基于信号分解和多种深度学习结合的上证指数预测模型
大家好,我是带我去滑雪!
为了给投资者提供更准确的投资建议、帮助政府和监管部门更好地制定相关政策,维护市场稳定,本文对股民情绪和上证指数之间的关系进行更深入的研究,并结合信号分解、优化算法和深度学习对上证指数进行预测,以期更好地理解股市的运行规律,为股民提供一定的参考。
选取了2014年12月17日至2024年4月17日的共计2269个交易日(覆盖牛市、熊市及调整期多个市场周期)的上证指数数据,建立了基于信号分解和多种深度学习结合的预测模型。在建模过程中,针对变分模态分解(VMD)参数难以选择的问题,我们利用鲸鱼捕食者算法(MPA)寻优能力强的特点自适应选取VMD的关键参数,使VMD分解效果最大化;针对预测精度问题,我们使用LSTM有效传递和表达经MPA-VMD分解后的上证指数信息,使用双向门控循环单元(BiGRU)模型通过正向和反向传播进行信息的交互和整合,添加注意力机制(Attention)为特征提供更具针对性的权重分配,最大程度上提高预测模型的效率和性能。
最终建立了基于上证指数的VMD-LSTM-BiGRU-Attention预测模型,该模型的拟合优度达到了0.98,而均方根误差(RMSE)、平均绝对误差(MAE)和平均绝对百分比误差(MAPE)也明显优于本文用于比较的其他模型,说明本文模型可为上证指数提供更加精准的预测。不仅如此,在相同VMD-LSTM-BiGRU-Attention模型的条件下,加入情绪指数与上证指数结合进行预测,比单独使用上证指数进行预测的准确率更高。这很好的体现了本文研究股民情绪指数和上证指数之间的关联性是有实际意义的,实现了基于股民情绪与上证指数混合模型的股票走向预测且性能优秀,可用于上证指数的预测分析,对股民及相关研究领域有一定的参考价值和指导作用。
下面开始代码实战:
目录
(1)数据展示
(2)MPA算法优化的VMD分解
(3)预测模型
(4)模型评价指标
(1)数据展示
选取东方财富网2014年12月17日至2024年4月17日的上证指数数据,共计2269个样本,将其划分为训练集和测试集,其中训练集为数据前80%,共计1815个,测试集为数据的后20%,共计454个。利用python将上证指数数据可视化,如图16所示。其中黄色实线为训练集数据,粉色虚线为测试集数据。

(2)MPA算法优化的VMD分解
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
import MPA
from scipy.signal import hilbert
from vmdpy import VMD
f= pd.read_csv('E:\工作\硕士\上证指数.csv',encoding="ANSI")
f=f.收盘
# VMD参数
tau = 0. # noise-tolerance (no strict fidelity enforcement) # 3 modes
DC = 0 # no DC part imposed
init = 1 # initialize omegas uniformly
tol = 1e-7
#MPA设置参数
num_particles = 30 #种群数量
MaxIter = 1000 #最大迭代次数
dim = 10 #维度
lb = -10*np.ones([dim, 1]) #下边界
ub = 10*np.ones([dim, 1])#上边界
# 计算每个IMF分量的包络熵
import numpy as np
from scipy.signal import hilbert
from scipy.stats import kurtosisdef calculate_entropy(imf):# 计算希尔伯特变换的包络线env = np.abs(hilbert(imf))# 归一化包络线env_norm = env / np.max(env)# 计算归一化包络线的概率分布p = env_norm / np.sum(env_norm)# 计算包络熵entropy = -np.sum(p * np.log2(p))# 计算峭度kurt = kurtosis(imf)# 返回包络熵和峭度的和return entropy + kurt# 定义适应度函数,即最大包络熵
def fitness_func(x):if x[1] < 0:x[1] = np.random.choice([3, 12])u, u_hat, omega = VMD(f, int(round(x[0])), tau, int(round(x[1])), DC, init, tol)num_modes = u.shape[0]entropy = np.zeros(num_modes)for i in range(num_modes):entropy[i] = calculate_entropy(u[i,:])# 找到最小的包络熵对应的模态min_entropy_index = np.argmin(entropy)min_entropy_mode = u[min_entropy_index]# print("最小包络熵对应的模态:", min_entropy_index)# x为VMD参数向量# signal为要分解的信号# 分解信号并计算最大包络熵# 返回最大包络熵值return entropy[min_entropy_index]def mpa_optimization(num_particles, dim,fitness_func, MaxIter):# 初始化海洋捕食者位置和速度predators_pos = np.zeros((num_particles, num_dimensions))for i in range(num_particles):predators_pos[i, 0] = np.random.uniform(500, 3000)predators_pos[i, 1] = np.random.uniform(3, 12)predators_vel = np.zeros((num_particles, num_dimensions))# 记录每个海洋捕食者的最佳位置和适应度值predators_best_pos = np.copy(predators_pos)predators_best_fit = np.zeros(num_particles)# 记录整个群体的最佳位置和适应度值global_best_pos = np.zeros(num_dimensions)global_best_fit = float('inf')# 迭代更新for i in range(max_iter):# 计算每个海洋捕食者的适应度值predators_fitness = np.array([fitness_func(p) for p in predators_pos])# 更新每个海洋捕食者的最佳位置和适应度值for j in range(num_particles):if predators_fitness[j] < predators_best_fit[j]:predators_best_fit[j] = predators_fitness[j]predators_best_pos[j] = np.copy(predators_pos[j])# 更新整个群体的最佳位置和适应度值global_best_idx = np.argmin(predators_fitness)if predators_fitness[global_best_idx] < global_best_fit:global_best_fit = predators_fitness[global_best_idx]global_best_pos = np.copy(predators_pos[global_best_idx])# 更新每个海洋捕食者的速度和位置for j in range(num_particles):# 计算新速度r1 = np.random.rand(num_dimensions)r2 = np.random.rand(num_dimensions)cognitive_vel = 2.0 * r1 * (predators_best_pos[j] - predators_pos[j])social_vel = 2.0 * r2 * (global_best_pos - predators_pos[j])predators_vel[j] = predators_vel[j] + cognitive_vel + social_vel# 更新位置predators_pos[j] = predators_pos[j] + predators_vel[j]# 记录每次迭代的global_best_pos和global_best_fitglobal_best_pos_list.append(global_best_pos)global_best_fit_list.append(global_best_fit)print("第:" + str(i) + '次迭代')# 返回全局最优# 返回全局最优位置和适应度值return global_best_pos, global_best_fit# 初始化空列表用于存储每次迭代的global_best_pos和global_best_fit
global_best_pos_list = []
global_best_fit_list = []
# 使用PSO算法优化VMD参数
num_particles = 2
num_dimensions = 2 # 假设有2个VMD参数
max_iter =30
best_pos, best_fit = mpa_optimization(num_particles, dim,fitness_func, MaxIter=max_iter)# 输出结果
print("Best VMD parameters:", best_pos)
print("Best fitness value:", best_fit)得到的最优参数组合和适应度变化曲线如下:

得到的分解序列和中心模态分别为如下所示:


在分解结果中,IMF1显示了一种相对平滑的趋势,可能代表了原始序列中的最低频成分或趋势项。而IMF2显示了略微增加的频率和振幅,但依旧比较平滑,可能捕捉到了次低频的周期性变化。IMF3-IMF7则展示了随着序号增加频率逐渐增高的成分。随着IMF序号的增加,我们可以看到更高频的振荡,这表明它们捕获了原始上证指数序列中的更快变化部分。可认为经MPA优化后的VMD在处理非线性和非平稳信号时具有较好的性能,它能够提取出不同频率范围的振动模态,并具有一定的抗噪能力和平滑性,适用于本文上证指数的分解。
(3)预测模型
根据以上分解过程,VMD将原始上证指数序列分解成多个代表不同频率成分的模态。通过对这些模态分别进行预测,最终可以实现上证指数的预测。本文之后就将基于VMD分解和深度学习结合的方法对上证指数进行预测。为了选取最适合本文上证指数预测的VMD-深度学习模型,在这里我们做了大量实验。首先将上证指数数据集以8:2的比例划分训练集和测试集,用训练集分别训练LSTM单一模型、VMD-LSTM、VMD-LSTM-BiGRU、VMD-LSTM-BiGRU-Attention。碍于篇幅原因,这里以VMD-LSTM-BiGRU-Attention模型为例,展示各个子模态的预测情况如下所示:

通过上面可以发现,VMD-LSTM-BiGRU-Attention模型的各个子模态的预测效果均较好,预测模型能够较好地跟踪和预测多个频率层面上的序列数据。经训练后分别使用了LSTM单一模型、VMD-LSTM、VMD-LSTM-BiGRU、VMD-LSTM-BiGRU-Attention对测试集进行拟合预测,并与实际值进行对比,绘制了不同模型预测效果对比图如下图所示:

部分代码:
from keras import backend as K
from keras.layers import Layerclass Embedding(Layer):def __init__(self, vocab_size, model_dim, **kwargs):self._vocab_size = vocab_sizeself._model_dim = model_dimsuper(Embedding, self).__init__(**kwargs)def build(self, input_shape):self.embeddings = self.add_weight(shape=(self._vocab_size, self._model_dim),initializer='glorot_uniform',name="embeddings")super(Embedding, self).build(input_shape)def call(self, inputs):if K.dtype(inputs) != 'int32':inputs = K.cast(inputs, 'int32')embeddings = K.gather(self.embeddings, inputs)embeddings *= self._model_dim ** 0.5 # Scalereturn embeddingsdef compute_output_shape(self, input_shape):return input_shape + (self._model_dim,)class PositionEncoding(Layer):def __init__(self, model_dim, **kwargs):self._model_dim = model_dimsuper(PositionEncoding, self).__init__(**kwargs)def call(self, inputs):seq_length = inputs.shape[1]position_encodings = np.zeros((seq_length, self._model_dim))for pos in range(seq_length):for i in range(self._model_dim):position_encodings[pos, i] = pos / np.power(10000, (i-i%2) / self._model_dim)position_encodings[:, 0::2] = np.sin(position_encodings[:, 0::2]) # 2iposition_encodings[:, 1::2] = np.cos(position_encodings[:, 1::2]) # 2i+1position_encodings = K.cast(position_encodings, 'float32')return position_encodingsdef compute_output_shape(self, input_shape):return input_shape
class Add(Layer):def __init__(self, **kwargs):super(Add, self).__init__(**kwargs)def call(self, inputs):input_a, input_b = inputsreturn input_a + input_bdef compute_output_shape(self, input_shape):return input_shape[0]class ScaledDotProductAttention(Layer):def __init__(self, masking=True, future=False, dropout_rate=0., **kwargs):self._masking = maskingself._future = futureself._dropout_rate = dropout_rateself._masking_num = -2**32+1super(ScaledDotProductAttention, self).__init__(**kwargs)def mask(self, inputs, masks):masks = K.cast(masks, 'float32')masks = K.tile(masks, [K.shape(inputs)[0] // K.shape(masks)[0], 1])masks = K.expand_dims(masks, 1)outputs = inputs + masks * self._masking_numreturn outputsdef future_mask(self, inputs):diag_vals = tf.ones_like(inputs[0, :, :])tril = tf.linalg.LinearOperatorLowerTriangular(diag_vals).to_dense() future_masks = tf.tile(tf.expand_dims(tril, 0), [tf.shape(inputs)[0], 1, 1])paddings = tf.ones_like(future_masks) * self._masking_numoutputs = tf.where(tf.equal(future_masks, 0), paddings, inputs)return outputsdef call(self, inputs):if self._masking:assert len(inputs) == 4, "inputs should be set [queries, keys, values, masks]."queries, keys, values, masks = inputselse:assert len(inputs) == 3, "inputs should be set [queries, keys, values]."queries, keys, values = inputsif K.dtype(queries) != 'float32': queries = K.cast(queries, 'float32')if K.dtype(keys) != 'float32': keys = K.cast(keys, 'float32')if K.dtype(values) != 'float32': values = K.cast(values, 'float32')matmul = K.batch_dot(queries, tf.transpose(keys, [0, 2, 1])) # MatMulscaled_matmul = matmul / int(queries.shape[-1]) ** 0.5 # Scaleif self._masking:scaled_matmul = self.mask(scaled_matmul, masks) # Mask(opt.)if self._future:scaled_matmul = self.future_mask(scaled_matmul)softmax_out = K.softmax(scaled_matmul) # SoftMax# Dropoutout = K.dropout(softmax_out, self._dropout_rate)outputs = K.batch_dot(out, values)return outputsdef compute_output_shape(self, input_shape):return input_shapeclass MultiHeadAttention(Layer):def __init__(self, n_heads, head_dim, dropout_rate=.1, masking=True, future=False, trainable=True, **kwargs):self._n_heads = n_headsself._head_dim = head_dimself._dropout_rate = dropout_rateself._masking = maskingself._future = futureself._trainable = trainablesuper(MultiHeadAttention, self).__init__(**kwargs)def build(self, input_shape):self._weights_queries = self.add_weight(shape=(input_shape[0][-1], self._n_heads * self._head_dim),initializer='glorot_uniform',trainable=self._trainable,name='weights_queries')self._weights_keys = self.add_weight(shape=(input_shape[1][-1], self._n_heads * self._head_dim),initializer='glorot_uniform',trainable=self._trainable,name='weights_keys')self._weights_values = self.add_weight(shape=(input_shape[2][-1], self._n_heads * self._head_dim),initializer='glorot_uniform',trainable=self._trainable,name='weights_values')super(MultiHeadAttention, self).build(input_shape)def call(self, inputs):if self._masking:assert len(inputs) == 4, "inputs should be set [queries, keys, values, masks]."queries, keys, values, masks = inputselse:assert len(inputs) == 3, "inputs should be set [queries, keys, values]."queries, keys, values = inputsqueries_linear = K.dot(queries, self._weights_queries) keys_linear = K.dot(keys, self._weights_keys)values_linear = K.dot(values, self._weights_values)queries_multi_heads = tf.concat(tf.split(queries_linear, self._n_heads, axis=2), axis=0)keys_multi_heads = tf.concat(tf.split(keys_linear, self._n_heads, axis=2), axis=0)values_multi_heads = tf.concat(tf.split(values_linear, self._n_heads, axis=2), axis=0)if self._masking:att_inputs = [queries_multi_heads, keys_multi_heads, values_multi_heads, masks]else:att_inputs = [queries_multi_heads, keys_multi_heads, values_multi_heads]attention = ScaledDotProductAttention(masking=self._masking, future=self._future, dropout_rate=self._dropout_rate)att_out = attention(att_inputs)outputs = tf.concat(tf.split(att_out, self._n_heads, axis=0), axis=2)return outputsdef compute_output_shape(self, input_shape):return input_shapedef build_model(X_train,mode='LSTM',hidden_dim=[32,16]):set_my_seed()if mode=='RNN':#RNNmodel = Sequential()model.add(SimpleRNN(hidden_dim[0],return_sequences=True, input_shape=(X_train.shape[-2],X_train.shape[-1])))model.add(SimpleRNN(hidden_dim[1])) model.add(Dense(1))elif mode=='MLP':model = Sequential()model.add(Dense(hidden_dim[0],activation='relu',input_shape=(X_train.shape[-1],)))model.add(Dense(hidden_dim[1],activation='relu'))model.add(Dense(1))elif mode=='LSTM':# LSTMmodel = Sequential()model.add(LSTM(hidden_dim[0],return_sequences=True, input_shape=(X_train.shape[-2],X_train.shape[-1])))model.add(LSTM(hidden_dim[1]))model.add(Dense(1))elif mode=='GRU':#GRUmodel = Sequential()model.add(GRU(hidden_dim[0],return_sequences=True, input_shape=(X_train.shape[-2],X_train.shape[-1])))model.add(GRU(hidden_dim[1]))model.add(Dense(1))elif mode=='CNN':#一维卷积model = Sequential()model.add(Conv1D(hidden_dim[0],17,activation='relu',input_shape=(X_train.shape[-2],X_train.shape[-1])))model.add(GlobalAveragePooling1D())model.add(Flatten())model.add(Dense(hidden_dim[1],activation='relu'))model.add(Dense(1))elif mode=='CNN+LSTM': model = Sequential()model.add(Conv1D(filters=hidden_dim[0], kernel_size=3, padding="same",activation="relu"))model.add(MaxPooling1D(pool_size=2))model.add(LSTM(hidden_dim[1]))model.add(Dense(1))elif mode=='BiLSTM':model = Sequential()model.add(Bidirectional(LSTM(hidden_dim[0],return_sequences=True, input_shape=(X_train.shape[-2],X_train.shape[-1]))))model.add(Bidirectional(LSTM(hidden_dim[1])))model.add(Dense(1))elif mode=='BiGRU':model = Sequential()model.add(Bidirectional(GRU(hidden_dim[0],return_sequences=True, input_shape=(X_train.shape[-2],X_train.shape[-1]))))model.add(Bidirectional(GRU(hidden_dim[1])))model.add(Dense(1))elif mode=='BiLSTM+Attention':inputs = Input(name='inputs',shape=[X_train.shape[-2],X_train.shape[-1]], dtype='float64')attention_probs = Dense(32, activation='softmax', name='attention_vec')(inputs)attention_mul = Multiply()([inputs, attention_probs])mlp = Dense(64)(attention_mul) #原始的全连接gru=Bidirectional(LSTM(32))(mlp)mlp = Dense(16,activation='relu')(gru)output = Dense(1)(mlp)model = Model(inputs=[inputs], outputs=output)elif mode=='Attention':inputs = Input(name='inputs',shape=[X_train.shape[-2],X_train.shape[-1]], dtype='float32')attention_probs = Dense(hidden_dim[0], activation='softmax', name='attention_vec')(inputs)attention_mul = Multiply()([inputs, attention_probs])mlp = Dense(hidden_dim[1])(attention_mul) #原始的全连接fla=Flatten()(mlp)output = Dense(1)(fla)model = Model(inputs=[inputs], outputs=output) elif mode=='BiGRU+Attention':inputs = Input(name='inputs',shape=[X_train.shape[-2],X_train.shape[-1]], dtype='float64')attention_probs = Dense(32, activation='softmax', name='attention_vec')(inputs)attention_mul = Multiply()([inputs, attention_probs])mlp = Dense(64)(attention_mul) #原始的全连接gru=Bidirectional(GRU(32))(mlp)mlp = Dense(16,activation='relu')(gru)output = Dense(1)(mlp)model = Model(inputs=[inputs], outputs=output)elif mode=='MultiHeadAttention': inputs = Input(shape=[X_train.shape[-2],X_train.shape[-1]], name="inputs")#masks = Input(shape=(X_train.shape[-2],), name='masks')encodings = PositionEncoding(X_train.shape[-2])(inputs)encodings = Add()([inputs, encodings])x = MultiHeadAttention(8, hidden_dim[0],masking=False)([encodings, encodings, encodings])x = GlobalAveragePooling1D()(x)x = Dropout(0.2)(x)x = Dense(hidden_dim[1], activation='relu')(x)outputs = Dense(1)(x)model = Model(inputs=[inputs], outputs=outputs)elif mode=='BiGRU+MAttention': inputs = Input(shape=[X_train.shape[-2],X_train.shape[-1]], name="inputs")encodings = PositionEncoding(X_train.shape[-2])(inputs)encodings = Add()([inputs, encodings])x = MultiHeadAttention(8, hidden_dim[0],masking=False)([encodings, encodings, encodings])
# x = GlobalAveragePooling1D()(x)x = Bidirectional(GRU(32))(x)x = Dropout(0.2)(x)output = Dense(1)(x)model = Model(inputs=[inputs], outputs=output)# elif mode=='BiGRU+Attention':
# inputs = Input(name='inputs',shape=[max_words,], dtype='float64')
# x = Embedding(top_words, input_length=max_words, output_dim=embed_dim)(inputs)
# x = Bidirectional(GRU(32,return_sequences=True))(x)
# x = MultiHeadAttention(2, key_dim=embed_dim)(x,x,x)
# x = Bidirectional(GRU(32))(x)
# x = Dropout(0.2)(x)
# output = Dense(num_labels, activation='softmax')(x)
# model = Model(inputs=[inputs], outputs=output)model.compile(optimizer='Adam', loss='mse',metrics=[tf.keras.metrics.RootMeanSquaredError(),"mape","mae"])return modeldef plot_loss(hist,imfname):plt.subplots(1,4,figsize=(16,2), dpi=600)for i,key in enumerate(hist.history.keys()):n=int(str('14')+str(i+1))plt.subplot(n)plt.plot(hist.history[key], 'k', label=f'Training {key}')plt.title(f'{imfname} Training {key}')plt.xlabel('Epochs')plt.ylabel(key)plt.legend()plt.tight_layout()plt.show()(4)模型评价指标
为了直观展示结果,绘制评价指标柱状图。如下图所示:

需要数据集的家人们可以去百度网盘(永久有效)获取:
链接:https://pan.baidu.com/s/16Pp57kAbC3xAqPylyfQziA?pwd=2138
提取码:2138
更多优质内容持续发布中,请移步主页查看。
点赞+关注,下次不迷路!
相关文章:
基于信号分解和多种深度学习结合的上证指数预测模型
大家好,我是带我去滑雪! 为了给投资者提供更准确的投资建议、帮助政府和监管部门更好地制定相关政策,维护市场稳定,本文对股民情绪和上证指数之间的关系进行更深入的研究,并结合信号分解、优化算法和深度学习对上证指数…...

基于Spring Boot的酒店住宿管理平台
1系统概述 1.1 研究背景 随着计算机技术的发展以及计算机网络的逐渐普及,互联网成为人们查找信息的重要场所,二十一世纪是信息的时代,所以信息的管理显得特别重要。因此,使用计算机来管理酒店客房管理系统的相关信息成为必然。开发…...

游聚对战平台 三国战纪2012CE修改器修改地址
游聚对战平台 三国战纪2012比较全的一次地址。 工具 ce修改器 自行百度下载 1袖箭 2褐色鸡蛋 3毒堂 4飞盘 5火焰弹 6绿色鸡蛋 7金珠 8毒蝎 9毒镖 10铁莲花 11张陵剑 12张角巾 13太清丹经 14黄石公 15九节杖 16隐身衣 17神仙笔 18 玉蜂术(效果不明)19天师…...

Qt Creator中的项目栏
shadow build: [基础]Qt Creator 的 Shadow build(影子构建)-CSDN博客 影子构建:将源码路径和构建路径分开(生成的makefile文件和其他产物都不放到源码路径),以此来保证源码路径的清洁。 实验1: 我创建了两个项目:…...

keepalived+web 实现双机热备
环境:利用keeplived实现web服务器的双机热备(高可用) 注意: (1) 利用keeplivedweb做双击热备(高可用),最少需要两台服务器,可以实现多域名对应一个VIP,并且访问不同域名,显示不同主页…...

关于python的import
在Python中,import语句用于导入其他模块或模块中的特定部分,以便在代码中使用它们。这就可以重用代码,而不是每次都从头开始编写所有的功能。 基本用法 导入整个模块: import module_name 例如: import math print(…...

帕金森后期吞咽困难:破解难题,重拾生活美味!
在这个快节奏的时代,健康成为了我们最宝贵的财富。然而,对于帕金森病患者及其家庭而言,随着病情的进展,尤其是进入后期阶段,吞咽困难成为了他们不得不面对的严峻挑战。今天,就让我们一起走进这个温暖而坚韧…...

android 添加USB网卡并配置DNS
工作需要,需要使用TBox分享的网络,Android将TBox当作一个USB网卡,接下来就简单了,配置这个网卡的信息即可。 加载默认网卡的信息在frameworks/opt/net/ethernet/java/com/android/server/ethernet/EthernetTracker.java中 Ethern…...

【面试经典150】day 8
#1024程序员节 | 征文# 作为一个未来的程序员,现在我要继续刷题了。 力扣时刻。 目录 1.接雨水 2.罗马数字转整数 3.最后一个单词的长度 4.最长公共前缀 5.反转字符串中的单词 1.接雨水 好好好好好好,一开始就接雨水。我记得接了n次了。。。 痛苦战…...

Python -- 网络爬虫
Python – 网络爬虫 流程: 1. 连接链接获取页面内容(html文件); 2. 过滤获取需要信息(正则) [可能重复步骤1,2] ; 3. 存储文件到本地。一)网络连接获取页面内容 # 网络…...

【英特尔IA-32架构软件开发者开发手册第3卷:系统编程指南】2001年版翻译,2-5
文件下载与邀请翻译者 学习英特尔开发手册,最好手里这个手册文件。原版是PDF文件。点击下方链接了解下载方法。 讲解下载英特尔开发手册的文章 翻译英特尔开发手册,会是一件耗时费力的工作。如果有愿意和我一起来做这件事的,那么ÿ…...
)
设计模式4 适配器 (adapter)
一句话,适配器按照客户的需求, 适配当前已有的接口。 目标接口:reqeust() public interface Target {void request(); //this is client needed interface }已有接口:specificRequest package com.example.adapter;import android.uti…...

《分布式机器学习模式》:解锁分布式ML的实战宝典
在大数据和人工智能时代,机器学习已经成为推动技术进步的重要引擎。然而,随着数据量的爆炸性增长和模型复杂度的提升,单机环境下的机器学习已经难以满足实际需求。因此,将机器学习应用迁移到分布式系统上,成为了一个不…...

【项目实战】HuggingFace初步实战,使用HF做一些小型任务
Huggingface初步实战 一、前期准备工作二、学习pipline2.1.试运行代码,使用HuggingFace下载模型2.2. 例子1,情感检测分析(只有积极和消极两个状态)2.3. 例子2,文本生成 三、学会使用Tokenizer & Model3.1.tokenizer(分词器&am…...

堆的应用——堆排序和TOP-K问题
1.堆排序 想法⼀: 基于已有数组建堆、取堆顶元素完成排序。也就是利用写好的堆数据结构(之前的文章有讲解),去实现排序。 void HeapSort(int* a, int n){HP hp;for(int i 0; i < n; i){HPPush(&hp,a[i]);}int i 0;whi…...

探秘 MySQL 数据类型的艺术:性能与存储的精妙平衡
文章目录 前言🎀一、数据类型分类🎀二、整数类型(举例 TINYINT 和 INT )🎫2.1 TINYINT 和 INT 类型的定义2.1.1 TINYINT2.1.2 INT 🎫2.2 表的操作示例2.2.1 创建包含 TINYINT 和 INT 类型的表2.2.2 插入数据…...

使用任意绘图软件自学并结合上课所学内容完成数据库原理图绘制
本次绘图采用亿图图示软件...

static、 静态导入、成员变量的初始化、单例模式、final 常量(Content)、嵌套类、局部类、抽象类、接口、Lambda、方法引用
static static 常用来修饰类的成员:成员变量、方法、嵌套类 成员变量 被static修饰:类变量、成员变量、静态字段 在程序中只占用一段固定的内存(存储在方法区),所有对象共享可以通过实例、类访问 (一般用类名访问和修…...

基于SSM的智能养生平台管理系统源码带本地搭建教程
技术栈与架构 技术框架:采用SSM(Spring Spring MVC MyBatis)作为后端开发框架,结合前端技术栈layui、JSP、Bootstrap与jQuery,以及数据库MySQL 5.7,共同构建项目。 运行环境:项目在JDK 8环境…...

Latex中文排版字体和字号
中文排版 最近常用latex排版,也遇到了很多问题。这里对于主要的参考文章做一个总结和推荐。 一份不太简短的 LaTeX2ε 介绍【中文资料】ctex宏包用户手册,用户手册使用 命令行texdoc ctex 这两个文档都是中文的,而且几乎解决了我90%的排版…...

IoT/HCIP实验-3/LiteOS操作系统内核实验(任务、内存、信号量、CMSIS..)
文章目录 概述HelloWorld 工程C/C配置编译器主配置Makefile脚本烧录器主配置运行结果程序调用栈 任务管理实验实验结果osal 系统适配层osal_task_create 其他实验实验源码内存管理实验互斥锁实验信号量实验 CMISIS接口实验还是得JlINKCMSIS 简介LiteOS->CMSIS任务间消息交互…...

学习STC51单片机32(芯片为STC89C52RCRC)OLED显示屏2
每日一言 今天的每一份坚持,都是在为未来积攒底气。 案例:OLED显示一个A 这边观察到一个点,怎么雪花了就是都是乱七八糟的占满了屏幕。。 解释 : 如果代码里信号切换太快(比如 SDA 刚变,SCL 立刻变&#…...

Mac下Android Studio扫描根目录卡死问题记录
环境信息 操作系统: macOS 15.5 (Apple M2芯片)Android Studio版本: Meerkat Feature Drop | 2024.3.2 Patch 1 (Build #AI-243.26053.27.2432.13536105, 2025年5月22日构建) 问题现象 在项目开发过程中,提示一个依赖外部头文件的cpp源文件需要同步,点…...

云原生安全实战:API网关Kong的鉴权与限流详解
🔥「炎码工坊」技术弹药已装填! 点击关注 → 解锁工业级干货【工具实测|项目避坑|源码燃烧指南】 一、基础概念 1. API网关(API Gateway) API网关是微服务架构中的核心组件,负责统一管理所有API的流量入口。它像一座…...
 + 力扣解决)
LRU 缓存机制详解与实现(Java版) + 力扣解决
📌 LRU 缓存机制详解与实现(Java版) 一、📖 问题背景 在日常开发中,我们经常会使用 缓存(Cache) 来提升性能。但由于内存有限,缓存不可能无限增长,于是需要策略决定&am…...

Git 3天2K星标:Datawhale 的 Happy-LLM 项目介绍(附教程)
引言 在人工智能飞速发展的今天,大语言模型(Large Language Models, LLMs)已成为技术领域的焦点。从智能写作到代码生成,LLM 的应用场景不断扩展,深刻改变了我们的工作和生活方式。然而,理解这些模型的内部…...

Spring Security 认证流程——补充
一、认证流程概述 Spring Security 的认证流程基于 过滤器链(Filter Chain),核心组件包括 UsernamePasswordAuthenticationFilter、AuthenticationManager、UserDetailsService 等。整个流程可分为以下步骤: 用户提交登录请求拦…...
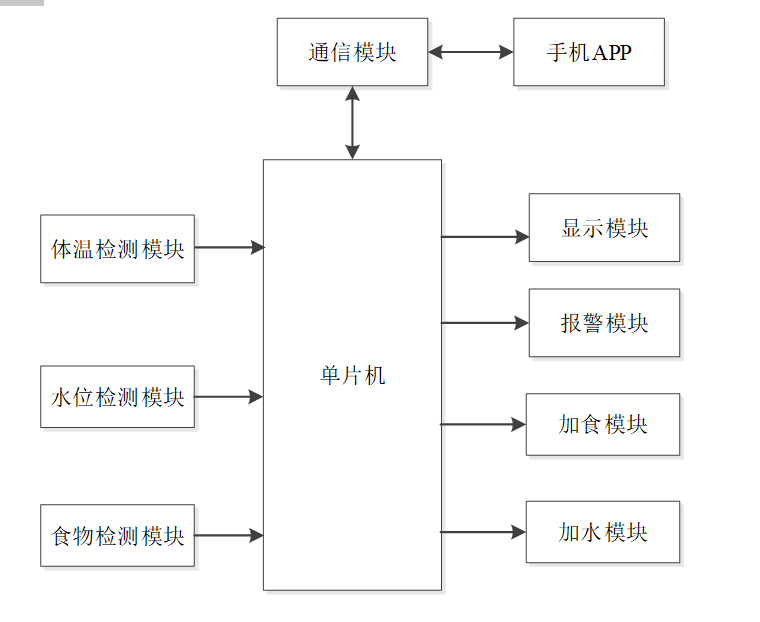
基于单片机的宠物屋智能系统设计与实现(论文+源码)
本设计基于单片机的宠物屋智能系统核心是实现对宠物生活环境及状态的智能管理。系统以单片机为中枢,连接红外测温传感器,可实时精准捕捉宠物体温变化,以便及时发现健康异常;水位检测传感器时刻监测饮用水余量,防止宠物…...

UE5 音效系统
一.音效管理 音乐一般都是WAV,创建一个背景音乐类SoudClass,一个音效类SoundClass。所有的音乐都分为这两个类。再创建一个总音乐类,将上述两个作为它的子类。 接着我们创建一个音乐混合类SoundMix,将上述三个类翻入其中,通过它管理每个音乐…...
C++中vector类型的介绍和使用
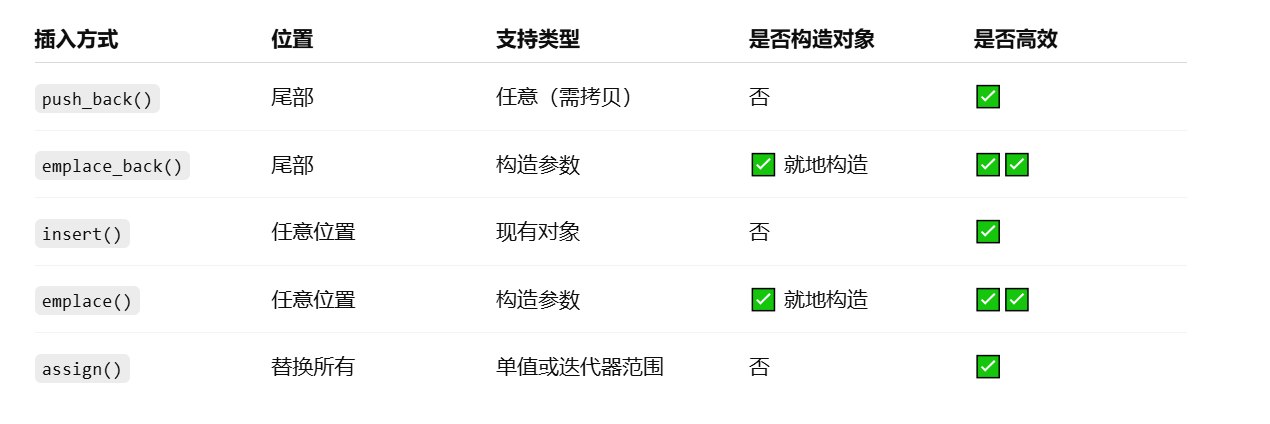
文章目录 一、vector 类型的简介1.1 基本介绍1.2 常见用法示例1.3 常见成员函数简表 二、vector 数据的插入2.1 push_back() —— 在尾部插入一个元素2.2 emplace_back() —— 在尾部“就地”构造对象2.3 insert() —— 在任意位置插入一个或多个元素2.4 emplace() —— 在任意…...