FastAPI部署大模型Llama 3.1
项目地址:[self-llm/models/Llama3_1/01-Llama3_1-8B-Instruct FastApi 部署调用.md at master · datawhalechina/self-llm (github.com)](https://github.com/datawhalechina/self-llm/blob/master/models/Llama3_1/01-Llama3_1-8B-Instruct FastApi 部署调用.md)
目的:使用AutoDL的深度学习环境,简单部署大模型
## 环境准备
考虑到部分同学配置环境可能会遇到一些问题,我们在AutoDL平台准备了LLaMA3-1的环境镜像,点击下方链接并直接创建Autodl示例即可。 ***https://www.codewithgpu.com/i/datawhalechina/self-llm/self-llm-llama3.1***
首先 `pip` 换源加速下载并安装依赖包
```
# 升级pip
python -m pip install --upgrade pip
# 更换 pypi 源加速库的安装
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
pip install fastapi==0.111.1
pip install uvicorn==0.30.3
pip install modelscope==1.16.1
pip install transformers==4.42.4
pip install accelerate==0.32.1
```
## 模型下载
模型下载社区有魔塔和huggingface(被墙,可能不能使用),所以同意使用魔塔社区的方式下载模型
新建 `model_download.py` 文件并在其中输入以下内容,粘贴代码后请及时保存文件,如下图所示。并运行 `python model_download.py` 执行下载,模型大小为 15GB,下载模型大概需要15 分钟。
```python
import torch
from modelscope import snapshot_download, AutoModel, AutoTokenizer
import os
model_dir = snapshot_download('LLM-Research/Meta-Llama-3.1-8B-Instruct', cache_dir='/root/autodl-tmp', revision='master')
```

> 注意:如果模型下载失败,可以多试几次:运行 `python model_download.py`
## API部署代码
新建 `api.py` 文件并在其中输入以下内容,粘贴代码后请及时保存文件(Ctrl+`s`)。以下代码有很详细的注释
```
from fastapi import FastAPI, Request
from transformers import AutoTokenizer, AutoModelForCausalLM
import uvicorn
import json
import datetime
import torch
# 设置设备参数
DEVICE = "cuda" # 使用CUDA
DEVICE_ID = "0" # CUDA设备ID,如果未设置则为空
CUDA_DEVICE = f"{DEVICE}:{DEVICE_ID}" if DEVICE_ID else DEVICE # 组合CUDA设备信息
# 清理GPU内存函数
def torch_gc():
if torch.cuda.is_available(): # 检查是否可用CUDA
with torch.cuda.device(CUDA_DEVICE): # 指定CUDA设备
torch.cuda.empty_cache() # 清空CUDA缓存
torch.cuda.ipc_collect() # 收集CUDA内存碎片
# 创建FastAPI应用
app = FastAPI()
# 处理POST请求的端点
@app.post("/")
async def create_item(request: Request):
global model, tokenizer # 声明全局变量以便在函数内部使用模型和分词器
json_post_raw = await request.json() # 获取POST请求的JSON数据
json_post = json.dumps(json_post_raw) # 将JSON数据转换为字符串
json_post_list = json.loads(json_post) # 将字符串转换为Python对象
prompt = json_post_list.get('prompt') # 获取请求中的提示
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
]
# 调用模型进行对话生成
input_ids = tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True)
model_inputs = tokenizer([input_ids], return_tensors="pt").to('cuda')
generated_ids = model.generate(model_inputs.input_ids,max_new_tokens=512)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
now = datetime.datetime.now() # 获取当前时间
time = now.strftime("%Y-%m-%d %H:%M:%S") # 格式化时间为字符串
# 构建响应JSON
answer = {
"response": response,
"status": 200,
"time": time
}
# 构建日志信息
log = "[" + time + "] " + '", prompt:"' + prompt + '", response:"' + repr(response) + '"'
print(log) # 打印日志
torch_gc() # 执行GPU内存清理
return answer # 返回响应
# 主函数入口
if __name__ == '__main__':
# 加载预训练的分词器和模型
model_name_or_path = '/root/autodl-tmp/LLM-Research/Meta-Llama-3___1-8B-Instruct'
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, use_fast=False)
model = AutoModelForCausalLM.from_pretrained(model_name_or_path, device_map="auto", torch_dtype=torch.bfloat16)
# 启动FastAPI应用
# 用6006端口可以将autodl的端口映射到本地,从而在本地使用api
uvicorn.run(app, host='0.0.0.0', port=6006, workers=1) # 在指定端口和主机上启动应用
```
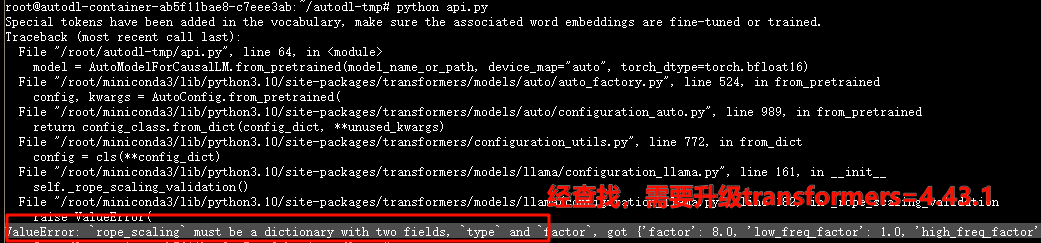
运行以上代码 `python api.py`
> 如果遇到以下bug:需要`pip install transformers==4.43.1`
## 部署测试
在终端输入以下命令启动api服务:
```
python api.py
```
加载完毕后出现如下信息说明成功。
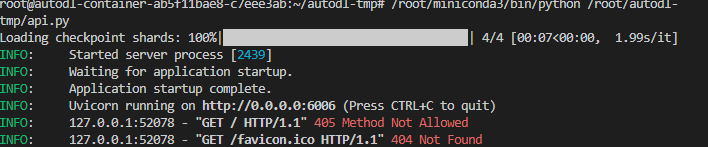
默认部署在 6006 端口,通过 POST 方法进行调用,可以使用 curl 调用,如下所示:

- `curl`: 这是命令行工具的名字,用于从服务器获取或发送数据。
- `-X POST`: 这个选项指定了请求类型为 `POST`。`POST` 请求通常用于向服务器发送数据。
- `"http://127.0.0.1:6006"`: 这是请求的目标 URL。`127.0.0.1` 是本地回环地址,意味着请求将被发送到同一台计算机上运行的服务。`6006` 是服务监听的端口号。
- `-H 'Content-Type: application/json'`: 这个选项设置了请求头 (`Header`) 中的 `Content-Type` 字段为 `application/json`。这告诉服务器发送的数据是 JSON 格式。
- `-d '{"prompt": "你好"}'`: 这个选项指定了要发送的数据体 (`Body`)。在这里,数据是一个 JSON 对象,其中包含一个键值对,键是 `"prompt"`,值是 `"你好"`。这个数据体将作为请求的一部分发送给服务器。
也可以使用 python 中的 requests 库进行调用,我们新建一个test.ibynb文件,复制如下代码,按`Enter+Shift`运行代码。
```
import requests
import json
def get_completion(prompt):
headers = {'Content-Type': 'application/json'}
data = {"prompt": prompt}
response = requests.post(url='http://127.0.0.1:6006', headers=headers, data=json.dumps(data))
return response.json()['response']
if __name__ == '__main__':
print(get_completion('我写了一篇文章:FastAPI部署大模型Llama3.1。你帮我写一段总结,100字以内'))
```
输出结果如下:

**部署大模型Llama 3.1 到 FastAPI**
本文介绍了如何将大模型Llama 3.1 部署到 FastAPI,一个现代、快速、强大的 Python web 框架。通过本教程,你将学习如何将 Llama 3.1 集成到 FastAPI 中,并利用其强大的自然语言处理能力来构建智能应用。
本文涵盖了以下内容:
* 安装和设置 FastAPI
* 下载和部署 Llama 3.1 模型
* 使用 FastAPI 与 Llama 3.1 进行交互
本教程适合任何对 AI 和机器学习感兴趣的开发者。
相关文章:

FastAPI部署大模型Llama 3.1
项目地址:[self-llm/models/Llama3_1/01-Llama3_1-8B-Instruct FastApi 部署调用.md at master datawhalechina/self-llm (github.com)](https://github.com/datawhalechina/self-llm/blob/master/models/Llama3_1/01-Llama3_1-8B-Instruct FastApi 部署调用.md) …...

C++拾趣——编译器预处理宏__COUNTER__的应用场景
大纲 生成唯一标识符调试信息宏展开模板元编程代码 在C中,__COUNTER__是一个特殊的预处理宏,它主要被用来生成唯一的整数标识符。这个宏是由一些编译器(如GCC和Visual Studio)内置支持的,而不是C标准的一部分。它的主要…...

使用HTML和cgi实现网页登录功能
0.HTML文件结构 一.HTML文件 1.test.html <!DOCTYPE html> <html><head><meta charset"utf-8"><title>菜鸟教程(runoob.com)</title></head><body><!-- 将结果提交给/cgi-bin/test.cgi下 --><form actio…...
Java流程控制01:用户交互Scanner
本节教学视频链接:https://www.bilibili.com/video/BV12J41137hu?p33&vd_sourceb5775c3a4ea16a5306db9c7c1c1486b5https://www.bilibili.com/video/BV12J41137hu?p33&vd_sourceb5775c3a4ea16a5306db9c7c1c1486b5 Scanner 类用于扫描输入文本从字符串中提…...

什么是回滚
回滚(Rollback)是指当程序或数据出现错误时,将程序或数据恢复到最近一个正确版本或上一次正确状态的行为。回滚机制在软件开发、数据库管理、系统部署等多个领域都有广泛应用,旨在保证系统的稳定性和数据的完整性。以下是关于回滚…...

Java项目通过IDEA远程debug调试
前言 在我们真实项目开发过程中,又是经常会发现一种问题,就是我们在开发环境功能是正常的,在测试环境可能也不太容易发现问题。 结果到了生产环境,由于数据量大,且数据类型变多后,就产生了一些比较难复现…...

Python 绘图入门
数据可视化的概念及意义 数据可视化有着久远的历史,最早可以追溯至10世纪,至今已经应用和发展了数百年。不知名的天文学家是已知的最早尝试以图形方式显示全年当中太阳,月亮和行星的位置变化的图。 图1 数据可视化的发展历程 什么是数据可视…...
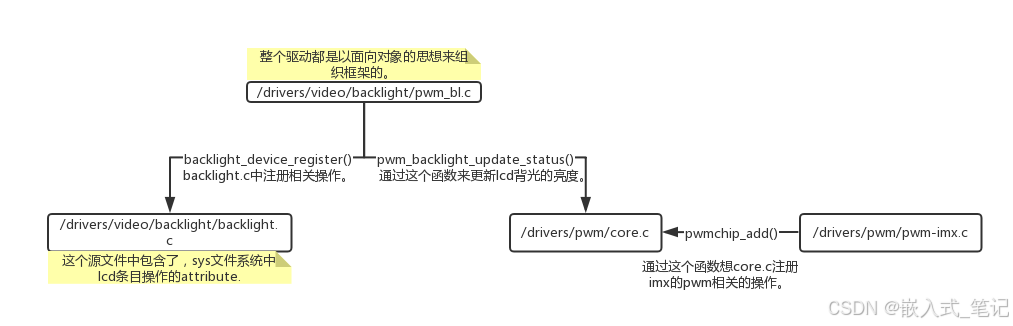
RK3568平台(背光篇)背光驱动代码分析
一.背光驱动设备树DTS backlight: backlight {compatible "pwm-backlight";pwms <&pwm1 0 5555555 1>;brightness-levels <77 77 78 78 79 79 80 8182 83 84 85 86 87 87 8888 89 90 90 91 91 92 9394 94 95 95 96 96 9…...

华为od统一考试B卷【比赛】python实现
def split_params(param_str): return list(map(int, param_str.split(,))) def main(): # 获取输入 target_str input().strip() # 输入验证,拆分并转换为整数 try: m, n split_params(target_str) except ValueError: print(-1) return # 检查 M 和 …...

Prometheus 监控接入规范
目录 一、目的 二、自定义监控指标定义规范 2.1 基本命名规范 2.1.1 指标命名规范 2.1.2 标签名称 2.2 控制基数 2.2.1 避免高基数标签 2.2.2 预定义标签集 2.2.3 动态数据的处理 2.2.4 评估与监控基数 2.2.5 降低历史数据的保留 2.2.6 适当使用 Histogram 和 Summa…...

优化 SQL 查询性能:深入理解 EXPLAIN 命令
优化 SQL 查询性能:深入理解 EXPLAIN 命令 在 MySQL 数据库管理中,优化 SQL 查询性能是确保高效数据处理的关键。EXPLAIN 命令是分析和优化 SQL 查询的强大工具,它帮助我们理解查询执行计划,从而找到性能瓶颈并进行优化。本文将详细解释 EXPLAIN 命令返回的各个列的含义,…...

@Mapper报红
检查pom.xml,导入 org.mybatis.spring.boot 依赖: <dependency><groupId>org.mybatis.spring.boot</groupId><artifactId>mybatis-spring-boot-starter</artifactId><version>3.0.3</version></dependency…...

shell综合小实验1-----查看系统硬件信息
echo命令的使用 1:echo -n 不换行 echo -n “我是个大聪明” #不换行输入我是大聪明 2:echo -e 开启颜色 echo -e "\03335m我是大聪明\033[0m" #用35m这种颜色输出我是大聪明然后关闭颜色显示, 30多是字体颜色,40多是…...

【过程管理】项目需求管理规程(Word原件)
在软件开发的过程中,开发人员与用户之间往往忽视有效的信息沟通,这常常导致开发出的软件无法满足用户的实际需求,进而引发不必要的返工。返工不仅为开发人员带来技术上的困扰,增加了人力和物力的消耗,还会对软件的整体…...

C# 不使用 `async` 和 `await` 的常见场景
虽然 async 和 await 是强大的异步编程工具,但在某些情况下,不使用它们可能更合适。以下是一些不使用 async 和 await 的常见场景: 方法是完全同步的: 如果方法中的所有操作都是同步的,并且没有异步调用,则…...

adb目录笔记《adb更新、进入开发者模式,adb查询packages、adb开启应用,查询进程、强制删除进程》
1.sideload模式 在需要安卓没有root权限的时候,可以使用adb reboot sideload命令进入sideload模式,之后运行对应文件 adb reboot sideload adb sideload <root.zip> 2.packages包查询、运行、删除 在需要查看安卓中packages包的名称时…...

VS2022 C++ EasyX EGE 吃豆人升级版
我是可爱的C小盆友(不要脸了),嘻嘻,等了这么久,吃豆人终于升级啦! 更新日志: 1.修复奇奇怪怪的bug 2.把敌人AI增强了一(hen)点(duo) 3.加入了…...

计算机图形学 | 动画模拟
动画模拟 布料模拟 质点弹簧系统: 红色部分很弱地阻挡对折 Steep connection FEM:有限元方法 粒子系统 粒子系统本质上就是在定义个体和群体的关系。 动画帧率 VR游戏要不晕需要达到90fps Forward Kinematics Inverse Kinematics 只告诉末端p点,中间…...

B2.3 Arm 内存模型定义
B2.3 Arm 内存模型定义 Arm 内存模型引入了以下几种关系: 内在关系 :例如,内在数据/控制/顺序依赖关系和内在翻译之前的关系,这些是源自指令语义的硬件要求。 之后关系 :例如,之后的连贯性和 TLB 之后的关系,这些关系在特定执行中发生这种方式,但在不同的执行中可以以…...

(javaweb)SpringBootWeb案例(毕业设计)案例--部门管理
目录 1.准备工作 2.部门管理--查询功能 3.前后端联调 3.部门管理--新增功能 1.准备工作 mapper数据访问层相当于dao层 根据页面原型和需求分析出接口文档--前后端必须遵循这种规范 大部分情况下 接口文档由后端人员来编写 前后端进行交互基于restful风格接口 http的请求方式…...
详解)
后进先出(LIFO)详解
LIFO 是 Last In, First Out 的缩写,中文译为后进先出。这是一种数据结构的工作原则,类似于一摞盘子或一叠书本: 最后放进去的元素最先出来 -想象往筒状容器里放盘子: (1)你放进的最后一个盘子(…...

css实现圆环展示百分比,根据值动态展示所占比例
代码如下 <view class""><view class"circle-chart"><view v-if"!!num" class"pie-item" :style"{background: conic-gradient(var(--one-color) 0%,#E9E6F1 ${num}%),}"></view><view v-else …...

【OSG学习笔记】Day 18: 碰撞检测与物理交互
物理引擎(Physics Engine) 物理引擎 是一种通过计算机模拟物理规律(如力学、碰撞、重力、流体动力学等)的软件工具或库。 它的核心目标是在虚拟环境中逼真地模拟物体的运动和交互,广泛应用于 游戏开发、动画制作、虚…...

K8S认证|CKS题库+答案| 11. AppArmor
目录 11. AppArmor 免费获取并激活 CKA_v1.31_模拟系统 题目 开始操作: 1)、切换集群 2)、切换节点 3)、切换到 apparmor 的目录 4)、执行 apparmor 策略模块 5)、修改 pod 文件 6)、…...

关于nvm与node.js
1 安装nvm 安装过程中手动修改 nvm的安装路径, 以及修改 通过nvm安装node后正在使用的node的存放目录【这句话可能难以理解,但接着往下看你就了然了】 2 修改nvm中settings.txt文件配置 nvm安装成功后,通常在该文件中会出现以下配置&…...

【Redis技术进阶之路】「原理分析系列开篇」分析客户端和服务端网络诵信交互实现(服务端执行命令请求的过程 - 初始化服务器)
服务端执行命令请求的过程 【专栏简介】【技术大纲】【专栏目标】【目标人群】1. Redis爱好者与社区成员2. 后端开发和系统架构师3. 计算机专业的本科生及研究生 初始化服务器1. 初始化服务器状态结构初始化RedisServer变量 2. 加载相关系统配置和用户配置参数定制化配置参数案…...

测试markdown--肇兴
day1: 1、去程:7:04 --11:32高铁 高铁右转上售票大厅2楼,穿过候车厅下一楼,上大巴车 ¥10/人 **2、到达:**12点多到达寨子,买门票,美团/抖音:¥78人 3、中饭&a…...

五年级数学知识边界总结思考-下册
目录 一、背景二、过程1.观察物体小学五年级下册“观察物体”知识点详解:由来、作用与意义**一、知识点核心内容****二、知识点的由来:从生活实践到数学抽象****三、知识的作用:解决实际问题的工具****四、学习的意义:培养核心素养…...

新能源汽车智慧充电桩管理方案:新能源充电桩散热问题及消防安全监管方案
随着新能源汽车的快速普及,充电桩作为核心配套设施,其安全性与可靠性备受关注。然而,在高温、高负荷运行环境下,充电桩的散热问题与消防安全隐患日益凸显,成为制约行业发展的关键瓶颈。 如何通过智慧化管理手段优化散…...

Rust 异步编程
Rust 异步编程 引言 Rust 是一种系统编程语言,以其高性能、安全性以及零成本抽象而著称。在多核处理器成为主流的今天,异步编程成为了一种提高应用性能、优化资源利用的有效手段。本文将深入探讨 Rust 异步编程的核心概念、常用库以及最佳实践。 异步编程基础 什么是异步…...