Linux内核IO基础知识与概念
什么是 IO
在计算机操作系统中,所谓的I/O就是 输入(Input)和输出(Output),也可以理解为读(Read)和写(Write),针对不同的对象,I/O模式可以划分为磁盘IO模型和网络IO模型。
IO操作会涉及到用户空间和内核空间的转换,先来理解以下规则:
内存空间分为用户空间和内核空间,也称为用户缓冲区和内核缓冲区;
用户的应用程序不能直接操作内核空间,需要将数据从内核空间拷贝到用户空间才能使用;
无论是read操作,还是write操作,都只能在内核空间里执行;
磁盘IO和网络IO请求加载到内存的数据都是先放在内核空间的;
再来看看所谓的读(Read)和写(Write)操作:
读操作:操作系统检查内核缓冲区有没有需要的数据,如果内核缓冲区已经有需要的数据了,那么就直接把内核空间的数据copy到用户空间,供用户的应用程序使用。如果内核缓冲区没有需要的数据,对于磁盘IO,直接从磁盘中读取到内核缓冲区(这个过程可以不需要cpu参与)。而对于网络IO,应用程序需要等待客户端发送数据,如果客户端还没有发送数据,对应的应用程序将会被阻塞,直到客户端发送了数据,该应用程序才会被唤醒,从Socket协议找中读取客户端发送的数据到内核空间,然后把内核空间的数据copy到用户空间,供应用程序使用。
写操作:用户的应用程序将数据从用户空间copy到内核空间的缓冲区中(如果用户空间没有相应的数据,则需要从磁盘—>内核缓冲区—>用户缓冲区依次读取),这时对用户程序来说写操作就已经完成,至于什么时候再写到磁盘或通过网络发送出去,由操作系统决定。除非应用程序显示地调用了sync 命令,立即把数据写入磁盘,或执行flush()方法,通过网络把数据发送出去。
绝大多数磁盘IO和网络IO的读写操作都是上述过程,除了后面要讲到的零拷贝IO。
用户空间&内核空间
野生程序员对于这个概念可能比较陌生,这其实是 Linux 操作系统中的概念。虚拟内存(操作系统中的概念,和物理内存是对应的)被操作系统划分成两块:User Space(用户空间 和 Kernel Space(内核空间),本质上电脑的物理内存是不划分这些的,只是操作系统开机启动后在逻辑上虚拟划分了地址和空间范围。
操作系统会给每个进程分配一个独立的、连续的虚拟内存地址空间(物理上可能不连续),以32位操作系统为例,该大小一般是4G,即232 。其中将高地址值的内存空间分配给系统内核占用(网上查资料得知:Linux下占1G,Windows下占2G),其余的内存地址空间分配给用户进程使用。
因为我们不是要深入学习操作系统,所以这里以32位系统举例旨在帮助你理解原理。32 位的 LInux 操作系统下,0~3G为用户空间,3~4G为内核空间:
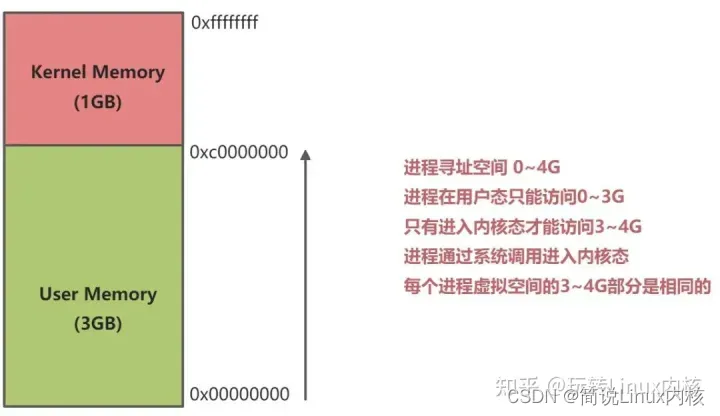
那为什么要这样划分出空间范围呢?
也很好理解,毕竟操作系统身份高贵,太重要了,不能和用户应用程序在一起玩耍,各自的数据都要分开存储并且严格控制权限不能越界。这样才能保证操作系统的稳定运行,用户应用程序太不可控了,不同公司或者个人都可以开发,碰到坑爹的误操作或者恶意破坏系统数据直接宕机玩完了。隔离后应用程序要挂你就挂,操作系统可以正常运行。
简单说,内核空间 是操作系统 内核代码运行的地方,用户空间 是 用户程序代码运行的地方。当应用进程执行系统调用陷入内核代码中执行时就处于内核态,当应用进程在运行用户代码时就处于用户态。
同时内核空间可以执行任意的命令,而用户空间只能执行简单的运算,不能直接调用系统资源和数据。必须通过操作系统提供接口,向系统内核发送指令。
一旦调用系统接口,应用进程就从用户空间切换到内核空间了,因为开始运行内核代码了。
简单看几行代码,分析下是应用程序在用户空间和内核空间之间的切换过程:
str = "i am qige" // 用户空间
x = x + 2
file.write(str) // 切换到内核空间
y = x + 4 // 切换回用户空间上面代码中,第一行和第二行都是简单的赋值运算,在用户空间执行。第三行需要写入文件,就要切换到内核空间,因为用户不能直接写文件,必须通过内核安排。第四行又是赋值运算,就切换回用户空间。
用户态切换到内核态的3种方式:
资料直通车:最新Linux内核源码资料文档+视频资料
内核学习地址:Linux内核源码/内存调优/文件系统/进程管理/设备驱动/网络协议栈
系统调用。也称为 System Call,是说用户态进程主动要求切换到内核态的一种方式,用户态进程使用操作系统提供的服务程序完成工作,比如上面示例代码中的写文件调用,还有像 fork() 函数实际上就是执行了一个创建新进程的系统调用。而系统调用的机制其核心还是使用了操作系统为用户特别开放的一个中断来实现。
异常。当CPU在用户空间执行程序代码时发生了不可预期的异常,这时会触发由当前运行进程切换到处理此异常的内核相关程序中,切换到内核态,比如缺页异常。
外围设备的中断。 当外围设备完成用户请求的某些操作后,会向CPU发送相应的中断信号,这时CPU会暂停执行下一条即将执行的指令转而去执行与中断信号对应的处理程序,如果当前正在运行用户态下的程序指令,自然就发了由用户态到内核态的切换。比如硬盘数据读写完成,系统会切换到中断处理程序中执行后续操作等。
以上3种方式,除了系统调用是进程主动发起切换,异常和外围设备中断是被动切换的。
查看 CPU 时间在 User Space 与 Kernel Space 之间的分配情况,可以使用top命令。它的第三行输出就是 CPU 时间分配统计。

我们来看看图中圈出来的 CPU 使用率的三个指标:
其中,第一项 7.57% user 就是 CPU 消耗在 User Space 的时间百分比,第二项 7.0% sys是消耗在 Kernel Space 的时间百分比。第三项 85.4% idle 是 CPU 消耗在闲置进程的时间百分比,这个值越低,表示 CPU 越忙。
PIO&DMA
大家都知道一般我们的数据是存储在磁盘上的,应用程序想要读写这些数据肯定就需要加载到内存中。接下来给大家介绍下 PIO 和 DMA 这两种 IO 设备和内存之间的数据传输方式。
PIO 工作原理
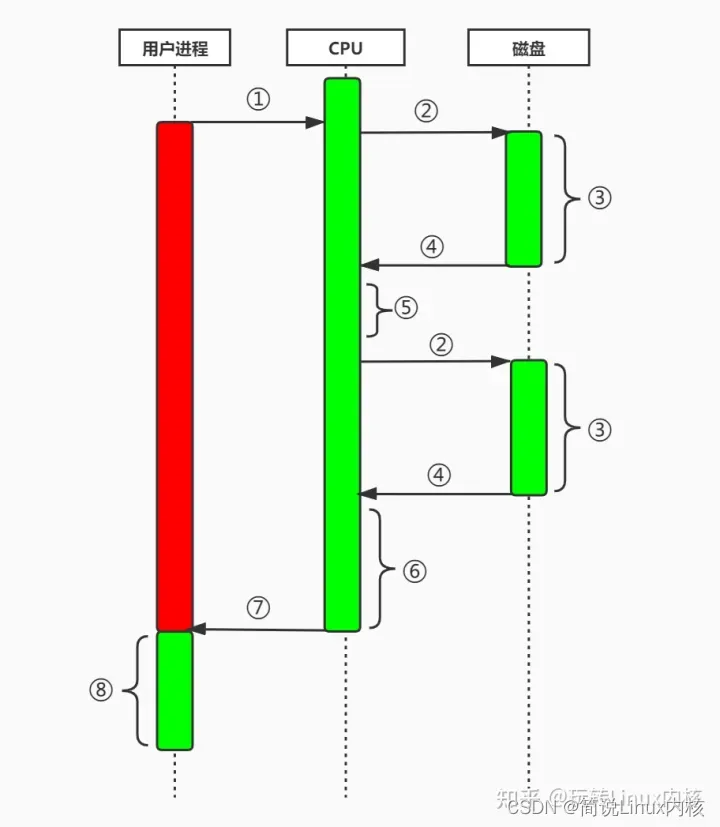
用户进程通过read等系统调用接口向操作系统(即CPU)发出IO请求,请求读取数据到自己的用户内存缓冲区中,然后该进程进入阻塞状态。
操作系统收到用户进程的请求后,进一步将IO请求发送给磁盘。
磁盘驱动器收到内核的IO请求后,把数据读取到自己的缓冲区中,此时不占用CPU。当磁盘的缓冲区被读满之后,向内核发起中断信号告知自己缓冲区已满。
内核收到磁盘发来的中断信号,使用CPU将磁盘缓冲区中的数据copy到内核缓冲区中。
如果内核缓冲区的数据少于用户申请读的数据,则重复步骤2、3、4,直到内核缓冲区的数据符合用户的要求为止。
内核缓冲区的数据已经符合用户的要求,CPU停止向磁盘IO请求。
CPU将数据从内核缓冲区拷贝到用户缓冲区,同时从系统调用中返回。
用户进程读取到数据后继续执行原来的任务。
PIO缺点:每次IO请求都需要CPU多次参与,效率很低。
DMA 工作原理
DMA(直接内存访问,Direct Memory Access)。
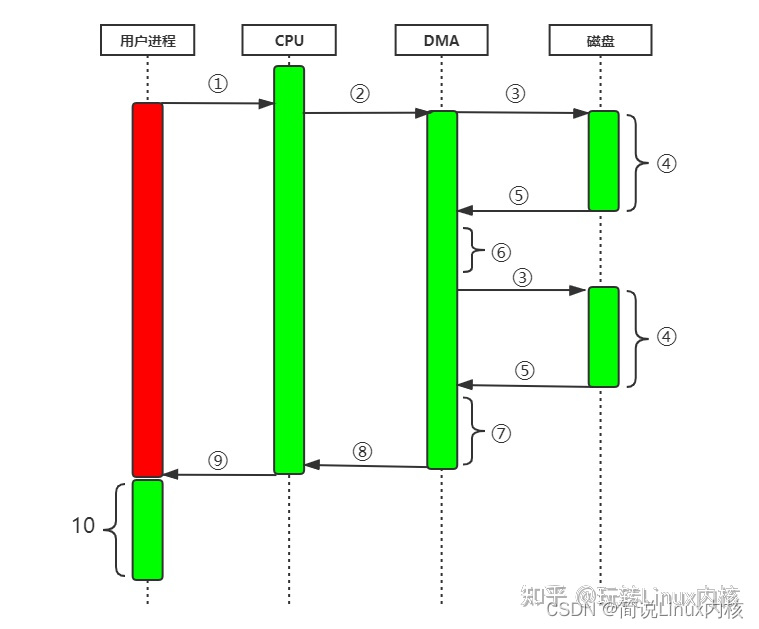
用户进程通过read等系统调用接口向操作系统(即CPU)发出IO请求,请求读取数据到自己的用户内存缓冲区中,然后该进程进入阻塞状态。
操作系统收到用户进程的请求后,进一步将IO请求发送给DMA,然后CPU就可以去干别的事了。
DMA将IO请求转发给磁盘。
磁盘驱动器收到内核的IO请求后,把数据读取到自己的缓冲区中,当磁盘的缓冲区被读满后,向DMA发起中断信号告知自己缓冲区已满。
DMA收到磁盘驱动器的信号,将磁盘缓冲区中的数据copy到内核缓冲区中,此时不占用CPU( PIO 这里是占用CPU的)。
如果内核缓冲区的数据少于用户申请读的数据,则重复步骤3、4、5,直到内核缓冲区的数据符合用户的要求为止。
内核缓冲区的数据已经符合用户的要求,DMA停止向磁盘发IO请求。
DMA发送中断信号给CPU。
CPU收到DMA的信号,知道数据已经准备好,于是将数据从内核空间copy到用户空间,系统调用返回。
用户进程读取到数据后继续执行原来的任务。
跟PIO模式相比,DMA就是CPU的一个代理,它负责了一部分的拷贝工作,从而减轻了CPU的负担。
需要注意的是,DMA承担的工作是从磁盘的缓冲区到内核缓冲区或网卡设备到内核的 soket buffer的拷贝工作,以及内核缓冲区到磁盘缓冲区或内核的 soket buffer 到网卡设备的拷贝工作,而内核缓冲区到用户缓冲区之间的拷贝工作仍然由CPU负责。
可以肯定的是,PIO模式的计算机我们现在已经很少见到了。
缓冲IO和直接IO
学习用户空间和内核空间的时候我们也说了,用户空间是不能直接访问内核空间的数据的,如果需要访问怎么办?很简单,就需要将数据从内核空间拷贝的用户空间。
缓冲 IO:其实就是磁盘中的数据通过 DMA 先拷贝到内核空间,然后再从内核空间拷贝到用户空间。
直接 IO:磁盘中的数据直接通过 DMA 拷贝到用户空间。
缓冲 IO
缓冲 IO 也被成为标准 IO,大多数的文件系统系统默认都是以缓冲 IO 的方式来工作的。在Linux的缓冲I/O机制中,数据先从磁盘复制到内核空间的缓冲区,然后从内核空间缓冲区复制到应用程序的地址空间。
接下来我们看看缓冲 IO 下读写操作是如何进行?
读操作:
操作系统检查内核的缓冲区有没有需要的数据,如果已经缓冲了,那么就直接从缓冲中返回;否则从磁盘中读取到内核缓冲中,然后再复制到用户空间缓冲中。
写操作:
将数据从用户空间复制到内核空间的缓冲中。这时对用户程序来说写操作就已经完成,至于什么时候再写到磁盘中由操作系统决定,除非显示地调用了sync同步命令。
缓冲I/O的优点:
在一定程度上分离了内核空间和用户空间,保护系统本身的运行安全;
因为内核中有缓冲,可以减少读盘的次数,从而提高性能。
缓冲I/O的缺点:
在缓冲 I/O 机制中,DMA 方式可以将数据直接从磁盘读到内核空间页缓冲中,或者将数据从内核空间页缓冲直接写回到磁盘上,而不能直接在用户地址空间和磁盘之间进行数据传输,这样数据在传输过程中需要在应用程序地址空间(用户空间)和内核缓冲(内核空间)之间进行多次数据拷贝操作,这些数据拷贝操作所带来的CPU以及内存开销是非常大的。
直接IO
顾名思义,直接IO就是应用程序直接访问磁盘数据,而不经过内核缓冲区,也就是绕过内核缓冲区,自己管理I/O缓冲区,这样做的目的是减少一次从内核缓冲区到用户程序缓冲的数据复制。
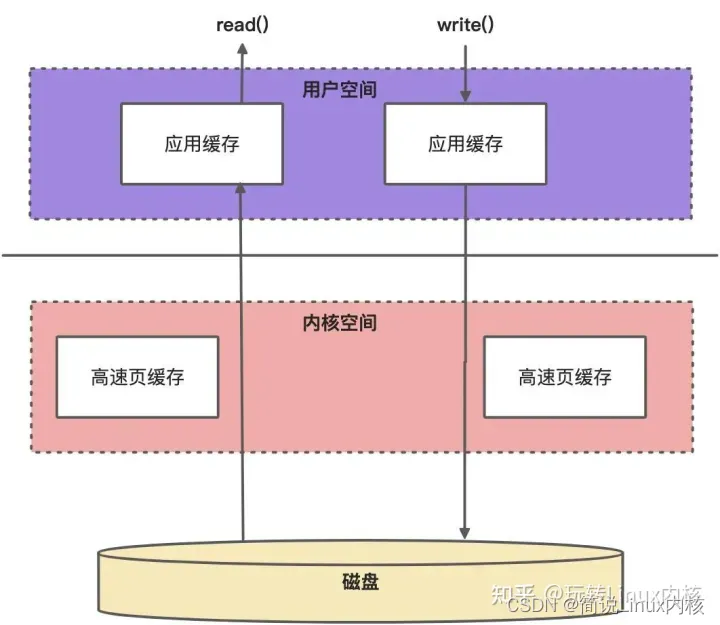
引入内核缓冲区这个主要是为了提升从磁盘读写数据文件的性能,这也是很多系统优化中常见的手段,多一层缓存可以有效减少很多磁盘 IO 操作;而当用户程序需要向磁盘文件中写入数据时,实际上只需要写入到内核缓冲区便可以返回了,而真正的落盘是有一定的延迟策略的,但这无疑提升了应用程序写入文件的响应速度。
在数据库管理系统这类应用中,它们更倾向于选择自己实现的缓存机制,因为数据库管理系统往往比操作系统更了解数据库中存放的数据,数据库管理系统可以提供一种更加有效的缓存机制来提高数据库中数据的存取性能。
直接I/O的优点:
应用程序直接访问磁盘数据,不经过操作系统内核数据缓冲区,这样做的最直观目的是减少一次从内核缓冲区到用户程序缓冲的数据复制。这种方式通常用在数据库、消息中间件中,由应用程序来实现数据的缓存管理。
直接I/O的缺点:
如果访问的数据不在应用程序缓冲中,那么每次数据都会直接从磁盘进行加载,这种直接加载会非常缓慢。通常 直接I/O 跟 异步I/O 结合使用会得到较好的性能。(异步IO:当访问数据的线程发出请求之后,线程会接着去处理其他事,而不是阻塞等待)
IO 访问方式
我们常说的 IO 操作,不仅仅是磁盘 IO,还有常见的网络数据传输即网络 IO。
磁盘 IO
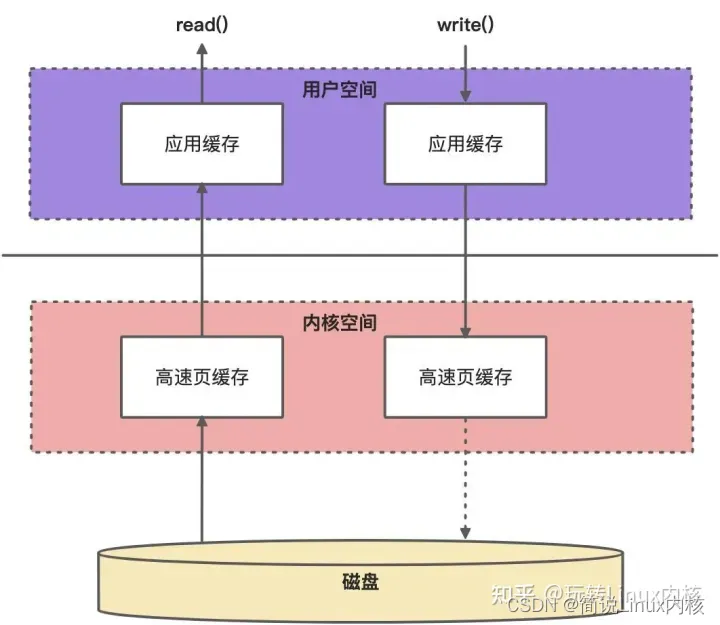
读操作:
当应用程序调用read()方法时,操作系统检查内核高速缓冲区中是否存在需要的数据,如果存在,那么就直接把内核空间的数据copy到用户空间,供用户的应用程序使用。如果内核缓冲区没有需要的数据,通过通过DMA方式从磁盘中读取数据到内核缓冲区,然后由CPU控制,把内核空间的数据copy到用户空间。
这个过程会涉及到两次缓冲区copy,第一次是从磁盘到内核缓冲区,第二次是从内核缓冲区到用户缓冲区,第一次是DMA的copy,第二次是CPU的copy。
写操作:
当应用程序调用write()方法时,应用程序将数据从用户空间copy到内核空间的缓冲区中(如果用户空间没有相应的数据,则需要从磁盘—>内核缓冲区—>用户缓冲区),这时对用户程序来说写操作就已经完成,至于什么时候把数据再写到磁盘(从内核缓冲区到磁盘的写操作也由DMA控制,不需要cpu参与),由操作系统决定。除非应用程序显示地调用了sync命令,立即把数据写入磁盘。
如果应用程序没准备好写的数据,则必须先从磁盘读取数据才能执行写操作,这时会涉及到四次缓冲区的copy,第一次是从磁盘的缓冲区到内核缓冲区,第二次是从内核缓冲区到用户缓冲区,第三次是从用户缓冲区到内核缓冲区,第四次是从内核缓冲区写回到磁盘。前两次是为了读,后两次是为了写。这其中有两次 CPU 拷贝,两次DMA拷贝。
磁盘IO的延时:
为了读或写,磁头必须能移动到所指定的磁道上,并等待所指定的扇区的开始位置旋转到磁头下,然后再开始读或写数据。磁盘IO的延时分成以下三部分:
寻道时间:把磁头移动到指定磁道上所经历的时间;
旋转延迟时间 :指定扇区移动到磁头下面所经历的时间;
传输时间 :数据的传输时间(数据读出或写入的时间);
网络 IO

读操作:
网络 IO 既可以从物理磁盘中读数据,也可以从Socket中读数据(从网卡中获取)。当从物理磁盘中读数据的时候,其流程和磁盘IO的读操作一样。当从Socket中读数据,应用程序需要等待客户端发送数据,如果客户端还没有发送数据,对应的应用程序将会被阻塞,直到客户端发送了数据,该应用程序才会被唤醒,从Socket协议栈(网卡)中读取客户端发送的数据到内核空间(这个过程也由DMA控制),然后把内核空间的数据 copy 到用户空间,供应用程序使用。
写操作:
为了简化描述,我们假设网络IO的数据从磁盘中获取,读写操作的流程如下:
当应用程序调用read()方法时,通过DMA方式将数据从磁盘拷贝到内核缓冲区;
由cpu控制,将内核缓冲区的数据拷贝到用户空间的缓冲区中,供应用程序使用;
当应用程序调用 write() 方法时,CPU 会把用户缓冲区中的数据 copy 到内核缓冲区的 Socket Buffer 中;
最后通过DMA方式将内核空间中的Socket Buffer拷贝到Socket协议栈(即网卡设备)中传输;
网络IO 的写操作也有四次缓冲区的copy,第一次是从磁盘缓冲区到内核缓冲区(由DMA控制),第二次是内核缓冲区到用户缓冲区(CPU控制),第三次是用户缓冲区到内核缓冲区的 Socket Buffer(由CPU控制),第四次是从内核缓冲区的 Socket Buffer 到网卡设备(由DMA控制)。四次缓冲区的copy工作两次由CPU控制,两次由DMA控制。
网络IO的延时:
网络IO主要延时是由:服务器响应延时+带宽限制+网络延时+跳转路由延时+本地接收延时 决定。一般为几十到几千毫秒,受环境影响较大。所以,一般来说,网络IO延时要大于磁盘IO延时(不过同数据中心的交互除外,会比磁盘 IO 更快)。
零拷贝 IO
在上述IO中,一次读写操作要经过四次缓冲区的拷贝,并经历了四次内核态和用户态的切换。 零拷贝(zero copy)IO 技术减少不必要的内核缓冲区跟用户缓冲区之间的拷贝,从而减少CPU的开销和状态切换带来的开销,达到性能的提升。
我们还是对比上面不使用零拷贝时的网络 IO 传输过程来对比分析下:
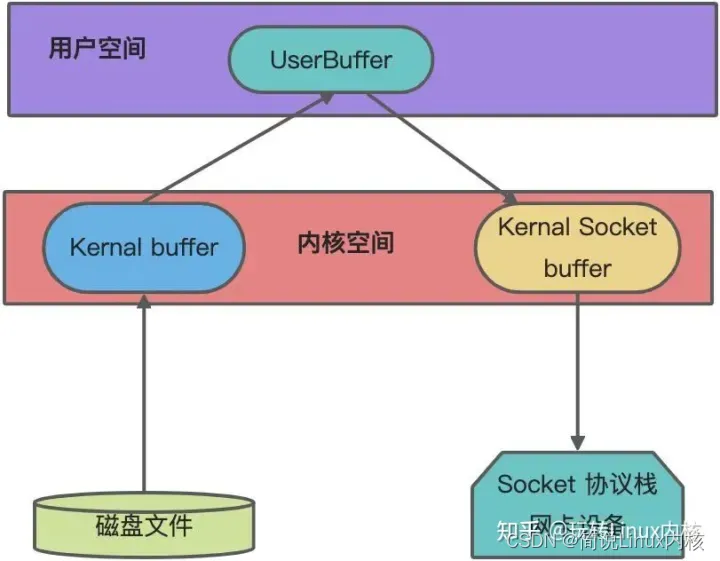
和上图普通的网络 IO 传输过程对比,零拷贝的传输过程:硬盘 -> kernel buffer (快速拷贝到kernel socket buffer) -> Socket协议栈(网卡设备中)。
当应用程序调用read()方法时,通过DMA方式将数据从磁盘拷贝到内核缓冲区;
由CPU控制,将内核缓冲区的数据直接拷贝到另外一个与 Socket 相关的内核缓冲区,即kernel socket buffer;
然后由 DMA 把数据从 kernel socket buffer 直接拷贝给 Socket 协议栈(网卡设备中);
这里,只经历了三次缓冲区的拷贝,第一次是从磁盘缓冲区到内核缓冲区,第二次是从内核缓冲区到 kernel socket buffer,第三次是从 kernel socket buffer 到Socket 协议栈(网卡设备中)。只发生两次内核态和用户态的切换,第一次是当应用程序调用read方法时,用户态切换到内核态执行read系统调用,第二次是将数据从网络中发送出去后系统调用返回,从内核态切换到用户态。
零拷贝(zero copy)的应用:
Linux 下提供了zero copy的接口:sendfile和splice,用户可通过这两个接口实现零拷贝传输;
Nginx 可以通过sendfile配置开启零拷贝;
在 Linux 系统中,Java NIO中 FileChannel.transferTo 的实现依赖于 sendfile()调用;
Apache 使用了 sendfile64() 来传送文件,sendfile64() 是 sendfile() 的扩展实现;
Kafka也用到了零拷贝的功能;
注意:零拷贝要求输入的fd必须是文件句柄,不能是socket,输出的fd必须是socket,也就是说,数据的来源必须是从本地的磁盘,而不能是从网络中,如果数据来源于socket,就不能使用零拷贝功能了。我们看一下sendfile接口就知道了:
#include <sys/sendfile.h>
ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count)out_fd:待写入文件描述符;
in_fd:待读出文件描述符;
offset:从读入文件流的哪个位置开始读,如果为空,则默认从起始位置开始;
count:指定在文件描述符in_fd 和out_fd之间传输的字节数;
返回值:成功时,返回出传输的字节数,失败返回-1;
**in_fd 必须指向真实的文件,不能是socket和管道;而out_fd则必须是一个socket。由此可见,**sendfile 几乎是专门为在网络上传输文件而设计的。
在Linxu系统中,一切皆文件,因此socket也是一个文件,也有文件句柄(或文件描述符)。
同步&异步、阻塞&非阻塞
这两组概念,我接触编程以来,经过听到别人说服务端是 同步非阻塞模型 或者 异步阻塞的 IO 模型,也前后了解过几次,但是理解都不够透彻,特别是这个非阻塞和异步、同步和阻塞的概念很容易懵逼,每个人的说法都不一样,最近我耐心看了几篇文章,这次我感觉我是顿悟了,这里分享下我的理解:
同步和异步是针对应用程序向内核发起任务后的状态而言的:如果发起调用后,在没有得到结果之前,当前调用就不返回,不能接着做后面的事情,一直等待就是同步。异步就是发出调用后,虽然不能立即得到结果,但是可以继续执行后面的事情,等调用结果出来时,会通过状态、通知和回调来通知调用者。
举个例子加深下理解:
在互联网普及之前,我们去医院看病都是排队的模式,想看病就得排队等,直到轮到你,在此之前你必须一直排队等待,这个就是同步;
现在互联网普及了,都是直接大屏叫号,我们预约登记后,就可以去休息厅坐着,打游戏啥的都可以干,到自己看病的时候会有通知的,这就是异步;
阻塞blocking、非阻塞non-blocking,则聚焦的是CPU在等待结果的过程中的状态。
阻塞调用是指调用结果返回之前,当前线程会被挂起,只有在得到结果之后才会返回。你可能会把阻塞调用和同步调用等同起来,实际上它们是不同的,同步只是说必须等到出结果才可以返回,但是等的过程中线程可以是激活的,阻塞是说线程被挂起了。
非阻塞和阻塞的概念相对应,指在不能立刻得到结果之前,该函数不会阻塞当前线程,而会立刻返回。
比如前面的例子,排队的过程中什么也不能做就是阻塞,CPU 执行权是交出去的;一边排队,一边看手机就是非阻塞,CPU 执行权还在自己手里,但是没看完病之前依旧是在排队死等,所以还是同步的。
总结
通过今天的学习,我们掌握了什么是 IO、常见的 IO 操作类型以及对应操作的原理,还有非常重要但是却很容易搞混的同步&异步、阻塞&非阻塞之间的区别,讲解的应该还是比较清楚的。
本文内容还是比较简单的,是一些基础知识,但是如果想深入学习网络编程这些基础是绕不开的,了解了操作系统对于 IO 操作的优化,才能搞明白各种高性能网络服务器的原理。
相关文章:
Linux内核IO基础知识与概念
什么是 IO在计算机操作系统中,所谓的I/O就是 输入(Input)和输出(Output),也可以理解为读(Read)和写(Write),针对不同的对象,I/O模式可以划分为磁盘…...
paper文献和科研小工具
一、好用的网站 Aminer 二、好用的工具 1. SciSpace SciSpace官网 【ChatGPT 论文阅读神器】SciSpace 用户注册与实战测试 SciSpace是一款基于 ChatGPT 的论文阅读神器。 2. ReadPaper 强大且超实用的论文阅读工具——ReadPaper ReadPaper官网 ReadPaper下载链接 Rea…...

dfs和bfs能解决的问题
一.理解暴力穷举之dfs和bfs暴力穷举暴力穷举是在解决问题中最常用的手段,而dfs和bfs算法则是这个手段的两个非常重要的工具。其实,最简单的穷举法是直接遍历,如数列求和,遍历一个数组即可求得所问答案,这与我在前两篇博…...

静态通讯录,适合初学者的手把手一条龙讲解
数据结构的顺序表和链表是一个比较困难的点,初见会让我们觉得有点困难,正巧C语言中有一个类似于顺序表和链表的小程序——通讯录。我们今天就来讲一讲通讯录的实现,也有利于之后顺序表和链表的学习。 目录 0.通讯录的初始化 1.菜单的创建…...
【你不知道的 CSS】你写的 CSS 太过冗余,以至于我对它下手了
:is() 你是否曾经写过下方这样冗余的CSS选择器: .active a, .active button, .active label {color: steelblue; }其实上面这段代码可以这样写: .active :is(a, button, label) {color: steelblue; }看~是不是简洁了很多! 是的,你可以使用…...

Lesson 8.1 决策树的核心思想与建模流程
文章目录一、借助逻辑回归构建决策树1. 决策树实例2. 决策树知识补充2.1 决策树简单构建2.2 决策树的分类过程2.3 决策树模型本质2.4 决策树的树生长过程2.5 树模型的基本结构二、决策树的分类与流派1. ID3(Iterative Dichotomiser 3) 、C4.5、C5.0 决策树2. CART 决策树3. CHA…...

【算法】FIFO先来先淘汰算法分析和编码实战
背景 在设计一个系统的时候,由于数据库的读取速度远小于内存的读取速度 为加快读取速度,将一部分数据放到内存中称为缓存,但内存容量是有限的,当要缓存的数据超出容量,就需要删除部分数据 这时候需要设计一种淘汰机制…...
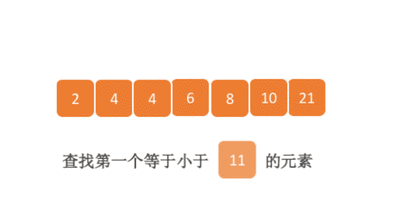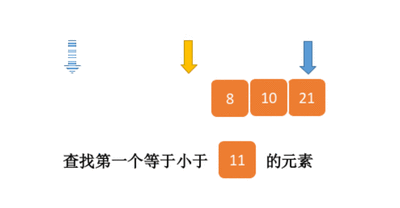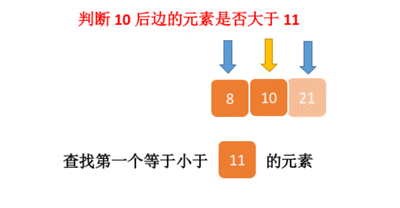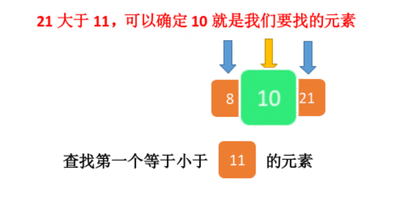
二分查找——我欲修仙(功法篇)
个人主页:【😊个人主页】 系列专栏:【❤️我欲修仙】 学习名言:临渊羡鱼,不如退而结网——《汉书董仲舒传》 系列文章目录 第一章 ❤️ 二分查找 文章目录系列文章目录前言🚗🚗🚗二分查找&…...

Python 多线程
文章目录一、简介1.1 多线程的特性1.2 GIL二、线程1.2 单线程1.3 多线程三、线程池3.1 pool.submit3.2 pool.map四、Lock(线程锁)4.1 无锁导致的线程资源异常4.2 有锁五、Event(事件)5.1 简介5.2 示例六、Queue(队列&a…...
JVM笔记(九)选择合适的垃圾收集器
Epsilon收集器Epsilon收集器由RedHat公司在JEP 318中提出,在此提案里Epsilon被形容成一个无操作的收集器(A No-Op Garbage Collector),而事实上只要Java虚拟机能够工作,垃圾收集器便不可能是真正“无操作”的。原因是“…...

二维图像处理到三维点云处理
一、Opencv和PCL 下面是opencv和pcl的特点、区别和联系的详细对比表格。 特点/区别/联系OpenCVPCL英文全称Open Source Computer Vision LibraryPoint Cloud Library语言C、Python、JavaC功能图像处理(图像处理和分析、特征提取和描述、图像识别和分类、目标检测和跟踪等)、计…...

leetcode 删除有序数组中的重复项
题目 给你一个 升序排列 的数组 nums ,请你 原地 删除重复出现的元素,使每个元素 只出现一次 ,返回删除后数组的新长度。元素的 相对顺序 应该保持 一致 。 由于在某些语言中不能改变数组的长度,所以必须将结果放在数组nums的第一…...

JVM学习.03 类加载机制
1、前言从事Java开发工作的都知道,Java程序提交到JVM运行时,需要编译成Class文件,才能被JVM加载运行。那么这些Class文件进入到虚拟机后会发生什么?以及Class是如何被加载的?这些都是本文要讲解的部分。2、类加载时机所…...
Celery使用:优秀的python异步任务框架
目录Celery 简介介绍安装基本使用Flask使用Celery异步任务定时任务Celery使用Flask上下文进阶使用参考停止Worker后台运行Celery 简介 介绍 Celery 是一个简单、灵活且可靠的,处理大量消息的分布式系统,并且提供维护这样一个系统的必需工具。 它是一个…...
第十四届蓝桥杯三月真题刷题训练——第 19 天
第 1 题:灌溉_BFS板子题 题目描述 小蓝负责花园的灌溉工作。 花园可以看成一个 n 行 m 列的方格图形。中间有一部分位置上安装有出水管。 小蓝可以控制一个按钮同时打开所有的出水管,打开时,有出水管的位置可以被认为已经灌溉好。 每经过一分…...

类和对象 - 下
本文已收录至《C语言》专栏! 作者:ARMCSKGT 目录 前言 正文 初始化列表 成员变量的定义与初始化 初始化列表的使用 变量定义顺序 explicit关键字 隐式类型转换 自定义类型隐式转换 explicit 限制转换 关于static static声明类成员 友元 友…...

【云原生】Linux基础IO(文件理解与操作)
✨个人主页: Yohifo 🎉所属专栏: Linux学习之旅 🎊每篇一句: 图片来源 🎃操作环境: CentOS 7.6 阿里云远程服务器 Great minds discuss ideas. Average minds discuss events. Small minds disc…...

CentOS 7 安装 mysql 8.0 客户端
只想安装 mysql-client 8.0 , 结果发现直接 yum install mysql mysql-client 安装的版本是 mysql Ver 15.1 Distrib 5.5.68-MariaDB ,这个版本太低,连接其他服务器上的 mysql 8.0 时总是失败,因为 mysql 8.0 加密方式改变了&#…...

Ubuntu下载、配置、安装和编译opencv
1 安装相关依赖安装opencv前,需要先准备好编译器、相关依赖sudo apt-get install gcc g cmake vim sudo apt-get install build-essential libgtk2.0-dev libavcodec-dev libavformat-dev libjpeg-dev libswscale-dev libtiff5-dev sudo apt-get install libgtk2.0-…...

第七讲 贪心
文章目录股票买卖 II货仓选址(贪心:排序中位数)糖果传递(❗贪心:中位数)雷达设备(贪心排序)付账问题(平均值排序❓)乘积最大(排序/双指针)后缀表达…...

Python爬虫实战:研究MechanicalSoup库相关技术
一、MechanicalSoup 库概述 1.1 库简介 MechanicalSoup 是一个 Python 库,专为自动化交互网站而设计。它结合了 requests 的 HTTP 请求能力和 BeautifulSoup 的 HTML 解析能力,提供了直观的 API,让我们可以像人类用户一样浏览网页、填写表单和提交请求。 1.2 主要功能特点…...

【OSG学习笔记】Day 18: 碰撞检测与物理交互
物理引擎(Physics Engine) 物理引擎 是一种通过计算机模拟物理规律(如力学、碰撞、重力、流体动力学等)的软件工具或库。 它的核心目标是在虚拟环境中逼真地模拟物体的运动和交互,广泛应用于 游戏开发、动画制作、虚…...

【力扣数据库知识手册笔记】索引
索引 索引的优缺点 优点1. 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。2. 可以加快数据的检索速度(创建索引的主要原因)。3. 可以加速表和表之间的连接,实现数据的参考完整性。4. 可以在查询过程中,…...

使用分级同态加密防御梯度泄漏
抽象 联邦学习 (FL) 支持跨分布式客户端进行协作模型训练,而无需共享原始数据,这使其成为在互联和自动驾驶汽车 (CAV) 等领域保护隐私的机器学习的一种很有前途的方法。然而,最近的研究表明&…...

抖音增长新引擎:品融电商,一站式全案代运营领跑者
抖音增长新引擎:品融电商,一站式全案代运营领跑者 在抖音这个日活超7亿的流量汪洋中,品牌如何破浪前行?自建团队成本高、效果难控;碎片化运营又难成合力——这正是许多企业面临的增长困局。品融电商以「抖音全案代运营…...

React19源码系列之 事件插件系统
事件类别 事件类型 定义 文档 Event Event 接口表示在 EventTarget 上出现的事件。 Event - Web API | MDN UIEvent UIEvent 接口表示简单的用户界面事件。 UIEvent - Web API | MDN KeyboardEvent KeyboardEvent 对象描述了用户与键盘的交互。 KeyboardEvent - Web…...

有限自动机到正规文法转换器v1.0
1 项目简介 这是一个功能强大的有限自动机(Finite Automaton, FA)到正规文法(Regular Grammar)转换器,它配备了一个直观且完整的图形用户界面,使用户能够轻松地进行操作和观察。该程序基于编译原理中的经典…...

听写流程自动化实践,轻量级教育辅助
随着智能教育工具的发展,越来越多的传统学习方式正在被数字化、自动化所优化。听写作为语文、英语等学科中重要的基础训练形式,也迎来了更高效的解决方案。 这是一款轻量但功能强大的听写辅助工具。它是基于本地词库与可选在线语音引擎构建,…...

R语言速释制剂QBD解决方案之三
本文是《Quality by Design for ANDAs: An Example for Immediate-Release Dosage Forms》第一个处方的R语言解决方案。 第一个处方研究评估原料药粒径分布、MCC/Lactose比例、崩解剂用量对制剂CQAs的影响。 第二处方研究用于理解颗粒外加硬脂酸镁和滑石粉对片剂质量和可生产…...

uniapp 开发ios, xcode 提交app store connect 和 testflight内测
uniapp 中配置 配置manifest 文档:manifest.json 应用配置 | uni-app官网 hbuilderx中本地打包 下载IOS最新SDK 开发环境 | uni小程序SDK hbulderx 版本号:4.66 对应的sdk版本 4.66 两者必须一致 本地打包的资源导入到SDK 导入资源 | uni小程序SDK …...