从Hive源码解读大数据开发为什么可以脱离SQL、Java、Scala
从Hive源码解读大数据开发为什么可以脱离SQL、Java、Scala
前言
【本文适合有一定计算机基础/半年工作经验的读者食用。立个Flg,愿天下不再有肤浅的SQL Boy】
谈到大数据开发,占据绝大多数人口的就是SQL Boy,不接受反驳,毕竟大数据主要就是为机器学习和统计报表服务的,自然从Oracle数据库开发转过来并且还是只会写几句SQL的人不在少数,个别会Python写个spark.sql(“一个sql字符串”)的已经是SQL Boy中的人才。这种只能处理结构化表的最基础的大数据开发人员,就是我们常提到的梗:肤浅的SQL Boy。。。对大数据完全不懂,思想还停留在数据库时代,大数据组件也都是拿来当RDBMS来用。。。这种业务开发人员的技术水平其实不敢恭维。
还有从Java后端开发转过来的,虽然不适应,但还是可以一个Main方法流畅地操作Spark、Flink,手写个JDBC,做点简单的二开,这种就是平台开发人员,技术水平要更高一些。Java写得好,Scala其实上手也快。
但是。。。这并不代表做大数据只能用SQL/Java/Scala。。。这么局限的话,也不比SQL Boy强到哪里去。
笔者最早还搞过嵌入式开发,自然明白C/C#/C++也可以搞大数据。。。
本文将以大数据开发中最常见的数仓组件Hive的drop table为例,抛砖引玉,解读为神马大数据开发可以脱离SQL、Java、Scala。
为神马可以脱离SQL
数据不外乎结构化数据和非结构化数据,SQL只能处理极其有限的结构化表【RDBMS、整齐的csv/tsv等】,绝大多数的半结构化、非结构化数据SQL是无能为力的【log日志文件、音图等】。古代的MapReduce本身就不可以用SQL,Spark和Flink老版本都是基于API的,没有SQL的年代大家也活得好好的。大数据组件对SQL的支持日渐友好都是后来的事情,主要是为了降低门槛,让SQL Boy也可以用上大数据技术。
肤浅的SQL Boy们当然只知道:
drop table db_name.tb_name;
正常情况这个Hive表就会被drop掉,认知也就局限于Hive是个数据库。
但是大数据平台开发知道去翻看Hive的Java API:
https://svn.apache.org/repos/infra/websites/production/hive/content/javadocs/r3.1.3/api/index.html
知道还有这种方式:
package com.zhiyong;import org.apache.hadoop.hive.conf.HiveConf;
import org.apache.hadoop.hive.metastore.HiveMetaStoreClient;/*** @program: zhiyong_study* @description: 测试MetaStore* @author: zhiyong* @create: 2023-03-22 22:57**/
public class MetaStoreDemo {public static void main(String[] args) throws Exception{HiveConf hiveConf = new HiveConf();HiveMetaStoreClient client = new HiveMetaStoreClient(hiveConf);client.dropTable("db_name","tb_name");}
}
通过调用API的方式,同样可以drop掉表。显然不一定要用DDL。通过HiveMetaStoreClient的方式,还可以create建表等操作。
懂大数据底层的平台开发当然还有更狠的方式:直接连Hive存元数据的MySQL,对元数据表的数据做精准crud。。。
对结构化表的ETL或者其它的运算处理完全可以用Spark的DataFrame、Flink的DataStream编程,纯API方式实现,SQL能实现的Java和Scala都能实现,至于SQL实现不了的Java和Scala也能实现。。。
笔者实在是想不到除了RDBMS和各类包皮产品【在开源的Apache组件基础上做一些封装】,还有哪些场景是只能用SQL的。。。
至此,可以说明大数据可以脱离SQL。
为神马可以脱离Java
虽然Hive底层是Java写的,但是这并不意味着只能用Java操作Hive。认知这么肤浅的话,也就活该一辈子调参调API了。。。
找到dropTable的实际入口
从Hive3.1.2源码,可以找到dropTable方法:
@Overridepublic void dropTable(String dbname, String name, boolean deleteData,boolean ignoreUnknownTab) throws MetaException, TException,NoSuchObjectException, UnsupportedOperationException {dropTable(getDefaultCatalog(conf), dbname, name, deleteData, ignoreUnknownTab, null);}@Overridepublic void dropTable(String dbname, String name, boolean deleteData,boolean ignoreUnknownTab, boolean ifPurge) throws TException {dropTable(getDefaultCatalog(conf), dbname, name, deleteData, ignoreUnknownTab, ifPurge);}@Overridepublic void dropTable(String dbname, String name) throws TException {dropTable(getDefaultCatalog(conf), dbname, name, true, true, null);}@Overridepublic void dropTable(String catName, String dbName, String tableName, boolean deleteData,boolean ignoreUnknownTable, boolean ifPurge) throws TException {//build new environmentContext with ifPurge;EnvironmentContext envContext = null;if(ifPurge){Map<String, String> warehouseOptions;warehouseOptions = new HashMap<>();warehouseOptions.put("ifPurge", "TRUE");envContext = new EnvironmentContext(warehouseOptions);}dropTable(catName, dbName, tableName, deleteData, ignoreUnknownTable, envContext);}
虽然有多个同名方法,但是底层调用的还是同一个方法:
/*** Drop the table and choose whether to: delete the underlying table data;* throw if the table doesn't exist; save the data in the trash.** @param catName catalog name* @param dbname database name* @param name table name* @param deleteData* delete the underlying data or just delete the table in metadata* @param ignoreUnknownTab* don't throw if the requested table doesn't exist* @param envContext* for communicating with thrift* @throws MetaException* could not drop table properly* @throws NoSuchObjectException* the table wasn't found* @throws TException* a thrift communication error occurred* @throws UnsupportedOperationException* dropping an index table is not allowed* @see org.apache.hadoop.hive.metastore.api.ThriftHiveMetastore.Iface#drop_table(java.lang.String,* java.lang.String, boolean)*/public void dropTable(String catName, String dbname, String name, boolean deleteData,boolean ignoreUnknownTab, EnvironmentContext envContext) throws MetaException, TException,NoSuchObjectException, UnsupportedOperationException {Table tbl;try {tbl = getTable(catName, dbname, name);} catch (NoSuchObjectException e) {if (!ignoreUnknownTab) {throw e;}return;}HiveMetaHook hook = getHook(tbl);if (hook != null) {hook.preDropTable(tbl);}boolean success = false;try {drop_table_with_environment_context(catName, dbname, name, deleteData, envContext);if (hook != null) {hook.commitDropTable(tbl, deleteData || (envContext != null && "TRUE".equals(envContext.getProperties().get("ifPurge"))));}success=true;} catch (NoSuchObjectException e) {if (!ignoreUnknownTab) {throw e;}} finally {if (!success && (hook != null)) {hook.rollbackDropTable(tbl);}}}
主要就是获取了表对象,然后做了preDropTable预提交和commitDropTable实际的提交。这种2PC方式表面上还是很严谨。。。
可以发现HiveMetaHook这其实是个接口:
package org.apache.hadoop.hive.metastore;/*** HiveMetaHook defines notification methods which are invoked as part* of transactions against the metastore, allowing external catalogs* such as HBase to be kept in sync with Hive's metastore.**<p>** Implementations can use {@link MetaStoreUtils#isExternalTable} to* distinguish external tables from managed tables.*/
@InterfaceAudience.Public
@InterfaceStability.Stable
public interface HiveMetaHook {public String ALTER_TABLE_OPERATION_TYPE = "alterTableOpType";public List<String> allowedAlterTypes = ImmutableList.of("ADDPROPS", "DROPPROPS");/*** Called before a table definition is removed from the metastore* during DROP TABLE.** @param table table definition*/public void preDropTable(Table table)throws MetaException;/*** Called after failure removing a table definition from the metastore* during DROP TABLE.** @param table table definition*/public void rollbackDropTable(Table table)throws MetaException;/*** Called after successfully removing a table definition from the metastore* during DROP TABLE.** @param table table definition** @param deleteData whether to delete data as well; this should typically* be ignored in the case of an external table*/public void commitDropTable(Table table, boolean deleteData)throws MetaException;
}
继承关系:

显然不是这个:
package org.apache.hadoop.hive.metastore;public abstract class DefaultHiveMetaHook implements HiveMetaHook {/*** Called after successfully INSERT [OVERWRITE] statement is executed.* @param table table definition* @param overwrite true if it is INSERT OVERWRITE** @throws MetaException*/public abstract void commitInsertTable(Table table, boolean overwrite) throws MetaException;/*** called before commit insert method is called* @param table table definition* @param overwrite true if it is INSERT OVERWRITE** @throws MetaException*/public abstract void preInsertTable(Table table, boolean overwrite) throws MetaException;/*** called in case pre commit or commit insert fail.* @param table table definition* @param overwrite true if it is INSERT OVERWRITE** @throws MetaException*/public abstract void rollbackInsertTable(Table table, boolean overwrite) throws MetaException;
}
更不可能是这个test的Mock类:
/*** Mock class used for unit testing.* {@link org.apache.hadoop.hive.ql.lockmgr.TestDbTxnManager2#testLockingOnInsertIntoNonNativeTables()}*/
public class StorageHandlerMock extends DefaultStorageHandler {}
所以是AccumuloStorageHandler这个类:
package org.apache.hadoop.hive.accumulo;/*** Create table mapping to Accumulo for Hive. Handle predicate pushdown if necessary.*/
public class AccumuloStorageHandler extends DefaultStorageHandler implements HiveMetaHook,HiveStoragePredicateHandler {}
但是:
@Overridepublic void preDropTable(Table table) throws MetaException {// do nothing}
这个do nothing!!!一言难尽。这种2PC方式表面上确实很严谨。。。
所以dropTable的入口是:
@Overridepublic void commitDropTable(Table table, boolean deleteData) throws MetaException {String tblName = getTableName(table);if (!isExternalTable(table)) {try {if (deleteData) {TableOperations tblOpts = connectionParams.getConnector().tableOperations();if (tblOpts.exists(tblName)) {tblOpts.delete(tblName);}}} catch (AccumuloException e) {throw new MetaException(StringUtils.stringifyException(e));} catch (AccumuloSecurityException e) {throw new MetaException(StringUtils.stringifyException(e));} catch (TableNotFoundException e) {throw new MetaException(StringUtils.stringifyException(e));}}}
按照最简单的内部表、需要删数据来看,实际上调用的是这个delete方法。而TableOperations又是个接口:
package org.apache.accumulo.core.client.admin;/*** Provides a class for administering tables**/public interface TableOperations {/*** Delete a table** @param tableName* the name of the table* @throws AccumuloException* if a general error occurs* @throws AccumuloSecurityException* if the user does not have permission* @throws TableNotFoundException* if the table does not exist*/void delete(String tableName) throws AccumuloException, AccumuloSecurityException, TableNotFoundException;
}
继承关系简单:

当然就是这个实现类:
package org.apache.accumulo.core.client.impl;public class TableOperationsImpl extends TableOperationsHelper {@Overridepublic void delete(String tableName) throws AccumuloException, AccumuloSecurityException, TableNotFoundException {checkArgument(tableName != null, "tableName is null");List<ByteBuffer> args = Arrays.asList(ByteBuffer.wrap(tableName.getBytes(UTF_8)));Map<String,String> opts = new HashMap<>();try {doTableFateOperation(tableName, TableNotFoundException.class, FateOperation.TABLE_DELETE, args, opts);} catch (TableExistsException e) {// should not happenthrow new AssertionError(e);}}
}
所以实际入口是这里的doTableFateOperation方法。枚举体的FateOperation.TABLE_DELETE=2。
找到doTableFateOperation方法的调用栈
跳转到:
private void doTableFateOperation(String tableOrNamespaceName, Class<? extends Exception> namespaceNotFoundExceptionClass, FateOperation op,List<ByteBuffer> args, Map<String,String> opts) throws AccumuloSecurityException, AccumuloException, TableExistsException, TableNotFoundException {try {doFateOperation(op, args, opts, tableOrNamespaceName);} }
继续跳转:
String doFateOperation(FateOperation op, List<ByteBuffer> args, Map<String,String> opts, String tableOrNamespaceName) throws AccumuloSecurityException,TableExistsException, TableNotFoundException, AccumuloException, NamespaceExistsException, NamespaceNotFoundException {return doFateOperation(op, args, opts, tableOrNamespaceName, true);}
继续跳转:
String doFateOperation(FateOperation op, List<ByteBuffer> args, Map<String,String> opts, String tableOrNamespaceName, boolean wait)throws AccumuloSecurityException, TableExistsException, TableNotFoundException, AccumuloException, NamespaceExistsException, NamespaceNotFoundException {Long opid = null;try {opid = beginFateOperation();executeFateOperation(opid, op, args, opts, !wait);if (!wait) {opid = null;return null;}String ret = waitForFateOperation(opid);return ret;} catch (ThriftSecurityException e) {switch (e.getCode()) {case TABLE_DOESNT_EXIST:throw new TableNotFoundException(null, tableOrNamespaceName, "Target table does not exist");case NAMESPACE_DOESNT_EXIST:throw new NamespaceNotFoundException(null, tableOrNamespaceName, "Target namespace does not exist");default:String tableInfo = Tables.getPrintableTableInfoFromName(context.getInstance(), tableOrNamespaceName);throw new AccumuloSecurityException(e.user, e.code, tableInfo, e);}} catch (ThriftTableOperationException e) {switch (e.getType()) {case EXISTS:throw new TableExistsException(e);case NOTFOUND:throw new TableNotFoundException(e);case NAMESPACE_EXISTS:throw new NamespaceExistsException(e);case NAMESPACE_NOTFOUND:throw new NamespaceNotFoundException(e);case OFFLINE:throw new TableOfflineException(context.getInstance(), Tables.getTableId(context.getInstance(), tableOrNamespaceName));default:throw new AccumuloException(e.description, e);}} catch (Exception e) {throw new AccumuloException(e.getMessage(), e);} finally {Tables.clearCache(context.getInstance());// always finish table op, even when exceptionif (opid != null)try {finishFateOperation(opid);} catch (Exception e) {log.warn(e.getMessage(), e);}}}
在这里可以发现一些奇怪的现象,居然catch了好多Thrift相关的Exception。继续跳转:
// This method is for retrying in the case of network failures; anything else it passes to the caller to deal withprivate void executeFateOperation(long opid, FateOperation op, List<ByteBuffer> args, Map<String,String> opts, boolean autoCleanUp)throws ThriftSecurityException, TException, ThriftTableOperationException {while (true) {MasterClientService.Iface client = null;try {client = MasterClient.getConnectionWithRetry(context);client.executeFateOperation(Tracer.traceInfo(), context.rpcCreds(), opid, op, args, opts, autoCleanUp);break;} catch (TTransportException tte) {log.debug("Failed to call executeFateOperation(), retrying ... ", tte);UtilWaitThread.sleep(100);} finally {MasterClient.close(client);}}}
这个死循环里获取了Client对象。但是这个Client一看就没那么简单。。。调用的executeFateOperation方法还不能直接Idea点开,需要手动定位。
分析client对象
package org.apache.accumulo.core.client.impl;import com.google.common.net.HostAndPort;public class MasterClient {private static final Logger log = LoggerFactory.getLogger(MasterClient.class);public static MasterClientService.Client getConnectionWithRetry(ClientContext context) {while (true) {MasterClientService.Client result = getConnection(context);if (result != null)return result;UtilWaitThread.sleep(250);}}
}
实际上又是这个:
public static class Client extends FateService.Client implements Iface {
}
所以其父类是:
package org.apache.accumulo.core.master.thrift;@SuppressWarnings({"unchecked", "serial", "rawtypes", "unused"}) public class FateService {public interface Iface {public void executeFateOperation(org.apache.accumulo.core.trace.thrift.TInfo tinfo, org.apache.accumulo.core.security.thrift.TCredentials credentials, long opid, FateOperation op, List<ByteBuffer> arguments, Map<String,String> options, boolean autoClean) throws org.apache.accumulo.core.client.impl.thrift.ThriftSecurityException, org.apache.accumulo.core.client.impl.thrift.ThriftTableOperationException, org.apache.thrift.TException;}public void executeFateOperation(org.apache.accumulo.core.trace.thrift.TInfo tinfo, org.apache.accumulo.core.security.thrift.TCredentials credentials, long opid, FateOperation op, List<ByteBuffer> arguments, Map<String,String> options, boolean autoClean) throws org.apache.accumulo.core.client.impl.thrift.ThriftSecurityException, org.apache.accumulo.core.client.impl.thrift.ThriftTableOperationException, org.apache.thrift.TException
{send_executeFateOperation(tinfo, credentials, opid, op, arguments, options, autoClean);recv_executeFateOperation();
}public static class Client extends org.apache.thrift.TServiceClient implements Iface {}
}
所以这种client对象才可以执行executeFateOperation方法。
查看executeFateOperation方法
分为2步,字面意思send_executeFateOperation方法发送了啥,recv_executeFateOperation方法又接收了啥。显然发送消息是需要重点关心的:
public void send_executeFateOperation(org.apache.accumulo.core.trace.thrift.TInfo tinfo, org.apache.accumulo.core.security.thrift.TCredentials credentials, long opid, FateOperation op, List<ByteBuffer> arguments, Map<String,String> options, boolean autoClean) throws org.apache.thrift.TException
{executeFateOperation_args args = new executeFateOperation_args();args.setTinfo(tinfo);args.setCredentials(credentials);args.setOpid(opid);args.setOp(op);args.setArguments(arguments);args.setOptions(options);args.setAutoClean(autoClean);sendBase("executeFateOperation", args);
}
这个发送的方法把入参的表名、操作类型【Drop表】设置为sendBase方法的入参。
package org.apache.thrift;/*** A TServiceClient is used to communicate with a TService implementation* across protocols and transports.*/
public abstract class TServiceClient {protected void sendBase(String methodName, TBase<?,?> args) throws TException {sendBase(methodName, args, TMessageType.CALL);}private void sendBase(String methodName, TBase<?,?> args, byte type) throws TException {oprot_.writeMessageBegin(new TMessage(methodName, type, ++seqid_));args.write(oprot_);oprot_.writeMessageEnd();oprot_.getTransport().flush();}}
其中:
package org.apache.thrift.protocol;/*** Message type constants in the Thrift protocol.**/
public final class TMessageType {public static final byte CALL = 1;public static final byte REPLY = 2;public static final byte EXCEPTION = 3;public static final byte ONEWAY = 4;
}
这个type传入的其实是1。用于构造方法:
package org.apache.thrift.protocol;/*** Helper class that encapsulates struct metadata.**/
public final class TMessage {public TMessage(String n, byte t, int s) {name = n;type = t;seqid = s;}public final String name;public final byte type;public final int seqid;}
另一个泛型TBase:
package org.apache.thrift;import java.io.Serializable;import org.apache.thrift.protocol.TProtocol;/*** Generic base interface for generated Thrift objects.**/
public interface TBase<T extends TBase<?,?>, F extends TFieldIdEnum> extends Comparable<T>, Serializable {/*** Reads the TObject from the given input protocol.** @param iprot Input protocol*/public void read(TProtocol iprot) throws TException;/*** Writes the objects out to the protocol** @param oprot Output protocol*/public void write(TProtocol oprot) throws TException;
}
按照注释可以知道write方法是把Java的对象输出给协议。
而executeFateOperation_args类:
public static class executeFateOperation_args implements org.apache.thrift.TBase<executeFateOperation_args, executeFateOperation_args._Fields>, java.io.Serializable, Cloneable, Comparable<executeFateOperation_args> {
public void write(org.apache.thrift.protocol.TProtocol oprot) throws org.apache.thrift.TException {schemes.get(oprot.getScheme()).getScheme().write(oprot, this);}
}
它的write方法:
package org.apache.thrift.scheme;import org.apache.thrift.TBase;public interface IScheme<T extends TBase> {public void read(org.apache.thrift.protocol.TProtocol iproto, T struct) throws org.apache.thrift.TException;public void write(org.apache.thrift.protocol.TProtocol oproto, T struct) throws org.apache.thrift.TException;}
又是跳转到接口。。。

可以看到有2大抽象类。
而getScheme拿到的:
package org.apache.thrift.protocol;import java.nio.ByteBuffer;import org.apache.thrift.TException;
import org.apache.thrift.scheme.IScheme;
import org.apache.thrift.scheme.StandardScheme;
import org.apache.thrift.transport.TTransport;/*** Protocol interface definition.**/
public abstract class TProtocol {public Class<? extends IScheme> getScheme() {return StandardScheme.class;}public abstract void writeMessageBegin(TMessage message) throws TException;
}
显然get到的是StandardScheme类。而writeMessageBegin又是这个抽象类的抽象方法。
该抽象类的继承关系:

至此可以知道原生支持的协议有这些。最常用的当然就是二进制协议:TBinaryProtocol。
查看TBinaryProtocol二进制协议
package org.apache.thrift.protocol;import java.io.UnsupportedEncodingException;
import java.nio.ByteBuffer;import org.apache.thrift.TException;
import org.apache.thrift.transport.TTransport;/*** Binary protocol implementation for thrift.**/
public class TBinaryProtocol extends TProtocol {public void writeMessageBegin(TMessage message) throws TException {if (strictWrite_) {int version = VERSION_1 | message.type;writeI32(version);writeString(message.name);writeI32(message.seqid);} else {writeString(message.name);writeByte(message.type);writeI32(message.seqid);}}
}
可以看出writeMessageBegin方法就是实际的写数据操作,把消息拆分后写出。
public void writeString(String str) throws TException {try {byte[] dat = str.getBytes("UTF-8");writeI32(dat.length);trans_.write(dat, 0, dat.length);} catch (UnsupportedEncodingException uex) {throw new TException("JVM DOES NOT SUPPORT UTF-8");}
}
以此为例。会去把数据作为字节数组写出:
package org.apache.thrift.transport;import java.io.Closeable;/*** Generic class that encapsulates the I/O layer. This is basically a thin* wrapper around the combined functionality of Java input/output streams.**/
public abstract class TTransport implements Closeable {/*** Reads up to len bytes into buffer buf, starting at offset off.** @param buf Array to read into* @param off Index to start reading at* @param len Maximum number of bytes to read* @return The number of bytes actually read* @throws TTransportException if there was an error reading data*/public abstract int read(byte[] buf, int off, int len)throws TTransportException;/*** Writes up to len bytes from the buffer.** @param buf The output data buffer* @param off The offset to start writing from* @param len The number of bytes to write* @throws TTransportException if there was an error writing data*/public abstract void write(byte[] buf, int off, int len)throws TTransportException;
}
这才是真正的传输对象。其继承关系:

搞过嵌入式开发的一定很熟悉这个Socket!!!就是IP+port的那个Socket。应用层与TCP/IP传输层间的抽象层。。。
查看TIOStreamTransport传输类
package org.apache.thrift.transport;/*** This is the most commonly used base transport. It takes an InputStream* and an OutputStream and uses those to perform all transport operations.* This allows for compatibility with all the nice constructs Java already* has to provide a variety of types of streams.**/
public class TIOStreamTransport extends TTransport {public int read(byte[] buf, int off, int len) throws TTransportException {if (inputStream_ == null) {throw new TTransportException(TTransportException.NOT_OPEN, "Cannot read from null inputStream");}int bytesRead;try {bytesRead = inputStream_.read(buf, off, len);} catch (IOException iox) {throw new TTransportException(TTransportException.UNKNOWN, iox);}if (bytesRead < 0) {throw new TTransportException(TTransportException.END_OF_FILE);}return bytesRead;}/*** Writes to the underlying output stream if not null.*/public void write(byte[] buf, int off, int len) throws TTransportException {if (outputStream_ == null) {throw new TTransportException(TTransportException.NOT_OPEN, "Cannot write to null outputStream");}try {outputStream_.write(buf, off, len);} catch (IOException iox) {throw new TTransportException(TTransportException.UNKNOWN, iox);}}/*** Flushes the underlying output stream if not null.*/public void flush() throws TTransportException {if (outputStream_ == null) {throw new TTransportException(TTransportException.NOT_OPEN, "Cannot flush null outputStream");}try {outputStream_.flush();} catch (IOException iox) {throw new TTransportException(TTransportException.UNKNOWN, iox);}}
}
其子类TSocket重写了IP、Port和init等。
小结Drop表的流程
至此可以得知Java用API操作Hive的原理,大致是这样:
顶层API【dropTable】→表操作实现类【TableOperationsImpl】的删表方法【doTableFateOperation】
→executeFateOperation方法→Client类的实例对象的executeFateOperation方法
→sendBase方法→executeFateOperation_args静态类的实例对象的write方法输出数据给传输协议TProtocol
→传输协议类的write方法具体把数据写出给Thrift的Server
→Thrift的Server接收到消息后执行对应的操作
最出名的Thrift当然是Hive自己的Hive Server【Standalone】和Hive Server2,还有Spark的Thrift Server,借助它们,可以用JDBC或者Cli的方式去操作Hive。
但是!!!Thrift的初衷就是实现语言无关,毕竟底层只需要能把数据传输到位即可,数据传输并不是Java的特权。
其它语言的Thrift

在service-rpc这个路径下,可以发现有cpp、Java、php、py,rb的包!!!
Hive的官方文档写的很明白:
https://cwiki.apache.org/confluence/display/Hive/HiveClient#HiveClient-ThriftJavaClient
The command line client currently only supports an embedded server. The JDBC and Thrift-Java clients support both embedded and standalone servers. Clients in other languages only support standalone servers.
命令行模式目前只能用于嵌入式服务,JDBC和Thrift-Java的Client可以支持嵌入式和独立部署的服务。别的语言的Client只支持在独立部署的服务使用。
Connection con = DriverManager.getConnection("jdbc:hive://localhost:10000/default", "", "");
Statement stmt = con.createStatement();
这种古代的Hive Server就是嵌入模式。。。
Connection con = DriverManager.getConnection("jdbc:hive2://localhost:10000/default", "", "");
这种Hive Server2就是独立部署模式。
官方还给出了python的案例:
#!/usr/bin/env pythonimport sysfrom hive import ThriftHive
from hive.ttypes import HiveServerException
from thrift import Thrift
from thrift.transport import TSocket
from thrift.transport import TTransport
from thrift.protocol import TBinaryProtocoltry:transport = TSocket.TSocket('localhost', 10000)transport = TTransport.TBufferedTransport(transport)protocol = TBinaryProtocol.TBinaryProtocol(transport)client = ThriftHive.Client(protocol)transport.open()client.execute("CREATE TABLE r(a STRING, b INT, c DOUBLE)")client.execute("LOAD TABLE LOCAL INPATH '/path' INTO TABLE r")client.execute("SELECT * FROM r")while (1):row = client.fetchOne()if (row == None):breakprint rowclient.execute("SELECT * FROM r")print client.fetchAll()transport.close()except Thrift.TException, tx:print '%s' % (tx.message)
以及PHP的案例:
<?php
// set THRIFT_ROOT to php directory of the hive distribution
$GLOBALS['THRIFT_ROOT'] = '/lib/php/';
// load the required files for connecting to Hive
require_once $GLOBALS['THRIFT_ROOT'] . 'packages/hive_service/ThriftHive.php';
require_once $GLOBALS['THRIFT_ROOT'] . 'transport/TSocket.php';
require_once $GLOBALS['THRIFT_ROOT'] . 'protocol/TBinaryProtocol.php';
// Set up the transport/protocol/client
$transport = new TSocket('localhost', 10000);
$protocol = new TBinaryProtocol($transport);
$client = new ThriftHiveClient($protocol);
$transport->open();// run queries, metadata calls etc
$client->execute('SELECT * from src');
var_dump($client->fetchAll());
$transport->close();
Ruby好歹也给了个参考: https://github.com/forward3d/rbhive
至于Java、C++就不给Client的案例了。。。也是很容易理解。。。毕竟Java有JDBC和高层API,一般不会有人去用底层API了。
如果是做平台开发或者组件开发这种真正用得上底层API的情况,地方支援中央发型的老Java程序猿,查API填参数让程序跑起来,这点工程能力还是有的。
至于C++程序猿强悍的造轮子功力,没准像临摹Kafka的Red Panda那样,哪天也照猫画虎折腾出个C++版的Hive。。。
既然可以通过Thrift实现语言无关,那么调用组件就不必局限于Java或者Scala。而造轮子从来也不是Java和Scala的专利。
这就是为神马大数据开发可以脱离Java和Scala。
尾言
大数据并不是趋向SQL化,只是为了扩大受众群体,让广大技术水平不高的业务开发人员也能吃上大数据技术的红利。且SQL在处理结构化表的特定场景下开发效率更高。
但是。。。哪怕是这种极度细分的场景,SQL还是有很多缺陷,虽然API的方式也没有好到哪里去。
造轮子和组件调用,就更是语言无关的事情了。。。编程语言往往只是个表达思想的载体,技术栈足够全面才有做选择的权力。
转载请注明出处:https://lizhiyong.blog.csdn.net/article/details/129742904

相关文章:
从Hive源码解读大数据开发为什么可以脱离SQL、Java、Scala
从Hive源码解读大数据开发为什么可以脱离SQL、Java、Scala 前言 【本文适合有一定计算机基础/半年工作经验的读者食用。立个Flg,愿天下不再有肤浅的SQL Boy】 谈到大数据开发,占据绝大多数人口的就是SQL Boy,不接受反驳,毕竟大…...
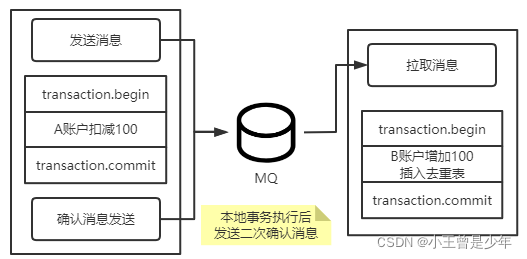
RocketMQ 事务消息 原理及使用方法解析
🍊 Java学习:Java从入门到精通总结 🍊 深入浅出RocketMQ设计思想:深入浅出RocketMQ设计思想 🍊 绝对不一样的职场干货:大厂最佳实践经验指南 📆 最近更新:2023年3月24日 &#x…...

为什么 ChatGPT 输出时经常会中断,需要输入“继续” 才可以继续输出?
作者:明明如月学长, CSDN 博客专家,蚂蚁集团高级 Java 工程师,《性能优化方法论》作者、《解锁大厂思维:剖析《阿里巴巴Java开发手册》》、《再学经典:《EffectiveJava》独家解析》专栏作者。 热门文章推荐…...

PyTorch 之 基于经典网络架构训练图像分类模型
文章目录一、 模块简单介绍1. 数据预处理部分2. 网络模块设置3. 网络模型保存与测试二、数据读取与预处理操作1. 制作数据源2. 读取标签对应的实际名字3. 展示数据三、模型构建与实现1. 加载 models 中提供的模型,并且直接用训练的好权重当做初始化参数2. 参考 pyto…...

Scrapy的callback进入不了回调方法
一、前言 有的时候,Scrapy的callback方法直接被略过了,不去执行其中的回调方法,可能排查好久都排查不出来,我来教大家集中解决方法。 yield Request(urlurl, callbackself.parse_detail, cb_kwargs{item: item})二、解决方法 1…...

第二十一天 数据库开发-MySQL
目录 数据库开发-MySQL 前言 1. MySQL概述 1.1 安装 1.2 数据模型 1.3 SQL介绍 1.4 项目开发流程 2. 数据库设计-DDL 2.1 数据库操作 2.2 图形化工具 2.3 表操作 3. 数据库操作-DML 3.1 增加(insert) 3.2 修改(update) 3.3 删除(delete) 数据库开发-MySQL 前言 …...

蓝桥杯每日一真题—— [蓝桥杯 2021 省 AB2] 完全平方数(数论,质因数分解)
文章目录[蓝桥杯 2021 省 AB2] 完全平方数题目描述输入格式输出格式样例 #1样例输入 #1样例输出 #1样例 #2样例输入 #2样例输出 #2提示思路:理论补充:完全平方数的一个性质:完全平方数的质因子的指数一定为偶数最终思路:小插曲&am…...
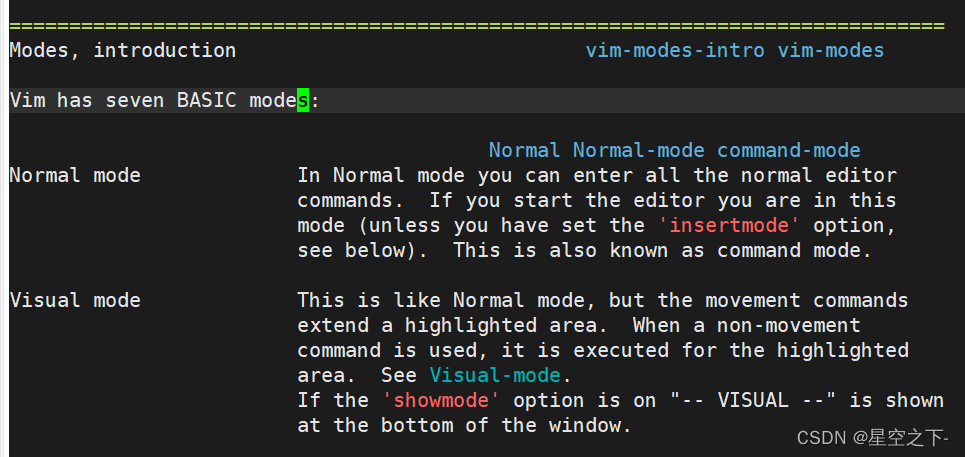
Linux编辑器-vim
一、vim简述1)vi/vim2)检查vim是否安装2)如何用vim打开文件3)vim的几种模式命令模式插入模式末行模式可视化模式二、vim的基本操作1)进入vim(命令行模式)2)[命令行模式]切换至[插入模式]3)[插入模式]切换至[命令行模式]4)[命令行模…...
5G将在五方面彻底改变制造业
想象一下这样一个未来,智能机器人通过在工厂车间重新配置自己,从多条生产线上组装产品。安全无人机处理着从监视入侵者到确认员工停车等繁琐的任务。自动驾驶汽车不仅可以在建筑物之间运输零部件,还可以在全国各地运输。工厂检查可以在千里之…...

http和https的区别?
http和https的区别?HTTPHTTPSHTTP与HTTPS区别HTTPS相比于HTTP协议的优点和缺点HTTP http是超文本传输协议 HTTP协议是基于传输层的TCP协议进行通信,通用无状态的协议。80端口 HTTPS https—安全的超文本传输协议 是以安全为目标的HTTP通道,…...
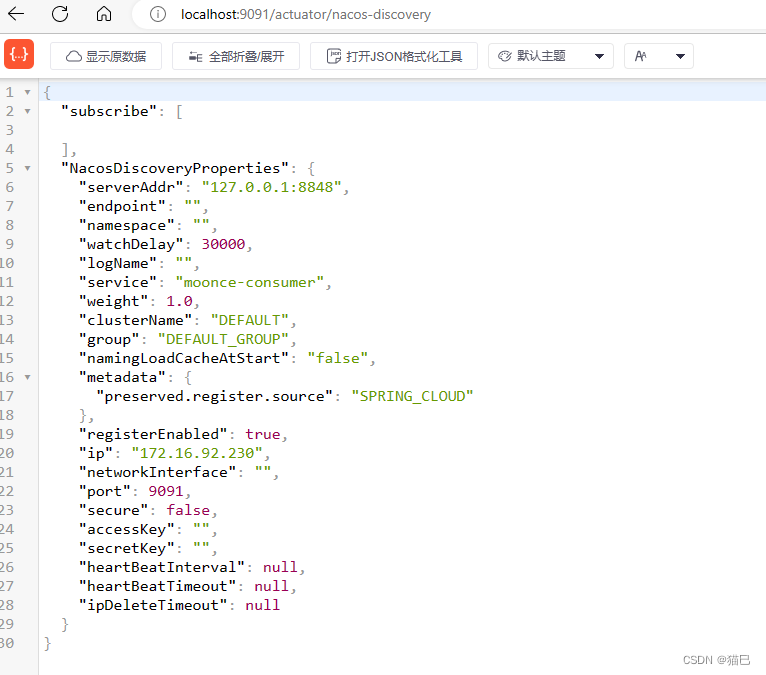
【Spring Cloud Alibaba】4.创建服务消费者
文章目录简介开始搭建创建项目修改POM文件添加启动类添加配置项添加Controller添加配置文件启动项目测试访问Nacos访问接口查看端点检查简介 接下来我们创建一个服务消费者,本操作先要完成之前的步骤,详情请参照【Spring Cloud Alibaba】Spring Cloud A…...
C语言——动态内存管理 malloc、calloc、realloc、free的使用
目录 一、为什么存在动态内存分配 二、动态内存函数的介绍 2.1malloc和free 2.2calloc 2.3realloc 三、常见的动态内存错误 3.1对NULL指针的解引用操作 3.2对动态开辟空间的越界访问 3.3对非动态开辟的内存使用free释放 3.4使用free释放一块动态开辟内存的一部分 3.5…...

技术分享——Java8新特性
技术分享——Java8新特性1.背景2. 新特性主要内容3. Lambda表达式4. 四大内置核心函数式接口4.1 Consumer<T>消费型接口4.2 Supplier<T>供给型接口4.3 Function<T,R>函数型接口4.4 Predicate<T> 断定型接口5. Stream流操作5.1 什么是流以及流的类型5.2…...

vue基础知识大全
1,指令作用 以v-开头,由vue提供的attribute,为渲染DOM应用提供特殊的响应式行为,也即是在表达式的值发生变化的时候响应式的更新DOM。其内容为可以被求值的js代码,可以写在return后面被返回的表达式。 指令的简写指令简…...
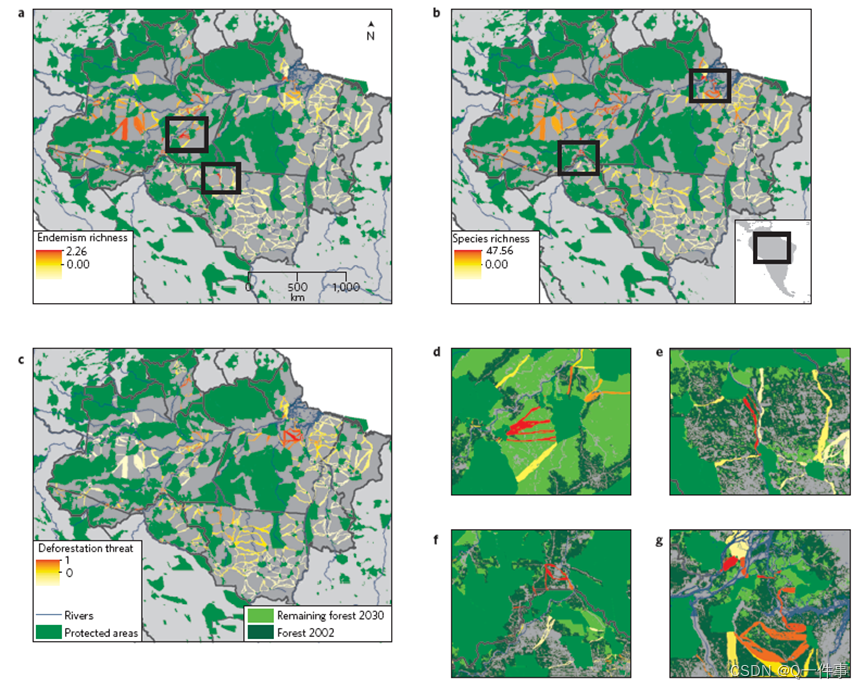
第2篇|文献研读|nature climate change|减缓气候变化和促进热带生物多样性的碳储量走廊
研究背景 从 2000 年到 2012 年,潮湿和干燥热带地区的森林总损失超过 90,000 平方公里 yr-1,这主要是由农业扩张驱动的。热带森林砍伐向大气中排放 0:95 Pg C yr-1 并导致广泛的生物多样性丧失。保护区的生物多样性取决于与保护区所在的更广泛景观的生态…...

从暴力递归到动态规划(2)小乖,你也在为转移方程而烦恼吗?
前引:继上篇我们讲到暴力递归的过程,这一篇blog我们将继续对从暴力递归到动态规划的实现过程,与上篇类似,我们依然采用题目的方式对其转化过程进行论述。上篇博客:https://blog.csdn.net/m0_65431718/article/details/…...

Leetcode.1638 统计只差一个字符的子串数目
题目链接 Leetcode.1638 统计只差一个字符的子串数目 Rating : 1745 题目描述 给你两个字符串 s和 t,请你找出 s中的非空子串的数目,这些子串满足替换 一个不同字符 以后,是 t串的子串。换言之,请你找到 s和 t串中 恰…...
KoTime:v2.3.9新增线程管理(线程统计、状态查询等)
功能概览 KoTime的开源版本已经迭代到了V2.3.9,目前功能如下: 实时监听方法,统计运行时长web展示方法调用链路,瓶颈可视化追踪追踪系统异常,精确定位到方法接口超时邮件通知,无需实时查看线上热更新&…...

直面风口,未来不仅是中文版ChatGPT,还有AGI大时代在等着我们
说到标题的AI2.0这个概念的研究早在2015年就研究起步了,其实大家早已知道,人工智能技术必然是未来科技发展战略中的重要一环,今天我们就从AI2.0入手,以GPT-4及文心一言的发布为切入角度,来谈一谈即将降临的AGI时代。 关…...
若依微服务(ruoyi-cloud)保姆版容器编排运行
一、简介 项目gitee地址:https://gitee.com/y_project/RuoYi-Cloud 由于该项目运行有很多坑,大家可以在git克隆拷贝到本地后,执行下面的命令使master版本回退到本篇博客的版本: git reset --hard 05ca78e82fb4e074760156359d09a…...

挑战杯推荐项目
“人工智能”创意赛 - 智能艺术创作助手:借助大模型技术,开发能根据用户输入的主题、风格等要求,生成绘画、音乐、文学作品等多种形式艺术创作灵感或初稿的应用,帮助艺术家和创意爱好者激发创意、提高创作效率。 - 个性化梦境…...

SkyWalking 10.2.0 SWCK 配置过程
SkyWalking 10.2.0 & SWCK 配置过程 skywalking oap-server & ui 使用Docker安装在K8S集群以外,K8S集群中的微服务使用initContainer按命名空间将skywalking-java-agent注入到业务容器中。 SWCK有整套的解决方案,全安装在K8S群集中。 具体可参…...

模型参数、模型存储精度、参数与显存
模型参数量衡量单位 M:百万(Million) B:十亿(Billion) 1 B 1000 M 1B 1000M 1B1000M 参数存储精度 模型参数是固定的,但是一个参数所表示多少字节不一定,需要看这个参数以什么…...

MongoDB学习和应用(高效的非关系型数据库)
一丶 MongoDB简介 对于社交类软件的功能,我们需要对它的功能特点进行分析: 数据量会随着用户数增大而增大读多写少价值较低非好友看不到其动态信息地理位置的查询… 针对以上特点进行分析各大存储工具: mysql:关系型数据库&am…...

【Redis技术进阶之路】「原理分析系列开篇」分析客户端和服务端网络诵信交互实现(服务端执行命令请求的过程 - 初始化服务器)
服务端执行命令请求的过程 【专栏简介】【技术大纲】【专栏目标】【目标人群】1. Redis爱好者与社区成员2. 后端开发和系统架构师3. 计算机专业的本科生及研究生 初始化服务器1. 初始化服务器状态结构初始化RedisServer变量 2. 加载相关系统配置和用户配置参数定制化配置参数案…...

定时器任务——若依源码分析
分析util包下面的工具类schedule utils: ScheduleUtils 是若依中用于与 Quartz 框架交互的工具类,封装了定时任务的 创建、更新、暂停、删除等核心逻辑。 createScheduleJob createScheduleJob 用于将任务注册到 Quartz,先构建任务的 JobD…...

拉力测试cuda pytorch 把 4070显卡拉满
import torch import timedef stress_test_gpu(matrix_size16384, duration300):"""对GPU进行压力测试,通过持续的矩阵乘法来最大化GPU利用率参数:matrix_size: 矩阵维度大小,增大可提高计算复杂度duration: 测试持续时间(秒&…...

实现弹窗随键盘上移居中
实现弹窗随键盘上移的核心思路 在Android中,可以通过监听键盘的显示和隐藏事件,动态调整弹窗的位置。关键点在于获取键盘高度,并计算剩余屏幕空间以重新定位弹窗。 // 在Activity或Fragment中设置键盘监听 val rootView findViewById<V…...
-HIve数据分析)
大数据学习(132)-HIve数据分析
🍋🍋大数据学习🍋🍋 🔥系列专栏: 👑哲学语录: 用力所能及,改变世界。 💖如果觉得博主的文章还不错的话,请点赞👍收藏⭐️留言Ǵ…...

项目部署到Linux上时遇到的错误(Redis,MySQL,无法正确连接,地址占用问题)
Redis无法正确连接 在运行jar包时出现了这样的错误 查询得知问题核心在于Redis连接失败,具体原因是客户端发送了密码认证请求,但Redis服务器未设置密码 1.为Redis设置密码(匹配客户端配置) 步骤: 1).修…...