[Few-shot learning] Siamese neural networks
这篇文章主要介绍的是Siamese Neural Network经典论文: Gregory Koch, et al., Siamese Neural Networks for One-shot Image Recognition. ICML 2015。
神经网络能够取得非常好的效果得益于使用大量的带标签数据进行有监督学习训练。但是这样的训练方法面临两个难题:
- 有些情况下我们无法采集到大量数据;
- 给数据打标签需要消耗大量人力财力。
当我们只有少量带标签的数据时如何训练出一个泛化性很好的模型呢?因此,few-shot learning问题应用而生。Few-shot learning仅需要每个类别含有少量带标签数据就可以对样本进行分类。
Gregory Koch等人提出了一种新的机器学习框架,当每个待测类别仅有1个样本的时候也能取得超过90%的识别准确率。
1. Omniglot数据集
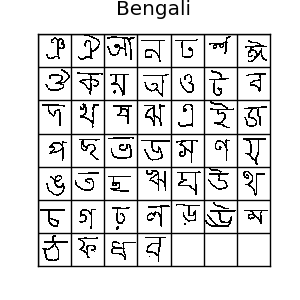
《Siamese Neural Networks for One-shot Image Recognition》论文中使用了Omniglot数据集。Omniglot数据集是Few-shot Learning中常用的数据集,它采集了来自50个字母表的1623个手写字符。每一个字符仅仅包含20个样本,每一个样本都是来自于不同人的手写笔迹。样本图片的分辨率为105x105。
这面展示几个手写字符:
 | |
 | |
 | |
 |
Omniglot数据集的下载方法:
git clone https://github.com/brendenlake/omniglot.git
cd omniglot/python
unzip images_evaluation.zip
unzip images_background.zip
cd ../..
# setup directory for saving models
mkdir models
Omniglot数据集通常被划分为30个训练字母表(background),20个测试字母表(evaluation)。这30个训练样本和20个测试样本是完全没有交际的,也就是说测试样本集中的类别完全是一个新的类别。这也是few-shot learning和传统的supervised learning不同的地方。
2. A one-shot learning baseline / 1 nearest neighbor
对于nnn-way 111-shot问题,由于我们手中只有一个样本,所以没有办法训练得到一个泛化性很好的神经网络模型。最简单的方法是K-nearest neighbours,只需计算测试样本到训练样本的欧式距离,然后选择最近的一个作为预测标签:
C(x^)=argmin∣∣x^−xc∣∣C(\hat{x})=\text{argmin}||\hat{x}-x_c|| C(x^)=argmin∣∣x^−xc∣∣
论文中显示,1-nn在202020-way 111-shot任务上的准确率为28%,而盲猜的正确率只有5%。因此,1-nn对于解决one-shot问题还是有用的,但是效果并不理想,但可以作为一个baseline。
3. Siamese Neural Networks
由于训练样本太少,用它来训练网络肯定会造成过拟合,所以我们不能像传统的有监督学习那样其训练分类模型,而是要让模型如何区分不同。
Siamese Networks即孪生网络,他们共享一部分网络结构。将两张图片输入到网络中得到两个特在向量。我们用向量的绝对差值度量两张图片的相似性。Siamese网络的结构图如下所示:
[图片上传失败…(image-275fb8-1679970385410)]
Siamese网络使用相同的特征提取网络提取特在得到两个向量,然后训练步骤为:
- 将两个样本分别输入到两个网络中,得到两个特征向量
x1和x2; - 计算向量的L1距离,
dis = np.abs(x1 - x2); - 将距离
dis输入到一个全连接网络中,全连接网络的神经元个数是1; - 经过Sigmoid函数得到预测输出,介于0-1之间。0表示两个样本属于不同类别,1表示两个样本属于同一类别。
- 使用二元交叉熵损失函数计算loss,反向传播更新参数。
对于kkk-way 111-shot问题,我们需要比较querry set样本与kkk个support sample的score,选择score最大的support sample作为标签。例如下图的252525-way 111-shot问题,相似度越高,Siamese 网络的输出值越大,因此可以确定query sample 的类别。
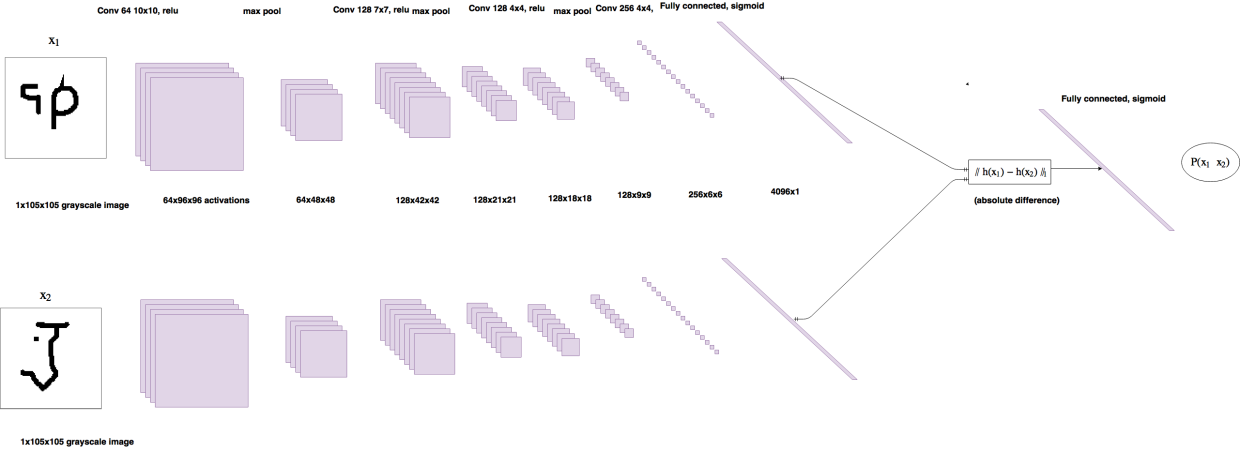
论文中模型的一般部署方法在Pytorch中的实现如下(参考4):
import torch.nn as nn
class Siamese(nn.Module):def __init__(self):super(Siamese, self).__init__()self.conv = nn.Sequential(nn.Conv2d(1, 64, 10), # 64@96*96nn.ReLU(inplace=True),nn.MaxPool2d(2), # 64@48*48nn.Conv2d(64, 128, 7),nn.ReLU(), # 128@42*42nn.MaxPool2d(2), # 128@21*21nn.Conv2d(128, 128, 4),nn.ReLU(), # 128@18*18nn.MaxPool2d(2), # 128@9*9nn.Conv2d(128, 256, 4),nn.ReLU(), # 256@6*6)self.liner = nn.Sequential(nn.Linear(9216, 4096), nn.Sigmoid())self.out = nn.Linear(4096, 1)def forward_one(self, x):x = self.conv(x)x = x.view(x.size()[0], -1)x = self.liner(x)return xdef forward(self, x1, x2):out1 = self.forward_one(x1)out2 = self.forward_one(x2)dis = torch.abs(out1 - out2)out = self.out(dis)return out
损失函数使用torch.nn.BCEWithLogitsLoss(size_average=True)函数。torch.nn.BCELoss函数,如果输出经过了nn.Sigmoid(),则损失函数就用torch.nn.BCELoss。
loss_fn = torch.nn.BCEWithLogitsLoss(size_average=True)
net = Siamese()
optimizer.zero_grad()
output = net.forward(img1, img2)
loss = loss_fn(output, label)
loss_val += loss.item()
loss.backward()
optimizer.step()
4. Few-shot task
4.1 Training tasks
Few-shot learnig的难点在于如何生成training tasks和test tasks, 这里我参考文献4的方法:
class OmniglotTrain(Dataset):def __init__(self, dataPath, transform=None):super(OmniglotTrain, self).__init__()np.random.seed(0)# self.dataset = datasetself.transform = transformself.datas, self.num_classes = self.loadToMem(dataPath)def loadToMem(self, dataPath):print("begin loading training dataset to memory")datas = {}agrees = [0, 90, 180, 270]idx = 0for agree in agrees:for alphaPath in os.listdir(dataPath):for charPath in os.listdir(os.path.join(dataPath, alphaPath)):datas[idx] = []for samplePath in os.listdir(os.path.join(dataPath, alphaPath, charPath)):filePath = os.path.join(dataPath, alphaPath, charPath, samplePath)datas[idx].append(Image.open(filePath).rotate(agree).convert('L'))idx += 1print("finish loading training dataset to memory")return datas,idxdef __len__(self):return 21000000def __getitem__(self, index):# image1 = random.choice(self.dataset.imgs)label = Noneimg1 = Noneimg2 = None# get image from same classif index % 2 == 1: # odd numberlabel = 1.0idx1 = random.randint(0, self.num_classes - 1)image1 = random.choice(self.datas[idx1])image2 = random.choice(self.datas[idx1])# get image from different classelse: # even numberlabel = 0.0idx1 = random.randint(0, self.num_classes - 1)idx2 = random.randint(0, self.num_classes - 1)while idx1 == idx2:idx2 = random.randint(0, self.num_classes - 1)image1 = random.choice(self.datas[idx1])image2 = random.choice(self.datas[idx2])if self.transform:image1 = self.transform(image1)image2 = self.transform(image2)return image1, image2, torch.from_numpy(np.array([label], dtype=np.float32))
这个方法方法比较常规,就是随即产生image pair,属于统一个字符标签为1,不属于标签为0。
然后使用
trainSet = OmniglotTrain(train_path, transform=data_transforms)
trainLoader = DataLoader(trainSet, batch_size=batch_size, shuffle=False, num_workers=workers)
调用即可。
4.2 Test tasks
需要着重注意的是测试集任务:
class OmniglotTest(Dataset):def __init__(self, dataPath, transform=None, times=200, way=20):np.random.seed(1)super(OmniglotTest, self).__init__()self.transform = transformself.times = times # number of samples, 参与测试的样本数量self.way = wayself.img1 = Noneself.c1 = Noneself.datas, self.num_classes = self.loadToMem(dataPath)def loadToMem(self, dataPath):print("begin loading test dataset to memory")datas = {}idx = 0for alphaPath in os.listdir(dataPath):for charPath in os.listdir(os.path.join(dataPath, alphaPath)):datas[idx] = []for samplePath in os.listdir(os.path.join(dataPath, alphaPath, charPath)):filePath = os.path.join(dataPath, alphaPath, charPath, samplePath)datas[idx].append(Image.open(filePath).convert('L'))idx += 1print("finish loading test dataset to memory")return datas, idxdef __len__(self):return self.times * self.waydef __getitem__(self, index):idx = index % self.waylabel = None# generate image pair from same classif idx == 0:self.c1 = random.randint(0, self.num_classes - 1)self.img1 = random.choice(self.datas[self.c1])img2 = random.choice(self.datas[self.c1])# generate image pair from different classelse:c2 = random.randint(0, self.num_classes - 1)while self.c1 == c2:c2 = random.randint(0, self.num_classes - 1)img2 = random.choice(self.datas[c2]) if self.transform:img1 = self.transform(self.img1)img2 = self.transform(img2)return img1, img2
这里需要提前了解到的一个前提是:
testSet = OmniglotTest(Flags.test_path, transform=transforms.ToTensor(), times = times, way = way)
testLoader = DataLoader(testSet, batch_size=way, shuffle=False, num_workers=workers)
这里loadToMem函数是往每一个character的往容器中存放数据,而每一个character有20个样本,所以self.datas中每20个样本为一个character,整个测试集evaluation数据集有659个character,每个chatacter共有20个样本,所以共有659*20=13180个样本。
这里要注意的是testLoader的shuffle的参数False,也就是说测试集是从第0个索引开始一个一个读取的。所以每一个epoch刚好是读取了一个类别的20个样本,也就是每次只判断一个类别预测结果的对错。
好了,现在我们来看看__getitem__函数。由于索引是从0开始,一次20个,所以第一个batch的索引为0-20,从0开始一次读取image。因此,必然会经过if idx == 0判断条件。运行步骤为:
- index = 0
- idx = index % 20 = 0
- if idx == 0成立,从所有类别中随即选择一个类别,在该类别下随机选择两张图片img1, img2
- index = 1,2,3,4,…,19
- idx = index % 20 = 1,2,3,4,…,19
- if idx == 0不成立,进入else语句,随即选择两个不同类别的图片img1, img2
- 第一个batch完成,判断batch是否读取完成,若是则退出循环,否则index+1,返回步骤2
这里测试的代码为:
for _, (test1, test2) in enumerate(testLoader, 1):test1, test2 = test1.cuda(), test2.cuda()test1, test2 = Variable(test1), Variable(test2)output = net.forward(test1, test2).data.cpu().numpy()pred = np.argmax(output)if pred == 0:right += 1else: error += 1
因为每个batch只有第一个img pair是相同的,如果预测正确,np.argmax(output)是0
本文原载于我的简书
Reference
- One Shot Learning and Siamese Networks in Keras
- Github - One-Shot-Learning-with-Siamese-Networks (Keras)
- Github - Pokemon: Siamese-Network-with-Contrastive-loss
- Github - Siamese Networks for One-Shot Learning (pytorch)
相关文章:
[Few-shot learning] Siamese neural networks
这篇文章主要介绍的是Siamese Neural Network经典论文: Gregory Koch, et al., Siamese Neural Networks for One-shot Image Recognition. ICML 2015。 神经网络能够取得非常好的效果得益于使用大量的带标签数据进行有监督学习训练。但是这样的训练方法面临两个难题…...

利用qiankun框架在自己项目中集成拖拽式低代码数据可视化开发平台
目前微前端已经是很成熟的技术了,各大公司都推出了自己的微前端框架,比如蚂蚁的qiankun,京东的micro-app,如果你的子应用不使用vite构建的话,我会更加推荐后者,micro-app使用更加简单,micro-app…...

【spring boot】在Java中操作缓存:
文章目录一、Jedis二、Spring Data Redis(常用)【1】pom.xml【2】application.yml【3】RedisConfig【4】RuiJiWaiMaiApplicationTests三、Spring Cache【1】常用注解:【2】使用案例【3】底层不使用redis,重启服务,内存…...
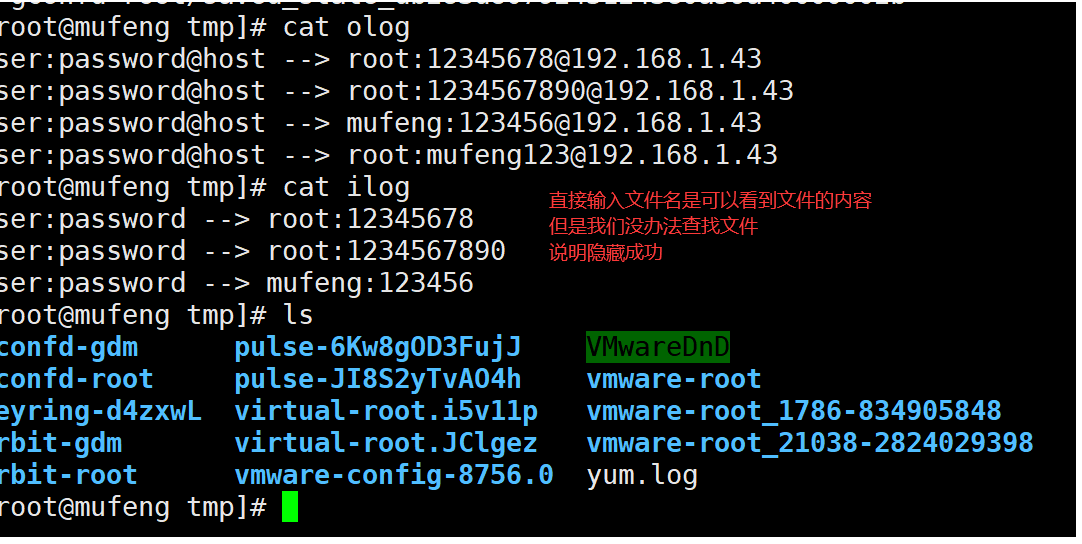
擂台赛-安全攻防之使用openssh后门获取root密码实战
前言 大家好,我是沐风晓月,我们开始组队学习了,介绍下我们的情况: 这几天跟队员 迎月,虹月,心月,古月打擂台,我和心月一组,相互攻占对方服务器。 终于在今早凌晨三点拿…...
关于React入门基础从哪学起?
文章目录前言一、React简介1. React是什么2. react 与 vue 最大的区别就是:3. React特点4. React介绍描述5. React高效的原因6.React强大之处二、React基础格式1.什么是虚拟dom?2.为什么要创建虚拟dom?三、React也分为俩种创建方式1. 使用js的方式来创建…...
python玄阶斗技--tkinter库
目录 一.tkinter库介绍 二.功能实现 1.窗口创建 2.Button 按钮 3.Entry 文本输入域 4.text 文本框 5.Listbox 多选下拉框 6.Radiobutton 多选项按钮 7.Checkbutton 多选按钮 8.Scale 滑块(拉动条) 9.Scroolbar 滚动条 10.Menu 菜单栏 11. messagebox 消息框 12…...
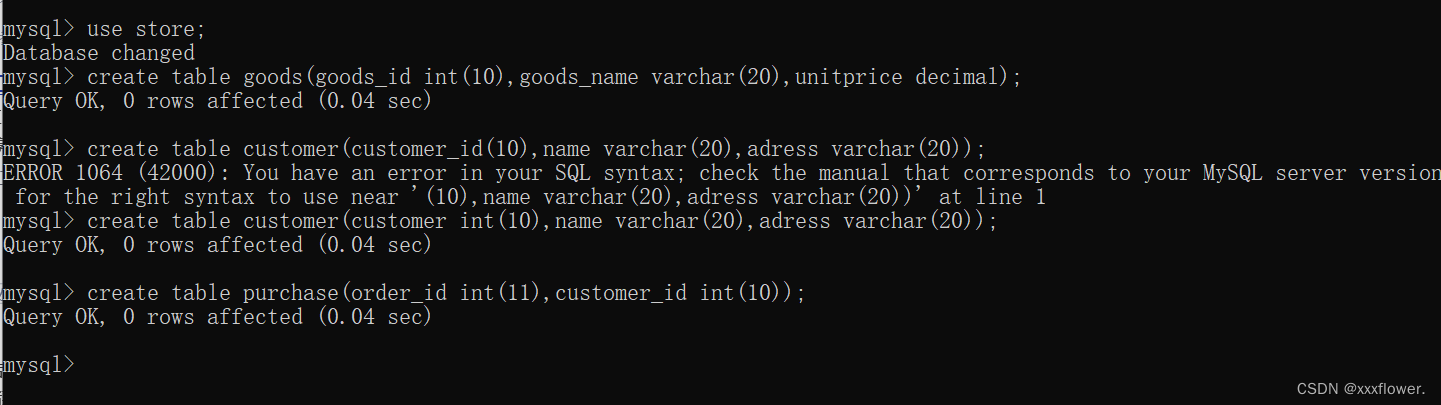
【MySQL】MySQL的介绍MySQL数据库及MySQL表的基本操作
文章目录数据库的介绍什么是数据库数据库分类MySQL的介绍数据库的基本操作数据库的操作创建数据库查看所有数据库选中指定的数据库删除数据库常用数据类型数值类型字符串类型日期类型表的操作创建表查看指定数据库下的所有表查看指定表的结构删除表小练习数据库的介绍 什么是数…...
)
【每日随笔】社会上层与中层的博弈 ( 技术无关、没事别点进来看 | 社会上层 | 上层与中层的保护层 | 推荐学习的知识 )
文章目录一、社会上层二、上层与中层的保护层三、推荐学习的知识一、社会上层 社会上层 掌握着 生产资料 和 权利 ; 社会中层 是 小企业主 和 中产打工人 ; 上层 名额有限 生产资料所有者 : 垄断巨头 , 独角兽 , 大型企业主 , 大型企业股东 , 数量有限 ;权利所有者 : 高级别的…...
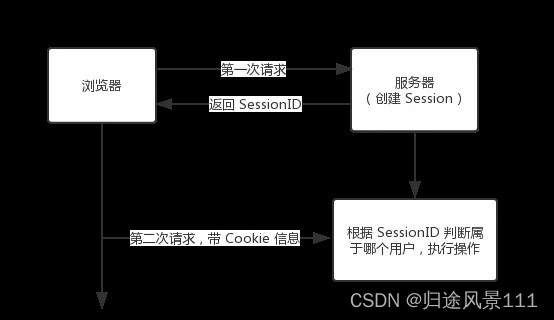
Cookie 和 Session的区别
文章目录时间:2023年3月23日第一:什么是 Cookie 和 Session ?什么是 Cookie什么是 Session第二:Cookie 和 Session 有什么不同?第三:为什么需要 Cookie 和 Session,他们有什么关联?第四&#x…...
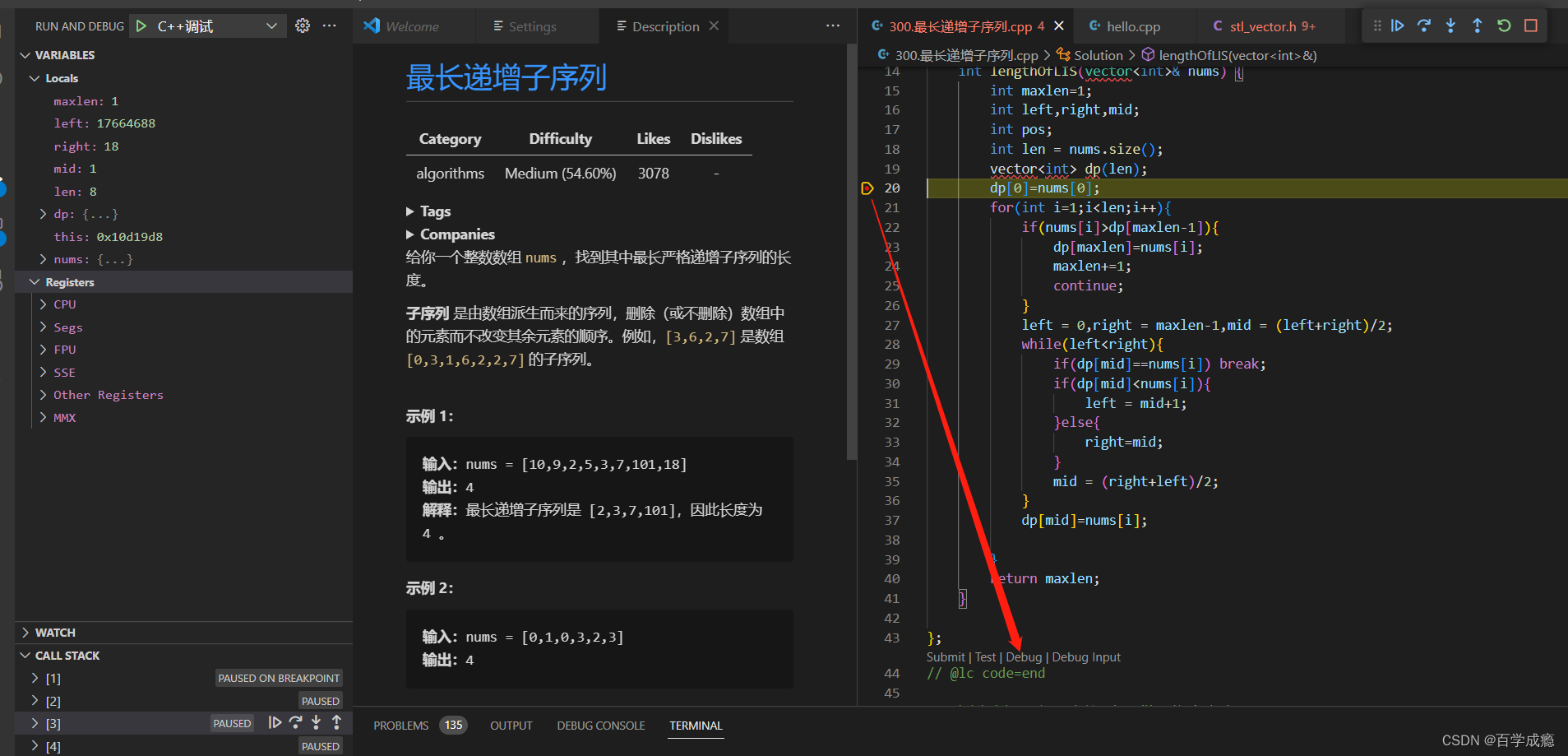
leetcode使用vscode调试C++代码
leetcode使用vscode调试C代码 这里记录一下大体思路吧,关于细节配置放上别的博主的链接,他们讲的更好 vscode只是编辑器,相当于记事本,需要下载minGW提供的编译器和调试器 官方介绍: C/C拓展不包括编译器或调试器&…...

树莓派Linux源码配置,树莓派Linux内核编译,树莓派Linux内核更换
目录 一 树莓派Linux的源码配置 ① 内核源码下载说明 ② 三种方法配置源码 二 树莓派Linux内核编译 ① 内核编译 ② 编译时报错及解决方案(亲测) 三 更换树莓派Linux内核 操作步骤说明 ● dmesg报错及解决方案(亲测࿰…...

【C语言】深度讲解 atoi函数 使用方法与模拟实现
文章目录atoi使用方法:atoi模拟实现atoi 功能:转化字符串到整数 头文件: #include <stdlib.h> int atoi (const char * str); 参数 str:要转换为整数的字符串 返回值 如果转换成功,函数将转换后的整数作为int值…...
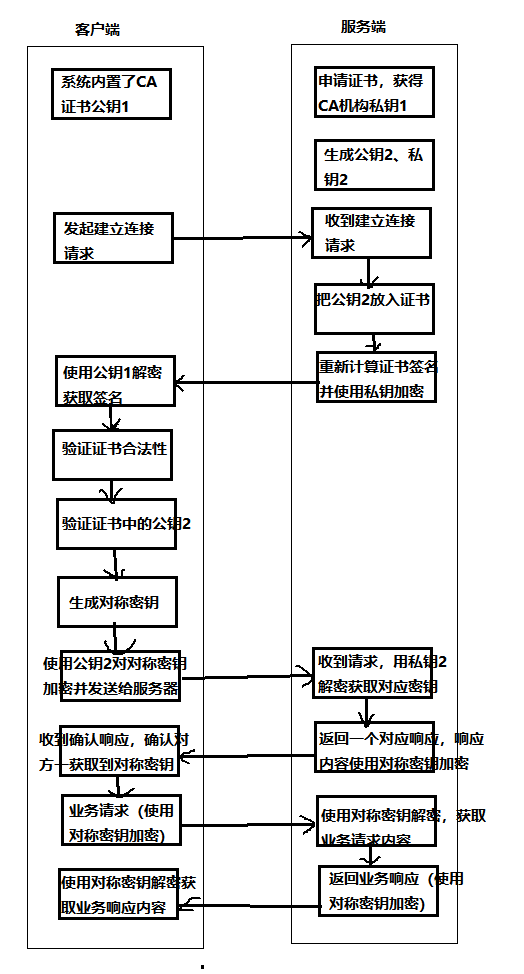
HTTPS的加密流程
1、概念HTTPS 是一个应用层协议,是在 HTTP 协议的基础上引入了一个加密层。HTTP 协议内容都是按照文本的方式明文传输的,这就导致在传输过程中出现一些被篡改的情况。HTTP协议传输的数据都是未加密的,也就是明文的,因此使用HTTP协…...
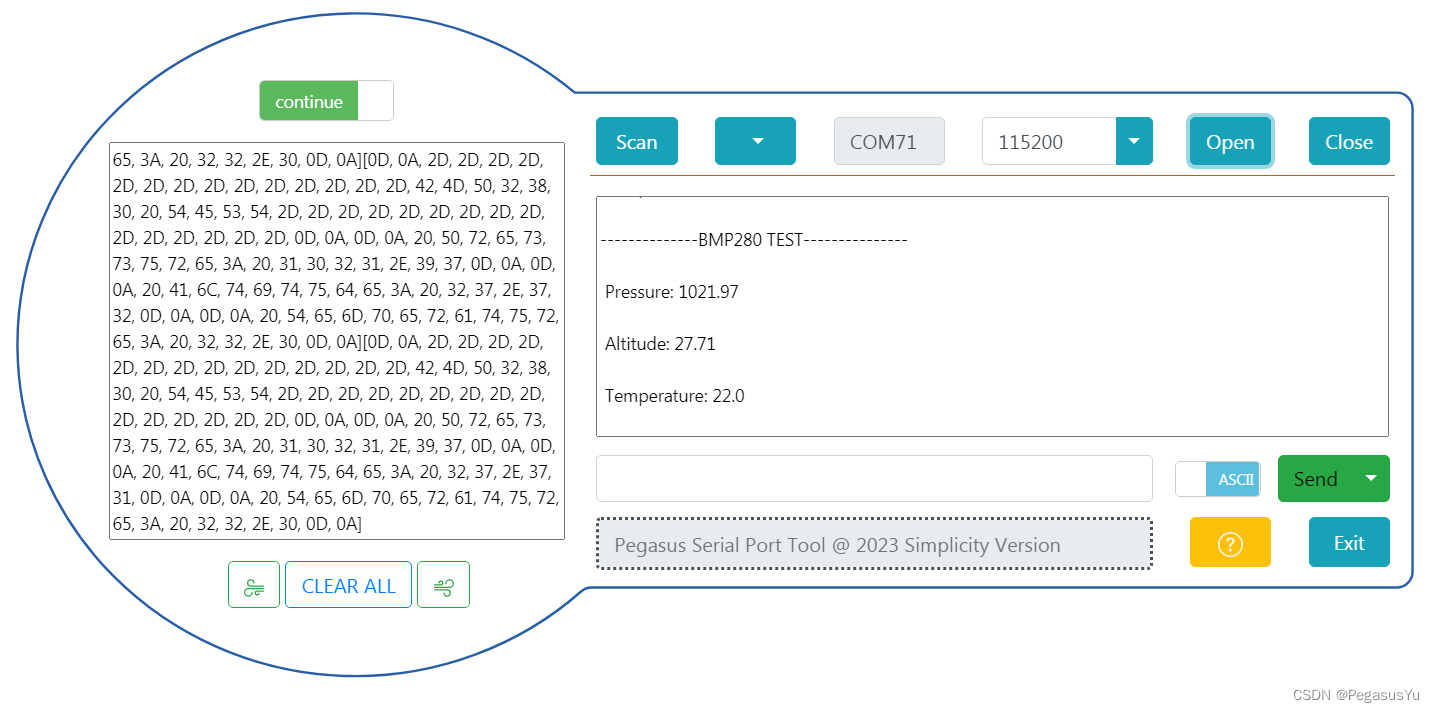
STM32配置读取BMP280气压传感器数据
STM32配置读取BMP280气压传感器数据 BMP280是在BMP180基础上增强的绝对气压传感器,在飞控领域的高度识别方面应用也比较多。 BMP280和BMP180的区别: 市面上也有一些模块: 这里介绍STM32芯片和BMP280的连接和数据读取。 电路连接 BMP28…...
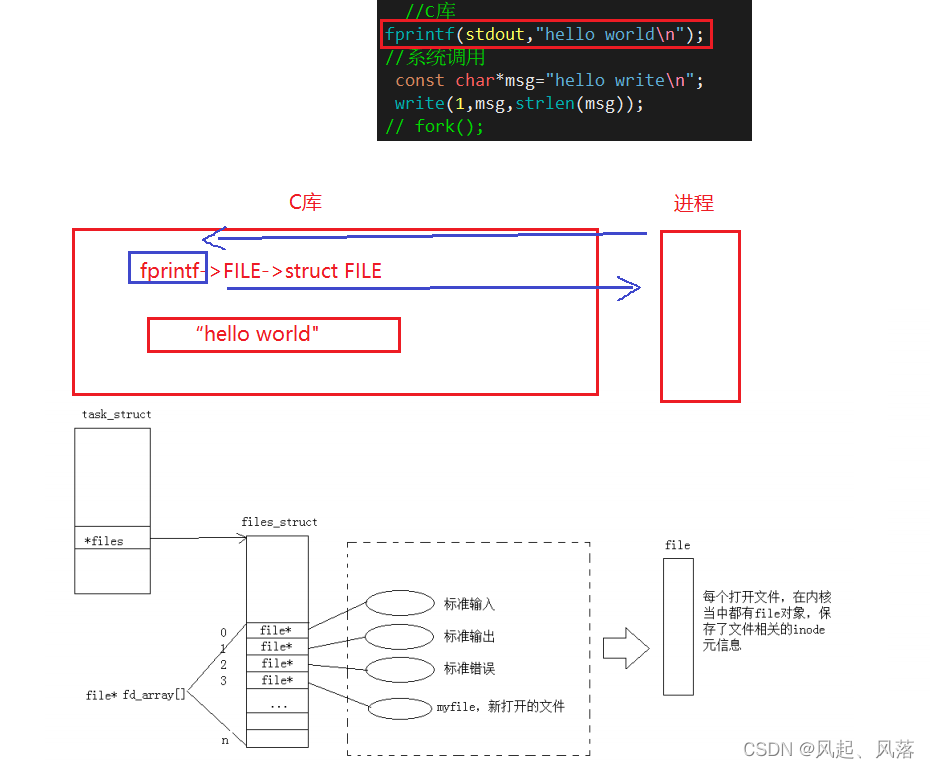
【Linux】 基础IO——文件(中)
文章目录1. 文件描述符为什么从3开始使用?2. 文件描述符本质理解3. 如何理解Linux下的一切皆文件?4. FILE是什么,谁提供?和内核的struct有关系么?证明struct FILE结构体中存在文件描述符fd5. 重定向的本质输出重定向输…...

蓝桥杯刷题冲刺 | 倒计时13天
作者:指针不指南吗 专栏:蓝桥杯倒计时冲刺 🐾马上就要蓝桥杯了,最后的这几天尤为重要,不可懈怠哦🐾 文章目录1.母牛的故事2.魔板1.母牛的故事 题目 链接: [递归]母牛的故事 - C语言网 (dotcpp.c…...
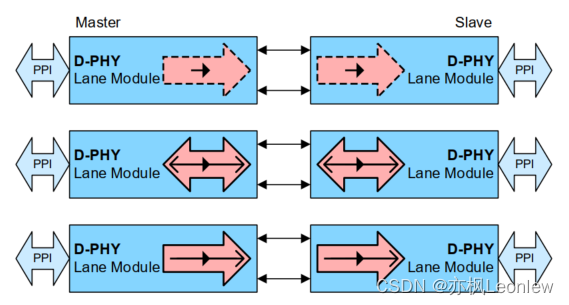
MIPI D-PHYv2.5笔记(5) -- 不同的PHY配置方式
声明:作者是做嵌入式软件开发的,并非专业的硬件设计人员,笔记内容根据自己的经验和对协议的理解输出,肯定存在有些理解和翻译不到位的地方,有疑问请参考原始规范看 规范5.7章节列举了一些常见的PHY配置,但实…...

【周末闲谈】文心一言,模仿还是超越?
个人主页:【😊个人主页】 系列专栏:【❤️周末闲谈】 周末闲谈 ✨第一周 二进制VS三进制 文章目录周末闲谈前言一、背景环境二、文心一言?(_)?三、文心一言的优势?😗😗😗四、文心一…...

《一“企”谈》 | 「佛山市政」:携手企企通,让采购业务数智化
近日,国家施工总承包壹级企业「佛山市市政建设工程有限公司」(以下简称“佛山市政”)正积极布局数字化建设工作,基于采购业务数智化,携手企企通打造了SaaS采购云平台。 01、岭南建筑强企 匠心铸造精品 …...
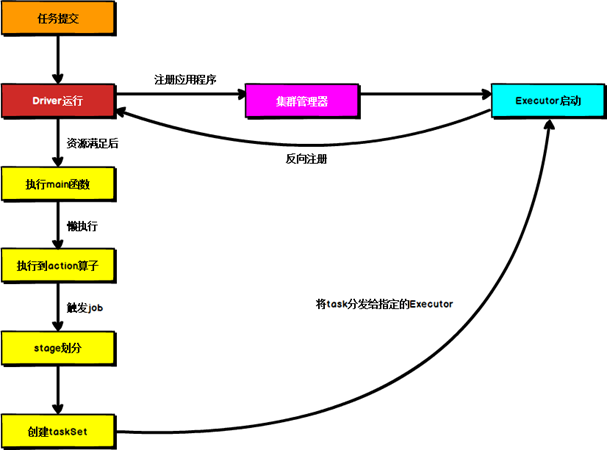
Spark运行架构
目录 1 运行架构 2 核心组件 2.1 Driver 2.2 Executor 2.3 Master & Worker 2.4 ApplicationMaster 3 核心概念 3.1 Executor 与 Core 3.2 并行度( Parallelism) 3.3 有向无环图( DAG) 4 提交流程 …...

linux arm系统烧录
1、打开瑞芯微程序 2、按住linux arm 的 recover按键 插入电源 3、当瑞芯微检测到有设备 4、松开recover按键 5、选择升级固件 6、点击固件选择本地刷机的linux arm 镜像 7、点击升级 (忘了有没有这步了 估计有) 刷机程序 和 镜像 就不提供了。要刷的时…...

【Web 进阶篇】优雅的接口设计:统一响应、全局异常处理与参数校验
系列回顾: 在上一篇中,我们成功地为应用集成了数据库,并使用 Spring Data JPA 实现了基本的 CRUD API。我们的应用现在能“记忆”数据了!但是,如果你仔细审视那些 API,会发现它们还很“粗糙”:有…...

leetcodeSQL解题:3564. 季节性销售分析
leetcodeSQL解题:3564. 季节性销售分析 题目: 表:sales ---------------------- | Column Name | Type | ---------------------- | sale_id | int | | product_id | int | | sale_date | date | | quantity | int | | price | decimal | -…...

【Java学习笔记】BigInteger 和 BigDecimal 类
BigInteger 和 BigDecimal 类 二者共有的常见方法 方法功能add加subtract减multiply乘divide除 注意点:传参类型必须是类对象 一、BigInteger 1. 作用:适合保存比较大的整型数 2. 使用说明 创建BigInteger对象 传入字符串 3. 代码示例 import j…...

08. C#入门系列【类的基本概念】:开启编程世界的奇妙冒险
C#入门系列【类的基本概念】:开启编程世界的奇妙冒险 嘿,各位编程小白探险家!欢迎来到 C# 的奇幻大陆!今天咱们要深入探索这片大陆上至关重要的 “建筑”—— 类!别害怕,跟着我,保准让你轻松搞…...

比较数据迁移后MySQL数据库和OceanBase数据仓库中的表
设计一个MySQL数据库和OceanBase数据仓库的表数据比较的详细程序流程,两张表是相同的结构,都有整型主键id字段,需要每次从数据库分批取得2000条数据,用于比较,比较操作的同时可以再取2000条数据,等上一次比较完成之后,开始比较,直到比较完所有的数据。比较操作需要比较…...
HubSpot推出与ChatGPT的深度集成引发兴奋与担忧
上周三,HubSpot宣布已构建与ChatGPT的深度集成,这一消息在HubSpot用户和营销技术观察者中引发了极大的兴奋,但同时也存在一些关于数据安全的担忧。 许多网络声音声称,这对SaaS应用程序和人工智能而言是一场范式转变。 但向任何技…...

解析奥地利 XARION激光超声检测系统:无膜光学麦克风 + 无耦合剂的技术协同优势及多元应用
在工业制造领域,无损检测(NDT)的精度与效率直接影响产品质量与生产安全。奥地利 XARION开发的激光超声精密检测系统,以非接触式光学麦克风技术为核心,打破传统检测瓶颈,为半导体、航空航天、汽车制造等行业提供了高灵敏…...

在树莓派上添加音频输入设备的几种方法
在树莓派上添加音频输入设备可以通过以下步骤完成,具体方法取决于设备类型(如USB麦克风、3.5mm接口麦克风或HDMI音频输入)。以下是详细指南: 1. 连接音频输入设备 USB麦克风/声卡:直接插入树莓派的USB接口。3.5mm麦克…...
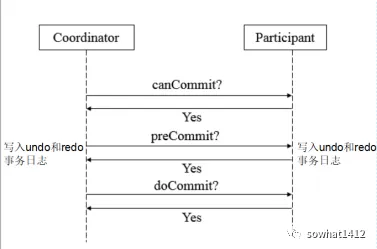
解析两阶段提交与三阶段提交的核心差异及MySQL实现方案
引言 在分布式系统的事务处理中,如何保障跨节点数据操作的一致性始终是核心挑战。经典的两阶段提交协议(2PC)通过准备阶段与提交阶段的协调机制,以同步决策模式确保事务原子性。其改进版本三阶段提交协议(3PC…...