【MySQL】多表查询——内连接,左/右连接
目录
准备工作
1.多表查询
2.INNER JOIN(内连接)
2.1.笛卡尔积
1.2.笛卡尔积的过滤
1.3.INNER JOIN(显式内连接)
1.4.SELF JOIN(自连接)
3. LEFT JOIN(左连接)
3.1.一个例子
4.RIGHT JOIN(右连接)
4.1.使用示例
在MySQL中,复合查询(有时也称为组合查询或多查询)通常涉及将多个查询组合在一起,以便执行更复杂的检索、过滤和操作。这些查询可以包括多个表之间的连接(JOIN)、子查询(SUBQUERY)、联合查询(UNION)等。
今天我们先讲解多表查询
准备工作
首先我们去这个网站下载一个.sql文件:阿里云盘分享 (alipan.com)


拿到该数据库文件以后,我们可以先打开该文件进行查看其内容:
vim scott_data.sql

我们会发现其里面都是SQL记录,对于MySQL我们备份其数据库时,其实备份的全部都是一条条有效的SQL记录,通过重新执行这些SQL,我们便能够得到和原来一摸一样数据库。
接下来我们就可以在mysql中将这个数据库给创建出来了:
source 该文件的绝对路径;
例如我这里是:
source /home/zs_113/scott_data.sql
然后我们查询我们的数据库,发现数据库中多了一个scott的数据库:
show databases;

我们进去看看
use scott;
show tables;
这三张表是
- EMP员工表
- DEPT部门表
- SALGRADE工资等级表
我们先分别查看一下表结构和表内容:
- EMP员工表
desc emp;
select * from emp;

- DEPT部门表
desc dept;select * from dept;
- SALGRADE工资等级表
desc salgrade;
select * from salgrade;
接下来我们的查询都会基于上面这一个数据库。
1.多表查询
你可以在 SELECT, UPDATE 和 DELETE 语句中使用 MySQL 的 JOIN 来联合多表查询。
JOIN 按照功能大致分为如下三类:
- INNER JOIN(内连接,或等值连接):获取两个表中字段匹配关系的记录。
- LEFT JOIN(左连接):获取左表所有记录,即使右表没有对应匹配的记录。
- RIGHT JOIN(右连接): 与 LEFT JOIN 相反,用于获取右表所有记录,即使左表没有对应匹配的记录。
2.INNER JOIN(内连接)
2.1.笛卡尔积
先来补充一下:
- 笛卡尔积
笛卡尔积是数学中集合运算的一种概念,也可以应用于数据库领域,特别是在关系型数据库中。以下是对笛卡尔积的详细解释:
一、定义
- 数学定义:笛卡尔积是指两个集合A和B之间的所有可能的有序对的集合。具体来说,如果A是一个集合,B也是一个集合,那么A和B的笛卡尔积A×B是一个新的集合,该集合中的元素是A中的元素和B中的元素的所有可能的有序对。
- 数据库定义:在数据库领域,尤其是关系型数据库中,当两个或多个表进行连接查询时,如果没有指定有效的连接条件或者连接条件错误,每个表中的每条记录都会与另一个表中的每条记录进行配对,形成大量的数据组合,这种现象被称为笛卡尔积。
二、特点
- 记录组合:笛卡尔积会生成两个或多个表中记录的所有可能组合。如果表A有m条记录,表B有n条记录,那么A和B的笛卡尔积将包含m×n条记录。
- 无序性:笛卡尔积中的记录是无序的,即不同记录之间的顺序并不影响笛卡尔积的结果。
- 冗余性:笛卡尔积可能会生成大量无用的数据组合,增加数据的冗余性。特别是在多表查询时,如果没有有效的连接条件,笛卡尔积会导致结果集急剧膨胀。
三、生成方式
- 隐式生成:在MySQL中,如果执行了多表查询而没有明确指定连接条件(ON子句),或者连接条件写错,无法正确匹配表中的记录,那么就会产生笛卡尔积。
- 显式生成:使用CROSS JOIN明确指示数据库进行笛卡尔积操作也会直接生成笛卡尔积。例如,SELECT s.name, c.class_name FROM students s CROSS JOIN classes c; 这个查询语句会生成students表和classes表的笛卡尔积。
四、应用场景与注意事项
- 应用场景:笛卡尔积在某些特定场景下可能是有用的,比如需要生成所有可能的组合时。但在大多数情况下,笛卡尔积并不是预期的查询结果,因此需要避免其产生。
- 注意事项:在进行多表查询时,应确保指定了有效的连接条件,以避免生成笛卡尔积。
- 如果确实需要生成笛卡尔积,应明确使用CROSS JOIN,并清楚其可能带来的性能问题和数据冗余性。
多表查询的语法:
- 将多张表的表名依次放到from子句之后,用逗号隔开即可,这时MySQL将会对给定的这多张表取笛卡尔积,作为多表查询的初始数据源。
- 所谓的对多张表取笛卡尔积,就是得到这多张表的记录的所有可能性全部组合出来。
....from table_1, table_2, table_4 ....
例如我们对下面这两张小表做笛卡尔积:

select * from dept, salgrade;

可以看出:对部门表和薪资等级表取笛卡尔积时,会先从薪资等级表中选出一条记录与部门表中的所有记录进行组合,然后再从薪资等级表中选出一条记录与部门表中的所有记录进行组合,以此类推,最终得到的就是这两张表的笛卡尔积。
1.2.笛卡尔积的过滤
需要注意的是,对多张表取笛卡尔积后得到的数据并不都是有意义的。
我们举个例子
select * from emp;
select * from dept; 
比如对员工表和部门表取笛卡尔积时,员工表中的每一个员工信息都会和部门表中的每一个部门信息进行组合,而实际一个员工只有和自己所在的部门信息进行组合才是有意义的。
select * from emp,dept;
很多数据都是没有用的,我们可以对此进行过滤。所以我们可以在where子句中指明:emp.deptno = dept.deptno,即从笛卡尔积中筛选出员工的部门号和部门的编号相等记录。
select * from emp,dept where emp.deptno = dept.deptno;
可以看到,这种一个员工只和自己所在的部门信息进行组合的表格才是正真有意义的表格。
说明: 进行笛卡尔积的多张表中可能会存在相同的列名,这时在选中列名时需要通过表名.列名的方式进行指明
1.3.INNER JOIN(显式内连接)
事实上,上面的select * from emp,dept where emp.deptno = dept.deptno;其实是INNER JOIN的隐式写法,尽管隐式内连接在语法上是正确的,并且许多数据库系统(包括 MySQL)都支持它,但显式内连接(使用 INNER JOIN)通常被认为是更好的做法,因为它更易于阅读和维护,特别是当查询变得复杂时。此外,显式连接语法也是 SQL 标准的一部分,因此在不同数据库系统之间的可移植性更好。
接下来我们来学习一下显示内连接
INNER JOIN 返回两个表中满足连接条件的匹配行,以下是 INNER JOIN 语句的基本语法:
SELECT column1, column2, ...FROM table1INNER JOIN table2 ON table1.column_name = table2.column_name;参数说明:
- column1, column2, ... 是你要选择的列的名称,如果使用 * 表示选择所有列。
- table1, table2 是要连接的两个表的名称。
- table1.column_name = table2.column_name 是连接条件,指定了两个表中用于匹配的列。
我们可以将上面那个隐式内连接
select * from emp,dept where emp.deptno = dept.deptno;改成显式内连接
select * from emp inner join dept on emp.deptno = dept.deptno;这条语句使用了 INNER JOIN 关键字来明确指示进行内连接操作,并通过 ON 子句指定了连接条件 emp.deptno = dept.deptno。这是 SQL 中推荐的做法,因为它使得查询的意图更加清晰,也更易于理解和维护。
与隐式内连接相比,显式内连接具有以下优点:
- 可读性更高:显式内连接的语法结构更加清晰,能够一眼看出是在进行表连接操作。
- 可维护性更强:当查询变得复杂,涉及多个表连接时,显式内连接更容易进行修改和扩展。
- 符合 SQL 标准:显式内连接是 SQL 标准的一部分,因此具有更好的跨数据库系统兼容性。
- 避免潜在错误:隐式内连接有时可能会因为缺少连接条件而意外地产生笛卡尔积,而显式内连接则通过 ON 子句明确要求连接条件,从而避免了这种错误。
因此,在实际开发中,建议优先使用显式内连接来替代隐式内连接。

可以看到结果和上面的一模一样。
注意:以后再遇到类似的情况,请用显式内连接写法!
下面我们来进行一些练习:
1. 显示部门号为10的部门名,员工名
- 员工名(ename)和工资(sal)这两个字段在emp表中,而部门名称在dept表中,所以我们要使用多表查询from emp, dept。
- 为了让两张表的笛卡儿积的结果是有效的,我们可以在where条件中使用emp.deptno = dept.deptno
- 由于我们只要部门号为10的部门,所以我们可以使用where条件进行筛选dept.deptno = 10,当然由于emp中也有deptno字段,所以我们也可以使用emp.deptno = 10。
隐式内连接的写法如下:
select ename, dept.deptno, dname from emp, dept where (emp.deptno=dept.deptno) and (dept.deptno = 10);

显式内连接的写法如下
select ename, dept.deptno, dname from emp inner join dept on (emp.deptno=dept.deptno) and (dept.deptno = 10);
2 显示各个员工的姓名,工资,及工资级别
- 员工名(ename)和工资(sal)这两个字段在emp表中,而工资级别在salgrade表中,所以我们要使用多表查询from emp, salgrade。
- 为了让两张表的笛卡儿积的结果是有效的,以及正确的显示工资级别,我们要在where子句中添加限制条件: sal between losal and hisal
隐式内连接写法
select ename, sal, grade , losal, hisal from emp, salgrade where sal between losal and hisal;

显式内连接写法
select ename, sal, grade , losal, hisal from emp inner join salgrade on sal between losal and hisal;

1.4.SELF JOIN(自连接)
刚才我们使用多表查询是:两张不同的表进行组合,那么对于同一张表能不能进行组合呢?
答案是可以的:对同一张表连接查询我们称之为自连接
自连接与内连接的关系
- 特殊性:自连接是一种特殊的内连接,因为自连接本质上是在一个表内进行的,而内连接通常涉及两个不同的表。但是,通过为表取别名,自连接在逻辑上将一个表视为两个表,从而可以使用内连接的语法和逻辑。
- 相同点:自连接和内连接都使用JOIN子句(尽管自连接可能不显式地使用JOIN关键字,而是通过逗号分隔和WHERE子句来实现),并指定连接条件来过滤结果集。
- 不同点:自连接只涉及一个物理表,而内连接涉及两个或更多不同的物理表。此外,自连接通常用于比较同一表中的不同行,而内连接用于从多个表中获取相关联的数据。
在MySQL中,自连接查询是指在同一张表中进行连接操作。通常情况下,我们通过表与表之间的关系来进行连接操作,但有时候我们需要在同一张表中进行数据的连接和比较,这就需要使用到自连接查询。
自连接的语法如下:
SELECT 列名 FROM 表名 表别名1, 表名 表别名2 WHERE 表别名1.列名 = 表别名2.列名; - SELECT 列名:这里您应该指定要从连接结果中选择的列。如果两个表中有同名的列,您需要使用表别名来区分它们,例如表别名1.列名或表别名2.列名。如果您只选择了一个列名而没有指定别名,那么SQL引擎通常会从它找到的第一个匹配的列中返回数据(这取决于查询优化器和具体的SQL实现)。但是,为了避免混淆和错误,最好总是使用表别名来明确指定要选择的列。
- FROM 表名 表别名1, 表名 表别名2:这里您指定了要从哪个表中选择数据,并且为同一个表指定了两个不同的别名(表别名1和表别名2),以便在查询中区分它们。这是自连接的关键部分。
- WHERE 表别名1.列名 = 表别名2.列名:这是连接条件,它指定了如何连接两个表的实例。在这个例子中,您正在查找表别名1中某个列的值与表别名2中相同列的值相等的记录。
为了使查询更清晰和标准化,您可以使用现代的JOIN子句风格来重写它,如下所示:
SELECT 表别名1.列名 AS 别名1列名, 表别名2.列名 AS 别名2列名 FROM 表名 表别名1 INNER JOIN 表名 表别名2 ON 表别名1.列名 = 表别名2.列名; 在这个重写后的查询中:
- 我使用了INNER JOIN来明确指定这是一个内连接。
- 我使用了ON子句来指定连接条件。
- 我为选择的每个列都指定了一个别名(别名1列名和别名2列名),以避免混淆(特别是当两个表中有同名的列时)。
请注意,如果您只选择一个列名而不指定别名,并且两个表都有该列名,那么您可能会得到一个错误,或者SQL引擎可能会默认选择其中一个表的列(这取决于具体的SQL实现和查询优化器的行为)。因此,最好总是使用表别名来明确指定要选择的列,并为它们提供清晰的别名。
语法:
我们直接像多表查询那样在from后面写上两次表名是不行的!因为两张表同名的话,我们后面对列进行各种操作时有歧义。
select * from dept,dept;

所以我们需要对表进行重命名,以保证我们后面对列进行各种操作时没有歧义!
select * from dept as t1, dept as t2;

下面我们来看一个例子帮我们更好的理解自连接:
1.显示员工FORD的上级领导的编号和姓名(mgr是员工领导的编号,empno是雇员编号)
- 首先理解题意:员工的上级领导也是员工,也有自己的员工编号。
此外员工表中的mgr字段能够将表中员工的信息和员工领导的信息关联起来

上图说明FORD和FORD的领导都在emp表里,我们要根据员工的mgr字段和其他人的empno进行比对得到FORO的领导是谁
- 方法一:使用多条SQL
首先我们可以先拿到员工FORD其领导的编号
select mgr from emp where ename = 'FORD';

- 然后根据这个编号进行查找其上级领导
select * from emp where empno=7566;

- 方法二:使用自连接
我们发现两次查找都是在emp表中进行查找,所以我们可以对emp表进行自连接,然后对自连接的结果按照 :
e1表的雇员名称必须是FORD而且员工的领导编号等于领导的员工编号即:(e1.ename='FORD') and (e1.mgr=e2.empno)的方式进行过滤。
select e2.ename,e2.empno
from emp as e1, emp as e2
where (e1.ename='FORD') and (e1.mgr=e2.empno);
怎么理解这个语句呢?
这里我们可以把e1和e2看作两张表,然后我们知道select * from emp as e1,emp as e2会形成笛卡尔积

然后我们通过限定条件e1.ename='FORD'来缩小到那14行。
select *
from emp as e1, emp as e2
where (e1.ename='FORD');
然后我们再通过限定条件 e1.mgr=e2.empno筛选出符合的那一行。其中e1是表的左边那半,e2是右边那半。
select *
from emp as e1, emp as e2
where (e1.ename='FORD') and (e1.mgr=e2.empno); 最后我们再筛选出那两列
最后我们再筛选出那两列
select e2.ename,e2.empno
from emp as e1, emp as e2
where (e1.ename='FORD') and (e1.mgr=e2.empno); 
这个查询将返回所有直接汇报给名为'FORD'的员工的下属的姓名和员工编号。
3. LEFT JOIN(左连接)
LEFT JOIN 返回左表的所有行,并包括右表中匹配的行,如果右表中没有匹配的行,将返回 NULL 值,以下是 LEFT JOIN 语句的基本语法:
SELECT column1, column2, ...
FROM table1
LEFT JOIN table2 ON table1.column_name = table2.column_name;这段SQL代码的功能是从两个表(table1 和 table2)中查询数据。
具体来说,它执行了一个左连接(LEFT JOIN)操作,这意味着查询结果将包含左表(table1)中的所有记录,即使这些记录在右表(table2)中没有匹配的记录。如果在右表中有匹配的记录,则这些匹配的记录信息也会被包含在结果中。如果没有匹配的记录,则结果中对应的右表(table2)的列将包含NULL值。
详细解释如下:
- SELECT column1, column2, ...:这部分指定了查询结果中需要包含的列。这里的column1, column2, ...应该替换为实际需要查询的列名,可以来自table1或table2,或者是通过计算得到的列(比如使用函数或表达式)。
- FROM table1:这指定了查询的主表,即左表。所有在table1中的记录都会出现在结果集中,即使它们在table2中没有匹配的记录。
- LEFT JOIN table2 ON table1.column_name = table2.column_name:这部分执行了一个左连接操作,将table1和table2连接起来。ON子句指定了连接条件,即两个表中哪些列的值需要相等才能认为记录是匹配的。这里的table1.column_name = table2.column_name应该替换为实际的列名,这些列名在两个表中都存在,并且用于确定哪些记录是相关的。
左连接的一个常见用途是确保结果集中包含左表的所有记录,同时尽可能地从右表中获取相关的匹配记录。如果右表中没有匹配的记录,结果集中的相应列将显示为NULL。
这种查询在处理需要保留主表所有记录的场景中非常有用,比如,在一个订单系统中,你想列出所有的订单,即使某些订单没有关联的客户信息(比如新客户还未被添加到客户表中)。
3.1.一个例子
给出一张学生表,学生表中的name代表的是学生的姓名,id代表的是学生的学号。如下:
create table stu(
id int,
name varchar(10)
);
insert into stu values (1,'jack'),(2,'tom'),(3,'kity'),(4,'nono');
select * from stu;

再给出一张成绩表,其中的id代表的是考试学生的学号,grade代表的是学生的成绩。如下:
create table exam(
id int,
grade int
);
insert into exam values (1,56),(2,76),(11,80);
select * from exam;
注意观察这两张表:
- 学生表中的3,4号学生在成绩表中是没有成绩的(可能是缺考了)
- 成绩表中的11号学生,在学生表中是不存在的,(可能学生表统计漏了)
现在我们如果使用内连接进行连接,显示学号很姓名的,我们发现有一些信息会因为不存在,而被筛选掉。
select * from stu inner join exam on stu.id=exam.id;

3号同学不见了。这样子可不行啊。
我们查询所有学生的成绩,如果这个学生没有成绩,也要将学生的个人信息显示出来
可以看出题目要求学生表的信息要被完全展示,而成绩表中的信息如果实在不满足连接条件可以被忽略。
所以我们可以使用左外连接保证左边的表要被完全显示:
select * from stu left join exam on stu.id=exam.id;

观察表格:
- 学生表中的信息被完全被展示出来了!就算在成绩表中找不到id与之匹配。同时因为找不到所以其对应的列全部以NULL进行填充
- 而成绩表中的11号id,因为无法匹配而被筛选掉了。
4.RIGHT JOIN(右连接)
RIGHT JOIN 返回右表的所有行,并包括左表中匹配的行,如果左表中没有匹配的行,将返回 NULL 值,以下是 RIGHT JOIN 语句的基本语法:
SELECT column1, column2, ...
FROM table1
RIGHT JOIN table2 ON table1.column_name = table2.column_name;右连接意味着查询结果将包含右表(table2)中的所有记录,以及左表(table1)中与之匹配的记录。如果左表中没有匹配的记录,则结果中对应的左表(table1)的列将包含NULL值。
详细解释如下:
- SELECT column1, column2, ...:这部分指定了查询结果中需要包含的列。这里的column1, column2, ...应该替换为实际需要查询的列名,这些列名可以来自table1或table2,或者是通过计算得到的列(比如使用函数或表达式)。
- FROM table1:这指定了查询中涉及的一个表,即左表。尽管在RIGHT JOIN中,左表不是结果集的主要来源(主要来源是右表),但它仍然是查询的一部分。
- RIGHT JOIN table2 ON table1.column_name = table2.column_name:这部分执行了一个右连接操作,将table1和table2连接起来。ON子句指定了连接条件,即两个表中哪些列的值需要相等才能认为记录是匹配的。这里的table1.column_name = table2.column_name应该替换为实际的列名,这些列名在两个表中都存在,并且用于确定哪些记录是相关的。
右连接的一个常见用途是确保结果集中包含右表的所有记录,同时尽可能地从左表中获取相关的匹配记录。如果左表中没有匹配的记录,结果集中的相应列将显示为NULL。
然而,需要注意的是,在实际应用中,RIGHT JOIN的使用相对较少,因为大多数情况下,可以通过调整查询的表顺序和使用LEFT JOIN来达到相同的目的。例如,如果你有一个RIGHT JOIN查询,你可以通过交换两个表的顺序(即将table1和table2的位置互换),并使用LEFT JOIN来达到相同的结果。
总的来说,无论是LEFT JOIN还是RIGHT JOIN,它们都是用于合并两个表的数据,并根据指定的连接条件来选择哪些记录应该出现在结果集中。选择使用哪种连接类型取决于你想要保留哪个表的所有记录,并尽可能地从另一个表中获取匹配的记录。
4.1.使用示例
我们继续沿用左连接的那个表
查询所有的成绩,就算这个成绩没有学生与它对应,也要将成绩信息显示出来
可以看出题目要求成绩表的信息要被完全展示,而学生表中的信息如果实在不满足连接条件可以被忽略。
所以我们可以使用右连接保证右边的表要被完全显示,(当然也可以调换表的顺序然后使用左外连接):
select * from stu right join exam on stu.id=exam.id;

观察表格:
- 成绩表中的信息被完全被展示出来了!就算在学生表中找不到id与之匹配。同时因为找不到所以其对应的列全部以NULL进行填充
- 而学生表中的3,4号id,因为无法匹配而被筛选掉了。
相关文章:
【MySQL】多表查询——内连接,左/右连接
目录 准备工作 1.多表查询 2.INNER JOIN(内连接) 2.1.笛卡尔积 1.2.笛卡尔积的过滤 1.3.INNER JOIN(显式内连接) 1.4.SELF JOIN(自连接) 3. LEFT JOIN(左连接) 3.1.一个例子…...

Naicat连接本地CentOS 7虚拟机上的MySQL数据库失败解决办法
注意:Navicat主机栏填的是Centos虚拟机的IP地址 一、检查mysql容器 确保网络正常、保证mysql容器处于运行中且用户名、密码和端口正确。 1、查看mysql容器是否运行 docker ps2、查看mysql容器详细信息,可查看端口 docker inspect mysql二、检查防火墙…...
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)的计算过程
cifar10数据集的众多demo中,在数据加载环节,transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)这条指令是经常看到的。这是一个 PyTorch 中用于图像数据标准化的函数调用,它将图像的每个通道的值进行标准化处理&…...
Excel表格如何修改“打开密码”,简单几步,轻松搞定
在保护Excel文件的安全性时,设置打开密码是常见且有效的方式。然而,有时我们需要修改已经设置的打开密码,以确保文件安全性或更新密码信息。今天小编来分享一下修改Excel文件打开密码的方法,操作简单,一起来看看吧&…...

pandas 数据分析实战
一、pandas常用数据类型 series,带标签的一维数组。类似于字典,但是键作为索引。 datatimeindex,时间序列。 dataframe,带标签且大小可变的二维表格结构。 panel,带标签且大小可变的三维数组。 1.一维数组与操…...

antd vue 输入框高亮设置关键字
<highlight-textareaplaceholder"请输入主诉"type"textarea"v-model"formModel.mainSuit":highlightKey"schema.componentProps.highlightKey"></highlight-textarea> 参考链接原生input,textarea demo地址 …...

python——扑克牌案列
斗地主发牌程序: 模拟一个斗地主发牌程序,实现对三个玩家进行手牌的派发,实现功能: ********** 欢迎进入 XX 斗地主 ********** 请输入玩家姓名:<用户控制台输入 A> 请输入玩家姓名:<用户控制台输…...

Java最全面试题->Java基础面试题->JavaWeb面试题->Git/SVN面试题
文章目录 Git/SVN面试题Git和SVN有什么区别?SVN优缺点?Git优缺点?说一下Git创建分支的步骤?说一下Git合并的两种方法以及区别?Git如何查看文件的提交历史和分支的提交历史?什么是 git stash?什么是git sta…...

引进Menu菜单与新增验证上传图片功能--系统篇
我的迭代小系统要更新2点。一是后台需要引进一种导航,众多导航之中我选择了Menu菜单。二是上传图片接口需要新增验证上传图片环节。先看看更新2点后的效果 引进Menu菜单效果如下,这部分修改后台前端代码 引进Menu菜单后,Menu菜单的默认数据我…...

安装Python及pip使用方法详解
一、安装Python Python是一种广泛使用的高级编程语言,其安装过程相对简单。以下是具体步骤: 访问Python官网: 打开浏览器,访问Python的官方网站[python.org](https://www.python.org/),确保下载的是最新版本的Python安…...

利用Arcgis进行沟道形态分析
在做项目的时候需要学习到水文分析和沟道形态分析的学习,所以自己摸索着做了下面的工作和内容。如有不对请多指正!! 一、沟道形态分析概述 沟道形态分析是水文分析的一个重要方面,用于研究河流的形态和特征。沟道形态分析可以帮助…...

Excel:vba实现筛选出有批注的单元格
实现的效果:代码: Sub test() Dim cell As RangeRange("F3:I10000").ClearlastRow Cells(Rows.Count, "f").End(xlUp).Row MsgBox lastrow For Each cell In Range("a1:a21")If Not cell.Comment Is Nothing ThenMsgBox…...

RabbitMQ 发布确认模式
RabbitMQ 发布确认模式 一、原理 RabbitMQ 的发布确认模式(Publisher Confirms)是一种机制,用于确保消息在被 RabbitMQ 服务器成功接收后,发布者能够获得确认。这一机制在高可用性和可靠性场景下尤为重要,能够有效防止…...

【面试题】什么是SpringBoot以及SpringBoot的优缺点
什么是SpringBoot以及SpringBoot的优缺点 什么是SpringBoot SpringBoot是基于Spring的一个微框架,其设计目的是用来简化新Spring应用的初始搭建以及开发过程。 SpringBoot的优点 可以创建独立的Spring应用程序,并且基于其Maven或Gradle插件,可以创建可执…...

git区分大小写吗?如果不区分,那要如何设置?
git区分大小写吗?如果不区分,那要如何设置? "Git在文件名的大小写方面是区分大小写的,但在某些操作系统(如Windows和macOS)上,文件系统默认是不区分大小写的。这可能导致一些问题…...

Docker 安装使用
1. 下载 下载地址:Index of linux/static/stable/x86_64/ 下载好后,将文件docker-18.06.3-ce.tgz用WinSCP等工具,上传到不能外网的linux系统服务器 2. 安装 解压后的文件夹docker中文件如下所示: 将docker中的全部文件ÿ…...

Linux Docker配置镜像加速
Docker配置常用镜像加速地址包含阿里、腾讯、百度、网易 1. 编辑docke配置文件 vim /etc/docker/daemon.json写入以下内容 {"registry-mirrors": ["https://docker.mirrors.aliyuncs.com","https://registry.docker-cn.com","https://mi…...

了解CSS Typed OM
CSS Typed OM(CSS Typed Object Model)是一项前沿的技术,旨在改变我们编写和操作CSS的方式。以下是对CSS Typed OM的详细解析: 一、CSS Typed OM概述 CSS Typed OM是一个包含类型和方法的CSS对象模型,它暴露了作为Ja…...

[ 钓鱼实战系列-基础篇-6 ] 一篇文章让你了解邮件服务器机制(SMTP/POP/IMAP)-2
🍬 博主介绍 👨🎓 博主介绍:大家好,我是 _PowerShell ,很高兴认识大家~ ✨主攻领域:【渗透领域】【数据通信】 【通讯安全】 【web安全】【面试分析】 🎉点赞➕评论➕收藏 养成习…...

在 Docker 中搭建 PostgreSQL16 主从同步环境
1. 环境搭建 本文介绍了如何在同一台机器上使用 Docker 容器搭建 PostgreSQL 的主从同步环境。通过创建互联网络和配置主库及从库,详细讲解了数据库初始化、角色创建、数据同步和验证步骤。主要步骤包括设置主库的连接信息、创建用于复制的角色、使用 pg_basebacku…...

在软件开发中正确使用MySQL日期时间类型的深度解析
在日常软件开发场景中,时间信息的存储是底层且核心的需求。从金融交易的精确记账时间、用户操作的行为日志,到供应链系统的物流节点时间戳,时间数据的准确性直接决定业务逻辑的可靠性。MySQL作为主流关系型数据库,其日期时间类型的…...

19c补丁后oracle属主变化,导致不能识别磁盘组
补丁后服务器重启,数据库再次无法启动 ORA01017: invalid username/password; logon denied Oracle 19c 在打上 19.23 或以上补丁版本后,存在与用户组权限相关的问题。具体表现为,Oracle 实例的运行用户(oracle)和集…...

连锁超市冷库节能解决方案:如何实现超市降本增效
在连锁超市冷库运营中,高能耗、设备损耗快、人工管理低效等问题长期困扰企业。御控冷库节能解决方案通过智能控制化霜、按需化霜、实时监控、故障诊断、自动预警、远程控制开关六大核心技术,实现年省电费15%-60%,且不改动原有装备、安装快捷、…...

【Java_EE】Spring MVC
目录 Spring Web MVC 编辑注解 RestController RequestMapping RequestParam RequestParam RequestBody PathVariable RequestPart 参数传递 注意事项 编辑参数重命名 RequestParam 编辑编辑传递集合 RequestParam 传递JSON数据 编辑RequestBody …...

LeetCode - 199. 二叉树的右视图
题目 199. 二叉树的右视图 - 力扣(LeetCode) 思路 右视图是指从树的右侧看,对于每一层,只能看到该层最右边的节点。实现思路是: 使用深度优先搜索(DFS)按照"根-右-左"的顺序遍历树记录每个节点的深度对于…...

深入浅出深度学习基础:从感知机到全连接神经网络的核心原理与应用
文章目录 前言一、感知机 (Perceptron)1.1 基础介绍1.1.1 感知机是什么?1.1.2 感知机的工作原理 1.2 感知机的简单应用:基本逻辑门1.2.1 逻辑与 (Logic AND)1.2.2 逻辑或 (Logic OR)1.2.3 逻辑与非 (Logic NAND) 1.3 感知机的实现1.3.1 简单实现 (基于阈…...

【免费数据】2005-2019年我国272个地级市的旅游竞争力多指标数据(33个指标)
旅游业是一个城市的重要产业构成。旅游竞争力是一个城市竞争力的重要构成部分。一个城市的旅游竞争力反映了其在旅游市场竞争中的比较优势。 今日我们分享的是2005-2019年我国272个地级市的旅游竞争力多指标数据!该数据集源自2025年4月发表于《地理学报》的论文成果…...

GeoServer发布PostgreSQL图层后WFS查询无主键字段
在使用 GeoServer(版本 2.22.2) 发布 PostgreSQL(PostGIS)中的表为地图服务时,常常会遇到一个小问题: WFS 查询中,主键字段(如 id)莫名其妙地消失了! 即使你在…...

spring boot使用HttpServletResponse实现sse后端流式输出消息
1.以前只是看过SSE的相关文章,没有具体实践,这次接入AI大模型使用到了流式输出,涉及到给前端流式返回,所以记录一下。 2.resp要设置为text/event-stream resp.setContentType("text/event-stream"); resp.setCharacter…...
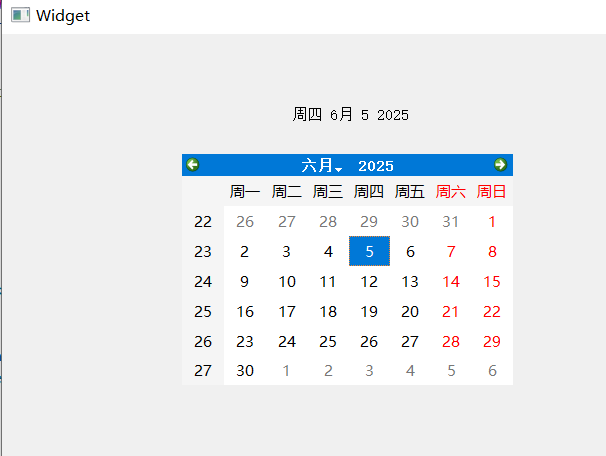
【QT控件】显示类控件
目录 一、Label 二、LCD Number 三、ProgressBar 四、Calendar Widget QT专栏:QT_uyeonashi的博客-CSDN博客 一、Label QLabel 可以用来显示文本和图片. 核心属性如下 代码示例: 显示不同格式的文本 1) 在界面上创建三个 QLabel 尺寸放大一些. objectName 分别…...