跨界创新|使用自定义YOLOv11和Ollama(Llama 3)增强OCR文本识别
《博主简介》
小伙伴们好,我是阿旭。专注于人工智能、AIGC、python、计算机视觉相关分享研究。
✌更多学习资源,可关注公-仲-hao:【阿旭算法与机器学习】,共同学习交流~
👍感谢小伙伴们点赞、关注!
《------往期经典推荐------》
一、AI应用软件开发实战专栏【链接】
| 项目名称 | 项目名称 |
|---|---|
| 1.【人脸识别与管理系统开发】 | 2.【车牌识别与自动收费管理系统开发】 |
| 3.【手势识别系统开发】 | 4.【人脸面部活体检测系统开发】 |
| 5.【图片风格快速迁移软件开发】 | 6.【人脸表表情识别系统】 |
| 7.【YOLOv8多目标识别与自动标注软件开发】 | 8.【基于YOLOv8深度学习的行人跌倒检测系统】 |
| 9.【基于YOLOv8深度学习的PCB板缺陷检测系统】 | 10.【基于YOLOv8深度学习的生活垃圾分类目标检测系统】 |
| 11.【基于YOLOv8深度学习的安全帽目标检测系统】 | 12.【基于YOLOv8深度学习的120种犬类检测与识别系统】 |
| 13.【基于YOLOv8深度学习的路面坑洞检测系统】 | 14.【基于YOLOv8深度学习的火焰烟雾检测系统】 |
| 15.【基于YOLOv8深度学习的钢材表面缺陷检测系统】 | 16.【基于YOLOv8深度学习的舰船目标分类检测系统】 |
| 17.【基于YOLOv8深度学习的西红柿成熟度检测系统】 | 18.【基于YOLOv8深度学习的血细胞检测与计数系统】 |
| 19.【基于YOLOv8深度学习的吸烟/抽烟行为检测系统】 | 20.【基于YOLOv8深度学习的水稻害虫检测与识别系统】 |
| 21.【基于YOLOv8深度学习的高精度车辆行人检测与计数系统】 | 22.【基于YOLOv8深度学习的路面标志线检测与识别系统】 |
| 23.【基于YOLOv8深度学习的智能小麦害虫检测识别系统】 | 24.【基于YOLOv8深度学习的智能玉米害虫检测识别系统】 |
| 25.【基于YOLOv8深度学习的200种鸟类智能检测与识别系统】 | 26.【基于YOLOv8深度学习的45种交通标志智能检测与识别系统】 |
| 27.【基于YOLOv8深度学习的人脸面部表情识别系统】 | 28.【基于YOLOv8深度学习的苹果叶片病害智能诊断系统】 |
| 29.【基于YOLOv8深度学习的智能肺炎诊断系统】 | 30.【基于YOLOv8深度学习的葡萄簇目标检测系统】 |
| 31.【基于YOLOv8深度学习的100种中草药智能识别系统】 | 32.【基于YOLOv8深度学习的102种花卉智能识别系统】 |
| 33.【基于YOLOv8深度学习的100种蝴蝶智能识别系统】 | 34.【基于YOLOv8深度学习的水稻叶片病害智能诊断系统】 |
| 35.【基于YOLOv8与ByteTrack的车辆行人多目标检测与追踪系统】 | 36.【基于YOLOv8深度学习的智能草莓病害检测与分割系统】 |
| 37.【基于YOLOv8深度学习的复杂场景下船舶目标检测系统】 | 38.【基于YOLOv8深度学习的农作物幼苗与杂草检测系统】 |
| 39.【基于YOLOv8深度学习的智能道路裂缝检测与分析系统】 | 40.【基于YOLOv8深度学习的葡萄病害智能诊断与防治系统】 |
| 41.【基于YOLOv8深度学习的遥感地理空间物体检测系统】 | 42.【基于YOLOv8深度学习的无人机视角地面物体检测系统】 |
| 43.【基于YOLOv8深度学习的木薯病害智能诊断与防治系统】 | 44.【基于YOLOv8深度学习的野外火焰烟雾检测系统】 |
| 45.【基于YOLOv8深度学习的脑肿瘤智能检测系统】 | 46.【基于YOLOv8深度学习的玉米叶片病害智能诊断与防治系统】 |
| 47.【基于YOLOv8深度学习的橙子病害智能诊断与防治系统】 | 48.【基于深度学习的车辆检测追踪与流量计数系统】 |
| 49.【基于深度学习的行人检测追踪与双向流量计数系统】 | 50.【基于深度学习的反光衣检测与预警系统】 |
| 51.【基于深度学习的危险区域人员闯入检测与报警系统】 | 52.【基于深度学习的高密度人脸智能检测与统计系统】 |
| 53.【基于深度学习的CT扫描图像肾结石智能检测系统】 | 54.【基于深度学习的水果智能检测系统】 |
| 55.【基于深度学习的水果质量好坏智能检测系统】 | 56.【基于深度学习的蔬菜目标检测与识别系统】 |
| 57.【基于深度学习的非机动车驾驶员头盔检测系统】 | 58.【太基于深度学习的阳能电池板检测与分析系统】 |
| 59.【基于深度学习的工业螺栓螺母检测】 | 60.【基于深度学习的金属焊缝缺陷检测系统】 |
| 61.【基于深度学习的链条缺陷检测与识别系统】 | 62.【基于深度学习的交通信号灯检测识别】 |
| 63.【基于深度学习的草莓成熟度检测与识别系统】 | 64.【基于深度学习的水下海生物检测识别系统】 |
| 65.【基于深度学习的道路交通事故检测识别系统】 | 66.【基于深度学习的安检X光危险品检测与识别系统】 |
二、机器学习实战专栏【链接】,已更新31期,欢迎关注,持续更新中~~
三、深度学习【Pytorch】专栏【链接】
四、【Stable Diffusion绘画系列】专栏【链接】
五、YOLOv8改进专栏【链接】,持续更新中~~
六、YOLO性能对比专栏【链接】,持续更新中~
《------正文------》
目录
- 引言
- 为什么我们需要使用OCR的YOLO和Ollama?
- 1.训练自定义Yolo11数据集
- 2.在视频上运行边界框的自定义模型
- 3.在边界框上运行OCR
- 4.使用Ollama优化文本
- 结论
引言

该项目通过将自定义训练的YOLO11模型与EasyOCR集成并使用LLM优化结果来增强文本识别工作流程LLM。
本文将大型语言模型(LLMs)与计算机视觉结合,通过计算机视觉训练的YOLO11模型定位文本区域,之后通过OCR的文本识别之后,最终大语言模型进行识别结果优化,以获取更加准确的文本识别效果。
为什么我们需要使用OCR的YOLO和Ollama?
传统的OCR(光学字符识别)方法可以很好地从简单的图像中提取文本,但当文本与其他视觉元素交织在一起时,往往会出现问题。通过使用自定义YOLO模型首先检测文本区域等对象,我们可以隔离这些区域进行OCR,从而显著降低噪声并提高准确性。
让我们通过在没有YOLO的图像上运行一个基本的OCR示例来演示这一点,以突出单独使用OCR的挑战:

import easyocr
import cv2
# Initialize EasyOCR
reader = easyocr.Reader(['en'])
# Load the image
image = cv2.imread('book.jpg')
# Run OCR directly
results = reader.readtext(image)
# Display results
for (bbox, text, prob) in results:print(f"Detected Text: {text} (Probability: {prob})")
THE 0 R |G |NAL B E STSELLE R THE SECRET HISTORY DONNA TARTT Haunting, compelling and brilliant The Times
不是你想要的,对吧?虽然它可以很好地处理简单的图像,但当有噪音或复杂的视觉模式时,错误就会开始堆积。这就是YOLO模型介入并真正发挥作用的地方。
1.训练自定义Yolo11数据集
通过对象检测增强OCR的第一步是在数据集上训练自定义YOLO模型。YOLO(You Only Look Once)是一个强大的实时对象检测模型,它将图像划分为网格,使其能够在一次向前传递中识别多个对象。这种方法非常适合检测图像中的文本,特别是当您希望通过隔离特定区域来改善OCR结果时。

我们将使用预先标注的书籍封面数据集,并在其上训练YOLO11模型。YOLO11针对较小的对象进行了优化,使其非常适合在具有挑战性的上下文(如视频或扫描文档)中检测文本。
from ultralytics import YOLOmodel = YOLO("yolo11.pt")
# Train the model
model.train(data="datasets/data.yaml", epochs=50, imgsz=640)
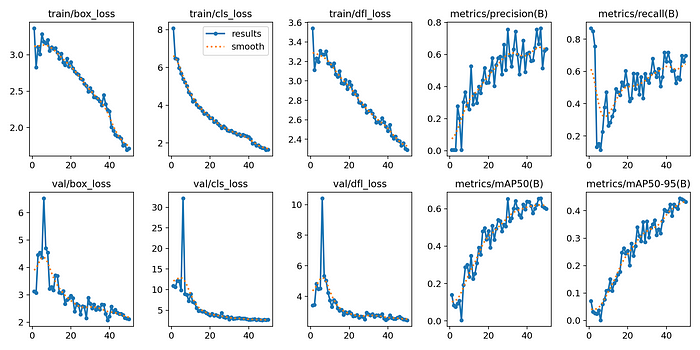
在我的例子中,在Google Colab上训练这个模型花了大约六个小时50个时期。您可以调整参数,如epoch数量和数据集大小,或使用超参数进行实验,以提高模型的性能和准确性。
2.在视频上运行边界框的自定义模型
一旦YOLO模型经过训练,您就可以将其应用于视频,以检测文本区域周围的边界框。这些边界框隔离了感兴趣的区域,确保了更清晰的OCR过程:
import cv2
# Open video file
video_path = 'books.mov'
cap = cv2.VideoCapture(video_path)
# Load YOLO model
model = YOLO('model.pt')
# Function for object detection and drawing bounding boxes
def predict_and_detect(model, frame, conf=0.5):results = model.predict(frame, conf=conf)for result in results:for box in result.boxes:# Draw bounding boxx1, y1, x2, y2 = map(int, box.xyxy[0].tolist())cv2.rectangle(frame, (x1, y1), (x2, y2), (255, 0, 0), 2)return frame, results
# Process video frames
while cap.isOpened():ret, frame = cap.read()if not ret:break# Run object detectionprocessed_frame, results = predict_and_detect(model, frame)# Show video with bounding boxescv2.imshow('YOLO + OCR Detection', processed_frame)if cv2.waitKey(1) & 0xFF == ord('q'):break
# Release video
cap.release()
cv2.destroyAllWindows()

此代码实时处理视频,在检测到的文本周围绘制边界框,并隔离这些区域,为下一步- OCR完美地设置它们。
3.在边界框上运行OCR
现在我们已经使用YOLO隔离了文本区域,我们可以在这些特定区域内应用OCR,与在整个图像上运行OCR相比,大大提高了准确性:
import easyocr
# Initialize EasyOCR
reader = easyocr.Reader(['en'])
# Function to crop frames and perform OCR
def run_ocr_on_boxes(frame, boxes):ocr_results = []for box in boxes:x1, y1, x2, y2 = map(int, box.xyxy[0].tolist())cropped_frame = frame[y1:y2, x1:x2]ocr_result = reader.readtext(cropped_frame)ocr_results.append(ocr_result)return ocr_results
# Perform OCR on detected bounding boxes
for result in results:ocr_results = run_ocr_on_boxes(frame, result.boxes)# Extract and display the text from OCR resultsextracted_text = [detection[1] for ocr in ocr_results for detection in ocr]print(f"Extracted Text: {', '.join(extracted_text)}")
'THE, SECRET, HISTORY, DONNA, TARTT'
结果得到了显著改善,因为OCR引擎现在只处理明确识别为包含文本的区域,降低了不相关图像元素的误解风险。
4.使用Ollama优化文本
在使用easyocr提取文本之后,Llama 3可以通过改进通常不完美和混乱的结果来进一步改进。OCR功能很强大,但它仍然可能误解文本或返回无序的数据,特别是书籍标题或作者姓名。
LLM介入整理输出,将原始OCR结果转换为结构化的连贯文本。通过引导Llama 3使用特定的提示来识别和组织内容,我们可以将不完善的OCR数据细化为格式整齐的书名和作者姓名。最精彩的部分?你可以在本地使用Ollama!
import ollama
# Construct a prompt to clean up the OCR output
prompt = f"""
- Below is a text extracted from an OCR. The text contains mentions of famous books and their corresponding authors.
- Some words may be slightly misspelled or out of order.
- Your task is to identify the book titles and corresponding authors from the text.
- Output the text in the format: '<Name of the book> : <Name of the author>'.
- Do not generate any other text except the book title and the author.
TEXT:
{output_text}
"""
# Use Ollama to clean and structure the OCR output
response = ollama.chat(model="llama3",messages=[{"role": "user", "content": prompt}]
)
# Extract cleaned text
cleaned_text = response['message']['content'].strip()
print(cleaned_text)
The Secret History : Donna Tartt
完全正确!一旦LLM清理了文本,抛光输出可以存储在数据库中或在各种现实世界的应用程序中工作,例如:
- 数字图书馆或书店:自动分类和显示图书标题旁边的作者。
- 档案系统:将扫描的书籍封面或文档转换为可搜索的数字记录。
- 自动元数据生成:根据提取的信息为图像、PDF或其他数字资产生成元数据。
- 数据库输入:将清理后的文本直接插入数据库,确保大型系统的结构化和一致的数据。
通过结合对象检测、OCR和LLMs,您可以解锁一个强大的管道,实现更结构化的数据处理,非常适合需要高精度的应用程序。
结论
您可以通过将自定义训练的YOLO11模型与EasyOCR相结合并使用LLM增强结果来显着改进文本识别工作流程。LLM无论您是处理棘手的图像或视频中的文本,清理OCR混乱,还是使一切都超级精美,此管道都可以为您提供实时精确的文本提取和细化。
好了,这篇文章就介绍到这里,喜欢的小伙伴感谢给点个赞和关注,更多精彩内容持续更新~~
关于本篇文章大家有任何建议或意见,欢迎在评论区留言交流!
相关文章:
跨界创新|使用自定义YOLOv11和Ollama(Llama 3)增强OCR文本识别
《博主简介》 小伙伴们好,我是阿旭。专注于人工智能、AIGC、python、计算机视觉相关分享研究。 ✌更多学习资源,可关注公-仲-hao:【阿旭算法与机器学习】,共同学习交流~ 👍感谢小伙伴们点赞、关注! 《------往期经典推…...

一些关于 WinCC Comfort 和 WinCC Advanced 脚本编程语言 VBS 的实用技巧
为什么一个由内部变量的 “数值更变” 事件触发的脚本不执行? 如果使用一个内部变量调用另外一个内部变量,以此,例如被调用的变量又去执行一个脚本(比如,根据变量变化),此时一个安全机制会阻止这…...

Java|乐观锁和悲观锁在自旋的时候分别有什么表现?
乐观锁和悲观锁是两种不同的并发控制策略,各自采用不同的机制来处理线程之间的资源竞争。 乐观锁 1. 定义 乐观锁是一种假设冲突不会发生的并发控制策略,通常不对资源进行加锁,而是在操作前不加锁,操作后再进行验证。乐观锁通常…...

Linux定时器定时任务清理log日志文件
首先,创建xx.sh文件,内容如下 #!/bin/bash sfecho "" > /var/lib/docker/containers/12379e809ea1294eea9b117368181cff1dd3915fdb1611f940c5cf3d6077d734/12379e809ea1294eea9b117368181cff1dd3915fdb1611f940c5cf3d6077d734-json.log 打…...
介绍)
美国大学生数学建模竞赛(MCM/ICM)介绍
美国大学生数学建模竞赛(MCM/ICM)是一项具有较高影响力的国际赛事。以下是一份美赛教程: 一、前期准备 组队 寻找合适的队友,最好具备不同的专业技能,如数学、计算机、工程等。团队成员应具备良好的沟通能力、合作精神和责任心。明确各自的分工,例如有人负责建模、有人负…...
【独家:AI编程助手Cursor如何revolutionize Java设计模式学习】
【独家:AI编程助手Cursor如何revolutionize Java设计模式学习】 导语 在Java高级编程的世界里,设计模式是每个开发者必须掌握的利器。但是,如何快速理解并灵活运用这些模式呢?让我们一起探索如何借助AI编程助手Cursor,轻松掌握设计模式,提升Java编程技能! 正文 设计模式:J…...

数据仓库宽表概述
宽表是指一种将多个相关数据集整合到一个表中的数据建模方法,具有减少连接操作、提高查询性能、简化数据管理的优点。 一、宽表的定义 宽表,顾名思义,是一种在数据仓库中使用的表格形式,其特征是包含了大量的列。这种表格设计的…...

在数据库中编程 vs 在应用程序中编程
原文地址 https://brandur.org/fragments/code-database-vs-app 数据库领域有一个长期存在的问题:你是更愿意将应用逻辑放在更接近数据库本身的存储过程和触发器中,还是置于数据库之上的应用程序代码中? 没有客观正确的答案,只有…...

【设计模式系列】装饰器模式
目录 一、什么是装饰器模式 二、装饰器模式中的角色 三、装饰器模式的典型应用场景 四、装饰器模式在BufferedReader中的应用 一、什么是装饰器模式 装饰器模式是一种结构型设计模式,用于在不修改对象自身的基础上,通过创建一个或多个装饰类来给对象…...

你真的知道TCP协议中的序列号确认、上层协议及记录标识问题吗?
引言 在前面的内容中,我们已经详细讲解了一系列与TCP相关的面试问题。然而,这些问题都是基于个别知识点进行扩展的。今天,我们将重点讨论一些场景问题,并探讨如何解决这些问题。 序列号确认问题 当A主机与B主机建立了TCP连接后…...

一家生物技术企业终止,科创属性可能不足,报告期内专利数猛增
轩凯生物九成以上营业收入来源于植物营养领域,收入来源结构单一,产品下游应用领域较为集中。报告期内公司应收账款账面价值逐年上升,回款比例显著低于前两年,遭交易所问询是否存在较大的坏账风险。 轩凯生物核心技术是否成熟以及是…...

使用 Python 的 BeautifulSoup(bs4)解析复杂 HTML
使用 Python 的 BeautifulSoup(bs4)解析复杂 HTML:详解与示例 在 Web 开发和数据分析中,解析 HTML 是一个常见的任务,尤其是当你需要从网页中提取数据时。Python 提供了多个库来处理 HTML,其中最受欢迎的就…...

Spring Cache Caffeine 高性能缓存库
Caffeine 背景 Caffeine是一个高性能的Java缓存库,它基于Guava Cache进行了增强,提供了更加出色的缓存体验。Caffeine的主要特点包括: 高性能:Caffeine使用了Java 8最新的StampedLock乐观锁技术,极大地提高了缓存…...

Python3入门--数据类型
文章目录 一、基础语法编码标识符注释单行注释以 # 开头多行注释用多个 # 号,还有 和 """ 空行行与缩进同一行显示多条语句多行语句 二、数据类型Number(数字)type和isinstance查询变量类型数值运算 String(字符串…...

开发运维警示录-20241024
开发警示录 1、作为开发,不要私自修改业务人员给的SQL语句,虽然个人感觉SQL很冗余,效率低等。 2、开发前,要明确需求,必要时通过图和文字形成文档与需求方确认、留痕。 3、开发复杂的业务逻辑代码前,先疏通…...

Linux运维_搭建smb服务
Samba(SMB)是一个开源软件,允许Linux和Unix系统与Windows系统共享文件和打印机。以下是一些关于Samba和SMB的基本信息和操作步骤: Samba 和 SMB 基本概念 Samba:实现了SMB(Server Message Blockÿ…...
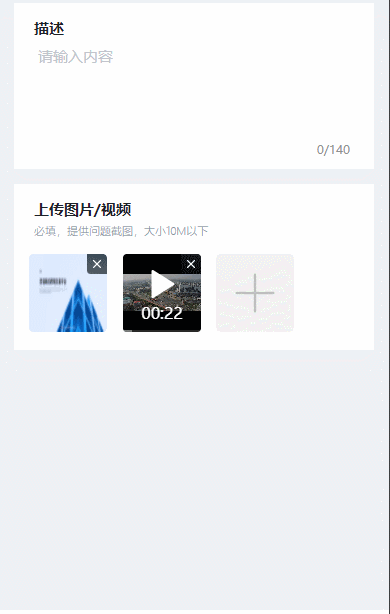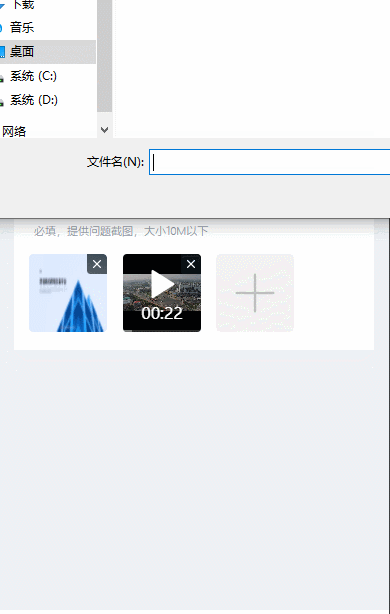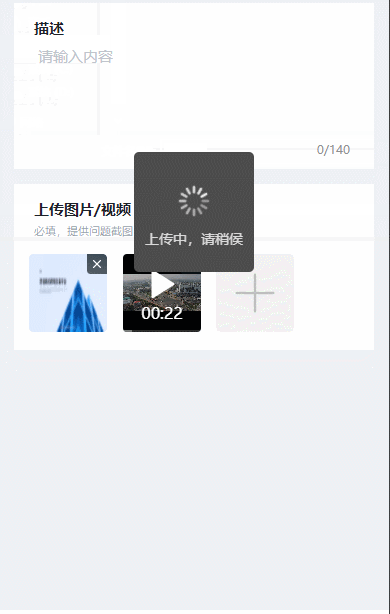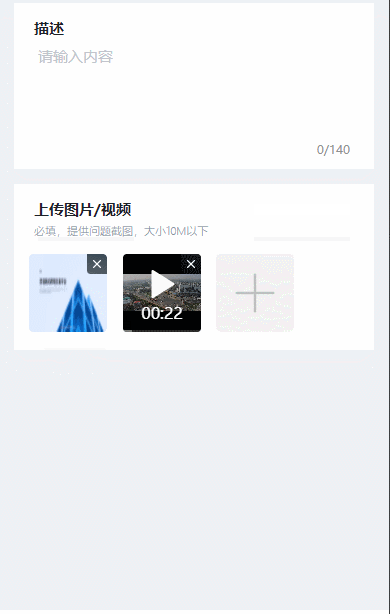
vue3移动端可同时上传照片和视频的组件
uni-app中的uni-file-picker可单独上传照片或视频,但不支持同时上传照片和视频。本篇博客使用image标签和video标签实现移动端(H5app小程序)中照片和视频的同时上传。 本篇博客采用的是照片和视频的单独上传,但可同时展示…...

PyQt入门指南二十七 QTableView表格视图组件
# 创建一个QStandardItemModel实例,用于存储表格数据model QStandardItemModel(4, 2) # 4行2列# 填充模型数据for row in range(4):for column in range(2):item QStandardItem(fRow {row}, Column {column})model.setItem(row, column, item)# 创建一个QTableVi…...
)
AI学习指南深度学习篇-自注意力机制(Self-Attention Mechanism)
AI学习指南深度学习篇—自注意力机制(Self-Attention Mechanism) 在深度学习的研究领域,自注意力机制(Self-Attention Mechanism)作为一种创新的模型结构,已成为了神经网络领域的一个重要组成部分…...

【JAVA毕业设计】基于Vue和SpringBoot的校园管理系统
本文项目编号 T 026 ,文末自助获取源码 \color{red}{T026,文末自助获取源码} T026,文末自助获取源码 目录 一、系统介绍二、演示录屏三、启动教程四、功能截图五、文案资料5.1 选题背景5.2 国内外研究现状5.3 可行性分析 六、核心代码6.1 管…...

eNSP-Cloud(实现本地电脑与eNSP内设备之间通信)
说明: 想象一下,你正在用eNSP搭建一个虚拟的网络世界,里面有虚拟的路由器、交换机、电脑(PC)等等。这些设备都在你的电脑里面“运行”,它们之间可以互相通信,就像一个封闭的小王国。 但是&#…...

7.4.分块查找
一.分块查找的算法思想: 1.实例: 以上述图片的顺序表为例, 该顺序表的数据元素从整体来看是乱序的,但如果把这些数据元素分成一块一块的小区间, 第一个区间[0,1]索引上的数据元素都是小于等于10的, 第二…...

GC1808高性能24位立体声音频ADC芯片解析
1. 芯片概述 GC1808是一款24位立体声音频模数转换器(ADC),支持8kHz~96kHz采样率,集成Δ-Σ调制器、数字抗混叠滤波器和高通滤波器,适用于高保真音频采集场景。 2. 核心特性 高精度:24位分辨率,…...

JavaScript基础-API 和 Web API
在学习JavaScript的过程中,理解API(应用程序接口)和Web API的概念及其应用是非常重要的。这些工具极大地扩展了JavaScript的功能,使得开发者能够创建出功能丰富、交互性强的Web应用程序。本文将深入探讨JavaScript中的API与Web AP…...

【Elasticsearch】Elasticsearch 在大数据生态圈的地位 实践经验
Elasticsearch 在大数据生态圈的地位 & 实践经验 1.Elasticsearch 的优势1.1 Elasticsearch 解决的核心问题1.1.1 传统方案的短板1.1.2 Elasticsearch 的解决方案 1.2 与大数据组件的对比优势1.3 关键优势技术支撑1.4 Elasticsearch 的竞品1.4.1 全文搜索领域1.4.2 日志分析…...
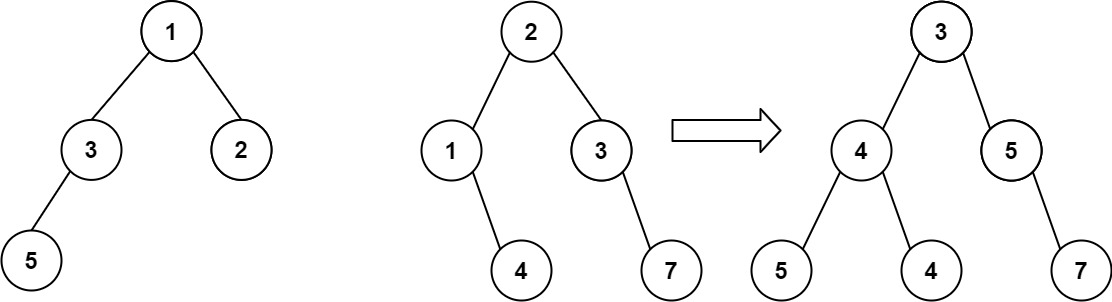
算法打卡第18天
从中序与后序遍历序列构造二叉树 (力扣106题) 给定两个整数数组 inorder 和 postorder ,其中 inorder 是二叉树的中序遍历, postorder 是同一棵树的后序遍历,请你构造并返回这颗 二叉树 。 示例 1: 输入:inorder [9,3,15,20,7…...
——统计抽样学习笔记(考试用))
统计学(第8版)——统计抽样学习笔记(考试用)
一、统计抽样的核心内容与问题 研究内容 从总体中科学抽取样本的方法利用样本数据推断总体特征(均值、比率、总量)控制抽样误差与非抽样误差 解决的核心问题 在成本约束下,用少量样本准确推断总体特征量化估计结果的可靠性(置…...
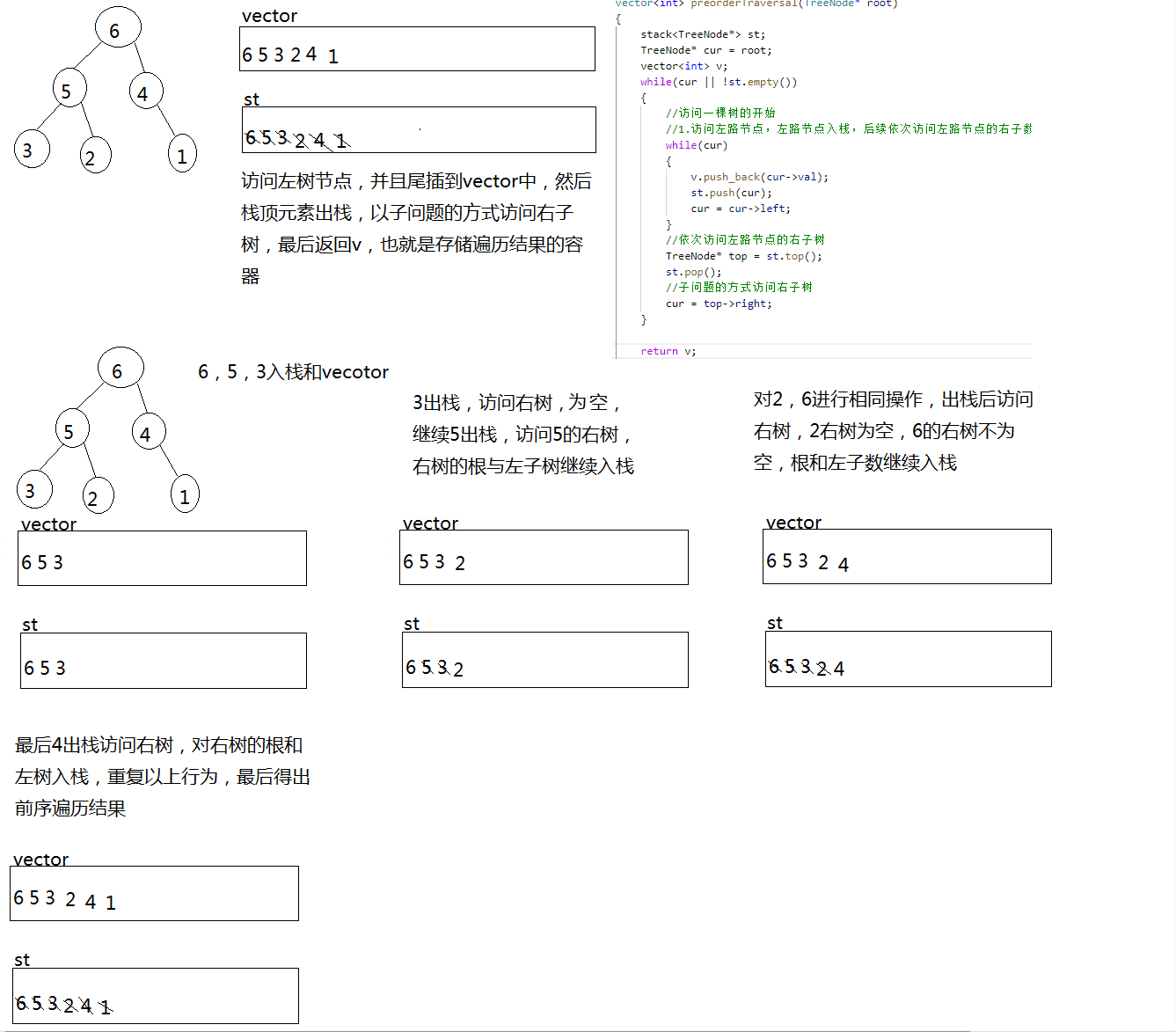
二叉树-144.二叉树的前序遍历-力扣(LeetCode)
一、题目解析 对于递归方法的前序遍历十分简单,但对于一位合格的程序猿而言,需要掌握将递归转化为非递归的能力,毕竟递归调用的时候会调用大量的栈帧,存在栈溢出风险。 二、算法原理 递归调用本质是系统建立栈帧,而非…...

AT模式下的全局锁冲突如何解决?
一、全局锁冲突解决方案 1. 业务层重试机制(推荐方案) Service public class OrderService {GlobalTransactionalRetryable(maxAttempts 3, backoff Backoff(delay 100))public void createOrder(OrderDTO order) {// 库存扣减(自动加全…...

前端打包工具简单介绍
前端打包工具简单介绍 一、Webpack 架构与插件机制 1. Webpack 架构核心组成 Entry(入口) 指定应用的起点文件,比如 src/index.js。 Module(模块) Webpack 把项目当作模块图,模块可以是 JS、CSS、图片等…...