Grafana中的rate与irate以及histogram
用法
rate
rate函数用于计算一个时间序列在给定时间范围内的平均速率。它对每个数据点进行线性插值来计算速率,因此对于平滑和稳定的数据来说,rate是一个不错的选择。语法如下:
rate(metric_name[time_range])
metric_name: 指标名称。time_range: 时间范围,例如5m表示过去5分钟。
示例:
rate(http_requests_total[5m])
这个查询返回的是http_requests_total指标在过去5分钟内的平均请求速率。
irate
irate函数用于计算时间序列的瞬时速率。它仅使用时间范围内的最后两个数据点来计算速率,因此对于检测突发变化或短期波动非常有用。语法如下:
irate(metric_name[time_range])
metric_name: 指标名称。time_range: 时间范围,例如5m表示过去5分钟。
示例:
irate(http_requests_total[5m])
这个查询返回的是http_requests_total指标在过去5分钟内的瞬时请求速率。
选择rate还是irate
- 如果你需要一个平滑的平均速率,可以选择
rate。 - 如果你需要捕捉短期的突发变化或尖峰,可以选择
irate。
rate(http_requests_total[5m]) 返回的是 http_requests_total 指标在过去 5 分钟内的平均请求速率,通常可以解释为平均 QPS(每秒请求数)。
histogram_quantile
histogram_quantile 函数的语法如下:
histogram_quantile(quantile, sum(rate(metric_name_bucket[time_range])) by (le))
**quantile**: 要计算的分位数,取值范围是 0 到 1,例如 0.5 表示 50th percentile(中位数)。**metric_name_bucket**: 直方图指标的名称,_bucket是其后缀,用于表示不同的桶(bucket)。**time_range**: 用于计算速率的时间范围,例如5m表示过去 5 分钟。**le**: 桶的标签,用于按桶进行分组。
示例
假设你有一个名为 http_request_duration_seconds_bucket 的直方图指标,它记录了 HTTP 请求的延迟,并且包含以下桶:
http_request_duration_seconds_bucket{le="0.1"}http_request_duration_seconds_bucket{le="0.2"}http_request_duration_seconds_bucket{le="0.5"}http_request_duration_seconds_bucket{le="1"}http_request_duration_seconds_bucket{le="2"}http_request_duration_seconds_bucket{le="+Inf"}
要计算 95th percentile(即 0.95 分位数)的请求延迟,你可以使用以下查询:
histogram_quantile(0.95, sum(rate(http_request_duration_seconds_bucket[5m])) by (le))
查询解释
1. rate(http_request_duration_seconds_bucket[5m])
- 功能:计算每个桶在过去 5 分钟内的请求速率。
- 过程:对每个桶的计数器数据进行速率计算,这表示每秒钟有多少请求落在该桶内。
2. sum(rate(http_request_duration_seconds_bucket[5m])) by (le)
- 在 Prometheus 直方图中,
le标签用于表示桶(bucket)的上限,而不是简单的指示标签。le是 “less than or equal” 的缩写,用来指定每个桶能容纳的最大值。因此,le="0.1"表示这个桶包含了所有延迟时间小于或等于 0.1 秒的请求。 - 功能:将速率按桶的标签
le进行分组求和。 - 过程:将每个桶的速率汇总,以便能够按桶的上限(
le标签)进行分组。le标签表示每个桶的最大延迟值。例如,le="0.1"表示 延迟在0.1 秒以内的请求。
3. histogram_quantile(0.95, ...)
- 功能:计算指定分位数(0.95,即 95th percentile)的值。
- 过程:
- 累积分布:首先,根据每个桶的速率计算累积分布。累积分布函数 (CDF) 表示小于或等于某个值的请求的比例。
- 插值计算:然后,根据累积分布函数的结果插值计算 95th percentile 的值。也就是说,它在累积分布中找到 0.95 位置对应的延迟值。这个位置表示有 95% 的请求延迟小于或等于该值。
函数计算原理
rate
rate(http_requests_total[5m]) 返回的是 http_requests_total 指标在过去 5 分钟内的平均请求速率,通常可以解释为平均 QPS(每秒请求数)。
计算方法
假设 http_requests_total 是一个计数器,记录了从某个时间点开始累计的 HTTP 请求总数。计数器会随着每个新的 HTTP 请求递增。rate 函数通过以下步骤计算过去 5 分钟的平均速率:
- 选择指定时间范围内的所有数据点(例如过去 5 分钟内的所有数据点)。
- 进行线性插值,计算每个数据点之间的速率。
- 取这些速率的平均值,得到整个时间范围内的平均速率。
示例
假设我们有以下数据点在过去 5 分钟内:
- 在时间 T0,
http_requests_total的值是 1000。 - 在时间 T1(1 分钟后),
http_requests_total的值是 1100。 - 在时间 T2(2 分钟后),
http_requests_total的值是 1150。 - 在时间 T3(3 分钟后),
http_requests_total的值是 1200。 - 在时间 T4(4 分钟后),
http_requests_total的值是 1250。 - 在时间 T5(5 分钟后),
http_requests_total的值是 1300。
rate 函数会对这些数据点进行线性插值,并计算平均速率:
- 速率=Δ值 / Δ时间
每分钟的速率分别为:
- 从 T0 到 T1:1100−1000/60=1.67 QPS
- 从 T1 到 T2:1150−1100/60=0.83 QPS
- 从 T2 到 T3:1200−1150/60=0.83 QPS
- 从 T3 到 T4:1250−1200/60=0.83 QPS
- 从 T4 到 T5:1300−1250/60=0.83 QPS
然后,取这些速率的平均值:
- 平均速率=(1.67+0.83+0.83+0.83+0.83)/5=1.00 QPS
irate
irate(http_requests_total[5m]) 返回的是 http_requests_total 指标在过去 5 分钟内的瞬时请求速率。与 rate 不同,irate 只使用时间范围内的最后两个数据点来计算速率,因此它更适合捕捉短期内的突发变化或尖峰。
计算方法
- 选择过去 5 分钟内的最后两个数据点。
- 计算这两个数据点之间的增量。
- 将增量除以这两个数据点之间的时间间隔,以得到瞬时速率。
示例
假设在时间 T1 和 T2 是过去 5 分钟内的最后两个数据点:
- 在时间 T1 时,
http_requests_total的值是 1000。 - 在时间 T2 时,
http_requests_total的值是 1300。 - T1 和 T2 之间的时间间隔是 1 分钟(60 秒)。
那么,irate 的计算过程如下:
- 瞬时速率= (1300 - 1000) / 60 秒 = 5 QPS
histogram_quantile
计算方法
假设你有以下桶的速率数据(单位是每秒请求数):
le="0.1": 10 req/sle="0.2": 15 req/sle="0.5": 20 req/sle="1": 25 req/sle="2": 30 req/sle="+Inf": 35 req/s
计算过程如下:
- 计算累积分布:
le="0.1": 10 req/sle="0.2": 10 + 15 = 25 req/sle="0.5": 25 + 20 = 45 req/sle="1": 45 + 25 = 70 req/sle="2": 70 + 30 = 100 req/sle="+Inf": 100 + 35 = 135 req/s
- 计算总请求数:135 req/s
- 计算 95th percentile 的请求数:
- 95% 的请求数 = 135 * 0.95 = 128.25 req/s
- 查找对应的桶:
le="1": 70 req/s < 128.25 req/sle="2": 100 req/s < 128.25 req/sle="+Inf": 135 req/s > 128.25 req/s- 95th percentile 的请求数为 128.25 req/s,落在
le="2"桶和le="+Inf"桶之间。
- 插值计算:
- 因为
le="2"桶已经包含了绝大部分请求,实际插值计算会让我们确定 95th percentile 的延迟值接近le="2"桶的上限(即 2 秒)。实际的插值计算会让我们在le="2"桶的上限附近找到精确的值。
- 因为
插值计算公式中的“上限”
在给出的案例中:
le="2"桶的上限是 2 秒。le="+Inf"桶的上限理论上是无限大,但在实际计算中,我们用le="2"的上限值来做插值,因为le="+Inf"的上限并不提供具体的延迟值。
插值计算的详细步骤
我们已经知道:
le="2"桶的累积请求数是 100 req/s。le="+Inf"桶的累积请求数是 135 req/s。- 95th percentile 的请求数是 128.25 req/s。
我们需要在 le="2" 桶和 le="+Inf" 桶之间插值。由于 le="+Inf" 桶的具体上限不明确,我们通常将计算结果定在 le="2" 桶的上限附近。
- 计算差异:
le="2"桶的请求数:100 req/sle="+Inf"桶的请求数:135 req/s- 差异:135 req/s - 100 req/s = 35 req/s
计算插值:
- 95th percentile 的请求数是 128.25 req/s,落在
le="2"桶和le="+Inf"桶之间。 - 计算 95th percentile 在这两个桶之间的位置,可以用以下插值公式:
- 延迟值=2+((128.25−100)/(135−100)×(上限−2))
在这里,上限是指 le="+Inf" 桶的理论上限,但实际插值会以 le="2" 桶的上限(即 2 秒)作为基准。
实际插值步骤
计算插值比例:
- 比例=(128.25−100)/(135−100)=28.25/35≈0.807
计算延迟值:
- 延迟值=2+(0.807×(上限−2))
由于 le="+Inf" 的上限理论上是无限大,实际中我们将插值结果定在 le="2" 的上限附近,即 2 秒。
插值结论
在实际情况下,因为 le="+Inf" 桶的上限是无限大,实际插值计算中我们通常将 95th percentile 的延迟值定在 le="2" 桶的上限附近,即 2 秒。因此:
- 插值结果:95th percentile 的延迟值在
le="2"桶的上限(2 秒)附近。
插值计算的主要目的是找出更精确的延迟值,但由于 le="+Inf" 的上限不具体,结果一般在 le="2" 桶的上限附近。
示例
假设我们有以下桶的定义:
http_request_duration_seconds_bucket{le="0.1"}: 包含所有延迟小于或等于 0.1 秒的请求。http_request_duration_seconds_bucket{le="0.2"}: 包含所有延迟小于或等于 0.2 秒的请求。http_request_duration_seconds_bucket{le="0.5"}: 包含所有延迟小于或等于 0.5 秒的请求。http_request_duration_seconds_bucket{le="1"}: 包含所有延迟小于或等于 1 秒的请求。http_request_duration_seconds_bucket{le="+Inf"}: 包含所有延迟小于或等于无限大(即所有请求)的数据。
在直方图中,每个桶的 le 标签提供了该桶的延迟上限,使得我们能够理解请求的延迟分布情况。例如,如果你看到 http_request_duration_seconds_bucket{le="0.5"} 中的请求数为 1000,http_request_duration_seconds_bucket{le="1"} 中的请求数为 2000,那么可以得出结论:在 0.5 秒和 1 秒之间的请求数是 1000。
总结
le 标签在 Prometheus 直方图中表示桶的最大延迟值,以 “less than or equal” 的方式来说明。这样设计可以更精确地反映数据分布,并方便进行数学计算和分析。
相关文章:

Grafana中的rate与irate以及histogram
用法 rate rate函数用于计算一个时间序列在给定时间范围内的平均速率。它对每个数据点进行线性插值来计算速率,因此对于平滑和稳定的数据来说,rate是一个不错的选择。语法如下: rate(metric_name[time_range])metric_name: 指标名称。time…...

什么是网络安全态势感知
态势感知是一种基于环境的、动态、整体地洞悉安全风险的能力,是以安全大数据为基础,从全局视角提升对安全威胁的发现识别、理解分析、响应处置能力的一种方式、最终是为了决策与行动,是安全能力的落地 态势感知的重要性 随着网络与信息技术的…...

php 在app中唤起微信app进行支付,并处理回调通知
<?phpnamespace app\api\controller;use think\facade\Db; use think\facade\Log;class Wxzf {...
高效同步与处理:ADTF流服务在自动驾驶数采中的应用
目录 一、ADTF 流服务 1、流服务源(Streaming Source) 2、流服务汇(Streaming Sink) 二、数据链路 1、数据管道(Data Pipe) 2、子流(Substreams) 3、触发管道(Tri…...

【Arduino】ATmega328PB 连接 LSM6DS3 姿态传感器,并读数据(不确定 ESP 系列是否可行,但大概率是可行的)
总览 1.初始化 ATmega328PB,默认大家已经完成了 328 的配置准备工作,已经直接能够向里面写入程序 2.接线,然后验证 mega328 的 I2C 设备接口能否扫描到 LSM6DS3 3.编写代码,上传,查看串口数据。完成。 一、初始化 AT…...
live2d + edge-tts 优雅的实现数字人讲话 ~
震惊!live2d数字人竟开口说话 ~ 之前有想做数字人相关项目,查了一些方案。看了一些三方大厂的商用方案,口型有点尴尬,而且很多是采用视频流的方案,对流量的消耗很大。后来了解了live2d 技术,常在博客网页上…...

二进制安装php
下载php二进制包: 官网地址:https://www.php.net/releases/ PHP: Releaseshttps://www.php.net/releases/在里边可以选择自己要下载的包进行下载; 下载完成后进行解压: tar xvzf php-7.3.12.tar.gz 解压后 进入目录进行预编…...

旧版Pycharm支持的python版本记录
版权声明:本文为博主原创文章,如需转载请贴上原博文链接:旧版Pycharm支持的python版本记录-CSDN博客 前言:近期由于打算研究GitHub上一个开源量化交易平台开发框架,但是该框架是基于python3.10的版本开发,所…...
java实现七牛云内容审核功能,文本、图片和视频的内容审核(鉴黄、鉴暴恐、敏感人物)
目录 1、七牛云内容审核介绍 2、查看内容审核官方文档 2.1、文本内容审核 2.1.1、文本内容审核的请求示例 2.1.2、文本内容审核的返回示例 2.2、图片内容审核 2.2.1、请求参数 2.2.2、返回参数 2.3、视频内容审核 3、代码实现 3.1、前期代码准备 3.2、文本内容审核…...

C++面试基础系列-struct
系列文章目录 文章目录 系列文章目录C面试基础系列-struct1.C中struct2.C中struct2.1.同名函数2.2.typedef定义结构体别名2.3.继承 3.总结3.1.C和C中的Struct区别 4.struct字节对齐5.struct与const 关于作者 C面试基础系列-struct 1.C中struct struct里面只能放数据类型&#…...

代码随想录算法训练营 | 动态规划 part05
完全背包 有N件物品和一个最多能背重量为W的背包。第i件物品的重量是weight[i],得到的价值是value[i] 。每件物品都有无限个(也就是可以放入背包多次),求解将哪些物品装入背包里物品价值总和最大。 例子: 背包可容纳重…...

英特尔XPU大模型应用创新
...

仿Muduo库实现高并发服务器——socket网络通信模块
本项目就是基于TCP网络通信搭建的。 TCP: 客户端:socket(),connect(). 服务端:socket(),bind(),listen(),accept(). 下面代码就是对原生API网络套接字的封装。需要熟悉原生API网络套接字接口。 下面这段代码,没什么好讲的,就不…...

模型 神经网络(通俗解读)
系列文章 分享 模型,了解更多👉 模型_思维模型目录。仿脑智能,深度学习,精准识别。 1 神经网络的应用 1.1 鸢尾花分类经典问题 神经网络的一个经典且详细的经典应用是鸢尾花分类问题 。主要是通过构建一个神经网络模型来自动区分…...

事务的使用
1.如何使用事务: 1.1.事务的完成过程: 1.步骤1:开启事务2.步骤2:一系列的DML操作3.步骤3:事务结束状态:提交事务(COMMIT),中止事务(事务回滚ROLLBACK) 1.2.事务分类: …...

【免费】企业级大模型应用推荐:星环科技无涯·问知
无涯问知是星环科技发布的大模型应用系统,那么我们先简单了解下星环科技吧! 星环科技(股票代码:688031)致力于打造企业级大数据和人工智能基础软件,围绕数据的集成、存储、治理、建模、分析、挖掘和流通等数…...

从〇 搭建PO模式的Web UI自动化测试框架
Page Object模式简介 核心思想 将页面元素和操作行为封装在独立的类中,形成页面对象(Page Object)。每个页面对象代表应用程序中的一个特定页面或组件。 优点: 代码复用性高 页面对象可以在多个测试用例中复用。 易于维护 …...

在Ubuntu中重装Vscode(没有Edit Configurations(JSON)以及有错误但不标红波浪线怎么办?)
在学习时需要将vscode删除重装,市面上很多方法都不能删干净,删除之后拓展都还在。因此下面的方法可以彻底删除。注意,我安装时使用的是snap方法。 如果你的VScode没有Edit Configurations(JSON),以及有错误但不标红波浪线的话&…...

Oracle 用户-表空间-表之间关系常用SQL
问题: 当某一个表数据量特别大,突然插入数据一直失败,可能是表空间不足,需要查看表的使用率 用户-表空间-表之间关系:用户可以有多个表空间,表空间可以有多个表,表只能拥有一个表空间和用户 1.…...
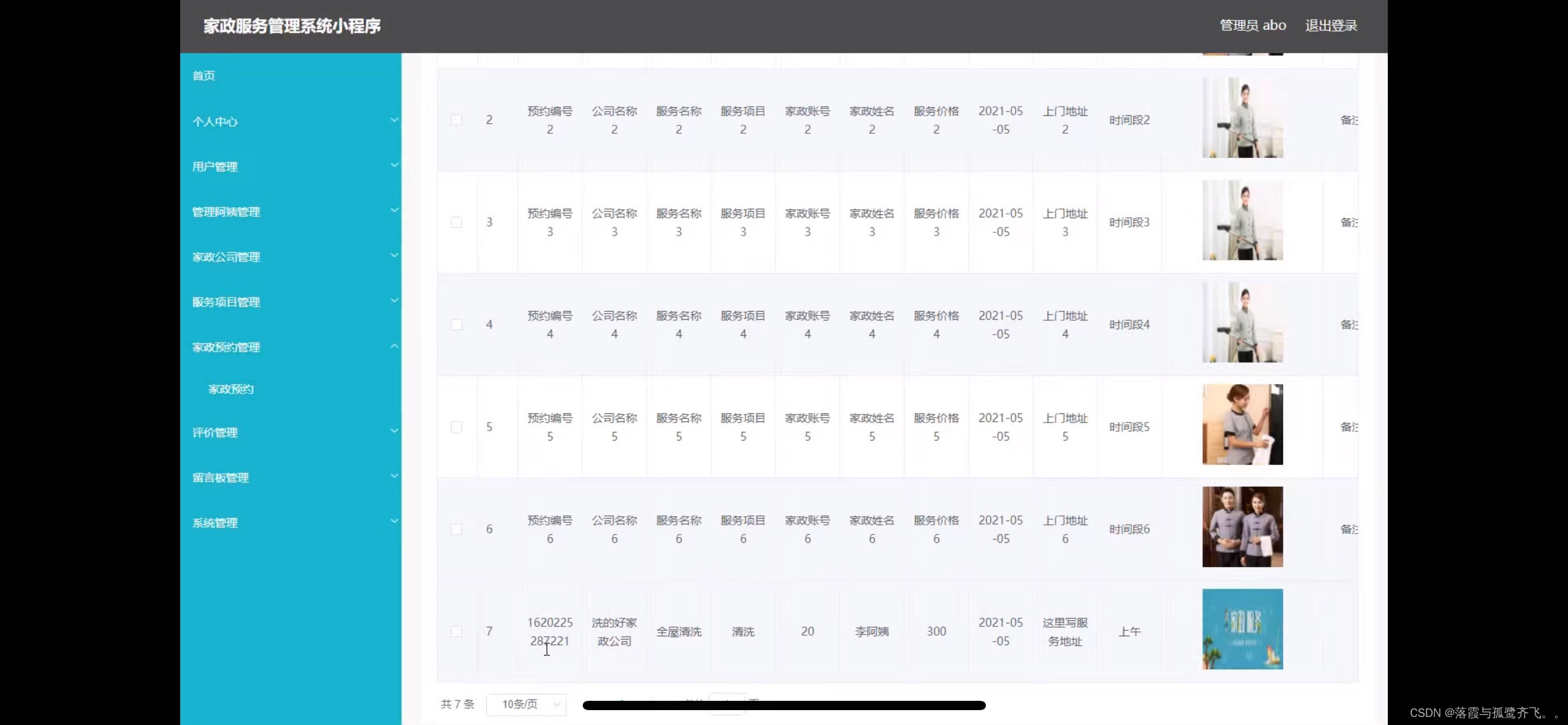
家政服务管理系统小程序的设计
管理员账户功能包括:系统首页,个人中心,用户管理,管理阿姨管理,家政公司管理,服务项目管理,家政预约管理,评价管理,留言板管理,系统管理 微信端账号功能包括…...

JavaSec-RCE
简介 RCE(Remote Code Execution),可以分为:命令注入(Command Injection)、代码注入(Code Injection) 代码注入 1.漏洞场景:Groovy代码注入 Groovy是一种基于JVM的动态语言,语法简洁,支持闭包、动态类型和Java互操作性,…...

在鸿蒙HarmonyOS 5中实现抖音风格的点赞功能
下面我将详细介绍如何使用HarmonyOS SDK在HarmonyOS 5中实现类似抖音的点赞功能,包括动画效果、数据同步和交互优化。 1. 基础点赞功能实现 1.1 创建数据模型 // VideoModel.ets export class VideoModel {id: string "";title: string ""…...

【大模型RAG】Docker 一键部署 Milvus 完整攻略
本文概要 Milvus 2.5 Stand-alone 版可通过 Docker 在几分钟内完成安装;只需暴露 19530(gRPC)与 9091(HTTP/WebUI)两个端口,即可让本地电脑通过 PyMilvus 或浏览器访问远程 Linux 服务器上的 Milvus。下面…...

测试markdown--肇兴
day1: 1、去程:7:04 --11:32高铁 高铁右转上售票大厅2楼,穿过候车厅下一楼,上大巴车 ¥10/人 **2、到达:**12点多到达寨子,买门票,美团/抖音:¥78人 3、中饭&a…...

Psychopy音频的使用
Psychopy音频的使用 本文主要解决以下问题: 指定音频引擎与设备;播放音频文件 本文所使用的环境: Python3.10 numpy2.2.6 psychopy2025.1.1 psychtoolbox3.0.19.14 一、音频配置 Psychopy文档链接为Sound - for audio playback — Psy…...
)
WEB3全栈开发——面试专业技能点P2智能合约开发(Solidity)
一、Solidity合约开发 下面是 Solidity 合约开发 的概念、代码示例及讲解,适合用作学习或写简历项目背景说明。 🧠 一、概念简介:Solidity 合约开发 Solidity 是一种专门为 以太坊(Ethereum)平台编写智能合约的高级编…...

工业自动化时代的精准装配革新:迁移科技3D视觉系统如何重塑机器人定位装配
AI3D视觉的工业赋能者 迁移科技成立于2017年,作为行业领先的3D工业相机及视觉系统供应商,累计完成数亿元融资。其核心技术覆盖硬件设计、算法优化及软件集成,通过稳定、易用、高回报的AI3D视觉系统,为汽车、新能源、金属制造等行…...

AI编程--插件对比分析:CodeRider、GitHub Copilot及其他
AI编程插件对比分析:CodeRider、GitHub Copilot及其他 随着人工智能技术的快速发展,AI编程插件已成为提升开发者生产力的重要工具。CodeRider和GitHub Copilot作为市场上的领先者,分别以其独特的特性和生态系统吸引了大量开发者。本文将从功…...

Android15默认授权浮窗权限
我们经常有那种需求,客户需要定制的apk集成在ROM中,并且默认授予其【显示在其他应用的上层】权限,也就是我们常说的浮窗权限,那么我们就可以通过以下方法在wms、ams等系统服务的systemReady()方法中调用即可实现预置应用默认授权浮…...

蓝桥杯3498 01串的熵
问题描述 对于一个长度为 23333333的 01 串, 如果其信息熵为 11625907.5798, 且 0 出现次数比 1 少, 那么这个 01 串中 0 出现了多少次? #include<iostream> #include<cmath> using namespace std;int n 23333333;int main() {//枚举 0 出现的次数//因…...