LuaJIT源码分析(五)词法分析
LuaJIT源码分析(五)词法分析
lua虽然是脚本语言,但在执行时,还是先将脚本编译成字节码,然后再由虚拟机解释执行。在编译脚本时,首先需要对源代码进行词法分析,把源代码分解为token流。lua的token可以分为若干不同的类型,比如关键字,标识符,字面量,运算符,分隔符等等。
标识符
可以是由字母、数字和下划线组成的任意字符串,但不能以数字开头。
关键字
具有特殊含义的保留字,不可以用作标识符,共有22个。
and break do else elseifend false for function ifin local nil not orrepeat return then true until while
字符串字面常量
lua的字面字符串定义相当灵活,以下几种写法都是合法的,而且表示同一个字符串:
a = 'alo\n123"'a = "alo\n123\""a = '\97lo\10\04923"'a = [[alo123"]]a = [==[alo123"]==]
数字字面常量
一个数值常量可以用可选的小数部分和可选的小数指数来表示。lua还接受十六进制整数常量,通过在前面加上0x来表示。以下几种表示形式都是合法的:
3 3.0 3.1416 314.16e-2 0.31416E1 0xff 0x56
运算符和分隔符
主要有以下若干种。
+ - * / % ^ #== ~= <= >= < > =( ) { } [ ]; : , . .. ...
LuaJIT的词法分析代码集中在lex_scan这个函数上。在深入之前,我们先了解一下LuaJIT用于词法分析的数据结构。
// lj_lex.h
/* Lua lexer state. */
typedef struct LexState {struct FuncState *fs; /* Current FuncState. Defined in lj_parse.c. */struct lua_State *L; /* Lua state. */TValue tokval; /* Current token value. */TValue lookaheadval; /* Lookahead token value. */const char *p; /* Current position in input buffer. */const char *pe; /* End of input buffer. */LexChar c; /* Current character. */LexToken tok; /* Current token. */LexToken lookahead; /* Lookahead token. */SBuf sb; /* String buffer for tokens. */lua_Reader rfunc; /* Reader callback. */void *rdata; /* Reader callback data. */BCLine linenumber; /* Input line counter. */BCLine lastline; /* Line of last token. */GCstr *chunkname; /* Current chunk name (interned string). */const char *chunkarg; /* Chunk name argument. */const char *mode; /* Allow loading bytecode (b) and/or source text (t). */VarInfo *vstack; /* Stack for names and extents of local variables. */MSize sizevstack; /* Size of variable stack. */MSize vtop; /* Top of variable stack. */BCInsLine *bcstack; /* Stack for bytecode instructions/line numbers. */MSize sizebcstack; /* Size of bytecode stack. */uint32_t level; /* Syntactical nesting level. */int endmark; /* Trust bytecode end marker, even if not at EOF. */int fr2; /* Generate bytecode for LJ_FR2 mode. */
} LexState;
数据结构看上去很复杂,不过好在每个成员变量都有相应的注释,而且在目前讨论的词法分析阶段中,只有少数几个成员变量需要考虑:
// lj_lex.h
/* Lua lexer state. */
typedef struct LexState {TValue tokval; /* Current token value. */TValue lookaheadval; /* Lookahead token value. */const char *p; /* Current position in input buffer. */const char *pe; /* End of input buffer. */LexChar c; /* Current character. */LexToken tok; /* Current token. */LexToken lookahead; /* Lookahead token. */SBuf sb; /* String buffer for tokens. */
} LexState;
tokval和lookaheadval分别表示当前扫描到的token和下一个即将被扫描的token;p和pe表示扫描的源代码buffer当前位置和重点位置;c表示当前扫描到的字符;tok和lookahead分别表示当前和下一个扫描的token类型;最后sb表示处理当前token所缓存的buffer。
LuaJIT的词法分析实现基本上也是个有限状态机,根据当前读到的字符,切换到不同的读取状态:
/* Get next lexical token. */
static LexToken lex_scan(LexState *ls, TValue *tv)
{lj_buf_reset(&ls->sb);for (;;) {if (lj_char_isident(ls->c)) {GCstr *s;if (lj_char_isdigit(ls->c)) { /* Numeric literal. */lex_number(ls, tv);return TK_number;}/* Identifier or reserved word. */do {lex_savenext(ls);} while (lj_char_isident(ls->c));s = lj_parse_keepstr(ls, ls->sb.b, sbuflen(&ls->sb));setstrV(ls->L, tv, s);if (s->reserved > 0) /* Reserved word? */return TK_OFS + s->reserved;return TK_name;}switch (ls->c) {case '\n':case '\r':lex_newline(ls);continue;case ' ':case '\t':case '\v':case '\f':lex_next(ls);continue;case '-':lex_next(ls);if (ls->c != '-') return '-';lex_next(ls);if (ls->c == '[') { /* Long comment "--[=*[...]=*]". */int sep = lex_skipeq(ls);lj_buf_reset(&ls->sb); /* `lex_skipeq' may dirty the buffer */if (sep >= 0) {lex_longstring(ls, NULL, sep);lj_buf_reset(&ls->sb);continue;}}/* Short comment "--.*\n". */while (!lex_iseol(ls) && ls->c != LEX_EOF)lex_next(ls);continue;case '[': {int sep = lex_skipeq(ls);if (sep >= 0) {lex_longstring(ls, tv, sep);return TK_string;} else if (sep == -1) {return '[';} else {lj_lex_error(ls, TK_string, LJ_ERR_XLDELIM);continue;}}case '=':lex_next(ls);if (ls->c != '=') return '='; else { lex_next(ls); return TK_eq; }case '<':lex_next(ls);if (ls->c != '=') return '<'; else { lex_next(ls); return TK_le; }case '>':lex_next(ls);if (ls->c != '=') return '>'; else { lex_next(ls); return TK_ge; }case '~':lex_next(ls);if (ls->c != '=') return '~'; else { lex_next(ls); return TK_ne; }case ':':lex_next(ls);if (ls->c != ':') return ':'; else { lex_next(ls); return TK_label; }case '"':case '\'':lex_string(ls, tv);return TK_string;case '.':if (lex_savenext(ls) == '.') {lex_next(ls);if (ls->c == '.') {lex_next(ls);return TK_dots; /* ... */}return TK_concat; /* .. */} else if (!lj_char_isdigit(ls->c)) {return '.';} else {lex_number(ls, tv);return TK_number;}case LEX_EOF:return TK_eof;default: {LexChar c = ls->c;lex_next(ls);return c; /* Single-char tokens (+ - / ...). */}}}
}
lex_scan会返回当前扫描的token类型,LuaJIT只对那些不能用单字符表示的token,进行了定义,如果token本身就是单字符的,比如( + - / )之类,就直接用该字符作为它的token类型。由于char的取值范围为0-255,那么特殊定义的token类型,需要从256开始了。
// lj_lex.h
/* Lua lexer tokens. */
#define TKDEF(_, __) \_(and) _(break) _(do) _(else) _(elseif) _(end) _(false) \_(for) _(function) _(goto) _(if) _(in) _(local) _(nil) _(not) _(or) \_(repeat) _(return) _(then) _(true) _(until) _(while) \__(concat, ..) __(dots, ...) __(eq, ==) __(ge, >=) __(le, <=) __(ne, ~=) \__(label, ::) __(number, <number>) __(name, <name>) __(string, <string>) \__(eof, <eof>)enum {TK_OFS = 256,
#define TKENUM1(name) TK_##name,
#define TKENUM2(name, sym) TK_##name,
TKDEF(TKENUM1, TKENUM2)
#undef TKENUM1
#undef TKENUM2TK_RESERVED = TK_while - TK_OFS
};
可能会有疑问的一点是,为什么这里要引入TKENUM1和TKENUM2两种不同的宏,明明作用完全相同。答案是作者为了简洁,少写一些代码,把LuaJIT的关键字定义,也套用到了TKDEF这个宏上:
// lj_lex.c
/* Lua lexer token names. */
static const char *const tokennames[] = {
#define TKSTR1(name) #name,
#define TKSTR2(name, sym) #sym,
TKDEF(TKSTR1, TKSTR2)
#undef TKSTR1
#undef TKSTR2NULL
};
接下来我们回到lex_scan函数上,首先函数会调用lj_buf_reset清理缓存的token buffer,这个buffer只在单次scan中有效。然后,LuaJIT开始判断当前字符是一个什么样的字符。这里LuaJIT使用了查表的方式,预先将ASCII表中的所有字符进行属性标记。
// lj_char.h
#define LJ_CHAR_CNTRL 0x01
#define LJ_CHAR_SPACE 0x02
#define LJ_CHAR_PUNCT 0x04
#define LJ_CHAR_DIGIT 0x08
#define LJ_CHAR_XDIGIT 0x10
#define LJ_CHAR_UPPER 0x20
#define LJ_CHAR_LOWER 0x40
#define LJ_CHAR_IDENT 0x80
#define LJ_CHAR_ALPHA (LJ_CHAR_LOWER|LJ_CHAR_UPPER)
#define LJ_CHAR_ALNUM (LJ_CHAR_ALPHA|LJ_CHAR_DIGIT)
#define LJ_CHAR_GRAPH (LJ_CHAR_ALNUM|LJ_CHAR_PUNCT)LJ_DATA const uint8_t lj_char_bits[257];
剩下的逻辑其实就比较简单了,如果当前字符是数字,那么就走假设token是数字字面常量的逻辑;如果是字母下划线,那就走关键字或是标识符的逻辑;否则就走其他处理逻辑。这些处理逻辑都比较简单,如果只通过当前字符无法判断token类型,就会去读取下一个字符甚至更多字符来进行判断。例如遇到字符.时,会尝试再读取一个字符,如果依旧是.,那么还需要再读一个字符来确定当前token是TK_dots ...还是TK_concat ..;如果不是,那么根据字符是否为数字,就能得出token是TK_number还是.类型了。
相关文章:
词法分析)
LuaJIT源码分析(五)词法分析
LuaJIT源码分析(五)词法分析 lua虽然是脚本语言,但在执行时,还是先将脚本编译成字节码,然后再由虚拟机解释执行。在编译脚本时,首先需要对源代码进行词法分析,把源代码分解为token流。lua的toke…...

005 匿名信
005 匿名信 题目描述 电视剧《分界线》里面有一个片段,男主为了向警察透露案件细节,且不暴露自己,于是将报刊上的字剪下来,剪拼成一封匿名信。现在有一名举报人,希望借鉴这种方式,使用英文报刊完成举报操…...

聊聊Web3D 发展趋势
随着 Web 技术的不断演进,Web3D 正逐渐成为各行业数字化的重要方向。Web3D 是指在网页中展示 3D 内容的技术集合。近年来,由于 WebGL、WebGPU 等技术的发展,3D 内容已经能够直接在浏览器中渲染,为用户提供更加沉浸、互动的体验。以…...

【数据结构与算法】LeetCode: 贪心算法
文章目录 LeetCode: 贪心算法买卖股票的最佳时机 (Hot100)买卖股票的最佳时机 II跳跃游戏 (Hot100)跳跃游戏 II(Hot100)划分字母区间 (Hot100)分发饼干K次取反后最大化的…...

Date 日期类的实现(c++)
本文用c实现日期类 将会实现以下函数 bool operator<(const Date& d);bool operator<(const Date& d);bool operator>(const Date& d);bool operator>(const Date& d);bool operator(const Date& d);bool operator!(const Date& d);Date&…...

智能家居10G雷达感应开关模块,飞睿智能uA级别低功耗、超高灵敏度,瞬间响应快
在当今科技飞速发展的时代,智能家居已经逐渐成为人们生活中不可或缺的一部分。从智能灯光控制到智能家电的联动,每一个细节都在为我们的生活带来便利和舒适。而在众多智能家居产品中,10G 雷达感应开关模块以其独特的优势,正逐渐成…...

头歌——人工智能(机器学习 --- 决策树2)
文章目录 第5关:基尼系数代码 第6关:预剪枝与后剪枝代码 第7关:鸢尾花识别代码 第5关:基尼系数 基尼系数 在ID3算法中我们使用了信息增益来选择特征,信息增益大的优先选择。在C4.5算法中,采用了信息增益率…...

一七一、React性能优化方式
在 React 中进行性能优化可以通过多种手段来减少渲染次数、优化渲染效率并减少内存消耗。以下是常见的性能优化方法及示例: 1. shouldComponentUpdate shouldComponentUpdate 是类组件中的生命周期方法,它可以让组件在判断是否需要重新渲染时ÿ…...

编写dockerfile生成镜像,并且构建容器运行
编写dockerfile生成镜像,并且构建容器运行 目录 编写dockerfile生成镜像,并且构建容器运行 概述 一、dockerfile文件详解 Dockerfile的基本结构 Dockerfile的常用指令 二、构建过程 概述 随着微服务应用越来越多,大家需要尽快掌握dock…...

Java项目练习——学生管理系统
1. 整体结构 代码实现了基本的学生管理系统功能,包括登录、注册、忘记密码、添加、删除、修改和查询学生信息。 使用了ArrayList来存储用户和学生信息。 使用了Scanner类来处理用户输入。 2. 主要功能模块 登录 (logIn):验证用户名和密码,…...

sqlserver、达梦、mysql的差异
差异项sqlserver达梦mysql单行注释---- 1、-- ,--后面带个空格 2、# 包裹对象名称,如表、表字段等 [tableName] "tableName"tableName表字段自增IDENTITY(1, 1)IDENTITY(1, 1)AUTO_INCREMENT二进制数据类型IMAGEIMAGE、BLOBBLOB 存储一个汉字需…...

Spring AOP(定义、使用场景、用法、3种事务、事务失效场景及解决办法、面试题)
目录 1. AOP定义? 2.常见的AOP使用场景: 3.Spring AOP用法 3.1 Spring AOP中的几个核心概念 3.1.1 切面、切点、通知、连接点 3.1.2 切点表达式AspectJ 3.2 使用 Spring AOP 的步骤总结 3.2.1 添加依赖: 3.2.2 定义切面和切点(切点和…...

Flutter鸿蒙next 封装对话框详解
✅近期推荐:求职神器 https://bbs.csdn.net/topics/619384540 🔥欢迎大家订阅系列专栏:flutter_鸿蒙next 💬淼学派语录:只有不断的否认自己和肯定自己,才能走出弯曲不平的泥泞路,因为平坦的大路…...
【项目实战】通过LLaMaFactory+Qwen2-VL-2B微调一个多模态医疗大模型
前言 随着多模态大模型的发展,其不仅限于文字处理,更能够在图像、视频、音频方面进行识别与理解。医疗领域中,医生们往往需要对各种医学图像进行处理,以辅助诊断和治疗。如果将多模态大模型与图像诊断相结合,那么这会…...

SCSI驱动与 UFS 驱动交互概况
SCSI子系统概况 SCSI(Small Computer System Interface)子系统是 Linux 中的一个模块化框架,用于提供与存储设备的通用接口。通过 SCSI 子系统,可以支持不同类型的存储协议(如 UFS、SATA、SAS),…...

软件工程实践项目:人事管理系统
一、项目的需求说明 通过移动设备登录app提供简单、方便的操作。根据公司原来的考勤管理制度,为公司不同管理层次提供相应的权限功能。通过app上面的各种标准操作,考勤管理无纸化的实现,使公司的考勤管理更加科学规范,从而节省考…...
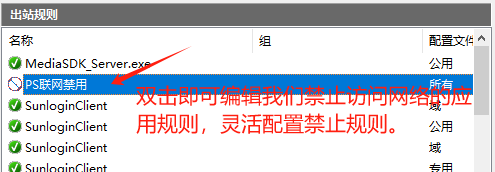
不使用三方软件,win系统下禁止单个应用联网能力的详细操作教程
本篇文章主要讲解,在win系统环境下,禁止某个应用联网能力的详细操作教程,通过本教程您可以快速掌握自定义对单个程序联网能力的限制和禁止。 作者:任聪聪 日期:2024年10月30日 步骤一、按下win按键(四个小方…...

近似线性可分支持向量机的原理推导
近似线性可分的意思是训练集中大部分实例点是线性可分的,只是一些特殊实例点的存在使得这种数据集不适用于直接使用线性可分支持向量机进行处理,但也没有到完全线性不可分的程度。所以近似线性可分支持向量机问题的关键就在于这些少数的特殊点。 相较于…...

Golang开发环境
Golang开发环境搭建 Go 语言开发包 国外:https://golang.org/dl/ 国内(推荐): https://golang.google.cn/dl/ 编辑器 Golang:https://www.jetbrains.com/go/ Visual Studio Code: https://code.visualstudio.com/ 搭建 Go 语言开发环境,需要…...

测试华为GaussDB(DWS)数仓,并通过APISQL快速将(表、视图、存储过程)发布为API
华为数据仓库服务 数据仓库服务(Data Warehouse Service,简称DWS)是一种基于公有云基础架构和平台的在线数据处理数据库,提供即开即用、可扩展且完全托管的分析型数据库服务。DWS是基于华为融合数据仓库GaussDB产品的云原生服务&a…...

如何用STM32CubeMX快速验证你的硬件设计:以UART通信为例
如何用STM32CubeMX快速验证你的硬件设计:以UART通信为例 在嵌入式开发中,硬件验证往往是最耗时且最容易出错的环节之一。想象一下,当你精心设计的电路板终于到手,却发现某个外设无法正常工作,那种挫败感足以让任何开发…...

解决Simulink中S-Function模块缺失问题:以NREL FAST风力发电机模拟为例
1. 当Simulink提示S-Function模块缺失时该怎么办 遇到Simulink报错"S-Function模块不存在"时,很多工程师的第一反应是怀疑模型文件损坏。但根据我处理NREL FAST风力机模拟的经验,90%的情况其实是环境配置问题。就像你买了一台新电脑却打不开游…...

从人工智障到智能感知:探索McCulloch-Pitts与Rosenblatt模型的演进之路
1. 从"人工智障"到智能感知的起点 第一次接触神经网络的朋友们,常常会戏称早期的模型为"人工智障"。这其实很形象——就像婴儿学步一样,人工智能也经历了从蹒跚到稳健的过程。1943年,神经生理学家Warren McCulloch和数学…...

从‘Hello World’到实战:用Python+sklearn复现经典手写数字识别项目,保姆级代码逐行解析
从‘Hello World’到实战:用Pythonsklearn复现经典手写数字识别项目,保姆级代码逐行解析 当你第一次接触机器学习时,手写数字识别项目就像编程界的"Hello World"一样经典。这个看似简单的项目背后,却蕴含着机器学习从数…...

Phi-3-mini-128k-instruct代码解释能力实测:逆向工程与文档生成
Phi-3-mini-128k-instruct代码解释能力实测:逆向工程与文档生成 最近在尝试一些新的代码辅助工具,发现微软开源的Phi-3-mini-128k-instruct模型挺有意思。它主打轻量化和指令跟随,特别是那个128k的超长上下文,理论上能塞进去不少代…...

Dify部署
简介 Dify 是可在本地部署的,开源的智能体管理平台 本文介绍如何在本地部署 Dify,官网地址:https://dify.ai/ 部署 简单一点,用 Docker-Compose 部署,我这里用 Docker-Desktop Docker-Desktop 是桌面版的 Docker&…...
统计分析报告生成器说明)
fMRI(4-1)统计分析报告生成器说明
fMRI 统计分析报告生成器说明 文件:generate_stats_report.m 版本:v1.0 依赖:run_full_pipeline.m run_post_analysis.m 的完整输出 被试分组 CSV 目录 功能概述依赖环境目录结构要求输入参数输出文件全局配置参数调用方式数据预加载流程报…...

从ChatUI到AgentOS:下一代AIAgent交互范式迁移,3类企业已紧急重构前端架构
第一章:AIAgent架构人机交互界面设计的范式演进本质 2026奇点智能技术大会(https://ml-summit.org) 人机交互界面(HMI)在AIAgent架构中已从静态控件集合跃迁为动态语义协商场域,其演进本质并非UI组件的堆叠升级,而是认…...

FreeRTOS队列实战:uxQueueMessagesWaiting在UART中断中的那些坑
FreeRTOS队列深度解析:UART中断中的uxQueueMessagesWaiting陷阱与实战对策 在嵌入式开发中,UART通信与FreeRTOS队列的结合使用堪称经典组合,但正是这种看似简单的组合,却暗藏诸多玄机。我曾在一个工业传感器采集项目中,…...

iCloud照片批量下载终极指南:如何用icloudpd轻松备份你的数字记忆
iCloud照片批量下载终极指南:如何用icloudpd轻松备份你的数字记忆 【免费下载链接】icloud_photos_downloader A command-line tool to download photos from iCloud 项目地址: https://gitcode.com/GitHub_Trending/ic/icloud_photos_downloader 如果你正在…...