一文理解决策树:原理、数学公式与全流程实战讲解
一、背景与来源
决策树(Decision Tree)是一种常见的机器学习算法,主要用于分类和回归问题。其概念来源于统计学和决策论,能够直观地模拟人类的决策过程。最早的决策树算法之一是 1963 年由 Hunt 等人提出的,该算法逐渐发展成为今天的多种改进版本,如 ID3、C4.5、CART 等。
决策树的核心思想是通过递归地将数据集划分为多个子集,形成树状结构。每个内部节点代表一个特征的决策,每个叶子节点则是决策结果(分类或回归值)。
二、数学原理
决策树的构建主要基于“信息增益”(Information Gain)或“基尼不纯度”(Gini Impurity)等指标。其核心思想是逐步选择最佳的特征来划分数据集,从而构建出能够最好地分类或回归的树。
-
信息增益:表示某个特征对分类结果的不确定性的减少量,公式为:
信息增益 = 熵 ( D ) − ∑ i ∣ D i ∣ ∣ D ∣ ⋅ 熵 ( D i ) \text{信息增益} = \text{熵}(D) - \sum_{i} \frac{|D_i|}{|D|} \cdot \text{熵}(D_i) 信息增益=熵(D)−i∑∣D∣∣Di∣⋅熵(Di)
其中,熵(Entropy)是衡量数据集混乱程度的指标,定义为:熵 ( D ) = − ∑ i = 1 n p i log 2 ( p i ) \text{熵}(D) = - \sum_{i=1}^n p_i \log_2(p_i) 熵(D)=−i=1∑npilog2(pi)
p i p_i pi 表示类别 i i i 的概率。 -
基尼不纯度:基尼不纯度用于衡量一个数据集在某特征下的不纯度,定义为:
G ( D ) = 1 − ∑ i = 1 n p i 2 G(D) = 1 - \sum_{i=1}^{n} p_i^2 G(D)=1−i=1∑npi2
p i p_i pi 仍表示类别 i i i 的概率。基尼不纯度越低,数据集越“纯”。
三、 决策树的构建流程
决策树的构建过程可以分为四个主要步骤,按照递归的方式生成树的结构,直到满足终止条件。构建决策树的核心是基于数据集的特征,逐步选择最优特征来进行数据的划分,从而产生不同的子集,直至满足某个停止条件。
1. 选择最优特征
首先,决策树通过选择具有最高信息增益(或最小基尼不纯度)的特征来划分数据。信息增益越大,表示该特征越能有效减少不确定性,从而更好地划分数据。
2. 划分数据集
选择一个特征后,决策树会根据该特征的不同取值将数据集分成不同的子集。对于每一个子集,递归重复选择最优特征来划分数据。
3. 递归生成子树
在每一次划分后,决策树会对子集递归地继续进行相同的过程,直到满足某些停止条件为止:
- 终止条件 1:当前节点的样本都属于同一个类别。此时,不再需要进一步划分。
- 终止条件 2:属性集合为空,或样本在所有属性上取值都相同。此时,无法继续划分,将此节点设置为叶子节点,类别为当前子集中样本最多的类别。
- 终止条件 3:样本集为空。此时,用父节点中最多的类别作为预测值。
4. 剪枝(可选)
为了防止决策树过拟合,有时需要进行剪枝操作。剪枝的过程是去除不必要的分支,保留重要的决策节点,从而提高模型的泛化能力。
剪枝的原因
决策树是一种贪心算法,倾向于不断细化树的每个分支,直到所有数据都被分开。尽管这种方法能够在训练集上取得较好的准确率,但它也容易导致模型过度复杂,从而难以在新的数据上做出准确的预测。这就是过拟合现象。
为了解决这个问题,剪枝通过去除那些对整体预测贡献较小的分支来简化决策树,从而提升模型在新数据上的表现。
剪枝的两种方式
剪枝可以分为两种类型:预剪枝和后剪枝。
(1) 预剪枝(Pre-pruning)
预剪枝是在构建决策树的过程中进行剪枝。具体做法是在划分节点时,提前判断是否需要继续分裂。只有当进一步的分裂能够显著提升模型性能时,才会进行划分,否则将终止划分。这种方法可以减少树的高度,防止生成过于复杂的决策树。
- 预剪枝的判断标准:
- 信息增益阈值:如果节点划分带来的信息增益低于某个设定的阈值,则停止划分。
- 样本数量:当某个节点中的样本数少于某个设定的最小样本数时,停止进一步划分。
- 树的深度:限制树的最大深度,防止树过深导致过拟合。
优点:预剪枝可以有效减少训练时间,因为它避免了生成过于复杂的树。
缺点:预剪枝有时会过早停止分裂,导致模型的表现不如预期。
(2) 后剪枝(Post-pruning)
后剪枝是在生成完整的决策树之后再进行剪枝。该方法首先构建出一棵完整的决策树,然后从底部开始回溯,判断是否需要将某些子树替换为叶节点,从而简化模型。
- 后剪枝的过程:
- 从树的叶节点开始回溯,计算每个非叶节点的误差率。
- 如果将一个子树替换为叶节点后的误差率降低或变化不大,则进行剪枝。
- 重复这一过程,直到不能进一步剪枝。
优点:后剪枝在生成了完全拟合数据的决策树后再进行简化,因此能够避免预剪枝过早停止分裂的问题。
缺点:由于要先构建出一棵完整的决策树,后剪枝的计算成本较高。
剪枝的具体方法
剪枝的目的是减少不必要的分支,通常有几种常见的剪枝技术:
(1) 基于误差的剪枝
在这种方法中,使用 交叉验证 或独立的验证集来评估决策树中每个子树的表现。
具体来说,剪枝的过程是先考虑将一个子树替换为叶节点,计算这种简化后的误差。如果这个替换操作不会显著增加决策树在验证集上的预测误差,那么就进行剪枝操作,否则保留子树。
这种方法的优势在于它通过 独立数据集 的验证,确保剪枝不会过度简化模型。
(2) 最小误差剪枝(Minimal Error Pruning)
最小误差剪枝的核心思想是对比子树和替换为叶节点后的误差率。如果将某个子树替换为叶节点能够减少整体误差率,那么这个子树就可以被剪掉。
误差的衡量标准可以使用均方误差(MSE)或其他相关的损失函数。这种剪枝方法注重减少每一步操作的误差,以提高模型的性能。
(3) 代价复杂度剪枝(Cost Complexity Pruning)
代价复杂度剪枝是CART算法中常用的一种剪枝方法。它通过引入一个代价函数来平衡决策树的复杂度与其对数据拟合的效果。代价复杂度剪枝的目标是最小化以下函数:
R α ( T ) = R ( T ) + α × ∣ T ∣ R_{\alpha}(T) = R(T) + \alpha \times |T| Rα(T)=R(T)+α×∣T∣
其中:
- R ( T ) R(T) R(T) 是子树 T T T 在训练集上的误差;
- ∣ T ∣ |T| ∣T∣ 是树的叶节点数(即树的复杂度);
- α \alpha α 是惩罚参数,用于控制误差和复杂度之间的平衡。
通过调节参数 α \alpha α,可以找到最佳的剪枝程度,即在保证模型预测能力的前提下,尽可能地减少树的复杂度。较大的 α \alpha α 会倾向于生成较小的树,而较小的 α \alpha α 则允许生成更复杂的树。
这种方法有效防止了决策树在训练集上过拟合,同时保留了重要的结构信息。
实例分析:使用 ID3 算法构建决策树
我们将通过一个实际的例子来解释决策树的构建过程。
数据集
假设我们有如下数据集,包含了天气相关的信息以及是否适合进行户外活动的判断(“Yes” or “No”)。数据集有以下 4 个特征:
- 天气(Outlook):有 3 种取值:Sunny、Overcast、Rainy
- 温度(Temperature):有 3 种取值:Hot、Mild、Cool
- 湿度(Humidity):有 2 种取值:High、Normal
- 风速(Wind):有 2 种取值:Weak、Strong
数据表
| Index | Outlook | Temperature | Humidity | Wind | Play Tennis |
|---|---|---|---|---|---|
| 1 | Sunny | Hot | High | Weak | No |
| 2 | Sunny | Hot | High | Strong | No |
| 3 | Overcast | Hot | High | Weak | Yes |
| 4 | Rainy | Mild | High | Weak | Yes |
| 5 | Rainy | Cool | Normal | Weak | Yes |
| 6 | Rainy | Cool | Normal | Strong | No |
| 7 | Overcast | Cool | Normal | Strong | Yes |
| 8 | Sunny | Mild | High | Weak | No |
| 9 | Sunny | Cool | Normal | Weak | Yes |
| 10 | Rainy | Mild | Normal | Weak | Yes |
| 11 | Sunny | Mild | Normal | Strong | Yes |
| 12 | Overcast | Mild | High | Strong | Yes |
| 13 | Overcast | Hot | Normal | Weak | Yes |
| 14 | Rainy | Mild | High | Strong | No |
目标是根据特征预测是否适合 “Play Tennis”(即 “Yes” 或 “No”)。
决策树构建步骤
Step 1:计算熵(Entropy)
首先,我们需要计算 整个数据集 的熵。熵是衡量数据集混乱程度的一个指标。它的公式如下:
熵 ( D ) = − ∑ i = 1 n p i log 2 ( p i ) \text{熵}(D) = -\sum_{i=1}^n p_i \log_2(p_i) 熵(D)=−i=1∑npilog2(pi)
其中, p i p_i pi 表示数据集中每一类的概率。
在这个例子中,数据集中有 9 个 “Yes” 和 5 个 “No”,因此:
p Yes = 9 14 , p No = 5 14 p_{\text{Yes}} = \frac{9}{14}, \quad p_{\text{No}} = \frac{5}{14} pYes=149,pNo=145
熵 H ( D ) H(D) H(D) 为:
H ( D ) = − ( 9 14 log 2 9 14 + 5 14 log 2 5 14 ) = − ( 0.643 × log 2 0.643 + 0.357 × log 2 0.357 ) = 0.940 H(D) = -\left( \frac{9}{14} \log_2 \frac{9}{14} + \frac{5}{14} \log_2 \frac{5}{14} \right) = - \left( 0.643 \times \log_2 0.643 + 0.357 \times \log_2 0.357 \right) = 0.940 H(D)=−(149log2149+145log2145)=−(0.643×log20.643+0.357×log20.357)=0.940
Step 2:计算每个特征的信息增益
1. 天气(Outlook)
有三种可能的取值:Sunny、Overcast、Rainy。我们将根据这些取值划分数据集,然后计算每个子集的熵,并求出信息增益。
-
Sunny:
- 类别:3 个 “No”,2 个 “Yes”
- 熵: H ( S u n n y ) = − ( 3 5 log 2 3 5 + 2 5 log 2 2 5 ) = 0.971 H(Sunny) = -\left( \frac{3}{5} \log_2 \frac{3}{5} + \frac{2}{5} \log_2 \frac{2}{5} \right) = 0.971 H(Sunny)=−(53log253+52log252)=0.971
-
Overcast:
- 类别:4 个全是 “Yes”
- 熵: H ( O v e r c a s t ) = 0 (纯数据集) H(Overcast) = 0 \quad (纯数据集) H(Overcast)=0(纯数据集)
-
Rainy:
- 类别:3 个 “Yes”,2 个 “No”
- 熵: H ( R a i n y ) = − ( 3 5 log 2 3 5 + 2 5 log 2 2 5 ) = 0.971 H(Rainy) = -\left( \frac{3}{5} \log_2 \frac{3}{5} + \frac{2}{5} \log_2 \frac{2}{5} \right) = 0.971 H(Rainy)=−(53log253+52log252)=0.971
加权平均熵:
H ( Outlook ) = 5 14 × 0.971 + 4 14 × 0 + 5 14 × 0.971 = 0.693 H(\text{Outlook}) = \frac{5}{14} \times 0.971 + \frac{4}{14} \times 0 + \frac{5}{14} \times 0.971 = 0.693 H(Outlook)=145×0.971+144×0+145×0.971=0.693
信息增益:
信息增益 ( O u t l o o k ) = H ( D ) − H ( O u t l o o k ) = 0.940 − 0.693 = 0.247 \text{信息增益}(Outlook) = H(D) - H(Outlook) = 0.940 - 0.693 = 0.247 信息增益(Outlook)=H(D)−H(Outlook)=0.940−0.693=0.247
2. 温度(Temperature)
取值有:Hot、Mild、Cool。我们对每个子集计算熵。
-
Hot:
- 类别:2 个 “No”,1 个 “Yes”
- 熵: H ( H o t ) = − ( 2 3 log 2 2 3 + 1 3 log 2 1 3 ) = 0.918 H(Hot) = -\left( \frac{2}{3} \log_2 \frac{2}{3} + \frac{1}{3} \log_2 \frac{1}{3} \right) = 0.918 H(Hot)=−(32log232+31log231)=0.918
-
Mild:
- 类别:2 个 “No”,4 个 “Yes”
- 熵: H ( M i l d ) = − ( 2 6 log 2 2 6 + 4 6 log 2 4 6 ) = 0.918 H(Mild) = -\left( \frac{2}{6} \log_2 \frac{2}{6} + \frac{4}{6} \log_2 \frac{4}{6} \right) = 0.918 H(Mild)=−(62log262+64log264)=0.918
-
Cool:
- 类别:1 个 “No”,3 个 “Yes”
- 熵: H ( C o o l ) = − ( 1 4 log 2 1 4 + 3 4 log 2 3 4 ) = 0.811 H(Cool) = -\left( \frac{1}{4} \log_2 \frac{1}{4} + \frac{3}{4} \log_2 \frac{3}{4} \right) = 0.811 H(Cool)=−(41log241+43log243)=0.811
加权平均熵:
H ( Temperature ) = 3 14 × 0.918 + 6 14 × 0.918 + 4 14 × 0.811 = 0.889 H(\text{Temperature}) = \frac{3}{14} \times 0.918 + \frac{6}{14} \times 0.918 + \frac{4}{14} \times 0.811 = 0.889 H(Temperature)=143×0.918+146×0.918+144×0.811=0.889
信息增益:
信息增益 ( Temperature ) = 0.940 − 0.889 = 0.051 \text{信息增益}(\text{Temperature}) = 0.940 - 0.889 = 0.051 信息增益(Temperature)=0.940−0.889=0.051
3. 湿度(Humidity)
取值有:High、Normal。
- High:
- 类别:4 个 “No”,2 个 “Yes”
- 熵:$$
H(High) = -\left( \frac{4}{6} \log_2 \frac{4}{6
} + \frac{2}{6} \log_2 \frac{2}{6} \right) = 0.918
$$
- Normal:
- 类别:1 个 “No”,6 个 “Yes”
- 熵: H ( N o r m a l ) = − ( 1 7 log 2 1 7 + 6 7 log 2 6 7 ) = 0.592 H(Normal) = -\left( \frac{1}{7} \log_2 \frac{1}{7} + \frac{6}{7} \log_2 \frac{6}{7} \right) = 0.592 H(Normal)=−(71log271+76log276)=0.592
加权平均熵:
H ( Humidity ) = 6 14 × 0.918 + 7 14 × 0.592 = 0.788 H(\text{Humidity}) = \frac{6}{14} \times 0.918 + \frac{7}{14} \times 0.592 = 0.788 H(Humidity)=146×0.918+147×0.592=0.788
信息增益:
信息增益 ( Humidity ) = 0.940 − 0.788 = 0.152 \text{信息增益}(\text{Humidity}) = 0.940 - 0.788 = 0.152 信息增益(Humidity)=0.940−0.788=0.152
4. 风速(Wind)
取值有:Weak、Strong。
-
Weak:
- 类别:2 个 “No”,6 个 “Yes”
- 熵: H ( W e a k ) = − ( 2 8 log 2 2 8 + 6 8 log 2 6 8 ) = 0.811 H(Weak) = -\left( \frac{2}{8} \log_2 \frac{2}{8} + \frac{6}{8} \log_2 \frac{6}{8} \right) = 0.811 H(Weak)=−(82log282+86log286)=0.811
-
Strong:
- 类别:3 个 “No”,3 个 “Yes”
- 熵: H ( S t r o n g ) = − ( 3 6 log 2 3 6 + 3 6 log 2 3 6 ) = 1.000 H(Strong) = -\left( \frac{3}{6} \log_2 \frac{3}{6} + \frac{3}{6} \log_2 \frac{3}{6} \right) = 1.000 H(Strong)=−(63log263+63log263)=1.000
加权平均熵:
H ( Wind ) = 8 14 × 0.811 + 6 14 × 1.000 = 0.892 H(\text{Wind}) = \frac{8}{14} \times 0.811 + \frac{6}{14} \times 1.000 = 0.892 H(Wind)=148×0.811+146×1.000=0.892
信息增益:
信息增益 ( Wind ) = 0.940 − 0.892 = 0.048 \text{信息增益}(\text{Wind}) = 0.940 - 0.892 = 0.048 信息增益(Wind)=0.940−0.892=0.048
Step 3:选择最优特征
通过计算每个特征的信息增益,我们得到:
- Outlook 的信息增益:0.247
- Temperature 的信息增益:0.051
- Humidity 的信息增益:0.152
- Wind 的信息增益:0.048
最优特征是 Outlook,因为它具有最高的信息增益(0.247)。因此,我们将 Outlook 作为根节点进行划分。
第一轮划分(根节点:Outlook)
我们已经根据 Outlook 将数据集分为三个子集:
-
Sunny 子集:
Index Outlook Temperature Humidity Wind Play Tennis 1 Sunny Hot High Weak No 2 Sunny Hot High Strong No 8 Sunny Mild High Weak No 9 Sunny Cool Normal Weak Yes 11 Sunny Mild Normal Strong Yes -
Overcast 子集:
Index Outlook Temperature Humidity Wind Play Tennis 3 Overcast Hot High Weak Yes 7 Overcast Cool Normal Strong Yes 12 Overcast Mild High Strong Yes 13 Overcast Hot Normal Weak Yes -
Rainy 子集:
Index Outlook Temperature Humidity Wind Play Tennis 4 Rainy Mild High Weak Yes 5 Rainy Cool Normal Weak Yes 6 Rainy Cool Normal Strong No 10 Rainy Mild Normal Weak Yes 14 Rainy Mild High Strong No
对 Sunny 子集递归划分
对于 Sunny 子集,我们需要重新计算剩余特征(Temperature、Humidity、Wind)的信息增益,选择最优特征进行下一步划分。
- Sunny 子集熵:
- 类别:3 个 “No”,2 个 “Yes”
- 总熵: H ( S u n n y ) = − ( 3 5 log 2 3 5 + 2 5 log 2 2 5 ) = 0.971 H(Sunny) = -\left( \frac{3}{5} \log_2 \frac{3}{5} + \frac{2}{5} \log_2 \frac{2}{5} \right) = 0.971 H(Sunny)=−(53log253+52log252)=0.971
1. 计算 Temperature 的信息增益
在 Sunny 子集中,Temperature 有三个取值:Hot、Mild、Cool。
- Hot:2 个 “No”
- 熵: H ( H o t ) = − ( 2 2 log 2 2 2 ) = 0 H(Hot) = -\left( \frac{2}{2} \log_2 \frac{2}{2} \right) = 0 H(Hot)=−(22log222)=0
- Mild:1 个 “No”,1 个 “Yes”
- 熵: H ( M i l d ) = − ( 1 2 log 2 1 2 + 1 2 log 2 1 2 ) = 1 H(Mild) = -\left( \frac{1}{2} \log_2 \frac{1}{2} + \frac{1}{2} \log_2 \frac{1}{2} \right) = 1 H(Mild)=−(21log221+21log221)=1
- Cool:1 个 “Yes”
- 熵: H ( C o o l ) = − ( 1 1 log 2 1 1 ) = 0 H(Cool) = -\left( \frac{1}{1} \log_2 \frac{1}{1} \right) = 0 H(Cool)=−(11log211)=0
加权平均熵:
H ( Temperature ) = 2 5 × 0 + 2 5 × 1 + 1 5 × 0 = 0.4 H(\text{Temperature}) = \frac{2}{5} \times 0 + \frac{2}{5} \times 1 + \frac{1}{5} \times 0 = 0.4 H(Temperature)=52×0+52×1+51×0=0.4
信息增益:
信息增益 ( Temperature ) = 0.971 − 0.4 = 0.571 \text{信息增益}(\text{Temperature}) = 0.971 - 0.4 = 0.571 信息增益(Temperature)=0.971−0.4=0.571
2. 计算 Humidity 的信息增益
Humidity 有两个取值:High 和 Normal。
- High:3 个 “No”
- 熵: H ( H i g h ) = − ( 3 3 log 2 3 3 ) = 0 H(High) = -\left( \frac{3}{3} \log_2 \frac{3}{3} \right) = 0 H(High)=−(33log233)=0
- Normal:2 个 “Yes”
- 熵: H ( N o r m a l ) = − ( 2 2 log 2 2 2 ) = 0 H(Normal) = -\left( \frac{2}{2} \log_2 \frac{2}{2} \right) = 0 H(Normal)=−(22log222)=0
加权平均熵:
H ( Humidity ) = 3 5 × 0 + 2 5 × 0 = 0 H(\text{Humidity}) = \frac{3}{5} \times 0 + \frac{2}{5} \times 0 = 0 H(Humidity)=53×0+52×0=0
信息增益:
信息增益 ( Humidity ) = 0.971 − 0 = 0.971 \text{信息增益}(\text{Humidity}) = 0.971 - 0 = 0.971 信息增益(Humidity)=0.971−0=0.971
3. 计算 Wind 的信息增益
Wind 有两个取值:Weak 和 Strong。
- Weak:2 个 “No”,1 个 “Yes”
- 熵: H ( W e a k ) = − ( 2 3 log 2 2 3 + 1 3 log 2 1 3 ) = 0.918 H(Weak) = -\left( \frac{2}{3} \log_2 \frac{2}{3} + \frac{1}{3} \log_2 \frac{1}{3} \right) = 0.918 H(Weak)=−(32log232+31log231)=0.918
- Strong:1 个 “No”,1 个 “Yes”
- 熵: H ( S t r o n g ) = − ( 1 2 log 2 1 2 + 1 2 log 2 1 2 ) = 1 H(Strong) = -\left( \frac{1}{2} \log_2 \frac{1}{2} + \frac{1}{2} \log_2 \frac{1}{2} \right) = 1 H(Strong)=−(21log221+21log221)=1
加权平均熵:
H ( Wind ) = 3 5 × 0.918 + 2 5 × 1 = 0.951 H(\text{Wind}) = \frac{3}{5} \times 0.918 + \frac{2}{5} \times 1 = 0.951 H(Wind)=53×0.918+52×1=0.951
信息增益:
信息增益 ( Wind ) = 0.971 − 0.951 = 0.020 \text{信息增益}(\text{Wind}) = 0.971 - 0.951= 0.020 信息增益(Wind)=0.971−0.951=0.020
选择最优特征
通过比较 Sunny 子集中各特征的信息增益,Humidity 拥有最高的信息增益(0.971),因此选择 Humidity 作为划分标准。将 Sunny 子集按照 Humidity 划分成两个子集。
- High 子集:全部为 “No”,直接作为叶节点,标记为 “No”。
- Normal 子集:全部为 “Yes”,直接作为叶节点,标记为 “Yes”。
此时,Sunny 子集的递归过程结束,节点结构如下:
Outlook = Sunny-> Humidity = High: No-> Humidity = Normal: Yes
对 Overcast 子集递归划分
对于 Overcast 子集:
| Index | Outlook | Temperature | Humidity | Wind | Play Tennis |
|---|---|---|---|---|---|
| 3 | Overcast | Hot | High | Weak | Yes |
| 7 | Overcast | Cool | Normal | Strong | Yes |
| 12 | Overcast | Mild | High | Strong | Yes |
| 13 | Overcast | Hot | Normal | Weak | Yes |
该子集中全部样本类别为 “Yes”,因此直接返回 “Yes” 作为该节点的叶节点。
对 Rainy 子集递归划分
对于 Rainy 子集,类似于对 Sunny 子集的划分,依次计算剩余特征的熵和信息增益,选择最优特征进行划分。最终的结构可能类似如下:
Outlook = Rainy-> Wind = Weak: Yes-> Wind = Strong: No
递归终止条件
递归过程需要满足一定的条件来停止继续划分。当满足以下任何一个条件时,递归过程会停止,当前节点会被标记为叶节点。
终止条件 1:同一类别
如果某个子集中的所有样本都属于同一个类别,则无需继续划分,该节点直接标记为该类别的叶节点。例如,所有样本的类别都是 “Yes”,则该节点为 “Yes” 类别的叶节点。
终止条件 2:属性为空或样本在所有属性上的取值相同
如果子集中的样本在所有剩余属性上的取值相同,无法进一步划分。此时无法区分不同类别,直接返回该节点中多数类别作为该节点的预测类别。
举例说明:
- 假设划分后的一个子集中,所有样本在
Temperature、Humidity和Wind属性上取值完全相同,但类别不同。这种情况下,因为没有其他属性可以进一步区分样本,返回多数类别作为预测结果。
终止条件 3:样本集合为空
如果划分过程中某一分支没有样本(即子集为空),则无法继续划分。此时应返回父节点中的多数类别作为该分支的预测结果
最终决策树结构
根据递归划分过程,最终构建的决策树结构如下:
Outlook
├── Sunny
│ ├── Humidity = High: No
│ └── Humidity = Normal: Yes
├── Overcast: Yes
└── Rainy├── Wind = Weak: Yes└── Wind = Strong: No
- 根节点:
Outlook:决策树首先根据Outlook(天气)这个特征将数据集分成三个子集:- 如果
Outlook = Sunny,则进一步根据Humidity划分:Humidity = High时,预测为 “No”。Humidity = Normal时,预测为 “Yes”。
- 如果
Outlook = Overcast,预测为 “Yes”。因为所有样本都是 “Yes”。 - 如果
Outlook = Rainy,则进一步根据Wind划分:Wind = Weak时,预测为 “Yes”。Wind = Strong时,预测为 “No”。
- 如果
总结
通过递归划分特征,决策树将复杂的分类问题逐步分解为简单的条件判断。我们使用信息增益选择最优特征,直到满足停止条件。最终生成的决策树结构直观、易解释,能够根据特征的不同取值来预测是否适合打网球。
决策树的构建过程清晰体现了数据集划分的逐步细化,通过特征选择、子集划分与递归处理,生成了一棵结构化的树来进行分类任务。这一模型不仅简洁直观,也为实际应用中的分类问题提供了强有力的支持。
相关文章:

一文理解决策树:原理、数学公式与全流程实战讲解
一、背景与来源 决策树(Decision Tree)是一种常见的机器学习算法,主要用于分类和回归问题。其概念来源于统计学和决策论,能够直观地模拟人类的决策过程。最早的决策树算法之一是 1963 年由 Hunt 等人提出的,该算法逐渐…...

day04-LogStash扩展
1.LogStash性能不稳定(某天关闭后,再次启动就非常慢),所以后面我们用Filebeat。2.先禁用 # geoip { # source > "clientip" # }3.在生产中要是用nignx服务或tomcat服务我们用EFK架构就可以排查技巧观察点 LogS…...
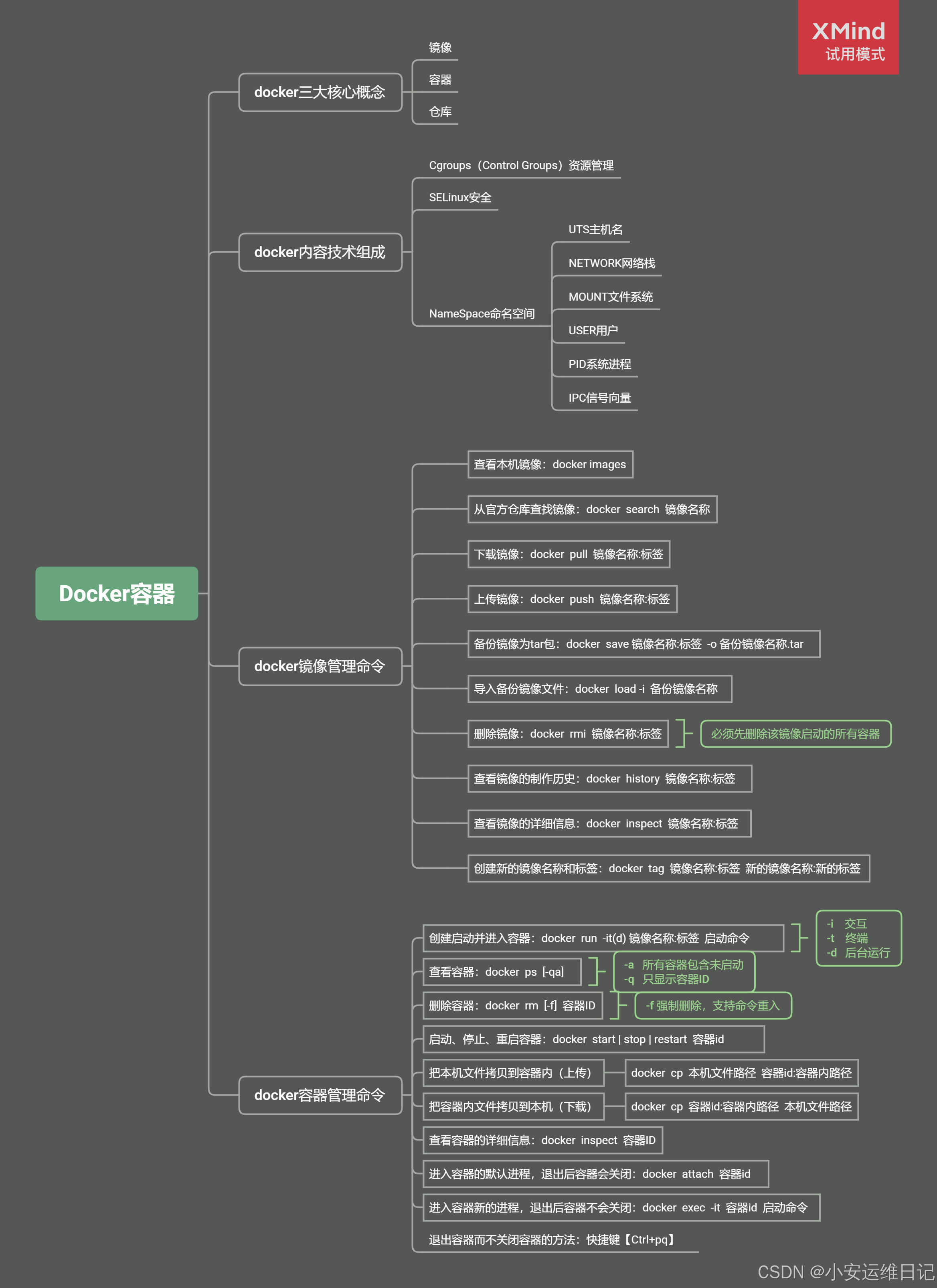
Linux云计算 |【第五阶段】CLOUD-DAY4
主要内容: Linux容器基础、安装Docker、镜像管理、容器管理、容器部署应用 一、容器介绍 容器(Container) 是一种轻量级的虚拟化技术,用于在操作系统级别隔离应用程序及其依赖项。容器允许开发者在同一台主机上运行多个独立的应…...

为什么QNAP威联通NAS的APP center无法安装APP?
创作立场:原创不易,拒绝搬运~ hello大家好,我是你们的老伙伴,稳重的大王~ 如题,大王带你一起来排查一下,可能遇到的问题。如有帮助,请给个关注鼓励,互谢~ 1 首先,安装…...

Kafka 基础入门
文章内容是学习过程中的知识总结,如有纰漏,欢迎指正 文章目录 前言 1. 核心概念 1.1 Producer 1.2 broker 1.3 consumer 1.4 zookeeper 1.5 controller 1.6 Cluster 2. 逻辑组件 2.1 Topic 2.2 Partition 2.3 Replication 2.4 leader & follower 3. …...

网络问题排查
1.ping 域名发现响应时间很长,怎么分析卡在哪里? 当你在 Linux 系统中 ping 一个域名并发现响应时间很长时,可能存在于多个环节的问题。以下是一些步骤和工具,可以帮助你分析和诊断问题出在哪里: 1. 检查 DNS 解析时…...

webGlL变量的声明与使用
抢先观看: 变量的声明格式:<存储限定符><类型限定符><变量名> 存储限定符:const, attribute, uniform, varying, buffer。 类型限定符:void, bool, int, float, double, vec2, vec3, vec4, mat2, mat3, mat4, s…...

qt的c++环境配置和c++基础【正点原子】嵌入式Qt5 C++开发视频
QT c 环境配置和c基础 c环境配置和工程创建 1.配置步骤 2.新建qt 工程目录和工程 3.重启qt后打开最近的qt项目 c基础-类和对象 1.什么是类和对象 A.类的定义 B.类的结构表示 C.类的访问权限 D.对象的定义 E.类和对象的关系 2.类…...

中间件安全(三)
本文仅作为学习参考使用,本文作者对任何使用本文进行渗透攻击破坏不负任何责任。 前言: 本文主要讲解apache命令执行漏洞(cve_2021_41773)。 靶场链接:Vulfocus 漏洞威胁分析平台 一,漏洞简介。 cve_2021_41773漏洞…...

唱戏机上的内存卡怎么加密?教你两个方法
唱戏机是中老年人群休闲时光的好伴侣。然而,很多唱戏机商家都会面临一个困扰:如何保护唱戏机上内存卡中的音频,避免他人随意复制呢?今天这篇文章看完,问题将迎刃而解~ 数据隐藏 将内存卡插到电脑上,对卡里…...
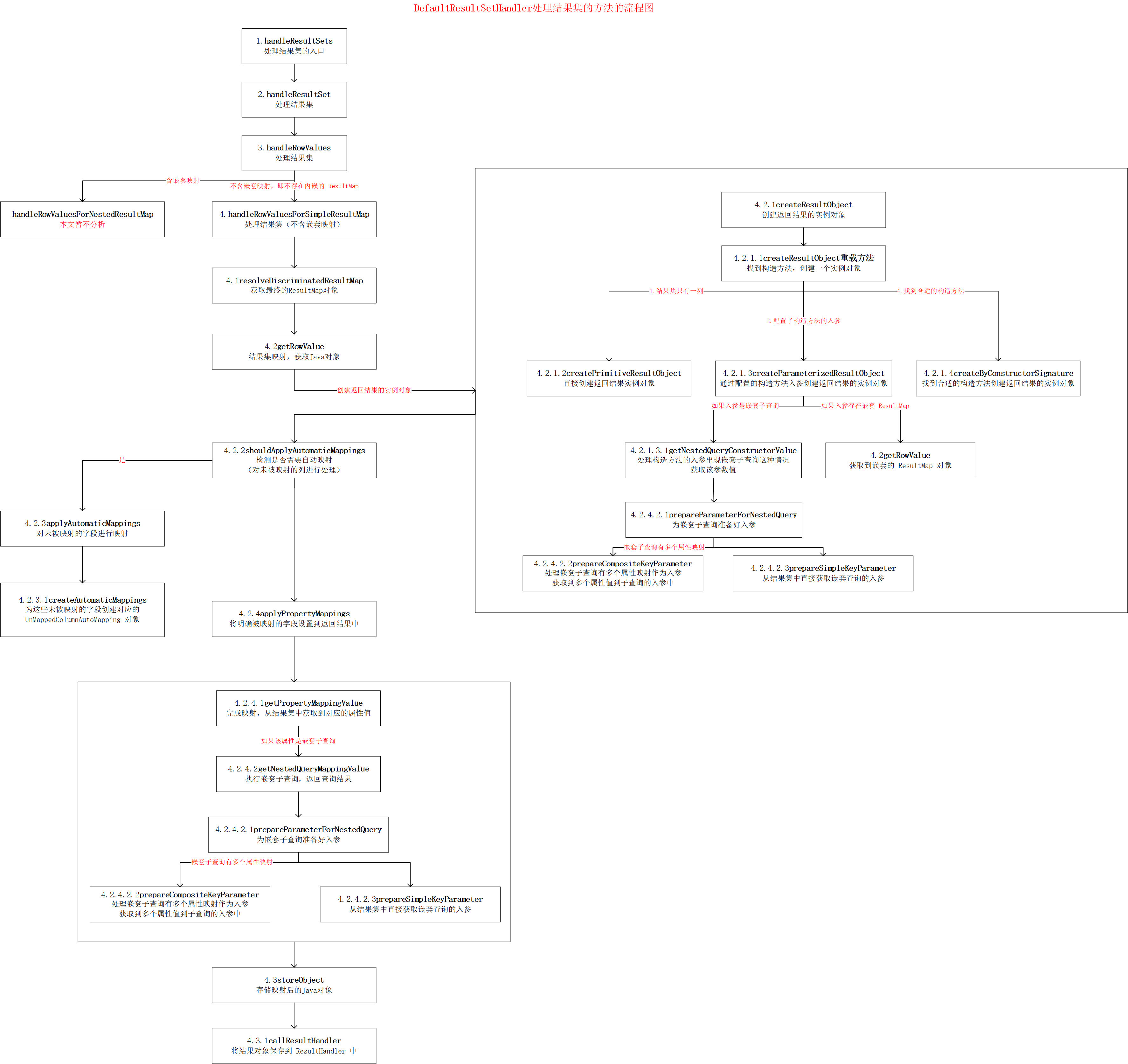
MyBatis 源码分析 - SQL执行过程(三)之 ResultSetHandler
MyBatis的SQL执行过程 在前面一系列的文档中,我已经分析了 MyBatis 的基础支持层以及整个的初始化过程,此时 MyBatis 已经处于就绪状态了,等待使用者发号施令了 那么接下来我们来看看它执行SQL的整个过程,该过程比较复杂ÿ…...

webpack解决使用window.open方法打开history路由页面提示404的问题
问题: 一般情况下应该使用history.push(/ssh)打开history路由页面 但项目中使用window.open(/ssh),然后使用new WebSocket进行通信 开发环境下启动项目后,/ssh页面打开却显示cannot get /ssh,控制台提示404 排查问题: 在React开发环境中使用 window.open 打开路由页面时&a…...

怎么把视频的声音转化为文字免费?7个小妙招,视频转文字轻松解决!
您是否也曾在做会议记录时,希望能免费把视频的声音转化为文字呢?在如今我们的办公生活中,用视频记录会议、记录的生活似乎已经成为了我们一项必备技能,但也并非所有人都能轻松获取视频中的信息。尤其是有着听力障碍的人群…...

【无标题】2024年第五届 MathorCup 数学应用挑战赛——大数据竞赛赛题
2024年第五届 MathorCup 数学应用挑战赛——大数据竞赛赛题已发布~,本届初赛时间为:2024年10月25日18:00至2024年11月1日20:00。本次赛题分为A,B两道,所有参赛队从赛道 A、B 中任选一题作答。在报名系统内选择自己队伍的赛道时&am…...

新能源行业必会基础知识---电力现货问答---第9问---什么是输电权?什么是输电权市场?
新能源行业必会基础知识-----电力现货问答-----主目录-----持续更新https://blog.csdn.net/grd_java/article/details/142909208 虽然这本书已经出来有几年了,现货市场已经产生了一定变化,但是原理还是相通的。还是推荐大家买来这本书进行阅读观看&#…...

视频文案素材获取渠道分享
做视频时为文案发愁?别担心!今天为大家推荐几个实用的视频文案素材网站,让你灵感爆棚,轻松创作文案。 蛙学网 首先要推荐的是蛙学网。作为专业短视频素材库,不仅有修牛蹄、解压视频等热门素材,还为短视频创…...

尚硅谷-react教程-求和案例-数据共享(下篇)-完成数据共享-笔记
#1024程序员节|征文# public/index.html <!DOCTYPE html> <html><head><meta charset"UTF-8"><title>redux</title></head><body><div id"root"></div></body> </html&…...

VB中如何创建和使用自定义控件
在Visual Basic(VB)中,创建和使用自定义控件是一个高级功能,它允许开发者根据特定需求创建具有独特行为和外观的控件。以下是在VB中创建和使用自定义控件的一般步骤: 一、创建自定义控件 打开VB开发环境: …...

Java继承的super关键字
在Java中,super关键字用于调用父类的构造方法、访问父类的成员变量和成员方法。 调用父类的构造方法: 在子类的构造方法中,可以使用super关键字来调用父类的构造方法。这可以帮助子类初始化从父类继承的属性。调用父类的构造方法要使用以下语…...

3D点云与2D图像的相互转换:2D图像对应像素的坐标 转为3D空间的对应坐标
2d ----> 3d 对应像素到空间坐标的转换 参考:深度相机,通过2d检测得到目标坐标系的3d检测框_深度图到相机坐标-CSDN博客...

Appium+python自动化(十六)- ADB命令
简介 Android 调试桥(adb)是多种用途的工具,该工具可以帮助你你管理设备或模拟器 的状态。 adb ( Android Debug Bridge)是一个通用命令行工具,其允许您与模拟器实例或连接的 Android 设备进行通信。它可为各种设备操作提供便利,如安装和调试…...

【JVM】- 内存结构
引言 JVM:Java Virtual Machine 定义:Java虚拟机,Java二进制字节码的运行环境好处: 一次编写,到处运行自动内存管理,垃圾回收的功能数组下标越界检查(会抛异常,不会覆盖到其他代码…...

高频面试之3Zookeeper
高频面试之3Zookeeper 文章目录 高频面试之3Zookeeper3.1 常用命令3.2 选举机制3.3 Zookeeper符合法则中哪两个?3.4 Zookeeper脑裂3.5 Zookeeper用来干嘛了 3.1 常用命令 ls、get、create、delete、deleteall3.2 选举机制 半数机制(过半机制࿰…...

ESP32 I2S音频总线学习笔记(四): INMP441采集音频并实时播放
简介 前面两期文章我们介绍了I2S的读取和写入,一个是通过INMP441麦克风模块采集音频,一个是通过PCM5102A模块播放音频,那如果我们将两者结合起来,将麦克风采集到的音频通过PCM5102A播放,是不是就可以做一个扩音器了呢…...
)
GitHub 趋势日报 (2025年06月08日)
📊 由 TrendForge 系统生成 | 🌐 https://trendforge.devlive.org/ 🌐 本日报中的项目描述已自动翻译为中文 📈 今日获星趋势图 今日获星趋势图 884 cognee 566 dify 414 HumanSystemOptimization 414 omni-tools 321 note-gen …...

UR 协作机器人「三剑客」:精密轻量担当(UR7e)、全能协作主力(UR12e)、重型任务专家(UR15)
UR协作机器人正以其卓越性能在现代制造业自动化中扮演重要角色。UR7e、UR12e和UR15通过创新技术和精准设计满足了不同行业的多样化需求。其中,UR15以其速度、精度及人工智能准备能力成为自动化领域的重要突破。UR7e和UR12e则在负载规格和市场定位上不断优化…...

Android Bitmap治理全解析:从加载优化到泄漏防控的全生命周期管理
引言 Bitmap(位图)是Android应用内存占用的“头号杀手”。一张1080P(1920x1080)的图片以ARGB_8888格式加载时,内存占用高达8MB(192010804字节)。据统计,超过60%的应用OOM崩溃与Bitm…...

听写流程自动化实践,轻量级教育辅助
随着智能教育工具的发展,越来越多的传统学习方式正在被数字化、自动化所优化。听写作为语文、英语等学科中重要的基础训练形式,也迎来了更高效的解决方案。 这是一款轻量但功能强大的听写辅助工具。它是基于本地词库与可选在线语音引擎构建,…...

Proxmox Mail Gateway安装指南:从零开始配置高效邮件过滤系统
💝💝💝欢迎莅临我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:「storms…...

从物理机到云原生:全面解析计算虚拟化技术的演进与应用
前言:我的虚拟化技术探索之旅 我最早接触"虚拟机"的概念是从Java开始的——JVM(Java Virtual Machine)让"一次编写,到处运行"成为可能。这个软件层面的虚拟化让我着迷,但直到后来接触VMware和Doc…...