【C++深度探索】unordered_set、unordered_map封装


文章目录
- 前言
- 1. unordered_set和unordered_map介绍
- ✨unordered_map介绍
- ✨unordered_set介绍
- 2. 修改哈希表
- 3. 迭代器
- ✨const迭代器
- 4. unordered_map的[]访问
- 5. unordered_set和unordered_map封装
- ✨修改后的哈希表
- ✨unordered_map类
- ✨unordered_set类
- 6. 结语
前言
前面我们学习过红黑树实现map、set的封装,而unordered_set和unordered_map的功能与map和set类似,所不同的是其存储元素是无序的,底层是使用哈希表,所以今天我们就可以利用之前学习过的哈希表的实现,来对C++STL库中的unordered_set和unordered_map进行模拟实现。
1. unordered_set和unordered_map介绍
在C++98中,STL提供了底层为红黑树结构的一系列关联式容器,例如:map、set。在查询时效率可达到 l o g 2 N log_2 N log2N,即最差情况下需要比较红黑树的高度次,当树中的节点非常多时,查询效率也不理想。最好的查询是,进行很少的比较次数就能够将元素找到,因此在C++11中,STL又提供了4个unordered系列的关联式容器,这四个容器与红黑树结构的关联式容器使用方式基本类似,只是其底层结构不同。
✨unordered_map介绍
介绍文档,点击跳转
- unordered_map是存储<key, value>键值对的关联式容器,其允许通过key快速的索引到与其对应的value。
- 在unordered_map中,键值通常用于惟一地标识元素,而映射值是一个对象,其内容与此键关联。键和映射值的类型可能不同。
- 在内部,unordered_map没有对<kye, value>按照任何特定的顺序排序, 为了能在常数范围内找到key所对应的value,unordered_map将相同哈希值的键值对放在相同的桶中。
- unordered_map容器通过key访问单个元素要比map快,但它通常在遍历元素子集的范围迭代方面效率较低。
- unordered_maps实现了直接访问操作符(operator[]),它允许使用key作为参数直接访问value。
unordered_map和map核心功能重复90%,它们区别在于:
- 对键值对中key要求不同:
- map:key要支持比较大小
- unordered_map:key要支持转换成整型+比较相等
- map遍历有序,unordered_map遍历无序
- map有双向迭代器,unordered_map单向迭代器
- 它们之间性能有差异
unordered_map常见接口:
| 函数声明 | 功能介绍 |
|---|---|
| unordered_map() | 构造不同格式的unordered_map对象 |
| bool empty() const | 检测unordered_map是否为空 |
| size_t size() const | 获取unordered_map的有效元素个数 |
| begin | 返回unordered_map第一个元素的迭代器 |
| end | 返回unordered_map最后一个元素下一个位置的迭代器 |
| cbegin | 返回unordered_map第一个元素的const迭代器 |
| cend | 返回unordered_map最后一个元素下一个位置的const迭代器 |
| operator[] | 返回与key对应的value |
| iterator find(const K& key) | 返回key在哈希桶中的位置 |
| size_t count(const K& key) | 返回哈希桶中关键码为key的键值对的个数 |
| insert | 向容器中插入键值对 |
| erase | 删除容器中的键值对 |
| void clear() | 清空容器中有效元素个数 |
| void swap(unordered_map&) | 交换两个容器中的元素 |
| size_t bucket_count()const | 返回哈希桶中桶的总个数 |
| size_t bucket_size(size_t n)const | 返回n号桶中有效元素的总个数 |
| size_t bucket(const K& key) | 返回元素key所在的桶号 |
注意:operator[]函数中实际调用哈希桶的插入操作,用参数key与V()构造一个默认值往底层哈希桶中插入,如果key不在哈希桶中,插入成功,返回V(),插入失败,说明key已经在哈希桶中,将key对应的value返回。这与之前的map类似,插入函数返回一个键值对,键存放指针,对存放bool值,用来判断是否插入成功。
✨unordered_set介绍
文档介绍,点击跳转
unordered_set与unordered_map类似,不同在于前者储存单个数据,后者储存键值对,这里就不过多介绍。
2. 修改哈希表
因为我们要使用哈希表来实现对unordered_set和unordered_map的封装,之前实现的哈希表都是插入键值对,是没办法很好封装unordered_set的,所以我们先得对哈希表进行改造,改造类似于使用红黑树封装map和set对红黑树的改造,具体实现如下:
我们之前模拟实现过哈希表,插入的节点是键值对
pair类型,而如果要使用哈希表来对unordered_set和unordered_map封装的话,unordered_set存储的应该是单个值,而不是键值对,所以我们就需要对哈希表进行修改,使得unordered_set和unordered_map都能适用:
- 首先哈希表存储节点的类需要从只能存储键值对改为能够存储任意数据:
- 修改前:
template<class K,class V>
struct HashNode
{pair<K, V> _kv;HashNode<K, V>* _next;HashNode(const pair<K, V>& kv):_kv(kv), _next(nullptr){}
};
- 修改后:
template<class T>
struct HashNode
{T _data;HashNode<T>* _next;HashNode(const T& data):_data(data), _next(nullptr){}
};- 相应的,哈希表的模板参数也需要修改:
- 修改前:
//哈希表类
template<class K,class V, class Hash = HashFunc<K>>
class HashTable {
public:typedef HashNode<K,V> Node;Node* Find(const K& key);//查找函数private:vector<Node*> _tables;size_t _n;//记录存储数据个数
};
因为节点类只有一个模板参数了,所以哈希表前面两个模板参数有点多余,但是如果将哈希表的模板参数也改为一个,如下面代码所示:
//哈希表
template<class T,class Hash = HashFunc<T>>
class HashTable
{
public:typedef HashNode<T> Node;Node* Find(const T& key);//?查找函数private:vector<Node*> _tables;size_t _n;//记录存储数据个数
}; 那么对于class Hash这个模板参数不可能也传入一个键值对,此外在实现查找上面代码中的Find函数时,对于unordered_map查找时Find函数参数就得传一个完整的键值对,我们不可能把完整的键值对全部传过去查找,这样查找就没有意义,我们只需要获得键值对的键查找到相应的键值对即可,所以我们还应该传一个模板参数用于传给class Hash、Find和Erase函数:
//哈希表
template<class K,class T,class Hash = HashFunc<K>>//K存储键,T存储键值对
class HashTable
{
public:typedef HashNode<T> Node;//传入键值对Node* Find(const K& key);//查找函数,只传键pair<Node*,bool> Insert(const T& data);//插入,传入Tbool Erase(const K& key);//删除,只传键
private:vector<Node*> _tables;size_t _n;//记录存储数据个数
};
这样对于不同函数的需求就可以传入不同的模板参数了🥳🥳
如果是unordered_map存储的是键值对,我们就可以往哈希表的两个模板参数中传入一个键和一个键值对:
//unordered_map类
template<class K,class V>
class unordered_map {
public:
private:HashTable<K, pair<K,V>> _ht;
};
这样哈希表的第一个模板参数帮助我们解决仿函数传参、查找和删除函数传参的问题,第二个则是必须的,除了存储数据外,插入等函数也需要第二个模板参数
如果是unordered_set存储的不是键值对,我们也可以复用上面的代码,传入两个一样的参数即可:
//unordered_set类
template<class K>
class unordered_set {
public:
private:HashTable<K, K> _ht;
};
虽然
unordered_set看起来传了两个一模一样的参数是无意义的,但是这样就可以实现对哈希表的复用,不用单独为了unordered_set再写一个哈希表了,如下图所示:

- 插入函数的参数也得从键值对改为任意数据:
bool Insert(const T& data)//之前:bool Insert(const pair<K, V>& data)
除此以外,我们在寻找插入的位置时不可避免需要通过节点中存储的_data使用哈希函数来获取插入的位置:
//通过Hash函数找到插入位置
Hash hs;
size_t addr = hs(data.first) % _tables.size();
我们发现之前插入键值对都是使用键值对的键来传给哈希函数获取哈希值,当我们将哈希表改成可以存储任意数据后,就不支持上述获取哈希值的方式了。
因此为了实现代码的复用,我们需要传入一个新的模板参数,以便在不同情况下都能按照我们需要的方式进行获取哈希值,因为如果是unordered_map需要通过键来获取,unordered_set则直接通过数据进行获取,所以我们可以在set类和map类中各定义一个类来获取传给哈希函数的数据,再传给哈希表:
// unordered_map类
template<class K,class V>
class unordered_map {
//定义一个类获取键值对里面的键
struct MapKeyOfT {const K& operator()(const pair<K, V>& data){return data.first;}
};private:HashTable<K, pair<K,V>, MapKeyOfT> _ht;//传给哈希表};
//unordered_set类
template<class K>
class unordered_set{
//也定义一个类返回data即可,虽然有点多此一举,但是可以实现代码复用
struct SetKeyOfT {const K& operator()(const K& data){return data;}
};private:HashTable<K, K, SetKeyOfT> _ht;//传给哈希表
};
看起来unordered_set定义的类似乎做了无用功,但是这一切都是为了能够实现哈希表的复用,unordered_map多传了一个参数,unordered_set也要多传。
那么哈希表的模板参数也要修改一下:
template<class K, class T, class KeyOfT, class Hash = HashFunc<K>>
class HashTable {
public:typedef HashNode<T> Node;private:vector<Node*> _tables;size_t _n;//记录存储数据个数
};
这样我们在插入函数进行比较时,就可以通过类模板KeyOfT定义一个对象然后使用括号来获取需要进行比较的数了:
bool Insert(const T& data)
{KeyOfT kot;//使用类模板,定义一个对象Hash hs;//1.先找是否已经插入过相同的值if (Find(kot(data)))return false;//2.判断是否需要扩容...//3.通过Hash函数找到插入位置size_t addr = hs(kot(data)) % _tables.size();//...}
这样就可以使用类模板定义的对象通过重载括号获取你想要的值,如果插入类型是键值对,那么就获得键值对中的键;如果不是键值对,括号返回的也是数据本身;这样不同的数据都可以传给哈希函数🥳🥳
3. 迭代器
哈希表的迭代器与链表的迭代器类似,都是使用指针来构造:
//迭代器
template<class T>
struct HashTableIterator {typedef HashNode<T> Node;typedef HashTableIterator<T> self;T& operator*(){return _node->_data;}T* operator->(){return &(_node->_data);}bool operator!=(const self& t){return _node != t._node;}bool operator==(const self& t){return _node == t._node;}self& operator++(){//...}//构造HashTableIterator(Node* node):_node(node){}Node* _node;};
✨对于operator++:
因为哈希表中是使用哈希桶,当一个桶遍历完,就需要寻找下一个桶,所以我们得将哈希表传过去来寻找下一个桶:
self& operator++()
{if (_node->_next)_node = _node->_next;//如果当前桶走完了,找下一个桶//1.先找到当前位置KeyOfT kot;Hash hs;size_t hash = hs(kot(_node->_data)) % _pht->_tables.size();++hash;while (hash < _pht->_tables.size()){if (_pht->_tables[hash])break;hash++;}if (hash >= _pht->_tables.size())_node = nullptr;else_node = _pht->_tables[hash];return *this;
}
可以看出上述代码使用了KeyOfT和Hash类分别获得传给哈希函数的值和哈希函数计算的哈希值,所以迭代器模板也要传入这两个参数:
template<class K, class T, class KeyOfT, class Hash>
truct HashTableIterator {typedef HashNode<T> Node;typedef HashTableIterator<K,T, KeyOfT, Hash> self;typedef HashTable<K, T, KeyOfT, Hash> HashTable;//...};
又因为获取哈希表需要传入四个参数,所以迭代器的参数也得包括这四个,所以除了KeyOfT和Hash还要传入K这个参数
然后在迭代器中除了需要定义一个指针外,还需要一个哈希表的指针以便将哈希表传过去:
template<class K, class T, class KeyOfT, class Hash>
truct HashTableIterator {typedef HashNode<T> Node;typedef HashTableIterator<K,T, KeyOfT, Hash> self;typedef HashTable<K, T, KeyOfT, Hash> HashTable;//构造HashTableIterator(Node* node, HashTable* pht):_node(node),_pht(pht){}Node* _node;HashTable* _pht;//传入哈希表指针
};完整的普通迭代器类代码如下:
// 前置声明,因为迭代器类中要使用哈希表所以需要前置声明
template<class K, class T, class KeyOfT, class Hash>
class HashTable;//迭代器
template<class K, class T, class KeyOfT, class Hash>
struct HashTableIterator {typedef HashNode<T> Node;typedef HashTableIterator<K,T, KeyOfT, Hash> self;typedef HashTable<K, T, KeyOfT, Hash> HashTable;T& operator*(){return _node->_data;}T* operator->(){return &(_node->_data);}bool operator!=(const self& t){return _node != t._node;}bool operator==(const self& t){return _node == t._node;}self& operator++(){if (_node->_next)_node = _node->_next;//如果当前桶走完了,找下一个桶//1.先找到当前位置KeyOfT kot;Hash hs;size_t hash = hs(kot(_node->_data)) % _pht->_tables.size();++hash;while (hash < _pht->_tables.size()){if (_pht->_tables[hash])break;hash++;}if (hash >= _pht->_tables.size())_node = nullptr;else_node = _pht->_tables[hash];return *this;}//构造HashTableIterator(Node* node, HashTable* pht):_node(node),_pht(pht){}Node* _node;HashTable* _pht;};✨const迭代器
相较于普通迭代器,const迭代器指向的内容不可以被修改,也就是说operator*和operator->返回值不可以修改,所以只要在其返回值前加const修饰即可,为了与普通迭代器复用同一个迭代器类,我们需要在迭代器类的模板参数中多加两个:
// 前置声明
template<class K, class T,class KeyOfT, class Hash>
class HashTable;//迭代器
template<class K, class T, class Ref, class Ptr,class KeyOfT, class Hash>
struct HashTableIterator {typedef HashNode<T> Node;typedef HashTableIterator<K,T,Ref, Ptr, KeyOfT, Hash> self;typedef const HashTable<K, T, KeyOfT, Hash> HashTable;//注意这里是constRef operator*(){return _node->_data;}Ptr operator->(){return &(_node->_data);}bool operator!=(const self& t){return _node != t._node;}bool operator==(const self& t){return _node == t._node;}self& operator++(){if (_node->_next)_node = _node->_next;//如果当前桶走完了,找下一个桶//1.先找到当前位置KeyOfT kot;Hash hs;size_t hash = hs(kot(_node->_data)) % _pht->_tables.size();++hash;while (hash < _pht->_tables.size()){if (_pht->_tables[hash])break;hash++;}if (hash >= _pht->_tables.size())_node = nullptr;else_node = _pht->_tables[hash];return *this;}//构造HashTableIterator(Node* node, HashTable* pht):_node(node),_pht(pht){}Node* _node;HashTable* _pht;};
这样在哈希表中如果是普通迭代器就传T,T&,T*这三个模板参数,如果是const迭代器就传T,const T&,const T*这三个模板参数,这样就很好限制了const迭代器修改指向的内容:
template<class K, class T, class KeyOfT, class Hash = HashFunc<K>>
class HashTable {
public:// 友元声明template<class K, class T, class Ref, class Ptr,class KeyOfT, class Hash>friend struct HashTableIterator;typedef HashNode<T> Node;typedef HashTableIterator<K, T, T&, T*, KeyOfT, Hash> Iterator;typedef HashTableIterator<K, T, const T&, const T*, KeyOfT, Hash> Const_Iterator;Iterator Begin(){if (_n == 0)return End();int i = 0;while (i < _tables.size()){if (_tables[i] != nullptr)break;i++;}return Iterator(_tables[i],this);}Iterator End(){return Iterator(nullptr,this);}Const_Iterator Begin() const{if (_n == 0)return End();int i = 0;while (i < _tables.size()){if (_tables[i] != nullptr)break;i++;}return Const_Iterator(_tables[i], this);}Const_Iterator End() const{return Const_Iterator(nullptr, this);}//...
private:vector<Node*> _tables;size_t _n;//记录存储数据个数
};因为在迭代器类中要使用哈希表中的数据,所以我们将迭代器设置为哈希表类的友元类
有了迭代器之后,Find查找函数的返回值就可以使用迭代器了🥳🥳:
// 检测哈希表中是否存在值为key的节点,存在返回该节点的迭代器,否则返回End()
Iterator Find(const K& key)
{//先找到key对应的Hash值KeyOfT kot;Hash hs;size_t ht = hs(key) % _tables.size();Node* cur = _tables[ht];while (cur){if (kot(cur->_data) == key)return Iterator(cur,this);cur = cur->_next;}return End();
}
这里同样要注意,查找函数需要通过特定的值获取哈希值,所以我们可以利用之前在插入函数中使用的类模板继续创建一个对象来获取哈希值。
4. unordered_map的[]访问
在unordered_map的使用介绍中,我们知道可以用[]来访问修改键值对以及插入数据:
//迭代器构造
std::vector<pair<string, string>> v = { {"上", "up"}, { "下", "down"}, { "左", "left"}, { "右", "right"} };
std::unordered_map<string, string> m(v.begin(), v.end());//[]访问
cout << m["上"] << endl;
cout << m["下"] << endl;
cout << m["左"] << endl;
cout << m["右"] << endl;//[]修改
m["右"] += "tutu";//[]插入
m["中"] = "center";cout << endl;
cout << "修改插入后:" << endl;
std::unordered_map<string, string>::iterator it = m.begin();
while (it != m.end())
{cout << it->first << ":" << it->second << endl;++it;
}
cout << endl;
结果如下:

unordered_map的[]能够插入数据是因为其复用了插入函数,如果[]里面引用的值不存在unordered_map中就会插入并返回键值对的值,存在就直接返回键值对的值,而插入函数中恰好会先寻找合适的插入位置,并返回bool值,所以我们只需对插入函数返回的值进行修改,这与之前学习过的map类似:
我们将插入函数的返回值设为pair类型,如果插入成功就返回新节点的迭代器和true;如果插入失败,那么map中肯定以及有相同的值,那么返回该位置的迭代器和false
这样在[]中就可以复用插入函数完成插入和修改操作了:
V& operator[](const K& key){pair<iterator, bool> ret = _ht.insert(make_pair(key, V()));return ret.first->second;}
插入函数只需要修改返回值即可:
pair<Iterator,bool> Insert(const T& data)
{//...简写//1.插入成功return make_pair(Iterator(newnode,this),true);//2.插入失败return make_pair(it,false);//已有位置的迭代器
}5. unordered_set和unordered_map封装
我们对于unordered_set和unordered_map封装需要各种新开一个头文件unordered_set.h和unordered_map.h来进行,并且都需要包含Hash.h头文件,放在自己的命名空间内,避免与STL标准库中的map和set弄混。
✨修改后的哈希表
//哈希函数
template<class K>
struct HashFunc
{size_t operator()(const K& key){return (size_t)key;}
};// 哈希表中支持字符串的操作
template<>
struct HashFunc<string>
{size_t operator()(const string& key){size_t hash = 0;for (auto e : key){hash *= 31;hash += e;}return hash;}
};//哈希节点类
template<class T>
struct HashNode
{T _data;HashNode<T>* _next;HashNode(const T& data):_data(data), _next(nullptr){}
};// 前置声明
template<class K, class T,class KeyOfT, class Hash>
class HashTable;//迭代器
template<class K, class T, class Ref, class Ptr,class KeyOfT, class Hash>
struct HashTableIterator {typedef HashNode<T> Node;typedef HashTableIterator<K,T,Ref, Ptr, KeyOfT, Hash> self;typedef const HashTable<K, T, KeyOfT, Hash> HashTable;Ref operator*(){return _node->_data;}Ptr operator->(){return &(_node->_data);}bool operator!=(const self& t){return _node != t._node;}bool operator==(const self& t){return _node == t._node;}self& operator++(){if (_node->_next)_node = _node->_next;//如果当前桶走完了,找下一个桶//1.先找到当前位置KeyOfT kot;Hash hs;size_t hash = hs(kot(_node->_data)) % _pht->_tables.size();++hash;while (hash < _pht->_tables.size()){if (_pht->_tables[hash])break;hash++;}if (hash >= _pht->_tables.size())_node = nullptr;else_node = _pht->_tables[hash];return *this;}//构造HashTableIterator(Node* node, HashTable* pht):_node(node),_pht(pht){}Node* _node;HashTable* _pht;};//哈希类template<class K, class T, class KeyOfT, class Hash = HashFunc<K>>class HashTable {public:// 友元声明template<class K, class T, class Ref, class Ptr,class KeyOfT, class Hash>friend struct HashTableIterator;typedef HashNode<T> Node;typedef HashTableIterator<K, T, T&, T*, KeyOfT, Hash> Iterator;typedef HashTableIterator<K, T, const T&, const T*, KeyOfT, Hash> Const_Iterator;Iterator Begin(){if (_n == 0)return End();int i = 0;while (i < _tables.size()){if (_tables[i] != nullptr)break;i++;}return Iterator(_tables[i],this);}Iterator End(){return Iterator(nullptr,this);}Const_Iterator Begin() const{if (_n == 0)return End();int i = 0;while (i < _tables.size()){if (_tables[i] != nullptr)break;i++;}return Const_Iterator(_tables[i], this);}Const_Iterator End() const{return Const_Iterator(nullptr, this);}HashTable(){_tables.resize(10, nullptr);}~HashTable(){// 依次把每个桶释放for (size_t i = 0; i < _tables.size(); i++){Node* cur = _tables[i];while (cur){Node* next = cur->_next;delete cur;cur = next;}_tables[i] = nullptr;}}pair<Iterator, bool> Insert(const T& data){KeyOfT kot;//1.先找是否已经插入过相同的值Iterator it = Find(kot(data));if (it != End())return make_pair(it,false);Hash hs;//2.判断是否需要扩容//如果负载因子为1就扩容if (_n == _tables.size()){HashTable<K, T, KeyOfT> h;h._tables.resize(2 * _tables.size(), nullptr);//只需要将哈希桶插入即可for (size_t i = 0; i < _tables.size(); i++){Node* cur = _tables[i];while (cur){size_t hash = hs(kot(cur->_data)) % h._tables.size();Node* Next = cur->_next;cur->_next = h._tables[hash];h._tables[hash] = cur;cur = Next;}_tables[i] = nullptr;}_tables.swap(h._tables);}//3.通过Hash函数找到插入位置size_t addr = hs(kot(data)) % _tables.size();//4.头插到新表if (_tables[addr] == nullptr)//如果是空,_n就需要++_n++;Node* newnode = new Node(data);newnode->_next = _tables[addr];_tables[addr] = newnode;return make_pair(Iterator(newnode,this), true);}Iterator Find(const K& key){//先找到key对应的Hash值Hash hs;KeyOfT kot;size_t ht = hs(key) % _tables.size();Node* cur = _tables[ht];while (cur){if (kot(cur->_data) == key)return Iterator(cur,this);cur = cur->_next;}return End();}bool Erase(const K& key){//1.先找到删除的位置Hash hs;KeyOfT kot;size_t ht = hs(key) % _tables.size();Node* cur = _tables[ht];Node* parent = nullptr;while (cur){if (kot(cur->_data) == key)break;parent = cur;cur = cur->_next;}if (cur == nullptr)return false;//2.删除对应节点if (parent)parent->_next = cur->_next;else_tables[ht] = cur->_next;//修改_nif (_tables[ht] == nullptr)_n--;//3.释放原节点delete cur;return true;}private:vector<Node*> _tables;size_t _n;//记录存储数据个数};
✨unordered_map类
#include"Hash.h"
// unordered_map类
namespace tutu
{
template<class K, class V>
class unordered_map {
public://定义一个类获取键值对里面的键struct MapKeyOfT {const K& operator()(const pair<K, V>& data){return data.first;}};typedef typename HashTable<K, pair<K, V>, MapKeyOfT>::Iterator iterator;typedef typename HashTable<K, pair<K, V>, MapKeyOfT>:: Const_Iterator const_iterator;iterator begin(){return _ht.Begin();}iterator end() {return _ht.End();}const_iterator begin() const{return _ht.Begin();}const_iterator end() const{return _ht.End();}pair<iterator, bool> insert(const pair<K, V>& kv){return _ht.Insert(kv);}V& operator[](const K& key){pair<iterator, bool> ret = _ht.Insert(make_pair(key, V()));return ret.first->second;}iterator Find(const K& key){return _ht.Find(key);}bool Erase(const K& key){return _ht.Erase(key);}private:HashTable<K, pair<K, V>, MapKeyOfT> _ht;//传给哈希表};//测试函数void test_map(){unordered_map<string, string> dict;dict.insert({ "sort", "排序" });dict.insert({ "left", "左边" });dict.insert({ "right", "右边" });dict["left"] = "左边,剩余";dict["insert"] = "插入";dict["string"];unordered_map<string, string>::iterator it = dict.begin();while (it != dict.end()){cout << it->first << ":" << it->second << endl;++it;}cout << endl;}
}结果如下:

✨unordered_set类
#include"Hash.h"
namespace tutu{template<class K>class unordered_set{struct SetKeyOfT{const K& operator()(const K& key){return key;}};public:typedef typename HashTable<K, const K, SetKeyOfT>::Iterator iterator;typedef typename HashTable<K, const K, SetKeyOfT>::Const_Iterator const_iterator;iterator begin(){return _ht.Begin();}iterator end(){return _ht.End();}const_iterator begin() const{return _ht.Begin();}const_iterator end() const{return _ht.End();}pair<iterator, bool> insert(const K& key){return _ht.Insert(key);}iterator Find(const K& key){return _ht.Find(key);}bool Erase(const K& key){return _ht.Erase(key);}private:HashTable<K, const K, SetKeyOfT> _ht;};void Print(const unordered_set<int>& s){unordered_set<int>::const_iterator it = s.begin();while (it != s.end()){// *it += 1;cout << *it << " ";++it;}cout << endl;}void test_set()
{unordered_set<int> s;int a[] = { 4, 2, 6, 1, 3, 5, 15, 7, 16, 14, 3,3,15 };for (auto e : a){s.insert(e);}for (auto e : s){cout << e << " ";}cout << endl;unordered_set<int>::iterator it = s.begin();while (it != s.end()){//*it += 1;cout << *it << " ";++it;}cout << endl;Print(s);
}}结果如下:

6. 结语
unordered_map和unordered_set的底层都是使用哈希表来实现的,然后在外面套了一层壳,为了能够更好的实现代码复用,我们对哈希表进行了很多修改还使用了仿函数,封装了普通迭代器和const迭代器等,最终成功对unordered_map和unordered_set实现了封装,它们和使用红黑树对map和set封装非常类似,大家可以一起参考学习。以上就是今天所有的内容啦~ 完结撒花 ~🥳🎉🎉
相关文章:
【C++深度探索】unordered_set、unordered_map封装
🔥 个人主页:大耳朵土土垚 🔥 所属专栏:C从入门至进阶 这里将会不定期更新有关C/C的内容,欢迎大家点赞,收藏,评论🥳🥳🎉🎉🎉 文章目录…...

CSS——字体背景(Font Background)
一、字体族 1、字体的相关样式: ① color 用来设置字体颜色(前景颜色) ② font-size 字体的大小 和font-size相关的单位: em 相对于当前元素的一个font-size rem 相对于根元素的一个font-size ③ font-family 字体族&#x…...

秋招突击——8/15——知识补充——Socket通信
文章目录 引言正文基于TCP协议的Socket通信基于UDP协议的Socket通信服务端如何接收更多项目多进程多线程IO多路复用select轮询IO多路复用epoll事件通知 使用Socket实现同一个机器上的多线程通信服务端创建对应socket监听端口客户端发起对应的连接请求 总结 引言 上次面试腾讯的…...
Qt第十四章 模型视图
Model/View(模型/视图)结构 文章目录 Model/View(模型/视图)结构简介视图组件Model/View结构的一些概念项目控件组(item Widgets)模型/视图 如何使用项目视图组设置行的颜色交替变换拖拽设置编辑操作其他操作 选择模型自定义选择多…...

硬件工程师必须掌握的MOS管详细知识
MOS管,全称为金属-氧化物半导体场效应晶体管(Metal-Oxide-Semiconductor Field-Effect Transistor,MOSFET),是一种重要的半导体器件,广泛应用于电子工业中各种电路的开关、放大、调制、数字电路和模拟电路等…...

希尔排序,详细解析(附图解)
1.希尔排序思路 希尔排序是一种基于插入排序的算法,通过将原始数据分成若干个子序列,然后对子序列进行插入排序,逐渐减小子序列的间隔,最后对整个序列进行一次插入排序。 1.分组直接插入排序,目标接近有序--------…...

【C语言篇】编译和链接以及预处理介绍(下篇)
文章目录 前言#和###运算符##运算符 命名约定#undef命令⾏定义条件编译#if和#endif多个分支的条件编译判断是否被定义嵌套指令 头文件被包含头文件被包含的方式本地文件包含库文件的包含 嵌套文件包含 其他预处理指令 写在最后 前言 本篇接前一篇【C语言篇】编译和链接以及预处…...

利用Llama2 7b自己实现一套离线AI
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家, 可以当故事来看,轻松学习。 离了 ChatGPT 本人简直寸步难行,今天 ChatGPT 大面积宕机,服务直到文章写作&am…...

Ciallo~(∠・ω・ )⌒☆第十七篇 Ubuntu基础使用 其一
Ubuntu是一种基于Linux的操作系统,它是开源的、免费的,并且具有广泛的用户群体。 基本文件操作:Ubuntu使用命令行工具来进行文件操作。以下是一些常用的命令: 切换到用户主目录: cd ~ 切换到上级目录: cd .…...

Linux-零拷贝技术
什么是零拷贝? 在传统的数据传输过程中,数据需要从磁盘读取到内核空间的缓冲区,然后再从内核空间拷贝到用户空间的应用程序缓冲区。如果需要将数据发送到网络,数据还需要再次从用户空间拷贝到内核空间的网络缓冲区。这个过程涉及…...

小区团购管理
TOC springboot254小区团购管理 第1章 绪论 1.1选题动因 当前的网络技术,软件技术等都具备成熟的理论基础,市场上也出现各种技术开发的软件,这些软件都被用于各个领域,包括生活和工作的领域。随着电脑和笔记本的广泛运用&…...
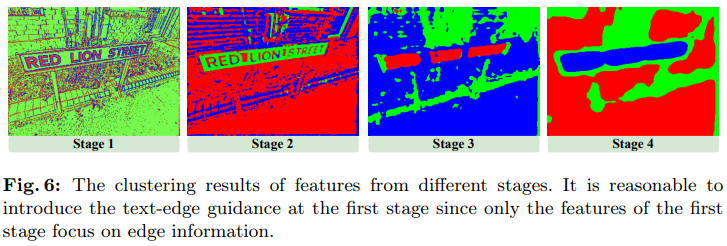
图像文本擦除无痕迹!复旦提出EAFormer:最新场景文本分割新SOTA!(ECCV`24)
文章链接:https://arxiv.org/pdf/2407.17020 git链接:https://hyangyu.github.io/EAFormer/ 亮点直击 为了在文本边缘区域实现更好的分割性能,本文提出了边缘感知Transformer(EAFormer),该方法明确预测文…...

Codeforces Round 966 (Div. 3)(A,B,C,D,E,F)
A. Primary Task 签到 void solve() {string s;cin>>s;bool bltrue;if(s.size()<2)blfalse;else{if(s.substr(0,2)"10"){if(s[2]0)blfalse;else if(s[2]1&&s.size()<3)blfalse; }else blfalse;}if(bl)cout<<"YES\n";else cout…...

【代码随想录算法训练营第42期 第六天 | LeetCode242.有效的字母异位词、349. 两个数组的交集、202. 快乐数、1. 两数之和】
代码随想录算法训练营第42期 第六天 | LeetCode242.有效的字母异位词、349. 两个数组的交集、202. 快乐数、1. 两数之和 一、242.有效的字母异位词 解题代码C: bool isAnagram(char* s, char* t) {int len1 strlen(s);int len2 strlen(t);int al[26] {0};int b…...

WebRTC音视频开发读书笔记(一)
一、基本概念 WebRTC(Web Real-Time Communication,网页即时通信)于2011年6月1日开源,并被纳入万维网联盟的W3C推荐标准,它通过简单API为浏览器和移动应用提供实时通信RTC功能。 1、特点 跨平台:可以在Web,Android、…...

llama3.1本地部署方式
llama3.1 资源消耗情况 Llama 3.1 - 405B、70B 和 8B 的多语言与长上下文能力解析  70B版本,FP1616K token需要的资源约为75G;FP16128K token需要的资源约为110G  1、ollama ollama工具部署及使用…...
——色差仪颜色观察者视角)
相机光学(三十四)——色差仪颜色观察者视角
1.为什么会有观察者视角 颜色观察角度主要涉及到人眼观察物体时,视角的大小以及屏幕显示颜色的方向性对颜色感知的影响。 人眼观察物体的视角:在黑暗条件下,人眼主要依靠杆体细胞来分辨物体的轮廓,而杆体细胞分布在视网…...

思二勋:web3.0是打造应对复杂市场敏捷组织的关键
本文内容摘自思二勋所著的《分布式商业生态战略》一书。 数字化时代,需要企业具备敏捷应对变化的能力,以敏捷反应应对客户和市场的迅速变化。敏捷能力的建设需要触点网络、信息系统、IT 架构、业务流程等同时实现敏捷。尤其是在多变且复杂环境中,特别要求战略管理的敏捷性和…...

一文带你快速了解——HAProxy负载均衡
一、HAProxy简介 1.1、什么是Haproxy HAProxy是法国开发者 威利塔罗(Willy Tarreau)在2000年使用C语言开发的一个开源软件是一款具备高并发(万级以上)、高性能的TCP和HTTP负载均衡器支持基于cookie的持久性,自动故障切换,支持正则表达式及web状态统计。…...

【C++高阶】哈希—— 位图 | 布隆过滤器 | 哈希切分
✨ 人生如梦,朝露夕花,宛若泡影 🌏 📃个人主页:island1314 🔥个人专栏:C学习 ⛺️ 欢迎关注:👍点赞 👂&am…...

golang循环变量捕获问题
在 Go 语言中,当在循环中启动协程(goroutine)时,如果在协程闭包中直接引用循环变量,可能会遇到一个常见的陷阱 - 循环变量捕获问题。让我详细解释一下: 问题背景 看这个代码片段: fo…...

在鸿蒙HarmonyOS 5中实现抖音风格的点赞功能
下面我将详细介绍如何使用HarmonyOS SDK在HarmonyOS 5中实现类似抖音的点赞功能,包括动画效果、数据同步和交互优化。 1. 基础点赞功能实现 1.1 创建数据模型 // VideoModel.ets export class VideoModel {id: string "";title: string ""…...

React Native在HarmonyOS 5.0阅读类应用开发中的实践
一、技术选型背景 随着HarmonyOS 5.0对Web兼容层的增强,React Native作为跨平台框架可通过重新编译ArkTS组件实现85%以上的代码复用率。阅读类应用具有UI复杂度低、数据流清晰的特点。 二、核心实现方案 1. 环境配置 (1)使用React Native…...

ETLCloud可能遇到的问题有哪些?常见坑位解析
数据集成平台ETLCloud,主要用于支持数据的抽取(Extract)、转换(Transform)和加载(Load)过程。提供了一个简洁直观的界面,以便用户可以在不同的数据源之间轻松地进行数据迁移和转换。…...

Spring AI 入门:Java 开发者的生成式 AI 实践之路
一、Spring AI 简介 在人工智能技术快速迭代的今天,Spring AI 作为 Spring 生态系统的新生力量,正在成为 Java 开发者拥抱生成式 AI 的最佳选择。该框架通过模块化设计实现了与主流 AI 服务(如 OpenAI、Anthropic)的无缝对接&…...

Unit 1 深度强化学习简介
Deep RL Course ——Unit 1 Introduction 从理论和实践层面深入学习深度强化学习。学会使用知名的深度强化学习库,例如 Stable Baselines3、RL Baselines3 Zoo、Sample Factory 和 CleanRL。在独特的环境中训练智能体,比如 SnowballFight、Huggy the Do…...

Android15默认授权浮窗权限
我们经常有那种需求,客户需要定制的apk集成在ROM中,并且默认授予其【显示在其他应用的上层】权限,也就是我们常说的浮窗权限,那么我们就可以通过以下方法在wms、ams等系统服务的systemReady()方法中调用即可实现预置应用默认授权浮…...

10-Oracle 23 ai Vector Search 概述和参数
一、Oracle AI Vector Search 概述 企业和个人都在尝试各种AI,使用客户端或是内部自己搭建集成大模型的终端,加速与大型语言模型(LLM)的结合,同时使用检索增强生成(Retrieval Augmented Generation &#…...

人机融合智能 | “人智交互”跨学科新领域
本文系统地提出基于“以人为中心AI(HCAI)”理念的人-人工智能交互(人智交互)这一跨学科新领域及框架,定义人智交互领域的理念、基本理论和关键问题、方法、开发流程和参与团队等,阐述提出人智交互新领域的意义。然后,提出人智交互研究的三种新范式取向以及它们的意义。最后,总结…...

20个超级好用的 CSS 动画库
分享 20 个最佳 CSS 动画库。 它们中的大多数将生成纯 CSS 代码,而不需要任何外部库。 1.Animate.css 一个开箱即用型的跨浏览器动画库,可供你在项目中使用。 2.Magic Animations CSS3 一组简单的动画,可以包含在你的网页或应用项目中。 3.An…...