Python 使用 LSTM 进行情感分析:处理文本序列数据的指南
使用 LSTM 进行情感分析:处理文本序列数据的指南
长短期记忆网络(LSTM)是一种适合处理序列数据的深度学习模型,广泛应用于情感分析、语音识别、文本生成等领域。它通过在训练过程中“记住”过去的数据特征来理解和预测序列数据的未来趋势。本文将介绍如何使用 LSTM 模型进行情感分析,帮助新手了解从数据预处理到模型训练的整个流程。

1. LSTM 和情感分析的基础知识
什么是 LSTM
LSTM(Long Short-Term Memory)是一种特殊的循环神经网络(RNN),其结构设计使其能够“记住”较长的序列信息。传统 RNN 在处理长序列数据时容易出现“梯度消失”或“梯度爆炸”的问题,而 LSTM 引入了“遗忘门”、“输入门”和“输出门”结构,使其能够在较长的时间跨度内保持记忆。
什么是情感分析
情感分析是一种自然语言处理(NLP)技术,用于分析文本中表达的情绪。通过情感分析,我们可以将一段文本标记为正面、负面或中性等类别。LSTM 对情感分析特别有效,因为它能够捕捉到文本中的上下文和词语之间的顺序关系。
2. 项目概述
在这个项目中,我们将使用 Python 中的 Keras 库实现一个 LSTM 模型,以 IMDB 电影评论数据集为例,进行情感分析。主要步骤如下:
- 数据预处理:对文本进行清理和编码。
- 构建 LSTM 模型:设计网络结构。
- 训练模型:输入训练数据并优化模型参数。
- 模型评估:检查模型的准确性。
- 预测情感:使用训练好的模型对新文本进行预测。
3. 准备工作
首先,我们需要安装所需的库:TensorFlow(Keras 包含在 TensorFlow 中)和 numpy。可以通过以下命令安装:
pip install tensorflow numpy
4. 加载和预处理数据
我们将使用 Keras 提供的 IMDB 电影评论数据集。该数据集包含 50,000 条标记为正面或负面的电影评论,非常适合用来训练情感分析模型。
导入必要库和数据集
import numpy as np
from tensorflow.keras.datasets import imdb
from tensorflow.keras.preprocessing.sequence import pad_sequences# 设置最大单词数(只使用最常见的 10,000 个单词)
max_words = 10000
max_len = 200 # 每个评论的最大长度# 加载 IMDB 数据集
(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=max_words)
数据预处理
IMDB 数据集中的评论已经被转换为整数序列,每个整数代表一个单词。为了使每条评论长度一致,我们使用 pad_sequences 函数对每条评论进行填充或截断,使其长度为 200 个单词。
x_train = pad_sequences(x_train, maxlen=max_len)
x_test = pad_sequences(x_test, maxlen=max_len)
5. 构建 LSTM 模型
LSTM 模型通常包含以下几个层:
- 嵌入层(Embedding Layer):将整数序列转换为密集的词向量。
- LSTM 层:负责记忆序列数据。
- 全连接层(Dense Layer):用于生成最终的分类结果。
创建 LSTM 模型
我们使用 Keras 构建一个简单的 LSTM 模型。以下代码定义了模型的架构:
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, LSTM, Dense# 定义模型
model = Sequential([Embedding(input_dim=max_words, output_dim=128, input_length=max_len), # 嵌入层LSTM(128, dropout=0.2, recurrent_dropout=0.2), # LSTM 层Dense(1, activation='sigmoid') # 输出层
])# 编译模型
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])# 打印模型摘要
model.summary()
模型架构解释
- Embedding 层:将输入的单词 ID 转换为 128 维的稠密向量表示。
- LSTM 层:包含 128 个隐藏单元,
dropout和recurrent_dropout分别表示正则化,减少过拟合。 - Dense 层:使用 sigmoid 激活函数将输出映射到 [0, 1] 之间的概率,用于二分类(正面或负面)。
6. 训练模型
使用训练集对模型进行训练。batch_size 表示每次输入到模型的样本数,epochs 表示遍历整个数据集的次数。
# 训练模型
batch_size = 64
epochs = 10history = model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, validation_split=0.2) # 20% 的训练集用作验证集
训练过程中的常见问题
- 过拟合:如果模型在训练集上的准确率很高,但在测试集上较低,可能是过拟合导致。可以尝试增加
dropout值,或降低 LSTM 单元数量。 - 不足拟合:如果模型表现不佳,可以尝试增加 LSTM 单元数量,或增加训练轮数。
7. 模型评估
在训练完模型后,我们可以在测试集上评估其表现:
# 在测试集上评估模型
test_loss, test_acc = model.evaluate(x_test, y_test, verbose=0)
print(f'测试集准确率: {test_acc:.4f}')
通过观察测试集的准确率,可以大致判断模型的实际表现。
8. 使用模型进行情感预测
在模型训练完成后,我们可以使用它对新评论的情感进行预测。首先,我们需要对输入的文本进行处理,将其转换为整数序列,然后填充到统一长度:
from tensorflow.keras.preprocessing.text import Tokenizer# 假设我们有一个新的评论
new_review = ["The movie was fantastic and the acting was superb!"]# 创建一个 Tokenizer,并将评论转换为整数序列
tokenizer = Tokenizer(num_words=max_words)
tokenizer.fit_on_texts(new_review) # 新评论的分词# 将评论序列填充到指定长度
new_review_seq = tokenizer.texts_to_sequences(new_review)
new_review_pad = pad_sequences(new_review_seq, maxlen=max_len)# 预测情感
prediction = model.predict(new_review_pad)
print(f"情感预测(0 表示负面,1 表示正面): {prediction[0][0]:.4f}")
9. LSTM 模型的优缺点
优点
- 长序列信息处理:LSTM 能够记住较长时间内的序列信息,非常适合情感分析。
- 适应性强:可用于各种序列数据任务,如文本生成、情感分类、时间序列预测等。
缺点
- 训练耗时:LSTM 模型参数较多,训练时间长,特别是在长序列上。
- 计算资源消耗高:LSTM 需要大量计算资源,如果数据量很大,通常需要高性能的硬件支持。
10. 扩展:使用双向 LSTM 和预训练嵌入层
为了提升模型效果,我们可以使用双向 LSTM 和预训练的词向量,例如 GloVe。双向 LSTM 可以同时考虑句子前后文,而预训练词向量则能够使模型更快收敛。
双向 LSTM 的代码示例
from tensorflow.keras.layers import Bidirectionalmodel = Sequential([Embedding(input_dim=max_words, output_dim=128, input_length=max_len),Bidirectional(LSTM(128, dropout=0.2, recurrent_dropout=0.2)),Dense(1, activation='sigmoid')
])
11. 总结
本文详细介绍了如何使用 LSTM 网络进行情感分析。通过 IMDB 数据集的实例,我们了解了数据预处理、模型构建、训练、评估以及情感预测的整个流程。LSTM 模型在文本情感分析上表现优异,适合有较长依赖关系的序列任务。不过,LSTM 也有一些缺点,如训练时间较长、资源消耗大等。
希望本文能帮助您更好地理解 LSTM 网络及其在情感分析中的应用,为以后的自然语言处理任务打下基础。
相关文章:
Python 使用 LSTM 进行情感分析:处理文本序列数据的指南
使用 LSTM 进行情感分析:处理文本序列数据的指南 长短期记忆网络(LSTM)是一种适合处理序列数据的深度学习模型,广泛应用于情感分析、语音识别、文本生成等领域。它通过在训练过程中“记住”过去的数据特征来理解和预测序列数据的…...

MySQL:INSERT IGNORE 语句的用法
INSERT IGNORE 语句 在MySQL中,INSERT IGNORE 语句用于尝试向表中插入一行数据,但如果插入操作会导致表中唯一索引或主键的冲突,MySQL将忽略该操作并继续执行,而不会引发错误。这意味着,如果表中已经存在具有相同唯一…...

java模拟进程调度
先来先服务优先级调度短作业优先调度响应比优先调度 代码 import java.util.ArrayList; import java.util.Comparator; import java.util.List; import java.util.Scanner;class Main {static class tasks{int id;//序号char jinchengname;//进程名int jinchengId;//double a…...

大模型AI在教育领域有哪些创业机会?
大模型AI在教育领域有很多创业机会,尤其是在个性化学习、教学辅助、教育资源优化等方面。以下是一些潜在的创业机会: 个性化学习平台 学习路径定制:根据学生的学习数据与兴趣,为他们设计个性化的学习路径,提供适合的课…...

网页上视频没有提供下载权限怎么办?
以腾讯会议录屏没有提供下载权限为例,该怎么办呢? 最好的办法就是找到管理员,开启下载权限。如果找不到呢,那就用这个办法下载。 1.打开Microsoft Edge浏览器的扩展 2.搜索“视频下载”,选择“视频下载Pro” 3.点击“…...

【去哪里找开源商城项目】
有很多途径可以找到开源项目,以下是一些常用的方法: 开源代码托管平台:许多开源项目都托管在平台上,例如GitHub、GitLab和Bitbucket。你可以在这些平台上浏览项目,搜索关键词,查看项目的星级和贡献者数量等…...
ei会议检索:第二届网络、通信与智能计算国际会议(NCIC 2024)
第二届网络、通信与智能计算国际会议(NCIC 2024)将于2024年11月22-25日在北京信息科技大学召开,聚焦网络、通信与智能计算,欢迎国内外学者投稿交流,录用文章将在Springer出版,并提交EI等检索。 NCIC 2024&a…...

vue添加省市区
主要参考“element”框架:Element - The worlds most popular Vue UI framework <div class"block"><span class"demonstration">默认 click 触发子菜单</span><el-cascaderv-model"value":options"optio…...

运维监控丨16条常用的Kafka看板监控配置与告警规则
本期我们针对企业运维监控的场景,介绍一些监控配置和告警规则。可以根据Kafka集群和业务的具体要求,灵活调整和扩展这些监控配置及告警规则。在实际应用场景中,需要综合运用多种监控工具(例如Prometheus、Grafana、Zabbix等&#…...

ECharts饼图,配置标注示例
const color ["#00FFB4", "#5498FD", "#6F54FD", "#FD5454", "#FDA354",]const datas [{ value: 100, name: "一年级" },{ value: 70, name: "二年级" },{ value: 184, name: "三年级" },{…...

【大象数据集】大象图像识别 目标检测 机器视觉(含数据集)
一、背景意义 在信息时代,数据的收集和分析技术得到了飞速发展。深度学习算法的出现,为处理和分析这些复杂的鱼类数据集提供了强大的工具。深度学习具有强大的模式识别和特征提取能力,能够从海量的数据中自动学习和发现规律,为鱼…...

LN 在 LLMs 中的不同位置 有什么区别么
Layer Normalization(LN)是一种在深度学习中用于稳定和加速神经网络训练的归一化技术。它通过对单个样本的所有激活进行归一化来工作,与Batch Normalization(BN)不同,BN是对一个mini-batch中的所有样本的激…...

【代码随想录Day57】图论Part08
拓扑排序精讲 题目链接/文章讲解:代码随想录 import java.util.*;public class Main {public static void main(String[] args) {Scanner scanner new Scanner(System.in);// 读取文件数量 n 和依赖关系数量 mint n scanner.nextInt();int m scanner.nextInt()…...

记录一次mmpretrain训练数据并转onnx推理
目录 1.前言 2.代码 3.数据形态【分类用】 4.配置文件 5.训练 6.测试-分析-混淆矩阵等等,测试图片效果等 7.导出onnx 8.onnx推理 9.docker环境简单补充 1.前言 好久没有做图像分类了,于是想用商汤的mmclassification快速搞一波,发现已…...

shodan5,参数使用,批量查找Mongodb未授权登录,jenkins批量挖掘
查找美国安全局漏洞 nww.nsa.gov(美国安全局官方网站) net参数使用 搜索指定的ip网段 shodan search --limit 10 --fields ip_str,port net:208.88.84.0/24 (老美国家安全局的一个网段)可能直接访问不太行,可以使用host参数,得到域名再去…...

telnet 密码模式 访问路由器
telnet 密码访问华为路由器 模拟被访问路由 sy [Huawei]int g0/0/0 //选中 g0/0/0端口 [Huawei-GigabitEthernet0/0/0]ip add 192.168.1.1 24 //设置端口ip [Huawei]user-interface vty 0 4 //配置vty [Huawei-ui-vty0-4]set authentication password cipher huawei123 //设置…...

文心一言 VS 讯飞星火 VS chatgpt (380)-- 算法导论24.4 12题
十二、给出一个有效算法来解决 A x ⩽ b Ax⩽b Ax⩽b 的差分约束系统,这里 b b b 的所有元素为实数,而变量 x i x_i xi 中某个给定的子集是整数。如果要写代码,请用go语言。 文心一言: 差分约束系统问题通常用于解决带有约…...
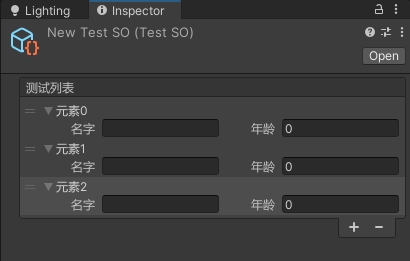
Unity自定义数组在Inspector窗口的显示方式
了解 单行高度:EditorGUIUtility.singleLineHeight获取 PropertyField 控件所需的高度:EditorGUI.GetPropertyHeight属性是否在Inspector窗口展开:SerializedProperty.isExpanded可重新排序列表类:ReorderableList绘制纯色矩形:EditorGUI.Dr…...
--SPCL论文阅读笔记(2024-10-29))
ERC论文阅读(03)--SPCL论文阅读笔记(2024-10-29)
SPCL论文阅读笔记 论文中心思想 这篇论文是研究ERC任务的论文,作者提出了监督原型对比学习的方法用于ERC任务。 论文 EMNLP2022 paper “Supervised Prototypical Contrastive Learning for Emotion Recognition in Conversation” 现存问题 现存的使用监督对…...

Straightforward Layer-wise Pruning for More Efficient Visual Adaptation
对于模型中冗余的参数,一个常见的方法是通过结构化剪枝方法减少参数容量。例如,基于幅度值和基于梯度的剪枝方法。尽管这些方法在传统训练上通用性,本文关注的PETL迁移有两个不可避免的问题: 显著增加了模型存储负担。由于不同的…...

利用ngx_stream_return_module构建简易 TCP/UDP 响应网关
一、模块概述 ngx_stream_return_module 提供了一个极简的指令: return <value>;在收到客户端连接后,立即将 <value> 写回并关闭连接。<value> 支持内嵌文本和内置变量(如 $time_iso8601、$remote_addr 等)&a…...

python/java环境配置
环境变量放一起 python: 1.首先下载Python Python下载地址:Download Python | Python.org downloads ---windows -- 64 2.安装Python 下面两个,然后自定义,全选 可以把前4个选上 3.环境配置 1)搜高级系统设置 2…...

Map相关知识
数据结构 二叉树 二叉树,顾名思义,每个节点最多有两个“叉”,也就是两个子节点,分别是左子 节点和右子节点。不过,二叉树并不要求每个节点都有两个子节点,有的节点只 有左子节点,有的节点只有…...

【开发技术】.Net使用FFmpeg视频特定帧上绘制内容
目录 一、目的 二、解决方案 2.1 什么是FFmpeg 2.2 FFmpeg主要功能 2.3 使用Xabe.FFmpeg调用FFmpeg功能 2.4 使用 FFmpeg 的 drawbox 滤镜来绘制 ROI 三、总结 一、目的 当前市场上有很多目标检测智能识别的相关算法,当前调用一个医疗行业的AI识别算法后返回…...

Java 二维码
Java 二维码 **技术:**谷歌 ZXing 实现 首先添加依赖 <!-- 二维码依赖 --><dependency><groupId>com.google.zxing</groupId><artifactId>core</artifactId><version>3.5.1</version></dependency><de…...

Python 包管理器 uv 介绍
Python 包管理器 uv 全面介绍 uv 是由 Astral(热门工具 Ruff 的开发者)推出的下一代高性能 Python 包管理器和构建工具,用 Rust 编写。它旨在解决传统工具(如 pip、virtualenv、pip-tools)的性能瓶颈,同时…...

LLMs 系列实操科普(1)
写在前面: 本期内容我们继续 Andrej Karpathy 的《How I use LLMs》讲座内容,原视频时长 ~130 分钟,以实操演示主流的一些 LLMs 的使用,由于涉及到实操,实际上并不适合以文字整理,但还是决定尽量整理一份笔…...

作为测试我们应该关注redis哪些方面
1、功能测试 数据结构操作:验证字符串、列表、哈希、集合和有序的基本操作是否正确 持久化:测试aof和aof持久化机制,确保数据在开启后正确恢复。 事务:检查事务的原子性和回滚机制。 发布订阅:确保消息正确传递。 2、性…...

【从零开始学习JVM | 第四篇】类加载器和双亲委派机制(高频面试题)
前言: 双亲委派机制对于面试这块来说非常重要,在实际开发中也是经常遇见需要打破双亲委派的需求,今天我们一起来探索一下什么是双亲委派机制,在此之前我们先介绍一下类的加载器。 目录 编辑 前言: 类加载器 1. …...

LOOI机器人的技术实现解析:从手势识别到边缘检测
LOOI机器人作为一款创新的AI硬件产品,通过将智能手机转变为具有情感交互能力的桌面机器人,展示了前沿AI技术与传统硬件设计的完美结合。作为AI与玩具领域的专家,我将全面解析LOOI的技术实现架构,特别是其手势识别、物体识别和环境…...