排序算法之梳排序
title: 梳排序
date: 2024-7-30 14:46:27 +0800
categories:
- 排序算法
tags: - 排序
- 算法
- 梳排序
description: 梳排序(Comb Sort)是一种由弗拉基米尔·多博舍维奇(Wlodzimierz Dobosiewicz)于1980年所发明的不稳定排序算法,并由史蒂芬·莱西(Stephen Lacey)和理查德·博克斯(Richard Box)于1991年四月号的Byte杂志中推广。梳排序是改良自冒泡排序和快速排序,其要旨在于消除“乌龟”,亦即在数组尾部的小数值,这些数值是造成冒泡排序缓慢的主因。相对地,“兔子”,亦即在数组前端的大数值,不影响冒泡排序的性能。
math: true
梳排序
梳排序(Comb Sort)是一种改进的冒泡排序算法。它通过消除“乌龟”(即数组中的小值)和“兔子”(即数组中的大值)来提高排序效率。梳排序的核心思想是先使用较大的间隙(gap)进行比较和交换,然后逐渐减小间隙,最终进行常规的冒泡排序。
梳排序的原理
梳排序的关键在于间隙的选择和逐渐缩小。初始间隙通常设置为数组长度,然后在每次迭代中将间隙除以一个因子(通常为1.3),直到间隙缩小到1,此时进行最后的冒泡排序。
图示

梳排序的步骤
- 设置初始间隙:初始间隙为数组长度。
- 调整间隙:在每次迭代中,将间隙除以因子(通常为1.3)。
- 比较和交换:在当前间隙下比较并交换元素。
- 重复步骤2和3:直到间隙缩小到1,进行最后的冒泡排序。
梳排序示例
假设待数组[10 4 3 9 6 5 2 1 7 8]
第一次循环
待排数组长度为10,而10÷1.3=8,则比较10和7,4和8,并做交换
交换后的结果为[7 4 3 9 6 5 2 1 10 8]
第二次循环
更新间距为8÷1.3=6,比较7和2,4和1,3和10,9和8,7和2,4和1,9和8,需要交换
交换后的结果为[2 1 3 8 6 5 7 4 10 9]
第三次循环
更新距离为4,比较2和6,1和5,3和7,8和4,6和10,5和9,8和4,需要交换
[2 1 3 4 6 5 7 8 10 9]
第四次循环
更新距离为3,比较2和4,1和6,3和5,4和7,6和8,5和10,7和9,不需要交换
第五次循环
更新距离为2,比较2和3,1和4,3和6,4和5,6和7,5和8,7和10,8和9,不需要交换
第六次循环
更新距离为1,为冒泡排序。
[1 2 3 4 5 6 7 8 9 10]
交换后排序结束,顺序输出即可得到[1 2 3 4 5 6 7 8 9 10]
复杂度分析
递减率的设置影响着梳排序的效率,原作者以随机数作实验,得到最有效递减率为1.3的。如果此比率太小,则导致一循环中有过多的比较,如果比率太大,则未能有效消除数组中的乌龟。
亦有人提议用 1 / ( 1 − 1 e φ ) ≈ 1.247330950103979 1/\left(1-{\frac {1}{e^{\varphi }}}\right)\approx 1.247330950103979 1/(1−eφ1)≈1.247330950103979作递减率,同时增加换算表协助于每一循环开始时计算新间距。
因为编程语言中乘法比除法快,故会取递减率倒数与间距相乘, 1 1.247330950103979 = 0.801711847137793 ≈ 0.8 \frac{1}{1.247330950103979}=0.801711847137793\approx 0.8 1.2473309501039791=0.801711847137793≈0.8
时间复杂度
- 最佳情况: O ( n log n ) O(n\log n) O(nlogn)。
- 最坏情况: Ω ( n 2 ) \Omega(n^2) Ω(n2)。
- 平均情况: Ω ( n 2 2 p ) \Omega (\frac{n^2}{2^p}) Ω(2pn2)。
空间复杂度
- 空间复杂度: O ( 1 ) O(1) O(1)。
Java代码实现
import java.util.Arrays;public class CombSort {public static void combSort(int[] arr) {int n = arr.length;int gap = n;boolean swapped = true;while (gap != 1 || swapped) {// 调整间隙gap = getNextGap(gap);swapped = false;// 比较和交换for (int i = 0; i < n - gap; i++) {if (arr[i] > arr[i + 1]) {int temp = arr[i];arr[i] = arr[i + gap];arr[i + gap] = temp;swapped = true;}}}}// 计算下一个间隙private static int getNextGap(int gap) {gap = (gap * 10) / 13;if (gap < 1) {return 1;}return gap;}public static void main(String[] args) {int[] arr = {6, 4, 3, 7, 1, 9, 8, 2, 5};System.out.println("Given Array:");System.out.println(Arrays.toString(arr));// 调用梳排序函数combSort(arr);System.out.println("Sorted Array:");System.out.println(Arrays.toString(arr));}
}
变异形式
梳排序-11
设置递减率为1.3时,最后只会有三种不同的间距组合:(9, 6, 4, 3, 2, 1)、(10, 7, 5, 3, 2, 1)、或 (11, 8, 6, 4, 3, 2, 1)。实验证明,如果间距变成9或10时一律改作11,则对效率有明显改善,原因是如果间距曾经是9或10,则到间距变成1时,数值通常不是递增序列,故此要进行几次冒泡排序循环修正。加入此指定间距的变异形式称为梳排序-11(Combsort11)_。
混合梳排序和其他排序算法
如同快速排序和归并排序,梳排序的效率在开始时最佳,接近结束时最差。如果间距变得太小时(例如小于10),改用插入排序或希尔排序等算法,可提升整体性能。
此方法最大好处是不需要检查是否进行过交换程序以将排序循环提早结束。
相关文章:
排序算法之梳排序
title: 梳排序 date: 2024-7-30 14:46:27 0800 categories: 排序算法 tags:排序算法梳排序 description: 梳排序(Comb Sort)是一种由弗拉基米尔多博舍维奇(Wlodzimierz Dobosiewicz)于1980年所发明的不稳定排序算法,并…...

ESP8266 创建TCP连接
TCP Client 使用WiFiClient类可以实现TCP Client 基本方法 连接Server,connect WiFiClient client; client.connect(host, port) 检测客户端是否存在数据流 client.available() 读取客户端的一个字符 client.read(); 检查连接状态 client.connected() 使用…...

OceanBase内存管理小窍门
本文来自OceanBase热心用户的实践分享。 本文主要是对OceanBase内存管理的实用技巧分享,而并非直接深入OceanBase的代码层面进行阐述。 阅读本文章你将了解: 重载运算符new 与malloc在返回值上区别?在ceph 双向链表新用法&am…...

【问题解决】git status中文文件名乱码
问题复现 解决办法 在git bash中直接执行如下命令 git config --global core.quotepath false原因 通过 git config --help 可以查看到以下内容: core.quotePath Commands that output paths (e.g. ls-files, diff), will quote “unusual” characters in the p…...
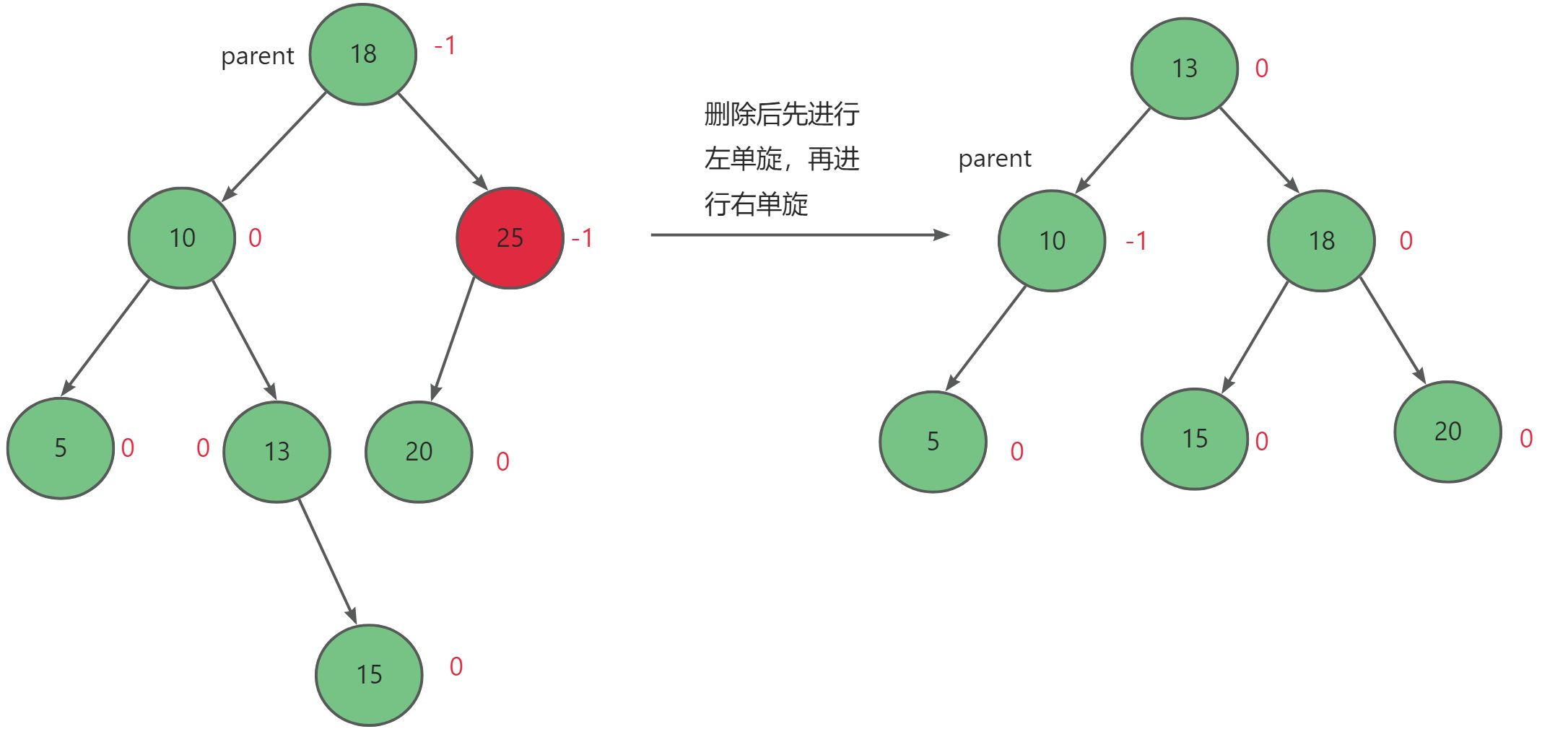
探索数据结构:AVL树的分析与实现
✨✨ 欢迎大家来到贝蒂大讲堂✨✨ 🎈🎈养成好习惯,先赞后看哦~🎈🎈 所属专栏:数据结构与算法 贝蒂的主页:Betty’s blog 1. AVL树的介绍 在前面我们学习二叉搜索树时知道,在数据有序…...

使用 C++ 实现简单的插件系统
使用 C 实现简单的插件系统 在现代软件开发中,插件系统是一种常见的架构模式,它允许开发者在不修改主程序的情况下,扩展应用程序的功能。通过插件,用户可以根据需要添加或移除功能模块,从而提高软件的灵活性和可维护性…...

使用Python创建省份城市地图选择器
在这篇博客中,我们将探讨如何使用Python创建一个简单而实用的省份城市地图选择器。这个项目不仅能帮助我们学习Python的基础知识,还能让我们了解如何处理JSON数据和集成网页浏览器到桌面应用程序中。 C:\pythoncode\new\geographicgooglemap.py 全部代码…...

【Java 数据结构】Stack和Queue介绍
Stack和Queue StackStack是什么Stack的使用构造方法常用方法 栈的模拟实现初始化和基本方法入栈出栈查看栈顶 栈的应用链栈的简单介绍 QueueQueue是什么Queue的使用队列的模拟实现初始化入队出队查看队头元素 循环队列循环队列的定义及其注意点循环队列的实现初始化和基本方法获…...
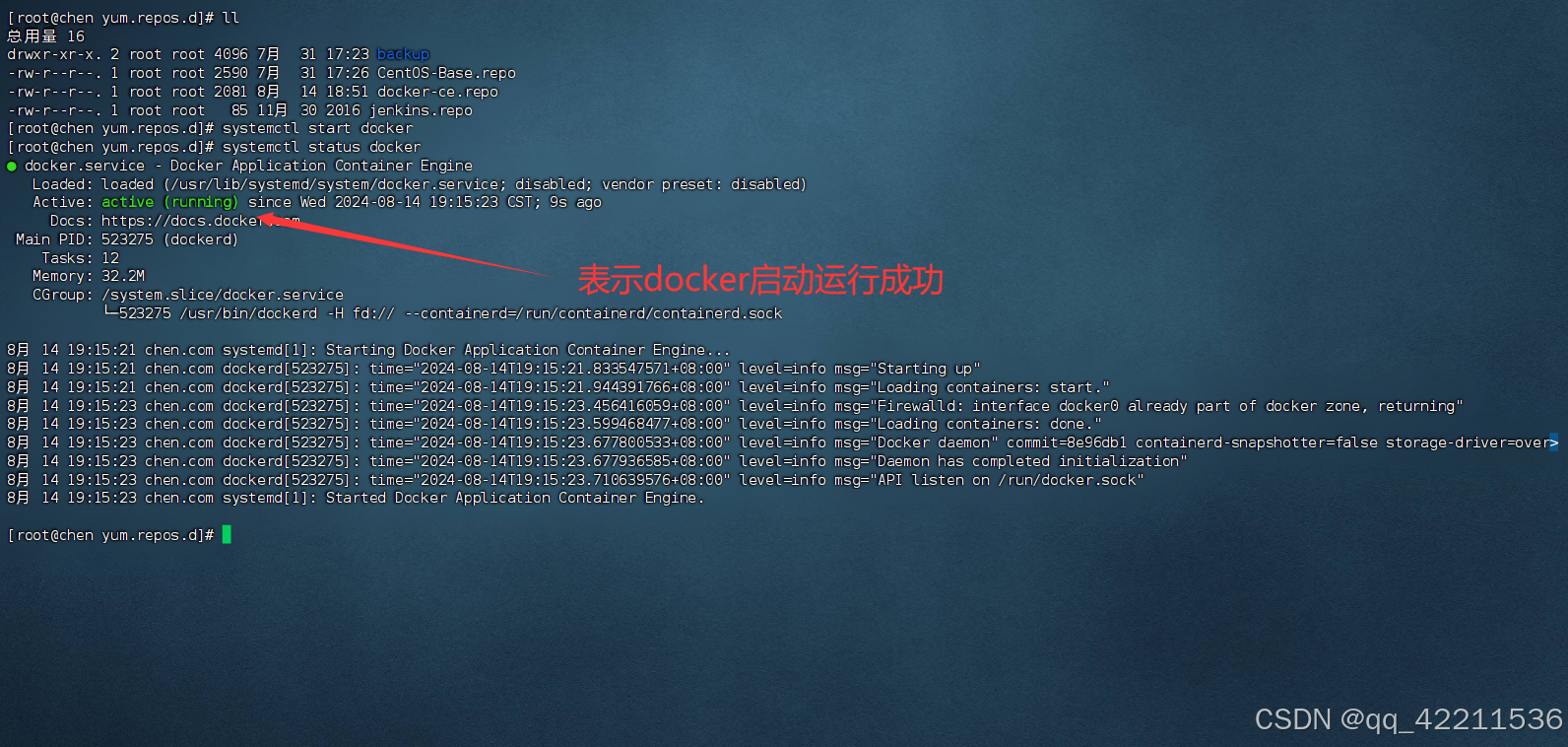
Docker基本语法
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、更新yum镜像仓库(一)查看本地yum镜像源地址(二)设置docker的镜像仓库(1)安装必要工具…...

uniapp 对于scroll-view滑动和页面滑动的联动处理
需求 遇到一个需求 解决方案 这个时候可以做一个内页面滑动判断 <!-- scroll-y 做true或者false的判断是否滑动 --> <view class"u-menu-wrap" style"background-color: #fff;"><scroll-view :scroll-y"data.isGo" scroll-wit…...

opencv基础的图像操作
1.读取图像,显示图像,保存图像 #图像读取、显示与保存 import numpy as np import cv2 imgcv2.imread(./src/1.jpg) #读取 cv2.imshow("img",img) #显示 cv2.imwrite("./src/2.jpg",img) #保存 cv2.waitKey(0) #让程序进入主循环(让…...

Java | Leetcode Java题解之第337题打家劫舍III
题目: 题解: class Solution {public int rob(TreeNode root) {int[] rootStatus dfs(root);return Math.max(rootStatus[0], rootStatus[1]);}public int[] dfs(TreeNode node) {if (node null) {return new int[]{0, 0};}int[] l dfs(node.left);i…...

本地查看的Git远程仓库分支与远程仓库分支数量不一致
说明:一次,在IDEA中想切换到某分支,但是查看Remote没有找到要切换的分支,但是打开GitLab,查看远程仓库,是有这个分支的。 解决:1)在IDEA的Git中,点下面Fatch获取一下远程…...

opencv-python实战项目九:基于拉普拉斯金字塔的图像融合
文章目录 一,简介:二,拉普拉斯金字塔介绍:三,算法实现步骤3.1 构建融合拉普拉斯金字塔3.2 融合后的拉普拉斯金字塔复原: 四,整体代码实现:五,效果: 一&#x…...

浅谈JDK
JDK(Java Development Kit) JDK是Java开发工具包,是Java编程语言的核心软件开发工具。 JDK包含了一系列用于开发、编译和运行Java应用程序的工具和资源。其中包括: 1.Java编译器(javac):用于将Java源代码编译成字节…...

爬虫案例3——爬取彩票双色球数据
简介:个人学习分享,如有错误,欢迎批评指正 任务:从500彩票网中爬取双色球数据 目标网页地址:https://datachart.500.com/ssq/ 一、思路和过程 目标网页具体内容如下: 我们的任务是将上图中…...

C++ | Leetcode C++题解之第337题打家劫舍III
题目: 题解: struct SubtreeStatus {int selected;int notSelected; };class Solution { public:SubtreeStatus dfs(TreeNode* node) {if (!node) {return {0, 0};}auto l dfs(node->left);auto r dfs(node->right);int selected node->val…...

软件架构设计师-UML知识导图
软件架构设计师-UML知识导图,包含如下内容: 结构化设计,包含结构化设计的概念、结构化设计的主要内容、概要设计、详细设计及模块设计原则;UML是什么:介绍UML是什么;UML的结构:构造块、公共机制…...
在使用transformers和pytorch时出现的版本冲突的问题
在使用transformers和torch库的时候,出现了以下问题: 1、OSError: [WinError 126] 找不到指定的模块。 Error loading "D:\Program Files\anaconda3\envs\testenv\Lib\site-packages\torch\lib\fbgemm.dll" or one of its dependencies. 2、…...

uniapp粘贴板地址识别
1: 插件安装 主要是依靠 address-parse 这个插件: 官网 收货地址自动识别 支持pc、h5、微信小程序 - DCloud 插件市场 // 首先需要引入插件 npm install address-parse --save 2:html部分 <view class""><view class&quo…...
:にする)
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(33):にする
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(33):にする 1、前言(1)情况说明(2)工程师的信仰2、知识点(1) にする1,接续:名词+にする2,接续:疑问词+にする3,(A)は(B)にする。(2)復習:(1)复习句子(2)ために & ように(3)そう(4)にする3、…...

什么是库存周转?如何用进销存系统提高库存周转率?
你可能听说过这样一句话: “利润不是赚出来的,是管出来的。” 尤其是在制造业、批发零售、电商这类“货堆成山”的行业,很多企业看着销售不错,账上却没钱、利润也不见了,一翻库存才发现: 一堆卖不动的旧货…...

1.3 VSCode安装与环境配置
进入网址Visual Studio Code - Code Editing. Redefined下载.deb文件,然后打开终端,进入下载文件夹,键入命令 sudo dpkg -i code_1.100.3-1748872405_amd64.deb 在终端键入命令code即启动vscode 需要安装插件列表 1.Chinese简化 2.ros …...

如何为服务器生成TLS证书
TLS(Transport Layer Security)证书是确保网络通信安全的重要手段,它通过加密技术保护传输的数据不被窃听和篡改。在服务器上配置TLS证书,可以使用户通过HTTPS协议安全地访问您的网站。本文将详细介绍如何在服务器上生成一个TLS证…...

【碎碎念】宝可梦 Mesh GO : 基于MESH网络的口袋妖怪 宝可梦GO游戏自组网系统
目录 游戏说明《宝可梦 Mesh GO》 —— 局域宝可梦探索Pokmon GO 类游戏核心理念应用场景Mesh 特性 宝可梦玩法融合设计游戏构想要素1. 地图探索(基于物理空间 广播范围)2. 野生宝可梦生成与广播3. 对战系统4. 道具与通信5. 延伸玩法 安全性设计 技术选…...

R语言速释制剂QBD解决方案之三
本文是《Quality by Design for ANDAs: An Example for Immediate-Release Dosage Forms》第一个处方的R语言解决方案。 第一个处方研究评估原料药粒径分布、MCC/Lactose比例、崩解剂用量对制剂CQAs的影响。 第二处方研究用于理解颗粒外加硬脂酸镁和滑石粉对片剂质量和可生产…...

uniapp 字符包含的相关方法
在uniapp中,如果你想检查一个字符串是否包含另一个子字符串,你可以使用JavaScript中的includes()方法或者indexOf()方法。这两种方法都可以达到目的,但它们在处理方式和返回值上有所不同。 使用includes()方法 includes()方法用于判断一个字…...

Oracle11g安装包
Oracle 11g安装包 适用于windows系统,64位 下载路径 oracle 11g 安装包...

uniapp 实现腾讯云IM群文件上传下载功能
UniApp 集成腾讯云IM实现群文件上传下载功能全攻略 一、功能背景与技术选型 在团队协作场景中,群文件共享是核心需求之一。本文将介绍如何基于腾讯云IMCOS,在uniapp中实现: 群内文件上传/下载文件元数据管理下载进度追踪跨平台文件预览 二…...
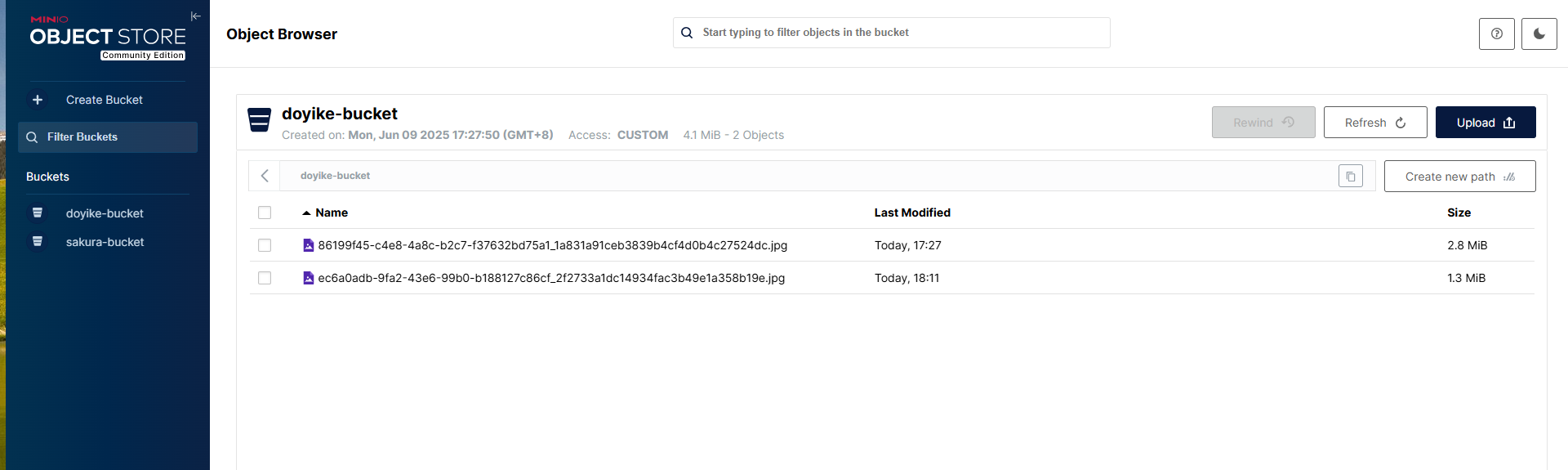
Linux部署私有文件管理系统MinIO
最近需要用到一个文件管理服务,但是又不想花钱,所以就想着自己搭建一个,刚好我们用的一个开源框架已经集成了MinIO,所以就选了这个 我这边对文件服务性能要求不是太高,单机版就可以 安装非常简单,几个命令就…...