树形结构查找(B树、B+树)
平衡树结构的树高为 O(logn) ,平衡树结构包括两种平衡二叉树结构(分别为 AVL 树和 RBT)以及一种树结构(B-Tree,又称 B 树,它的度大于 2 )。AVL 树和 RBT 适合内部存储的应用,而 B 树适合外部存储的应用。对于 B 树,应掌握其查找、插入以及删除的操作过程,对于 B+ 树(一种 B 树的变形树) ,需了解其基本概念和性质。
一、了解m叉搜索树
1. m叉搜索树的定义
m 叉搜索树(m-way search tree)可以是一棵空树。如果非空,它必须满足以下特征:
1)在相应的扩充搜索树中(即用外部结点替换空指针之后所得到的搜索树),每个内部结点最多可以有 m 个孩子以及 1 ~ m - 1 个元素(外部结点指不含元素和孩子的结点)。
2)每一个含有 p 个元素的结点都有 p + 1 个孩子。
3)对任意一个含有 p 个元素的结点,设 k1 , … , kp 分别是这些元素的关键字。这些元素按顺序排列,即 k1 < k2 < … < kp 。设 c0 , c1 , … , cp 是该结点的 p + 1 个孩子。在以 c0 为根的子树中,元素的关键字小于 k1 ;在以 cp 为根的子树中,元素的关键字大于 kp ;在以 ci 为根的子树中,元素的关键字大于 ki,而小于 ki+1,其中 1 <= i < p。
下图是一棵七叉搜索树,其中黑色方块代表外部结点,其他都是内部结点。
根结点包含 2 个元素(关键字是 10 和 80 ) 以及 3 个孩子,中间的孩子有 6 个元素和 7 个孩子,这 7 个孩子中有 6 个孩子是外部结点。

2. m叉搜索树的搜索
1)在上图的七叉搜索树中,要查找关键字为 31 的元素,先从根结点开始。
2)由于 31 位于 10 和 80 之间,因此沿中间的指针(第二棵子树)往下找。(根据定义,在第一棵子树中所有元素的关键字 < 10,在第三棵子树中所有元素的关键字>80)
3)搜索中间子树的根。因为 31 位于 30 和 40 之间,所以要移动到该结点的第三棵子树中。
4)此时 31 < 32,因此要继续移动到该结点的第一棵子树中。
5)这时的移动搜索到达了外部结点。由此得知,在搜索树中,不包含关键字为 31 的元素。
3. m叉搜索树的插入
1)如果要插入关键字为 31 的元素:
I、先按上述步骤查找该元素,然后在结点 [32, 36] 处查找失败。
II、由于该结点最多可以容纳 6 个元素(根据定义,七叉树搜索树的每个结点最多可以容纳 6 个元素),所以新元素被插入该结点的第一个位置。
2)如果要插入关键字为 65 的元素:
I、先按上述步骤查找该元素,然后在结点 [20, 30, 40, 50, 60, 70] 处查找失败。
II、因为该结点已满,所以必须生成一个新的结点来容纳该元素,而且要成为结点 [20, 30, 40, 50, 60, 70] 的第六个孩子。
4. m叉搜索树的删除
1)如果要删除关键字为 20 的元素:
I、先按上述步骤查找该元素,它位于根结点的中间孩子中,且是中间孩子的第一个元素。
II、因为该元素没有与之相邻的非空子树,所以该元素可以直接从结点中删除。这时的结点变为 [30, 40, 50, 60, 70]。
2)如果要删除关键字为 84 的元素:
I、类似的,首先确定该元素的位置,它是根结点的第三个孩子中的第二个元素。
II、因为该元素没有与之相邻的非空子树,所以该元素可以直接从结点中删除,这时的结点变为 [82, 86, 88]。
3)如果要删除关键字为 5 的元素:
删除关键字为 5 的元素要复杂一点,因为该元素不仅是结点中唯一的一个元素,而且与它相邻的孩子有 1 个是非空的(位于该元素的左侧)。这时需要用左侧相邻的非空子树中关键字最大的元素(即关键字为 4 的元素)来替换被删除的元素。
4)如果要删除关键字为 10 的元素:
要在根结点中删除关键字为 10 的元素, 既可以用左侧相邻的非空子树中关键字最大的元素来替换,也可以用右侧相邻的非空子树中关键字最小的元素来替换。如果用左侧相邻的非空子树中关键字最大的元素进行替换,那么将关键字为 5 的元素移上来之后,还要继续做一次替换,即用关键字为 4 的元素占据原来 5 的位置(即上述情况 3))。
5. m叉搜索树的高
一棵高度为 h 的 m 叉搜索树(不含外部结点) 最少有 h 个元素(每层一个结点,每个结点包含一个元素),最多有 mh - 1 个元素(除根结点外,每层 m 个结点,每个结点包含 m - 1 个元素)。因为在高度为 h 的 m 叉搜索树中,元素个数在 h 到 mh - 1 之间,所以一棵 n 元素的 m 叉搜索树的高度在 logm(n + 1) 到 n 之间。
当搜索树储存在磁盘上时,搜索、插入和删除的时间取决于磁盘的访问次数(假设每一个结点的大小不大于一个磁盘块)。当 h 是树的高度时,这个次数为 O(h),因此,要减少磁盘访问次数,就要确保树的高度接近于 logm(n + 1) ,为此就要利用 m 叉平衡搜索树。
二、平衡搜索树——B树及其基本操作
所谓 m 阶 B 树是所有结点的平衡因子均等于 0 的 m 路平衡查找树。B 树的英文是 B - Tree,因此 B 树也可写成 B - 树,需要注意的是这里的“-”是连接词,而非减号。
1. B树的定义
m 阶 B 树(B - Tree of order m)是一棵 m 叉搜索树。如果 B 树非空,那么相应的扩展树满足下列特征:
1)若根结点不是叶结点,则根结点至少有 2 个孩子。
2)除根结点以外,所有内部结点至少有 ⌈m / 2⌉ 个孩子,,即至少含有 ⌈m / 2⌉ - 1 个关键字。
3)树中每个结点至多有 m 棵子树,即至多含有 m - 1 个关键字。
4)所有外部结点在同一层。
所有非叶结点的结构如下图所示:

介绍 m 叉搜索树时用于举例的那颗七叉搜索树不是一棵七阶 B 树,因为它的外部结点不在同一层,同时它的非根内部结点 [5] 和 [32, 36] 分别有 2 个孩子和 3 个孩子,而七阶的 B 树的非根内部结点应该至少有 ⌈7 / 2⌉ = 4 个孩子。
下图所示的七叉搜索树就是是七阶 B 树,因为它的外部结点均在第 3 层,根结点有 3 个孩子,且其余内部结点至少有 4 个孩子。

2. 二~五阶B树
1)二阶 B 树
在二阶 B 树中,每个内部结点都不会有 2 个以上的孩子,而每个内部结点又至少有 2 个孩子,因此二阶 B 树的所有内部结点都恰好有 2 个孩子。又因为所有外部结点都处于同一层上,所以二阶 B 树是满二叉树。因此,对某个树高为 h 的二阶 B 树,仅当其元素个数为 2h - 1 时,该树才存在。
2)三阶 B 树与四阶 B 树
① 一棵三阶 B 树,因为其内部结点必须有 2 个孩子或 3 个孩子,所以也称 2 - 3 树;
② 一棵四阶 B 树,因为其内部结点必须有 2 个、3 个或 4 个孩子,所以也称 2 - 3 - 4 树(或简称2, 4 树)。
下图是一棵 2 - 3 树。不过,如果把关键字为 14 和 16 的元素加入 20 的左孩子中,这棵树就成为 2 - 3 - 4 树了。

3)五阶 B 树
下图是一颗 5 阶 B 树,对它进行分析:

① 结点的孩子个数等于该结点中关键字个数加 1 。
② 如果根结点没有关键字就没有子树,此时 B 树为空;如果根结点有关键字,则其子树个数必然大于或者等于 2,因为子树个数等于关键字个数加 1 。
③ 除根结点外的所有非叶结点至少有 ⌈m / 2⌉ = ⌈5 / 2⌉ = 3 棵子树(即至少有 ⌈m / 2⌉ - 1 = ⌈5 / 2⌉ - 1 = 2 个关键字);至多有 5 棵子树(即至多有 4 个关键字)。
④ 结点中的关键字从左到右递增有序,关键字两侧均有指向子树的指针,左侧指针所指子树的所有关键字均小于该关键字,右侧指针所指子树的所有关键字均大于该关键字。或者看成下层结点的关键字总是落在由上层结点的关键字所划分的区间内。如第二层最左结点的关键字划分成了 3 个区间:(-∞, 5), (5, 11), (11, +∞) ,该结点中的 3 个指针所指子树的关键字均分别落在这 3 个区间内。
⑤ 所有叶结点均在第 4 层,代表查找失败的位置。
3. B树的高度(磁盘存取次数)
B 树中的大部分操作所需的磁盘存取次数与 B 树的高度成正比。
下面来分析 B 树在不同情况下的高度。当然,首先应该明确 B 树的高度不包括最后的不带任何信息的叶结点所处的那一层。

若 n >= 1,则对任意一棵包含 n 个关键字、高度为 h 、阶数为 m 的 B 树:
1)若让每个结点中的关键字个数达到最多,则容纳同样多关键字的 B 树的高度达到最小。
因为 B 树中每个结点最多有 m 棵子树,m - 1 个关键字,所以在一棵高度为 h 的 m 阶 B 树中关键字的个数应满足 n <= (m - 1) × (1 + m + m2 + … + mh-1) = mh - 1,因此有 h >= logm(n + 1) 。
2)若让每个结点中的关键字个数达到最少,则容纳同样多关键字的 B 树的高度达到最大。
第一层至少有 1 个结点;第二层至少有 2 个结点;除根结点外的每个非叶结点至少有 ⌈m / 2⌉ 棵子树,则第三层至少有 2 × ⌈m / 2⌉ 个结点……第 h + 1 层至少有 2 × (⌈m / 2⌉)h-1 个结点,注意到第 h + 1 层是不包含任何信息的叶结点。对于关键字个数为 n 的 B 树,叶结点即查找不成功的结点为 n + 1 个,由此有 n + 1 >= 2 × (⌈m / 2⌉)h-1 ,即 h <= log⌈m/2⌉((n + 1) / 2) + 1 。
推出:logm(n + 1) <= h <= log⌈m/2⌉((n + 1) / 2) + 1
例如,假设一棵 3 阶 B 树共有 8 个关键字,则其高度范围为 2 <= h <= 3.17,h 取整数。
4. B树的查找
B 树的搜索算法与 m 叉搜索树的搜索算法相同。在搜索过程中,从根至外部结点路径上的所有内部结点都有可能被搜索到,因此,磁盘访问次数最多为 h(其中,h 是 B 树的高度)。
在 B 树上进行查找与二叉查找树很相似,只是每个结点都是多个关键字的有序表,在每个结点上所做的不是两路分支决定,而是根据该结点的子树所做的多路分支决定。
B 树的查找包含 两个基本操作 :1)在B 树中找结点;2)在结点内找关键字。
由于 B 树常存储在磁盘上,因此前一个查找操作是在磁盘上进行的,而后一个查找操作是在内存中进行的,即在找到目标结点后,先将结点信息读入内存,然后在结点内采用顺序查找法或折半查找法。因此,在磁盘上进行查找的次数即目标结点在 B 树上的层次数,决定了 B 树的查找效率。
在 B 树上查找到某个结点后,先在有序表中进行查找,若找到则查找成功,否则按照对应的指针信息到所指的子树中去查找。查找到叶结点时(对应指针为空),则说明树中没有对应的关键字,查找失败。
5. B树的插入
要在 B 树中插入一个新元素,首先要在 B 树中搜索关键字与之相同的元素。如果存在这样的元素,那么插入失败,因为在 B 树的元素中不允许有重复的关键字。如果不存在这样的元素,便可以将元索插入在搜索路径中所遇到的最后一个内部结点中。
与二叉查找树的插入操作相比,B 树的插入操作要复杂得多。在 B 树中查找到插入的位置后,并不能简单地将其添加到终端结点(最底层的非叶结点)中,因为此时可能会导致整棵树不再满足 B 树定义中的要求。将关键字 key 插入 B 树的过程如下:
1)定位
利用上述 B 树的查找算法,找出插入该关键字的最底层中的某个非叶结点。
(在 B 树中查找 key 时, 会找到表示查找失败的叶结点,这样就确定了最底层非叶结点的插入位置。注意:插入位置一定是最底层中的某个非叶结点。)
2)插入
在 B 树中,每个非失败结点的关键字个数都在区间 [⌈m / 2⌉ - 1 , m - 1] 内。若结点插入后的关键字个数小于 m,则可以直接插入;若结点插入后的关键字个数大于等于 m,则必须对结点进行分裂操作。
分裂的方法是:取一个新结点,在插入 key 后的原结点,从中间位置(⌈m / 2⌉)将其中的关键字分为两部分,左部分包含的关键字放在原结点中,右部分包含的关键字放到新结点中,中间位置(⌈m / 2⌉)的结点插入原结点的父结点。若此时导致其父结点的关键字个数也超过了上限,则继续进行这种分裂操作,直至这个过程传到根结点为止,进而导致 B 树高度增 1 。
示例 ①

示例 ②
对于 m = 7 的 B 树,所有结点中最多能有 6 个关键字。若某结点中已存在 6 个关键字,则该结点已满。
a)插入元素 3 得到:
对根结点有 1 次磁盘读操作,对根结点的第一个孩子结点有 1 次磁盘读操作、 1 次磁盘写操作。因此,磁盘访问次数一共是 3 次。

b)进一步插入元素 25 得到:【当在一个饱和结点中插入一个新元素时,需要分裂该结点。】
对根结点有 1 次磁盘读操作,对根结点的中间孩子结点有 1 次磁盘读操作,然后需要将分开的两个结点和修改后的根结点写回磁盘。因此,磁盘访问次数一共是 5 次。

示例 ③
对于 m = 3 的 B 树,所有结点中最多能有 2 个关键字。若某结点中已存在 2 个关键字,则该结点已满。
插入元素 44 得到:
读取结点 [30, 80]、[50, 60] 和 [35, 40] 需要访问 3 次磁盘;有 3 个结点被分裂,所以执行了 6 次磁盘写操作(每次结点分裂之后,要将修改的结点和新结点写回磁盘,因此需要访问两次磁盘);最后产生一个新的根结点并写回磁盘,又需要访问 1 次磁盘。因此,磁盘访问次数一共是 10 次。

当插入操作引起了 s 个结点分裂时,磁盘访问的次数为:
h(读取搜索路径上的结点)+ 2 × s( 回写分裂出的两个新结点)+ 1(回写新的根结点或插入后没有导致分裂的结点)。
因此,所需要的磁盘访问次数是 h + 2 × s + 1 ,最多可达到 3 × h + 1 。
6. B树的删除
删除一个元素分为两种情况:① 该元素位于叶结点, 即该结点的所有孩子都是外部结点;② 该元素位于非叶结点。
B 树中的删除操作与插入操作类似,但要稍微复杂一些,即要使得删除后的结点中的关键字个数 >= ⌈m / 2⌉ - 1,因此将涉及结点的“合并”问题。
当被删关键字 k 不在终端结点(最底层的非叶结点)中时,可以用 k 的前驱(或后继) k’ (即 k 的左侧子树中“最右下”的元素 或 右侧子树中“最左下”的元素)来替代 k,然后在相应的结点中删除 k’,关键字 k’ 必定落在某个终端结点中,则转换成了被删关键字在终端结点中的情形。
示例:在下图的 4 阶 B 树中,删除关键字 80,用其前驱 78 替代,然后在终端结点中删除 78。

因此 只需讨论被删关键字在终端结点 中的情形,有下列三种情况:
1)直接删除关键字
若被删关键字所在结点删除前的关键字个数 >= ⌈m / 2⌉,表明删除该关键字后仍满足 B 树的定义,则直接删去该关键字。
此时,在沿搜索路径从根结点到叶结点的过程中需要 h 次磁盘访问,将修改后的叶结点写回磁盘还需要一次额外的磁盘访问。因此,磁盘访问次数一共是 h + 1 次。
2)兄弟够借
若被删关键字所在结点删除前的关键字个数 = ⌈m / 2⌉ - 1,且与该结点相邻的右(或左)兄弟结点的关键字个数 >= ⌈m / 2⌉,则需要调整该结点、右( 或左)兄弟结点及其双亲结点(父子换位法),以达到新的平衡。
【注意,除了根结点以外,每个结点都会有一个最邻近的左兄弟或一个最邻近的右兄弟,或二者都有。为了降低在最坏情况下的磁盘访问次数,在删除一个元素后的结点缺少一个元素时,我们只考察它的一个最邻近的兄弟。】
示例 ①
在下图的 4 阶 B 树中,删除关键字 65,右兄弟关键字个数 >= ⌈m / 2⌉ = 2,将 71 取代原 65 的位置,将 74 调整到 71 的位置。

示例 ②
对于 m = 7 的 B 树,所有结点中最多能有 6 个关键字,最少要有 3 个关键字。
删除元素 25 得到:6 上去,10 下来。
删除后得到的结点是 [20, 30] ,元素个数为 2 。但七阶 B 树的非根结点至少要有 3 个元素。它最邻近的左兄弟 [2, 3, 4, 6] 可以提供一个额外的元素,因此可把该结点的最大元素移至其父结点,然后把关键字为10 的元素移下来,结果下图所示。
磁盘访问次数为:2(读根结点和 25 所在的叶结点)+ 1(读取该叶结点的最邻近的左兄弟)+ 3(写回修改后的叶结点、左兄弟结点以及父结点)= 6 。

3)兄弟不够借
若被删关键字所在结点删除前的关键字个数 = ⌈m / 2⌉ - 1,且此时与该结点相邻的左、右兄弟结点的关键字个数均 = ⌈m / 2⌉ - 1,则将关键字删除后与左(或右) 兄弟结点及双亲结点中的关键字进行合并(将两个兄弟与父结点中介于两个兄弟之间的元素合并成一个新结点)。
由于被删关键字所在结点与其相邻的左(或右)兄弟结点分别有有 ⌈m / 2⌉ - 2 和 ⌈m / 2⌉ - 1 个元素,因此合并后的结点共有 (⌈m / 2⌉ - 2) + (⌈m / 2⌉ - 1) + 1 = 2 × ⌈m / 2⌉ - 2 个元素。当 m 是奇数时,2 × ⌈m / 2⌉ - 2 = m - 1;而当 m 是偶数时,2 × ⌈m / 2⌉ - 2 = m - 2 。可以得出结点有足够的空间来容纳这么多元素。
示例 ①
在下图的 4 阶 B 树中,删除关键字 5,它及其右兄弟结点的关键字个数 = ⌈m / 2⌉ - 1 = 1,所以在 5 删除后将 60 合并到 65 结点中。

示例 ②
对于 m = 3 的 B 树,所有结点中最多能有 2 个关键字,最少要有 1 个关键字。
删除元素 10 得到:
删除元素 10 后得到的结点不含任何元素。它的最相邻右兄弟 [25] 没有额外的元素,因此,删除元素结点、右兄弟结点 [25] 及父结点 [20] 的元素被合并到一个结点,结果如下图 (I) 所示。
I、树叶层合并:

现在第二层有一个结点缺少一个元素,它的最邻近的右兄弟 [50, 60] 有一个额外的元素。因此,把该兄弟中最左边的元素(关键字为 50 的元素)移到父结点中,并将父结点中关键字为 30 的元素移下来,结果下图 (II) 所示。注意,结点 [50, 60] 的左子树也要移动。
II、第二层合并:

到达被删除元素所在的叶结点需要 3 次读访问,取得第二层和叶结点层的最邻近右兄弟结点需要 2 次读访问,将第一、二和三层的 4 个修改后的结点写回磁盘需要 4 次写访问。因此,总的磁盘访问次数是 3 + 2 + 4 = 9 次。
示例 ③
对于 m = 3 的 B 树,所有结点中最多能有 2 个关键字,最少要有 1 个关键字。
删除元素 44 得到:树的高度减少了一层。
找到被删除元素所在的叶结点需要 4 次磁盘访问,最邻近的兄弟需要 3 次读取磁盘和 3 次写磁盘。因此总的访问磁盘次数是 10 次。

【总结】:
在合并过程中, 双亲结点中的关键字个数会减 1 。
I、若其双亲结点是根结点且关键字个数减少至 0(根结点关键字个数为 1 时,有 2 棵子树),则直接将根结点删除,合并后的新结点成为根,树的高度减 1;
II、若双亲结点不是根结点, 且关键字个数减少到 ⌈m / 2⌉ - 2,则需要选择与双亲结点最邻近的一个兄弟结点,要么从中取一个元素,要么与它合并。
a)如果从最邻近的左(右)兄弟中取一个元素,那么此兄弟结点的最右(最左)子树也将被读取。
b)如果进行合并,那么祖父结点的关键字个数也可能因此减少到 ⌈m / 2⌉ - 2,导致祖父结点也需要重复上述相同的过程。
最坏情况下,这种过程会一直回溯到根结点(需要重复上述步骤,直至符合 B 树的要求为止)。
对高度为 h 的 B 树实施删除操作,最坏情况是:合并操作发生在 h, h-1, … , 3 层进行合并,从最邻近的兄弟中获取一个元素的操作发生在第 2 层。在最坏情况下磁盘访问次数是 3 × h。
【(找到被删除元素所在的结点需要 h 次读访问)+(得到第 2 至 h 层的最邻近兄弟需要 h - 1 次读访问)+(第 3 至 n 层的合并需要 h - 2 次写访问)+(对修改过的根结点和第 2 层的 2个结点进行 3 次写访问)】
7. 有关B树的历年统考真题
① 【2009 统考真题】下列叙述中,不符合 m 阶 B 树定义要求的是( A)。
A. 根结点至多有 m 棵子树
B. 所有叶结点都在同一层上
C. 各结点内关键宇均升序或降序排列
D. 叶结点之间通过指针链接
② 【2012 统考真题】已知一棵 3 阶 B 树,如下图所示。删除关键字 78 得到一棵新 B 树,其最右叶结点中的关键字是( D )。

A. 60
B. 60, 62
C. 62, 65
D. 65
③ 【2013 统考真题】在一棵高度为 2 的 5 阶 B 树中,所含关键字的个数至少是( A )。
A. 5
B. 7
C. 8
D. 14
④ 【2014 统考真题】在一棵有 15 个关键字的 4 阶 B 树中,含关键字的结点个数最多是( D )。
A. 5
B. 6
C. 10
D. 15
⑤ 【2018 统考真题】高度为 5 的 3 阶 B 树含有的关键字个数至少是( B )。
A. 15
B. 31
C. 62
D. 242
⑥【2020 统考真题】依次将关键字 5, 6, 9, 13, 8, 2, 12, 15 插入初始为空的 4 阶 B 树后,根结点中包含的关键字是( B )。
A. 8
B. 6, 9
C. 8, 13
D. 9, 12
⑦ 【2021 统考真题】在一棵高度为 3 的 3 阶 B 树中,根为第 1 层,若第 2 层中有 4 个关键字,则该树的结点数最多是( A )。
A. 11
B. 10
C. 9
D. 8
⑧ 【2022 统考真题】在下图所示的 5 阶 B 树 T 中,删除关键字 260 之后需要进行必要的调整,得到新的 B 树 T1 。下列选项中,不可能是 T1 根结点中关键字序列的是( D )。

A. 60, 90, 280
B. 60, 90, 350
C. 60, 85, 110, 350
D. 60, 90, 110, 350
⑨ 【2023 统考真题】下列关于非空 B 树的叙述中,正确的是( B )。
I、插入操作可能增加树的高度
II、删除操作一定会导致叶结点的变化
III、查找某关键字总是要查找到叶结点
IV、插入的新关键字最终位于叶结点中
A. 仅 I
B. 仅 I、II
C. 仅 III、IV
D. 仅 I、II、IV
三、B树的变形——B+树的基本概念
1. B+树的定义
B+ 树是应数据库所需而出现的一种 B 树的变形树。一棵 m 阶的 B+ 树需满足下列条件:
1)每个分支结点最多有 m 棵子树(孩子结点)。
2)非叶根结点至少有 2 棵子树,其他每个分支结点至少有 ⌈m / 2⌉ 棵子树。
3)结点的子树个数与关键字个数相等。
4)所有叶结点包含全部关键字及指向相应记录的指针,叶结点中将关键字按大小顺序排列,并且相邻叶结点按大小顺序相互链接起来(支持顺序查找)。
5)所有分支结点(可视为索引的索引)中仅包含它的各个子结点(即下一级的索引块)中关键字的最大值及指向其子结点的指针。
2. m阶B+树与m阶B树的差异
m 阶的 B+ 树与 m 阶的 B 树的主要差异如下:
1)在 B+ 树中,具有 n 个关键字的结点只含有 n 棵子树,即每个关键字对应一棵子树;而在 B 树中,具有 n 个关键字的结点含有 n + 1 棵子树。
2)在 B+ 树中,每个结点( 非根内部结点)的关键字个数 n 的范围是 ⌈m / 2⌉ <= n <= m(非叶根结点:2 <= n <= m);而在 B 树中,每个结点(非根内部结点)的关键字个数 n 的范围是 ⌈m / 2⌉ - 1 <= n <= m - 1(根结点:1 <= n <= m - 1)。
3)在 B+ 树中,叶结点包含了全部关键字,非叶结点中出现的关键字也会出现在叶结点中;而在 B 树中,最外层的终端结点包含的关键字和其他结点包含的关键字是不重复的。
4)在 B+ 树中,叶结点包含信息,所有非叶结点仅起索引作用,非叶结点中的每个索引项只含有对应子树的最大关键字和指向该子树的指针,不含有该关键字对应记录的存储地址。这样能使一个磁盘块存储更多的关键字,使得磁盘读 / 写次数更少,查找速度更快。
5)在 B+ 树中,用一个指针指向关键字最小的叶结点,将所有叶结点串成一个线性链表。
下图所示为一棵 4 阶 B+ 树。可以看出,分支结点的某个关键字是其子树中最大关键字的副本。通常在 B+ 树中有两个头指针:一个指向根结点,另一个指向关键字最小的叶结点。因此,可以对 B+ 树进行两种查找运算: 一种是从最小关键字开始的顺序查找,另一种是从根结点开始的多路查找。

B+ 树的查找、插入和删除操作和 B 树的基本类似。只是在查找过程中,非叶结点上的关键字值等于给定值时并不终止,而是继续向下查找,直到叶结点上的该关键字为止。所以,在 B+ 树中查找时,无论查找成功与否,每次查找都是一条从根结点到叶结点的路径。
3. 有关B+树的历年统考真题
① 【2016 统考真题】B+树不同于 B 树的特点之一是( A )。
A. 能支持顺序查找
B. 结点中含有关键字
C. 根结点至少有两个分支
D. 所有叶结点都在同一层上
② (2017 统考真题】下列应用中,适合使用 B+树的是( B )。
A. 编译器中的词法分析
B. 关系数据库系统中的索引
C. 网络中的路由表快速查找
D. 操作系统的磁盘空闲块管理
相关文章:
树形结构查找(B树、B+树)
平衡树结构的树高为 O(logn) ,平衡树结构包括两种平衡二叉树结构(分别为 AVL 树和 RBT)以及一种树结构(B-Tree,又称 B 树,它的度大于 2 )。AVL 树和 RBT 适合内部存储的应用,而 B 树…...

网络通信(TCP/UDP协议 三次握手四次挥手 )
三、TCP协议与UDP协议 1、TCP/IP、TCP、 UDP是什么 TCP/IP协议是一个协议簇,里面包括很多协议的, UDP只是其中的一个, 之所以命名为TCP/IP协议, 因为TCP、 IP协议是两个很重要的协议,就用他两命名了,而TCP…...

C# ADO.Net 通用按月建表插入数据
原理是获取原表表结构以及索引动态拼接建表SQL,如果月表存在则不创建,不存在则创建表结构 代码如下 /// <summary>/// 根据指定的表名和时间按月进行建表插入(如果不存在对应的月表)/// </summary>/// <param nam…...

19-ESP32-C3加大固件储存区
1默认编译情况。 2、改flash4M。ESP-IDF Partition Table Editor修改。 3、设置输入Partition Table 改自定义.CSV。保存。 4、查看命令输入Partition Table Editor打开-分区表编辑器UI。按图片增加。 nvs,data,nvs,0x9000,0x6000,, phy_init,data,phy,0xF000,0x1000,, factory…...

【STL】stack/queue 容器适配器 deque
1.stack的介绍和使用 1.1.stack的介绍 1. stack是一种容器适配器,专门用在具有后进先出操作的上下文环境中,其删除只能从容器的一端进行元素的插入与提取操作。 2. stack是作为容器适配器被实现的,容器适配器即是对特定类封装作为其底层的容…...

(回溯) LeetCode 17. 电话号码的组合
原题链接 一. 题目描述 17. 电话号码的字母组合 已解答 中等 相关标签 相关企业 给定一个仅包含数字 2-9 的字符串,返回所有它能表示的字母组合。答案可以按 任意顺序 返回。 给出数字到字母的映射如下(与电话按键相同)。注意 1 不对…...

Ghidra:开源软件逆向工程框架
Ghidra 是一个软件逆向工程 (SRE) 框架 Ghidra 是一种尖端的开源软件逆向工程 (SRE) 框架,是美国国家安全局 (NSA) 研究局的产品。 Ghidra 该框架具有高端软件分析工具,使用户能够分析跨各种平台(包括 Windows、macOS 和 Linux)…...
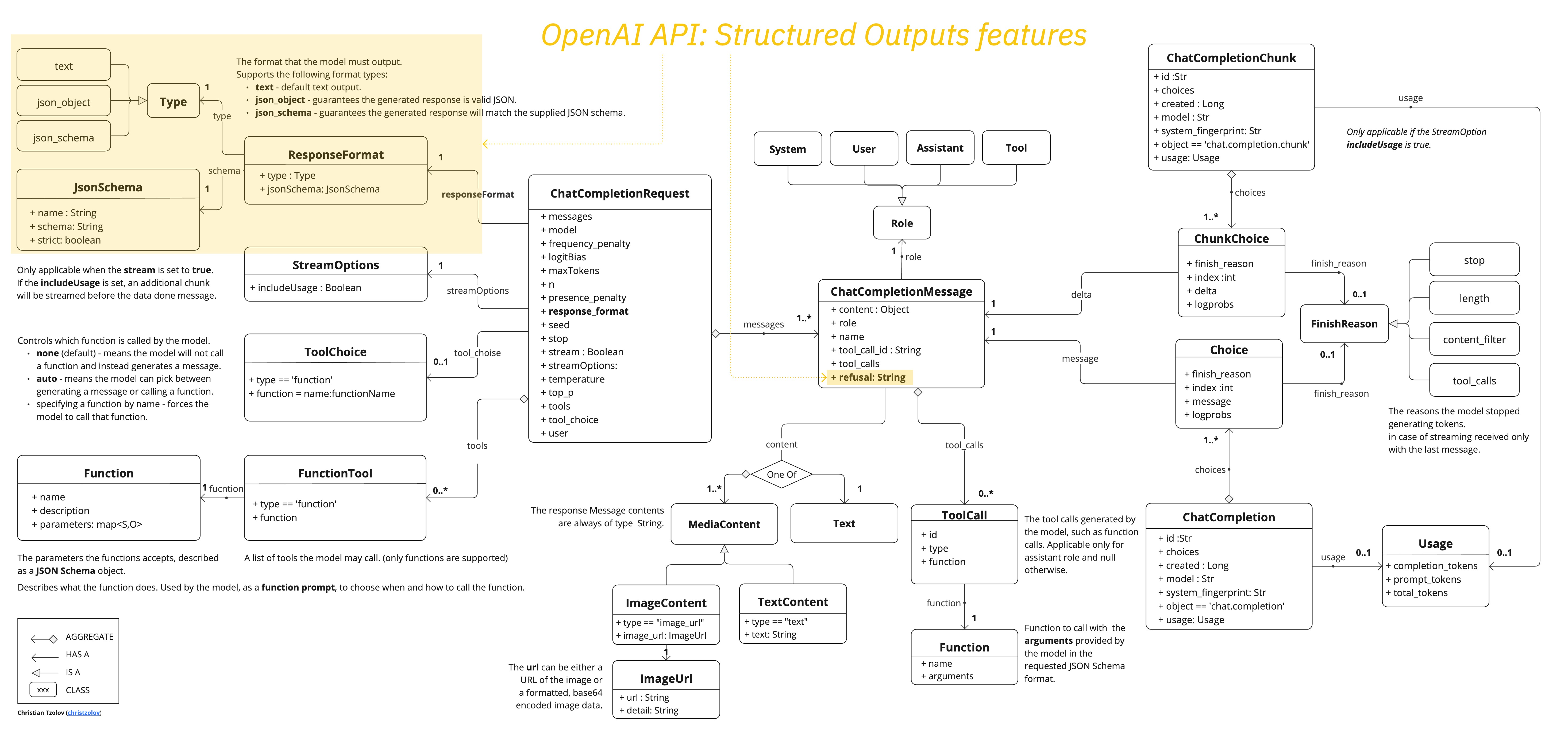
Spring AI 更新:支持OpenAI的结构化输出,增强对JSON响应的支持
就在昨晚,Spring AI发了个比较重要的更新。由于最近OpenAI推出了结构化输出的功能,可确保 AI 生成的响应严格遵守预定义的 JSON 模式。此功能显着提高了人工智能生成内容在现实应用中的可靠性和可用性。Spring AI 紧随其后,现在也可以对OpenA…...

java.util.ConcurrentModificationException 并发修改异常
目录 异常代码片段 详细说明 解决方案 使用迭代器进行遍历 使用临时集合存储结果 异常代码片段 if (ObjectUtil.isNotEmpty(candidateUsers)) {candidateUsers candidateUsers.stream().filter(Objects::nonNull).distinct().collect(Collectors.toList());for (String …...
)
Flask数据库操作(第四阶段)
目录 Flask数据库操作一、数据库基础1.1 关系型数据库与非关系型数据库选择数据库 二、Flask-SQLAlchemy2.1 安装 Flask-SQLAlchemy2.2 创建数据库模型2.2.1 创建 Flask 应用2.2.2 定义模型 2.3 执行 CRUD 操作2.3.1 创建(Create)2.3.2 读取(…...

C语言问答进阶--5、基本表达式和基本语句
赋值表达式 表达式是什么?表达式是由运算符和操作数组成的式子。 如下的代码 #include "iostream.h" int main() { int a1,b2,sum; cout<<(sumab)<<endl; return 0; } 那么如下的呢? #include "iostream.h" int mai…...

uniapp3.0实现图片上传公用组件上传uni-file-picker,uni.uploadFile
用uniapp3.0的写法组合式api,setup形式封装一个图片上传公用组件,要求 1、使用uni-file-picker选择文件 2、uni.uploadFile上传图片 3、要能支持上传接口动态化 4、支持删除如片列表中已上传项 5、可以预览已上传列表图片 6、支持动态化限制图片格…...

Unity游戏开发002
Unity游戏开发002 目录 第一章:Hello,Unity!第二章:创建一个游戏体 本文目录 Unity游戏开发 Unity游戏开发002目录本文目录前言一、创建一个游戏体1. 编辑器语言设置2. 创建游戏对象的两种方法3. 快速复制和粘贴物体4. 注意事项…...

MySQL基础练习题38-每位教师所教授的科目种类的数量
目录 题目 准备数据 分析数据 总结 题目 查询每位老师在大学里教授的科目种类的数量。 准备数据 ## 创建库 create database db; use db;## 创建表 Create table If Not Exists Teacher (teacher_id int, subject_id int, dept_id int)## 向表中插入数据 Truncate table…...

haproxy 原理+实战
haproxy 1 haproxy简介1.1 定义1.2 原理讲解1.3 HAProxy的优点: 2. haproxy的基本部署2.1 实验环境2.1.2 haproxy主机配置2.1.3 webserver1配置2.1.4 webserver2配置 3. haproxy的全局配置4. haproxy代理参数5. haporxy的热处理6.haproxy的算法6.1 静态算法6.1.1sta…...

OSPF进阶
一、LSA详解 Type:LSA的类型(1、2、3、4、5、7类) link-state-ID:链路状态表示符 ADV router:产生该LSA的路由器 age:老化时间 Metric:开销值,一般都为ADV router到达该路由的开…...
SuccBI+低代码文档中心 — 可视化分析(仪表板)(下)
制作仪表板 引入数据模型 仪表板所需模型已经在数据模块中准备好,可以将对应模型表添加到数据模型中。提供了两种添加方式: 在数据栏中点击添加按钮,在弹出框中通过搜索或直接在其所在目录下选中该模型,点击确定。 点击数据按钮…...

前端创作纪念日
机缘 作者也是一名新人大学生,在学习过程中总是get不到专业的知识体系,机缘巧合下了解通过md文档记笔记然后分享在各大博客平台上面,可以吸引社区博客朋友们的关注的鼓励,使得直接创作努力学习的心更加澎湃。 实战项目中的经验分…...

丰收季遇科技之光:北斗卫星导航引领现代农业新篇章
在这个金风送爽、硕果累累的丰收时节,广袤的田野上洋溢着农民们欢声笑语,每一粒饱满的果实都是大自然与辛勤耕耘者的共同馈赠。而在这片希望的田野上,一项科技革命的浪潮正悄然改变着传统农业的面貌——北斗卫星导航系统,正以它精…...
解决windows7虚拟机安装不了vmtools问题
安装不了vmtools问题所在: 没打补丁 打补丁问题 补丁在本地下载之后无法传到win7虚拟机中 补丁获取 补丁链接如下: https://catalog.s.download.windowsupdate.com/c/msdownload/update/software/secu/2019/09/windows6.1-kb4474419-v3-x64_b5614c6…...

网络六边形受到攻击
大家读完觉得有帮助记得关注和点赞!!! 抽象 现代智能交通系统 (ITS) 的一个关键要求是能够以安全、可靠和匿名的方式从互联车辆和移动设备收集地理参考数据。Nexagon 协议建立在 IETF 定位器/ID 分离协议 (…...

家政维修平台实战20:权限设计
目录 1 获取工人信息2 搭建工人入口3 权限判断总结 目前我们已经搭建好了基础的用户体系,主要是分成几个表,用户表我们是记录用户的基础信息,包括手机、昵称、头像。而工人和员工各有各的表。那么就有一个问题,不同的角色…...

高危文件识别的常用算法:原理、应用与企业场景
高危文件识别的常用算法:原理、应用与企业场景 高危文件识别旨在检测可能导致安全威胁的文件,如包含恶意代码、敏感数据或欺诈内容的文档,在企业协同办公环境中(如Teams、Google Workspace)尤为重要。结合大模型技术&…...

pikachu靶场通关笔记22-1 SQL注入05-1-insert注入(报错法)
目录 一、SQL注入 二、insert注入 三、报错型注入 四、updatexml函数 五、源码审计 六、insert渗透实战 1、渗透准备 2、获取数据库名database 3、获取表名table 4、获取列名column 5、获取字段 本系列为通过《pikachu靶场通关笔记》的SQL注入关卡(共10关࿰…...
-HIve数据分析)
大数据学习(132)-HIve数据分析
🍋🍋大数据学习🍋🍋 🔥系列专栏: 👑哲学语录: 用力所能及,改变世界。 💖如果觉得博主的文章还不错的话,请点赞👍收藏⭐️留言Ǵ…...

SiFli 52把Imagie图片,Font字体资源放在指定位置,编译成指定img.bin和font.bin的问题
分区配置 (ptab.json) img 属性介绍: img 属性指定分区存放的 image 名称,指定的 image 名称必须是当前工程生成的 binary 。 如果 binary 有多个文件,则以 proj_name:binary_name 格式指定文件名, proj_name 为工程 名&…...

uniapp 开发ios, xcode 提交app store connect 和 testflight内测
uniapp 中配置 配置manifest 文档:manifest.json 应用配置 | uni-app官网 hbuilderx中本地打包 下载IOS最新SDK 开发环境 | uni小程序SDK hbulderx 版本号:4.66 对应的sdk版本 4.66 两者必须一致 本地打包的资源导入到SDK 导入资源 | uni小程序SDK …...

MySQL:分区的基本使用
目录 一、什么是分区二、有什么作用三、分类四、创建分区五、删除分区 一、什么是分区 MySQL 分区(Partitioning)是一种将单张表的数据逻辑上拆分成多个物理部分的技术。这些物理部分(分区)可以独立存储、管理和优化,…...

手机平板能效生态设计指令EU 2023/1670标准解读
手机平板能效生态设计指令EU 2023/1670标准解读 以下是针对欧盟《手机和平板电脑生态设计法规》(EU) 2023/1670 的核心解读,综合法规核心要求、最新修正及企业合规要点: 一、法规背景与目标 生效与强制时间 发布于2023年8月31日(OJ公报&…...

comfyui 工作流中 图生视频 如何增加视频的长度到5秒
comfyUI 工作流怎么可以生成更长的视频。除了硬件显存要求之外还有别的方法吗? 在ComfyUI中实现图生视频并延长到5秒,需要结合多个扩展和技巧。以下是完整解决方案: 核心工作流配置(24fps下5秒120帧) #mermaid-svg-yP…...