NLP实验-基于预训练模型的文本分类
使用BERT及其变体实现AclImdb情感分类
- 前言
- 数据集介绍
- 【Hugging Face】使用方法和如何挑选一个自己需要的模型
- 基于BERT预训练模型的本文分类
- 数据预处理
- 载入文本标记器
- 将数据转化为模型可以接受的格式
- 训练模型
- 加载模型
- 基于RoBerta预训练模型的文本分类
- 基于DeBerta预训练模型的文本分类
- 全部代码链接
2024.05.05 17:35
实现基于预训练模型的文本分类任务,使用三种不同的预训练模型,并对比分类准确率。
前言
数据集介绍
数据集来源:链接
数据集简要概述:该数据集包含电影评论及情感极性标签,其可用于作为一个基准情绪的分类。
共50000条评论,分为25k训练集,25k测试集,25k正面评论,25k负面评论,还有50000条未标记数据用于无监督学习。
数据集结构如下:
|- test
|-- neg
|-- pos
|- train
|-- neg
|-- pos
除此之外,每个电影的评论不超过30条,因为多了会存在相关性。
负面评价≤4分,证明评价≥7分,满分10分。
【Hugging Face】使用方法和如何挑选一个自己需要的模型
参考文章
模型名称解读:在Hugging Face上,模型名称通常是对模型架构、训练数据和任务的一种描述。这些模型名称通常包含了一些关键信息,帮助用户理解模型的基本特征。
【例子】
-
“bert-base-uncased”
这个模型名称中的"bert"代表了模型架构为BERT(Bidirectional Encoder Representations from Transformers)。
"base"表示这是基本版的模型,通常是指相对较小的模型规模。
"uncased"表示这个模型是在训练数据中将所有文本转换为小写处理的,没有区分大小写。
"bert-base-uncased"表示了一个基于BERT架构的小型模型,适用于不区分大小写的任务。 -
“gpt2-medium”
这个模型名称中的"gpt2"代表了模型架构为GPT-2(Generative Pre-trained Transformer 2)。
"medium"表示这是GPT-2模型系列中的中型规模模型。
"gpt2-medium"表示了一个中等规模的GPT-2模型。 -
“roberta-large”
这个模型名称中的"roberta"代表了模型架构为RoBERTa(Robustly Optimized BERT approach)。
"large"表示这是RoBERTa模型系列中的大型规模模型。
"roberta-large"表示了一个大型的RoBERTa模型。 -
“distilbert-base-uncased-finetuned-sst-2-english”
这个模型名称解释了一些特定的信息。"distilbert"指的是经过蒸馏(distillation)处理的BERT模型,特点是具有较小的模型规模和更快的推理速度。
"base"和"uncased"与之前提到的意义相同。
"finetuned-sst-2"表示这个模型是在SST-2(斯坦福情感树库)数据集上进行了微调(Fine-tuning)以用于情感分类任务。
"english"表示这个模型是为英语任务预训练和微调而创建的。 -
“t5-base”
这个模型名称中的"t5"是指T5(Text-to-Text Transfer Transformer)模型,这是一种基于Transformer架构的文本生成模型。
"base"与之前提到的意义相同,表示模型的基本版本。 -
“facebook/wmt19-mu-en-1024”
这个模型名称指的是Facebook团队针对WMT19 Multilingual Translation任务训练的英语-多语言(mu)翻译模型。
"-en"表示英语作为源语言
"1024"表示模型的隐藏状态大小为1024。 -
TheBloke/Llama-2-13B-chat-GGML
“TheBloke”:这部分可能是指该模型的创建者、团队或者用户名。
“Llama-2-13B”:这部分可能是指模型的架构、版本或系列。它可能是从较早版本的Llama模型发展而来,或者是在Llama模型系列中的第二个版本。 “2-13B"可能指的是模型参数和规模,表明该模型具有130亿个参数。
“chat”:这部分可能指出该模型是专门用于对话或聊天任务的。这种指明任务类型的信息有助于用户了解模型的适用性。
GGML”:这部分可能是指模型的训练或微调框架、方法或技术。 -
stabilityai/sd-vae-ft-mse-original
“stabilityai”:这部分可能是指模型的创建者、提供者或组织名称。它可能代表一个名为 “stabilityai” 的实体或团队。
“sd-vae-ft-mse-original”:这部分可能提供了关于模型的其他关键信息。例如,“sd-vae” 可能表示变分自动编码器(VAE)的一种改进或特定类型。“ft” 可能是指模型进行了微调(fine-tuning)。“mse-original” 可能是指在模型训练过程中使用了均方误差(Mean Squared Error)作为损失函数或评价指标。
基于BERT预训练模型的本文分类
本文使用 https://huggingface.co/models 中的bert-base-uncased预训练模型进行实战。
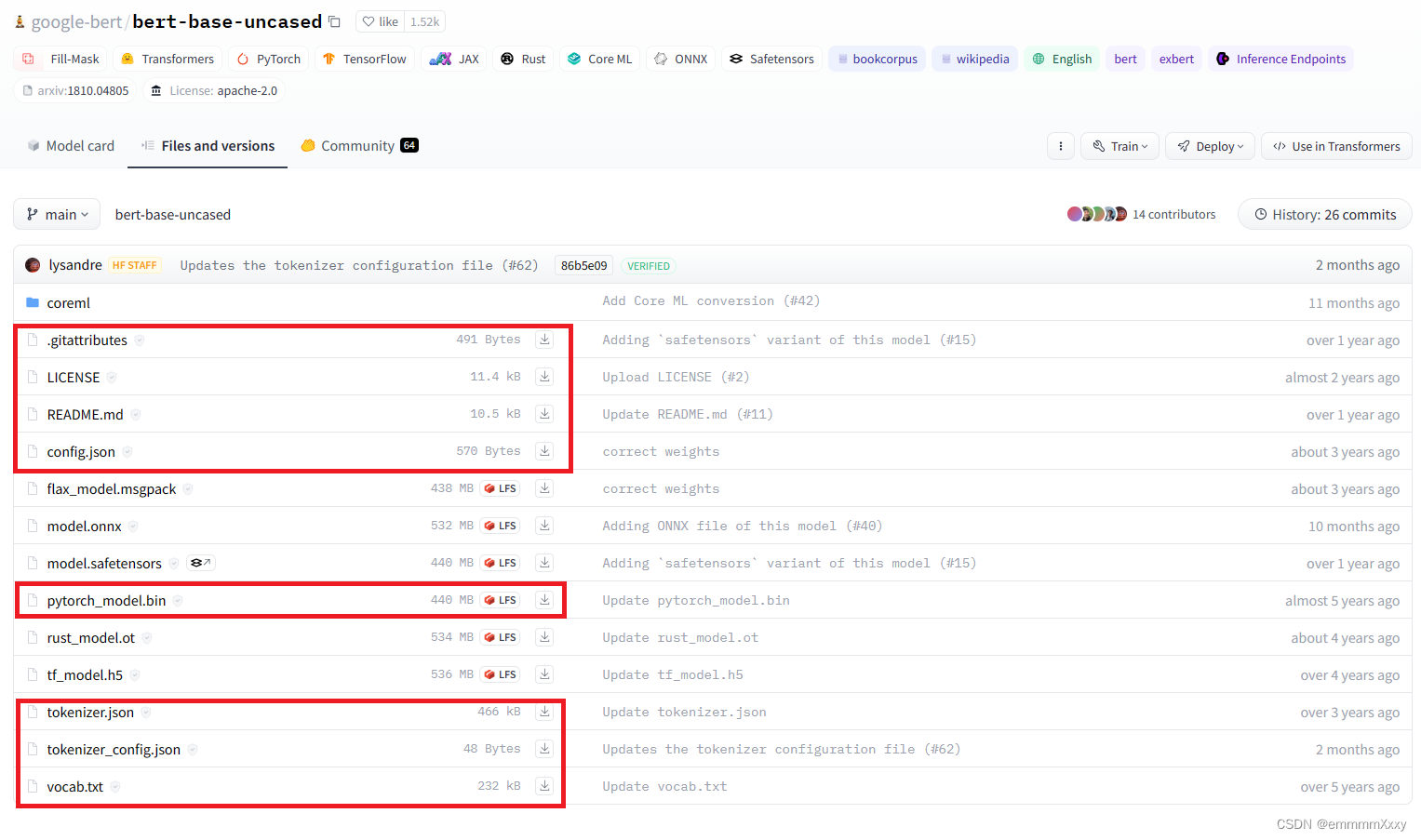
首先是模型参数的下载,进入huggingface网址,搜索bert,选择下图中第一个选项,

点击下载按钮,下载下图中框起来的文件到本地,文件夹命名为’bert-base-uncased‘。
数据预处理
要想使用Trainer进行训练,需要将数据调整到一定的规范,以下展示使用预训练模型对应的文本标记器(tokenizer)和datasets库处理原始数据。
"token"是什么?:在AI领域,token指文本或代码的最小单元,可以理解为单词或字符的更高级表示,token将文本分解成有意义的片段,例如单词、词根或标点符号,这些片段作为模型的输入,帮助模型理解和生成内容。例如:“我喜欢人工智能”这句话可以被分解成“我”、“喜欢”、“人工智能”三个token,每个token都代表一个独立的语义概念,token的长度和类型取决于具体的模型和应用,有些模型使用单个字符作为token,而有些模型则使用更长的词组或短语作为token。总而言之,token是AIGC模型处理和生成内容的基本单位,对于理解AIGC的工作原理至关重要。
from datasets import Dataset
from transformers import BertTokenizer
import os# 载入原始数据
def load_data(base_path):paths = os.listdir(base_path)result = []for path in paths:with open(os.path.join(base_path, path), 'r', encoding='utf-8') as f:result.append(f.readline())return result# 读入数据并转化为datasets.Dataset
def get_dataset(base_path):# 为了展示方便,这里只取前3个数据,真实使用需要删掉切片操作pos_data = load_data(os.path.join(base_path, 'pos'))[:3]neg_data = load_data(os.path.join(base_path, 'neg'))[:3]# 列表合并texts = pos_data + neg_data# 生成标签,其中使用 '1.' 和 '0.' 是因为需要转化为浮点数,要不然模型训练时会报错labels = [[1., 0.]]*len(pos_data) + [[0., 1.]] * len(neg_data)dataset = Dataset.from_dict({'texts':texts, 'labels':labels})return dataset# 加载数据
train_dataset = get_dataset('../data/aclImdb/train/')
test_dataset = get_dataset('../data/aclImdb/test/')# 可查看数据集结构、标签、特征等
print(train_dataset)
print(train_dataset['labels'])
print(train_dataset.features)
载入文本标记器
# cache_dir是预训练模型的地址
cache_dir="../transformersModels/bert-base-uncased/"
tokenizer = BertTokenizer.from_pretrained(cache_dir)
-注意: 这个路径的模型要自己下载,不能是transformer包下的,要不会报错。
将数据转化为模型可以接受的格式
# 设置最大长度
MAX_LENGTH = 512# 使用文本标记器对texts进行编码
train_dataset = train_dataset.map(lambda e: tokenizer(e['texts'], truncation=True, padding='max_length', max_length=MAX_LENGTH), batched=True)
test_dataset = test_dataset.map(lambda e: tokenizer(e['texts'], truncation=True, padding='max_length', max_length=MAX_LENGTH), batched=True)# 保存处理好的数据到本地
# 在数据量大的时候,处理数据需要很长的时间,为了不每次都重新处理数据,可以将数据先存到本地
train_dataset.save_to_disk('./data/train_dataset')
test_dataset.save_to_disk('./data/test_dataset')
‘texts’, ‘labels’, ‘input_ids’, ‘token_type_ids’, ‘attention_mask’
训练模型
from transformers import BertForSequenceClassification, BertTokenizer, Trainer, TrainingArguments, BertConfig
import torch
from datasets import Dataset
import json
import os
# 设定使用的GPU编号,也可以不设置,但trainer会默认使用多GPU
os.environ["CUDA_VISIBLE_DEVICES"] = "1"# 将num_labels设置为2,因为我们训练的任务为2分类
model = BertForSequenceClassification.from_pretrained('../transformersModels/bert-base-uncased/', num_labels=2)# 加载处理好的数据
train_dataset = Dataset.load_from_disk('./data/train_dataset/')
test_dataset = Dataset.load_from_disk('./data/test_dataset/')# 冻结BERT参数
'''
因为BERT是预训练模型,因此可以不再进行权重更新,只对尾部的分类器进行优化。
与此同时,这个设置也会减少训练时使用的时间和显存。
'''
for param in model.base_model.parameters():param.requires_grad = False# 创建trainer
# 训练超参配置
training_args = TrainingArguments(output_dir='./my_results', # output directory 结果输出地址num_train_epochs=10, # total # of training epochs 训练总批次per_device_train_batch_size=128, # batch size per device during training 训练批大小per_device_eval_batch_size=128, # batch size for evaluation 评估批大小logging_dir='./my_logs', # directory for storing logs 日志存储位置
)# 创建Trainer
trainer = Trainer(model=model.to('cuda'), # the instantiated 🤗 Transformers model to be trained 需要训练的模型args=training_args, # training arguments, defined above 训练参数train_dataset=train_dataset, # training dataset 训练集eval_dataset=test_dataset, # evaluation dataset 测试集
)# 训练、评估和保存模型
# 开始训练
trainer.train()# 开始评估模型
trainer.evaluate()# 保存模型 会保存到配置的output_dir处
trainer.save_model()
torch.save(model.state_dict(), 'model_save.bin')
这里保存模型参数代码不同可以看:链接
保存模型会生成三个文件:
# 模型配置文件
config.json# 模型数据文件
model_save.bin# 训练配置文件
training_args.bin
加载模型
output_config_file = './my_results/config.json'
output_model_file = './my_results/model_save.bin'config = BertConfig.from_json_file(output_config_file)
model = BertForSequenceClassification(config)
state_dict = torch.load(output_model_file)
model.load_state_dict(state_dict)cache_dir="../transformersModels/bert-base-uncased/"
tokenizer = BertTokenizer.from_pretrained(cache_dir)
data = tokenizer(['This is a good movie', 'This is a bad movie'], max_length=512, truncation=True, padding='max_length', return_tensors="pt")
print(model(**data))输出结果:
SequenceClassifierOutput(
loss=None, logits=tensor([
[-0.2951, 0.5463],
[-0.4638, 0.6353]],
grad_fn=<AddmmBackward0>),
hidden_states=None,
attentions=None)
由于只用3条数据训练了10轮,因此结果很差,正常训练结果可以变好了。
参考文章:Transformers实战——使用本地数据进行AclImdb情感分类
基于RoBerta预训练模型的文本分类
将Bert模型中的部分代码进行修改
注:
from transformers import RobertaModel 和 from transformers import RobertaForSequenceClassification 之间的区别在于它们所代表的模型的不同。
-
RobertaModel是 Hugging Face Transformers 库中的一个类,它表示了 RoBERTa 模型的基本架构。RobertaModel只提供了预训练的 RoBERTa 模型的基本功能,例如输入编码、注意力机制等,但不包含用于特定任务(如分类)的额外层。 -
RobertaForSequenceClassification是RobertaModel的一个派生类,它专门用于进行序列分类任务。RobertaForSequenceClassification在RobertaModel的基础上添加了一个用于分类的线性层(linear layer),该层接收 RoBERTa 的输出并生成分类预测。这使得RobertaForSequenceClassification在进行分类任务时更加方便和高效。
因此,当你想要使用 RoBERTa 模型进行序列分类任务时,推荐使用 RobertaForSequenceClassification。如果你只需要 RoBERTa 模型的基本功能,而不涉及特定的任务,那么使用 RobertaModel 就足够了。
from transformers import RobertaTokenizer, RobertaModel, RobertaConfigtokenizer = RobertaTokenizer.from_pretrained("pretrained_model/roberta_base/")
config = RobertaConfig.from_pretrained("pretrained_model/roberta_base/")
model = RobertaModel.from_pretrained("pretrained_model/roberta_base/")基于DeBerta预训练模型的文本分类
ValueError: Couldn't instantiate the backend tokenizer from one of:
(1) a `tokenizers` library serialization file,
(2) a slow tokenizer instance to convert or
(3) an equivalent slow tokenizer class to instantiate and convert.
You need to have sentencepiece installed to convert a slow tokenizer to a fast one.
pip install sentencepiece
之后报错
TypeError: stat: path should be string, bytes, os.PathLike or integer, not NoneType
from transformers import AutoTokenizertokenizer = AutoTokenizer.from_pretrained("albert-base-v2")
看到某个博客下写的解决方案:
就是把你在huggingface上参考的那个模型,models下面其他相关文件别管有用没用全传上去,我之前就传了两,报这个错
试了下,成功!
全部代码链接
链接如下,欢迎star
相关文章:
NLP实验-基于预训练模型的文本分类
使用BERT及其变体实现AclImdb情感分类 前言数据集介绍【Hugging Face】使用方法和如何挑选一个自己需要的模型 基于BERT预训练模型的本文分类数据预处理载入文本标记器将数据转化为模型可以接受的格式训练模型加载模型 基于RoBerta预训练模型的文本分类基于DeBerta预训练模型的…...

Table API SQL的概念和通用API
目录 表API和SQL程序的结构 创建表环境(Create a TableEnvironment) 在目录中创建表(Create Tables in the Catalog) 临时表与永久表(Temporary vs Permanent tables) 遮蔽(Shadowing) 创建表(Create a Table) 连接器表(Connector Tables) 虚拟表(Virtual…...
【网络】UDP和TCP之间的差别和回显服务器
文章目录 UDP 和 TCP 之间的差别有连接/无连接可靠传输/不可靠传输面向字节流/面向数据报全双工/半双工 UDP/TCP API 的使用UDP APIDatagramSocket构造方法方法 DatagramPacket构造方法方法 回显服务器(Echo Server)1. 接收请求2. 根据请求计算响应3. 将…...

Electron:摄像头录制和屏幕录制
摄像头录制 main.js const { app, BrowserWindow} require(electron)let mainWin null const createWindow () > {mainWin new BrowserWindow({width: 800,height: 600,title: 自定义菜单,webPreferences: {// 允许渲染进程使用nodejsnodeIntegration: true,// 允许渲…...

【uniapp】vue3+vite配置tailwindcss
安装 npm install autoprefixer tailwindcss uni-helper/vite-plugin-uni-tailwind -Dautoprefixer :自动管理浏览器前缀的插件,可以解析css文件并且添加前缀到css内容里。uni-helper/vite-plugin-uni-tailwind: 将 Tailwind CSS 框架集成到使用 Vite 作…...

从源码到应用:医疗陪诊系统与在线问诊小程序开发详解
在数字化医疗时代,医疗陪诊系统与在线问诊小程序的开发成为了医疗机构和技术公司关注的焦点。接下来,小编将与您一同深入了解。 一、医疗陪诊系统的核心功能 医疗陪诊系统旨在为患者提供更贴心的医疗服务,通过专业人员陪同患者完成就医过程。…...

mysql数据库中decimal数据类型比较大小
在MySQL中,DECIMAL数据类型用于存储精确的数值,它非常适合用于需要高精度计算的场景,如金融应用。当我们需要在MySQL数据库中比较DECIMAL类型数据的大小时,可以使用标准的比较运算符,如>, <, >, <, 和 &l…...
掌控库存,简化管理 — InvenTree 开源库存管理系统
InvenTree :简化您的库存管理,让效率和控制力触手可及。- 精选真开源,释放新价值。 概览 InvenTree,一款专为精细化库存管理而设计的开源系统,以其高效和灵活性在众多库存管理工具中脱颖而出。它以Python和Django框架…...

Linux---项目自动化构建工具-make/Makefile
一、背景 会不会写makefile,从一个侧面说明了一个人是否具备完成大型工程的能力一个工程中的源文件不计数,其按类型、功能、模块分别放在若干个目录中,makefile定义了一系列的 规则来指定,哪些文件需要先编译,哪些文件…...

嘉立创EDA个人学习笔记1(PCB板介绍)
前言 本篇文章属于嘉立创EDA的学习笔记,来源于B站教学视频。下面是这位up主的视频链接。本文为个人学习笔记,只能做参考,细节方面建议观看视频,肯定受益匪浅。 嘉立创EDA-PCB设计零基础入门课程(54集全)_…...

(转)Restful接口设计(1)
.representational:代表性的 URI(Universal Resouce Identifier):Universal :普遍的;共同的。Identifier:标识符。统一资源标识符。 31-RESTful接口介绍-02_哔哩哔哩_bilibili 31-RESTful接口介绍-03_哔哩…...

Python进阶之3D图形
Python进阶之3D图形 在数据可视化中,2D图形通常可以满足大多数需求。然而,对于一些复杂的数据或分析,3D图形可以提供更多的视角和洞察。在Python中,使用 Matplotlib 和 Plotly 等库可以轻松创建各种3D图形。本文将介绍如何使用这…...

机器学习深度学习中的搜索算法浅谈
机器学习&深度学习中的搜索算法浅谈 搜索算法是计算机科学中的核心算法,用于在各种数据结构(如数组、列表、树、图等)中查找特定元素或信息。这些算法不仅在理论上具有重要意义,还在实际应用中扮演着关键角色。本文将详细探讨…...

基于IMX8M_plus+FPGA+AI监护仪解决方案
监护仪是一种以测量和控制病人生理参数,并可与已知设定值进行比较,如果出现超标可发出警报的装置或系统。 (1)监护仪主要采集测量人体生理参数,心电、血压、血氧、体温等需要采集处理大量的数据,系统需要多…...
)
仿RabbitMq实现简易消息队列正式篇(路由匹配篇)
TOC 目录 路由匹配模块 代码展示 路由匹配模块 决定了一条消息是否能够发布到指定的队列 在每个队列根交换机的绑定信息中,都有一个binding_key(在虚拟机篇有说到)这是队列发布的匹配规则 在每条要发布的消息中,都有一个rout…...

一套完整的NVR网络硬盘录像机解决方案和NVR程序源码介绍
随着网络技术的发展,视频数据存储的需求激增,促使硬盘录像机(DVR)逐渐演变为具备网络功能的网络视频录像机(NVR)。NVR,即网络视频录像机,负责网络视音频信号的接入、存储、转发、解码…...

2024年人工智能固态硬盘采购容量预计超过45 EB
根据TrendForce发布的最新市场报告,人工智能(AI)服务器客户在过去两个季度显著增加了对企业级固态硬盘(SSD)的订单。为了满足AI应用中不断增长的SSD需求,上游供应商正在加速工艺升级,并计划在20…...

Java的反射原理
反射允许程序在运行时检查或修改其类、接口、字段和方法的行为。反射主要通过java.lang.reflect包中的类和接口实现,它主要用于以下目的: 在运行时分析类的能力:通过反射,可以在运行时检查类的结构,比如它的方法、构造…...

vue.config.js 配置
vue.config.js 文件是 Vue CLI 项目中的全局配置文件,它允许你以 JavaScript 的形式来配置构建选项,而不是通过命令行参数或者 .vue-clirc 的 JSON 格式。 官方文档: https://cli.vuejs.org/zh/config/#全局-cli-配置 基础配置 publicPath 设置构建好的…...

C ++ 也可以搭建Web?高性能的 C++ Web 开发框架 CPPCMS + MySQL 实现快速入门案例
什么是CPPCMS? CppCMS 是一个高性能的 C Web 开发框架,专为构建快速、动态的网页应用而设计,特别适合高并发和低延迟的场景。其设计理念类似于 Python 的 Django 或 Ruby on Rails,但针对 C 提供了更细粒度的控制和更高效的性能。…...

Vim 调用外部命令学习笔记
Vim 外部命令集成完全指南 文章目录 Vim 外部命令集成完全指南核心概念理解命令语法解析语法对比 常用外部命令详解文本排序与去重文本筛选与搜索高级 grep 搜索技巧文本替换与编辑字符处理高级文本处理编程语言处理其他实用命令 范围操作示例指定行范围处理复合命令示例 实用技…...

python打卡day49
知识点回顾: 通道注意力模块复习空间注意力模块CBAM的定义 作业:尝试对今天的模型检查参数数目,并用tensorboard查看训练过程 import torch import torch.nn as nn# 定义通道注意力 class ChannelAttention(nn.Module):def __init__(self,…...

【Linux】C语言执行shell指令
在C语言中执行Shell指令 在C语言中,有几种方法可以执行Shell指令: 1. 使用system()函数 这是最简单的方法,包含在stdlib.h头文件中: #include <stdlib.h>int main() {system("ls -l"); // 执行ls -l命令retu…...

【算法训练营Day07】字符串part1
文章目录 反转字符串反转字符串II替换数字 反转字符串 题目链接:344. 反转字符串 双指针法,两个指针的元素直接调转即可 class Solution {public void reverseString(char[] s) {int head 0;int end s.length - 1;while(head < end) {char temp …...

【Web 进阶篇】优雅的接口设计:统一响应、全局异常处理与参数校验
系列回顾: 在上一篇中,我们成功地为应用集成了数据库,并使用 Spring Data JPA 实现了基本的 CRUD API。我们的应用现在能“记忆”数据了!但是,如果你仔细审视那些 API,会发现它们还很“粗糙”:有…...

ardupilot 开发环境eclipse 中import 缺少C++
目录 文章目录 目录摘要1.修复过程摘要 本节主要解决ardupilot 开发环境eclipse 中import 缺少C++,无法导入ardupilot代码,会引起查看不方便的问题。如下图所示 1.修复过程 0.安装ubuntu 软件中自带的eclipse 1.打开eclipse—Help—install new software 2.在 Work with中…...

MySQL中【正则表达式】用法
MySQL 中正则表达式通过 REGEXP 或 RLIKE 操作符实现(两者等价),用于在 WHERE 子句中进行复杂的字符串模式匹配。以下是核心用法和示例: 一、基础语法 SELECT column_name FROM table_name WHERE column_name REGEXP pattern; …...

selenium学习实战【Python爬虫】
selenium学习实战【Python爬虫】 文章目录 selenium学习实战【Python爬虫】一、声明二、学习目标三、安装依赖3.1 安装selenium库3.2 安装浏览器驱动3.2.1 查看Edge版本3.2.2 驱动安装 四、代码讲解4.1 配置浏览器4.2 加载更多4.3 寻找内容4.4 完整代码 五、报告文件爬取5.1 提…...

Rapidio门铃消息FIFO溢出机制
关于RapidIO门铃消息FIFO的溢出机制及其与中断抖动的关系,以下是深入解析: 门铃FIFO溢出的本质 在RapidIO系统中,门铃消息FIFO是硬件控制器内部的缓冲区,用于临时存储接收到的门铃消息(Doorbell Message)。…...

AI书签管理工具开发全记录(十九):嵌入资源处理
1.前言 📝 在上一篇文章中,我们完成了书签的导入导出功能。本篇文章我们研究如何处理嵌入资源,方便后续将资源打包到一个可执行文件中。 2.embed介绍 🎯 Go 1.16 引入了革命性的 embed 包,彻底改变了静态资源管理的…...