关于算法的时间复杂度和空间复杂度的分析
由于最近开始准备蓝桥杯(python组),开始对编程基础进行一些复习,当我发现蓝桥对大多数题目程序运行时间及大小有要求时,我知道我不得不考虑性能问题,而不是能跑就行🤓
写下这篇文章希望对其他同志有帮助吧
什么是算法的时间复杂度和空间复杂度
算法(Algorithm)是指用来操作数据、解决程序问题的一组方法。衡量不同算法的优劣,主要还是根据算法所占的空间和时间两个维度去考虑。一个问题总有无数种解决办法,对于同一个问题,我们可以使用不同的方法去解决,但使用不同算法所耗费的资源和时间不同。
世界上没有完全完美的东西,也没有最合适你的女孩,不存在既不消耗最多的时间,也不占用最多的空间的完美无瑕的程序,鱼和熊掌不可得兼,那么就需要我们从中去寻找一个平衡点,写出能出色解决问题的较为完美的代码。
时间维度
时间维度指执行当前算法所消耗的时间,通常用时间复杂度来描述,算法执行时间需通过依据该算法编制的程序在计算机上运行时所消耗的时间来度量。度量一个程序的执行时间通常有两种方法:
事后统计法
该方法有两个缺陷:一是要想对设计的算法的运行性能进行评测,必须先依据算法编制相应的程序并实际运行;二是所得时间的统计量依赖于计算机的硬件、软件等环境因素,有时容易掩盖算法本身的优势。
事前分析法
程序运行前,对算法进行估算。程序运行时所消耗的时间取决于:算法采用的策略、方法;编译产生的代码质量;问题的输入规模;计算机硬件执行的速度。
时间频度
程序执行所耗费的时间,从理论上是不能算出来的,必须实际运行测试才能知道。
一个算法中的语句执行次数称为语句频度或时间频度T(n),它只是一个估计值,一个算法花费的时间与算法中语句的执行次数成正比例,哪个算法中语句执行次数多,它花费时间就多。
时间复杂度
在计算机科学中,时间复杂度是一个描述算法运行时间如何随着输入数据规模变化的度量。它是对算法运行时间增长趋势的一种抽象表示。
在时间频度中,n称为问题的规模,当n不断变化时,时间频度T(n)也会不断变化。如果想知道它变化时呈现什么规律时,需要引入时间复杂度概念。 一般情况下,算法中基本操作重复执行的次数是问题规模n的某个函数,用T(n)表示,若有某个辅助函数f(n),使得当n趋近于无穷大时,T(n)/f(n)的极限值为不等于零的常数,则称f(n)是T(n)的同数量级函数。记作T(n)=O(f(n)),称O(f(n)) 为算法的渐进时间复杂度,简称时间复杂度。
常见时间复杂度量级
O(1) - 常数时间复杂度
这种复杂度表示算法的运行时间不随输入数据的大小而改变。
def constant_time_function(x): return x * 2 # 这是一个常数时间操作 # 无论x的值是多少,这个函数都只需要一个固定的时间来完成O(n) - 线性时间复杂度
这种复杂度表示算法的运行时间与输入数据的大小成正比。
def linear_time_function(arr): total = 0 for num in arr: # 遍历数组中的每个元素 total += num # 这是一个常数时间操作 return total # 如果arr的长度为n,则这个函数需要n个时间单位来完成O(n^2) - 二次时间复杂度
这种复杂度表示算法的运行时间与输入数据大小的平方成正比。
def linear_time_function(arr): total = 0 for num in arr: # 遍历数组中的每个元素 total += num # 这是一个常数时间操作 return total # 如果arr的长度为n,则这个函数需要n个时间单位来完成O(log n) - 对数时间复杂度
这种复杂度通常出现在基于分治的算法中,如二分查找。
def linear_time_function(arr): total = 0 for num in arr: # 遍历数组中的每个元素 total += num # 这是一个常数时间操作 return total # 如果arr的长度为n,则这个函数需要n个时间单位来完成O(n log n) - 线性对数时间复杂度
这种复杂度通常出现在排序算法中,如归并排序和快速排序(在平均情况下)。
# 这个过程的时间复杂度为O(n log n)。快速排序也类似,通过选择一个基准元素并将数组分成两部分, # 然后递归地对两部分进行排序,其平均时间复杂度也是O(n log n)。 def merge_sort(lst):if len(lst) <= 1:return lst mid = len(lst) // 2left_half = merge_sort(lst[:mid])right_half = merge_sort(lst[mid:]) return merge(left_half, right_half) def merge(left, right):merged = []left_index = 0right_index = 0 while left_index < len(left) and right_index < len(right):if left[left_index] < right[right_index]:merged.append(left[left_index])left_index += 1else:merged.append(right[right_index])right_index += 1 merged += left[left_index:]merged += right[right_index:] return merged lst = [38, 27, 43, 3, 9, 82, 10] print(merge_sort(lst)) # 输出:[3, 9, 10, 27, 38, 43, 82]O(2^n) - 指数时间复杂度
这种复杂度表示算法的运行时间随输入数据的大小呈指数级增长,通常出现在递归算法中,且没有适当的剪枝或记忆化。
def exponential_time_function(n): if n == 0: return 1 else: return 2 * exponential_time_function(n - 1) # 每次递归调用都会使问题规模减半,但总时间呈指数增长 # 对于一个输入n,这个函数的时间复杂度为O(2^n)
空间复杂度
空间复杂度是对在运行过程中临时占用存储空间大小的一个量度,同样反映的是一个趋势
关于空间复杂度 S(n) 的讨论,一个算法的空间复杂度(Space Complexity)S(n)定义为该算法所耗费的存储空间,空间复杂度并不是程序占用了多少bytes的空间,因为这个也没有太大意义,空间复杂度算的是变量的个数。空间复杂度计算规则基本跟时间复杂度类似,也使用大O渐进表示法。它也是问题规模n的函数。渐近空间复杂度也常常简称为空间复杂度。
常见空间复杂度
常数空间 O(1)*O*(1):
空间需求是固定的,不随输入规模变化。例如,交换两个数的值:
def swap(a, b):temp = aa = bb = tempreturn a, b print(swap(1, 2)) # 输出:(2, 1)线性空间 O(n)*O*(*n*):
空间需求与输入规模线性相关。例如,创建一个与输入规模大小相同的新列表:
def swap(a, b):temp = aa = bb = tempreturn a, b print(swap(1, 2)) # 输出:(2, 1)二次空间 O(n2)*O*(*n*2):
空间需求与输入规模的平方成正比。例如,创建一个 n×nn×n 的二维数组:
def swap(a, b):temp = aa = bb = tempreturn a, b print(swap(1, 2)) # 输出:(2, 1)
时间复杂度和空间复杂度的计算
时间复杂度计算
时间复杂度是衡量算法执行时间随输入数据规模增长而变化的快慢程度的指标。它通常表示为输入数据规模n的函数,即T(n)。算法的时间复杂度越低,表示它在处理大规模数据时所需的执行时间越短,效率越高。
识别基本操作:
-
基本操作是算法中执行次数最多的操作,它通常是算法的核心部分,决定了算法的整体性能。
-
在分析时,需要关注循环、递归等可能导致操作次数大量增加的部分。
计算执行次数:
-
对于单层循环,执行次数通常是输入数据规模n的线性函数,即O(n)。
-
对于嵌套循环,需要分别计算每一层循环的迭代次数,并将它们相乘得到总执行次数。例如,两层嵌套循环的执行次数通常为O(n^2)。
-
对于递归算法,需要分析递归调用的次数和递归深度,以及每次递归调用中的操作次数。
应用大O表示法:
-
大O表示法用于简化执行次数的表达式,只保留最高阶项,并忽略系数和常数项。这是因为当n足够大时,高阶项的增长速度将远远超过低阶项和常数项。
-
例如,如果执行次数为3n2)。
考虑最坏情况:
-
在分析时间复杂度时,通常考虑最坏情况,即输入数据使得算法执行时间最长的情况。这是因为最坏情况给出了算法性能的上界,有助于评估算法在最不利条件下的表现。
示例分析:
-
线性搜索:在最坏情况下,需要遍历整个数组才能找到目标元素,因此时间复杂度为O(n)。
-
二分搜索:在有序数组中查找元素时,每次将搜索范围减半,因此时间复杂度为O(log n)。
-
冒泡排序:通过相邻元素的比较和交换进行排序,每趟排序都会将最大的元素移动到数组的末尾。在最坏情况下,需要进行n-1趟排序,每趟排序的比较次数为n-i(i为当前趟数),因此总时间复杂度为O(n^2)。
-
归并排序:将数组分成两半分别排序,然后合并结果。每次合并的复杂度为O(n),递归深度为log n,因此总时间复杂度为O(n log n)。
空间复杂度的计算
分析存储需求:
-
包括算法中定义的局部变量、数组、链表、栈、队列等数据结构所占用的空间。
-
注意区分输入数据所占用的空间和算法执行过程中产生的临时空间。输入数据所占用的空间通常不计入空间复杂度。
计算空间总量:
-
根据算法的执行过程,计算所需存储空间的总量。这包括所有局部变量和临时数据结构所占用的空间。
-
如果空间使用量与输入数据规模成正比,则空间复杂度为O(n)等。
应用大O表示法:
-
与时间复杂度类似,使用大O表示法来简化空间总量的表达式。只保留最高阶项,并忽略系数和常数项。
考虑递归栈空间:
-
对于递归算法,需要考虑递归栈的深度。递归栈空间用于存储递归调用过程中的局部变量和返回地址等信息。
-
如果递归深度与输入数据规模成正比,则空间复杂度为O(n)。如果递归深度是固定的(如二分搜索),则空间复杂度为O(1)(不考虑系统栈空间)。
示例分析:
-
常数空间:如果算法只使用固定数量的额外空间(如几个变量),则空间复杂度为O(1)。
-
线性空间:如果算法使用与输入数据规模成正比的额外空间(如一个长度为n的数组),则空间复杂度为O(n)。
-
递归空间:对于递归算法,如果递归深度与输入数据规模成正比(如递归求解斐波那契数列),则空间复杂度为O(n)。如果递归深度是固定的(如二分搜索),则空间复杂度为O(1)(不考虑系统栈空间)。但需要注意的是,在实际应用中,系统栈空间也是有限的,因此过深的递归可能会导致栈溢出错误。
写在最后:
区分不同情况:时间复杂度和空间复杂度通常考虑最坏情况,但也可以分析最好情况和平均情况。最好情况和平均情况可能给出更准确的算法性能评估,但在某些情况下(如在线算法或实时系统),最坏情况可能更为重要。
考虑常数项和系数:虽然大O表示法忽略了常数项和系数,但在实际应用中,它们可能对算法性能有显著影响。特别是在处理小规模数据时,低阶项和系数可能占据主导地位。因此,在评估算法性能时,需要综合考虑时间复杂度和空间复杂度以及常数项和系数的影响。
综合评估:在选择算法时,除了时间复杂度和空间复杂度外,还需要考虑算法的稳定性、可读性、可维护性等因素。一个优秀的算法应该在这些方面都有良好的表现。
相关文章:

关于算法的时间复杂度和空间复杂度的分析
由于最近开始准备蓝桥杯(python组),开始对编程基础进行一些复习,当我发现蓝桥对大多数题目程序运行时间及大小有要求时,我知道我不得不考虑性能问题,而不是能跑就行🤓 写下这篇文章希望对其他同志有帮助吧 什么是算法…...

深入浅出 C++ STL:解锁高效编程的秘密武器
引言 C 标准模板库(STL)是现代 C 的核心部分之一,为开发者提供了丰富的预定义数据结构和算法,极大地提升了编程效率和代码的可读性。理解和掌握 STL 对于 C 开发者来说至关重要。以下是对 STL 的详细介绍,涵盖其基础知…...

2024年1024程序人生总结
2024-1024 0.大环境0.1.经济0.2.战争 1.我的程序人生1.1.游戏 2.节日祝福 0.大环境 今年的1024最大的感触就是没有节日氛围,往年公司还会准备节日礼物,今年没有,由此可见大环境有多么糟糕。 除此之外,就是到公司应聘的程序员越来…...

【p2p、分布式,区块链笔记 分布式容错算法】: 拜占庭将军问题+实用拜占庭容错算法PBFT
papercodehttps://pmg.csail.mit.edu/papers/osdi99.pdfhttps://github.com/luckydonald/pbft 其他相关实现:This is an implementation of the Pracltical Byzantine Fault Tolerance protocol using PythonAn implementation of the PBFT consensus algorithm us…...
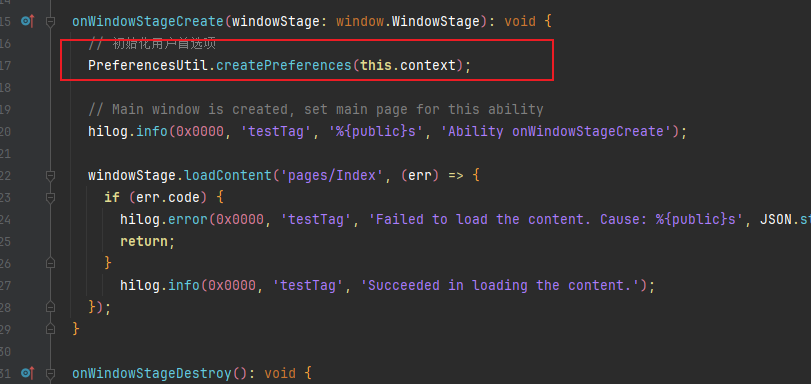
鸿蒙NEXT开发-应用数据持久化之用户首选项(基于最新api12稳定版)
注意:博主有个鸿蒙专栏,里面从上到下有关于鸿蒙next的教学文档,大家感兴趣可以学习下 如果大家觉得博主文章写的好的话,可以点下关注,博主会一直更新鸿蒙next相关知识 专栏地址: https://blog.csdn.net/qq_56760790/…...

人工智能_神经网络103_感知机_感知机工作原理_感知机具备学习能力_在学习过程中自我调整权重_优化效果_多元线性回归_逻辑回归---人工智能工作笔记0228
由于之前一直对神经网络不是特别清楚,尤其是对神经网络中的一些具体的概念,包括循环,神经网络卷积神经网络以及他们具体的作用,都是应用于什么方向不是特别清楚,所以现在我们来做教程来具体明确一下。 当然在机器学习之后还有深度学习,然后在深度学习中对各种神经网络的…...

WISE:重新思考大语言模型的终身模型编辑与知识记忆机制
论文地址:https://arxiv.org/abs/2405.14768https://arxiv.org/abs/2405.14768 1. 概述 随着世界知识的不断变化,大语言模型(LLMs)需要及时更新,纠正其生成的虚假信息或错误响应。这种持续的知识更新被称为终身模型编…...

网络安全证书介绍
网络安全领域有很多专业的证书,可以帮助你提升知识和技能,增强在这个行业中的竞争力。以下是一些常见的网络安全证书: 1. CompTIA Security 适合人群:初级安全专业人员证书内容:基础的网络安全概念和实践,…...

【已解决】【hadoop】【hive】启动不成功 报错 无法与MySQL服务器建立连接 Hive连接到MetaStore失败 无法进入交互式执行环境
启动hive显示什么才是成功 当你成功启动Hive时,通常会看到一系列的日志信息输出到控制台,这些信息包括了Hive服务初始化的过程以及它与Metastore服务连接的情况等。一旦Hive完成启动并准备就绪,你将看到提示符(如 hive> &#…...

基于架设一台NFS服务器实操作业
架设一台NFS服务器,并按照以下要求配置 首先需要关闭防火墙和SELinux 1、开放/nfs/shared目录,供所有用户查询资料 赋予所有用户只读的权限,sync将数据同步写到磁盘上 在客户端需要创建挂载点,把服务端共享的文件系统挂载到所创建…...

eachers中的树形图在点击其中某个子节点时关闭其他同级子节点
答案在代码末尾!!!!! tubiaoinit(params: any) {// 手动触发变化检测this.changeDetectorRef.detectChanges();if (this.myChart ! undefined) {this.myChart.dispose();}this.myChart echarts.init(this.pieChart?…...

Maven 介绍与核心概念解析
目录 1. pom文件解析 2. Maven坐标 3. Maven依赖范围 4. Maven 依赖传递与冲突解决 Maven,作为一个广泛应用于 Java 平台的自动化构建和依赖管理工具,其强大功能和易用性使得它在开发社区中备受青睐。本文将详细解析 Maven 的几个核心概念&a…...
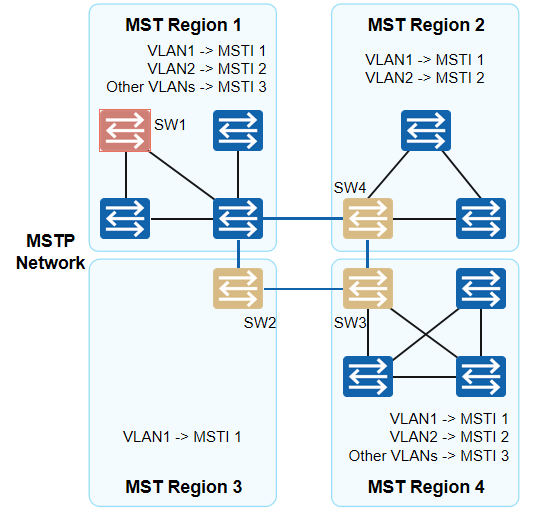
计算机网络-MSTP概述
一、RSTP/STP的缺陷与不足 前面我们学习了RSTP对于STP的一些优化与快速收敛机制。但在划分VLAN的网络中运行RSTP/STP,局域网内所有的VLAN共享一棵生成树,被阻塞后的链路将不承载任何流量,无法在VLAN间实现数据流量的负载均衡,导致…...

Redisson(三)应用场景及demo
一、基本的存储与查询 分布式环境下,为了方便多个进程之间的数据共享,可以使用RedissonClient的分布式集合类型,如List、Set、SortedSet等。 1、demo <parent><groupId>org.springframework.boot</groupId><artifact…...
1)
考研要求掌握的C语言程度(堆排序)1
含义 堆排序就是把数组的内容在心中建立为大根堆,然后每次循环把根顶和没交换过的根末进行调换,再次建立大根堆的过程 建树的几个公式 一个数组有n个元素 最后一个父亲节点是n/2-1; 假如父亲节点在数组的下标为a 那么左孩子节点在数组下标为2*a1,…...

chronyd配置了local的NTP server之后, NTP报文中出现public IP的问题
描述 客户在Rocky Linux 9.4的VM上配了一个local的NTP server(IP: 10.64.1.76)。 配置完成后, 时钟可以同步,但一段时间后客户的firewall收到告警, 拒绝了大量目标端口为123的请求, 且这些请求的目的IP并不是客户指定的NTP server的IP,客户要求解释原因…...

docker常用命令整理
文章目录 docker 常用操作命令一、镜像类操作1.构建镜像2.从容器创建镜像3.查看镜像列表4.删除镜像5. 从远程镜像仓库拉取镜像6. 将镜像推送到镜像仓库中7. 将镜像导出8. 导入镜像9. 登录镜像仓库 二、容器相关操作1. 运行容器2. 进入容器3. 查看容器的运行状态4. 查看容器的日…...

将CSDN博客转换为PDF的Python Web应用开发--Flask实战
文章目录 项目概述技术栈介绍 项目目录应用结构 功能实现单页博客转换示例: 专栏合集博客转换示例: PDF效果: 代码依赖文件requirements.txt:app.py:代码解释: /api/onepage.py:代码解释: /api/zhuanlan.py…...
AIGC学习笔记(3)——AI大模型开发工程师
文章目录 AI大模型开发工程师002 GPT大模型开发基础1 OpenAI账户注册2 OpenAI官网介绍3 OpenAI GPT费用计算4 OpenAI Key获取与配置5 OpenAI 大模型总览6 代码演示安装依赖导入依赖初始化客户端执行代码遇到的问题 AI大模型开发工程师 002 GPT大模型开发基础 1 OpenAI账户注册…...

Windows server 2003服务器的安装
Windows server 2003服务器的安装 安装前的准备: 1.镜像SN序列号 图1-1 Windows server 2003的安装包非常人性化 2.指定一个安装位置 图1-2 选择好安装位置 3.启动虚拟机打开安装向导 图1-3 打开VMware17安装向导 图1-4 给虚拟光驱插入光盘镜像 图1-5 输入SN并…...

Android Wi-Fi 连接失败日志分析
1. Android wifi 关键日志总结 (1) Wi-Fi 断开 (CTRL-EVENT-DISCONNECTED reason3) 日志相关部分: 06-05 10:48:40.987 943 943 I wpa_supplicant: wlan0: CTRL-EVENT-DISCONNECTED bssid44:9b:c1:57:a8:90 reason3 locally_generated1解析: CTR…...

HTML 语义化
目录 HTML 语义化HTML5 新特性HTML 语义化的好处语义化标签的使用场景最佳实践 HTML 语义化 HTML5 新特性 标准答案: 语义化标签: <header>:页头<nav>:导航<main>:主要内容<article>&#x…...

7.4.分块查找
一.分块查找的算法思想: 1.实例: 以上述图片的顺序表为例, 该顺序表的数据元素从整体来看是乱序的,但如果把这些数据元素分成一块一块的小区间, 第一个区间[0,1]索引上的数据元素都是小于等于10的, 第二…...

HTML前端开发:JavaScript 常用事件详解
作为前端开发的核心,JavaScript 事件是用户与网页交互的基础。以下是常见事件的详细说明和用法示例: 1. onclick - 点击事件 当元素被单击时触发(左键点击) button.onclick function() {alert("按钮被点击了!&…...

selenium学习实战【Python爬虫】
selenium学习实战【Python爬虫】 文章目录 selenium学习实战【Python爬虫】一、声明二、学习目标三、安装依赖3.1 安装selenium库3.2 安装浏览器驱动3.2.1 查看Edge版本3.2.2 驱动安装 四、代码讲解4.1 配置浏览器4.2 加载更多4.3 寻找内容4.4 完整代码 五、报告文件爬取5.1 提…...
多光源(Multiple Lights))
C++.OpenGL (14/64)多光源(Multiple Lights)
多光源(Multiple Lights) 多光源渲染技术概览 #mermaid-svg-3L5e5gGn76TNh7Lq {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-3L5e5gGn76TNh7Lq .error-icon{fill:#552222;}#mermaid-svg-3L5e5gGn76TNh7Lq .erro…...

Webpack性能优化:构建速度与体积优化策略
一、构建速度优化 1、升级Webpack和Node.js 优化效果:Webpack 4比Webpack 3构建时间降低60%-98%。原因: V8引擎优化(for of替代forEach、Map/Set替代Object)。默认使用更快的md4哈希算法。AST直接从Loa…...

nnUNet V2修改网络——暴力替换网络为UNet++
更换前,要用nnUNet V2跑通所用数据集,证明nnUNet V2、数据集、运行环境等没有问题 阅读nnU-Net V2 的 U-Net结构,初步了解要修改的网络,知己知彼,修改起来才能游刃有余。 U-Net存在两个局限,一是网络的最佳深度因应用场景而异,这取决于任务的难度和可用于训练的标注数…...
HybridVLA——让单一LLM同时具备扩散和自回归动作预测能力:训练时既扩散也回归,但推理时则扩散
前言 如上一篇文章《dexcap升级版之DexWild》中的前言部分所说,在叠衣服的过程中,我会带着团队对比各种模型、方法、策略,毕竟针对各个场景始终寻找更优的解决方案,是我个人和我司「七月在线」的职责之一 且个人认为,…...

云原生周刊:k0s 成为 CNCF 沙箱项目
开源项目推荐 HAMi HAMi(原名 k8s‑vGPU‑scheduler)是一款 CNCF Sandbox 级别的开源 K8s 中间件,通过虚拟化 GPU/NPU 等异构设备并支持内存、计算核心时间片隔离及共享调度,为容器提供统一接口,实现细粒度资源配额…...