Redis底层数据结构(详细篇)
Redis底层数据结构
- 一、常见数据结构的底层数据结构
- 1、动态字符串SDS(Simple Dynamic String)
- 组成
- 2、IntSet
- 组成
- 如何保证动态
- 如何确保有序呢? 底层如何查找的呢?
- 3、Dict(dictionary)
- 3.1组成
- 3.2 扩容
- 3.3 收缩
- 3.4 rehash
- 4、ZipList
- 连锁更新问题
- 总结特性
- 5、 QuickList
- 5.1 组成
- 5.2 底层源码(结合组成示意图理解)
- 5.3 特点总结
- 6、SkipList
- 它和其他传统链表不同:1、元素按升序排列(也是方便后续的查找)
- 2、节点可能包含多个指针,跨度不一样(加速查找效率,跳表的来源)
- 特点总结:
- 最后:redis的对象(redisObject)
- 逐层分析
- 1、type
- 2、encoding
- 3、lru(最后一次使用时间)
- 4、refcount
- 5、ptr(指针)
- 二、常见数据结构
- 1、String
- 2、LIST
- 3、Set(无序唯一)
- 4、ZSet(SortedSet)
- 5、Hash
一、常见数据结构的底层数据结构
1、动态字符串SDS(Simple Dynamic String)

组成
字符数组存储数据,头部存储字符数量,预分配内存,SDS类型(5个字节已被弃用)。
问题来了:为什么要这样设计呢?为什么不用c语言的字符串呢?
回答
- 1、保证二进制安全 2、无需遍历数组获取长度
其实c语言没有字符串,是靠字符数组实现的,并且以“ \0 ”作为结束标志,但是如果数据中间存在结束字符会导致读取数据不全的问题,所以引入len变量来保存字符数量,以len作为标准去读取数据,同时无需遍历数组获取长度(len)。 - 3、动态扩容

预分配有啥好处嘛?
在操作系统中,分配内存需要内核态和用户态的转换,该过程十分损耗性能,所以当大于1m,会分配多1m,防止多次分配带来的性能损耗。
2、IntSet
组成
本质是一个动态有序的整数数组。

encoding表示编码方式,数组中的数据就按照该编码方式存储。
如何保证动态
问题来了:如果数据超过了编码的范围怎么办呢?


回答: 我们通过编码升级,倒叙依次拷贝(防止正序覆盖当前数据),再添加新元素,最后头信息:length+1并且编码修改为对应的编码类型。
如何确保有序呢? 底层如何查找的呢?

本质就是二分查找,找到则不插入返回错误,没找到则插入有序的适当位置。
3、Dict(dictionary)
3.1组成
和java中jdk1.7版本的HashMap底层数据结构十分相似,由三部分组成:hash表(数组),哈希节点(entry)、字典(Dict)

每个Dict有两个hashTable一个用于存储当前数据,一个用于rehash(后续详细介绍)。
每个hashTable(dictHT)存储entry的指针以及hash表大小和entry个数,其中有一个sizemask用于进行hash求索引比如n&sizemask等价于n%size(sizemask+1),&运算速率更加快。
当发生hash碰撞的时候就是key运算后索引相同则使用单向链表,进行前插法添加新元素。

3.2 扩容

3.3 收缩
hashTable默认size为4,怎么收缩都不能低于4。
收缩后的size为大于等于实际entry个数的最小2的n次方(5->8)

3.4 rehash

因为一次新增的数据太多,导致rehash一次性更新到新的hashTable时长太长而影响其他业务性能,所以每次执行增删改查的时候才会去更新一个索引的数据,直到结束为止。
4、ZipList

为什么不使用相同内存存储entry呢?
回答:之所以叫压缩列表,就是因为去除了链表中的指针(一个指针8字节),并且每个entry由实际内容决定,节省了大批内存空间。

在遍历的时候,无需使用链表的指针来获取前一个元素和下一个元素,而是根据previous_enrty_length计算前一个entry的起始地址,通过自身大小计算下一节点地址。


连锁更新问题

如果这个时候插入一个节点并且长度大于254,将会导致pre_enrty_length属性由1字节变成5字节导致后面的该属性全部连锁更新为5字节。
(该情况发生概率很低)

总结特性
- 可以看成一种连续空间的"双向链表" ,首尾操作简单
- 节点之间不通过指针连接,记录上一节点和本节点长度寻址,节省内存
- 如果节点数量过多,导致链表过长,需要逐个遍历,查询效率不高
- 增删大数据时可能发生连续更新问题
5、 QuickList
上面说到ZipList的致命缺点:空间连续,如果数据过多,申请效率会变低,查询效率也下降,如何解决呢?
- 可以通过限制ZipList的长度和entry大小
- 对于大量的数据进行分片,多个ZipList存储
- 多个ZipList进行联系,引入主角:QuickList
5.1 组成
QuickList本质是一个双端链表,但是每个节点指向ZipList,使得ZipList们联系起来。

config get list-max-ziplist-size


config get list-compress-depth

5.2 底层源码(结合组成示意图理解)

5.3 特点总结
- 是一个节点为ZipList的双端链表
- 节点采用ZipList,解决了传统链表的内存占用问题(指针)
- 控制了ZipList的大小,解决申请效率的问题
- 中间节点可以进一步压缩,进一步节省内存空间。
6、SkipList
上面聊了这么多链表,其实都没看到怎么去解决快速查找中间节点的问题,这里引入的SkipList就优化了链表中元素查找效率。
它和其他传统链表不同:1、元素按升序排列(也是方便后续的查找)
根据score值进行排序
2、节点可能包含多个指针,跨度不一样(加速查找效率,跳表的来源)
上源码:是个双向链表,每个节点值是SDS,整个排序考score,然后就是前后指针,由于增序,所以多级指针体现在forword(向后),跨度不一所以使用数组存储。

示意图

特点总结:
- 双向链表,每个节点都含score和ele值
- 节点按score排序,score值相同则按 ele字典排序(字符串)
- 每个节点可包含多级指针,1-32之间
- 指针层级越高,跨度越大
- 增删修改效率和红黑树 基本一致,实现却简单
最后:redis的对象(redisObject)

逐层分析
1、type
就是我们熟悉的5中常见类型string 、hash、list、set和zset(4个bit)
2、encoding
就是五种类型在数据量不同的情况下不同的编码方式(4个bit)


3、lru(最后一次使用时间)
便于统计使用情况,用于统计空闲时间。(24bit)
4、refcount
引用计数器,便于淘汰和回收。
5、ptr(指针)
指向真正的数据。
其实这里就可以发现: 如果我们一直使用string类型去存储大量数据,会浪费很多对象的头内存,我们可以将其使用集合去存储进行内存的优化。
二、常见数据结构
1、String
使用的编码格式有三种 RAW EMBSTR INT
- 基本的编码方式是raw,基于SDS(动态字符串),存储上限为512mb。
- 如果存储的SDS长度小于等于44字节,则采用EMBSTR 编码,此时redisobj head和SDS是一段连续空间。申请内存时只需要调用一次内存分配函数(设计到内核态和用户态的切换),效率更高。
- 如果存储的字符串是整数,并且大小在LONG_max范围内,则采用INT编码,直接使用pre指针位置(刚好8字节),不需要SDS。

2、LIST
- 在3.2版本之前,Redis采用ZipList和Linklist来实现List,当元素小于512并且元素大小小于64字节时采用ZipList编码,超过采用Linklist。
- 3.2之后,统一使用QuickList来实现。
具体QuickList请看上述中的详解。
3、Set(无序唯一)
- 为了查询效率和唯一性,set采用HT编码(Dict)。Dict中的key用来存储元素,value统一为null。
- 当存储的数据都是整数的时候,并且元素数量不超过set-max-intset-entries时,set采用IntSet编码,以节省空间。
如图 当元素为{5,10,20}这时候sadd s1 m1会将编码方式由intset转为dict。

4、ZSet(SortedSet)
其中的每一个元素都需要指定一个score值和member值:
- 根据score值排序
- member值唯一(set都是这样的)
- 根据member查询score
so:底层数据结构必须满足 键值存储,键唯一,可排序 - dict 满足键值存储和根据key找value
- skipList 满足可排序,可以存储score和member
其实底层就是综合了他们的优点来满足需求,二者都要,一共两份数据(空间换时间)。
示意图:

key存ele ,value存score实现ele找score ,但是根据score排序。
大家可以看到当元素少的时候其实性价比不高,内存消耗比较大,所以:
当元素不多的时候,底层会采用zipList实现存储。
什么叫不多?界限是啥? 同时满足以下两个条件(一般都是个数,内存大小)
- 元素小于128(默认)可以调节。
- 每个元素小于64字节
学了zipList知道其实他本身不具备 键值存储,键唯一,可排序三个特点如何实现呢?
- zipList是连续空间,因此score和ele紧挨着一起的两个enrty,ele在前。
- score越小越接近队首,按score升序排列。

5、Hash
其实学了zset,发现二者很相似,只不过hash不需要保证有序,所以立马知道,其底层就是dict,但是当数据量不多则使用zipList。
hash默认是使用zipList编码,节省空间,相邻两个entry存的就是key 和value。
当数据量大时则转为HT(dict)编码,触发条件有两个:
- 元素数量超过512(默认,可调节)
- 大小超过64字节(默认,可调节)

以上则是Redis底层主要的数据结构。
相关文章:
Redis底层数据结构(详细篇)
Redis底层数据结构 一、常见数据结构的底层数据结构1、动态字符串SDS(Simple Dynamic String)组成 2、IntSet组成如何保证动态如何确保有序呢? 底层如何查找的呢? 3、Dict(dictionary)3.1组成3.2 扩容3.3 收缩3.4 rehash 4、ZipList连锁更新问题总结特…...

树和二叉树基本术语、性质
总结二叉树的度、树高、结点数等属性之间的关系(通过王道书 5.2.3 课后小题来复习“二叉 树的性质”) 树的相关知识 叶子结点的度0 层次默认从1开始 有些题目从0 开始也不要奇怪 常见考点1:结点数总度数+1 常见考点2࿱…...

FEDERATED引擎
入门 MySQL引擎主要有以下几种: MyISAM:这是MySQL 5.5.5之前的默认存储引擎,不支持事务、外键约束和聚簇索引,适用于读多写少的场景。InnoDB:这是MySQL 5.5.5之后的默认存储引擎,支持事务、外键约束、行级…...

Android NDK工具
Android NDK工具 Android NDK Crash 日志抓取及定位 NDK-STACK 定位 NDK Crash 位置 只要执行如下代码就行: adb logcat | ndk-stack -sym /yourProjectPath/obj/local/armeabi-v7aPS: 必须是带symbols的so,也就是在’\app\src\main\obj\local\下面的…...

使用 Docker 进入容器并运行命令的详细指南
Docker 是一款开源的容器化平台,它可以将应用程序和依赖环境打包到一个可移植的“容器”中,以保证应用不受运行环境的影响。使用 Docker 容器化应用后,有时需要进入容器内部执行一些命令进行调试或管理。 一、Docker 基础命令 在开始进入容…...

【人工智能】OpenAI最新发布的o1-preview模型,和GPT-4o到底哪个更强?最新分析结果就在这里!
在人工智能的快速发展中,OpenAI的每一次新模型发布都引发了广泛的关注与讨论。2023年9月13日,OpenAI正式推出了名为o1的新模型,这一模型不仅是其系列“推理”模型中的首个代表,更是朝着类人人工智能迈进的重要一步。本文将综合分析…...

Spring Boot-版本兼容性问题
Spring Boot 版本兼容性问题探讨 Spring Boot 是一个用于构建微服务和现代 Java 应用的流行框架,随着 Spring Boot 版本的更新和发展,它在功能、性能和安全性上不断提升。但与此同时,Spring Boot 的版本兼容性问题也逐渐成为开发者必须关注的…...

Java原生HttpURLConnection实现Get、Post、Put和Delete请求完整工具类分享
这里博主纯手写了一个完整的 HTTP 请求工具类,该工具类支持多种请求方法,包括 GET、POST、PUT 和 DELETE,并且可以选择性地使用身份验证 token。亲测可用,大家可以直接复制并使用这段代码,以便在自己的项目中快速实现 HTTP 请求的功能。 目录 一、完整代码 二、调用示例…...

如何微调(Fine-tuning)大语言模型?
本文介绍了微调的基本概念,以及如何对语言模型进行微调。 从 GPT3 到 ChatGPT、从GPT4 到 GitHub copilot的过程,微调在其中扮演了重要角色。什么是微调(fine-tuning)?微调能解决什么问题?什么是 LoRA&…...

wopop靶场漏洞挖掘练习
1、SQL注入漏洞 1、在搜索框输入-1 union select 1,2,3# 2、输入-1 union select 1,2,database()# ,可以得出数据库名 3、输入-1 union select 1,2,group_concat(table_name) from information_schema.tables where table_schematest#,可以得出数据库中…...

探索Python的隐秘角落:Keylogger库的神秘面纱
文章目录 探索Python的隐秘角落:Keylogger库的神秘面纱背景:为何需要Keylogger?库简介:什么是Keylogger?安装指南:如何将Keylogger纳入你的项目?函数使用:5个简单函数的介绍与代码示…...

JAVA开源项目 校园管理系统 计算机毕业设计
本文项目编号 T 026 ,文末自助获取源码 \color{red}{T026,文末自助获取源码} T026,文末自助获取源码 目录 一、系统介绍二、演示录屏三、启动教程四、功能截图五、文案资料5.1 选题背景5.2 国内外研究现状5.3 可行性分析 六、核心代码6.1 管…...

Java--常见的接口--Comparable
String类型的compareTo方法: 在String引用中,有一个方法可以比较两个字符串的大小: 和C语言中是一样的,两个字符串一个字符一个去比较。 那么这个方法是怎么实现的呢? 其实就是一个接口:Comparable接口里…...
luogu基础课题单 入门 上
【深基2.例5】苹果采购 题目描述 现在需要采购一些苹果,每名同学都可以分到固定数量的苹果,并且已经知道了同学的数量,请问需要采购多少个苹果? 输入格式 输入两个不超过 1 0 9 10^9 109 正整数,分别表示每人分到…...

物理设计-物理数据模型优化策略
物理数据模型优化策略 1. 引言:物理设计的重要性 在数据库设计的生命周期中,物理设计是将逻辑模型转化为实际可执行的数据库架构的关键步骤。它直接关系到系统的性能、可扩展性和维护成本。一个优化的物理数据模型能够显著提升数据访问速度ÿ…...

产学研合作赋能产业升级新动能
在当今快速发展的时代,产业升级已成为经济持续增长的关键。而产学研合作模式正以其独特的优势,为产业升级注入新动能。 产学研合作,即将产业、学校与科研机构紧密结合起来。产业提供实际的需求和应用场景,学校培养专业的人才&…...

uniapp tabBar不显示
开发中发现某个页面不显示tabbar,而有的页面显示 需要在tabBar配置中添加需要展示的页面 刚开始我发现登录页面不展示tabbar,把登录页面的路径配置进去就会展示了...

论文阅读《Robust Steganography for High Quality Images》高质量因子图片的鲁棒隐写
TCSVT 2023 中国科学技术大学 Kai Zeng, Kejiang Chen*, Weiming Zhang, Yaofei Wang, Nenghai Yu, "Robust Steganography for High Quality Images," in IEEE Transactions on Circuits and Systems for Video Technology, doi: 10.1109/TCSVT.2023.3250750. 一、…...

node前端开发基本设置
加快下载源速度 要将 npm 切换到淘宝的源镜像,你可以按照以下步骤操作: 查看当前 npm 源: npm config get registry这个命令会显示当前使用的 npm 源地址,默认情况下它会是 https://registry.npmjs.org/。 切换到淘宝镜像&#…...

深入掌握:如何进入Docker容器并运行命令
感谢浪浪云支持发布 浪浪云活动链接 :https://langlangy.cn/?i8afa52 文章目录 查看正在运行的容器使用 docker exec 命令进入容器进入容器的交互式 shell在容器中运行命令 使用 docker attach 命令附加到容器检查容器日志退出容器从 docker exec 方式退出从 docke…...

XCTF-web-easyupload
试了试php,php7,pht,phtml等,都没有用 尝试.user.ini 抓包修改将.user.ini修改为jpg图片 在上传一个123.jpg 用蚁剑连接,得到flag...

.Net框架,除了EF还有很多很多......
文章目录 1. 引言2. Dapper2.1 概述与设计原理2.2 核心功能与代码示例基本查询多映射查询存储过程调用 2.3 性能优化原理2.4 适用场景 3. NHibernate3.1 概述与架构设计3.2 映射配置示例Fluent映射XML映射 3.3 查询示例HQL查询Criteria APILINQ提供程序 3.4 高级特性3.5 适用场…...

【HTML-16】深入理解HTML中的块元素与行内元素
HTML元素根据其显示特性可以分为两大类:块元素(Block-level Elements)和行内元素(Inline Elements)。理解这两者的区别对于构建良好的网页布局至关重要。本文将全面解析这两种元素的特性、区别以及实际应用场景。 1. 块元素(Block-level Elements) 1.1 基本特性 …...
-HIve数据分析)
大数据学习(132)-HIve数据分析
🍋🍋大数据学习🍋🍋 🔥系列专栏: 👑哲学语录: 用力所能及,改变世界。 💖如果觉得博主的文章还不错的话,请点赞👍收藏⭐️留言Ǵ…...

云原生玩法三问:构建自定义开发环境
云原生玩法三问:构建自定义开发环境 引言 临时运维一个古董项目,无文档,无环境,无交接人,俗称三无。 运行设备的环境老,本地环境版本高,ssh不过去。正好最近对 腾讯出品的云原生 cnb 感兴趣&…...

解读《网络安全法》最新修订,把握网络安全新趋势
《网络安全法》自2017年施行以来,在维护网络空间安全方面发挥了重要作用。但随着网络环境的日益复杂,网络攻击、数据泄露等事件频发,现行法律已难以完全适应新的风险挑战。 2025年3月28日,国家网信办会同相关部门起草了《网络安全…...

jmeter聚合报告中参数详解
sample、average、min、max、90%line、95%line,99%line、Error错误率、吞吐量Thoughput、KB/sec每秒传输的数据量 sample(样本数) 表示测试中发送的请求数量,即测试执行了多少次请求。 单位,以个或者次数表示。 示例:…...

从 GreenPlum 到镜舟数据库:杭银消费金融湖仓一体转型实践
作者:吴岐诗,杭银消费金融大数据应用开发工程师 本文整理自杭银消费金融大数据应用开发工程师在StarRocks Summit Asia 2024的分享 引言:融合数据湖与数仓的创新之路 在数字金融时代,数据已成为金融机构的核心竞争力。杭银消费金…...

比较数据迁移后MySQL数据库和OceanBase数据仓库中的表
设计一个MySQL数据库和OceanBase数据仓库的表数据比较的详细程序流程,两张表是相同的结构,都有整型主键id字段,需要每次从数据库分批取得2000条数据,用于比较,比较操作的同时可以再取2000条数据,等上一次比较完成之后,开始比较,直到比较完所有的数据。比较操作需要比较…...
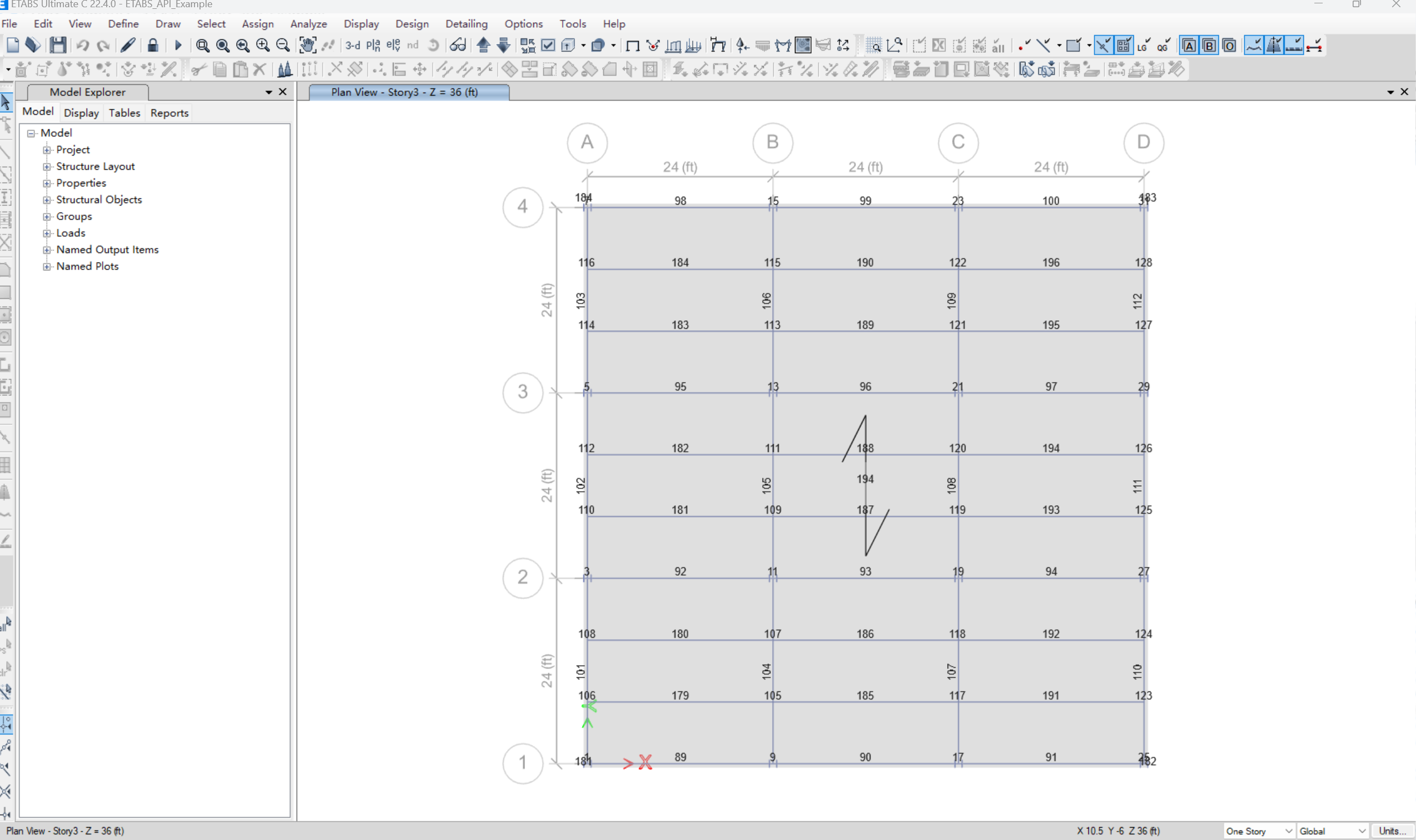
【Post-process】【VBA】ETABS VBA FrameObj.GetNameList and write to EXCEL
ETABS API实战:导出框架元素数据到Excel 在结构工程师的日常工作中,经常需要从ETABS模型中提取框架元素信息进行后续分析。手动复制粘贴不仅耗时,还容易出错。今天我们来用简单的VBA代码实现自动化导出。 🎯 我们要实现什么? 一键点击,就能将ETABS中所有框架元素的基…...