Linux相关概念和易错知识点(17)(文件、文件的系统调用接口、C语言标准流)
目录
1.文件
(1)文件组成和访问
(2)文件的管理
(3)C语言标准流
(4)struct file
①文件操作表
②文件内核缓冲区
(5)Linux下一切皆文件
(6)file的管理(文件描述符表)
(7)struct files_struct
(8)总结图
2.文件的系统调用接口
(1)对文件的系统调用接口的理解
(2)open、close
①open
②close
(3)write、read
①write
②二进制文件和文本文件
③read
3.C语言标准流
(1)语言、硬件、系统描述
(2)引用计数在标准流上的使用
(3)语言封装库函数和流的意义
1.文件
(1)文件组成和访问
文件 = 内容 + 属性,空文件要占领磁盘空间,文件名、大小等属性这些都要被记录,只不过一般不会显示出来,这和进程类似(进程 = 数据和代码 + 属性)
打开一个文件的时候,是谁在访问呢?本质上文件是进程在访问。当程序跑起来并执行到打开文件的代码时(fopen、open等),系统才会去打开并加载文件。一个进程可以打开多个文件。
访问文件之前,必须先打开文件,为什么?因为文件没有被打开的时候在磁盘上。根据冯诺依曼体系结构,CPU不能直接访问磁盘,因此每次访问都要先打开文件,加载到内存当中。
因此我们可以总结出,打开文件 = 把文件(内容和属性)加载到内存中。当然不一定一次性全部加载,存在分批加载的处理。
(2)文件的管理
OS要不要管理加载到内存中的文件呢?必须要!
OS如何管理文件?和进程的管理一样都是先描述、再组织。内核中,被管理的文件 = 文件中的内核数据结构(文件的属性,使用struct保存) + 文件的内容,这类似管理进程的结构体struct PCB(PCB进程控制块,用于管理进程属性和数据代码)。因此,我们研究打开的文件本质上是在研究进程和文件的关系,管理文件本质上就是管理文件的数据结构!
那没有被打开的文件存在哪里呢?磁盘中。被打开的文件在内存中。没有被打开的文件肯定更多。
(3)C语言标准流
我们接下来通过C语言的三个流进一步理解文件。
stdin、stout、stderr分别叫标准输入流、标准输出流、标准错误流,典型的标准输入设备是是键盘,标准输出和错误设备是显示器。进程会默认打开三个流,这属于系统的特性,每种语言都要处理这种特性,尽管流的名字可能不同。
stdin、stout、stderr的类型都是FILE*,在Linux下一切皆文件,这三个流在底层都是文件(这三个流也叫文件流),FILE的本质是结构体,是用来描述文件的各种信息的。FILE属于stdio.h,是C语言封装的一个结构体,而并非系统内核描述文件的结构体,我们一定要分清。
在硬件侧,每种硬件都有自己的驱动程序(键盘、显示器、网卡、磁盘等),再往上层就是操作系统。操作系统是软硬件管理的系统。通过先描述、再组织的方法管理硬件,OS里面使用struct device描述硬件的信息,里面有type、id、status、vender等属性,也有来调用驱动程序的接口的函数指针,组织时通过调用结构体里面的函数指针来完成。所有device都通过指针连接在一起,形成一张描述硬件的链表struct device*。前面讲进程时我们也提过这个概念,当进程链入device里后进程会变成阻塞状态。
我们需要进一步深入,硬件都叫外设,不同设备有不同功能,比如键盘充当输入功能,显示器充当输出功能,网卡充当传输和接收功能。但所有设备都可以提取出共有属性,比如这些都有名字id、都有类型type、都有各自的供应商vender,只是这些属性的值不一样,device里面的一部分成员就提取了这些共有属性。但是外设的核心功能是IO(读写操作),不同设备的IO方法一定不相同,如显示器和网卡的写入方式不一样。device里面的具体输入输出函数指针名字不一样,如read_keyboard(),write_screen()。虽然像名字这些属性可以提取出来,但每个功能相关的函数各不相同(不统一命名为read()或write()考虑了可维护性和接口的设计等),怎么办呢?很多人会想为什么不能统一命名呢?既然device层无法统一,这就需要更上一层的封装了。这就是接下来要介绍的struct file。
(4)struct file
①文件操作表
操作系统有一种结构体struct file,里面有函数指针int (*read) (...),int (*write) (...)(简单的理解方式,实际上还会有单独的封装,不过底层原理一致),它们指向底层struct device里面的读写函数。通过file,我们不用关心device里面的方法名字是否相同,我们在struct file里调用封装的函数指针就可以了。这相当于在系统层面做了一层软件的封装,只要找到了file,就能访问硬件,这样一套系统叫虚拟文件系统vfs。
对于一般文件而言,当它们被加载到内存时,系统会直接创建struct file用来描述文件信息,其中读写信息系统会自动分配,而不是像硬件那样对device里面的方法做封装。
struct file类似多态,它是父类,struct device等是子类。在file侧它能调用的函数接口都长一样,但是实现了不同的功能(类似虚函数表,指向函数地址不同,但向上层提供的接口一致)。
简单来说,文件操作表就是函数指针的集合,将针对具体的文件能实现不同操作,并通过file的封装让硬件和文件划上了等号。
②文件内核缓冲区
我们设想一种情况,当我们想向硬件读入或写入时,数据会直接刷新到硬件中去吗?显然不会,因为系统的一切操作都是在存储器也就是内存里进行的,它的读写速度是比硬件的读写速度快很多的。因此在系统层面还有一个内核缓冲区,会先写入缓冲区,当缓冲区满了或是触发某些条件(如遇到\n了)再刷新到硬件中去。
这个内核缓冲区存在于file里面,每个file都有一个自己的缓冲区。当系统读文件或者写文件时都是向缓冲区进行的,OS会自主决定何时刷新缓冲区到硬件,何时读硬件。
(5)Linux下一切皆文件
如此一来,我们通过file可以统一访问普通文件和硬件。站在系统的层面来讲,普通文件和硬件都是文件,它们都被file集中描述起来了,这就是struct file存在的意义,这个时候我们也能理解为什么device侧没必要对读写方法做统一命名,因为file层面会做统一封装,将硬件和文件紧密联系起来,形成一个更大的文件的概念。系统调用文件操作时就是在file层面进行的,因此我们才会说Linux下一切皆文件。
(6)file的管理(文件描述符表)
之前我们遇到的PCB、struct device等都是按照链表的形式连接在一起的。但对于file而言就有弊端了。为了实现一些特殊的功能,如重定向、同一文件被多个进程使用等,file的管理需要一种更快速更高效的访问,就是顺序表。
顺序表要求数据集中,这显然对于文件来说太过苛责,每个file都不算小,扩容等操作难免效率低,因此采用指针数组struct file* fd_array[N],里面存着指向每个file的指针。如此一来,系统就可以通过struct file* fd_array[N]这一个数组管理所有文件,包括所有输入输出设备、硬件、文件等,它们通过file的封装使得系统可以无差别调用。
这就引入了文件描述符fd,fd就是指的struct file* fd_array[N]的下标,通过这个下标,我们可以找到file,进而进行文件操作。对于系统而言,这就是该进程使用文件的身份证,只有拥有fd,系统才能在struct file* fd_array[N]中找到file*,进一步找到file,进行读写操作。struct file* fd_array[N]也被叫做文件描述符表。
但是到这里还是有一个问题:我们研究打开的文件本质上是在研究进程和文件的关系,管理文件本质上就是管理文件的数据结构。后半句我们已深有体会,但前半句始终不明,struct file* fd_array[N]如何进一步被进程管理的呢?这就需要再上一层封装了。
(7)struct files_struct
单单一层struct file* fd_array[N]还是不足以管理好文件,首先我们还需要记录fd_array[N]这个数组的元素个数(也就是文件描述符的个数),并且同一个file可能被多个进程使用,比如几乎所有进程都会使用标准输入、标准输出、标准错误流。也有的文件只被一个进程使用。这就要用到引用计数了,当最后一个使用该文件的进程不再使用该文件时,就释放file,这显然需要每个进程的共同作用。并且还有一些文件相关的属性等也都需要单独维护,这就是files_struct干的事情了。struct files_struct里面存的就是struct file* fd_array[N]以及一些文件相关的属性,保证文件被很好地管理起来了。至此,我们的文件系统就搭建好了,struct files_struct以指针的形式交给PCB进行保管,每个进程都有struct files_struct* files,这也系统想要进行文件管理的入口。
(8)总结图

2.文件的系统调用接口
我们在大致了解文件系统的框架之后,我们需要逐一深化刚才的知识点,首先就是对接口的理解
(1)对文件的系统调用接口的理解
我们常用的文件操作无非就是fopen、fclose、fputs、fgets、fwrite、fread、fscanf、fprintf等函数。这些函数都是C语言的库函数,它们都是语言级函数,语言级函数要对文件进行操作只能通过系统调用接口,也就是调用系统调用接口来实现。因此上述的所有函数都只是一个壳子,它的底层也是靠别人来完成的。这就是文件系统调用接口,open、close、write、read。这四个函数组合实现了上面所有函数的功能。
(2)open、close
open和close都是系统调用接口,是所有语言底层和系统调用接壤的接口,是C语言写的。

①open
返回值都是执行成功为fd,失败为-1。
第一个参数pathname(文件名,可带路径可不带),第二个参数int flag(32位int构成的位图)。其中标记位主要有:O_RDONLY(只读),O_WRONLY(只写),O_APPEND(追加),O_CREAT(创建),O_RDWR(读写),O_TRUNC(覆盖)。
标记位的本质是宏。每个标记位都是只有一个bit位为1的值并保证互相独立,使用O_RDWR | O_RDONLY传参使flag拥有组合属性,函数可按位与解析属性。如0001和0010的按位或就是0011,open函数拿到这个值后分别按位与1000、0100、0010、0001来解析原来的属性,如果按位与结果不是0就说明有该属性,会针对该属性进行处理。
我们还发现open函数有个版本有第三个参数mode_t mode(权限,填0666取后三个指明权限)。注意,我们设置的mode要经过权限掩码umask。我们可以在程序中直接写umask(0)设置权限掩码。权限掩码也是针对当前进程的,执行程序会调用当前进程设置的新的权限掩码,同时不会影响父进程或已创建的子进程。如果要创建文件O_CREAT一定要写第三个参数,有文件的话写两个参数即可,调用时会根据传参个数来调用。
②close
返回值都是执行成功为fd,失败为-1。
close(fd)就是用文件描述符关闭文件。

我们发现fd是3,这是因为前3个分别被标准输入、输出、错误占领了。对于fd的分配来说,默认会分配fd_array中目前处于空位的最小的下标,这就意味着一个下标可以先后被多个文件使用。

这个例子实现的就是fopen("test.txt", "w")的功能。其中权限掩码要在open前设置,并且注意权限掩码是减去对应权限而不是单纯数字相减,要转换为权限的减法,例如在这里0333的x权限就是无效的,和0222效果一样。
(3)write、read
这两个函数可以实现包括printf等在内的所有关于文件读写的操作,它们作为系统调用接口有什么特别之处呢?为什么C语言要封装那么多函数呢?下面的展示会告诉我们答案。
①write

这个函数也是根据fd来寻找要写入的文件,buf是一个void*指针,最多写入count字节,ssize_t返回实际写入字节,一般来讲我们就根据自己要写的字节数传进去即可。

向文件写数据要注意不需要考虑\0,字符串以\0结尾是C语言要求,不是文件的规范,写进去其实算是乱码,会影响我们的预期效果。
write还有另一个特性

我们直接向文件里面写入了二进制数据!
这是一个很需要我们仔细体会的地方,很考验我们对源码的理解,这也涉及到二进制文件和文本文件的理解。
②二进制文件和文本文件
在上面的例子中,int msg的32位数据里只用到了前几位,剩下的都是0。我们直接将这个整数的指针传过去并写入1个字节,就相当于将前8个bit写了进去(系统调用接口会根据字节序同步处理处理,注意数组存储顺序是从低地址到高地址,和字节序没关系)。这个时候文件里面就有了96对应的二进制。当cat读取文件内容时,二进制会被通过ASCII码转为a,最终呈现在我们眼前。为什么会有ASCII码的转换步骤呢?为什么读取出来不是97呢?
这里需要引入格式化的概念。我们打印内容到显示器文件时,我们向显示器写的其实是一个一个字符,显示器是字符设备。因此当我们打印整型97时,显示的确实是97,但对于显示器来讲是"97"这个字符串,这就意味着我们用的printf("%d", 97)是帮我们将整型转为了字符,%d就是一套转换的标准,包括%lf这些都可理解为帮助我们格式化为字符串的“选项”。在源码上来讲,显示器得到的早就不是源码97对应的二进制了,而是'9'、'7'两个字符对应的ASCII码对应的二进制。同理,当我在键盘里输入1234,我们最初得到的也是字符,也需要scanf系列函数格式化输入转为%d。
计算机底层文件都是二进制,区分它们是不是文本文件的关键就在于是否经历格式化这个步骤。对于文本文件而言,一切内容都需要经过ASCII编码才能存储,以文本文件的形式读入时也需要经过ASCII的转换才行,这都是在软件层进行转换的。
对于二进制文件而言,就是直接转换为二进制写入。int直接按照内存中int的源码形式直接写入文件,包括浮点等都是如此。这就是为什么上面write的第二个参数是void*的原因,write只需要拿到地址开头和读取长度,当输入"Hello"时当然没问题,因为它不需要转换,它本身的源码形式就是ASCII转换的文本形式,所以虽然write以二进制的形式写入,但读取依然正常;而当输入int、float时,write会直接将它们的源码写进文件。当我们用文本文件来读二进制文件时,它会自动用ASCII转换一次,因此我们存的97,文件中确实存的就是97的二进制,但读入时是文本文件的格式,ASCII转换过来就是字母a。
所以一般情况下文本文件读二进制文件都是乱码,就是多了一次格式化的过程。在硬件层根本不存在二进制文件和文本文件。而对于系统调用接口write和read而言,它们都是以指针和字节数为基准,按照二进制的形式直接读写。文本文件和二进制文件的区分要到上层软件层才能区分出来。
这就是为什么会有一系列printf、scanf函数的原因。它帮我们格式化总比我们自己格式化方便很多,并且要理解到这一点需要前期很多的计算机知识,对入门来讲很不友好。
③read

用法和write一致,参数等含义都一致。

如果我们想要读之前写的内容,还可以lseek来定位指针到最前面,不然read只会向后读,读不到我们之前写的内容。

read的底层也都是以二进制形式直接将源码填到我们传过去的指针对应的空间里。所以我们只能用char的数组来接收,且当存储时是以字符形式(文本形式)进行时才能保证正常解析。
从上面write和read的讲解中,我们应该能够很自然的理解fwrite和fprintf之间的区别了,也能很清晰地明白它们的底层调用是什么,以及为什么要上层封装。
3.C语言标准流
前面我们靠C语言标准流帮助我们理解了文件,现在我们要重新认识标准流了。
(1)语言、硬件、系统描述
前面我说过进程会默认打开三个流,这属于系统的特性,每种语言都要处理这种特性,尽管流的名字可能不同。什么意思呢?stdin、stdout、stderr是语言级描述,每种语言都有自己的一套叫法;键盘、显示器是硬件层面上的描述,进程会默认去打开对应硬件的流;fd是系统找文件的身份证,因此0、1、2是系统级描述。
这三个描述紧密相连,stdin、stdout、stderr的类型都是FILE,这也是一个结构体,属于语言上的描述。语言的底层就是系统,FILE的描述信息里就有对应文件的fd,即_fileno成员。只有通过_fileno才能通过语言级描述转为系统级描述,系统再通过fd找到file,最终file转为对硬件的描述,这样一个读写流程才能完成。
(2)引用计数在标准流上的使用
默认情况下输入、输出、错误流分别占据fd_array[N]的前三个下标。所有进程都会使用这三个file,因此files_struct上的引用计数很有用处,一个file可以被好几百个进程指向,这极大地节约了空间,不用每次都针对每个进程重新创建file了。
就算该进程关闭了输入流,但是这只会修改这个进程的fd_array并对files_struct的引用计数--,实际上输入流对应的file依然没有关闭,因为进程之间具有独立性,对一个进程的操作不会影响其他进程。
(3)语言封装库函数和流的意义
C语言为什么要封装呢?换句话说,为什么每个语言都要封装自己的流呢?
这就是对跨平台、可移植性的考虑了。如果运行代码的平台换了,在Windows、MacOS、Linux之间互相切换,由于不同系统的调用接口不一样,比如在某个系统open函数参数有差别,这时我们如果不封装上层fopen、fprintf这些函数,也不封装FILE,而是直接使用open等系统调用接口的话,我们的代码就跑不了,流都没法打开。因此要提高语言的可移植性、提高跨平台性,就必须对那些兼容性较差的部分做封装。我们上层的使用库函数和FILE的代码不需要改,动的是代码底层调用,这只需要我们选择对应安装包就可解决。
对于C语言来说,fopen、fclose、printf的具体实现在glibc库(C标准库)里面,里面有语言的源代码。源文件有不同版本,源代码在编译时也会按照不同系统编译,Linux版、Windows版、MacOS版,安装环境也需要根据不同系统安装。这一点相信我们在配置环境时都遇到过,这也解释了为什么我们要根据自己的系统选择对应版本的安装包。这在系统层面是关键问题。
相关文章:
Linux相关概念和易错知识点(17)(文件、文件的系统调用接口、C语言标准流)
目录 1.文件 (1)文件组成和访问 (2)文件的管理 (3)C语言标准流 (4)struct file ①文件操作表 ②文件内核缓冲区 (5)Linux下一切皆文件 (…...

三防加固工业平板国产化的现状与展望
在当今全球科技竞争日益激烈的背景下,工业4.0和智能制造的浪潮推动了工业自动化设备的迅速发展,其中,三防加固工业平板电脑作为连接物理世界与数字世界的桥梁,其重要性不言而喻。所谓“三防”,即防水、防尘、防震&…...

3.1.3 看对于“肮脏”页面的处理
3.1.3 看对于“肮脏”页面的处理 文章目录 3.1.3 看对于“肮脏”页面的处理再看对于“肮脏”页面的处理MmPageOutVirtualMemory() 再看对于“肮脏”页面的处理 MmPageOutVirtualMemory() NTSTATUS NTAPI MmPageOutVirtualMemory(PMADDRESS_SPACE AddressSpace,PMEMORY_AREA Me…...

学 Python 还是学 Java?——来自程序员的世纪困惑!
文章目录 1. Python:我就是简单,so what?2. Java:严谨到让你头疼,但大佬都在用!3. 到底谁更香?——关于学哪门语言的百思不得姐结论——到底该选谁?推荐阅读文章 每个程序员都可能面…...

Spring Web MVC 入门
1. 什么是 Spring Web MVC Spring Web MVC 是基于 Servlet API 构建的原始 Web 框架,从从⼀开始就包含在Spring框架中。它的 正式名称“SpringWebMVC”来⾃其源模块的名称(Spring-webmvc),但它通常被称为"Spring MVC". 什么是Servlet呢? Ser…...
吃牛羊肉的季节来了,快来看看怎么陈列与销售!
一、肉品陈列基本原则 (一)新鲜卫生 1、保证商品在正确的温度、正确的方式下陈列 (1)正确的温度:冷藏柜-2℃-2℃;冷冻柜库-20℃-18℃ (2)正确的方式: 商品不遮挡冷气出风口&…...

租房业务全流程管理:Spring Boot系统应用
摘要 随着信息技术在管理上越来越深入而广泛的应用,管理信息系统的实施在技术上已逐步成熟。本文介绍了租房管理系统的开发全过程。通过分析租房管理系统管理的不足,创建了一个计算机管理租房管理系统的方案。文章介绍了租房管理系统的系统分析部分&…...
Linker链接脚本)
GCC之编译(7)Linker链接脚本
GCC之(7)Linker链接脚本 Author: Once Day Date: 2024年10月25日 一位热衷于Linux学习和开发的菜鸟,试图谱写一场冒险之旅,也许终点只是一场白日梦… 漫漫长路,有人对你微笑过嘛… 本文档翻译自GNU LD链接脚本官方手册 参考文章: GNU LD …...

【设计模式系列】适配器模式(九)
目录 一、什么是适配器模式 二、适配器模式的角色 三、适配器模式的典型应用 四、适配器模式在InputStreamReader中的应用 一、什么是适配器模式 适配器模式(Adapter Pattern)是一种结构型设计模式,它允许将不兼容的接口转换为一个客户端…...

C# 文档打印详解与示例
文章目录 一、概述二、PrintDocument 类的使用三、PrintDialog 类的使用四、PageSetupDialog 类的使用五、PrintPreviewDialog 类的使用六、完整示例七、总结 在软件开发过程中,文档打印是一个常见的功能需求。本文将详细介绍如何在C#中实现文档打印,并给…...

Spring Cloud --- Sentinel 熔断规则
熔断规则 慢调用比例 发送10个请求,每个请求理想响应时长为200毫秒。统计1秒钟,如果10个请求响应时间超过200毫秒的比例大于等于10%,则触发熔断,熔断5秒。 异常比例 1秒内,发送请求出现异常率为20%,则触…...

使用爬虫爬取Python中文开发者社区基础教程的数据
👨💻个人主页:开发者-曼亿点 👨💻 hallo 欢迎 点赞👍 收藏⭐ 留言📝 加关注✅! 👨💻 本文由 曼亿点 原创 👨💻 收录于专栏:…...
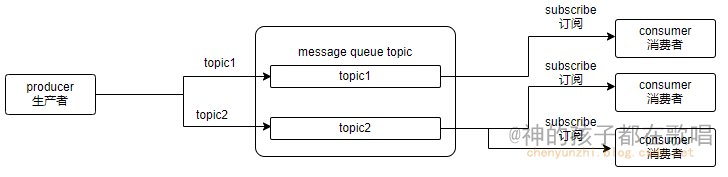
你了解kafka消息队列么?
消息队列概述 一. 消息队列组件二. 消息队列通信模式2.1 点对点模式2.2 发布/订阅模式 三. 消息队列的优缺点3.1 消息队列的优点3.2 消息队列的缺点 四. 总结 前言 这是我在这个网站整理的笔记,有错误的地方请指出,关注我,接下来还会持续更新。 作者&…...

力扣102 二叉树的层序遍历 广度优先搜索
二叉树的层序遍历 题目描述 给你二叉树的根节点 root ,返回其节点值的 层序遍历 。 (即逐层地,从左到右访问所有节点)。 示例 1: 输入:root [3,9,20,null,null,15,7] 输出:[[3],[9,20],[15…...

堆(堆排序,TOP K, 优先级队列)
1 概念解释 堆的定义:堆是一颗完全二叉树,分为大堆和小堆 大堆:一棵树中,任何父亲节点都大于等于孩子的节点,大堆的根结点最大 小堆:一棵树中,任何父亲节点都小于等于孩子节点,小堆…...

(三)行为模式:11、模板模式(Template Pattern)(C++示例)
目录 1、模板模式含义 2、模板模式的UML图学习 3、模板模式的应用场景 4、模板模式的优缺点 5、C实现的实例 1、模板模式含义 模板模式(Template Method Pattern)是一种行为设计模式,它定义了一个操作中的算法骨架,将某些步骤…...

贝叶斯中的充分统计量
内容来源 贝叶斯统计(第二版)中国统计出版社 前两篇笔记简述经典统计中的充分统计量和判断充分统计量的 N e y m a n Neyman Neyman 因子分解定理 而在贝叶斯统计中,充分统计量也有一个充要条件 定理兼定义 设 x ( x 1 , x 2 , ⋯ , x …...

012:ArcGIS Server 10.2安装与站点创建教程
摘要:本文详细介绍地理信息系统服务器软件ArcGIS Server 10.2的安装与站点创建流程。 一、软件介绍 ArcGIS Server 10.2是Esri公司开发的一款强大的地理信息系统(GIS)服务器软件。它支持发布和共享地图、地理数据处理服务及空间分析功能&…...

xlive.dll错误的详细解决办法步骤教程,xlive.dll基本状况介绍
在计算机的众多文件中,“xlive.dll”扮演着独特而重要的角色。所以当你的电脑丢失了xlive.dll文件时,会倒是电脑不能正常运行,那么出现这样的问题有什么办法可以将丢失的xlive.dll进行修复呢?今天这篇文章将和大家聊聊xlive.dll错…...
通俗易懂的餐厅例子来讲解JVM
餐厅版本 JVM(Java虚拟机)可以想象成一个虚拟的计算机,它能够运行Java程序。为了让你更容易理解,我们可以用一个餐厅的比喻来解释JVM: 菜单(Java源代码): 想象一下,Java…...

React 第五十五节 Router 中 useAsyncError的使用详解
前言 useAsyncError 是 React Router v6.4 引入的一个钩子,用于处理异步操作(如数据加载)中的错误。下面我将详细解释其用途并提供代码示例。 一、useAsyncError 用途 处理异步错误:捕获在 loader 或 action 中发生的异步错误替…...

linux之kylin系统nginx的安装
一、nginx的作用 1.可做高性能的web服务器 直接处理静态资源(HTML/CSS/图片等),响应速度远超传统服务器类似apache支持高并发连接 2.反向代理服务器 隐藏后端服务器IP地址,提高安全性 3.负载均衡服务器 支持多种策略分发流量…...
)
论文解读:交大港大上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架(二)
HoST框架核心实现方法详解 - 论文深度解读(第二部分) 《Learning Humanoid Standing-up Control across Diverse Postures》 系列文章: 论文深度解读 + 算法与代码分析(二) 作者机构: 上海AI Lab, 上海交通大学, 香港大学, 浙江大学, 香港中文大学 论文主题: 人形机器人…...

利用ngx_stream_return_module构建简易 TCP/UDP 响应网关
一、模块概述 ngx_stream_return_module 提供了一个极简的指令: return <value>;在收到客户端连接后,立即将 <value> 写回并关闭连接。<value> 支持内嵌文本和内置变量(如 $time_iso8601、$remote_addr 等)&a…...

SpringCloudGateway 自定义局部过滤器
场景: 将所有请求转化为同一路径请求(方便穿网配置)在请求头内标识原来路径,然后在将请求分发给不同服务 AllToOneGatewayFilterFactory import lombok.Getter; import lombok.Setter; import lombok.extern.slf4j.Slf4j; impor…...

智能分布式爬虫的数据处理流水线优化:基于深度强化学习的数据质量控制
在数字化浪潮席卷全球的今天,数据已成为企业和研究机构的核心资产。智能分布式爬虫作为高效的数据采集工具,在大规模数据获取中发挥着关键作用。然而,传统的数据处理流水线在面对复杂多变的网络环境和海量异构数据时,常出现数据质…...

学校时钟系统,标准考场时钟系统,AI亮相2025高考,赛思时钟系统为教育公平筑起“精准防线”
2025年#高考 将在近日拉开帷幕,#AI 监考一度冲上热搜。当AI深度融入高考,#时间同步 不再是辅助功能,而是决定AI监考系统成败的“生命线”。 AI亮相2025高考,40种异常行为0.5秒精准识别 2025年高考即将拉开帷幕,江西、…...

华硕a豆14 Air香氛版,美学与科技的馨香融合
在快节奏的现代生活中,我们渴望一个能激发创想、愉悦感官的工作与生活伙伴,它不仅是冰冷的科技工具,更能触动我们内心深处的细腻情感。正是在这样的期许下,华硕a豆14 Air香氛版翩然而至,它以一种前所未有的方式&#x…...

2025季度云服务器排行榜
在全球云服务器市场,各厂商的排名和地位并非一成不变,而是由其独特的优势、战略布局和市场适应性共同决定的。以下是根据2025年市场趋势,对主要云服务器厂商在排行榜中占据重要位置的原因和优势进行深度分析: 一、全球“三巨头”…...

【SpringBoot自动化部署】
SpringBoot自动化部署方法 使用Jenkins进行持续集成与部署 Jenkins是最常用的自动化部署工具之一,能够实现代码拉取、构建、测试和部署的全流程自动化。 配置Jenkins任务时,需要添加Git仓库地址和凭证,设置构建触发器(如GitHub…...