HBase 的基本架构 详解
HBase 是一个分布式的、面向列的数据库,构建在 HDFS(Hadoop Distributed File System)之上,提供高效的随机读写操作。为了全面理解 HBase 的基础架构,需要从逻辑架构、物理存储、组件之间的交互、数据管理和底层设计出发,结合源码进行深入剖析。
1. HBase 的基本架构概览
HBase 的整体架构可以分为以下几个关键部分:
- HMaster:负责管理 HBase 集群中的元数据、表的创建、分区的拆分和合并、Region 的分配和迁移等任务。
- RegionServer:负责管理存储在其中的区域(Region),处理数据的读写请求。
- Zookeeper:HBase 用 Zookeeper 进行分布式协调,帮助管理元数据、故障恢复和分布式锁。
- HDFS:HBase 的底层存储依赖于 HDFS,数据最终保存在 HDFS 的文件系统中。
- 客户端:用户通过 HBase 客户端进行数据的读写,客户端与 Zookeeper 和 RegionServer 交互,定位数据并执行操作。
HBase 通过这些组件的协同工作,提供了可伸缩的分布式存储系统。接下来,我们从每个组件的角度深入分析其架构设计和源码实现。
2. HBase 的逻辑架构
HBase 采用面向列的存储模型,表的基本单元是“列族(Column Family)”。在 HBase 中,每个表由若干行组成,每一行有一个唯一的 RowKey 作为标识,每行又包含多个列。与传统关系型数据库不同,HBase 的列族是动态的,用户可以为不同的行存储不同的列。
HBase 的逻辑架构包括以下几个重要概念:
- 表(Table):行和列的集合,行由
RowKey唯一标识。 - 列族(Column Family):列被组织为族,每个列族中的数据被存储在一起。
- Region:HBase 将表中的行分割为多个区域(Region),每个区域负责存储某个
RowKey范围内的行。 - Store:每个列族对应一个
Store,用于管理该列族的数据。 - MemStore 和 HFile:每个
Store由内存中的MemStore和磁盘上的HFile组成。数据先写入MemStore,然后定期将MemStore中的数据刷到磁盘形成HFile。
HBase 的表分片(Sharding)
HBase 通过 Region 来对表进行分片,每个 Region 负责一部分 RowKey 范围的行。当表中的数据增长到一定程度时,Region 会被拆分为两个新的 Region。每个 Region 被分配到一个 RegionServer 上进行管理。
3. HBase 的物理架构
HBase 的物理架构依赖于 HDFS。HBase 中的数据被分布式存储在 HDFS 上,但由 RegionServer 进行管理。RegionServer 是 HBase 的核心组件,负责处理数据的读写操作,管理 Region 和维护数据的一致性。
HBase 的物理架构主要包括以下部分:
- HMaster:集群管理节点,负责全局管理,如
Region分配、分裂、合并和RegionServer监控等。 - RegionServer:负责管理
Region,处理客户端的读写请求,将数据写入HFile和WAL中。 - HDFS:底层存储,所有的数据最终都以
HFile的形式存储在 HDFS 中。 - Zookeeper:负责分布式协调,如监控
RegionServer的状态、分布式锁等。
HMaster 的角色和职责
HMaster 是 HBase 集群的主节点,负责管理 RegionServer 和 Region 的元数据、表的分裂与合并、Region 的分配、RegionServer 的负载均衡等任务。
在 HBase 源代码中,HMaster 的核心逻辑实现主要位于 HMaster.java 文件中。
public class HMaster extends HasThread implements MasterServices, Server {// HMaster的启动逻辑@Overridepublic void run() {// 启动 HMasterinitialize();// 处理 RegionServer 和表管理的元数据...}
}
HMaster 的职责包括:
- 管理元数据表:HMaster 负责管理
hbase:meta表,该表保存了所有Region的元数据信息,如Region的RowKey范围、RegionServer地址等。 - 监控 RegionServer:通过 Zookeeper 监控
RegionServer的状态,当RegionServer失效时,HMaster 会将其上托管的Region重新分配到其他可用的RegionServer上。 - Region 分裂和合并:HMaster 负责决定何时分裂或合并
Region,以保持集群的负载均衡。
RegionServer 的角色和职责
RegionServer 是 HBase 集群中的工作节点,负责处理客户端的请求,管理表数据并提供对 HDFS 的读写操作。
- MemStore 和 StoreFile:每个
Region的列族数据存储在MemStore中,定期会将MemStore的内容刷到 HDFS 上,形成StoreFile(即HFile)。 - WAL(Write-Ahead Log):
RegionServer使用WAL来保证数据的持久性。在每次写操作前,先将数据写入 WAL 中,以便在服务器故障时可以进行恢复。
在 HBase 源码中,RegionServer 的逻辑主要位于 HRegionServer.java 文件中:
public class HRegionServer extends HasThread implements RegionServerServices, RpcServerInterface {@Overridepublic void run() {// RegionServer的启动逻辑initialize();// 处理读写请求while (running) {// 处理客户端的写请求,写入MemStore和WALhandleWriteRequests();// 处理客户端的读请求,从MemStore或StoreFile中读取数据handleReadRequests();}}
}
RegionServer 的职责包括:
- 管理 Region:每个
RegionServer管理多个Region,并为客户端提供数据的读写服务。 - 处理客户端请求:RegionServer 通过 RPC 接口处理客户端的读写请求。写入操作会先写入
WAL,然后更新MemStore,读操作则从MemStore或StoreFile中读取数据。 - Compaction(合并):定期将
MemStore刷盘形成的多个StoreFile进行合并,减少文件碎片,提高读写效率。
Zookeeper 的角色和职责
Zookeeper 作为分布式协调服务,在 HBase 集群中起到以下作用:
- 维护元数据:Zookeeper 保存
HMaster和RegionServer的运行状态,并帮助HMaster进行元数据管理。 - 故障恢复:当
RegionServer宕机时,Zookeeper 通过监控机制发现这一变化,通知HMaster进行故障处理。 - 分布式锁:HBase 使用 Zookeeper 实现分布式锁机制,避免集群中多个节点同时执行冲突的操作。
HBase 使用 Zookeeper 来实现集群协调,确保多个 HMaster 和 RegionServer 可以安全、高效地工作。
4. HBase 的数据写入过程
理解 HBase 的写入路径是了解其底层架构的重要部分。HBase 的写入过程是由多个步骤组成的,涵盖了 WAL、MemStore 和 StoreFile 的写入。
- 写入 WAL(Write-Ahead Log):当客户端发送写请求时,RegionServer 首先将数据记录到 WAL 中,以保证数据不会因服务器宕机而丢失。WAL 是一种顺序写入的日志文件,用于故障恢复。
- 写入 MemStore:接着,数据被写入
MemStore,MemStore是位于内存中的数据结构,用于缓存数据。每个列族都有自己的MemStore。 - Flush 到 HFile:当
MemStore中的数据达到一定大小时,RegionServer 会将MemStore中的数据刷盘,生成一个HFile文件,并存储到 HDFS 中。 - 数据合并(Compaction):由于多次刷盘会生成多个 HFile 文件,HBase 会定期将小的 HFile 文件进行合并,减少文件碎片,提高读取性能。
5. HBase 的数据读取过程
HBase 的读操作首先通过 Zookeeper 定位数据所在的 RegionServer,接着 RegionServer 处理读请求:
- 查找 MemStore:首先在
MemStore中查找数据。 - 查找 BlockCache:若
MemStore中没有找到数据,RegionServer 会检查缓存中的BlockCache。 - 查找 HFile:如果缓存中也没有,RegionServer 会读取 HDFS 上的
HFile,并将结果返回客户端。
6. HBase 的一致性与容错机制
HBase 通过 WAL、MemStore 和 HDFS 的协调,实现了数据的强一致性。WAL 提供了持久化保障,MemStore 提供快速写入,HFile 提供了数据的持久存储。而 HBase 依赖于 HDFS 和 Zookeeper 来实现故障恢复与容错机制。
- 数据恢复:如果 RegionServer 宕机,HMaster 会通过 Zookeeper 检测并重新分配该 RegionServer 上的 Region,利用 WAL 进行数据恢复。
7. 结论
HBase 通过设计一套基于列族的存储模型,结合 HDFS 的分布式存储与 Zookeeper 的协调,构建了一个高效的、可伸缩的分布式 NoSQL 数据库。它的架构层次清晰,核心包括 HMaster、RegionServer、Zookeeper、WAL、MemStore 和 HFile。
相关文章:

HBase 的基本架构 详解
HBase 是一个分布式的、面向列的数据库,构建在 HDFS(Hadoop Distributed File System)之上,提供高效的随机读写操作。为了全面理解 HBase 的基础架构,需要从逻辑架构、物理存储、组件之间的交互、数据管理和底层设计出…...

crypt.h:No such file or directory报错处理
crypt.h:No such file or directory 报错处理 前言:本文初编辑于2024年9月27日 CSDN主页:https://blog.csdn.net/rvdgdsva 博客园主页:https://www.cnblogs.com/hassle 博客园本文链接: 大!萌࿰…...

网络消费维权的9个常见法律问题
一、忘记付尾款,定金能否退还? 不能。消费者在网络提交订单后,合同即成立。合同成立后,消费者的义务为按时付款。若消费者在支付定金后未能支付尾款,即未能履行付款义务,会导致合同无法履行,构…...

detectron2是怎么建立模型的?以SparseInst代码为例
看SparseInst论文发现论文里有些地方没讲清楚;遂找SparseInst源码来看模型结构 我选择从推理代码来找模型结构: 经探索,在SparseInst代码里,推理需要执行代码 python demo.py --config-file configs/sparse_inst_r50_base.yaml …...

kafka监控平台Kafdrop:使用记录
背景 AI的发展真是太方便了,让它给我推荐一款轻量级,没有学习曲线的kafka监控平台,它就给我推荐这一款。用了一下果然没有一点学习曲线。 目前已经满足了我的需求,可视化界面,topic、消息、消费者group信息以及消费情…...

的使用和内联函数
今天我们来了解一下C中的&和内联函数 引用标识符& C觉得C语言部分的指针有些麻烦,容易混乱,所以C创造了一个标识符&,表示是谁的别名。跟指针对比一下:int* a1&b1;int &a2b2;这样看,显然a1存放的…...

征程6 上基于 DEB 工具实现包管理
1.引言 在开发、调测过程中,开发人员需要将系统软件、应用软件部署到 Soc 板端,以用于运行调试。传统的部署方式是通过解压复制或者调用部署脚本。这样的部署方式需要有着方式不统一、维护投入大的缺点。 在 linux 系统上,大多采用包管理的…...

【git】一文详解: git rebase到底有啥问题
引子 我反复看到这样的评论:“git rebase 像屎一样”。人们似乎对此有很强烈的感受,我真的很惊讶,因为我没有遇到太多使用 rebase 的问题,而且我一直在使用它。 使用 rebase 的成本有多大?在实际使用中它给你带来了什…...
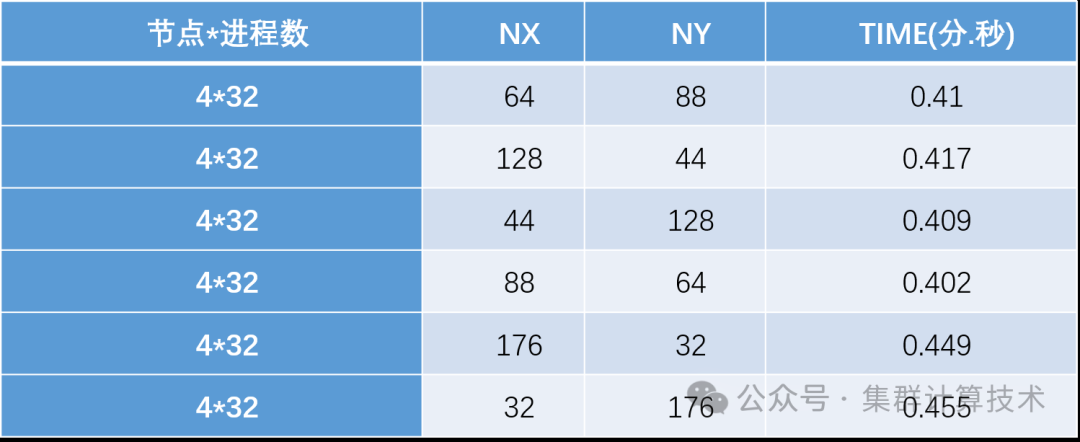
高性能计算应用优化实践之WRF
WRF(Weather Research Forecast)模式是由美国国家大气研究中心(NCAR)、国家环境预报中心(NCEP)等机构自1997年起联合开发的新一代高分辨率中尺度天气研究预报模式,重点解决分辨率为1~…...

nsight-compute使用教程
一 安装 有的时候在linux上安装上了nsight-compute,可以生成报告,但是却因为缺少qt组件而无法打开,我选择的方法是在linux上生成报告,在window上的nsight compute的图形界面打开,需要注意的是,nsight compute图形界面的版本一定要更高,不然无法打开 二 使用 2.1 生成…...

【深度学习】03-神经网络01-4 神经网络的pytorch搭建和参数计算
# 计算模型参数,查看模型结构,我们要查看有多少参数,需要先安装包 pip install torchsummary import torch import torch.nn as nn from torchsummary import summary # 导入 summary 函数,用于计算模型参数和查看模型结构# 创建神经网络模型类 class Mo…...

我与Linux的爱恋:命令行参数|环境变量
🔥个人主页:guoguoqiang. 🔥专栏:Linux的学习 文章目录 一.命令行参数二.环境变量1.环境变量的基本概念2.查看环境变量的方法3.环境变量相关命令4.环境变量的组织方式以及获取环境变量的三种方法 环境变量具有全局属性 一…...

django drf 统一Response格式
场景 需要将响应体按照格式规范返回给前端。 例如: 响应体中包含以下字段: {"result": true,"data": {},"code": 200,"message": "ok","request_id": "20cadfe4-51cd-42f6-af81-0…...

SM2协同签名算法中随机数K的随机性对算法安全的影响
前面介绍过若持有私钥d的用户两次SM2签名过程中随机数k相同,在对手获得两次签名结果Sig1和Sig2的情况下,可破解私钥d。 具体见SM2签名算法中随机数K的随机性对算法安全的影响_sm2关闭随机数-CSDN博客 另关于SM2协同签名过程,具体见SM2协同签…...

解决setMouseTracking(true)后还是无法触发mouseMoveEvent的问题
如图,在给整体界面设置鼠标追踪且给ui界面的子控件也设置了鼠标追踪后,运行后的界面仍然有些地方移动鼠标无法触发 mouseMoveEvent函数,这就令人头痛。。。 我的解决方法是:重载event函数: 完美解决。。。...

基于深度学习的花卉智能分类识别系统
温馨提示:文末有 CSDN 平台官方提供的学长 QQ 名片 :) 1. 项目简介 传统的花卉分类方法通常依赖于专家的知识和经验,这种方法不仅耗时耗力,而且容易受到主观因素的影响。本系统利用 TensorFlow、Keras 等深度学习框架构建卷积神经网络&#…...

Springboot集成MongoDb快速入门
1. 什么是MongoDB 1.1. 基本概念 MongoDB是一个基于分布式文件存储 [1] 的数据库。由C语言编写。旨在为WEB应用提供可扩展的高性能数据存储解决方案。 MongoDB是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数…...

DERT目标检测—End-to-End Object Detection with Transformers
DERT:使用Transformer的端到端目标检测 论文题目:End-to-End Object Detection with Transformers 官方代码:https://github.com/facebookresearch/detr 论文题目中包括的一个创新点End to End(端到端的方法)简单的理解就是没有使…...

软件后端开发速度慢的科技公司老板有没有思考如何破局
最近接到两个科技公司咨询,说是他们公司后端开发速度太慢,前端程序员老等着,后端程序员拖了项目进度。 这种问题不只他们公司,在软件外包公司中,有一部分项目甲方客户要得急,以至于要求软件开发要快&#…...

开放原子超级链内核XuperCore可搭建区块链
区块链是一种分布式数据库技术,它以块的形式存储数据,并使用密码学方法保证数据的安全性和完整性。 每个块包含一定数量的交易信息,并通过加密链接到前一个块,形成一个不断增长的链条。 这种设计使得数据在网络中无法被篡改,因为任何尝试修改一个块的数据都会破坏整个链的…...

idea大量爆红问题解决
问题描述 在学习和工作中,idea是程序员不可缺少的一个工具,但是突然在有些时候就会出现大量爆红的问题,发现无法跳转,无论是关机重启或者是替换root都无法解决 就是如上所展示的问题,但是程序依然可以启动。 问题解决…...

【WiFi帧结构】
文章目录 帧结构MAC头部管理帧 帧结构 Wi-Fi的帧分为三部分组成:MAC头部frame bodyFCS,其中MAC是固定格式的,frame body是可变长度。 MAC头部有frame control,duration,address1,address2,addre…...

Psychopy音频的使用
Psychopy音频的使用 本文主要解决以下问题: 指定音频引擎与设备;播放音频文件 本文所使用的环境: Python3.10 numpy2.2.6 psychopy2025.1.1 psychtoolbox3.0.19.14 一、音频配置 Psychopy文档链接为Sound - for audio playback — Psy…...

Swagger和OpenApi的前世今生
Swagger与OpenAPI的关系演进是API标准化进程中的重要篇章,二者共同塑造了现代RESTful API的开发范式。 本期就扒一扒其技术演进的关键节点与核心逻辑: 🔄 一、起源与初创期:Swagger的诞生(2010-2014) 核心…...
Mobile ALOHA全身模仿学习
一、题目 Mobile ALOHA:通过低成本全身远程操作学习双手移动操作 传统模仿学习(Imitation Learning)缺点:聚焦与桌面操作,缺乏通用任务所需的移动性和灵活性 本论文优点:(1)在ALOHA…...

基于TurtleBot3在Gazebo地图实现机器人远程控制
1. TurtleBot3环境配置 # 下载TurtleBot3核心包 mkdir -p ~/catkin_ws/src cd ~/catkin_ws/src git clone -b noetic-devel https://github.com/ROBOTIS-GIT/turtlebot3.git git clone -b noetic https://github.com/ROBOTIS-GIT/turtlebot3_msgs.git git clone -b noetic-dev…...

使用LangGraph和LangSmith构建多智能体人工智能系统
现在,通过组合几个较小的子智能体来创建一个强大的人工智能智能体正成为一种趋势。但这也带来了一些挑战,比如减少幻觉、管理对话流程、在测试期间留意智能体的工作方式、允许人工介入以及评估其性能。你需要进行大量的反复试验。 在这篇博客〔原作者&a…...

MFC 抛体运动模拟:常见问题解决与界面美化
在 MFC 中开发抛体运动模拟程序时,我们常遇到 轨迹残留、无效刷新、视觉单调、物理逻辑瑕疵 等问题。本文将针对这些痛点,详细解析原因并提供解决方案,同时兼顾界面美化,让模拟效果更专业、更高效。 问题一:历史轨迹与小球残影残留 现象 小球运动后,历史位置的 “残影”…...
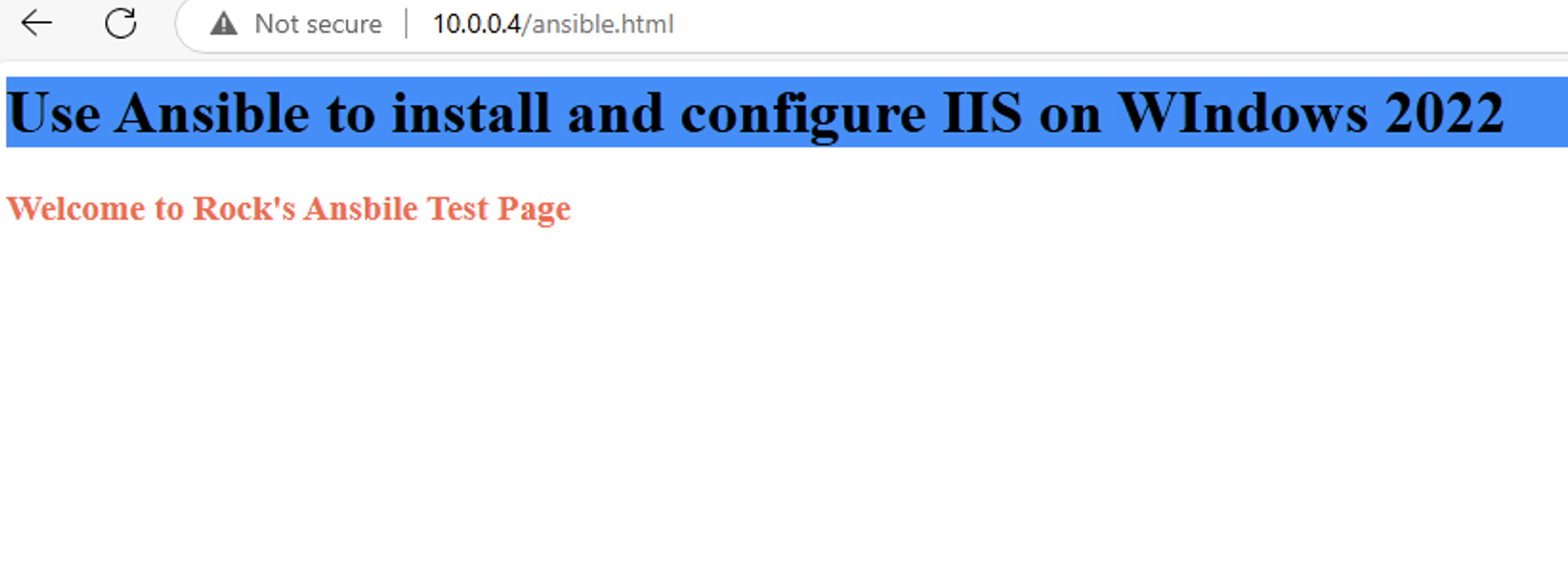
通过 Ansible 在 Windows 2022 上安装 IIS Web 服务器
拓扑结构 这是一个用于通过 Ansible 部署 IIS Web 服务器的实验室拓扑。 前提条件: 在被管理的节点上安装WinRm 准备一张自签名的证书 开放防火墙入站tcp 5985 5986端口 准备自签名证书 PS C:\Users\azureuser> $cert New-SelfSignedCertificate -DnsName &…...

提升移动端网页调试效率:WebDebugX 与常见工具组合实践
在日常移动端开发中,网页调试始终是一个高频但又极具挑战的环节。尤其在面对 iOS 与 Android 的混合技术栈、各种设备差异化行为时,开发者迫切需要一套高效、可靠且跨平台的调试方案。过去,我们或多或少使用过 Chrome DevTools、Remote Debug…...