基于OpenCV的实时年龄与性别识别(支持CPU和GPU)
关于深度实战社区
我们是一个深度学习领域的独立工作室。团队成员有:中科大硕士、纽约大学硕士、浙江大学硕士、华东理工博士等,曾在腾讯、百度、德勤等担任算法工程师/产品经理。全网20多万+粉丝,拥有2篇国家级人工智能发明专利。
社区特色:深度实战算法创新
获取全部完整项目数据集、代码、视频教程,请进入官网:zzgcz.com。竞赛/论文/毕设项目辅导答疑,v:zzgcz_com
1. 项目简介
本项目旨在实现一个基于OpenCV的实时年龄与性别识别系统,使用深度学习模型进行人脸检测和特征提取,并结合预训练的性别与年龄分类模型进行推断。随着计算机视觉和深度学习技术的快速发展,自动化的人脸识别和属性分类技术得到了广泛应用,包括安防监控、智能零售、人机交互等领域。本项目的目标是通过摄像头实时捕获用户的面部图像,并预测其年龄和性别,提升交互体验或为其他应用提供数据支持。项目中使用了深度学习网络进行人脸检测,并通过OpenCV DNN模块加载预训练的Caffe模型来实现年龄与性别分类。这些模型在大型数据集上训练,能够准确预测多种年龄段(例如0-2岁、4-6岁、25-32岁等)以及性别(男性、女性)。此外,项目支持在CPU和GPU上进行推理,以满足不同的计算资源需求。在CPU设备上,系统利用OpenCV的高效DNN加速推理;在GPU设备上,则通过CUDA优化模型计算,以加速性能。本项目的实现能够广泛应用于需要快速识别用户属性的场景,具有较强的实用性和扩展性。

2.技术创新点摘要
- 集成多个预训练模型的高效应用:项目采用了预训练的深度学习模型(Caffe模型)来实现性别与年龄的识别,结合了人脸检测、性别分类和年龄预测三个任务。使用OpenCV的DNN模块对预训练的性别和年龄模型进行推理,能够有效降低开发难度并加快实现速度。此外,这些模型在大规模数据集上训练,具备较高的准确率和鲁棒性,尤其适合实时应用场景。
- CPU与GPU设备的自适应支持:代码中针对CPU和GPU设备进行了不同的优化处理,使得模型能够灵活地在不同计算资源下运行。对于CPU设备,OpenCV的DNN模块能够在非GPU硬件上高效推理。而对于GPU设备,代码通过CUDA支持,利用GPU加速推理过程,大幅提升了处理速度。这种对硬件的自适应支持,显著提高了系统的可移植性和运行效率,尤其适用于需要高性能推理的应用场景。
- 基于OpenCV的高效人脸检测:项目中使用了基于OpenCV的深度神经网络模块进行人脸检测,采用了高置信度的检测机制来确保检测到的人脸位置准确无误。代码通过对检测结果的置信度进行过滤,避免了低置信度的人脸检测误报,从而提升了识别的准确性。此外,在检测到人脸后,程序为每个检测到的人脸进行精细化裁剪,为后续的性别与年龄分类提供了高质量的输入数据。
- 实时视频处理与多任务并行:代码不仅能够处理静态图像,还能通过摄像头流的方式实时捕捉帧并进行连续的识别处理。每一帧视频都经过人脸检测、裁剪、年龄和性别分类等多重步骤,确保系统在实时场景中的流畅性和准确性。这种多任务并行处理的架构为后续的扩展提供了良好的基础。
3. 数据集与预处理
本项目的核心使用了预训练的Caffe模型进行年龄和性别识别,模型的训练数据集来源于广泛的人脸识别数据集,如IMDB-WIKI数据集和Adience数据集。这些数据集包含了大量标注好的人脸图像,涵盖了不同性别、年龄段、种族以及多样的拍摄角度和光照条件。IMDB-WIKI数据集是目前最大的公开人脸年龄数据集,包含超过50万张图像及其对应的年龄标签。Adience数据集则专注于年龄分段(Age Group)和性别预测,具备较高的分类精度,是学术界和工业界常用的测试集。
在预处理阶段,项目首先对输入图像或视频流进行人脸检测。检测后的人脸图像会被裁剪到指定的尺寸(227x227),确保模型输入图像的标准化。之后,代码采用了OpenCV的blobFromImage函数进行预处理操作,包括将图像从RGB转换为BGR格式,进行像素值的均值减法(使用预定义的均值值:78.4、87.8、114.9)以及尺寸调整,生成适合深度学习模型输入的blob数据。模型预期输入的图像通道顺序与原始图像格式不同,因此进行了通道变换,确保在推理时不会因通道错乱而导致识别精度下降。
此外,该项目对输入图像未使用复杂的数据增强(如旋转、平移、镜像等),主要是因为模型在大规模数据集上已具备较强的泛化能力。然而,项目中的每一帧图像都会进行逐帧裁剪和检测,确保在不同姿势和光照条件下的人脸都能被准确识别。
4. 模型架构
1. 模型结构逻辑
本项目使用了基于Caffe框架预训练的深度学习模型进行年龄和性别识别,模型主要包括三部分:人脸检测模型、年龄分类模型和性别分类模型。以下是每个模型的架构和功能:
(1) 人脸检测模型
该模型使用了OpenCV提供的基于深度学习的ResNet架构进行人脸检测,网络结构包含多层卷积、池化和全连接层,核心是用来识别图像中存在的人脸区域。输入图像首先经过卷积层(Convolutional Layer),计算公式为:
Z = W ⋅ X + b Z = W \cdot X + b Z=W⋅X+b
其中,W 表示卷积核权重矩阵,X 表示输入图像,b 是偏置项,Z 是经过卷积层后的特征图。之后,通过多层卷积和池化(Pooling)层逐步提取图像特征,并通过全连接层将特征映射到二维坐标空间(Bounding Box的坐标)。该模型输出的格式为:每个人脸的置信度分数以及对应的矩形框(x1, y1, x2, y2)。
(2) 年龄识别模型
年龄识别模型是基于Caffe框架的轻量级卷积神经网络(CNN),网络输入为经过归一化的面部图像,输出为8个类别的概率分布(对应不同的年龄区间)。该模型的主要结构为:
- 输入层:接收大小为227x227的面部图像。
- 卷积层1:提取低层次特征(如边缘和纹理),卷积操作公式同上。
- 池化层(Pooling Layer) :进行降维,减少计算复杂度。
- 全连接层(Fully Connected Layer) :将特征向量映射到年龄分布概率空间。输出的概率分布计算公式为:
P ( y = j ∣ x ) = exp ( W j ⋅ x + b j ) ∑ k = 1 K exp ( W k ⋅ x + b k ) P(y=j|x) = \frac{\exp(W_j \cdot x + b_j)}{\sum_{k=1}^{K} \exp(W_k \cdot x + b_k)} P(y=j∣x)=∑k=1Kexp(Wk⋅x+bk)exp(Wj⋅x+bj)
其中,Wj和 bj是第j类别的权重和偏置项,P(y=j∣x) 表示输入图像 x 属于第 j 个年龄区间的概率。
(3) 性别识别模型
性别识别模型结构与年龄识别模型类似,但输出为两个类别(男性和女性)。输入的面部图像经过卷积和池化层后,映射到两个输出类别。性别分类采用Softmax层进行概率估计:
P ( y = male ∣ x ) = exp ( W male ⋅ x + b male ) exp ( W male ⋅ x + b male ) + exp ( W female ⋅ x + b female ) P(y=\text{male}|x) = \frac{\exp(W_{\text{male}} \cdot x + b_{\text{male}})}{\exp(W_{\text{male}} \cdot x + b_{\text{male}}) + \exp(W_{\text{female}} \cdot x + b_{\text{female}})} P(y=male∣x)=exp(Wmale⋅x+bmale)+exp(Wfemale⋅x+bfemale)exp(Wmale⋅x+bmale)
同样,P(y=male∣x)表示输入图像被识别为男性的概率,输出最大概率的类别即为模型的性别预测结果。
2. 模型整体训练流程
虽然项目中使用了预训练模型,但在训练这些模型时通常经历了以下几个步骤:
-
数据准备与预处理:从IMDB-WIKI或Adience数据集获取人脸图像,进行裁剪、尺寸缩放、颜色归一化处理。将图像标签进行One-Hot编码(性别二分类,年龄为多类别分类)。
-
模型架构设计与初始化:采用轻量级CNN模型,初始化权重参数(使用Xavier或He初始化方法)。
-
损失函数选择:
- 年龄识别:使用交叉熵损失函数(Cross-Entropy Loss),计算类别概率分布与真实标签之间的误差。
-
L age = − ∑ i = 1 N ∑ j = 1 K y i j ⋅ log ( P i j ) L_{\text{age}} = -\sum_{i=1}^{N} \sum_{j=1}^{K} y_{ij} \cdot \log(P_{ij}) Lage=−i=1∑Nj=1∑Kyij⋅log(Pij)其中,yij 表示第 i 张图像属于第 j 类别的标签值(0或1),Pij 为模型预测的概率。
- 性别识别:采用二分类交叉熵损失,计算性别的分类误差。
-
优化器选择:采用Adam或SGD优化器进行反向传播,调整网络权重。学习率初始设定为0.001,并在训练过程中动态衰减。
-
训练过程:通过前向传播计算损失值,再进行反向传播更新权重。每次迭代时计算训练集的准确率,并记录验证集的性能,防止过拟合。
-
模型评估指标:
- 准确率(Accuracy) :用于衡量模型对性别和年龄预测的整体性能。
- 混淆矩阵(Confusion Matrix) :衡量每个类别的分类效果。
- 平均绝对误差(Mean Absolute Error, MAE) :用于评估年龄预测的连续误差。
通过这些流程,模型能够逐步提升在性别和年龄分类任务中的性能,确保在不同应用场景下均能保持较高的准确性。
5. 核心代码详细讲解
1. 数据预处理与人脸检测
def getFaceBox(net, frame, conf_threshold=0.7):frameOpencvDnn = frame.copy()frameHeight = frameOpencvDnn.shape[0]frameWidth = frameOpencvDnn.shape[1]blob = cv.dnn.blobFromImage(frameOpencvDnn, 1.0, (300, 300), [104, 117, 123], True, False)
-
def getFaceBox(net, frame, conf_threshold=0.7): 定义了一个名为getFaceBox的函数,用于通过预训练的人脸检测网络 (net) 从输入帧图像 (frame) 中检测人脸。conf_threshold参数指定了用于过滤低置信度检测框的阈值(默认为0.7)。 -
frameOpencvDnn = frame.copy(): 复制输入的帧图像,确保不会在原始图像上进行操作。 -
frameHeight = frameOpencvDnn.shape[0]&frameWidth = frameOpencvDnn.shape[1]: 分别获取输入图像的高度和宽度,用于后续计算边界框坐标。 -
blob = cv.dnn.blobFromImage(frameOpencvDnn, 1.0, (300, 300), [104, 117, 123], True, False):- 使用
cv.dnn.blobFromImage函数将输入图像转换为OpenCV DNN(深度神经网络)模块可以处理的格式。这个函数的作用是进行图像的预处理操作,将图像归一化,并调整输入数据格式。 1.0是缩放比例(scale factor),表示不缩放。(300, 300)是目标输入图像的尺寸,即将图像调整到 300x300 大小。[104, 117, 123]是各个通道(BGR)所需减去的均值,用来标准化输入数据。True参数表示是否将颜色通道从 RGB 转换为 BGR 格式(OpenCV 的标准格式)。False表示不进行图像裁剪(crop)。
- 使用
2. 模型输入与检测结果的处理
net.setInput(blob) ``detections = net.forward()
net.setInput(blob): 将预处理后的输入图像blob送入深度神经网络net中,以便进行前向传播(forward pass)计算。detections = net.forward(): 调用网络的forward方法,获取网络的检测结果。detections是一个包含检测到的所有边界框、类别置信度等信息的矩阵。
3. 边界框坐标解析与过滤
bboxes = []
for i in range(detections.shape[2]):confidence = detections[0, 0, i, 2]if confidence > conf_threshold:x1 = int(detections[0, 0, i, 3] * frameWidth)y1 = int(detections[0, 0, i, 4] * frameHeight)x2 = int(detections[0, 0, i, 5] * frameWidth)y2 = int(detections[0, 0, i, 6] * frameHeight)bboxes.append([x1, y1, x2, y2])
bboxes = []: 初始化一个空列表,用于存储所有检测到的边界框。for i in range(detections.shape[2]): 遍历检测结果中的每个检测项。detections.shape[2]表示检测到的目标数量。confidence = detections[0, 0, i, 2]: 获取当前检测框的置信度分数(confidence score)。detections[0, 0, i, 2]表示第i个检测结果的置信度。if confidence > conf_threshold: 仅保留置信度分数大于阈值的检测结果(过滤掉置信度较低的检测框)。x1 = int(detections[0, 0, i, 3] * frameWidth)和y1 = int(detections[0, 0, i, 4] * frameHeight): 计算左上角坐标 (x1, y1) 的像素位置,原始检测结果是比例值,需要乘以图像的宽度和高度来获得实际坐标。x2 = int(detections[0, 0, i, 5] * frameWidth)和y2 = int(detections[0, 0, i, 6] * frameHeight): 计算右下角坐标 (x2, y2)。bboxes.append([x1, y1, x2, y2]): 将边界框的坐标信息(x1, y1, x2, y2)加入bboxes列表中,供后续绘制与处理。
4. 性别和年龄的预测
face = frame[max(0,bbox[1]-padding):min(bbox[3]+padding,frame.shape[0]-1), max(0,bbox[0]-padding):min(bbox[2]+padding, frame.shape[1]-1)]
blob = cv.dnn.blobFromImage(face, 1.0, (227, 227), MODEL_MEAN_VALUES, swapRB=False)
genderNet.setInput(blob)
genderPreds = genderNet.forward()
gender = genderList[genderPreds[0].argmax()]
face = frame[...: 裁剪出人脸区域。使用bbox中保存的边界框坐标,对原始图像frame进行裁剪。max和min函数用于防止越界。blob = cv.dnn.blobFromImage(face, 1.0, (227, 227), MODEL_MEAN_VALUES, swapRB=False): 对裁剪后的人脸图像进行预处理,生成大小为 227x227 的blob输入数据。MODEL_MEAN_VALUES是(78.4263377603, 87.7689143744, 114.895847746),即模型的预设均值,用于标准化输入数据。genderNet.setInput(blob): 将人脸数据blob输入到性别分类网络genderNet中。genderPreds = genderNet.forward(): 执行前向传播,输出性别的预测结果。genderPreds是一个大小为 [1, 2] 的向量,表示预测为男性或女性的概率。gender = genderList[genderPreds[0].argmax()]: 使用argmax()方法获取预测概率最大的类别索引,并转换为性别字符串(“Male” 或 “Female”)。
5. 结果显示
cv.putText(frameFace, label, (bbox[0], bbox[1]-10), cv.FONT_HERSHEY_SIMPLEX, 0.8, (0, 255, 255), 2, cv.LINE_AA)
cv.imshow("Age Gender Demo", frameFace)
cv.putText(frameFace, label, (bbox[0], bbox[1]-10), ...): 在检测到的人脸上方显示性别与年龄标签(label)。(bbox[0], bbox[1]-10)表示文本显示的起始坐标。cv.FONT_HERSHEY_SIMPLEX是字体类型,0.8为字体大小,(0, 255, 255)是黄色字体颜色,2是文本粗细,cv.LINE_AA是反锯齿线条类型。cv.imshow("Age Gender Demo", frameFace): 在OpenCV窗口中显示处理后的视频帧。
6. 模型优缺点评价
模型优点:
- 高效的多任务集成:项目通过结合人脸检测、性别分类和年龄预测模型,能够在一个流程中实现多种识别任务,节省了计算开销,并确保了任务的高效性。
- 实时性较好:该项目使用了OpenCV的DNN模块,能够在CPU和GPU上灵活切换。通过CUDA优化实现了GPU加速,使模型可以在实时场景中进行流畅的视频推理,提升了实际应用效果。
- 预训练模型泛化能力强:使用IMDB-WIKI和Adience等大规模数据集训练的模型,具有良好的泛化能力,能够在不同场景、不同光照条件下准确预测性别和年龄。
模型缺点:
- 精度有限:模型使用了轻量级的深度学习网络,虽然适合实时性,但在复杂的年龄段(如中年和老年)分类上存在较大的误差。此外,性别分类可能受光照、遮挡和面部表情的影响而不稳定。
- 鲁棒性不足:该模型在处理非标准人脸(如侧脸、低分辨率、过度曝光)时可能存在较高的误检率和漏检率。
- 模型规模较小:模型的复杂度较低,可能无法充分提取深层次的图像特征,从而影响其在不同人种、特殊年龄段上的表现。
可能的模型改进方向:
- 引入更深的神经网络架构:可以尝试使用ResNet、MobileNet等更深或更复杂的网络结构,以提升模型的特征提取能力,从而提升预测精度。
- 增加数据增强策略:在训练数据上引入更多的数据增强方法,如随机旋转、水平翻转、亮度调节等,增强模型对各种非理想条件的适应性。
- 超参数优化:可以通过调整学习率、权重初始化、优化器选择等方法来改善模型的收敛速度与最终精度。
通过这些优化,可以提升模型的准确率和鲁棒性,使其更好地应对复杂的实际场景。
↓↓↓更多热门推荐:
LSTM预测未来30天销售额
基于小波变换与稀疏表示优化的RIE数据深度学习预测模型
全部项目数据集、代码、教程进入官网zzgcz.com
相关文章:
基于OpenCV的实时年龄与性别识别(支持CPU和GPU)
关于深度实战社区 我们是一个深度学习领域的独立工作室。团队成员有:中科大硕士、纽约大学硕士、浙江大学硕士、华东理工博士等,曾在腾讯、百度、德勤等担任算法工程师/产品经理。全网20多万粉丝,拥有2篇国家级人工智能发明专利。 社区特色…...

理解Js执行上下文
执行上下文 执行上下文(Context)又称上下文,在 JavaScript 中是一个重要的概念,它决定了变量和函数的可访问性及其行为。每个上下文都有一个关联的变量对象(Variable Object),所有在该上下文中定义的变量和…...

微信小程序 蓝牙通讯
客户的需求如下:通过微信小程序控制蓝牙ble设备(电子面膜),通过不同指令控制面膜的亮度和时间。 01.首先看下客户的ble设备服务文档:(本部分需要有点蓝牙基础,在调试过程中可以用安卓软件nRF Connect软件来执行测试命令) 0xFFF1灯控命令 命…...

java后端项目技术记录
后端使用技术记录 一、软件1. apifox,API管理软件问题 2. nginx前端服务器(1) 反向代理(2) 负载均衡 二、问题1. 使用spring全局异常处理器处理特定的异常2. 扩展springmvc的消息转换器(对象和json数据的转换)3. 路径参数的接收4. 实体构建器…...
PostgreSQL数据库与PostGIS在Windows中的部署与运行
本文介绍在Windows电脑中,下载、安装、部署并运行PostgreSQL与PostGIS数据库服务的方法。 PostgreSQL是一种功能强大的开源关系型数据库管理系统(RDBMS),以其稳定性、可靠性和丰富的功能而闻名;其支持多种高级特性&…...

高级算法设计与分析 学习笔记10 平摊分析
动态表,可以变长。 一溢出就另起一个两倍大小的表。 可以轻易证明把n个数字放进去的时间复杂度是O(n),n n/2 n/4……也就2n,插入数字本身也就是n,加起来最多不超过3n. 这种复杂度究竟是怎么算的?毕竟每次插入复杂度…...

从“纸面算力”到“好用算力”,超聚变打通AI+“最后一公里”
如果要评选2024年的年度科技名词,AI当属最热门的候选项。 年初的《政府工作报告》中首次提出了“人工智能”行动,正在从顶层设计着手,加快形成以人工智能为引擎的新质生产力。 折射到市场层面,AI作为一种新的范式,不…...

【有啥问啥】具身智能(Embodied AI):人工智能的新前沿
具身智能(Embodied AI):人工智能的新前沿 引言 在人工智能(AI)的进程中,具身智能(Embodied AI)正逐渐成为研究与应用的焦点。具身智能不仅关注于机器的计算能力,更强调…...

11-pg内核之锁管理器(六)死锁检测
概念 每个事务都在等待集合中的另一事务,由于这个集合是一个有限集合,因此一旦在这个等待的链条上产生了环,就会产生死锁。自旋锁和轻量锁属于系统锁,他们目前没有死锁检测机制,只能靠内核开发人员在开发过程中谨慎的…...

Git 与标签管理
在 Git 中,标签 tag 是指向某个 commit 的指针(所以创建和删除都很快)。Git 有 commit id 了,为什么还要有 tag?commit id 是一串无规律的数字,不好记;而 tag 是我们自定义的,例如我…...
初始化 MyPgXact)
【0334】Postgres内核之 auxiliary process(辅助进程)初始化 MyPgXact
1. MyPgXact(ProcGlobal->allPgXact)间接初始化 在上一篇文章【0333】Postgres内核之 auxiliary process(辅助进程)创建 PGPROC 中, 讲解了Postgres内核完成 AuxiliaryProcess 初始化 pid、lxid、procLatch、myProcLocks、lockGroupMembers等所有成员的过程。 这些成员…...

20.1 分析pull模型在k8s中的应用,对比push模型
本节重点介绍 : push模型和pull模型监控系统对比为什么在k8s中只能用pull模型的k8s中主要组件的暴露地址说明 push模型和pull模型监控系统 对比下两种系统采用的不同采集模型,即push型采集和pull型采集。不同的模型在性能的考虑上是截然不同的。下面表格简单的说…...

Ubuntu 镜像替换为阿里云镜像:简化你的下载体验
Ubuntu,作为一款广受欢迎的Linux发行版,以其稳定性和易用性著称。但你是否曾因为下载速度慢而感到沮丧?现在,你可以通过将Ubuntu的默认下载源替换为阿里云镜像来解决这个问题。本文将指导你如何完成这一过程。 为什么选择阿里云镜…...

The Sandbox 游戏制作教程第 6 章|如何使用装备制作出色的游戏 —— 避免环境危险
欢迎回到我们的系列,我们将记录 The Sandbox Game Maker 的 “On-Equip”(装备)功能的多种用途。 如果你刚加入 The Sandbox,装备功能是 “可收集组件”(Collectable Component)中的一个多功能工具…...

JavaScript中的输出方式
1. console.log() console.log() 是开发者在调试代码时最常用的方法。它将信息打印到浏览器的控制台,使开发者能够查看变量的值、程序的执行状态以及其他有用的信息。 用途:用于调试和记录程序运行时的信息。优点:简单易用,适合…...

力扣9.25
2306. 公司命名 给你一个字符串数组 ideas 表示在公司命名过程中使用的名字列表。公司命名流程如下: 从 ideas 中选择 2 个 不同 名字,称为 ideaA 和 ideaB 。 交换 ideaA 和 ideaB 的首字母。 如果得到的两个新名字 都 不在ideas 中,那么 …...

从零开始之AI面试小程序
从零开始之AI面试小程序 文章目录 从零开始之AI面试小程序前言一、工具列表二、开发部署流程1. VMWare安装2. Centos安装3. Centos环境配置3.1. 更改子网IP3.2. 配置静态IP地址 4. Docker和Docker Compose安装5. Docker镜像加速源配置6. 部署中间件6.1. MySQL部署6.2. Redis部署…...
Html2OpenXml:HTML转化为OpenXml的.Net库,轻松实现Html转为Word。
推荐一个开源库,轻松实现HTML转化为OpenXml。 01 项目简介 Html2OpenXml 是一个开源.Net库,旨在将简单或复杂的HTML内容转换为OpenXml组件。 该项目始于2009年,最初是为了将用户评论转换为Word文档而设计的 随着时间的推移,Ht…...

HumanNeRF:Free-viewpoint Rendering of Moving People from Monocular Video 精读
1. 姿态估计和骨架变换模块 人体姿态估计:HumanNeRF 通过已知的单目视频对视频中人物的姿态进行估计。常见的方法是通过人体姿态估计器(如 OpenPose 或 SMPL 模型)提取人物的骨架信息,获取 3D 关节的位置信息。这些关节信息可以帮…...
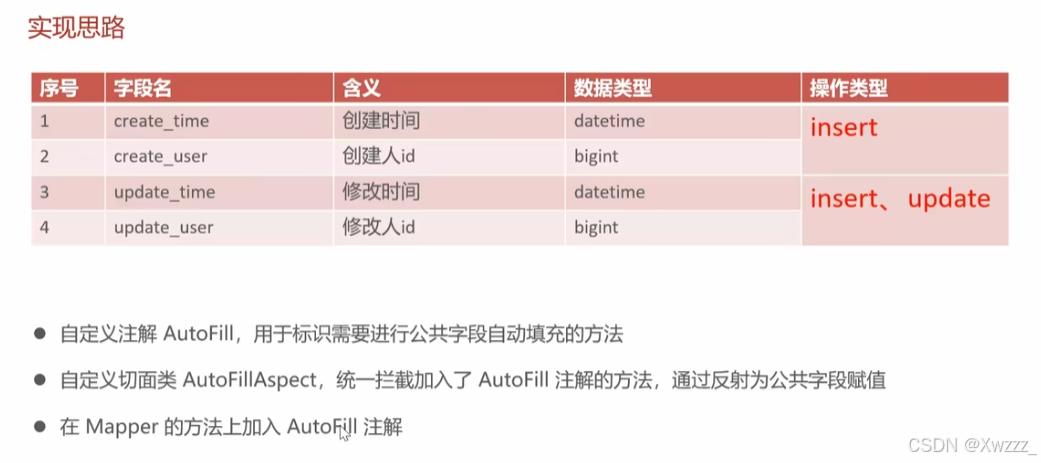
Springboot中基于注解实现公共字段自动填充
1.使用场景 当我们有大量的表需要管理公共字段,并且希望提高开发效率和确保数据一致性时,使用这种自动填充方式是很有必要的。它可以达到一下作用 统一管理数据库表中的公共字段:如创建时间、修改时间、创建人ID、修改人ID等,这些…...

wordpress后台更新后 前端没变化的解决方法
使用siteground主机的wordpress网站,会出现更新了网站内容和修改了php模板文件、js文件、css文件、图片文件后,网站没有变化的情况。 不熟悉siteground主机的新手,遇到这个问题,就很抓狂,明明是哪都没操作错误&#x…...

第19节 Node.js Express 框架
Express 是一个为Node.js设计的web开发框架,它基于nodejs平台。 Express 简介 Express是一个简洁而灵活的node.js Web应用框架, 提供了一系列强大特性帮助你创建各种Web应用,和丰富的HTTP工具。 使用Express可以快速地搭建一个完整功能的网站。 Expre…...

css实现圆环展示百分比,根据值动态展示所占比例
代码如下 <view class""><view class"circle-chart"><view v-if"!!num" class"pie-item" :style"{background: conic-gradient(var(--one-color) 0%,#E9E6F1 ${num}%),}"></view><view v-else …...

从零实现富文本编辑器#5-编辑器选区模型的状态结构表达
先前我们总结了浏览器选区模型的交互策略,并且实现了基本的选区操作,还调研了自绘选区的实现。那么相对的,我们还需要设计编辑器的选区表达,也可以称为模型选区。编辑器中应用变更时的操作范围,就是以模型选区为基准来…...

MongoDB学习和应用(高效的非关系型数据库)
一丶 MongoDB简介 对于社交类软件的功能,我们需要对它的功能特点进行分析: 数据量会随着用户数增大而增大读多写少价值较低非好友看不到其动态信息地理位置的查询… 针对以上特点进行分析各大存储工具: mysql:关系型数据库&am…...

线程同步:确保多线程程序的安全与高效!
全文目录: 开篇语前序前言第一部分:线程同步的概念与问题1.1 线程同步的概念1.2 线程同步的问题1.3 线程同步的解决方案 第二部分:synchronized关键字的使用2.1 使用 synchronized修饰方法2.2 使用 synchronized修饰代码块 第三部分ÿ…...

YSYX学习记录(八)
C语言,练习0: 先创建一个文件夹,我用的是物理机: 安装build-essential 练习1: 我注释掉了 #include <stdio.h> 出现下面错误 在你的文本编辑器中打开ex1文件,随机修改或删除一部分,之后…...

STM32F4基本定时器使用和原理详解
STM32F4基本定时器使用和原理详解 前言如何确定定时器挂载在哪条时钟线上配置及使用方法参数配置PrescalerCounter ModeCounter Periodauto-reload preloadTrigger Event Selection 中断配置生成的代码及使用方法初始化代码基本定时器触发DCA或者ADC的代码讲解中断代码定时启动…...

【Java_EE】Spring MVC
目录 Spring Web MVC 编辑注解 RestController RequestMapping RequestParam RequestParam RequestBody PathVariable RequestPart 参数传递 注意事项 编辑参数重命名 RequestParam 编辑编辑传递集合 RequestParam 传递JSON数据 编辑RequestBody …...

数据库分批入库
今天在工作中,遇到一个问题,就是分批查询的时候,由于批次过大导致出现了一些问题,一下是问题描述和解决方案: 示例: // 假设已有数据列表 dataList 和 PreparedStatement pstmt int batchSize 1000; // …...