Spark-序列化、依赖关系、持久化
序列化
闭包检查
序列化方法和属性
依赖关系
RDD 血缘关系
RDD 窄依赖
RDD 宽依赖
RDD 任务划分
RDD 持久化
RDD Cache 缓存
RDD CheckPoint 检查点
缓存和检查点区别
序列化
闭包检查
从计算的角度, 算子以外的代码都是在 Driver 端执行, 算子里面的代码都是在 Executor 端执行。那么在 scala 的函数式编程中,就会导致算子内经常会用到算子外的数据,这样就 形成了闭包的效果,如果使用的算子外的数据无法序列化,就意味着无法传值给 Executor 端执行,就会发生错误,所以需要在执行任务计算前,检测闭包内的对象是否可以进行序列 化,这个操作我们称之为闭包检测。Scala2.12 版本后闭包编译方式发生了改变
序列化方法和属性
从计算的角度, 算子以外的代码都是在 Driver 端执行, 算子里面的代码都是在 Executor 端执行。
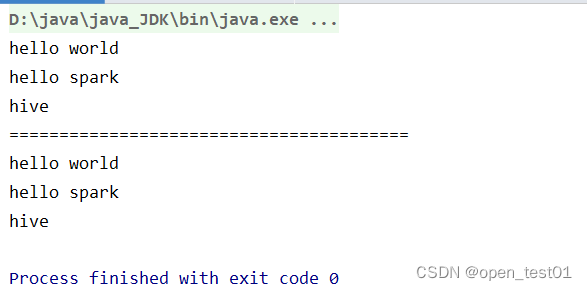
object spark_02 {def main(args: Array[String]): Unit = {//准备环境//"*"代表线程的核数 应用程序名称"RDD"val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")val sc = new SparkContext(sparkConf)val rdd: RDD[String] = sc.makeRDD(Array("hello world", "hello spark", "hive", "atguigu"))//创建查询对象val search = new Search("h")//函数传递,打印:ERROR Task not serializablesearch.getMatch1(rdd).collect().foreach(println)println("========================================")//属性传递,打印:ERROR Task not serializablesearch.getMatch2(rdd).collect().foreach(println)//关闭环境sc.stop()}
}//查询对象
//类的构造参数是类的属性,构造参数需要进行闭包检查(对类进行闭包检查)
class Search(query:String) extends Serializable {def isMatch(s: String): Boolean = {s.contains(query)}// 函数序列化案例def getMatch1 (rdd: RDD[String]): RDD[String] = {rdd.filter(isMatch)}// 属性序列化案例def getMatch2(rdd: RDD[String]): RDD[String] = {rdd.filter(x => x.contains(query))}
}
依赖关系
相邻的两个RDD关系称之为依赖关系
RDD 血缘关系
多个连续的RDD的依赖关系称之为血缘关系
RDD 只支持粗粒度转换,即在大量记录上执行的单个操作。将创建 RDD 的一系列 Lineage (血统)记录下来,以便恢复丢失的分区。RDD 的 Lineage 会记录 RDD 的元数据信息和转 换行为,当该 RDD 的部分分区数据丢失时,它可以根据这些信息来重新运算和恢复丢失的 数据分区。
val fileRDD: RDD[String] = sc.textFile("input/1.txt")
println(fileRDD.toDebugString) //打印输出血缘关系
println("----------------------")
val wordRDD: RDD[String] = fileRDD.flatMap(_.split(" "))
println(wordRDD.toDebugString)
println("----------------------")
val mapRDD: RDD[(String, Int)] = wordRDD.map((_,1))
println(mapRDD.toDebugString)
println("----------------------")
val resultRDD: RDD[(String, Int)] = mapRDD.reduceByKey(_+_)
println(resultRDD.toDebugString)
resultRDD.collect()RDD 窄依赖
窄依赖表示每一个父(上游)RDD 的 Partition 最多被子(下游)RDD 的一个 Partition 使用, 窄依赖我们形象的比喻为独生子女。
RDD 宽依赖
宽依赖表示同一个父(上游)RDD 的 Partition 被多个子(下游)RDD 的 Partition 依赖,会 引起 Shuffle,总结:宽依赖我们形象的比喻为多生。
RDD 任务划分
RDD 任务切分中间分为:Application、Job、Stage 和 Task:
- Application:初始化一个 SparkContext 即生成一个 Application;
- Job:一个 Action 算子就会生成一个 Job;
- Stage:Stage 等于宽依赖(ShuffleDependency)的个数加 1;
- Task:一个 Stage 阶段中,最后一个 RDD 的分区个数就是 Task 的个数。
注意:Application->Job->Stage->Task 每一层都是 1 对 n 的关系。
RDD 持久化
RDD Cache 缓存
RDD 通过 Cache 或者 Persist 方法将前面的计算结果缓存,默认情况下会把数据以缓存 在 JVM 的堆内存中。但是并不是这两个方法被调用时立即缓存,而是触发后面的 action 算 子时,该 RDD 将会被缓存在计算节点的内存中,并供后面重用。
// cache 操作会增加血缘关系,不改变原有的血缘关系
println(wordToOneRdd.toDebugString)
// 数据缓存。
wordToOneRdd.cache()
// 可以更改存储级别
//mapRdd.persist(StorageLevel.MEMORY_AND_DISK_2)
缓存有可能丢失,或者存储于内存的数据由于内存不足而被删除,RDD 的缓存容错机 制保证了即使缓存丢失也能保证计算的正确执行。通过基于 RDD 的一系列转换,丢失的数 据会被重算,由于 RDD 的各个 Partition 是相对独立的,因此只需要计算丢失的部分即可, 并不需要重算全部 Partition。 Spark 会自动对一些 Shuffle 操作的中间数据做持久化操作(比如:reduceByKey)。这样 做的目的是为了当一个节点 Shuffle 失败了避免重新计算整个输入。但是,在实际使用的时 候,如果想重用数据,仍然建议调用 persist 或 cache。
RDD CheckPoint 检查点
所谓的检查点其实就是通过将 RDD 中间结果写入磁盘 由于血缘依赖过长会造成容错成本过高,这样就不如在中间阶段做检查点容错,如果检查点 之后有节点出现问题,可以从检查点开始重做血缘,减少了开销。 对 RDD 进行 checkpoint 操作并不会马上被执行,必须执行 Action 操作才能触发。
// 设置检查点路径
sc.setCheckpointDir("./checkpoint1")
// 创建一个 RDD,读取指定位置文件:hello atguigu atguigu
val lineRdd: RDD[String] = sc.textFile("input/1.txt")
// 业务逻辑
val wordRdd: RDD[String] = lineRdd.flatMap(line => line.split(" "))
val wordToOneRdd: RDD[(String, Long)] = wordRdd.map {word => {(word, System.currentTimeMillis())}
}
// 增加缓存,避免再重新跑一个 job 做 checkpoint
wordToOneRdd.cache()
// 数据检查点:针对 wordToOneRdd 做检查点计算
wordToOneRdd.checkpoint()
// 触发执行逻辑
wordToOneRdd.collect().foreach(println)
缓存和检查点区别
- Cache 缓存只是将数据保存起来,不切断血缘依赖。Checkpoint 检查点切断血缘依赖。
- Cache 缓存的数据通常存储在磁盘、内存等地方,可靠性低。Checkpoint 的数据通常存 储在 HDFS 等容错、高可用的文件系统,可靠性高。
- 建议对 checkpoint()的 RDD 使用 Cache 缓存,这样 checkpoint 的 job 只需从 Cache 缓存 中读取数据即可,否则需要再从头计算一次 RDD。
相关文章:
Spark-序列化、依赖关系、持久化
序列化 闭包检查 序列化方法和属性 依赖关系 RDD 血缘关系 RDD 窄依赖 RDD 宽依赖 RDD 任务划分 RDD 持久化 RDD Cache 缓存 RDD CheckPoint 检查点 缓存和检查点区别 序列化 闭包检查 从计算的角度, 算子以外的代码都是在 Driver 端执行, 算子里面的代码都是在 E…...

蓝桥杯刷题冲刺 | 倒计时16天
作者:指针不指南吗 专栏:蓝桥杯倒计时冲刺 🐾马上就要蓝桥杯了,最后的这几天尤为重要,不可懈怠哦🐾 文章目录1.青蛙跳杯子1.青蛙跳杯子 题目 链接: 青蛙跳杯子 - 蓝桥云课 (lanqiao.cn) X 星球的…...

Java设计模式-12 、建造者模式
建造者模式 (将一个 复杂对象的构建与它的表示分离,使得同样的构建过程可以创建不同的表示。) 建造者模式是一种创建型的模式,有一些对象的创建过程new 是很繁杂的。 什么时候去使用建造者模式 由上文可以得出在一些对象创建…...
一款全新的基于GPT4的Python神器,关键还免费
chartgpt大火之后,随之而来的就是一大类衍生物了。 然后,今天要给大家介绍的是一款基于GPT4的新一代辅助编程神器——Cursor。 它最值得介绍的地方在于它免费,我们可以直接利用它来辅助我们编程,真正做到事半功倍。 注意&#…...

上岸整理:2023前端面试题-vue,小程序,js,css
前端: 今年疫情结束后,前端行情不好,竞争压力很大,现在整理下个人认为面试很频繁的前端问题。 正题:无分类,因为面试官的问题也是随机的 一、基础 1、浏览器常见的报错信息与含义 2、304与204的区别&am…...

Linux下LED设备驱动开发(LED灯实现闪烁)
文章目录一、配置连接说明二、更新设备树(1)将led灯引脚添加到pinctrl子系统(2)设备树中添加LDE灯的设备树节点(3)编译更新设备树三、驱动开发与测试(1)编写设备驱动代码(…...
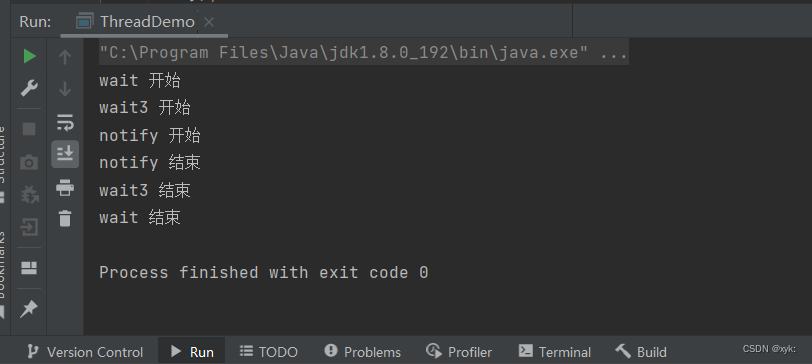
JavaEE-多线程中wait和notify都有哪些区别?
更多内容请点击了解 本篇文章将详细讲述wait和notify的区别,请往下看 目录 更多内容请点击了解 文章目录 一、wait和notify概念 二、wait()方法详解 三、notify()方法详解 代码如下: 3.1notifyAll()详解 四、wait和sleep的对比 一、wait和notif…...

JavaScript实现列表分页(小白版)
组件用惯了,突然叫你用纯cssJavaScript写一个分页,顿时就慌了。久久没有接触js了,不知道咋写了。本文章也是借与参考做的一个demo案例,小白看了都会的那种。咱们就以ul列表为例进行分页: 首先模拟的数据列表是这样的&a…...

Python调用GPT3.5接口的最新方法
GPT3.5接口调用方法主要包括openai安装、api_requestor.py替换、接口调用、示例程序说明四个部分。 1 openai安装 Python openai库可直接通过pip install openai安装。如果已经安装openai,但是后续提示找不到ChatCompletion,那么请使用命令“pip instal…...

Java开发 - 拦截器初体验
目录 前言 拦截器 什么是拦截器 拦截器和过滤器 Spring MVC的拦截器 Mybatis的拦截器...

【数据仓库-7】-- 使用维度建模的一些缘由
维度建模是一种用于设计数据仓库和商业智能系统的方法。以下是选择维度建模的两类理由。 1.传统方法,有背书且可靠 易于理解和使用:维度建模使用直观的图形和术语,使得非技术人员也能够理解和使用数据仓库和商业智能系统。 快速开发和部署:维度建模是一种迭代开发方法,能…...

【开发实践】在线考试系统(一) 生成错题知识点的思维导图
一、需求分析设计 笔者开发了一个在线考试系统,导师提出一个需求:添加对考试错题相关知识点的总结。 在question表中关联知识点的编号,题目可能关联多个知识点。这里笔者的设计是,只关联一个知识点,便于维护。 下面是知…...

Java Web 实战 17 - 计算机网络之传输层协议(2)
大家好 , 这篇文章继续给大家讲解 TCP 协议当中的一些操作 , 比如 : 滑动窗口、流量控制、拥塞控制、延时应答、捎带应答、面向字节流这几个提升 TCP 效率的操作 . 我们还会给大家分析 TCP 连接出现异常的时候 , 该如何处理 . 最后会将 TCP 和 UDP 进行比较 上一篇文章的链接也…...
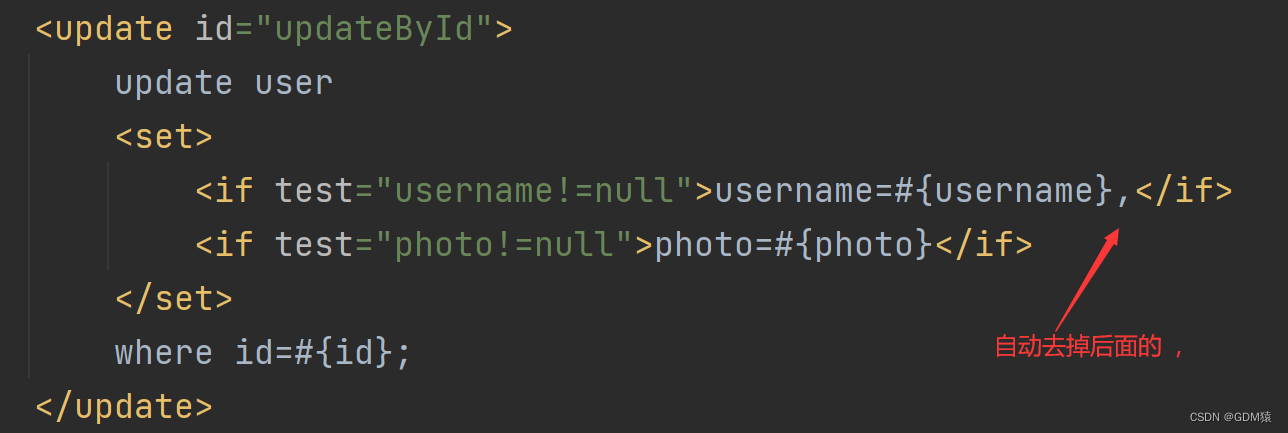
MyBatis<3>:动态SQL的使用<if><trim><where><set><foreach>
动态SQL是MyBatis的强大特性之一,能够完成不同条件下不同的sql拼接。参考官方文档:https://mybatis.org/mybatis-3/zh/dynamic-sql.html<if>标签看这个场景,有必填字段 和 非必填字段 ,当字段不确定是否传入的时候ÿ…...

【超好懂的比赛题解】暨南大学2023东软教育杯ACM校赛个人题解
title : 暨南大学2023东软教育杯ACM校赛 题解 tags : ACM,练习记录 date : 2023-3-26 author : Linno 文章目录暨南大学2023东软教育杯ACM校赛 题解A-小王的魔法B-苏神的遗憾C-神父的碟D-基站建设E-小王的数字F-Uziの真身G-电子围棋H-二分大法I-丁真的小马朋友们J-单车运营K-超…...

go-zero学习及使用中遇到的问题
go-zero学习及使用中遇到的问题1 go-zero入门--单体服务demo1.1 单体服务【官方示例】1.1.1 创建greet服务1.1.2 目录结构1.1.3 编写逻辑1.1.4 启动并访问服务1.2 修改GET入参1.2.1 去除options限制的入参值1.2.2 重启并访问服务1.3 添加post请求【新增方法】1.3.1 修改 greet/…...
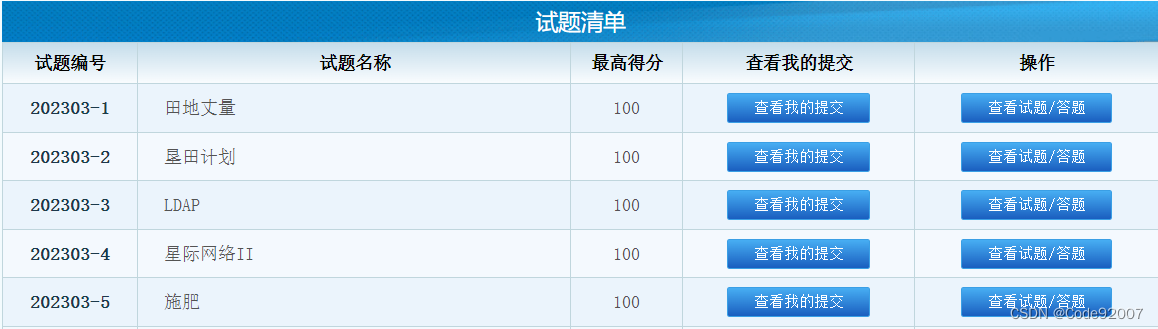
CCF-CSP认证 202303 500分题解
202303-1 田地丈量(矩阵面积交) 矩阵面积交x轴线段交长度*y轴线段交长度 线段交长度,相交的时候是min右端点-max左端点,不相交的时候是0 #include<bits/stdc.h> using namespace std; int n,a,b,ans,x,y,x2,y2; int f(in…...

板内盘中孔设计狂飙,细密间距线路中招
一博高速先生成员:王辉东大风起兮云飞扬,投板兮人心舒畅。赵理工打了哈欠,伸了个懒腰,看了看窗外,对林如烟说道:“春天虽美,但是容易让人沉醉。如烟,快女神节了,要不今晚…...
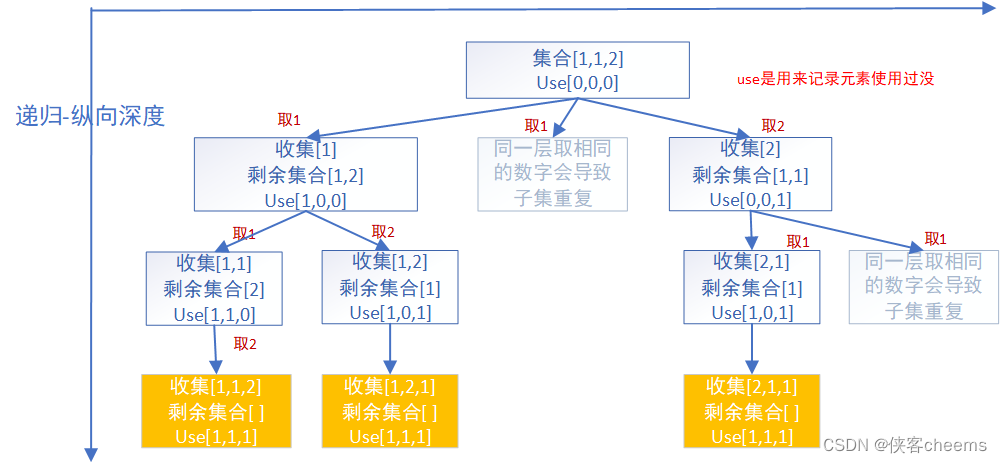
面试热点题:回溯算法 递增子序列与全排列 II
前言: 如果你一点也不了解什么叫做回溯算法,那么推荐你看看这一篇回溯入门,让你快速了解回溯算法的基本原理及框架 递增子序列 给你一个整数数组 nums ,找出并返回所有该数组中不同的递增子序列,递增子序列中 至少有两…...

怎么找回回收站删除的文件
我们都知道,电脑文件都是放在桌面上的,单独存放或者一起存放在文件夹里。但总会有已用完或者是没用的文件,这让我们不得不对其进行清理。而清空回收站也是不可避免的。如果出现了清空文件中还有我们需要的文件,怎么找回回收站删除…...

Qt/C++开发监控GB28181系统/取流协议/同时支持udp/tcp被动/tcp主动
一、前言说明 在2011版本的gb28181协议中,拉取视频流只要求udp方式,从2016开始要求新增支持tcp被动和tcp主动两种方式,udp理论上会丢包的,所以实际使用过程可能会出现画面花屏的情况,而tcp肯定不丢包,起码…...

【网络安全产品大调研系列】2. 体验漏洞扫描
前言 2023 年漏洞扫描服务市场规模预计为 3.06(十亿美元)。漏洞扫描服务市场行业预计将从 2024 年的 3.48(十亿美元)增长到 2032 年的 9.54(十亿美元)。预测期内漏洞扫描服务市场 CAGR(增长率&…...

【Zephyr 系列 10】实战项目:打造一个蓝牙传感器终端 + 网关系统(完整架构与全栈实现)
🧠关键词:Zephyr、BLE、终端、网关、广播、连接、传感器、数据采集、低功耗、系统集成 📌目标读者:希望基于 Zephyr 构建 BLE 系统架构、实现终端与网关协作、具备产品交付能力的开发者 📊篇幅字数:约 5200 字 ✨ 项目总览 在物联网实际项目中,**“终端 + 网关”**是…...
)
相机Camera日志分析之三十一:高通Camx HAL十种流程基础分析关键字汇总(后续持续更新中)
【关注我,后续持续新增专题博文,谢谢!!!】 上一篇我们讲了:有对最普通的场景进行各个日志注释讲解,但相机场景太多,日志差异也巨大。后面将展示各种场景下的日志。 通过notepad++打开场景下的日志,通过下列分类关键字搜索,即可清晰的分析不同场景的相机运行流程差异…...

【HTML-16】深入理解HTML中的块元素与行内元素
HTML元素根据其显示特性可以分为两大类:块元素(Block-level Elements)和行内元素(Inline Elements)。理解这两者的区别对于构建良好的网页布局至关重要。本文将全面解析这两种元素的特性、区别以及实际应用场景。 1. 块元素(Block-level Elements) 1.1 基本特性 …...

Spring AI 入门:Java 开发者的生成式 AI 实践之路
一、Spring AI 简介 在人工智能技术快速迭代的今天,Spring AI 作为 Spring 生态系统的新生力量,正在成为 Java 开发者拥抱生成式 AI 的最佳选择。该框架通过模块化设计实现了与主流 AI 服务(如 OpenAI、Anthropic)的无缝对接&…...

多种风格导航菜单 HTML 实现(附源码)
下面我将为您展示 6 种不同风格的导航菜单实现,每种都包含完整 HTML、CSS 和 JavaScript 代码。 1. 简约水平导航栏 <!DOCTYPE html> <html lang"zh-CN"> <head><meta charset"UTF-8"><meta name"viewport&qu…...

DeepSeek 技术赋能无人农场协同作业:用 AI 重构农田管理 “神经网”
目录 一、引言二、DeepSeek 技术大揭秘2.1 核心架构解析2.2 关键技术剖析 三、智能农业无人农场协同作业现状3.1 发展现状概述3.2 协同作业模式介绍 四、DeepSeek 的 “农场奇妙游”4.1 数据处理与分析4.2 作物生长监测与预测4.3 病虫害防治4.4 农机协同作业调度 五、实际案例大…...
2025-05-08-deepseek本地化部署
title: 2025-05-08-deepseek 本地化部署 tags: 深度学习 程序开发 2025-05-08-deepseek 本地化部署 参考博客 本地部署 DeepSeek:小白也能轻松搞定! 如何给本地部署的 DeepSeek 投喂数据,让他更懂你 [实验目的]:理解系统架构与原…...
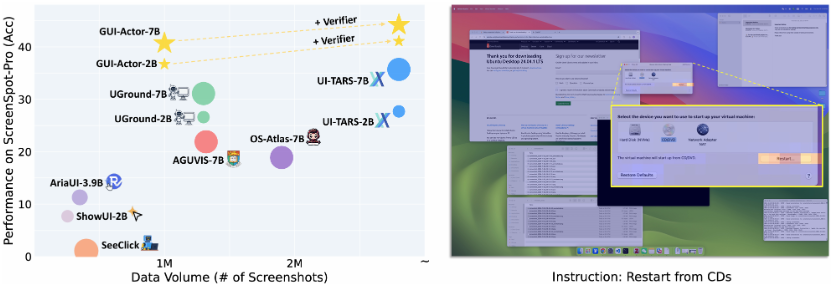
【AI News | 20250609】每日AI进展
AI Repos 1、OpenHands-Versa OpenHands-Versa 是一个通用型 AI 智能体,通过结合代码编辑与执行、网络搜索、多模态网络浏览和文件访问等通用工具,在软件工程、网络导航和工作流自动化等多个领域展现出卓越性能。它在 SWE-Bench Multimodal、GAIA 和 Th…...