QLoRA代码实战
QLoRA原理参考:
BiliBili:4bit量化与QLoRA模型训练
zhihu:QLoRA(Quantized LoRA)详解
下载llama3-8b模型
from modelscope import snapshot_download
model_dir = snapshot_download('LLM-Research/Meta-Llama-3-8B-Instruct')
设置quantization_config
from transformers import BitsAndBytesConfigquantization_config = BitsAndBytesConfig(load_in_4bit=True,bnb_4bit_quant_type="nf4",bnb_4bit_use_double_quant=True,bnb_4bit_compute_dtype=torch.bfloat16,
)
加载模型
加载量化后的llama3-8b模型,大概需要6G的GPU显存。
from transformers import AutoModelForCausalLM,AutoTokenizer,TrainingArguments,Trainer,DataCollatorForSeq2Seq
model = AutoModelForCausalLM.from_pretrained(model_dir,quantization_config=quantization_config,low_cpu_mem_usage=True)
tokenizer = AutoTokenizer.from_pretrained(model_dir)
一层的数据类型,可以看到除了layernorm,linear层都进行了量化。
model.layers.0.self_attn.q_proj.weight torch.uint8
model.layers.0.self_attn.k_proj.weight torch.uint8
model.layers.0.self_attn.v_proj.weight torch.uint8
model.layers.0.self_attn.o_proj.weight torch.uint8
model.layers.0.mlp.gate_proj.weight torch.uint8
model.layers.0.mlp.up_proj.weight torch.uint8
model.layers.0.mlp.down_proj.weight torch.uint8
model.layers.0.input_layernorm.weight torch.float16
model.layers.0.post_attention_layernorm.weight torch.float16
预处理模型
from peft import prepare_model_for_kbit_training
model = prepare_model_for_kbit_training(model)
设置LoRA参数
这里使用了默认设置,参数target_modules和modules_to_save可以设置具体训练哪些模块。
在peft/utils/constants.py中,默认定义了各种模型的LoRA target modules,llama模型对Q和V进行lora。
"llama": ["q_proj", "v_proj"],
config = LoraConfig(task_type=TaskType.CAUSAL_LM)
model = get_peft_model(model, config)
model.print_trainable_parameters()
#trainable params: 3,407,872 || all params: 8,033,669,120 || trainable%: 0.0424
print(model) #加入了LoRA后的模型结构。
加载并处理数据
数据下载:AI-ModelScope/alpaca-gpt4-data-zh
需要把下载的数据中dataset_infos.json 重命名为datasets_info.json,这样才能正确加载。
from datasets import load_datasetdataset = load_dataset("alpaca-data-zh")def process_func(example):# print(example)MAX_LENGTH = 256input_ids, attention_mask, labels = [], [], []# 将prompt进行tokenize,这里我们没有利用tokenizer进行填充和截断# 这里我们自己进行截断,在DataLoader的collate_fn函数中进行填充input = example["input"] if example["input"] is not None else ''instruction = tokenizer("\n".join(["Human: " + example["instruction"], input]).strip() + "\n\nAssistant: ")# 将output进行tokenize,注意添加eos_tokenresponse = tokenizer(example["output"] + tokenizer.eos_token)# 将instruction + output组合为inputinput_ids = instruction["input_ids"] + response["input_ids"]attention_mask = instruction["attention_mask"] + response["attention_mask"]# prompt设置为-100,不计算losslabels = [-100] * len(instruction["input_ids"]) + response["input_ids"]# 设置最大长度,进行截断if len(input_ids) > MAX_LENGTH:input_ids = input_ids[:MAX_LENGTH]attention_mask = attention_mask[:MAX_LENGTH]labels = labels[:MAX_LENGTH]return {"input_ids": input_ids,"attention_mask": attention_mask,"labels": labels}tokenized_ds = dataset['train'].map(process_func, remove_columns=dataset['train'].column_names)
设置TrainingArguments
在per_device_train_batch_size=1的情况下,大概需要9G显存。
args = TrainingArguments(output_dir="./llama3_4bit",per_device_train_batch_size=4,gradient_accumulation_steps=32,logging_steps=10,num_train_epochs=1,save_strategy='epoch',learning_rate=1e-4,# gradient_checkpointing=True,# optim="paged_adamw_32bit")
训练
trainer = Trainer(model=model,args=args,tokenizer=tokenizer,train_dataset=tokenized_ds,data_collator=DataCollatorForSeq2Seq(tokenizer=tokenizer, padding=True),
)
trainer.train(resume_from_checkpoint=False)
加载qlora
from transformers import AutoModelForCausalLM,AutoTokenizer
model_path = model_dir #llama3-8b的路径
model = AutoModelForCausalLM.from_pretrained(model_path,quantization_config=config,low_cpu_mem_usage=True)
tokenizer = AutoTokenizer.from_pretrained(model_path)
model_qlora = PeftModel.from_pretrained(model=model,model_id="llama3_4bit/checkpoint-7") #qlora路径
#预测
ipt = tokenizer("Human: {}\n{}".format("怎么学习llm", "").strip() + "\n\nAssistant: ", return_tensors="pt").to(model.device)
tokenizer.decode(model_qlora.generate(**ipt, max_length=128, do_sample=True)[0], skip_special_tokens=True)
合并LoRA
合并后的模型大概5.4G。
merge_model = model_qlora.merge_and_unload()
merge_model.save_pretrained("llama3")
相关文章:

QLoRA代码实战
QLoRA原理参考: BiliBili:4bit量化与QLoRA模型训练 zhihu:QLoRA(Quantized LoRA)详解 下载llama3-8b模型 from modelscope import snapshot_download model_dir snapshot_download(LLM-Research/Meta-Llama-3-8B-In…...

pyqt QGraphicsView 以鼠标为中心进行缩放
注意几个关键点: 1. 初始化 class CustomGraphicsView(QGraphicsView):def __init__(self, parentNone):super(CustomGraphicsView, self).__init__(parent)self.scene QGraphicsScene()self.setScene(self.scene)self.setGeometry(0, 0, 1024, 600)# 以下初始化…...

FPGA-Vivado-IP核-逻辑分析仪(ILA)
ILA IP核 背景介绍 在用FPGA做工程项目时,当Verilog代码写好,我们需要对代码里面的一些关键信号进行上板验证查看。首先,我们可以把需要查看的这些关键信号引出来,接好线通过示波器进行实时监测,但这会用到大量的线材…...
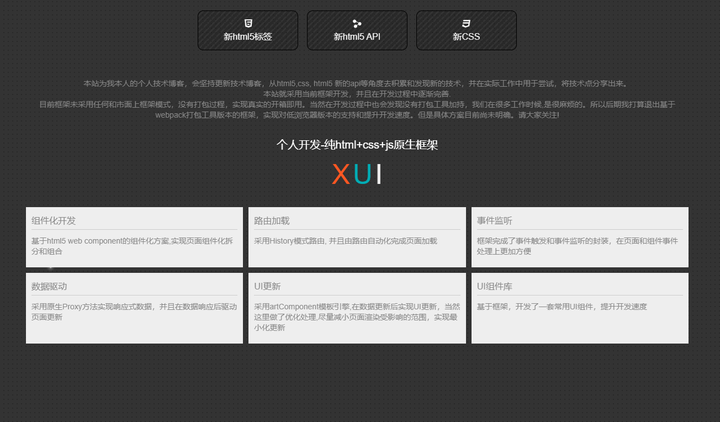
基于webComponents的纯原生前端框架
我本人的个人开发web前端前框架xui,正在开发中,业已完成50%的核心开发工作,并且在开发过程中逐渐完善. 目前框架未采用任何和市面上框架模式,没有打包过程,实现真实的开箱即用。 当然在开发过程中也会发现没有打包工…...

OpenCV-背景建模
文章目录 一、背景建模的目的二、背景建模的方法及原理三、背景建模实现四、总结 OpenCV中的背景建模是一种在计算机视觉中从视频序列中提取出静态背景的技术。以下是对OpenCV背景建模的详细解释: 一、背景建模的目的 背景建模的主要目标是将动态的前景对象与静态的…...

一个简单的摄像头应用程序6
主要改进点: 使用 ThreadPoolExecutor 管理多线程: 使用 concurrent.futures.ThreadPoolExecutor 来管理多线程,这样可以更高效地处理图像。 在 main 函数中创建一个 ThreadPoolExecutor,并在每个循环中提交图像处理任务。 减少…...

Pikachu-目录遍历
目录遍历,跟不安全文件上传下载有差不多; 访问 jarheads.php 、truman.php 都是通过 get 请求,往title 参数传参; 在后台,可以看到 jarheads.php 、truman.php所在目录: /var/www/html/vul/dir/soup 图片…...

用Python实现基于Flask的简单Web应用:从零开始构建个人博客
解锁Python编程的无限可能:《奇妙的Python》带你漫游代码世界 前言 在现代Web开发中,Python因其简洁、易用以及丰富的库生态系统,成为了许多开发者的首选编程语言。Flask作为一个轻量级的Python Web框架,以其简洁和灵活性深受开…...

IDEA的lombok插件不生效了?!!
记录一下,防止找不到解决方案,已经遇到好几次了 前面啰嗦的多,可以直接跳到末尾的解决方法,点击一下 问题现场情况 排查过程 确认引入的依赖正常 —》🆗 idea 是否安装了lombok插件 --》🆗 貌似没有问题…...

CSP-S 2022 T1假期计划
CSP-S 2022 T1假期计划 先思考暴力做法,题目需要找到四个不相同的景点,那我们就枚举这四个景点,判断它们之间的距离是否符合条件,条件是任意两个点之间的距离是否大于 k k k,所以我们需要求出任意两点之间的距离。常用…...

为什么要学习大模型?AI在把传统软件当早餐吃掉?
前言 上周末在推特平台上有一篇写在谷歌文档里的短文,在国外的科技/投资圈得到了非常广泛的浏览,叫做 The End of Software(软件的终结), 作者 Chris Paik 是位于纽约市的风险投资基金 Pace Capital 的创始合伙人&…...

全流程Python编程、机器学习与深度学习实践技术应用
近年来,人工智能领域的飞速发展极大地改变了各个行业的面貌。当前最新的技术动态,如大型语言模型和深度学习技术的发展,展示了深度学习和机器学习技术的强大潜力,成为推动创新和提升竞争力的关键。特别是PyTorch,凭借其…...

pWnos1.0 靶机渗透 (Perl CGI 的反弹 shell 利用)
靶机介绍 来自 vulnhub 主机发现 ┌──(kali㉿kali)-[~/testPwnos1.0] …...
 函数绑定无效)
jquery on() 函数绑定无效
on 前面的元素必须在页面加载的时候就存在于 dom 里面。动态的元素或者样式等,可以放在 on 的第二个参数里面。jQuery on() 方法是官方推荐的绑定事件的一个方法。使用 on() 方法可以给将来动态创建的动态元素绑定指定的事件,例如 append 等。 <div …...

数字化转型与企业创新的双向驱动
数字化转型与企业创新的双向驱动 在全球化的竞争环境中,数字化转型已成为企业保持竞争力的重要手段。未来几年,随着信息技术的进一步发展,数字化转型将不仅限于IT部门,而是深入到企业的各个业务层面,推动创新和效率的…...
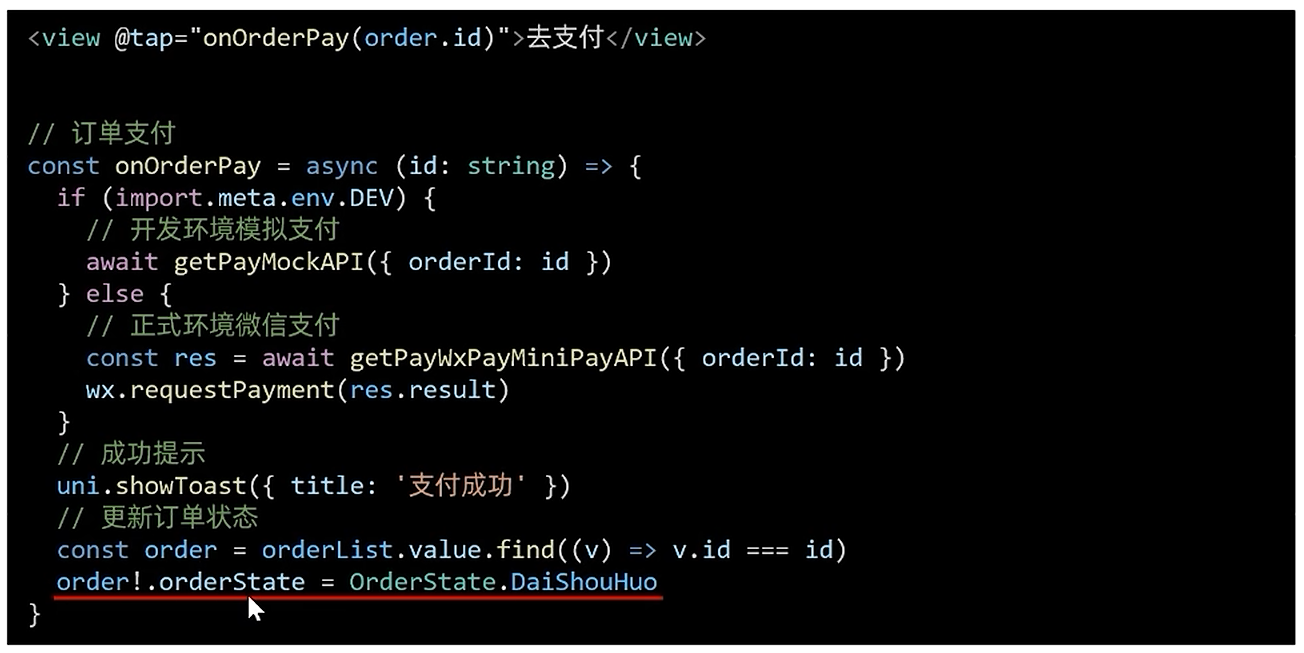
[uni-app]小兔鲜-07订单+支付
订单模块 基本信息渲染 import type { OrderState } from /services/constants import type { AddressItem } from ./address import type { PageParams } from /types/global/** 获取预付订单 返回信息 */ export type OrderPreResult {/** 商品集合 [ 商品信息 ] */goods: …...

Oracle数据库中表压缩的实现方式和特点
Oracle数据库中表压缩的实现方式和特点 在 Oracle 数据库中,表压缩是一项重要的功能,旨在优化存储空间和提高性能。Oracle 提供了多种表压缩技术,以适应不同的应用场景和需求。以下是 Oracle 数据库中表压缩的实现方式和特点: 1…...

【C语言】基础篇
简单输出“helloword” #include<stdio.h> int main(){printf("hello world!");return 0; } 和与商 #include<stdio.h> int main(){int a,b,sum,quotient;printf("Enter two numbers:");scanf("%d %d",&a,&b);sum a b…...

Meta MovieGen AI:颠覆性的文本生成视频技术详解
近年来,生成式AI技术的发展迅猛,尤其是在文本生成图像、文本生成视频等领域。Meta公司近期推出的MovieGen AI,以其强大的文本生成视频能力震撼了整个AI行业。本文将详细解读Meta MovieGen AI的核心技术、功能特性及其在实际应用中的潜力。 一…...

个人文章合集 - 前端相关
前端:简述表单提交前如何进行数据验证 前端:项目一个html中如何引入另一个html? 前端:一张图快速记忆CSS所有属性 前端:三个CSS预处理器(框架)-Sass、LESS 和 Stylus的比较 前端:基于Java角度理解nodejs/np…...

web vue 项目 Docker化部署
Web 项目 Docker 化部署详细教程 目录 Web 项目 Docker 化部署概述Dockerfile 详解 构建阶段生产阶段 构建和运行 Docker 镜像 1. Web 项目 Docker 化部署概述 Docker 化部署的主要步骤分为以下几个阶段: 构建阶段(Build Stage):…...
)
Java 语言特性(面试系列2)
一、SQL 基础 1. 复杂查询 (1)连接查询(JOIN) 内连接(INNER JOIN):返回两表匹配的记录。 SELECT e.name, d.dept_name FROM employees e INNER JOIN departments d ON e.dept_id d.dept_id; 左…...

微信小程序之bind和catch
这两个呢,都是绑定事件用的,具体使用有些小区别。 官方文档: 事件冒泡处理不同 bind:绑定的事件会向上冒泡,即触发当前组件的事件后,还会继续触发父组件的相同事件。例如,有一个子视图绑定了b…...

Spark 之 入门讲解详细版(1)
1、简介 1.1 Spark简介 Spark是加州大学伯克利分校AMP实验室(Algorithms, Machines, and People Lab)开发通用内存并行计算框架。Spark在2013年6月进入Apache成为孵化项目,8个月后成为Apache顶级项目,速度之快足见过人之处&…...

CentOS下的分布式内存计算Spark环境部署
一、Spark 核心架构与应用场景 1.1 分布式计算引擎的核心优势 Spark 是基于内存的分布式计算框架,相比 MapReduce 具有以下核心优势: 内存计算:数据可常驻内存,迭代计算性能提升 10-100 倍(文档段落:3-79…...

python如何将word的doc另存为docx
将 DOCX 文件另存为 DOCX 格式(Python 实现) 在 Python 中,你可以使用 python-docx 库来操作 Word 文档。不过需要注意的是,.doc 是旧的 Word 格式,而 .docx 是新的基于 XML 的格式。python-docx 只能处理 .docx 格式…...

【git】把本地更改提交远程新分支feature_g
创建并切换新分支 git checkout -b feature_g 添加并提交更改 git add . git commit -m “实现图片上传功能” 推送到远程 git push -u origin feature_g...

今日科技热点速览
🔥 今日科技热点速览 🎮 任天堂Switch 2 正式发售 任天堂新一代游戏主机 Switch 2 今日正式上线发售,主打更强图形性能与沉浸式体验,支持多模态交互,受到全球玩家热捧 。 🤖 人工智能持续突破 DeepSeek-R1&…...

OPenCV CUDA模块图像处理-----对图像执行 均值漂移滤波(Mean Shift Filtering)函数meanShiftFiltering()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 在 GPU 上对图像执行 均值漂移滤波(Mean Shift Filtering),用于图像分割或平滑处理。 该函数将输入图像中的…...

Linux --进程控制
本文从以下五个方面来初步认识进程控制: 目录 进程创建 进程终止 进程等待 进程替换 模拟实现一个微型shell 进程创建 在Linux系统中我们可以在一个进程使用系统调用fork()来创建子进程,创建出来的进程就是子进程,原来的进程为父进程。…...