2024.10月22日- MySql的 补充知识点
1、什么是数据库事务?
数据库事务: 是数据库管理系统执行过程中的一个逻辑单位,由一个有限的数据库操作序列构成,这些操作要么全部执行,要么全部不执行,是一个不可分割的工作单位。
2、Mysql事务的四大特性是什么?
- 原子性: 事务作为一个整体被执行,包含在其中的对数据库的操作要么全部被执行,要么都不执行。
- 一致性: 指在事务开始之前和事务结束以后,数据不会被破坏,假如A账户给B账户转10块钱,不管成功与否,A和B的总金额是不变的。
- 隔离性: 多个事务并发访问时,事务之间是相互隔离的,即一个事务不影响其它事务运行效果。
- 持久性: 表示事务完成以后,该事务对数据库所作的操作更改,将持久地保存在数据库之中。
3、事务ACID特性的实现原理?
- 原子性:是使用 undo log 来实现的,如果事务执行过程中出错或者用户执行了rollback,系统通过undo log日志返回事务开始的状态。
- 持久性:使用 redo log 来实现,只要redo log日志持久化了,当系统崩溃,即可通过redo log把数据恢复。
- 隔离性:通过锁以及 MVCC,使事务相互隔离开。
- 一致性:通过回滚、恢复,以及并发情况下的隔离性,从而实现一致性。
有关MVCC相关知识可以参考:看一遍就懂:MVCC原理详解
4、事务的隔离级别有哪些?
- 读未提交(Read Uncommitted)最低级别,任何情况都无法保证
- 读已提交(Read Committed)可避免脏读的发生
- 可重复读(Repeatable Read)可避免脏读、不可重复读的发生
- 串行化(Serializable)可避免脏读、不可重复读、幻读的发生
Mysql默认的事务隔离级别是可重复读(Repeatable Read)
5、什么是脏读、不可重复读、幻读呢?
- 脏读: 脏读指的是读到了其他事务未提交的数据,未提交意味着这些数据可能会回滚,也就是可能最终不会存到数据库中,也就是不存在的数据。读到了并不一定最终存在的数据,这就是脏读。
- 不可重复读: 不可重复读指的是在一个事务内,最开始读到的数据和事务结束前的任意时刻读到的同一批数据出现不一致的情况。
- 幻读: 幻读,并不是说两次读取获取的结果集不同,幻读侧重的方面是某一次的 select 操作得到的结果的数据状态无法支撑后续的业务操作。更为具体一些:select 某记录是否存在,不存在,准备插入此记录,但执行 insert 时发现此记录已存在,无法插入,此时就发生了幻读。
具体看之前写的一篇文章一文详解脏读、不可重复读、幻读
6、datetime和timestamp的区别?
它们和date的区别在于: date存储精度到天,它们存储精度都为秒。
它们的区别在于:
- datetime 的日期范围是 1001——9999 年;timestamp 的时间范围是 1970——2038 年
- datetime 存储时间与时区无关;timestamp 存储时间与时区有关,显示的值也依赖于时区
- datetime 的存储空间为 8 字节;timestamp 的存储空间为 4 字节
- datetime 的默认值为 null;timestamp 的字段默认不为空(not null),默认值为当前时间(current_timestamp)
7、varchar和char有什么区别?
char是一个定长字段,假如申请了char(10)的空间,那么无论实际存储多少内容.该字段都占用10个字符,而varchar是变长的,也就是说申请的只是最大长度,占用的空间为实际字符长度+1,最后一个字符存储使用了多长的空间。
在检索效率上来讲,char > varchar,因此在使用中,如果确定某个字段的值的长度,可以使用char,否则应该尽量使用varchar.例如存储用户MD5加密后的密码,则应该使用char。
8、count(1)、count(*) 与 count(列名) 的区别?
- count(*)包括了所有的列,相当于行数,在统计结果的时候,不会忽略列值为NULL
- count(1)包括了忽略所有列,用1代表代码行,在统计结果的时候,不会忽略列值为NULL
- count(列名)只包括列名那一列,在统计结果的时候,会忽略列值为空(这里的空表示null)的计数,即某个字段值为NULL时,不统计。
阿里巴巴Java开发手册有一条强制建议:不要使用count(列名)或count(常量)来代替count(*)。count(*)就是SQL92定义的标准统计行数语法,跟数据库无关。
9、exist和in的区别?
-- inselect * from a where id in (select id from b);-- existsselect * from A where exists(select 1 from B where B.id = A.id);使用in时,sql语句是先执行子查询,也就是先查询子表b,再查主表a。而使用exists是先查主表a ,再查询子表b。
根据小表驱动大表(即小的数据集驱动大的数据集)的原则,如果主查询中的表较大且又有索引时应该用in。 反之如果外层的主查询记录较少,子查询中的表大,又有索引时使用exists。
还有一点注意的是用 exists 该子查询实际上并不返回任何数据,而是返回值True或False。
not in 和not exists
如果查询语句使用了not in 那么内外表都进行全表扫描,没有用到索引;而not extsts 的子查询依然能用到表上的索引。所以无论那个表大,用not exists都比not in要快。
10、truncate、delete与drop区别?
| | delete | truncate | drop | | -------- | ---------------------------------------- | ------------------------------ | -------------------------------------------------- | | 类型 | DML | DDL | DDL | | 回滚 | 可回滚 | 不可回滚 | 不可回滚 | | 删除内容 | 表结构还在,删除表的全部或者一部分数据行 | 表结构还在,删除表中的所有数据 | 表结构也会删除,所有的数据行,索引和权限也会被删除 | | 删除速度 | 删除速度慢,逐行删除 | 删除速度快 | 删除速度最快 |
11、union与union all的区别?
- Union:对两个结果集进行并集操作,不包括重复行,同时进行默认规则的排序;
- Union All:对两个结果集进行并集操作,包括重复行,不进行排序;
从效率上说,union all 要比union快很多,所以,如果可以确认合并的两个结果集中不包含重复的数据的话,那么就使用union all
12、group by 和 distinct 的区别?
它们本质语言逻辑上的数据处理动作先后是不一样,distinct 是先获取结果集,再去重复记录。group by 是基于KEY先分组,再返回计算结果。
从效率上来讲 group by和distinct都能使用索引,在相同语义下,从执行效率上也看不到明显的差异;
那为什么,大家都更推崇使用group by?
- group by语义更为清晰
- group by可对数据进行更为复杂的一些处理
由于distinct关键字会对所有字段生效,在进行复合业务处理时,group by的使用灵活性更高,group by能根据分组情况,对数据进行更为复杂的处理,例如通过having对数据进行过滤,或通过聚合函数对数据进行运算。
13、Blob和text有什么区别?
- Blob用于存储二进制数据,而Text用于存储大字符串。
- Blob值被视为二进制字符串(字节字符串),它们没有字符集,并且排序和比较基于列值中的字节的数值。
- text值被视为非二进制字符串(字符字符串)。它们有一个字符集,并根据字符集的排序规则对值进行排序和比较。
14、常见的存储引擎有哪些?
Mysql中常用的四种存储引擎分别是:MyISAM、InnoDB、MEMORY、ARCHIVE。Mysql 5.5版本后默认的存储引擎为InnoDB。
15 说一说InnoDB与MyISAM的区别?
MyISAM和InnoDB两者之间还是有着明显区别
1) 事务支持
MyISAM不支持事务,而InnoDB支持。
2) 表锁差异
MyISAM:只支持表级锁。
InnoDB:支持事务和行级锁,是innodb的最大特色。行锁大幅度提高了多用户并发操作的新能。但是InnoDB的行锁,只有在索引上才可能是行锁,否则还是表锁。
3)索引结构
MyISAM引擎使用B+Tree作为索引结构,叶节点的data域存放的是数据记录的地址,即:MyISAM索引文件和数据文件是分离的,MyISAM的索引文件仅仅保存数据记录的地址。MyISAM中索引检索的算法为首先按照B+Tree搜索算法搜索索引,如果指定的Key存在,则取出其data域的值,然后以data域的值为地址,读取相应数据记录。MyISAM的索引方式也叫做“非聚集”的。
InnoDB引擎也使用B+Tree作为索引结构,但是InnoDB的数据文件本身就是索引文件,叶节点data域保存了完整的数据记录。这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引。这种索引叫做“聚焦索引”。InnoDB的辅助索引的data域存储相应记录主键的值而不是地址。
4)表主键
MyISAM:允许没有任何索引和主键的表存在,索引都是保存行的地址。 InnoDB:如果没有设定主键或者非空唯一索引,就会自动生成一个6字节的主键(用户不可见),数据是主索引的一部分,其它索引保存的是主索引的值。
5) 表的具体行数
MyISAM:保存有表的总行数,如果select count(*) from table;会直接取出出该值。
InnoDB:没有保存表的总行数(只能遍历),如果使用select count(*) from table;就会遍历整个表,消耗相当大,但是在加了where条件后,myisam和innodb处理的方式都一样。
6) 外键
MyISAM:不支持
InnoDB:支持
16 bin log/redo log/undo log是什么?
bin log、redo log、undo log三种日志属于不同级别的日志,按照Mysql的划分可以分为服务层和引擎层两大层,bin log是在服务层实现的;redo log、undo log是在引擎层实现的,且是innodb引擎独有的,主要和事务相关。
1、bin log
bin log是Mysql数据库级别的文件,记录对Mysql数据库执行修改的所有操作,不会记录select和show语句。使用任何存储引擎的 Mysql 数据库都会记录 binlog 日志。
在实际应用中, binlog 的主要使用场景有两个,分别是 主从复制 和 数据恢复 。
主从复制 :在 Master 端开启 binlog ,然后将 binlog发送到各个 Slave 端, 从而达到主从数据一致。 数据恢复 :通过使用 Mysqlbinlog 工具来恢复数据。
2、redo log
redo log中记录的是要更新的数据,比如一条数据已提交成功,并不会立即同步到磁盘,而是先记录到redo log中,等待合适的时机再刷盘,为了实现事务的持久性。
如果没有redo log,那么每次事务提交的时候,将该事务涉及修改的数据页全部刷新到磁盘中。但是这么做会有严重的性能问题,主要体现在两个方面:
因为 Innodb 是以 页 为单位进行磁盘交互的,而一个事务很可能只修改一个数据页里面的几个字节,这个时候将完整的数据页刷到磁盘的话,太浪费资源了!
一个事务可能涉及修改多个数据页,并且这些数据页在物理上并不连续,使用随机IO写入性能太差!
因此 Mysql 设计了 redo log , 具体来说就是只记录事务对数据页做了哪些修改,这样就能完美地解决性能问题了(相对而言文件更小并且是顺序IO)。
3、undo log
除了记录redo log外,当进行数据修改时还会记录undo log,undo log用于数据的撤回操作,它保留了记录修改前的内容。通过undo log可以实现事务回滚,并且可以根据undo log回溯到某个特定的版本的数据,实现MVCC。
17 bin log和redo log有什么区别?
- bin log会记录所有日志记录,包括InnoDB、MyISAM等存储引擎的日志;redo log只记录innoDB自身的事务日志。
- bin log只在事务提交前写入到磁盘,一个事务只写一次;而在事务进行过程,会有redo log不断写入磁盘。
- bin log是逻辑日志,记录的是SQL语句的原始逻辑;redo log是物理日志,记录的是在某个数据页上做了什么修改。
18 说一下数据库的三大范式?
- 第一范式:数据表中的每一列(每个字段)都不可以再拆分。
- 第二范式:在第一范式的基础上,非主键列完全依赖于主键,而不能是依赖于主键的一部分。
- 第三范式:在满足第二范式的基础上,表中的非主键只依赖于主键,而不依赖于其他非主键。
19 什么是存储过程?有哪些优缺点?
存储过程,就是一些编译好了的SQL语句,这些SQL语句代码像一个方法一样实现一些功能(对单表或多表的增删改查),然后给这些代码块取一个名字,在用到这个功能的时候调用即可。
优点:
- 存储过程是一个预编译的代码块,执行效率比较高
- 存储过程在服务器端运行,减少客户端的压力
- 允许模块化程序设计,只需要创建一次过程,以后在程序中就可以调用该过程任意次,类似方法的复用
- 一个存储过程替代大量SQL语句 ,可以降低网络通信量,提高通信速率
- 可以一定程度上确保数据安全
缺点:
- 调试麻烦
- 可移植性不灵活
- 重新编译问题
20 主键使用自增ID还是UUID?
推荐使用自增ID,不要使用UUID。
因为在InnoDB存储引擎中,主键索引是作为聚簇索引存在的,也就是说,主键索引的B+树叶子节点上存储了主键索引以及全部的数据(按照顺序),如果主键索引是自增ID,那么只需要不断向后排列即可,如果是UUID,由于到来的ID与原来的大小不确定,会造成非常多的数据插入,数据移动,然后导致产生很多的内存碎片,进而造成插入性能的下降。
21 超大分页怎么处理?
- 用id优化
先找到上次分页的最大ID,然后利用id上的索引来查询,类似于
select * from user where id>1000000 limit 100这样的效率非常快,因为主键上是有索引的,但是这样有个缺点,就是ID必须是连续的,并且查询不能有where语句,因为where语句会造成过滤数据。
- 用覆盖索引优化
Mysql的查询完全命中索引的时候,称为覆盖索引,是非常快的,因为查询只需要在索引上进行查找,之后可以直接返回,而不用再回表拿数据.因此我们可以先查出索引的ID,然后根据Id拿数据.
select * from table where id in (select id from table where age > 20 limit 1000000,10)- 在业务允许的情况下限制页数
建议跟业务讨论,有没有必要查这么后的分页啦。因为绝大多数用户都不会往后翻太多页。
22 一个6亿的表a,一个3亿的表b,通过外间tid关联,你如何最快的查询出满足条件的第50000到第50200中的这200条数据记录。
这是一道腾讯的面试题,其实这个问题和上面是同一个问题,都是超大分页的问题,这就像读书的时候做数学题一样,上面是公式、定理,下面是题目,所以要学会举一反三。
1、如果A表TID是自增长,并且是连续的,B表的ID为索引
select * from a,b where a.tid = b.id and a.tid>500000 limit 200;2、如果A表的TID不是连续的,那么就需要使用覆盖索引.TID要么是主键,要么是辅助索引,B表ID也需要有索引。
select * from b , (select tid from a limit 50000,200) a where b.id = a .tid;23 日常开发中是怎么优化SQL的?
这个问题问的挺大的,可以也先从几个大的纬度来回答。
- 添加合适索引
- 优化表结构
- 优化查询语句
然后针对每个大的纬度稍微讲几句。
1、添加合适索引
- 对作为查询条件和order by的字段建立索引。
- 对于多个查询字段的考虑建立组合索引,同时注意组合索引字段的顺序,将最常用作限制条件的列放在最左边,依次递减。
- 索引不宜太多,一般5个以内。
2、优化表结构
选择正确的数据类型,对于提高性能也是至关重要。下面给出几种原则:
- 数字型字段优于字符串类型
若只含数值信息的字段尽量不要设计为字符型,这会降低查询和连接的性能,并会增加存储开销。
- 数据类型更小通常更好
使用最小的数据类型,会减少磁盘的空间,内存和CPU缓存。好比时间类型尽量使用TIMESTAMP类型,因为其存储空间只需要 DATETIME 类型的一半。对于只需要精确到某一天的数据类型,建议使用DATE类型,因为他的存储空间只需要3个字节,比TIMESTAMP还少。
- 尽量使用 NOT NULL
NULL 类型比较特殊,SQL 难优化。如果是一个组合索引,那么这个NULL 类型的字段会极大影响整个索引的效率。此外,NULL 在索引中的处理也是特殊的,也会占用额外的存放空间。
3、优化查询语句
- 分析语句,是否加载了不必要的字段/数据。
- 分析SQl执行计划,是否命中索引等。
- 如果SQL很复杂,优化SQL结构
- 如果表数据量太大,考虑分表
相关文章:

2024.10月22日- MySql的 补充知识点
1、什么是数据库事务? 数据库事务: 是数据库管理系统执行过程中的一个逻辑单位,由一个有限的数据库操作序列构成,这些操作要么全部执行,要么全部不执行,是一个不可分割的工作单位。 2、Mysql事务的四大特性是什么? …...

Java中的对象——生命周期详解
1. 对象的创建 1.1 使用 new 关键字 执行过程:当使用 new 关键字创建对象时,JVM 会为新对象在堆内存中分配一块空间,并调用对应的构造器来初始化对象。 示例代码: MyClass obj new MyClass(); 内存变化:JVM 在堆…...
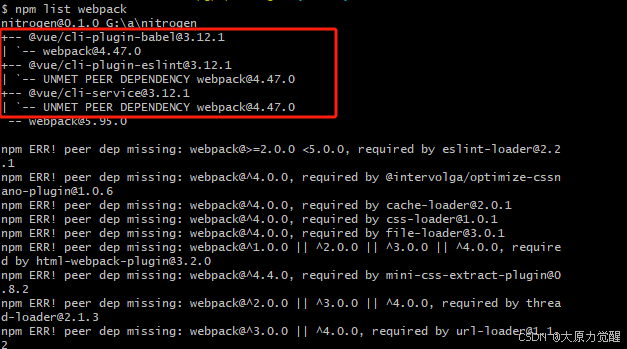
vue文件报Cannot find module ‘webpack/lib/RuleSet‘错误处理
检查 Node.js 版本:这个问题可能与 Node.js 的版本有关。你可以尝试将 Node.js 的版本切换到 12 或更低。如果没有安装 nvm(Node Version Manager),可以通过以下命令安装: curl -o- https://raw.githubusercontent.co…...

第 6 章 机器人系统仿真
对于ROS新手而言,可能会有疑问:学习机器人操作系统,实体机器人是必须的吗?答案是否定的,机器人一般价格不菲,为了降低机器人学习、调试成本,在ROS中提供了系统的机器人仿真实现,通过仿真&#x…...

爬虫——scrapy的基本使用
一,scrapy的概念和流程 1. scrapy的概念 Scrapy是一个Python编写的开源网络爬虫框架。它是一个被设计用于爬取网络数据、提取结构性数据的框架。 框架就是把之前简单的操作抽象成一套系统,这样我们在使用框架的时候,它会自动的帮我们完成很…...
聚类分析算法——K-means聚类 详解
K-means 聚类是一种常用的基于距离的聚类算法,旨在将数据集划分为 个簇。算法的目标是最小化簇内的点到簇中心的距离总和。下面,我们将从 K-means 的底层原理、算法步骤、数学基础、距离度量方法、参数选择、优缺点 和 源代码实现 等角度进行详细解析。…...
【Sublime Text】设置中文 最新最详细
在编程的艺术世界里,代码和灵感需要寻找到最佳的交融点,才能打造出令人为之惊叹的作品。而在这座秋知叶i博客的殿堂里,我们将共同追寻这种完美结合,为未来的世界留下属于我们的独特印记。 【Sublime Text】设置中文 最新最详细 开…...
C++学习路线(二十四)
静态成员函数 类的静态方法: 1.可以直接通过类来访问【更常用】,也可以通过对象(实例)来访问。 2.在类的静态方法中,不能访问普通数据成员和普通成员函数(对象的数据成员和成员函数) 1)静态数据成员 可以直接访问“静态数据成员”对象的成…...

MySQL-存储过程/函数/触发器
文章目录 什么是存储过程存储过程的优缺点存储过程的基本使用存储过程的创建存储过程的调用存储过程的删除存储过程的查看delimiter命令 MySQL中的变量系统变量用户变量局部变量参数 if语句case语句while循环repeat循环loop循环游标cursor捕获异常并处理存储函数触发器触发器概…...
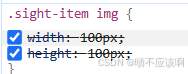
前端页面样式没效果?没应用上?
当我们在开发项目时会有很多个页面、相同的标签,也有可能有相同的class值。样式设置的多了,分不清哪个是当前应用的。我们可以使用网页的开发者工具。 在我们开发的网页中按下f12或: 在打开的工具中我们可以使用元素选择器,单击我…...

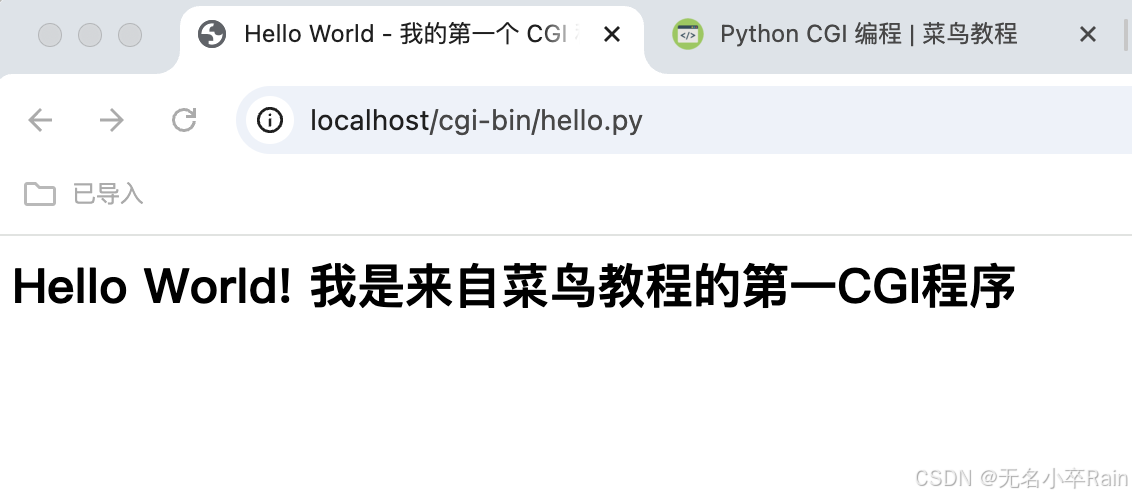
Mac apache配置cgi环境-修改httpd.conf文件、启动apache
Mac自带Apache,配置CGI,分以下几步: 找到httpd.conf。打开终端,编辑以下几处,去掉#或补充内容。在这个路径下写一个测试文件.py格式的,/Library/WebServer/CGI-Executables,注意第一行的python…...
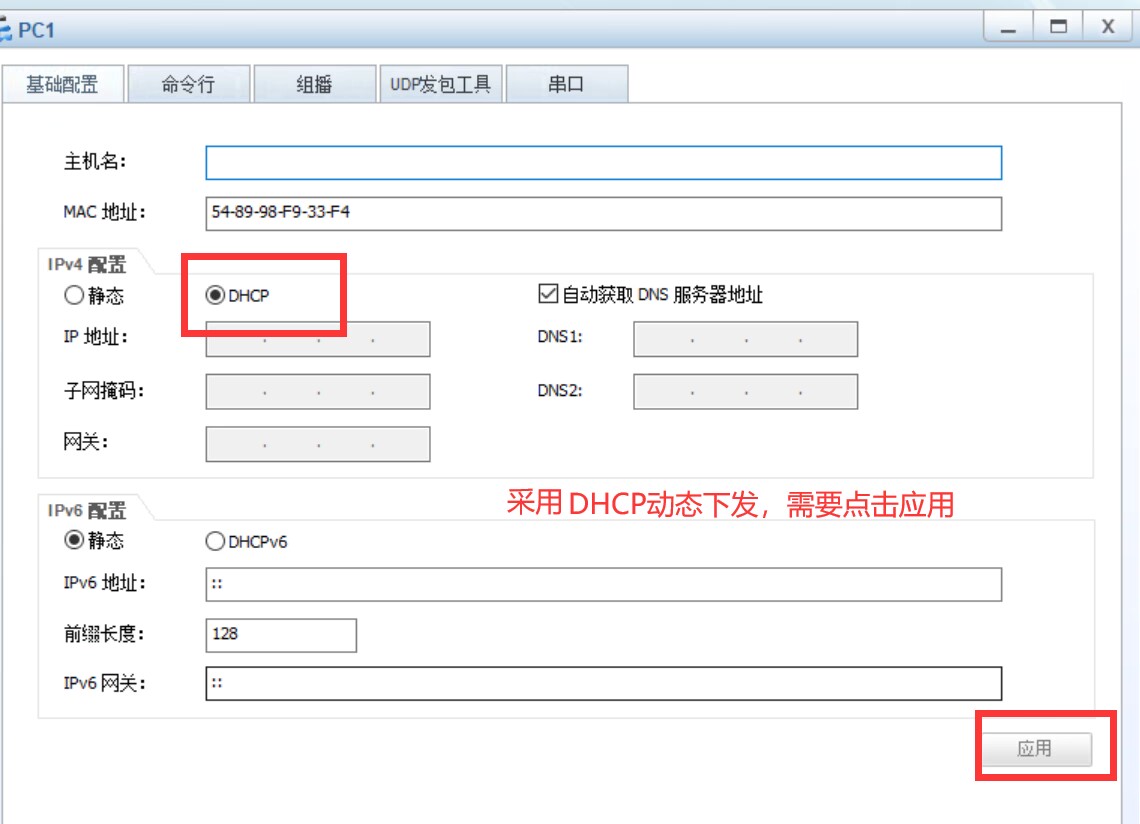
多厂商的实现不同vlan间通信
Cisco单臂路由 Cisco路由器配置 -交换机配置 -pc配置 华三的单臂路由 -路由器配置 -华三的接口默认是打开的 -pc配置及ping的结果 -注意不要忘记配置默认网关 Cisco-SVI -交换机的配置 -创建vlan -> 设置物理接口对应的Acess或Trunk -> 进入vlan接口,打开接…...

sh与bash的区别
sh与bash的区别 结论:对于一般开发者,没有区别;对于要使脚本兼容较老系统,或者兼容其他shell(如ksh,dash),那么意义可能很重大,要确保自己代码没有bash扩展的特性。 区…...

D48【python 接口自动化学习】- python基础之类
day48 练习:开发自动咖啡(上) 学习日期:20241025 学习目标:类 -- 62 小试牛刀:如何开发自动咖啡机?(上) 学习笔记: 案例解析 定义类 定义属性和方法 clas…...

PostgreSQL(WINDOWS)下载、安装、简单使用
下载 PostgreSQL: Downloads PostgreSQL: Windows installers EDB: Open-Source, Enterprise Postgres Database Management 安装 注意密码要方便自己使用,不能忘记。 打开pgAdmin,输入密码 新建数据库 打开命令工具 新建表...

Git的初次使用
一、下载git 找淘宝的镜像去下载比较快 点击这里 二、配置git 1.打开git命令框 2.设置配置 git config --global user.name "你的用名"git config --global user.email "你的邮箱qq.com" 3.制作本地仓库 新建一个文件夹即可,然后在文件夹…...

rocketmq服务的docker启动和配置
rocketmq的默认启动参数占用的内存实在是太大了,小于8G的电脑无法启动,docker中的开发环境又不可能用这么大,通用的该法是改sh文件 修改文件如下 runbroker.sh 默认8G JAVA_OPT"${JAVA_OPT} -server -Xms${Xms} -Xmx${Xmx} -Xmn${Xmn…...

BLE和经典蓝牙相比,有什么优缺点
蓝牙低功耗(Bluetooth Low Energy,简称 BLE)和经典蓝牙(Bluetooth Classic,即 BR/EDR,Basic Rate/Enhanced Data Rate)是蓝牙技术的两种主要模式。两者都有各自的优缺点,具体如下&am…...

ECharts图表图例知识点小结
ECharts 图表图例简述 一、知识点 1. 作用: - 用于标识图表中的不同系列,帮助用户理解图表所展示的数据内容。 2. 位置: - 可以通过配置项设置图例的位置,如 top 、 bottom 、 left 、 right 等。 3. 显示状态控制:…...

Golang 面试经典题:map 的 key 可以是什么类型?哪些不可以?
Golang 面试经典题:map 的 key 可以是什么类型?哪些不可以? 在 Golang 的面试中,map 类型的使用是一个常见的考点,其中对 key 类型的合法性 是一道常被提及的基础却很容易被忽视的问题。本文将带你深入理解 Golang 中…...

MFC内存泄露
1、泄露代码示例 void X::SetApplicationBtn() {CMFCRibbonApplicationButton* pBtn GetApplicationButton();// 获取 Ribbon Bar 指针// 创建自定义按钮CCustomRibbonAppButton* pCustomButton new CCustomRibbonAppButton();pCustomButton->SetImage(IDB_BITMAP_Jdp26)…...

OkHttp 中实现断点续传 demo
在 OkHttp 中实现断点续传主要通过以下步骤完成,核心是利用 HTTP 协议的 Range 请求头指定下载范围: 实现原理 Range 请求头:向服务器请求文件的特定字节范围(如 Range: bytes1024-) 本地文件记录:保存已…...

前端开发面试题总结-JavaScript篇(一)
文章目录 JavaScript高频问答一、作用域与闭包1.什么是闭包(Closure)?闭包有什么应用场景和潜在问题?2.解释 JavaScript 的作用域链(Scope Chain) 二、原型与继承3.原型链是什么?如何实现继承&a…...

html css js网页制作成品——HTML+CSS榴莲商城网页设计(4页)附源码
目录 一、👨🎓网站题目 二、✍️网站描述 三、📚网站介绍 四、🌐网站效果 五、🪓 代码实现 🧱HTML 六、🥇 如何让学习不再盲目 七、🎁更多干货 一、👨…...
)
C++课设:简易日历程序(支持传统节假日 + 二十四节气 + 个人纪念日管理)
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 专栏介绍:《编程项目实战》 目录 一、为什么要开发一个日历程序?1. 深入理解时间算法2. 练习面向对象设计3. 学习数据结构应用二、核心算法深度解析…...

CRMEB 中 PHP 短信扩展开发:涵盖一号通、阿里云、腾讯云、创蓝
目前已有一号通短信、阿里云短信、腾讯云短信扩展 扩展入口文件 文件目录 crmeb\services\sms\Sms.php 默认驱动类型为:一号通 namespace crmeb\services\sms;use crmeb\basic\BaseManager; use crmeb\services\AccessTokenServeService; use crmeb\services\sms\…...

【Android】Android 开发 ADB 常用指令
查看当前连接的设备 adb devices 连接设备 adb connect 设备IP 断开已连接的设备 adb disconnect 设备IP 安装应用 adb install 安装包的路径 卸载应用 adb uninstall 应用包名 查看已安装的应用包名 adb shell pm list packages 查看已安装的第三方应用包名 adb shell pm list…...

比较数据迁移后MySQL数据库和OceanBase数据仓库中的表
设计一个MySQL数据库和OceanBase数据仓库的表数据比较的详细程序流程,两张表是相同的结构,都有整型主键id字段,需要每次从数据库分批取得2000条数据,用于比较,比较操作的同时可以再取2000条数据,等上一次比较完成之后,开始比较,直到比较完所有的数据。比较操作需要比较…...
零知开源——STM32F103RBT6驱动 ICM20948 九轴传感器及 vofa + 上位机可视化教程
STM32F1 本教程使用零知标准板(STM32F103RBT6)通过I2C驱动ICM20948九轴传感器,实现姿态解算,并通过串口将数据实时发送至VOFA上位机进行3D可视化。代码基于开源库修改优化,适合嵌入式及物联网开发者。在基础驱动上新增…...