实例分割、语义分割和 SAM(Segment Anything Model)
实例分割、语义分割和 SAM(Segment Anything Model) 都是图像处理中的重要技术,它们的目标是通过分割图像中的不同对象或区域来帮助识别和分析图像,但它们的工作方式和适用场景各有不同。
1. 语义分割(Semantic Segmentation)
- 目标: 语义分割的目的是将图像中的每个像素归类到某一个类别中,不区分同类中的不同个体。
- 特点: 语义分割只关心“类别”,而不关心图像中有多少个对象。换句话说,如果图像中有多辆车,它们都被归类为“车”,但不会区分不同的车。
- 应用场景: 自动驾驶中的道路、建筑物、行人分割,医学图像中的器官分割。
例子: 在城市街景中,语义分割会将所有的树木标记为同一个类别“树”,所有的道路标记为“道路”,而不会区分某一棵树或某一段路。
2. 实例分割(Instance Segmentation)
- 目标: 实例分割不仅要将每个像素归类到某个类别,还要区分同类中的不同个体。
- 特点: 实例分割可以同时进行物体检测和像素级的分割。例如,它不仅会检测图像中的车,还会为每辆车生成单独的掩码,从而区分同一图像中的不同车辆。
- 应用场景: 实例分割常用于自动驾驶、增强现实(AR)、机器人视觉、视频监控等领域,在这些场景中需要区分同类物体的不同个体。
例子: 在同样的城市街景中,实例分割不仅会识别“车”这个类别,还会区分每一辆车。
3. SAM(Segment Anything Model)
- 目标: SAM 是一种通用的分割模型,旨在实现“一切的分割”。它结合了语义分割和实例分割的能力,但更加灵活。
- 特点: SAM 能够在提供提示(如边界框、点)的情况下进行精确的分割,而无需针对特定任务或类别进行专门训练。这意味着你可以通过简单的提示(如边界框、点击目标)来触发分割操作,无论图像中是什么物体,SAM 都可以尝试分割。
- 应用场景: SAM 可以在任何需要分割的场景下应用,尤其适用于需要用户交互的场景,如图像标注、医疗图像分析、用户定制分割等。它能够分割新类别的物体,而不依赖于预先定义的类别。
例子: SAM 可以根据给定的边界框分割出手、车、动物等,而不需要事先知道物体的类别。用户也可以通过点选某些区域来生成物体的分割掩码。
主要区别:
-
类别和个体的区分:
- 语义分割: 只关心类别,所有属于同一类别的物体都会被统一处理,不区分个体。
- 实例分割: 不仅分割类别,还区分每个个体,即使是同一类别的物体,也会生成单独的掩码。
- SAM: 可以基于提示(如点、边界框)分割任意物体,具有更大的灵活性,不局限于某一特定类别或预先定义的任务。
-
应用场景:
- 语义分割: 适合场景分类和大范围的物体分割,如识别整个场景中的类别。
- 实例分割: 适合需要区分多个同类物体的场景,如自动驾驶中的行人、车辆检测。
- SAM: 适合任意分割任务,可以应对未知类别和灵活的用户交互需求。
-
灵活性:
- 语义分割和实例分割通常依赖于预先定义的类别或特定任务进行训练。
- SAM 是一种通用分割工具,能够根据用户的提示分割出几乎任何类型的物体,无需预先训练。
小结:
- 语义分割 是针对类别的分割,适用于大范围的场景分析。
- 实例分割 通过区分同类个体,提供更精细的对象分割。
- SAM 则是一种通用分割工具,灵活且不局限于特定类别和任务。
首先我们写一段简单的代码来看一下语义分割,语义分割就是可以把具体的某个像素点分给某个物体,而不是像目标检测一样用一个框标出

import torch
from torchvision import models, transforms
from PIL import Image
import matplotlib.pyplot as plt# 加载预训练的DeepLabV3模型
model = models.segmentation.deeplabv3_resnet101(pretrained=True).eval()# 图像预处理
preprocess = transforms.Compose([transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])# 加载图像
image_path = "path/000000000257.jpg" # 替换为你的图片路径
image = Image.open(image_path)
input_tensor = preprocess(image).unsqueeze(0)# 执行语义分割
with torch.no_grad():output = model(input_tensor)['out'][0]
output_predictions = output.argmax(0) # 获取每个像素的类别# 将分割结果可视化
plt.figure(figsize=(10, 5))# 显示原图
plt.subplot(1, 2, 1)
plt.imshow(image)
plt.title("Original Image")# 显示语义分割结果
plt.subplot(1, 2, 2)
plt.imshow(output_predictions.cpu().numpy())
plt.title("Semantic Segmentation")
plt.show()

把物体和背景有效进行区分了
实例分割
import torch
from PIL import Image
from torchvision import models, transforms
import matplotlib.pyplot as plt
import cv2
import numpy as np# 加载预训练的Mask R-CNN模型
model = models.detection.maskrcnn_resnet50_fpn(pretrained=True).eval()# 图像预处理
preprocess = transforms.Compose([transforms.ToTensor(),
])# 加载图像
image_path = "path/000000000257.jpg" # 替换为你的图片路径
image = Image.open(image_path)
input_tensor = preprocess(image).unsqueeze(0)# 执行实例分割
with torch.no_grad():output = model(input_tensor)# 获取分割掩码
masks = output[0]['masks'].cpu().numpy()
boxes = output[0]['boxes'].cpu().numpy()# 可视化边界框和实例掩码
image_cv = cv2.cvtColor(np.array(image), cv2.COLOR_RGB2BGR)
for i in range(len(masks)):mask = masks[i, 0] # 获取掩码mask = cv2.resize(mask, (image_cv.shape[1], image_cv.shape[0])) # 将掩码调整为与原图大小一致# 将掩码叠加到图像上image_cv[mask > 0.5] = [0, 0, 255] # 红色掩码# 绘制边界框box = boxes[i].astype(int)cv2.rectangle(image_cv, (box[0], box[1]), (box[2], box[3]), (255, 0, 0), 2) # 蓝色边框# 显示结果
plt.imshow(cv2.cvtColor(image_cv, cv2.COLOR_BGR2RGB))
plt.title("Instance Segmentation (Mask R-CNN)")
plt.show()

当然小编这里导入的语义分割和实例分割的模型差异导致了识别也有差异
SAM
import matplotlib.pyplot as plt
import numpy as np
from ultralytics import YOLO
from PIL import Image
import cv2
from segment_anything import SamPredictor, sam_model_registry# 加载图像
image_path = r'F:/photos/photo_1.jpg' # 替换为你的图片路径
image = Image.open(image_path)# 将图像转换为 OpenCV 格式以便显示
image_cv = cv2.cvtColor(np.array(image), cv2.COLOR_RGB2BGR)# 加载 YOLO 模型
yolo_model = YOLO("F:/科研学习/yolo系列params/v10/YOLOv10x_gestures.pt")
# yolo_model = YOLO("F:/科研学习/yolov11/yolov11/yolov11/资料/模型文件/yolov8n.pt")
yolo_results = yolo_model(image)# 加载 SAM 模型
sam_model = sam_model_registry["vit_l"](checkpoint="C:/Users/张佳珲/Downloads/sam_vit_l_0b3195.pth")
predictor = SamPredictor(sam_model)# 将整个图像传递给 SAM 模型
predictor.set_image(np.array(image)) # 传递整个图像# 遍历 YOLO 检测结果并绘制边界框
for result in yolo_results:if len(result.boxes) > 0: # 检查是否有检测到物体boxes = result.boxes.xyxy # YOLO 边界框for box in boxes:# 画出 YOLO 边界框 (蓝色)x1, y1, x2, y2 = map(int, box)cv2.rectangle(image_cv, (x1, y1), (x2, y2), (255, 0, 0), 2) # 蓝色框代表 YOLO 的检测# 使用 SAM 模型预测分割掩码masks, _, _ = predictor.predict(box=np.array([x1, y1, x2, y2]), multimask_output=False)# 获取掩码并直接叠加到原图上mask = masks[0] # 使用第一个掩码mask_uint8 = mask.astype(np.uint8) # 将布尔掩码转换为 uint8 类型# 调整掩码大小为与原图一致,并直接叠加到原图上mask_resized = cv2.resize(mask_uint8, (image_cv.shape[1], image_cv.shape[0]), interpolation=cv2.INTER_NEAREST)image_cv[mask_resized == 1] = [0, 0, 255] # 红色表示分割区域# 使用 Matplotlib 显示 YOLO 边界框和 SAM 分割的对比
fig, ax = plt.subplots(1, 1, figsize=(10, 10))# 显示叠加了 SAM 掩码和 YOLO 边界框的原图
ax.imshow(cv2.cvtColor(image_cv, cv2.COLOR_BGR2RGB))
ax.set_title("Original Image with SAM Segmentation and YOLO Bounding Box")plt.show()

相关文章:
实例分割、语义分割和 SAM(Segment Anything Model)
实例分割、语义分割和 SAM(Segment Anything Model) 都是图像处理中的重要技术,它们的目标是通过分割图像中的不同对象或区域来帮助识别和分析图像,但它们的工作方式和适用场景各有不同。 1. 语义分割(Semantic Segme…...

深度学习项目----用LSTM模型预测股价(包含LSTM网络简介,代码数据均可下载)
前言 前几天在看论文,打算复现,论文用到了LSTM,故这一篇文章是小编学LSTM模型的学习笔记;LSTM感觉很复杂,但是结合代码构建神经网络,又感觉还行;本次学习的案例数据来源于GitHub,在…...

《精通开关电源设计》笔记一
重点 效率 纹波 环路响应 尺寸,从静态到动态的研究方法,假设开关电源稳态运行,以电感为中心,根据半导体器件(mos管或二极管)分段分析电路的状态,工具有电路原理和能量守恒 影响效率的主要是开关损耗,所以…...

QLoRA代码实战
QLoRA原理参考: BiliBili:4bit量化与QLoRA模型训练 zhihu:QLoRA(Quantized LoRA)详解 下载llama3-8b模型 from modelscope import snapshot_download model_dir snapshot_download(LLM-Research/Meta-Llama-3-8B-In…...

pyqt QGraphicsView 以鼠标为中心进行缩放
注意几个关键点: 1. 初始化 class CustomGraphicsView(QGraphicsView):def __init__(self, parentNone):super(CustomGraphicsView, self).__init__(parent)self.scene QGraphicsScene()self.setScene(self.scene)self.setGeometry(0, 0, 1024, 600)# 以下初始化…...

FPGA-Vivado-IP核-逻辑分析仪(ILA)
ILA IP核 背景介绍 在用FPGA做工程项目时,当Verilog代码写好,我们需要对代码里面的一些关键信号进行上板验证查看。首先,我们可以把需要查看的这些关键信号引出来,接好线通过示波器进行实时监测,但这会用到大量的线材…...
基于webComponents的纯原生前端框架
我本人的个人开发web前端前框架xui,正在开发中,业已完成50%的核心开发工作,并且在开发过程中逐渐完善. 目前框架未采用任何和市面上框架模式,没有打包过程,实现真实的开箱即用。 当然在开发过程中也会发现没有打包工…...

OpenCV-背景建模
文章目录 一、背景建模的目的二、背景建模的方法及原理三、背景建模实现四、总结 OpenCV中的背景建模是一种在计算机视觉中从视频序列中提取出静态背景的技术。以下是对OpenCV背景建模的详细解释: 一、背景建模的目的 背景建模的主要目标是将动态的前景对象与静态的…...

一个简单的摄像头应用程序6
主要改进点: 使用 ThreadPoolExecutor 管理多线程: 使用 concurrent.futures.ThreadPoolExecutor 来管理多线程,这样可以更高效地处理图像。 在 main 函数中创建一个 ThreadPoolExecutor,并在每个循环中提交图像处理任务。 减少…...

Pikachu-目录遍历
目录遍历,跟不安全文件上传下载有差不多; 访问 jarheads.php 、truman.php 都是通过 get 请求,往title 参数传参; 在后台,可以看到 jarheads.php 、truman.php所在目录: /var/www/html/vul/dir/soup 图片…...

用Python实现基于Flask的简单Web应用:从零开始构建个人博客
解锁Python编程的无限可能:《奇妙的Python》带你漫游代码世界 前言 在现代Web开发中,Python因其简洁、易用以及丰富的库生态系统,成为了许多开发者的首选编程语言。Flask作为一个轻量级的Python Web框架,以其简洁和灵活性深受开…...

IDEA的lombok插件不生效了?!!
记录一下,防止找不到解决方案,已经遇到好几次了 前面啰嗦的多,可以直接跳到末尾的解决方法,点击一下 问题现场情况 排查过程 确认引入的依赖正常 —》🆗 idea 是否安装了lombok插件 --》🆗 貌似没有问题…...

CSP-S 2022 T1假期计划
CSP-S 2022 T1假期计划 先思考暴力做法,题目需要找到四个不相同的景点,那我们就枚举这四个景点,判断它们之间的距离是否符合条件,条件是任意两个点之间的距离是否大于 k k k,所以我们需要求出任意两点之间的距离。常用…...

为什么要学习大模型?AI在把传统软件当早餐吃掉?
前言 上周末在推特平台上有一篇写在谷歌文档里的短文,在国外的科技/投资圈得到了非常广泛的浏览,叫做 The End of Software(软件的终结), 作者 Chris Paik 是位于纽约市的风险投资基金 Pace Capital 的创始合伙人&…...

全流程Python编程、机器学习与深度学习实践技术应用
近年来,人工智能领域的飞速发展极大地改变了各个行业的面貌。当前最新的技术动态,如大型语言模型和深度学习技术的发展,展示了深度学习和机器学习技术的强大潜力,成为推动创新和提升竞争力的关键。特别是PyTorch,凭借其…...

pWnos1.0 靶机渗透 (Perl CGI 的反弹 shell 利用)
靶机介绍 来自 vulnhub 主机发现 ┌──(kali㉿kali)-[~/testPwnos1.0] …...
 函数绑定无效)
jquery on() 函数绑定无效
on 前面的元素必须在页面加载的时候就存在于 dom 里面。动态的元素或者样式等,可以放在 on 的第二个参数里面。jQuery on() 方法是官方推荐的绑定事件的一个方法。使用 on() 方法可以给将来动态创建的动态元素绑定指定的事件,例如 append 等。 <div …...

数字化转型与企业创新的双向驱动
数字化转型与企业创新的双向驱动 在全球化的竞争环境中,数字化转型已成为企业保持竞争力的重要手段。未来几年,随着信息技术的进一步发展,数字化转型将不仅限于IT部门,而是深入到企业的各个业务层面,推动创新和效率的…...
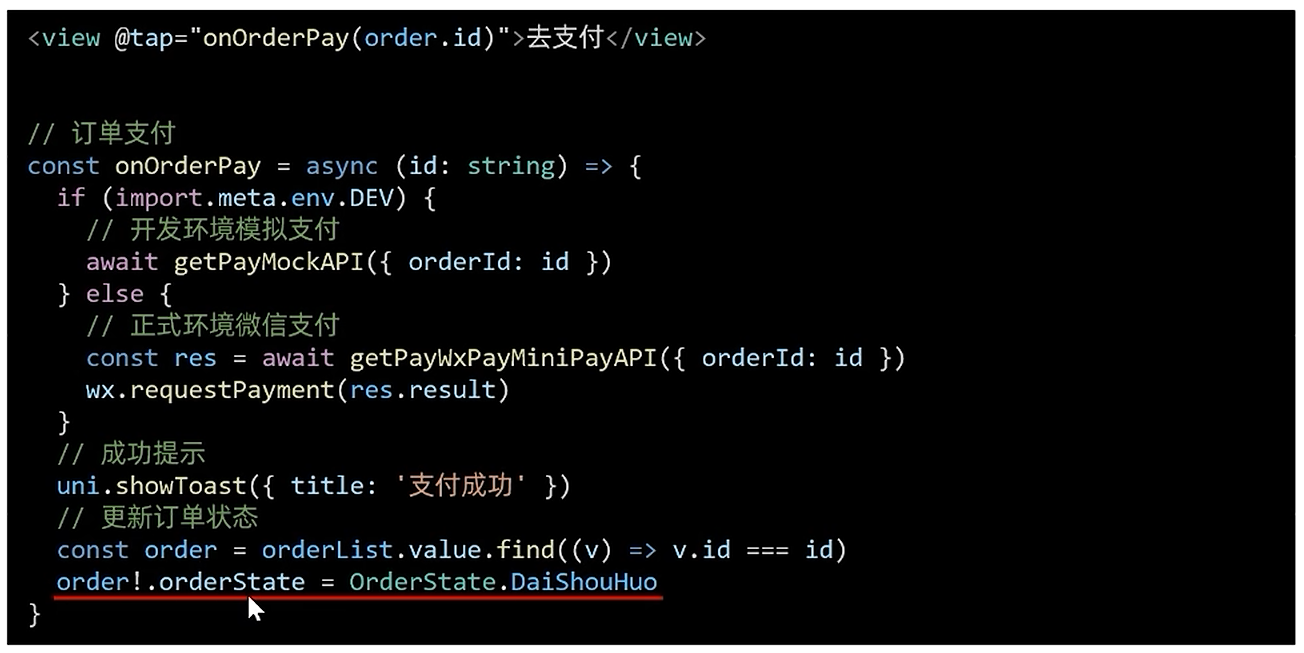
[uni-app]小兔鲜-07订单+支付
订单模块 基本信息渲染 import type { OrderState } from /services/constants import type { AddressItem } from ./address import type { PageParams } from /types/global/** 获取预付订单 返回信息 */ export type OrderPreResult {/** 商品集合 [ 商品信息 ] */goods: …...

Oracle数据库中表压缩的实现方式和特点
Oracle数据库中表压缩的实现方式和特点 在 Oracle 数据库中,表压缩是一项重要的功能,旨在优化存储空间和提高性能。Oracle 提供了多种表压缩技术,以适应不同的应用场景和需求。以下是 Oracle 数据库中表压缩的实现方式和特点: 1…...
)
论文解读:交大港大上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架(二)
HoST框架核心实现方法详解 - 论文深度解读(第二部分) 《Learning Humanoid Standing-up Control across Diverse Postures》 系列文章: 论文深度解读 + 算法与代码分析(二) 作者机构: 上海AI Lab, 上海交通大学, 香港大学, 浙江大学, 香港中文大学 论文主题: 人形机器人…...
)
Spring Boot 实现流式响应(兼容 2.7.x)
在实际开发中,我们可能会遇到一些流式数据处理的场景,比如接收来自上游接口的 Server-Sent Events(SSE) 或 流式 JSON 内容,并将其原样中转给前端页面或客户端。这种情况下,传统的 RestTemplate 缓存机制会…...

聊聊 Pulsar:Producer 源码解析
一、前言 Apache Pulsar 是一个企业级的开源分布式消息传递平台,以其高性能、可扩展性和存储计算分离架构在消息队列和流处理领域独树一帜。在 Pulsar 的核心架构中,Producer(生产者) 是连接客户端应用与消息队列的第一步。生产者…...

ESP32 I2S音频总线学习笔记(四): INMP441采集音频并实时播放
简介 前面两期文章我们介绍了I2S的读取和写入,一个是通过INMP441麦克风模块采集音频,一个是通过PCM5102A模块播放音频,那如果我们将两者结合起来,将麦克风采集到的音频通过PCM5102A播放,是不是就可以做一个扩音器了呢…...
指令的指南)
在Ubuntu中设置开机自动运行(sudo)指令的指南
在Ubuntu系统中,有时需要在系统启动时自动执行某些命令,特别是需要 sudo权限的指令。为了实现这一功能,可以使用多种方法,包括编写Systemd服务、配置 rc.local文件或使用 cron任务计划。本文将详细介绍这些方法,并提供…...

三体问题详解
从物理学角度,三体问题之所以不稳定,是因为三个天体在万有引力作用下相互作用,形成一个非线性耦合系统。我们可以从牛顿经典力学出发,列出具体的运动方程,并说明为何这个系统本质上是混沌的,无法得到一般解…...

Spring AI与Spring Modulith核心技术解析
Spring AI核心架构解析 Spring AI(https://spring.io/projects/spring-ai)作为Spring生态中的AI集成框架,其核心设计理念是通过模块化架构降低AI应用的开发复杂度。与Python生态中的LangChain/LlamaIndex等工具类似,但特别为多语…...

服务器--宝塔命令
一、宝塔面板安装命令 ⚠️ 必须使用 root 用户 或 sudo 权限执行! sudo su - 1. CentOS 系统: yum install -y wget && wget -O install.sh http://download.bt.cn/install/install_6.0.sh && sh install.sh2. Ubuntu / Debian 系统…...

Java + Spring Boot + Mybatis 实现批量插入
在 Java 中使用 Spring Boot 和 MyBatis 实现批量插入可以通过以下步骤完成。这里提供两种常用方法:使用 MyBatis 的 <foreach> 标签和批处理模式(ExecutorType.BATCH)。 方法一:使用 XML 的 <foreach> 标签ÿ…...

uniapp手机号一键登录保姆级教程(包含前端和后端)
目录 前置条件创建uniapp项目并关联uniClound云空间开启一键登录模块并开通一键登录服务编写云函数并上传部署获取手机号流程(第一种) 前端直接调用云函数获取手机号(第三种)后台调用云函数获取手机号 错误码常见问题 前置条件 手机安装有sim卡手机开启…...