。 ThreadLocal内部维护了一个ThreadLocalMap静态内部类,ThreadLocalMap中又维护了一个Entry静态内部类,和Entry数组。 Entry类继承弱引用类WeakReference,Entry类有一个有参构造函数,参数…...

Linux命令scp用法
本文主要讲的是scp用法如果哪里不对欢迎指出,主页https://blog.csdn.net/qq_57785602?typeblogscp 可以在win系统使用,本文百分之八十写的是win系统怎么使用,在本地上到服务器文件,从服务器下载文件到本地用工具连接到公司服务器时ÿ…...

数据质量怎么监控
目录 一、任务基线级别 二、任务级别 & 表级别 三、字段级别 1. 对指标字段的监控 2. 对维度字段的监控 四、报表级别监控 五、总结 跑了几场面试,数据质量怎么监控是经常被问到的问题,仅次于自我介绍。 因为数据行业发展了几年,数…...
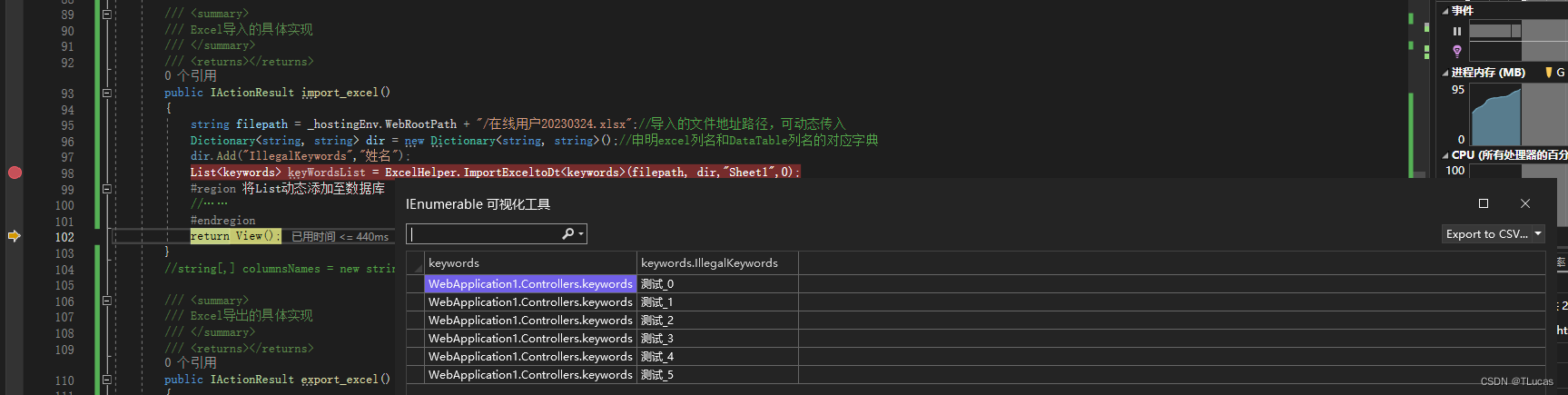
.NET Core 实现Excel的导入导出
.NET Core 使用NPOI实现Excel的导入导出前言NPOI简介一、安装相对应的程序包1.1、在 “管理NuGet程序包” 中的浏览搜索:“NPOI”二、新建Excel帮助类三、调用3.1、增加一个“keywords”模型类,用作导出3.2、添加一个控制器3.3、编写导入导出的控制器代码…...

排好队,一个一个来:宫本武藏教你学队列(附各种队列源码)
文章目录前言:理解“队列”的正确姿势一个关于队列的小思考——请求处理队列的两大“护法”————顺序队列和链式队列数组实现的队列链表实现的队列循环队列关于开篇,你明白了吗?最后说一句前言: 哈喽!欢迎来到黑洞晓…...
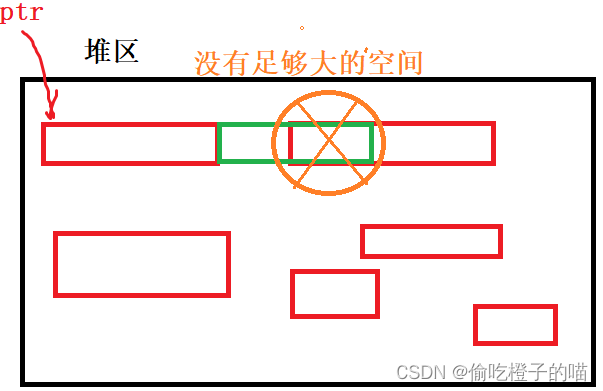
C语言--动态内存管理1
目录前言动态内存函数介绍mallocfreecallocrealloc常见的动态内存错误对NULL指针的解引用操作对动态开辟空间的越界访问对非动态开辟内存使用free释放使用free释放一块动态开辟内存的一部分对同一块动态内存多次释放动态开辟内存忘记释放(内存泄漏)对通讯…...
详解)
后进先出(LIFO)详解
LIFO 是 Last In, First Out 的缩写,中文译为后进先出。这是一种数据结构的工作原则,类似于一摞盘子或一叠书本: 最后放进去的元素最先出来 -想象往筒状容器里放盘子: (1)你放进的最后一个盘子(…...

python打卡day49
知识点回顾: 通道注意力模块复习空间注意力模块CBAM的定义 作业:尝试对今天的模型检查参数数目,并用tensorboard查看训练过程 import torch import torch.nn as nn# 定义通道注意力 class ChannelAttention(nn.Module):def __init__(self,…...

VB.net复制Ntag213卡写入UID
本示例使用的发卡器:https://item.taobao.com/item.htm?ftt&id615391857885 一、读取旧Ntag卡的UID和数据 Private Sub Button15_Click(sender As Object, e As EventArgs) Handles Button15.Click轻松读卡技术支持:网站:Dim i, j As IntegerDim cardidhex, …...

k8s从入门到放弃之Ingress七层负载
k8s从入门到放弃之Ingress七层负载 在Kubernetes(简称K8s)中,Ingress是一个API对象,它允许你定义如何从集群外部访问集群内部的服务。Ingress可以提供负载均衡、SSL终结和基于名称的虚拟主机等功能。通过Ingress,你可…...

基于uniapp+WebSocket实现聊天对话、消息监听、消息推送、聊天室等功能,多端兼容
基于 UniApp + WebSocket实现多端兼容的实时通讯系统,涵盖WebSocket连接建立、消息收发机制、多端兼容性配置、消息实时监听等功能,适配微信小程序、H5、Android、iOS等终端 目录 技术选型分析WebSocket协议优势UniApp跨平台特性WebSocket 基础实现连接管理消息收发连接…...

Swift 协议扩展精进之路:解决 CoreData 托管实体子类的类型不匹配问题(下)
概述 在 Swift 开发语言中,各位秃头小码农们可以充分利用语法本身所带来的便利去劈荆斩棘。我们还可以恣意利用泛型、协议关联类型和协议扩展来进一步简化和优化我们复杂的代码需求。 不过,在涉及到多个子类派生于基类进行多态模拟的场景下,…...

深入解析C++中的extern关键字:跨文件共享变量与函数的终极指南
🚀 C extern 关键字深度解析:跨文件编程的终极指南 📅 更新时间:2025年6月5日 🏷️ 标签:C | extern关键字 | 多文件编程 | 链接与声明 | 现代C 文章目录 前言🔥一、extern 是什么?&…...

多种风格导航菜单 HTML 实现(附源码)
下面我将为您展示 6 种不同风格的导航菜单实现,每种都包含完整 HTML、CSS 和 JavaScript 代码。 1. 简约水平导航栏 <!DOCTYPE html> <html lang"zh-CN"> <head><meta charset"UTF-8"><meta name"viewport&qu…...

Maven 概述、安装、配置、仓库、私服详解
目录 1、Maven 概述 1.1 Maven 的定义 1.2 Maven 解决的问题 1.3 Maven 的核心特性与优势 2、Maven 安装 2.1 下载 Maven 2.2 安装配置 Maven 2.3 测试安装 2.4 修改 Maven 本地仓库的默认路径 3、Maven 配置 3.1 配置本地仓库 3.2 配置 JDK 3.3 IDEA 配置本地 Ma…...

Python基于历史模拟方法实现投资组合风险管理的VaR与ES模型项目实战
说明:这是一个机器学习实战项目(附带数据代码文档),如需数据代码文档可以直接到文章最后关注获取。 1.项目背景 在金融市场日益复杂和波动加剧的背景下,风险管理成为金融机构和个人投资者关注的核心议题之一。VaR&…...