Python 代码实现对《红楼梦》文本的词频统计和数据可视化
Python 代码主要实现了对《红楼梦》文本的词频统计和数据可视化
完整详细下载地址:https://download.csdn.net/download/huanghm88/89879439
```python
""" 实训4 基于词频的篇章语义相似度与红楼梦内容分析 步骤3 针对红楼梦词频的数据可视化 """
# 引入 collections 包, json 包, codecs 包, jieba 包
import collections, json, codecs, jieba
# 引入tqdm循环可视化工具
from tqdm import tqdm
# 引入词云图绘制的 WordCloud 模块
from wordcloud import WordCloud
# 引入 matplotlib 的绘图模块,记作 plt
import matplotlib.pyplot as plt# 步骤1 中实现的函数
# 定义一个函数,输入一个 文件路径 input_path, 以utf-8格式,读入并解析json文件。
def json_load (input_path) :return json.load(codecs.open(input_path, 'r', 'utf-8'))# 实训2步骤3 中实现的函数
# 定义函数,输入为一个中文字串组成的list。利用jieba分词,对中文字串进行切分,并统计词频。
def word_count(document_words) :to_ret = collections.Counter()for word in document_words :word_cut = list(jieba.cut(word))word_cut_counter = collections.Counter(word_cut)to_ret = to_ret + word_cut_counterreturn to_ret# 实训2步骤4 中实现的函数
# 定义函数,输入为一个collections.Counter格式的词频统计, word_count ,和一个路径, outut_path 。
# 基于 word_count 绘制词云图,并储存在地址 outut_path 中
def word_cloud(word_count, outut_path) :for word in word_count :if word_count[word] == 1 :word_count[word] = 0if len(word) == 1 :word_count[word] = 0wc = WordCloud(width=2000, # 绘图的宽度height=1200, # 绘图的高度font_path='msyh.ttf', # 中文字体的路径colormap='spring' # 颜色风格,可以不设置) wc.generate_from_frequencies(word_count)wc.to_file(outut_path)# 利用 json_load 函数,读入红楼梦的json文件
# 辅导老师也可以准备其它文本用于处理
# 我们这里只对红楼梦前80回做处理
data = json_load('红楼梦.json')[:80]# 步骤1 中实现的内容
# 使用 word_count 函数,得到红楼梦每章的字数统计,存入word_counts。
# 同时使用tqdm循环可视化工具,可视化处理过程
word_counts = []
for chapter in tqdm(data) :count_t = word_count(chapter['content'])word_counts.append(count_t)# 使用实训2步骤4的内容,绘制两章的词云图
# word_cloud(word_counts[5], '红楼梦第6章.png')
# word_cloud(word_counts[15], '红楼梦第16章.png')# 分别得到宝玉、贾母、刘姥姥四个词汇在各个章节的词频统计数据。
baoyu_count = []
jiamu_count = []
liulaolao_count = []
for wc in word_counts :baoyu_count.append(wc['宝玉'])jiamu_count.append(wc['贾母'])liulaolao_count.append(wc['刘姥姥'])
# 如果好奇的话,这里可以打印词频统计结果
# print(baoyu_count)
# print(jiamu_count)
# print(liulaolao_count)# 第一部分:
# 使用plt工具画柱状图
def draw_bar_single(input_data, output_path) :# 每个柱子的位置position = list(range(1, len(input_data)+1))plt.bar(x = position, # 每个柱子的位置height = input_data # 每个柱子的高度)# 保存路径plt.savefig(output_path)# 清空缓存,可以背下来plt.clf()# 可以看到,宝玉通篇在提,刘姥姥只有来的几次被提。
draw_bar_single(liulaolao_count, '刘姥姥_bar.png')
draw_bar_single(baoyu_count, '宝玉_bar.png')# 第二部分:
# 使用plt工具画多重柱状图,这里是绘制宝玉和贾母的词频
# 每个柱子的位置
position_1 = [t-0.2 for t in range(1, len(baoyu_count)+1)]
position_2 = [t+0.2 for t in range(1, len(jiamu_count)+1)]plt.bar(x = position_1, height = baoyu_count,width = 0.4, # 柱子的宽度label = 'baoyu' # 标签
)
plt.bar(x = position_2, height = jiamu_count,width = 0.4, # 柱子的宽度label = 'jiamu' # 标签
)
# 绘制图例
plt.legend()
# 保存路径
plt.savefig('multi_bar.png')
# 清空缓存
plt.clf()# width = 0.2
# plt.bar(x = [1-width, 2-width, 3-width, 4-width], height = [4, 3, 2, 1], width = width*2, label = 'sampleA')
# plt.bar(x = [1+width, 2+width, 3+width, 4+width], height = [1, 2, 3, 4], width = width*2, label = 'sampleB')
# #
# plt.show()# 第三部分:
# 使用plt工具画折线图,这里是绘制宝玉和贾母的词频
# 折现数据点的位置position = list(range(1, len(baoyu_count)+1))plt.plot(position, # 数据点的位置baoyu_count, # 词频统计数据label="baoyu", # 标签color="blue", # 颜色marker=".", # 点的形状linestyle="-" # 线的形状)
plt.plot(position, # 数据点的位置jiamu_count, # 词频统计数据label="jiamu", # 标签color="green", # 颜色marker=".", # 点的形状linestyle="--" # 线的形状)# 横纵坐标标签
plt.xlabel("chapter")
plt.ylabel("word count")
# 绘制图例
plt.legend()
# 保存路径
plt.savefig('lines.png')
以下是对这段代码的分析:**一、整体功能概述**这段 Python 代码主要实现了对《红楼梦》文本的词频统计和数据可视化。具体功能包括:1. 读取《红楼梦》的 JSON 文件,并对前 80 回的内容进行处理。
2. 使用 jieba 分词对每章的内容进行切分,并统计词频。
3. 绘制特定章节的词云图,展示章节中的高频词汇。
4. 统计特定人物(宝玉、贾母、刘姥姥)在各章节中的词频。
5. 分别绘制人物词频的柱状图、多重柱状图和折线图进行可视化展示。**二、主要函数分析**1. `json_load(input_path)`:- 功能:以 UTF-8 格式读入并解析 JSON 文件。- 参数:`input_path`是 JSON 文件的路径。- 返回值:解析后的 JSON 数据。2. `word_count(document_words)`:- 功能:对输入的中文字串列表进行 jieba 分词,并统计词频。- 参数:`document_words`是一个由中文字串组成的列表。- 返回值:一个`collections.Counter`对象,包含了分词后的词频统计结果。3. `word_cloud(word_count, output_path)`:- 功能:根据输入的词频统计结果绘制词云图,并保存到指定路径。- 参数:`word_count`是一个`collections.Counter`格式的词频统计结果,`output_path`是保存词云图的路径。4. `draw_bar_single(input_data, output_path)`:- 功能:绘制单个的柱状图。- 参数:`input_data`是要绘制的柱子高度数据,`output_path`是保存柱状图的路径。**三、代码执行过程**1. 首先,使用`json_load`函数读入《红楼梦》的 JSON 文件,并只取前 80 回的数据。2. 然后,使用`tqdm`循环可视化工具,对每一章的内容进行词频统计,将结果存入`word_counts`列表中。3. 接着,分别统计宝玉、贾母、刘姥姥在各章节中的词频,并可以打印出来查看。4. 之后,分别绘制刘姥姥和宝玉的词频柱状图,以及宝玉和贾母的词频多重柱状图和折线图进行可视化展示。**四、应用场景**1. 文本分析:通过对文学作品进行词频统计和可视化,可以了解作品中不同词汇的出现频率和分布情况,从而深入分析作品的主题、人物等方面。2. 数据可视化教学:这段代码可以作为数据可视化的教学示例,展示如何使用 Python 的相关库进行词云图、柱状图和折线图的绘制。3. 完整详细下载地址:https://download.csdn.net/download/huanghm88/89879439相关文章:

Python 代码实现对《红楼梦》文本的词频统计和数据可视化
Python 代码主要实现了对《红楼梦》文本的词频统计和数据可视化 完整详细下载地址:https://download.csdn.net/download/huanghm88/89879439 python """ 实训4 基于词频的篇章语义相似度与红楼梦内容分析 步骤3 针对红楼梦词频的数据可视化 &qu…...

yjs机器学习数据操作01——数据的获取、可视化
数据的获取 1.库与模块: import sklearnfrom sklearn import datasets 2.数据集获取的API及解释 对于sklearn的数据获取,主要分为两大部分,分别是“小数据集的获取——load_xxx”和“大数据集的获取fetch_xxx” a.datasets.load_xxx(): …...
w~自动驾驶合集9
我自己的原文哦~ https://blog.51cto.com/whaosoft/12320882 #自动驾驶数据集全面调研 自动驾驶技术在硬件和深度学习方法的最新进展中迅速发展,并展现出令人期待的性能。高质量的数据集对于开发可靠的自动驾驶算法至关重要。先前的数据集调研试图回顾这些数据集&…...

232. 用栈实现队列 【复习链表】-用自定义链表实现栈 用栈实现队列
232. 用栈实现队列 已解答 简单 相关标签 相关企业 请你仅使用两个栈实现先入先出队列。队列应当支持一般队列支持的所有操作(push、pop、peek、empty): 实现 MyQueue 类: void push(int x) 将元素 x 推到队列的末尾int pop() 从队…...
)
G-Set(增长集合,Grow-Only Set)
一、概念 G-Set(增长集合,Grow-Only Set)是一种冲突自由复制数据类型(Conflict-Free Replicated Data Type, CRDT),用于在分布式系统中同步和合并数据,而不需要中央协调器。G-Set 支持两种操作…...

《Vue.js 组件开发秘籍:从基础到高级》
Vue.js 组件开发是构建 Vue 应用程序的核心方法之一。以下是对 Vue.js 组件开发的介绍: 一、什么是 Vue.js 组件? 在 Vue.js 中,组件是可复用的 Vue 实例,它们封装了特定的功能和用户界面。每个组件都有自己独立的模板、逻辑和样…...
【Next.js 项目实战系列】03-查看 Issue
原文链接 CSDN 的排版/样式可能有问题,去我的博客查看原文系列吧,觉得有用的话,给我的库点个star,关注一下吧 上一篇【Next.js 项目实战系列】02-创建 Issue 查看 Issue 展示 Issue 本节代码链接 首先使用 prisma 获取所有…...

Android Settings 设置项修改
Settings 设置项 在 Android 系统上,WRITE_SETTINGS 这个权限从 API 1 就已经开始有了。 通过在 app 中设置权限 android.permission.WRITE_SETTINGS 允许 app 读/写 系统设置。 在官方文档的描述中,还有一段注意事项: Note: If the app targets API level 23 or higher,…...

Windows远程桌面到Ubuntu
在Ubuntu系统中,默认情况下root账户是被禁用的,为了安全起见,建议不要直接使用root账户登录图形界面。但是,如果出于特定的管理或维护需求,您可以按照以下步骤启用和使用root账户登录图形界面: 启用root账户…...
)
解释 RESTful API,以及如何使用它构建 web 应用程序(AI)
RESTful API(Representational State Transfer)是一种基于HTTP协议的软件架构风格,用于构建可扩展、可维护和可重用的网络服务。 RESTful API的特点包括: 1. 基于资源:每个API都代表一个或多个资源,这些资…...

NestJs:处理身份验证和授权
使用 Nest.js 开发项目时,处理身份验证和授权是常见的需求,可以采用以下架构和实现方式。 架构 用户认证模块 (Auth Module): 服务 (Service): 处理用户登录逻辑,生成 JWT(JSON Web Token),以及验证 token…...
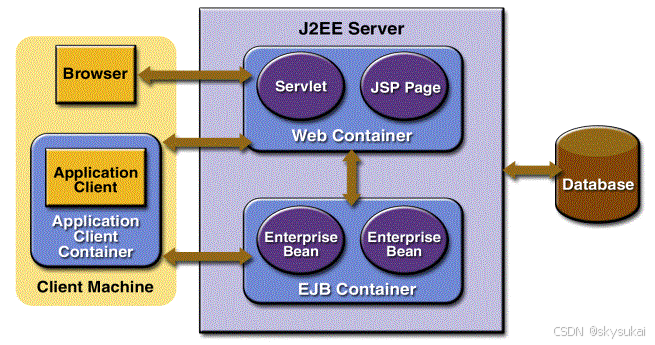
Java EE规范
1、简介 Java EE的全称是Java Platform, Enterprise Edition。早期Java EE也被称为J2EE,即Java 2 Platform Enterprise Edition的缩写。从J2EE1.5以后,就改名成为Java EE。一般来说,企业级应用具备这些特征:1、数据量特别大&…...

Ollama及其Open-WebUI部署更新
目录 1 安装ollama 2 安装Open-WebUI 2.1 不使用容器安装open-webui 2.2 使用Docker安装open-webui 2.3 基于docker升级open-webui 1 安装ollama curl -fsSL https://ollama.com/install.sh | sh启动、关闭ollama systemctl start ollama systemctl stop ollama sys…...

手写 | 设计模式
这里写目录标题 观察者 vs 发布订阅 观察者 vs 发布订阅 参考代码 观察者模式,一对多,两个角色:观察者observer和被观察者/主题Subject。 Subject维护一个数组,记录有哪些Observer;通过调自身的noticefy方法…...

基于深度学习的地形分类与变化检测
基于深度学习的地形分类与变化检测是遥感领域的一个关键应用,利用深度学习技术从卫星、无人机等地球观测平台获取的遥感数据中自动分析地表特征,并识别地形的变化。这一技术被广泛应用于城市规划、环境监测、灾害预警、土地利用变化分析等领域。 1. 地形…...

进程、线程、协程
文章目录 前言一、易混概念1.1 同步vs异步1.2 并发vs并行 二、进程(Process)2.1进程概念2.2 进程三个基本状态2.3多进程方式编程 三、线程(Thread)3.1 线程的引入3.2 线程概念3.3 多线程编程3.4 GIL对多线程的影响3.5 GIL是否意味…...
——元件基础(完整版))
嵌入式工程师成长之路(1)——元件基础(完整版)
系列文章目录 1.元件基础 2.电路设计 3.PCB设计 4.元件焊接 5.板子调试 6.程序设计 7.算法学习 8.编写exe 9.检测标准 10.项目举例 11.职业规划 文章目录 前言一、认识元件①、认识元件②、认识封装二、电阻1.上拉电阻与下拉电阻①、定义②、应用③、阻值选择④、因上下拉电…...

在Ubuntu 20.04 上安装 CoppeliaSim
在 Ubuntu 20.04 上安装 CoppeliaSim Edu V4.6.0 rev18 的步骤如下: 1. 下载安装文件: 首先,确保您已经下载了 CoppeliaSim_Edu_V4_6_0_rev18_Ubuntu20_04.tar.xz 文件。您可以从 Coppelia Robotics 的官方网站下载。 2. 解压缩文件: 打开终端&#…...
)
pulseaudio的相关操作(二)
这篇文章主要介绍pulseaudio playback的相关API,pulseaudio playback的具体实例可以参考[2]。如果用pulseaudio实现playback,简单地说就是创建一个playback stream,然后指定这个stream的sink,再定期的向这个stream中写数据。 mai…...

Selenium自动化测试工具
一 .Selenium简介 是一个用于Web应用程序测试的工具 Selenium的核心功能之一是测试软件在不同浏览器和操作系统上的兼容性,确保软件功能与用户需求的一致性,提升用户体验。 自动化脚本生成与执行 Selenium支持自动录制用户操作并生成多种编程语言的测…...

接口测试中缓存处理策略
在接口测试中,缓存处理策略是一个关键环节,直接影响测试结果的准确性和可靠性。合理的缓存处理策略能够确保测试环境的一致性,避免因缓存数据导致的测试偏差。以下是接口测试中常见的缓存处理策略及其详细说明: 一、缓存处理的核…...

Ubuntu系统下交叉编译openssl
一、参考资料 OpenSSL&&libcurl库的交叉编译 - hesetone - 博客园 二、准备工作 1. 编译环境 宿主机:Ubuntu 20.04.6 LTSHost:ARM32位交叉编译器:arm-linux-gnueabihf-gcc-11.1.0 2. 设置交叉编译工具链 在交叉编译之前&#x…...

java调用dll出现unsatisfiedLinkError以及JNA和JNI的区别
UnsatisfiedLinkError 在对接硬件设备中,我们会遇到使用 java 调用 dll文件 的情况,此时大概率出现UnsatisfiedLinkError链接错误,原因可能有如下几种 类名错误包名错误方法名参数错误使用 JNI 协议调用,结果 dll 未实现 JNI 协…...

Python爬虫实战:研究feedparser库相关技术
1. 引言 1.1 研究背景与意义 在当今信息爆炸的时代,互联网上存在着海量的信息资源。RSS(Really Simple Syndication)作为一种标准化的信息聚合技术,被广泛用于网站内容的发布和订阅。通过 RSS,用户可以方便地获取网站更新的内容,而无需频繁访问各个网站。 然而,互联网…...

【网络安全产品大调研系列】2. 体验漏洞扫描
前言 2023 年漏洞扫描服务市场规模预计为 3.06(十亿美元)。漏洞扫描服务市场行业预计将从 2024 年的 3.48(十亿美元)增长到 2032 年的 9.54(十亿美元)。预测期内漏洞扫描服务市场 CAGR(增长率&…...

Vue2 第一节_Vue2上手_插值表达式{{}}_访问数据和修改数据_Vue开发者工具
文章目录 1.Vue2上手-如何创建一个Vue实例,进行初始化渲染2. 插值表达式{{}}3. 访问数据和修改数据4. vue响应式5. Vue开发者工具--方便调试 1.Vue2上手-如何创建一个Vue实例,进行初始化渲染 准备容器引包创建Vue实例 new Vue()指定配置项 ->渲染数据 准备一个容器,例如: …...

管理学院权限管理系统开发总结
文章目录 🎓 管理学院权限管理系统开发总结 - 现代化Web应用实践之路📝 项目概述🏗️ 技术架构设计后端技术栈前端技术栈 💡 核心功能特性1. 用户管理模块2. 权限管理系统3. 统计报表功能4. 用户体验优化 🗄️ 数据库设…...

IP如何挑?2025年海外专线IP如何购买?
你花了时间和预算买了IP,结果IP质量不佳,项目效率低下不说,还可能带来莫名的网络问题,是不是太闹心了?尤其是在面对海外专线IP时,到底怎么才能买到适合自己的呢?所以,挑IP绝对是个技…...

【从零开始学习JVM | 第四篇】类加载器和双亲委派机制(高频面试题)
前言: 双亲委派机制对于面试这块来说非常重要,在实际开发中也是经常遇见需要打破双亲委派的需求,今天我们一起来探索一下什么是双亲委派机制,在此之前我们先介绍一下类的加载器。 目录 编辑 前言: 类加载器 1. …...

c# 局部函数 定义、功能与示例
C# 局部函数:定义、功能与示例 1. 定义与功能 局部函数(Local Function)是嵌套在另一个方法内部的私有方法,仅在包含它的方法内可见。 • 作用:封装仅用于当前方法的逻辑,避免污染类作用域,提升…...