51c~目标检测~合集2
我自己的原文哦~ https://blog.51cto.com/whaosoft/12377509
一、总结
这里概述了基于深度学习的目标检测器的最新发展。同时,还提供了目标检测任务的基准数据集和评估指标的简要概述,以及在识别任务中使用的一些高性能基础架构,其还涵盖了当前在边缘设备上使用的轻量级模型。
目标检测是指在图像或视频中分类和定位物体的任务。由于其广泛的应用,最近几年目标检测受到了越来越多的关注。本文概述了基于深度学习的目标检测器的最新发展。同时,还提供了目标检测任务的基准数据集和评估指标的简要概述,以及在识别任务中使用的一些高性能基础架构,其还涵盖了当前在边缘设备上使用的轻量级模型。在文章的最后,我们通过以图表的形式直观地在多个经典指标上比较了这些架构的性能。
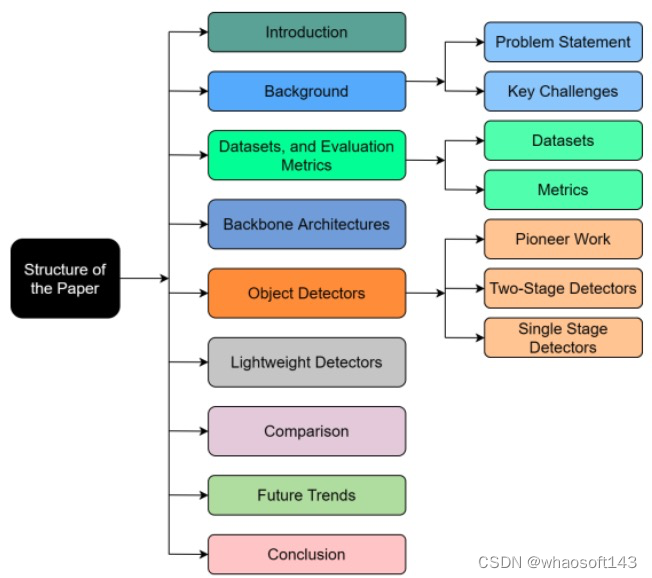
Structure of the paper
目标检测对于人类来说是一项很简单的任务,但是对于计算机来说却是一项艰巨的任务。目标检测涉及在视野范围内识别和定位所有物体(如汽车、人、街道标志等)的实例。此外,分类、分割、运动估计、场景理解等任务也是计算机视觉中的基本问题。早期的目标检测模型是由手工提取的特征提取器构建的,例如 Viola-Jones 检测器和方向梯度直方图(HOG)等。这些模型运行速度慢且检测不准确,在未熟悉的数据集上表现不佳。卷积神经网络(CNN)和深度学习在图像分类任务中的再次出现改变了视觉感知的景观。AlexNet 在 2012 年 ImageNet 大规模视觉识别挑战赛(ILSVRC)中以绝对优势获得了冠军,这极大地启发科研人员/从业者对基于深度学习的计算机视觉算法进行深入研究。今天,目标检测在自动驾驶汽车、身份检测、安防和医疗领域都有大量的应用。近年来,随着新工具和技术的快速发展,目标检测算法的性能取得了指数级增长。
目标检测是目标分类的自然延伸,其目的仅在于识别图像中的目标。目标检测的目标是检测预定义类别的所有实例,并通过轴对齐的框提供目标在图像中的粗略定位。检测算法应该能够识别目标类别的所有实例,并在其周围画出边界框。它通常被视为有监督学习问题。现代的目标检测模型可以通过大量的带标记图像进行训练,并在多个经典的基准数据集上上进行性能评估。
关键挑战
计算机视觉在过去十年取得了巨大进步,但仍有一些关键挑战需要克服。算法在实际应用中面临的一些关键挑战包括:
类内变化: 同一目标实例之间的类内变化在自然界中很常见。这种变化可能由多种原因引起,如遮挡、照明、姿势、视角等。这些不受约束的外部因素可能会对目标外观产生巨大影响。 某些目标可能具有非刚性变形或旋转、缩放或模糊等特性,这都使得特征提取变得异常困难。
类别数量: 同时检测大量的目标是一个非常具有挑战性的问题。它需要大量的高质量注释数据,这极大的增加了标注成本。 使用少样本训练策略来训练检测算法当前十分热门的研究领域。
效率: 当今的模型需要大量的计算资源来生成准确的检测结果。随着移动和边缘设备变得普遍,高效的目标检测器对计算机视觉领域的进一步发展至关重要。
数据集和评估指标
数据集
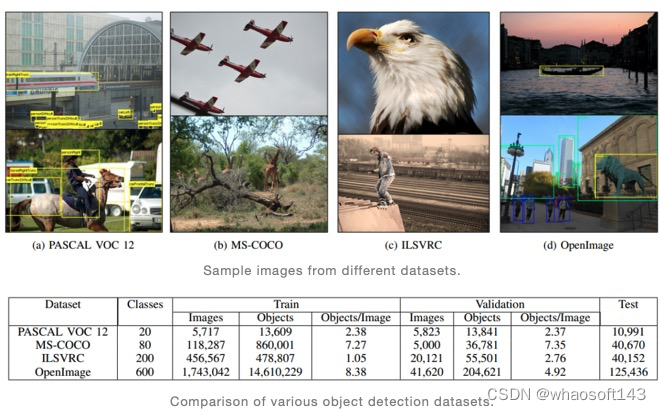
我们将在下文介绍一些常用的目标检测数据集。这些数据集可能包括图像数据集、视频数据集或者其他类型的数据集。我们会对这些数据集进行概述,包括数据集的大小、数据类型、标注信息等。
PASCAL VOC
Pascal Visual Object Classes(VOC)是目标检测领域常用的数据集。它于2005年开始,在四种目标类别上进行分类和检测任务,但两个版本的挑战通常被用作基准。VOC07数据集有5k张训练图片和超过12k张标注图片,而VOC12数据集将其增加到11k张训练图像和超过27k张标注图片。目标类别被扩展到20类,并且像分割和动作检测这样的任务也被包括在内。Pascal VOC引入了平均精度(mAP)并以IoU@50(交集除以并集)的标准来评估模型的性能。上图描绘了在Pascal VOC数据集中各类图像的数量分布。
ILSVRC
ImageNet Large Scale Visual Recognition Challenge(ILSVRC)是一项从2010年到2017年每年举办的挑战赛,并成为了评估算法性能的基准数据集。数据集大小超过100万张图像,其中包括1000个目标类别。其中200个类别被手选用于目标检测任务,包括超过500k张图像。包括ImageNet和Flikr在内的各种来源被用于构建检测数据集。此外,ILSVRC还通过放宽IoU阈值来更新评估指标,以用于评估小目标检测性能。上图描绘了在ImageNet数据集中各类图像的数量分布。
MS-COCO
Microsoft Common Objects in Context(MS-COCO)是当前可用的最具挑战性的数据集之一。它包含91种真实世界中常见的普通目标。它有超过200万个实例,平均每张图像有3.5类别。此外,每张图像平均包含7.7个实例,比其他流行数据集都要多。MS-COCO包含来自不同视角的图像。它还引入了一种更严格的方法来测量检测算法的性能。与Pascal VOC和ILSVCR不同,它阈值范围从0.5到0.95并以0.05为步长计算IoU,然后使用这10个值的组合作为最终度量标准,其称为平均精度(mAP)。除此之外,它还分别使用小、中、大目标的AP来比较不同尺度下的性能。上图描绘了在MS-COCO数据集中各类图像的数量分布。
Open Image
谷歌的Open Images数据集由9.2 m张图像组成,其中包括图像级标签、目标边界框和分割掩模等标注。它于2017年推出,并已经历了六次更新。对于目标检测,Open Images有16 m个边界框,针对1.9 m张图像的600个类别,这使它成为最大的目标定位数据集。它的创建者特别注意选择有趣、复杂和多样的图像,每张图像平均有8.3个目标类别。在Pascal VOC中引入的AP做了几点改变,比如忽略未标注的类别、类别及其子类别的检测要求等。上图描绘了在Open Images数据集中各类图像的数量分布。常用的目标检测数据集(如Pascal VOC、MS-COCO和Open Images)存在数据不平衡问题,即某些类别的图像数量远远大于其他类别。这种数据不平衡会导致训练出的目标检测模型在某些类别上表现较好,而在其他类别上表现较差。虽然ImageNet数据集也存在这一问题,但是程度要小得多。此外,ImageNet数据集中出现频率最高的类别是“考拉”,而在真实世界目标检测场景中(如人、车、交通标志等)最关注的类别并不在前几位。因此,在使用这些数据集训练目标检测模型时,需要注意这种数据不平衡带来的影响。
评估指标
目标检测任务常用多个标准来衡量检测算法的性能,如每秒帧数(FPS)、精度和召回率。但是,平均精度(mAP)是最常见的评估指标。精度是由交叉率(IoU)推导出来的,它是GT和预测边界框之间的重叠区域与联合区域的比率。此外,可以通过设定阈值来确定检测是否正确,如果IoU大于阈值,则将其分类为真阳性(True Positive),而IoU低于阈值时分类为假阳性(False Positive)。如果模型未能检测到GT中存在的目标,则称其为假阴性(False Negative)。

根据上述方程,将每个类别的平均精度分别计算出来。为了比较检测器之间的性能,使用所有类别的平均精度的平均值,称为 mAP,作为最终评估的单一指标。
主干网络结构
主干网络结构是目标检测算法最重要的组成部分之一。这些网络从输入图像中提取模型使用的特征。下面,我们讨论了一些在现代检测算法中常用的里程碑式的主干网络结构。
AlexNet
Krizhevsky等人于2012年提出了AlexNet,这是一种基于卷积神经网络的图像分类网络结构,并赢得了2012年的ImageNet大规模视觉识别挑战赛冠军。它的准确度显著高于(%26)当时其他选手的模型。AlexNet由八个可学习层组成,包括五个卷积层和三个全连接层。全连接层的最后一层连接到N路(N:类别数)softmax分类器。它在整个网络中使用多个卷积核从图像中获取特征。它还分别使用dropout和ReLU进行正则化和更快的训练收敛。AlexNet再次介绍了卷积神经网络,并很快成为处理图象数据的首选技术。
VGG
AlexNet 及其后继模型均只关注浅层CNN网络,并未对更深层的CNN网络进行研究。Simonyan和Zisserman通过调查网络深度对准确度的影响,提出了经典网络架构-VGG,这是一种使用小卷积滤波器构建的不同深度的网络。虽然较大的感受野可以通过一组较小的卷积滤波器捕获,但这大大减少了网络参数并且收敛速度更快。VGG向我们展示了如何使用深层网络架构(16-19层)进行图象分类,并具有更高的准确度。VGG是通过添加多个卷积层堆叠后再加上三个全连接层来构建的,网络最后跟着一个softmax层。根据VGG作者的说法,卷积层的数量可以从8到16不等。VGG在多次迭代中进行训练;首先,使用随机初始化训练最小的11层网络结构,然后使用这些权值训练更大更深的网络以防止梯度不稳定。VGG在单个网络性能类别中优于ILSVRC 2014获胜者GoogLeNet。它很快成为用于目标分类和检测模型中最常用主干网络之一。
GoogLeNet/Inception
尽管分类模型在实现更快,更准确的方向上取得了很大的进展,但由于计算资源仍不足以承受模型巨大的参数量,将它们部署到现实世界的应用中仍然很遥远。随着网络规模的增大,计算成本呈指数级增长。Szegedy等人提出网络中计算浪费是造成这种情况的主要原因。这是因为更大的模型也具有大量参数,大模型往往会导致数据过拟合。因此,他们提出使用局部稀疏连接的架构代替完全连接的架构来解决这些问题。GoogLeNet因此是一个22层深的网络,由多个Inception模块堆叠构成。Inception模块是一种具有多种尺寸滤波器的网络,输入特征图通过通过多个滤波器编码后再融合成一个特征图转发到下一层。该网络还在中间层使用辅助分类器,以助于网络梯度的有效传播。它在ImageNet数据集上实现了93.3%的top-5精度,而且比其他的分类模型更快。在接下来的几年中,Inception的更新版本也陆续发布,性能也得到了很大的提升,并为稀疏连接架构的有效性提供了进一步的证明。
ResNets
在卷积神经网络变得越来越深的情况下,Kaiming He等人通过大量的实验证明了它们的准确度是如何先被饱和,然后迅速降低。他们提出将残差连接应用于卷积堆叠层,以缓解网络性能下降的问题。残差连接可以通过在邻接层之间添加skip connection来实现。这种连接是块的输入和输出之间的元素加法,并不会为网络增加额外的参数或计算复杂度。典型的34层ResNet 实际上是由一个大(7x7)卷积过滤器、16个瓶颈模块(两个小3x3滤波器和身份快捷方式),以及一个全连接层组成。瓶颈架构可以通过堆叠3个卷积层(1x1,3x3,1x3)来调整网络深度。Kaiming He等人还证明了16层VGG网络与其深度较小的101层和152层ResNet架构相比具有更高的复杂度,更低的精度。在后续的论文中,作者还提出了使用批量归一化和ReLU层的Resnetv2,这是一种更通用且易于训练的网络架构。ResNets在分类和检测的基础架构中广泛使用,它的核心思想:“残差连接”启发了许多后续网络架构的设计。
ResNeXt
ResNeXt是 ILSVRC 2016 挑战赛的亚军。它的构建灵感来自于 VGG/ResNet 中堆叠相似块的构建方式和 Inception 模块的“分裂-变换-合并”策略。它的核心思想是用类似 Inception 的 ResNeXt 模块替换 ResNet 中的每个block,从而使得网络更容易缩放和泛化。ResNeXt 还提到了“基数(cardinality)(ResNeXt 块中的拓扑路径)”可以作为深度和宽度的第三维来提高模型准确度。与同等深度的 ResNet 架构相比,ResNeXt 在具有更少的超参数的情况下取得了更高的准确度。
CSPNet
虽然当前的神经网络在计算机视觉任务中表现出令人满意结果,但它们需要依赖大量的计算资源。Wang等人相信通过裁剪网络中重复的梯度信息可以减少大量的推理复杂度。他们设计的CSPNet旨在通过减少网络中重复梯度信息来降低推理计算的复杂度。它通过将基础层的特征图分成两部分来实现这一目的。其中一部分通过部分卷积网络块(例如DenseNet中的Dense和Transition块或ResNeXt中的Res(X)块)进行处理,另一部分在稍后的阶段与其输出合并。这样可以减少参数量,提高计算单元的利用率,并简化内存占用。CSPNet易于实现,并且足以适用于ResNet、ResNeXt、DenseNet、Scaled-YOLOv4等网络架构。在这些网络上应用CSPNet可以将计算量减少10%到20%,同时保持或提高精度。CSPNet还大大减少了内存成本和计算瓶颈,并被广泛用于许多先进检测模型,同时也被应用在移动或边端设备。
EfficientNet
Tan等人系统地研究了网络缩放对模型性能的影响。他们总结了网络参数的改变(如深度、宽度和分辨率)对其精度的影响。单独缩放任何参数都会有相关的代价。增加网络的深度可以帮助捕获更丰富和复杂的特征,但是梯度消失问题会使得网络难以训练。类似地,扩展网络宽度可以帮助捕获细粒度的特征,但是很难获得高级语义特征。增加图像分辨率的增益(如深度和宽度)会随着模型的扩展而饱和。在该篇论文中,Tan 等人提出了一个复合系数,可以均匀缩放这三个维度。每个模型参数都有一个相关的常数,通过将系数固定为1,并在基础网络上执行网格搜索来找合适的相关系数。基础网络结构是受到以前的文章启发构建的,主要思想是在搜索目标上进行神经网络架构搜索,同时优化精度和计算量。EfficientNet是一种简单高效的网络架构。它在精度和速度方面均优于现有模型,同时具备较小参数量。通过在效率方面提供里程碑式的提高,EfficientNet开启了高效网络领域的新时代。
目标检测算法
下面我们主要介绍的是目标检测算法,其中包含了传统目标检测算法以及基于深度学习的单/双阶段目标检测算法。具有生成区域建议模块的网络称为双阶段目标检测算法。这些算法在第一阶段尝试在图像中找到任意数量的目标候选区域,然后在第二阶段再对它们进行分类和定位。由于这些算法需要分两个步骤进行处理,它们具有复杂的架构、需要更长的推理时间并且缺乏全局背景信息。单阶段检测算法使用密集采样策略在单次推理中图象中目标分类和定位。通常,单阶段检测算法会使用各种尺度和宽高比的预定义框/关键点充当先验信息来辅助检测,并且在实时性能和简单设计方面优于双阶段检测算法。
传统方法
Viola-Jones
一种在2001年提出用于人脸检测的目标检测算法。Viola-Jones 结合了多种技术,如Haar-like特征,积分图像,Adaboost和级联分类器。第一步是在输入图像上滑动窗口搜索Haar-like特征,并使用积分图像来计算编码。然后,它使用训练过的Adaboost来找到每个haar特征的分类器并进行级联。得益于高效且快速的特性,Viola Jones算法仍然在小型设备中使用。
HOG
这是由Dalal和Triggs在2005年提出一种用于提取物体检测特征的方法。HOG提取边缘的梯度及其方向来创建特征表。首先将图像划分为等比例网格区域,然后使用特征表为每个网格中的单元格创建直方图,最后为感兴趣的区域生成HOG特征,并将其输入线性SVM分类器进行检测。该检测算法是为行人检测而提出的,同时也可以用于训练和检测各种类别。
DPM
这是由Felzenszwalb等人在2009年提出的可变形部件模型。它使用目标的单个“部分”进行检测,并且比HOG获得了更高的准确度。它遵循分而治之的理念,在推理时单独检测目标的组成部分,并将它们标记为感兴趣区域。例如,人的身体可以被视为头、手臂、腿和躯干等部分的集合。首先,模型会捕获整个图像中的一部分区域,并且循环该过程直至所有图象部分区域都被捕获。然后,模型会根据各个部分区域的相关性删除不相关区域,以生成最终的检测结果。DPM是深度学习时代之前最成功的算法之一。
二阶段检测器
R-CNN
一种基于卷积神经网络(CNN)改进的目标检测算法。它使用与类别无关的候选区域生成算法与CNN将检测转换为分类和定位问题。首先,将减去平均值的输入图像传递给候选区域生成算法,该模块产生2000个目标候选区域。该算法使用选择性搜索找到可能存在目标的区域。然后将这些候选区域统一采样并传递到CNN网络,该网络为每个候选区域生成4096维特征向量。Girshick等人使用AlexNet作为检测算法的主干网络,然后将特征向量传递给训练过的支持向量机(SVMs)以获得置信度分数。最后,根据IoU和类别的计算结果,对得分区域应用非最大抑制(NMS)得到最终的目标预测框。一旦确定了类别,算法就使用经过训练的边界框回归器来预测其边界框,该边界框回归器预测四个参数,即框的中心坐标以及其宽度和高度。
R-CNN 有一个复杂的多阶段训练过程。第一阶段是使用大型分类数据集进行预训练。第二阶段是使用经过特定预处理的图像输入至网络,通过随机初始化的 N+1 分类器(N 是类别数)替换分类层来进行检测微调,其中优化器使用的是随机梯度下降(SGD)。最终,R-CNN为每个类别训练一个单行 SVM 和边界框回归器。
R-CNN 引领了目标检测领域的新浪潮,但其缺点也十分明显:(1)推理速度十分慢(每张图片的推理时间约 47 秒);(2)它的训练过程很复杂,即使在计算共享优化的情况下,在小数据集上训练仍需几天的时间。
SPP-Net
He 等人提出了使用空间金字塔池化(SPP)层来处理任意大小或宽高比的图像。SPP-net 仅在候选区域生成算法之前的卷积层后添加了一个池化层,从而使网络能不再受限于固定尺寸的输入图象,并这一操作能减少大量的计算量。选择性搜索算法用于生成候选窗口。首先通过 ZF-5 网络的卷积层将输入图像映射到特征图,然后将候选窗口映射到特征图上,再将其通过金字塔池化层的空间 bins 转换为固定长度的表示,最后该向量通过全连接层并最终传递给 SVM 分类器以预测类别和分数。与 R-CNN 类似,SPP-net 也使用特定的后处理层来优化目标的定位结果,同时它也使用相同的多阶段训练过程,但仅需要在全连接层上进行微调。
SPP-net 的优势在于它可以处理任意大小和宽高比的输入图像,这得益于它使用了 SPP 层来将输入图像映射到固定长度的表示。这与 R-CNN 的固定输入大小形成了鲜明对比。另外,SPP-net 使用选择性搜索算法生成候选窗口,这比 R-CNN 生成的窗口更少,因此 SPP-net 的计算量更少。然而,SPP-net 仍然存在一些问题,如需要较长的训练时间和较大的内存使用量。
Fast R-CNN
R-CNN/SPP-Net 的一个主要问题是需要单独训练多个网络组件/模块。Fast R-CNN 通过创建单个端到端可训练系统解决了这个问题。 首先,该网络将图像和候选区域作为输入,图像通过一组卷积层,并将目标候选区域映射到所获得的特征图上。然后,使用 RoI 池化层取代 SPP-net 中的金字塔池化层进行特征编码,接着通过 2 个全连接层进行全局特征融合,最后输入至 N+1 类 SoftMax 层和边界框回归层得到最终的预测结果,其中边界框回归层有一个全连接层。该模型还将边界框回归器的损失函数从 L2 改为了平滑 L1以提高性能,同时引入了多任务损失来训练网络。
Fast R-CNN 的优势在于它是一个端到端可训练系统,因此可以避免 R-CNN/SPP-Net 中训练多个网络组合/模块问题。 它使用了 RoI 池化层,从而使网络能够处理任意大小的输入图像,同时使用了平滑 L1 损失来提高边界框回归的性能。然而,Fast R-CNN 仍然具有较长的训练时间和较大的内存使用量。
Faster R-CNN
虽然 Fast R-CNN 更能满足实时的需求,但其候选区域生成的速度仍然十分缓慢。Ren 等人提出使用全卷积网络作为候选区域建议网络(RPN),该网络接受任意输入图像并输出一组候选窗口。每个这样的窗口都具有关联的目标置信度,该分数决定了目标的可能性。与之前使用图像金字塔解决目标尺寸变化的方法不同,RPN 引入了锚框机制,其使用了多个不同长宽比的边界框作为先验值对目标的位置进行回归。 首先将输入图像通过 CNN 传递,以获得一组特征图。这些特征图被转发到 RPN,该 RPN 生成边界框及其类别。然后将候选区域映射回前一个 CNN 层获得的特征图上的 RoI 池化层。最终输入全连接层,并输入到分类器和边界框回归器。
Faster R-CNN 比先前最先进的检测算法提高了 3% 的精度,并将推理时间减少了一个数量级。它解决了候选区域提取缓慢的瓶颈,并以每秒 5 帧接近实时的速度运行。在候选区域建议模块中使用 CNN 的另一个优点是,它可以学习生成更好的候选区域,从而提高准确度。
FPN
使用图像金字塔提取多尺度图象信息是增强小物体检测的常用方法。虽然这种方法会增加检测算法的平均精度,但同时推理时间也是极大地增加。Lin 等人提出了特征金字塔网络 (FPN),它具有自上而下与横向连接的架构,这可以在不同尺度上建立高级语义特征。 具体地,FPN 具有两条通路,一条自下而上的通路是在对多个尺度特征图编码的 ConvNet,另一条自上而下的通路将来自更高级的粗糙特征映射升采样为高分辨率特征。这两条通路由横向连接相连,通过 1x1 卷积操作来增强特征中的语义信息。如上图所示,FPN 被用作于将主干网络的多尺度特征融合交互后再输入至RPN。
FPN 可以为所有尺度特征图提供高级语义,这可以有效降低检测中的误检率。它成为了未来检测模型的标准模块,同时也引起了很多基于FPN改进的模块的出现,如 PANet、NAS-FPN 和 EfficientNet。
R-FCN
在 R-FCN 中,输入图像经过主干网络获得特征图,然后将特征图送入分类子网络和回归子网络中。分类子网络包括一组卷积层,每个卷积层对应一个类别,所有类别共享权值。回归子网络的每个卷积层都对应一个位置,用于预测边界框的四个参数(中心坐标以及宽度和高度)。这种共享卷积层的方式使得 R-FCN 在计算效率方面优于其他两阶段检测算法,同时也能保留了不错的精度。具体地,首先输入图像先经过 ResNet-101 获得特征图,然后将中间输出(Conv4 层)传递给区域建议网络(RPN)以确定 RoI 候选区域,最终输出经过卷积层处理后输入到分类器和回归器。R-FCN 使用位置敏感得分图来编码主体的相对空间信息,并在后期使用池化层以确定精确的定位。R-FCN 使用了一个分类层和一个回归层,分别用于生成预测类别和输出边界框位置坐标。分类层结合了位置敏感映射和 RoI 建议(RoI,即感兴趣区域)来生成预测。分类层和回归层使用交叉熵和边界框回归损失函数进行训练。R-FCN 的训练过程和 Faster-RCNN 类似也是包括四个步骤,此外在训练过程中还使用了在线困难样本挖掘(OHEM)。在线困难样本挖掘是一种训练方法,用于选择较难预测的样本进行训练,可以有效提高模型的泛化能力。
Dai 等人提出了一种新方法来解决卷积神经网络中的平移不变性问题。R-FCN 将 Faster R-CNN 和 FCN 结合起来,实现了一个快速且更准确的检测器。尽管 R-FCN 的准确率没有多大提高,但是它的速度比其对手快了 2.5-20 倍。
Mask R-CNN
Mask R-CNN 是一种扩展了 Faster R-CNN 的双阶段目标检测算法,它在 Faster R-CNN 的基础上增加了一个并行分支,其用于像素级目标实例分割。该分支是一个在 RoI 上应用的全连接层,用于将每个像素分类以完成扩展的分割任务。它使用类似于 Faster R-CNN 的基本架构进行目标区域建议,并增加了一个Mask Head并行于分类 Head 和回归 Head。Mask R-CNN与 Faster R-CNN最主要区别是前者使用 RoIAlign 层,而不是 RoIPool 层,这可以避免由于空间量化而导致的像素不对齐问题。作者选择 ResNeXt-101 作为其主干网络,并使用特征金字塔网络(FPN)来提高准确率。此外,Mask R-CNN 的总体训练过程类似于 Faster R-CNN。
Mask R-CNN 的性能优于当时所有的双阶段检测算法,并且在只需很少的额外计算开销下增加了实例分割功能。它的训练简单、灵活,并且在关键点检测、人体姿态估计等应用中很好地推广。然而,它的实时推理速度(即每秒帧数)仍低于 30 fps。
DetectoRS
许多当代的双阶段检测算法均是使用“先查看再思考”机制,即先计算目标候选区域,再使用它们来提取特征来进行目标的分类与定位。DetectoRS 在网络的宏观和微观层面都应用了这种机制。在宏观层面,他们提出了递归特征金字塔(RFP),由多个特征金字塔网络(FPN)堆叠而成,并从 FPN 的自上而下层路径向 FPN 的自下而上层添加了额外的反馈连接。FPN 的输出在传递到下一个 FPN 层之前由空洞空间金字塔池化层(ASPP) 处理。DetectoRS 使用融合模块将来自不同模块的 FPN 输出结合起来以生成注意力图。在微观层面,Qiao 等人提出了可切换扩张卷积(SAC)来调节卷积的扩张率。使用 5x5 滤波器的平均池化层和 1x1 卷积作为切换函数来决定扩张卷积的速率,帮助主干网络实时检测不同尺度的物体。他们还将 SAC 嵌入在两个全局上下文模块之间,因为这有助于使切换更稳定。简单来说,递归特征金字塔和可切换扩张卷积的结合形成了 DetectoRS。
DetectoRS 结合了多个组件/模块来提高检测算法的性能,并成为了当时双阶段检测算法的SOTA水平。它的 RFP 和 SAC 模块具有很好的泛化性,可以用于其他检测模型。但由于它推理速度只达到约4FPS,并不适用于实时检测。
单阶段检测器YOLOv1
双阶段检测算法在第一阶段会将目标检测视为分类问题,区域建议模块提供了一些候选预取,网络将其分类为前景或背景。然而,YOLO 将其重新定义为纯回归问题,直接将图像像素预测为目标的类别及其边界框坐标。 在 YOLO 中,输入图像被划分为 S x S 网格,负责检测该物体的网格单元位于目标中心所在的单元格。一个网格单元预测多个边界框,每个预测数组由 5 个元素组成:边界框中心的 x 和 y 坐标、宽高 w 和 h,以及置信度得分。
YOLO 的灵感来自于提出小卷积层级联的图象分类模型 GoogLeNet。它预先在 ImageNet 数据上训练,直到模型达到高精度,然后通过添加随机初始化的卷积层和全连接层进行微调。YOLO 使用多任务损失(multitask loss)来优化模型,多任务损失即是所有预测分支的组合损失。此外,YOLO也是使用非最大抑制(non maximum suppression,NMS)删除类特定的多次检测。YOLO 在各种网络规模和计算资源之间提供了很好的平衡,并且可以在实时应用中使用。然而,它在处理小物体方面表现较差,并且易受到光照变化的影响。这些问题在后续的YOLO系列版本中得到改善。
SSD
Single Shot MultiBox Detector(SSD)是第一个与 Faster R-CNN 等双阶段检测算法精度相当的单阶段检测算法,同时实现了实时的推理速度。SSD 基于 VGG-16 构建,并添加了附加结构以提高网络性能。这些附加卷积层添加到模型末尾,并且输出特征图逐渐减小。当图像分辨率较大时,SSD 可以利用此部分特征来检测较小的物体,而较深层则负责默认框和宽高比的偏移。
在训练期间,SSD 会将每个GT 与具有最佳 jaccard 重叠的网络预测框进行匹配,并按照此训练网络。此外,它还使用了困难负样本挖掘和大量数据增强。与 DPM 类似,它使用位置和置信度损失的加权和来训练模型,最后再通过NMS获得预测结果。
尽管 SSD 比 YOLO 和 Faster R-CNN 等最先进的网络都快得多且更准确,但它在检测小物体方面仍存在困难。后来,通过使用更好的主干网络(如 ResNet)和其他的高级技术来解决了这个问题。
YOLOv2 and YOLO9000
YOLOv2 是 YOLO 的改进版,在速度和精度之间提供了更好的权衡,而 YOLO9000 模型则可以实现实时预测 9000 个目标类别。他们用 DarkNet-19代替 GoogLeNet 成为检测算法的主干架构。它结合了许多令人印象深刻的技术:批量归一化以提高收敛性、分类和检测系统的联合训练以增加检测类别、删除全连接层以增加运行速度以及使用锚框机制以提高召回率并具有更好的先验知识。Redmon 等人还通过使用 WordNet 将分类和检测数据集结合在层次结构中。其中WordTree 可用于预测更高的上位词的条件概率,即使下位词未被正确分类,从而提高系统的整体性能。YOLOv2 在精度和速度方面都比先前的 YOLO 模型有显著提高,并且可以达到实时预测的能力。然而,它在检测小物体方面仍存在困难,并且易受到光照变化的影响。
RetinaNet
Lin 等人认为单阶段检测算法精度低于双阶段检测算法的原因是“极端的前/背景类别不平衡” 。他们提出了一种称为 Focal loss 的重构交叉熵损失来改善这种不平衡问题。Focal loss 可以减少简单样本的损失贡献,同时增加困难样本的损失贡献。作者通过简单的单阶段检测算法 RetinaNet 展示了它的有效性,该检测算法通过密集采样输入图像的位置、尺度和宽高比来预测目标。如上图所示,它使用由 FPN 扩展的 ResNet 作为主干网络,以及两个类似的子网作为分类器和边界框回归器。在训练过程中,RetinaNet 使用 Focal loss 减少简单样本对损失的贡献,从而更多地关注困难样本。这有助于解决类别不平衡问题,并使 RetinaNet 在单阶段检测算法中获得了领先的性能。RetinaNet 还使用了在 FPN 中提出的概念,即通过使用更小的卷积核在不同的感受野之间获得更多的分辨率和精度。这有助于 RetinaNet 在检测小物体方面取得成功。 RetinaNet 的 FPN 的每一层都传递给子网,使其能够在不同尺度下检测目标。分类子网为每个位置预测目标分数,而边界框回归子网则对每个锚的偏移量进行回归以与真实值匹配。两个子网都是小的 FCN,并在各个网络之间共享参数。与大多数先前的工作不同,作者采用了无类别边界框回归器,并发现它们同样有效。
RetinaNet 训练简单、收敛快,易于实现。它在精度和运行时间方面都比双阶段检测器取得了更好的性能。此外,RetinaNet 还通过引入新的损失函数,推进了目标检测算法优化的方式。
YOLOv3
YOLOv3 对比之前的 YOLO 版本有不少的改进,其中包括将主干网络替换为更大的 Darknet-53 网络。此外,还结合了各种技术,如数据增强、多尺度训练、批归一化等。分类层中的 Softmax 被逻辑分类器取代。
尽管 YOLOv3 比 YOLOv2更快,但它没有从其前任中带来任何突破性的变化。
CenterNet
Zhou 等人提出的CenterNet采用了一种非常不同的方法,即将目标建模为点,而不是传统的边界框表示。 CenterNet 预测目标为边界框中心的单个点:输入图像通过 FCN 生成热图,其峰值对应于检测到的目标中心。它使用 Hourglass-101作为特征提取网络,并具有 3 个头 - 热图头来确定目标中心,维度头来估计目标大小,偏移头来纠正目标点的偏移。在训练时,三个头的多任务损失都被反向传播到特征提取器。在推理期间,使用偏移头的输出来确定目标点,最后生成预测框。由于预测是点而不是边界框,因此不需要 NMS 进行后处理。
CenterNet 抛弃了传统的边界框表示方式,为目标检测领域带来了一种全新的视角。它比之前的单阶段检测算法更准确,推理时间更短。它在多种任务(如 3D 目标检测、关键点估计、姿态、实例分割、方向检测等)中均具有很高的精度。
EfficientDet
EfficientDet 旨在构建具有更高准确率和运行效率的可扩展检测算法。它引入了有效的多尺度特征、BiFPN 和模型缩放策略。BiFPN 是双向特征金字塔网络,具有可学习的权重,用于在不同尺度的输入特征之间进行交叉连接。它通过删除一个输入节点并添加一个额外的横向连接来改进 NAS-FPN,从而减少了效率较低的节点,并增强了高级特征融合。与使用更大、更深的主干网络或堆叠 FPN 层来扩展的现有检测算法不同,EfficientDet 引入了一个复合系数,可用于“联合缩放主干网络、BiFPN 网络、分类器/回归器和分辨率的所有维度”。EfficientDet使用EfficientNet 作为主干网络,并在其中堆叠多组BiFPN层作为特征提取网络。每个最终BiFPN层的输出都被发送到类别和边界框预测网络。模型使用SGD优化器进行训练,并使用同步批归一化和swish激活,这能加快网络收敛速度并提高网络精度。
EfficientDet在更小、计算成本更低的情况下,比以前的检测算法实现了更好的效率和准确性。它易于扩展,在其他任务上推广良好,达到了当时单阶段检测算法的SOTA水平。
YOLOv4
YOLOv4是一种快速且易于训练的目标检测算法,可以在现有生产系统中工作。它使用了“免费物品袋”,即仅增加训练时间而不影响推理时间的方法。YOLOv4使用数据增强技术、正则化方法、类标签平滑、CIoU损失、交叉小批量标准化(CmBN)、自我对抗训练、余弦退火调度器和其他技巧来提高训练。只影响推理时间的方法,称为“Bag of Specials”,也被添加到网络中,包括Mish激活、跨阶段部分连接(CSP)、SPP块、PAN路径聚合块、多输入加权剩余连接(MiWRC)等。它还使用遗传算法搜索超参数。它具有在ImageNet上预训练的CSPNetDarknet-53骨干网络、SPP和PAN块颈部以及YOLOv3作为检测头。
大部分的检测算法需要用到多张GPU显卡进行训练,但YOLOv4可以仅用一张GPU显卡就能训练。并且它的推理速度比EfficientDet快两倍,这表现出强大的竞争力。
Swin Transformer
Transformer 是一种新型的神经网络架构,最初用于自然语言处理(NLP)领域,在诸如BERT(双向编码器表示 Transformer),GPT(生成预训练 Transformer),T5(文本到文本 Transformer)等语言模型中取得了巨大成功。Transformer 使用注意力模型来建立序列中元素之间的依赖关系,并且可以关注到比其他顺序架构更长的上下文信息。Transformer 在NLP领域的成功引发了人们对其在计算机视觉领域应用的兴趣。尽管CNN一直是视觉领域发展的支柱,但它们有一些固有的缺点,例如缺乏对全局上下文的关注以及固定的训练权重等。
Swin Transformer是一种基于 Transformer 的计算机视觉任务后端。首先,它将输入图像分割成多个不重叠的patch,并将它们转换为Embedding。然后,在4个编码阶段中对patch应用多个Swin Transformer模块,每个后继编码阶段减少patch的数量以保持分层表示。Swin Transformer模块由基于连续块中交替移位的局部多头自注意力(MSA)模块组成。在局部多头自注意力中,计算复杂度与图像大小呈线性关系,而移位窗口允许跨窗口连接。作者还通过大量实验表明,移位窗口仅需很少的开销便可增加检测精度。Swin Transformer 在MS COCO数据集上取得了最优的结果,但是与CNN相比拥有更多的参数。
YOLOv5
YOLOv5 是 one stage 的目标检测算法,该算法在 YOLOv4 的基础上添加了一些新的改进思路,使得其速度与精度都得到了极大的性能提升,具体包括:输入端的 Mosaic 数据增强、自适应锚框计算、自适应图片缩放操作、Focus 结构、CSP 结构、SPP 结构、FPN + PAN 结构、CIOU_Loss 等。
在 YOLOv3、YOLOv4 中,训练不同的数据集时,是使用单独的脚本进行初始锚框的计算,在 YOLOv5 中,则是将此功能嵌入到整个训练代码里中。所以在每次训练开始之前,它都会根据不同的数据集来自适应计算 anchor。此外,YOLOv5 提出一种方法能够自适应的添加最少的黑边到缩放之后的图片中,有效地提升了网络的推理速度。对于主干网络,YOLOv5使用了Focus模块使得信息不丢失的情况下提高计算力(在新版中,Focus模块替换为6 x 6 的卷积层。两者的计算量是等价的,但是对于一些 GPU 设备,使用 6 x 6 的卷积会更加高效),不同于 YOLOv4 只有主干网络使用了 CSP结构,YOLOv5 设计了两种 CSP 结构。其中,CSP1_X 应用于 Backbone,另一种 CSP2_X 则是应用于 Neck 中。在训练策略部分,YOLOv5 使用了多尺度训练,具体地,如果网络的输入是416 x 416。那么训练的时候就会从 0.5 x 416 到 1.5 x 416 中任意取值,但所取的值都是32的整数倍。此外,训练开始前会使用 warmup 进行训练,以及 cosine 学习率下降策略和 EMA 更新权重等技巧。在损失函数部分,采用的依旧是由 Classes loss、Objectness loss、Location loss组成。(1)Location loss 采用的是 CIOU loss,这里只会计算正样本的定位损失。(2)Classes loss 和 Objectness loss 采用的是 BCE loss,其中 Classes loss 也只会计算正样本的分类损失。(3)Objectness loss 是使用所有样本进行反向传播的计算,并且这里用的是网络预测的目标边界框与 GT Box 的CIOU。
YOLOv5 是一种非常快、性能强并且易用使用的目标检测算法。它提供了多个不同量级的参数模型应对不同的任务场景,目前被研究人员和从业人员广泛关注与使用。
YOLOX
YOLOv5面世不久后,旷世科技发表了研究改进的 YOLOX 算法,其主要贡献是在 YOLOv3 的基础上靠着 Decoupled Head、SimOTA 等方式进行优化。
不同Yolov3、Yolov4、Yolov5采用的都是 Anchor Based的方式来提取目标框。YOLOX 将 Anchor free 的方式引入到 YOLO 系列中,使用anchor free方法有如下好处:(1)降低了计算量,不涉及IoU计算,另外产生的预测框数量也更少;(2)缓解了正负样本不平衡问题;(3)避免了anchor的调参。在数据增强与网络结构部分,YOLOX 与 YOLOv5 大同小异,主要的区别在检测头和正负样本分配。在检测头部分,YOLOX 使用了解耦头(Decoupled Head)结构。具体地,通过将分类和回归任务进行分开预测,避免这两种不同类型的任务形成冲突状态,有效地加快了模型收敛速度以及提升了模型精度。在正负样本分配策略中,YOLOX 使用了SimOTA 算法,其主要思想是为图像中的所有 gt 找到全局的高置信度分配,这极大地改善了在开放场景中常见的多目标耦合问题。
YOLOv6
YOLOv6 是美团视觉智能部研发的一款目标检测框架,致力于工业应用。该框架同时专注于检测的精度和推理效率,在工业界常用的尺寸模型中,对比同级别参数的 YOLO 模型,YOLOv6 表现出非常具有竞争力的性能。在部署方面,YOLOv6 支持 GPU(TensorRT)、CPU(OPENVINO)、ARM(MNN、TNN、NCNN)等不同平台的部署,极大地简化工程部署时的适配工作。
YOLOv6 主要在 Backbone、Neck、Head 以及训练策略等方面进行了改进。首先是设计了更高效的 Backbone 和 Neck: 受到硬件感知神经网络设计思想的启发,基于 RepVGG style 设计了可重参数化、更高效的骨干网络 EfficientRep Backbone 和 Rep-PAN Neck。其次是更简洁有效的 Efficient Decoupled Head,在维持精度的同时,进一步降低了一般解耦头带来的额外延时开销。最后,在训练策略上采用了Anchor free 范式,同时辅以 SimOTA标签分配策略以及 SIoU 边界框回归损失来进一步提高检测精度。
YOLOv7
王建尧博士与AB大神在2022年七月初推出了最新力作 - YOLOv7,该算法在5FPS~160FPS范围内的速度和准确度都超过了所有已知的目标检测算法,像是基于 Transformer 的 SWIN-L-Cascade-Mask R-CNN、基于卷积的 ConvNeXt-XL,Cascade-Mask R-CNN、YOLO 系列的 YOLOv4, Scaled-YOLOv4, YOLOR, YOLOv5, YOLOX, PPYOLO、还有 DETR, Deformable DETR, DINO-5scale-R50, ViT-Adapter-B 等。
YOLOv7 减少了当今实时目标检测 SOTA 算法约40%的参数量和50%的计算量,主要分为两个方面进行优化:模型架构优化和训练过程优化,针对模型架构优化,作者提出了有效利用参数和计算量的 extended 和 scaling 方法,而针对训练过程优化,在YOLOv4 中将“以增加训练成本为代价提高准确率,但是不会增加推理成本的方法”,成为 bag-of-freebies,在 YOLOv7 中使用重参数化技术替换原始的CNN模块和使用 动态标签分类策略,将label 更有效利地分配给不同的输出层。
DAMO-YOLO
DAMO-YOLO 是阿里达摩院在2022年11月份提出的一个兼顾速度与精度的目标检测框架,其效果超越了目前的一众YOLO系列方法,在实现 SOTA 的同时,保持了很高的推理速度。DAMO-YOLO 是在 YOLO 框架基础上引入了一系列新技术,对整个检测框架进行了大幅的修改。具体包括:基于 NAS 搜索的新检测 backbone 结构,更深的 neck 结构,精简的 head 结构,以及引入蒸馏技术实现效果的进一步提升。模型之外,DAMO-YOLO还提供高效的训练策略以及便捷易用的部署工具,能够快速解决工业落地中的实际问题。
在网络的Backbone部分,不同于之前的 YOLO 系列算法的 Backbone 都是通过人工设计的,DAMO-YOLO 利用了其自研的一种启发式和免训练的 NAS 搜索方法,最终搜出来的 Backbone 结构能在同量级的模型复杂度下获得更优的模型精度和推理速度。在 Ncek 部分,DAMO-YOLO 使用了 RepGFPN 结构,对比传统的 PAFPN 结构,RepGFPN 能够充分交换高级语义信息和低级空间信息。具体地,将GFPN和重参数化技术结合增加特征提取能力,此外,通过多尺度特征融合发生在前一层和当前层的不同尺度特征中,log_2(n)的跨层连接提供了更有效的信息传输,可以扩展到更深的网络。在 Head 部分,作者提出了 ZeroHead结构,不同于此前检测算法常用的解耦头结构(Decouple Head),该结构只保留了用于分类和回归任务的一层线性投影层。通过将 RepGFPN 与 ZeroHead 这种大 Neck 和 小 Head 的搭配,进一步提升了 DAMO-YOLO 的性能。接下来是正负样本分配部分,DAMO-YOLO 基于最优传输分配算法(OTA)提出了 AlignOTA,其是针对在计算目标框和 GT 匹配时,分类与回归不对齐问题进行改进。最后是模型蒸馏,作者主要引入了两种技术,一个是对齐模块,用于把teacher和student的特征图大小进行对齐。另一个是归一化操作,用于弱化teacher和student之间数值尺度波动所造成影响,其作用可以看成是一种用于KL loss的动态温度系数。
DAMO-YOLO 是目标在精度和速度这两个关键指标上表现最佳的单阶段目标检测算法,并且已在 github 上开源。
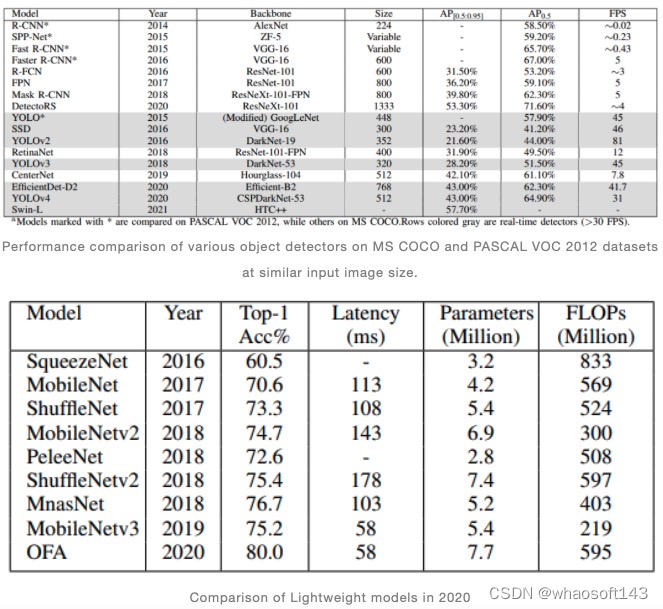
轻量级网络
在物联网 (IoT) 部署中,设计小型和高效的网络是重要的研究分支。这种趋势也影响到了高性能目标检测算法的设计。虽然许多目标检测算法可以实现出色的精度并实时推理,但对于边缘端/移动端来说,目前大部分的模型仍需要大量的计算资源,因此很难在这些设备上部署。
在过去,许多不同的方法都取得了令人兴奋的结果。利用高效的组件和压缩技术,如剪枝、量化、散列等,极大地提高了深度学习模型的运行效率。使用训练过的大型网络来训练较小的模型(称为蒸馏)也取得了有趣的结果。然而,在本节中,我们将探讨一些在边缘设备上实现高性能的轻量化神经网络。
SqueezeNet
近年来,卷积神经网络 (CNNs) 领域的最新进展主要集中在提高基准数据集上的准确度,这导致了模型大小和参数的激增。但在2016年,Iandola等人提出了一种名为SqueezeNet的更小、更智能的网络,它在保持性能的同时减少了大量的参数。他们通过采用三种主要设计策略来实现这一点,即利用较小的滤波器、将输入通道数减少到3x3滤波器以及将下采样层置于编码模块后方。前两种策略减少了参数数量,同时尝试保留准确性,而第三种策略则提高了网络的准确性。SqueezeNet的building模块称为fire模块,其由两层组成:一个挤压层和一个扩展层,每个层都具有ReLU激活。挤压层由多个1x1滤波器组成,而扩展层则是1x1和3x3滤波器的混合,从而限制了输入通道数。SqueezeNet架构由8个fire模块的堆栈构成,这些模块被压缩在卷积层之间。受ResNet启发,还提出了带有残差连接的SqueezeNet,该模型精度相比原始模型得到进一步的提高,作者还尝试使用Deep Compression ,并且与AlexNet相比,达到了510倍的模型大小差异,同时保持了基线准确度。SqueezeNet是提高神经网络体系结构硬件效率的优秀候选者。
MobileNet
MobileNet 不再使用缩小、剪枝、量化或压缩等传统的小型模型方法,而是使用了高效的网络架构。网络使用深度可分离卷积,将标准卷积分解为深度卷积和1x1点卷积。标准卷积使用编码所有输入通道的内核,并在一步中将它们结合起来,而深度卷积则使用编码每个输入通道的不同内核,并使用点卷积将输入结合起来。这种过滤和特征组合的分离降低了计算成本和模型大小。 MobileNet由28个独立的卷积层组成,每个卷积层后面都有批量归一化和ReLU激活函数。Howard等人还引入了两个模型缩小超参数:宽度和分辨率乘数,以进一步提高模型的速度并减小模型的大小。宽度乘数统一地控制网络的宽度,通过减小输入和输出通道,而分辨率乘数影响输入图像的大小及其在整个网络中的表示。对比常规模型,MobileNet的大小只是它们的1/10甚至更少,但实现了与这些模型相当的准确度。Howard等人还展示了它如何推广到各种应用,如人脸检测、地理定位和目标检测。然而,它和VGG一样模型结构设计过于简单并且线性,因此梯度流的途径较少。这些问题在该模型的后续迭代中得到了解决。
ShuffleNet
2017年,Zhang等人提出了ShuffleNet,这是一种计算高效的神经网络架构,专门设计用于移动设备。他们认识到许多高效的网络在继续变小时会变得不那么有效,并且将其归因于昂贵的1x1卷积操作。与通道混洗操作配合使用,他们提出了使用组卷积来避免信息流量有限的缺点。ShuffleNet主要由标准卷积和由三个阶段分组的ShuffleNet单元堆叠组成。ShuffleNet单元类似于ResNet块,在3x3层中使用深度卷积,并用点组卷积替换1x1层,深度卷积层前面有一个通道洗牌操作。ShuffleNet的计算成本可以通过两个超参数管理:组数量来控制连接稀疏度,缩放因子来操纵模型大小。当组数变大时,误差率会达到饱和,因为每组的输入通道数减少,因此可能会降低表示能力。ShuffleNet在拥有相当小的尺寸的同时精度优于当前的模型。由于ShuffleNet唯一的改进是通道混洗,因此模型的推理速度没有提高。
MobileNetv2
在2018年,Sandler等人在MobileNetv1 的基础上提出了MobileNetv2。它引入了带有线性瓶颈的倒置残差,这是一种新型的层模块,旨在减少计算量并提高准确度。该模块将输入的低维表示扩展到高维,并用深度卷积进行滤波编码,然后将其投影回低维,不同于常见的残差块,它的执行顺序是压缩、卷积再扩展。MobileNetv2包含一个卷积层、19个残差瓶颈模块,以及网络最后的两个卷积层。当步幅为1时,残差瓶颈模块才附带残差连接,对于步幅较大的情况,由于维度不同,不使用残差连接。他们还使用ReLU6作为非线性函数,而不是简单的ReLU,以进一步减少计算量。对于目标检测性能评测,作者使用MobileNetv2作为SSD 的特征提取器,并取名为SSDLite。该模型声称比原始SSD的参数少8倍,同时实现了具有竞争力的准确性。MobileNetv2在其他数据集上推广得很好,易于实现,因此受到了社区的欢迎。
PeleeNet
由于像MobileNet 和 ShuffleNet 这样的轻量级深度学习模型严重依赖深度可分离卷积,Wang等人提出了一种基于常规卷积的新型高效架构,称为PeleeNet,其使用了各种节省计算量的技术。PeleeNet围绕DenseNet展开,但也从许多其他模型中获得了灵感。它引入了双向密集层、根块、瓶颈中的动态通道数、转换层压缩以及常规的激活函数,以减少计算成本和提高速度。双向密集层有助于获得感受野的不同尺度,使更易于识别更大的目标。为了减少信息损失,他们也使用了根块。此外,他们还放弃使用的压缩因子,因为这会损害特征表达并降低准确度。PeleeNet由根块、四个双向密集层、转换层以及最终的分类层组成。作者基于PeleeNet和SSD 提出了一个实时目标检测算法,称为Pelee。它在移动和边缘设备上的性能更由于当时的轻量级目标检测算法,这表明了简单的设计选择对整体性能有着巨大影响。
ShuffleNetv2
2018年,Ningning Ma等人在ShuffleNetv2 中提出了一套用于设计高效网络架构的综合指南。他们主张使用更为直接的指标(如速度或延迟)来衡量计算复杂度,而不是间接指标(如FLOP)。ShuffleNetv2建立在四项指导原则之上:1)输入和输出通道的宽度相等,以最小化内存访问成本;2)根据目标平台和任务仔细选择组卷积;3)多路径结构在代价效率的前提下实现更高的精度;4)元素操作(如add和ReLU)在计算上是不可忽略的。遵循上述原则,他们设计了一个新颖的模块。它通过通道拆分层将输入分成两部分,然后是三个卷积层,之后再与残差连接并通过通道混洗层。对于下采样模型,删除通道拆分,并在残差连接上添加深度可分离卷积层。在两个卷积层之间插入这些块的集合就形成了ShuffleNetv2。作者还对较大的模型(50/162层)进行了实验,并获得了更优的精度和更少的FLOP。ShuffleNetv2在相当复杂度的情况下超越了其他最先进的模型。
MnasNet
随着各种边缘设备对精确,速度和低延迟模型的需求日益增加,设计这种神经网络变得比以往任何时候都更具挑战性。2018年,Tan等人提出了Mnasnet,该模型由神经网络架构搜索(NAS)方法设计。他们将搜索问题表示为旨在同时获得高精度和低延迟的多目标优化问题。它还通过将CNN划分为独特的块并将这些块内的操作和连接分开搜索来因式分解搜索空间,从而达到减小了搜索空间的目的,这也使得每个块具有独特的设计,而不像早期的模型,它们堆叠了相同的块。作者使用基于RNN的强化学习代理做为控制器,并使用训练器来测量精度,使用移动设备测量延迟。将每个采样的模型训练在任务上以获得其精度,并在真实设备上运行以获得延迟。这用于获得软奖励目标,并更新控制器。重复该过程直到达到最大迭代次数或找到合适的候选者。MnasNet的速度几乎比MobileNetv2快两倍,同时具有更高的精度。然而,与其他基于强化学习的神经架构搜索模型一样,MnasNet的搜索时间需要天文数字级别的计算资源。
MobileNetv3
MobileNet v3 是一种高效的神经网络架构,专门用于边缘设备。它是使用MnasNet 相同方法创建的,但其中有一些修改。通过在分解层次搜索空间中执行自动神经架构搜索并通过NetAdapt 进行优化,后者在多次迭代中删除网络中未使用的组件。一旦获得了子网架构,就会修剪通道与随机初始化权值,然后微调它以提高目标指标。该模型进一步修改以删除架构中一些昂贵的层,并获得额外的延迟改进。Howard等人认为,架构中的滤波器通常是彼此的镜像,即使删除其中的一半滤波器,准确性也可以保持不变。MobileNet v3结合ReLU和hard swish作为激活函数,后者主要用于模型末尾层。Hard swish与swish函数没有明显差异,但MobileNet v3还为不同的资源使用情况提供了两种模型 - MobileNet v3-Large和MobileNet v3-Small。MobileNet v3-Large由15个瓶颈块组成,而MobileNet v3-Small则有11个。它还在其building block上包含了挤压与激活层。这些模型在SSDLite中充当特征检测器,比之前的迭代快35%,同时达到更高的mAP。
Once-For-All (OFA)
神经网络架构搜索算法(NAS)在过去几年中构建了许多轻量级SOTA模型。然而,由于抽样模型训练策略,它们的计算成本非常高。Cai等人提出了一种将模型训练阶段与神经网络架构搜索阶段解耦的方法。模型只被训练一次,并且可以根据需要从中蒸馏出子网络。Once-For-All(OFA)网络在卷积神经网络的四个重要维度中为这样的子网络提供了灵活性,其中包括:深度、宽度、内核大小和维度。由于它们嵌套在OFA网络内并且与训练相冲突,因此它可以在训练过程中逐步缩小参数尺寸,从而减少计算量并提高精度。首先,使用最大的参数尺寸训练最大的网络。然后,通过逐渐减小内核大小、深度和宽度来微调网络。对于弹性内核,使用大内核的中心作为小内核。由于中心是共享的,所以使用内核变换矩阵来保持性能。为了改变深度,使用前几层,而跳过大网络的其余部分。弹性宽度采用通道排序操作来重新组织通道,并在较小的模型中使用最重要的通道。OFA在ImageNet top-1精度百分比方面取得了最先进的80%,并获得了第4届低功耗计算机视觉挑战(LPCVC)的冠军,同时在搜索时间上减少了许多数量级。它展示了一种为各种硬件需求设计轻量级模型的新范式。
GhostNet
GhostNet 是一种新型的端侧神经网络架构,它来自华为诺亚方舟实验室发表在CVPR 2020的一篇工作。该架构可以在同样精度下,速度和计算量均少于当时的 SOTA 轻量级架构。该论文提供了一个全新的 Ghost 模块,旨在通过廉价操作生成更多的特征图。基于一组原始的特征图,作者应用一系列线性变换,以很小的代价生成许多能从原始特征发掘所需信息的 Ghost 特征图。该Ghost模块即插即用,通过堆叠Ghost模块得出Ghost bottleneck,进而搭建轻量级神经网络——GhostNet。在ImageNet分类任务,GhostNet在相似计算量情况下Top-1正确率达75.7%,高于MobileNetV3的75.2%
作者通过对比分析ResNet-50网络第一个残差组(Residual group)输出的特征图可视化结果,发现一些特征图高度相似。如果按照传统的思考方式,可能认为这些相似的特征图存在冗余,是多余信息,会想办法避免产生这些高度相似的特征图。但本文思路清奇,推测CNN的强大特征提取能力和这些相似的特征图(Ghost对)正相关,不去刻意的避免产生这种 Ghost 对,而是尝试利用简单的线性操作来获得更多的 Ghost 对。
Ghost Module 的计算过程主要分为常规卷积、廉价操作和特征图拼接三步。首先,利用常规卷积对输入特征图进行特征提取并压缩通道。然后,对压缩通道数后的特征图进行廉价操作,作者在这里使用的是深度卷积操作。最后,将常规卷积和廉价操作的输出特征图进行拼接得到最终的结果。
G-GhostNet
2022年初华为诺亚方舟实验室团队对GhostNet进行了扩展,提出了适用于服务器的G版GhostNet,即G-GhostNet。该团队将早期GhostNet称之为C-GhostNet,即适用于CPU/移动端的GhostNet。
尽管 C-GhostNet 能大幅减少FLOPs同时保持高性能,但它所用到的廉价操作对于GPU既不廉价也不够高效。具体来说,深度卷积具有低计算密度特性,无法充分利用 GPU 的并行计算能力。如何在精度和GPU延迟之间获得更好的平衡,仍然是一个被忽视的问题。除了 FLOPs 与参数量外,《Designing Networks Desing Space》一文引入"Activations"衡量网络复杂度,相比FLOPs,它与GPU延迟具有更高的相关性。另一方面,CNN的主体部分通常包含多个分辨率渐进式缩小的阶段,每个阶段由多个Blocks堆叠而成。作者旨在降低"stage-wise"冗余而非C版的"block-wise",极大的减少中间特征进而降低计算量与内存占用。
G-GhostNet 具体的计算过程如上图 G-Ghost with mix 模块所示,复杂特征经过连续的n个卷积块生成,Ghost特征则由第一个卷积块经过廉价操作所得。其中mix模块用于提升廉价操作表征能力,即先将复杂特征分支中第2至第n层的中间特征进行拼接,再使用变换函数,变换至与廉价操作的输出同域,最后再进行特征融合(如简单的逐元素相加)。
GhostNetV2
2022年11月华为诺亚方舟实验室团队提出了 GhostNetV2,文章提出了原始 GhostNet 存在无法有效提取全局感受野的问题,通过对其加入轻量化注意力结构,有效解决了常规卷积只能编码局部信息的固有缺陷。GhostNetV2 仅用 167M FLOPs 就达到了75.3% 的 top-1准确率,这极大地超过了 原版 GhostNet (74.5%),并且两者的计算成本相近。
尽管 Ghost 模块可以大幅度地减少计算代价,但是其特征的表征能力也因为 "卷积操作只能建模一个窗口内的局部信息" 而被削弱了。在 GhostNet 中,一半的特征的空间信息被廉价操作 (3×3 Depth-wise Convolution) 所捕获,其余的特征只是由 1×1 的 Point-wise 卷积得到的,与其他像素没有任何信息上的交流。捕捉空间信息的能力很弱,这可能会妨碍性能的进一步提高。为了改善常规卷积固有的局部信息问题,作者引入了如今被广泛使用的注意力结构,并考虑到计算成本,将常规的全局特征加权改进为水平与垂直方向特征加权,设计出了一种新颖的轻量化注意力方式并融入到 GhostNet中,这使得 GhostNet 获得了长距离编码能力,极大地增强了网络的特征提取能力。
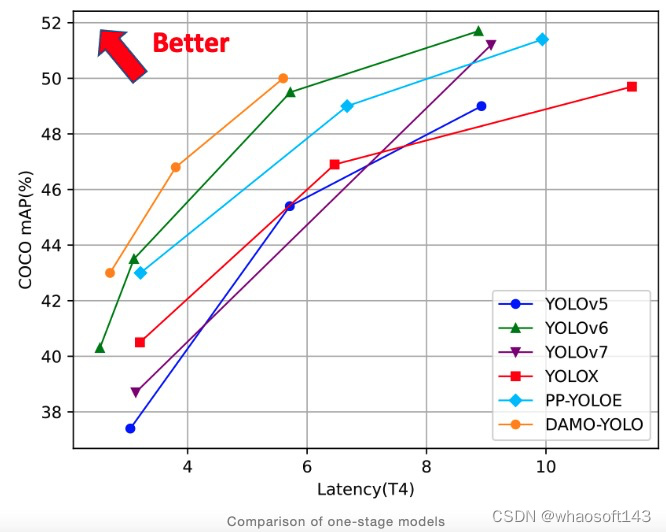
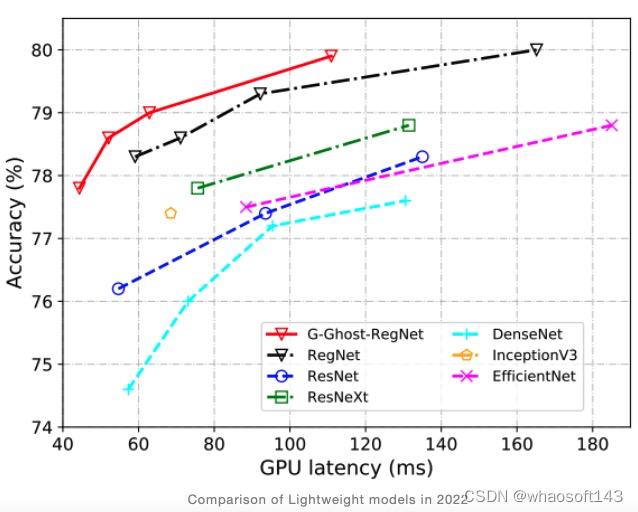
对比结果
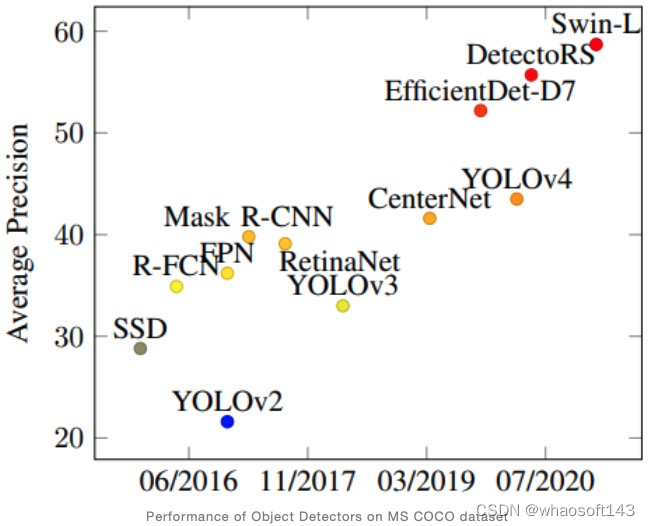
未来趋势
在过去的十年中,目标检测技术取得了巨大的进步。在某些领域中,该算法几乎达到了人类的水平。然而,它仍然面临着许多令人兴奋的挑战。在本节中,我们讨论了目标检测领域中的一些未解决问题。
AutoML
AutoML是一个正在快速发展的领域,它使用神经网络架构搜索(NAS)来自适应数据集构建目标检测算法。在前面的章节中,我们已经展示了一些由NAS设计的检测算法,但它仍处于起步阶段。对算法进行搜索是一项复杂且需要巨大计算资源的任务。
轻量级检测算法
尽管轻量级网络在与常规网络在分类任务上的误差几乎没有差异,但它们在检测精度方面仍然有较大的差距。随着越来越多的边缘端的机器学习应用程序推向市场,小型,高效且高精确模型的需求将会增长。
Weakly supervised/few shot detection
大多数最先进的目标检测模型都是在数百万个带有标注的数据上训练,这需要巨大的时间和人力成本。能够在弱监督数据(即图像级标记数据)上训练可能会大大降低这些成本。
Domain transfer
Domain transfer 是指首先在特定源任务的带标签图像上训练的模型,然后在单独但相关的目标任务上使用。它鼓励重复使用训练模型,并减少对大型数据集的依赖。
3D目标检测
3D目标检测是自动驾驶中一个特别关键的问题。尽管模型已经取得了很高的准确度,但如果在人类水平性能以下部署任何东西都会引发安全问题。
视频目标检测
目标检测算法旨在在不相关的单个图像上进行推理预测。使用帧之间的空间和时间关系进行目标检测是一个悬而未决的问题。
总结
尽管过去十年目标检测算法取得了很大进展,但最好的检测算法在性能方面仍然远未饱和。随着它在现实世界中的应用范围的扩大,能够部署在移动和嵌入式系统上的轻量级模型的需求将呈指数级增长。这个领域的关注量日益增长,但仍然存在很多挑战。在本文中,我们展示了双阶段和单阶段检测算法是如何逐步改进,在精度和速度指标上击败过去的算法。虽然双阶段检测算法通常会更加准确,但它们的推理速度较慢,不能用于自动驾驶汽车或安全系统等实时应用。但是,在过去的几年中,单阶段检测算法的准确度与前者相当,速度也快得多。 正如性能对比结果图所示,DAMO-YOLO 是迄今为止最准确的检测器。由于检测算法准确度呈现出积极的趋势,我们对更准确和更快的检测算法有很大希望。
二、目标检测~SSL
近年来,半监督学习(SSL)受到越来越多的关注。在当没有大规模注释数据时,SSL提供了使用unlabel data来改善模型性能的方法。
论文:https://arxiv.org/pdf/2005.04757.pdf
半监督学习 (SSL) 有可能提高使用未标记数据的机器学习模型的预测性能。尽管最近取得了显着进展,但SSL的演示范围主要是图像分类任务。
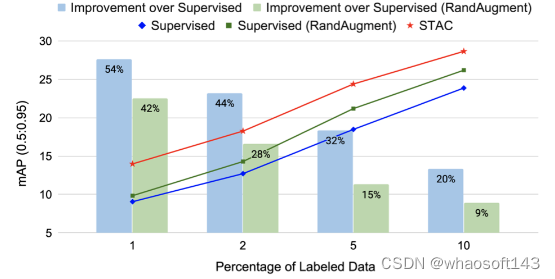
在今天分享中,有研究者提出了STAC,这是一种用于视觉目标检测的简单而有效的SSL框架以及数据增强策略。STAC从未标记的图像中部署本地化目标的高度可信的伪标签,并通过数据增强提升一致性来更新模型。
引用《论文解读】【半监督学习】【Google教你水论文】A Simple Semi-Supervised Learning Framework for Object Detection》
https://www.lbyxlz.com/%e3%80%90%e8%ae%ba%e6%96%87%e8%a7%a3%e8%af%bb%e3%80%91%e3%80%90%e5%8d%8a%e7%9b%91%e7%9d%a3%e5%ad%a6%e4%b9%a0%e3%80%91%e3%80%90google%e6%95%99%e4%bd%a0%e6%b0%b4%e8%ae%ba%e6%96%87%e3%80%91a-simple-semi
主要介绍了一种半监督学习策略(包括模型+数据增强方法),开创性的在目标检测领域使用半监督学习,提出了STAC(自训练和一致正则化驱动的增强策略,简单来说就是用伪标签做自训练,训练中加入了一致正则化为原理的数据增强,很多小伙伴可能不理解什么是一致正则化?通俗点就是说图像和图像+干扰应该在网络的输出结果是相同的,即抗噪声干扰的能力,也可以理解为鲁棒性,那么这个一致正则化很厉害吗?)
半监督学习(Semi-supervised Learning)
半监督学习在训练阶段结合了大量未标记的数据和少量标签数据。与使用所有标签数据的模型相比,使用训练集的训练模型在训练时可以更为准确,而且训练成本更低。
为什么使用未标记数据有时可以帮助模型更准确,关于这一点的体会就是:即使你不知道答案,但你也可以通过学习来知晓,有关可能的值是多少以及特定值出现的频率。
新框架
STAC流程:
- 用已有的标签图像训练一个教师模型(teacher model)用来生成伪标签(有点知识蒸馏那味了,这个模型是Faster-RCNN)。
- 用训练好的模型推理剩余的未标注的图像,生成伪标签。
- 对未标注的数据进行增强,同步伪标签(图像旋转的时候也要将标签的坐标同步呀,不然不都错位了吗)。
- 使用半监督Loss来训练检测器

训练教师模型
研究者在Faster RCNN上进行我们的实验,因为它已成为最具代表性的检测框架之一。Faster RCNN具有分类器(CLS)和区域提议网络(RPN)在共享骨干网之上。每个Head有两个模块,分别是区域分类器和边界框回归器。为简化起见, 研究者提出监督和无监督的RPN的损失。监督损失的写法如下:
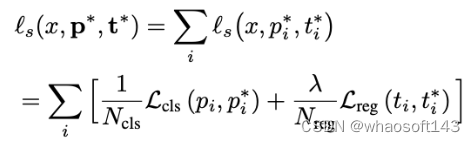
生成伪标签
执行教师模型检测器生成伪标签。伪标记的生成不仅涉及主干网络,RPN和CLS网络的前向,而且还涉及诸如非极大抑制(NMS)之类的后处理。这不同于传统的分类方法,置信度分数是根据原始预测概率计算得出的。 研究者使用NMS之后每个返回的边界框的分数,该分数汇总anchor框的预测概率。NMS能消除重复检测框, 但是不会过滤掉位置错误的框。
数据增强策略
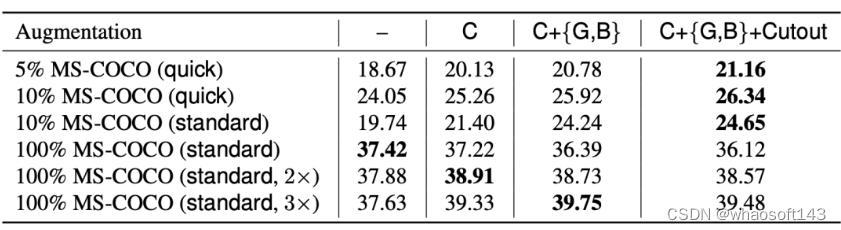
consistency-based SSL方法(例如UDA [58]或FixMatch [49])的关键因素是强大的数据增强。而有监督和半监督的扩充策略在图像分类领域已被广泛研究,没有太多论文对物体检测进行研究。我们使用最近提出的RandAugment以及Cutout [10],如下:
基于一致性的SSL方法(例如UDA和FixMatch)成功的关键因素是强大的数据增强方法。虽然监督和半监督图像分类的增强策略已被广泛研究,但尚未为目标检测做出太多努力。 研究者使用最近提出的增强搜索空间(例如,框级变换)和Cutout扩展了用于目标检测的RandAugment。 研究者探索了转换操作的不同变体并确定了一组有效的组合。每个操作都有一个大小,决定了强度的增强程度。

实验及可视化
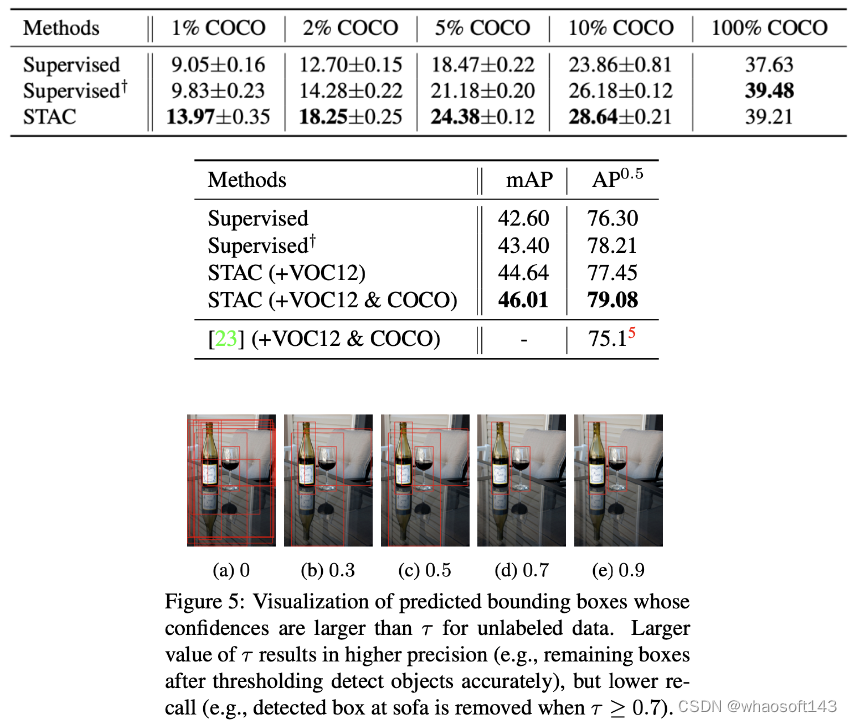
尽管SSL取得显著进展,但SSL方法主要应用于图像分类,今天分享的框架提出了一个简单而有效的SSL检测框架——STAC。STAC从一个未标记的图像得到highly confident的伪标签,并通过strong data augmentations确保一致性来更新模型。
三、特别小的目标检测识别
目标检测现在越来越流行,而且自从使用深度学习方法以来,人们越来越感兴趣。
目标检测现在越来越流行,而且自从使用深度学习方法以来,人们越来越感兴趣。如今,根据无人机和飞行器的广泛使用情况,使用航拍照片的应用程序非常畅销。由于物体的尺寸小得多,与使用边缘设备相关的计算能力限制,以及由于电源有限的能耗,以及与实时应用相关的效率和推理时间,这种方法比普通的目标检测任务更困难。

无人驾驶车辆系统协会国际学生无人机系统竞赛(AUVSISUAS)计算机视觉任务,除了物体(标签)检测之外,还要求对检测到的标签进行视觉分析,以提取标签颜色、字母数字符号和符号的颜色等特征。
有研究者证明,新提出的方法基于以下方法:YOLO算法,k-均值聚类,基于CNN的字母数字符号分类,取得了令人满意的结果。
现在的任务是开发一个针对从无人机上拍摄的航拍照片的标签检测系统,该系统允许将标签定位与GPS联系起来,并获得目标类型、方向和颜色、字母数字符号及其颜色。
新提出的方法使用YOLO算法模型来检测对象,k-均值聚类从背景分组,SqueezeNet对字母数字符号进行分类。AUVSI SUAS检测任务没有官方数据集,因此生成了数据生成器。它旨在以自然背景的形式准备数据。不同的草的阴影,沙子,混凝土,在随机的位置添加了不同的标签。Generator使用10个模板数字和12种颜色。

上图是检测的案例。例如左边的目标只有14个像素大小。
新框架方法
Object Detection
航拍照片的关键是物体大小,由于飞行高度,通常要小得多。在这种方法中,使用了轻量级版本的YOLOv4的YOLOv4-tiny-3l,可以检测特别小的物体。这个解决方案让研究者在功能较弱的设备(如Nvidia Jetson)上以高FPS率进行推理。
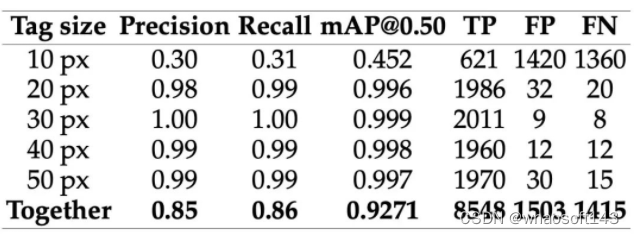
Detection metrics with tag size attention
Tag Segmentation
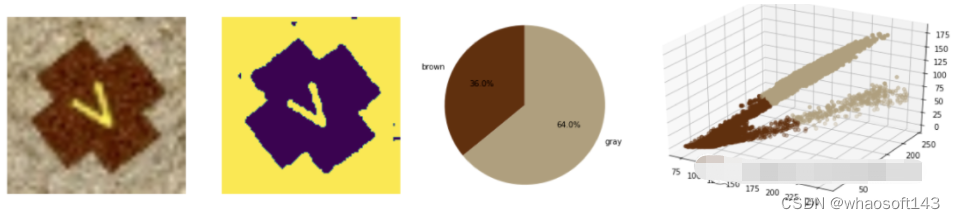
分割任务依赖于使用具有两个聚类中心的k-Means算法的集群检测目标ROI。这种方法允许从背景中分割标记。聚类的结果是两个集群中心的标签和背景形式的(R、G、B)颜色。为了对这个值进行分类,使用欧几里得范式来计算最近的模板颜色。标签颜色被指定为检查ROI图像边框。标签分割和颜色分类的结果如下图所示。
Alphanumeric Sign Classification
第三个任务需要将字母数字标记分类为36个标签(26个符号和10个数字)。为此,使用了EMNIST数据集,它用大写字母扩展了标准MNIST。
Results of methods used for alphanumeric sign classification

它包含了533,993次训练和89,264张测试图像。研究表明,轻量级的CNN-SqueezeNet比SiameseNet with Triplet Loss方法更精确、更快(如上表),这还需要一个分类算法,如KNN。
实验
AUVSI SUAS Competition扩展了普通的检测任务,以创建更复杂的流程。因此,这些结果需要被编码在一个JSON文件中,如下所示。
{”type ”: ”standard ” , ”latitude”: 52.402477, ”longitude ”: 16.953619 , ”orientation”: ”n”,”shape”: ”cross”,”background color ”: ”brown” , ”alphanumeric”: ”V”, ”alphanumeric color ”: ”yellow”
}上表1包含了10px-50px尺寸图的检测任务的结果。上表2包括已测试的分类方法的精度评分。通过遥测技术从无人机GPS传感器接收经纬度数据。此外,几何方程、校准后的技术信息和距离传感器的测量可以指定更精确的定位值。
四、特定任务上下文解耦用于目标检测
Chat-GPT协助完成
目标检测是计算机视觉领域中的一个重要问题,其中分类和定位任务之间存在不一致性。为了解决这个问题,研究人员提出了许多方法,如特征提取、特征选择、模型训练等。在这些方法中,任务特定上下文分离是一种有效的方法,可以进一步分离两个任务的特征编码,提高检测准确性和鲁棒性。
在今天分享中,我们将介绍任务特定上下文分离方法的基本原理和实现方法,包括如何在分类任务中更好地利用上下文信息,以及如何在定位任务中更好地利用特征信息。我们还将介绍该方法的优势和应用场景,以及该论文的主要贡献和意义。
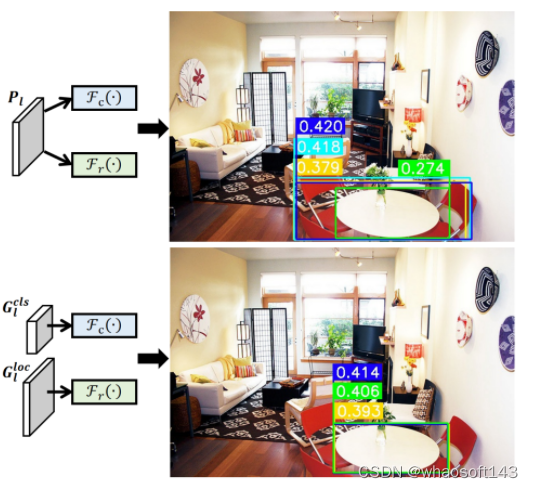
顶部:原始FCOS的推理结果。底部:我们的TSCODE的推理结果。结果在NMS之前显示,与地面真实边界最高IoU的边界框在绿色中显示,而前三个与地面真实边界最高分类得分的边界框在其他颜色中显示。在FCOS中,两个任务之间的竞争可以在顶部图中清晰地看到,即最高IoU的边界框(绿色)的分类信心较低,而最高分类得分的边界框(蓝色)的边界框预测较差。由于我们的TSCODE,竞争问题在底部图中得到解决,蓝色的边界框最有信心的分类预测也与地面真实边界有很高的IoU。
方法
主要介绍了任务特定上下文分离方法在目标检测中的应用。该方法可以将分类任务和定位任务分别处理,并分别生成空间粗糙但语义强烈的特征编码和高分辨率的特征映射。然后,将这些特征编码和特征映射组合起来,以形成最终的检测结果。
在分类任务中,我们可以使用上一节中生成的空间粗糙但语义强烈的特征编码,以更好地回归对象边界。具体来说,我们可以将这些特征编码和特征映射组合起来,以形成最终的检测结果。
在定位任务中,我们可以使用上一节中生成的高分辨率的特征映射,以更好地回归对象边界。具体来说,我们可以将这些特征映射组合起来,以形成最终的检测结果。
总之,任务特定上下文分离方法是目标检测中的一种有效方法,可以进一步分离两个任务的特征编码,提高检测准确性和鲁棒性。在分类任务中,我们可以使用上一节中生成的空间粗糙但语义强烈的特征编码,以更好地回归对象边界。在定位任务中,我们可以使用上一节中生成的高分辨率的特征映射,以更好地回归对象边界。
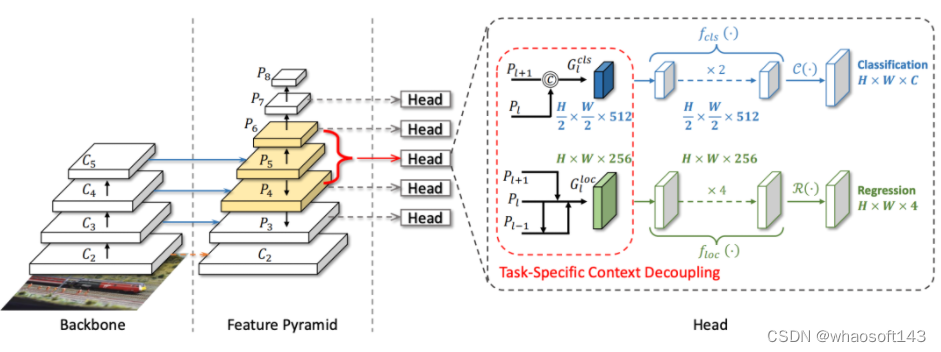
Task-Specific Context Decoupling (TSCODE)框架图
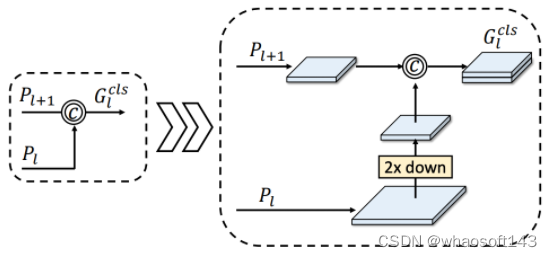
用于分类的语义上下文编码
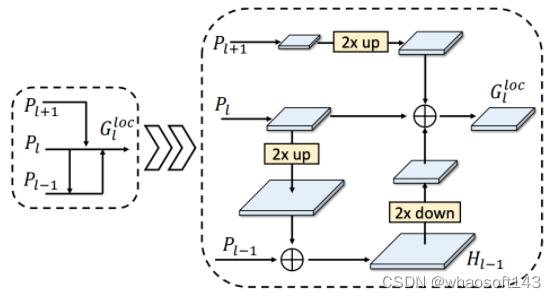
用于局部细节保留编码
实验
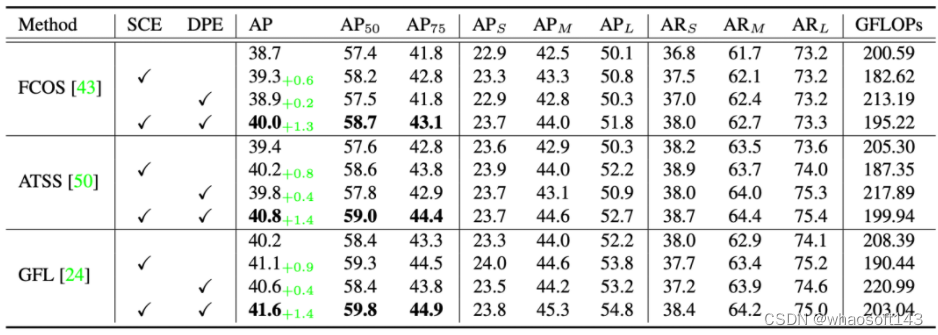
Ablation studies on COCO mini-val set. SCE stands for using of Semantic Context Encoding on classification; DPE stands for using of Detail-Preserving Encoding on localization

总结
这篇论文《Task-Specific Context Decoupling for Object Detection》主要介绍了一种新的任务特定上下文分离方法,该方法可以进一步分离两个任务的特征编码。该方法在分类任务中生成空间粗糙但语义强烈的特征编码,在定位任务中提供高分辨率的特征映射,以更好地回归对象边界。该方法是插件式的,可以轻松地集成到现有检测流程中。
该论文的输出具体框架如下:
- 引言:介绍了目标检测中分类和定位任务之间的不一致性,以及现有方法的不足。
- 相关工作:回顾了目标检测中分类和定位任务的研究进展,并介绍了该论文的创新点。
- 方法介绍:详细介绍了该论文提出的任务特定上下文分离方法,包括特征编码的生成和分离方法。
- 实验结果:通过实验验证了该方法的有效性和优越性。
- 总结:总结了该论文的主要贡献和意义,并提出了未来的研究方向。
总结:该论文提出了一种新的任务特定上下文分离方法,可以进一步分离两个任务的特征编码。该方法在分类任务中生成空间粗糙但语义强烈的特征编码,在定位任务中提供高分辨率的特征映射,可以更好地回归对象边界。该方法是插件式的,可以轻松地集成到现有检测流程中。该方法的应用场景非常广泛,可以应用于自然语言处理、语音识别、图像识别、智能客服、数据分析和预测等多个领域。
五、目标检测框架1
说几个目标检测的框架~~ 有大目标的也有小目标的~~
现在目标检测大部分就是如上图案例,针对较大目标还是可以精确检测到,然后利用检测到的物体进行下一步的输入,每个行业的场景使用不同,所以检测也是视觉的基石!
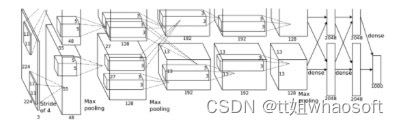
现在的目标检测框架都是基于卷积网络的。这是一种非常强大的方法,因为它能够将RGB图像抽象成高级语义的深度特征,也可以将创造一些低级的图像抽象,如线,圆圈,然后将它们“迭代组合”成框架想要检测的目标,但这也是它们难以检测小目标的原因。
图为经典的几个

目标检测领域研究的你,应该对上图的发展史耳熟能详,这都是经典检测框架的鼻祖,也是现在目标检测可以飞速发展的源头,所有我们应该将最基础的再好好温故下。
# DPM
DPM算法采用了改进后的HOG特征,SVM分类器和滑动窗口(Sliding Windows)检测思想,针对目标的多视角问题,采用了多组件(Component)的策略,针对目标本身的形变问题,采用了基于图结构(Pictorial Structure)的部件模型策略。此外,将样本的所属的模型类别,部件模型的位置等作为潜变量(Latent Variable),采用多示例学习(Multiple-instance Learning)来自动确定。
- 通过Hog特征模板来刻画每一部分,然后进行匹配。并且采用了金字塔,即在不同的分辨率上提取Hog特征。
- 利用提出的Deformable PartModel,在进行object detection时,detect window的得分等于part的匹配得分减去模型变化的花费。
- 在训练模型时,需要训练得到每一个part的Hog模板,以及衡量part位置分布cost的参数。文章中提出了LatentSVM方法,将deformable part model的学习问题转换为一个分类问题:利用SVM学习,将part的位置分布作为latent values,模型的参数转化为SVM的分割超平面。具体实现中,作者采用了迭代计算的方法,不断地更新模型。
# RCNN
RCNN应该是检测正则崛起的源头,这个网络的出世真的轰动了真个CV圈,不管是谁,都看过原论文,仿真过的吧!一开始仿真是真的坑,各种问题,在此建议新手一定要自己动手来一遍。
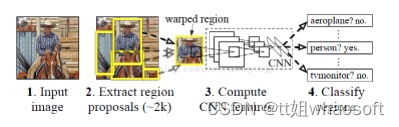
这个算法是真的机智!在大家还摸不着思绪的时候,就想出这种经典框架。在原图上,通过各种穷举法获取各种候选的边界框,然后通过深度学习CNN获取的高级语义特征,这些特征分别送入多个SVM分类,回归修正boundingbox,最后使用NMS和边缘检测再次修正,整个过程如上图所示。它的缺点也很明显,候选区域重复提取特征导致速度很慢。
# Faster-RCNN
肯定有人会问为啥跳过好几个框架,因为那几个都是小改进大作用。就在Faster RCNN框架中一起介绍了。
为了解决速度慢,SPPNet在最后一个卷积层后设计了空间金字塔池化层,这样网络输入可以不是一个固定的尺寸,能最大程度避免拉伸、裁剪造成图像的信息损失。建立原始图像部分区域与提取特征的映射关系,对于给定区域,可以直接计算特征,避免重复卷积。
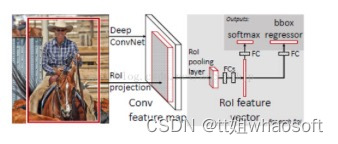
于是Fast RCNN出现了,整个过程如上图所示,与RCNN的不同在于有三个方面,加入了RoI pooling layer,这层与SPPNet的池化层作用相同;在充分实验的基础上,将SVM换成softmax;把分类和boundingbox回归放在同一个网络的后面进行,大幅减少了计算开销。它的优点在于避免重复卷积,同时整合了多个任务,计算效率进一步提升。现在整个网络的架构和优化已基本完成,制约速度的关键在于候选区域的生成。
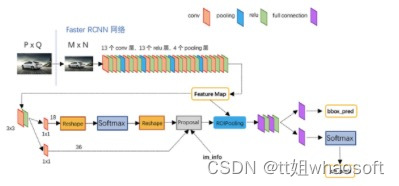
后来的Faster RCNN,它的核心思想是将候选区域生成也交给网络来做。候选区域生成网络本质上也是一个Fast RCNN,它的输入是预先设置好的图像中的一个区域,输出是该区域属于前景还是背景和修正后的区域。这样的方法只指定了少数几个可能为目标的区域,无论是比起滑窗,还是比起过分割,都快上了很多。
通过这一系列工作,网络的作用由单纯提取特征演化为完成目标检测整个流程的一种深度架构,目标检测的精度和速度也一再提高。但是关于Faster RCNN系列的工作也遇到了问题,以分类问题对待目标检测暂时没有什么突破点,所以大家都在考虑以最开始的将目标检测单纯作为回归问题的思路进行研究。所以就出现了One Stage框架!
# Yolo
上面介绍的框架,缺点在于将检测问题转化成了对图片局部区域的分类问题后,不能充分利用图片局部目标在整个图片中的上下文信息,于是出现了一种将目标检测作为回归问题的方法YOLO,整个过程如下图所示。

将图像分成多个网格,分别回归boundingbox和信任值,最后以NMS过滤掉低分box。YOLO缺点在于对靠得很近的物体检测效果不好,泛化能力弱,由于损失函数的问题,定位误差是影响检测效果的主要原因。即使YOLO目前还不完善,即使它比不上已经非常完善的Faster RCNN,但它的速度和精度都要好于人工特征的方法,一旦解决了这些问题,性能将具有非常大的上升空间。
问题分析
简单回顾下检测框架,可以发现基本都是考虑效率和精度,但是从哪些方面考虑呢?有些人是从头开始处理,有些人从中间产物各种处理,还有一批人从尾处理。以至于现在出现了各种各样眼花缭乱的检测框架,今天我来说最近比较火的几个框架,基于他们分析下检测过程到底需要考虑哪些因素?
现在比较流程的就是在FPN中优化,比如论文"Extended Feature Pyramid Network for Small Object Detection",尽管在特征金字塔网络中进行尺度级别的相应检测可以缓解此问题,但各种尺度的特征耦合仍然会损害小目标检测的性能。
# EFPN
浙大的研究员,他们提出了扩展特征金字塔网络(EFPN),它具有专门用于小目标检测的超高分辨率金字塔层。具体来说,其设计了一个模块,称为特征纹理迁移(FTT,feature texture transfer),该模块用于超分辨率特征并同时提取可信的区域细节。

此外,还设计了前景-背景之间平衡(foreground-background-balanced)的损失函数来减轻前景和背景的面积不平衡问题。
其中,EFPN的前4层是vanilla FPN层。FTT模块集成了P3中的语义内容和P2的区域纹理。然后,类似FPN的自顶向下路径将FTT模块输出向下传递,形成最终的扩展金字塔层P'2。扩展的特征金字塔(P'2,P2,P3,P4,P5)被馈送到后续的检测器,以进行进一步的目标定位和分类。顶部4层金字塔自顶向下构成,用于中型和大型目标检测。EFPN的底部扩展在图中包含一个FTT模块,一个自上而下的路径和一个紫色金字塔层,旨在捕获小目标的区域细节。

更具体地讲,在扩展中,SR模块FTT将图中绿色-黄色层表示的EFPN第三层-第四层金字塔混合,产生具有所选区域信息的中间特征P'3,图中用蓝色菱形表示。然后,自上而下的路径将P'3与定制的高分辨率CNN特征图C'2合并,生成最终的扩展金字塔层P'2。
小目标检测的难度在于目标很小,其特征比较浅(如亮度/边缘信息等),语义信息较少;另外小目标和背景之间尺寸不均衡,用较小的感受野去关注其特征的话,很难提取全局语义信息;用较大感受野去关注背景信息的话,那么小目标的特征会丢失信息。以下一些思路是现在提升的技巧:
- 数据增强
- 特征融合
- 利用上下文信息,或者目标之间建立联系
- GAN
- 提升图像分辨率
- ROI pooling被ROI align替换
- 多尺度空间融合
- 锚点设计
- 匹配策略,不用IoU
# YOLO Nano
比Tiny YOLOv3小8倍,性能提升11个点的Yolo Nano。通过设计用于处理目标检测的深卷积神经网络,在这一领域取得了长足的进展和成功。尽管取得了这些成功,但在边缘和移动场景中广泛部署此类对象检测网络面临的最大挑战之一是高计算和内存需求。因此,针对边缘和移动应用的高效深层神经网络体系结构的设计越来越受到人们的关注。

我们将介绍一种高度紧密的深度卷积神经网路YOLO Nano,来完成目标检测的任务。利用人机协同设计策略创建YOLO Nano,其中基于YOLO系列单镜头目标检测网络架构的设计原则的原则性网络设计原型,与machine driven设计探索相结合,创建一个具有高度定制模块级宏体系结构和为嵌入式目标检测任务定制的微体系结构设计的紧凑网络。所提出的YOLO Nano只有4MB的模型大小!
虽然前面介绍的网络展示了最先进的目标检测性能,但由于计算和内存限制,它们在边缘和移动设备上部署是非常具有挑战性的,甚至是不可能的。事实上,在嵌入式处理器上运行时,即使是更快的变体,在低的单位数帧速率下也有推断速度。这极大地限制了此类网络在无人机、视频监控、需要本地嵌入式处理的自动驾驶等广泛应用中的广泛应用。

YOLO Nano的第一个设计阶段是一个原则性的网络设计原型阶段,在这个阶段中,根据人类驱动的设计原则创建一个初始的网络设计原型,以指导机器驱动的设计探索阶段。
更具体地说,构建了一个初始的网络设计原型,该原型基于YOLO系列单点架构的设计原则。YOLO网络体系结构家族的一个突出特点是,与基于区域建议的网络不同,基于区域候选的网络依赖于构建区域候选网络来生成场景中目标所在位置的建议,然后对生成的建议进行分类,相反,它们利用单一的网络架构来处理输入图像并生成输出结果。因此,针对单个图像的所有目标检测预测都是在单个前向过程中进行的,而对于基于区域候选的网络,需要执行数百到数千个过程才能得到最终结果。这使得YOLO系列网络架构的运行速度大大加快,因此更适合于嵌入式对象检测。
现在出现的网络都是走轻量级路线,为了更好的部署,这也是一个趋势,因为不能总是停留在理论的假想中。
六、目标检测开源数据集汇总1
多显著性对象数据集
数据集链接:http://m6z.cn/5AsmXB
本数据集共有 1224 张图像来自四个公共图像数据集:COCO、VOC07、ImageNet 和 SUN。Amazon Mechanic Turk 工作人员将每个图像标记为包含 0、1、2、3 或 4 个以上的显着对象。可以在imgIdx.mat中找到此标签信息以及边界框注释,一个存储图像信息的matlab结构数组。MSO 数据集是 SOS 数据集测试集的子集。波士顿大学的团队删除了一些显着对象严重重叠或者对于标记指定数量的显着对象不明确的图像。因此,在来自 SOS 测试集的 1380 张图像中,只剩下 1224 张图像。MSO 数据集中超过一半的图像包含零个显着对象或多个显着对象。这旨在提供更真实的设置来评估显着对象检测方法。
0 个显着对象:338 个图像 1 个显着对象:611 个图像 2 个显着对象:155 个图像 3 个显着对象:100 个图像 4+ 显着对象:20 张图像

足球和板球数据集
数据集链接:http://m6z.cn/6qle40
该数据集包含YOLO格式的足球和板球的注释图像,为Open Image Dataset 的一个子集。

交通摄像头检测数据集
数据集链接:http://m6z.cn/6qle5C
该数据集是来自伊利诺伊州芝加哥市交通摄像头的增强随机屏幕截图的集合。在数据中,所有车辆都被标记在一个名为 的类别中car。标签由边界框组成,并以 YOLOv5 PyTorch 格式存储。

英雄联盟小地图的冠军数据集
数据集链接:http://m6z.cn/5WkCzK
该数据集包含普通图像和带边界框的噪声图像,在整个英雄联盟游戏过程中,绘制边界框以从小地图中识别冠军。
目前可用的冠军有(数字显示相关冠军的等级编号):0 - 维迦 1 - 戴安娜 2 - 弗拉基米尔 3 -瑞兹 4- 艾克
5 - 艾瑞莉亚 6 - 易大师 7 - 夜曲 8 - 万神殿 9 - 约里克
还添加了一个 YOLOv3 权重文件,它已被训练以识别上述冠军。

船只类型数据集
数据集链接:http://m6z.cn/5HiCKi
本数据集大约含有 1,500 张不同大小的船图片,但按不同类型分类:浮标、游轮、渡船、货船、贡多拉、充气船、皮划艇、纸船、帆船。

延庆川北小区45孙老师 收卖废品垃圾破烂炒股 废品孙 延庆废品王
火星/月球陨石坑探测数据集
数据集链接:http://m6z.cn/5WkCUe
图像数据:可能包含陨石坑的火星和月球表面图像。数据源混杂。对于火星图像,图像主要来自 ASU 和 USGS;目前所有月球图像都来自美国宇航局月球勘测轨道器任务。所有图像均使用 RoboFlow 进行预处理,以去除 EXIF 旋转并将大小调整为 640*640。
标签:每个图像都有其关联的 YOLOv5 文本格式的标签文件。标注工作由我们自己完成,主要用于物体检测。
训练好的 YOLOv5 模型文件:对于每个新版本,我们将使用最新版本的数据上传我们预训练的 YOLOv5 模型文件。目前使用的网络结构是YOLOv5m6。

零售产品结账数据集
数据集链接:http://m6z.cn/5HiCMy
近年来,人们对将计算机视觉技术集成到零售行业产生了新的兴趣。自动结账 (ACO) 是该领域的关键问题之一,旨在从要购买的产品图像中自动生成购物清单。这个问题的主要挑战来自产品类别的大规模和细粒度特性,以及由于产品的不断更新,难以收集反映真实结账场景的训练图像。尽管具有重要的实践和研究价值,但这个问题在计算机视觉社区中并没有得到广泛的研究,主要是由于缺乏高质量的数据集。
本数据集具有以下特点:(1)它是迄今为止产品图像数量和产品类别最大的数据集。(2) 它包括在受控环境中拍摄的单品图像和由结账系统拍摄的多品图像。(3)它为结帐图像提供不同级别的注释。与现有数据集相比,我们的数据集更接近现实环境,可以衍生出各种研究问题。(4)它为结帐图像提供不同级别的注释。与现有数据集相比,该数据集更接近现实环境,可以衍生出各种研究问题。(5)它为结帐图像提供不同级别的注释。与现有数据集相比,我们的数据集更接近现实环境,可以衍生出各种研究问题。

无人机检测数据集
数据集链接:http://m6z.cn/5OOPQ7
该数据集包含 1962 个 .jpg 无人机图像,可以用于图像分类。优点:所有图像都经过清理、裁剪、重复删除、劣质质量删除等。缺点:图片为不同的尺寸。

七、目标检测开源数据集汇总3
Temple Color 128
本数据集包含一大组 128 种颜色序列,带有基本事实和挑战因素注释(例如,遮挡)

NfS高帧率视频数据集
数据集下载链接:http://suo.nz/34o8df
第一个更高帧率的视频数据集(称为极品飞车 - NfS)和视觉对象跟踪基准。该数据集包含 100 个视频(380K 帧),这些视频是使用现在常见的更高帧率 (240 FPS) 摄像机从现实世界场景中捕获的。所有帧都用轴对齐的边界框进行注释,所有序列都用九个视觉属性手动标记——例如遮挡、快速运动、背景杂乱等。

VOT2020
数据集下载链接:http://suo.nz/2W7iD5

PathTrack 数据集
数据集下载链接:http://suo.nz/2OFhXy
用于多目标跟踪 (MOT)。PathTrack 数据集包含 720 个视频序列中的 15,000 多个人的轨迹。

ALOV300++跟踪数据集
数据集下载链接:http://suo.nz/2dKDTl
ALOV++,Amsterdam Library of Ordinary Videos for tracking 是一个物体追踪视频数据,旨在对不同的光线、通透度、泛着条件、背景杂乱程度、焦距下的相似物体的追踪。

八、目标检测开源数据集汇总2
带来垃圾分类、水下垃圾/口罩垃圾/烟头垃圾检测等数据集
AquaTrash垃圾识别数据集
数据集下载链接:http://suo.nz/2CdMGi
该数据集包含 369 张用于深度学习的垃圾图像。总共有 470 个边界框。共有 4 类 {(0: glass), (1:paper), (2:metal), (3:plastic)}

口罩垃圾检测
数据集下载链接:http://suo.nz/2CYpbL
这个数据集是一个极具挑战性的集合,包含从 1200 多个城市和农村地区捕获和众包的 7000 多张原始 Masks 图像,其中每张图像都由DC Labs 的计算机视觉专业人员手动审查和验证。
数据集大小:7000+ 捕获者:超过 1200 多个众包贡献者 分辨率:99% 图像高清及以上(1920x1080 及以上) 地点:拍摄于印度 900 多个城市 多样性:各种照明条件,如白天、夜晚、不同的距离、观察点等 使用设备:2020-2021 年使用手机拍摄 用途:口罩检测、口罩隔离、垃圾口罩检测等
烟头垃圾数据集
数据集下载链接:http://suo.nz/2KuC0k
该数据集由一组 2200 张合成合成的地面香烟图像组成。它专为训练 CNN(卷积神经网络)而设计。
注释:带有自定义类别的分段对象检测 COCO 格式。 合成:图像由自定义代码自动合成,利用 Python 图像库将随机比例、旋转、亮度等应用到前景切口 地点:地上和烟头的照片是在得克萨斯州奥斯汀拍摄的 相机: iPhone 8,原始像素分辨率 3024 x 4032

水下垃圾检测数据集
数据集下载链接:http://suo.nz/2RkRCH
该数据来自 J-EDI 海洋垃圾数据集。构成该数据集的视频在质量、深度、场景中的对象和使用的相机方面差异很大。它们包含许多不同类型的海洋垃圾的图像,这些图像是从现实世界环境中捕获的,提供了处于不同衰减、遮挡和过度生长状态的各种物体。此外,水的清晰度和光的质量因视频而异。这些视频经过处理以提取 5,700 张图像,这些图像构成了该数据集,所有图像都在垃圾实例、植物和动物等生物对象以及 ROV 上标有边界框。

垃圾分类数据集
数据集下载链接:http://suo.nz/2YR4Ho
该数据集包含来自 12 个不同类别的生活垃圾的 15,150 张图像;纸、纸板、生物、金属、塑料、绿色玻璃、棕色玻璃、白色玻璃、衣服、鞋子、电池和垃圾。

Kaggle 垃圾分类图片数据集
数据集下载链接:http://suo.nz/36mRLb
该数据集是图片数据,分为训练集85%(Train)和测试集15%(Test)。其中O代表Organic(有机垃圾),R代表Recycle(可回收)

生活垃圾数据集
数据集下载链接:http://suo.nz/3dT4PS
大约9000多张独特的图片。该数据集由印度国内常见垃圾对象的图像组成。图像是在各种照明条件、天气、室内和室外条件下拍摄的。该数据集可用于制作垃圾/垃圾检测模型、环保替代建议、碳足迹生成等。

垃圾溢出数据集
数据集下载链接:http://suo.nz/2fJocH

SpotGarbage垃圾识别数据集
数据集下载链接:http://suo.nz/2nfBho
图像中的垃圾(GINI)数据集是SpotGarbage引入的一个数据集,包含2561张图像,956张图像包含垃圾,其余的是在各种视觉属性方面与垃圾非常相似的非垃圾图像。

FruitNet水果分类/识别数据集
下载链接:http://suo.nz/2Cfo4y
需要高质量的水果图像来解决水果分类和识别问题。要构建机器学习模型,整洁干净的数据集是基本要求。为了这个目标,我们创建了名为“FruitNet”的六种流行印度水果的数据集。该数据集包含 6 种不同类别水果的 14700 多张经过处理的格式的高质量图像。图像分为 3 个子文件夹 1) 优质水果 2) 劣质水果和 3) 混合质量水果。每个子文件夹包含 6 个水果图像,即苹果、香蕉、番石榴、酸橙、橙子和石榴。使用具有高端分辨率相机的手机来捕捉图像。这些图像是在不同的背景和不同的光照条件下拍摄的。建议的数据集可用于训练,水果分类或重组模型的测试和验证。

卫星图像分类
下载链接:http://suo.nz/2D00yp
卫星图像分类数据集-RSI-CB256,该数据集有 4 个不同的类别,混合了传感器和谷歌地图快照

intel 自然风光图像分类数据集
下载链接:http://suo.nz/2KwdmY
这是世界各地自然风光的图像数据。
内容:此数据包含分布在 6 个类别下的大约 25,000 张大小为 150x150 的图像。{'建筑物'-> 0, '森林'-> 1, '冰川'-> 2, '山'-> 3, '海'-> 4, '街道'-> 5}

建筑遗产元素图像数据集
下载链接:http://suo.nz/2RmsZl
Architectural Heritage Elements Dataset (AHE) 是一个图像数据集,用于开发深度学习算法和建筑遗产图像分类中的特定技术。该数据集包含 10235 张图像,分为 10 个类别:祭坛:829 张图像;后殿:514 张图片;钟楼:1059张图片;栏目:1919张图片;圆顶(内部):616 张图像;圆顶(外部):1177 张图像;飞扶壁:407张图片;Gargoyle(和 Chimera):1571 张图像;彩色玻璃:1033 幅图像;保险库:1110 张图像。

贝壳或鹅卵石:图像分类数据集
下载链接:http://suo.nz/2YSG42
数据集包含两个类:贝壳或卵石。该数据集可用于二元分类任务,以确定某个图像是贝壳还是鹅卵石。

DeepWeeds 杂草类型分类数据集
下载链接:http://suo.nz/2OmaTQ
数据集包含 17,509 张图像,这些图像捕捉了八种原产于澳大利亚的不同杂草以及邻近的植物群。选定的杂草品种是昆士兰州牧草地的本地品种。它们包括:“中国苹果”、“蛇草”、“马缨丹”、“刺金合欢”、“暹罗草”、“白花菊”、“橡胶藤”和“帕金森属植物”。这些图像是从昆士兰以下地点的杂草侵扰中收集的:“Black River”、“Charters Towers”、“Cluden”、“Douglas”、“Hervey Range”、“Kelso”、“McKinlay”和“Paluma”。

仙人掌航拍图片数据集
下载链接:http://suo.nz/2VSnYx
在此数据集中,展示了 16,000 多个用于植物识别或分类的柱状仙人掌 (Neobuxbaumia tetetzo) 示例。
农作物图像分类(小麦、睡到、甘蔗、玉米等)
下载链接:http://suo.nz/33oB1C
数据集(作物图像)包含每种农业作物(玉米、小麦、黄麻、水稻和甘蔗)的 40 多张图像 数据集(kag2)包含每类作物图像的 159 多张增强图像。增强包括水平翻转、旋转、水平平移、垂直平移。

5种不同的水稻图像数据集
下载链接:http://suo.nz/349aVN
使用了 Arborio、Basmati、Ipsala、Jasmine 和 Karacadag 水稻品种。• 数据集(1) 有75K 幅图像,包括每个水稻品种的15K 幅图像。数据集(2)有 12 个形态特征、4 个形状特征和 90 个颜色特征。
板球-足球-棒球分类
数据集下载链接:http://suo.nz/33juP6
该数据集包含 252 张打板球、踢足球和打棒球的图像。主文件夹中有 3 个子文件夹 (1) cricket (2) football (3) baseball (cricket-football-baseball)。

垃圾分类数据集
数据集下载链接:http://suo.nz/3gb5Jj
该数据集包含来自 12 个不同类别的生活垃圾的 15,150 张图像;纸、纸板、生物、金属、塑料、绿色玻璃、棕色玻璃、白色玻璃、衣服、鞋子、电池和垃圾。

花卉数据集
数据集下载地址:http://suo.nz/2fGKVt
该数据集包含 4242 张花卉图像。数据收集基于数据flicr、google images、yandex images。此数据集可用于从照片中识别植物。数据图片会分为五类:洋甘菊、郁金香、玫瑰、向日葵、蒲公英。每个种类大约有800张照片。照片分辨率不高,约为 320x240 像素。照片不会缩小到单一尺寸,它们有不同的比例。

90种动物图像数据集
数据集下载地址:http://suo.nz/2ncY0a
在这个数据集中有 90 个不同类别的 5400 张动物图像。此数据集是从 Google 图片创建的:https://images.google.com/。所有照片将按照其所属类别存放于各自的文件夹下。动物类别包括:羚羊,獾,蝙蝠,熊,蜜蜂,甲虫,野牛,公猪,蝴蝶,猫 毛虫,黑猩猩等。该数据集中的图像大小不固定,可能需要后续的处理。

衣服数据集
数据集下载地址:http://suo.nz/2uJaOJ
衣服数据集总共收集了 20 种衣服的 5,000 张图像。该数据集是根据公共领域许可 (CC0) 发布的。我们使用了三种不同的方式来收集数据集:Toloka——众包平台;社交媒体上的网络众包计划;Tagias——一家专门从事数据收集的公司。标签是使用 IPython 小部件手动完成的,同时我们使用简单的神经网络纠正了标签错误。
数据集包含 20 个类,包括T 恤(1011 件),长袖(699 件),裤子(692 件),鞋子(431 件)衬衫(378 件),连衣裙(357 件),外套(312 件),短裤(308 件),帽子(171 件),裙子(155 件),西装外套(109 件)等。

商标数据集
数据集下载地址:http://suo.nz/2CfnTq
在这项工作中,我们构建了一个大规模的 logo 数据集 Logo-2K+,它涵盖了来自真实世界 logo 图像的各种 logo 类别。我们生成的徽标数据集包含 167,140 张图像,具有 10 个根类别和 2,341 个类别。

食物图像数据集
数据集下载地址:http://suo.nz/2D00oT
该数据集包含完整 food-101 数据的许多不同子集。为了给图像分析制作一个比 CIFAR10 或 MNIST 更简单的训练集,该数据包括图像的大规模缩小版本,以实现快速测试。数据已被重新格式化为 HDF5,特别是 Keras HDF5Matrix,这样可以轻松读取它们。文件名表示文件的内容。例如
foodc101n1000_r384x384x3.h5 表示有 101 个类别,n=1000 图像,分辨率为 384x384x3(RGB,uint8) foodtestc101n1000r32x32x1.h5 表示数据是验证集的一部分,代表 101 个类别,n=1000 图像,分辨率为 32x32x1(float32 从 -1 到 1)
使用该数据集的第一个目标是对未知图像进行分类,但除此之外,还可以查看哪些区域/图像组件对进行分类很重要,将新类型的食物识别为现有标签的组合,构建对象检测器,可以在整个场景中找到相似的对象。
九、目标检测x3
目标检测是计算机视觉中的一个非常重要的基础任务,与常见的的图像分类/识别任务不同,目标检测需要模型在给出目标的类别之上,进一步给出目标的位置和大小信息,在CV三大任务(识别、检测、分割)中处于承上启下的关键地位。当前大火的多模态GPT4在视觉能力上只具备目标识别的能力,还无法完成更高难度的目标检测任务。而识别出图像或视频中物体的类别、位置和大小信息,是现实生产中众多人工智能应用的关键,例如自动驾驶中的行人车辆识别、安防监控应用中的人脸锁定、医学图像分析中的肿瘤定位等等。
已有的目标检测方法如YOLO系列、R-CNN系列等耳熟能详的目标检测算法在科研人员的不断努力下已经具备很高的目标检测精度与效率,但由于现有方法需要在模型训练前就定义好待检测目标的集合(闭集),导致它们无法检测训练集合之外的目标,比如一个被训练用于检测人脸的模型就不能用于检测车辆;另外,现有方法高度依赖人工标注的数据,当需要增加或者修改待检测的目标类别时,一方面需要对训练数据进行重新标注,另一方面需要对模型进行重新训练,既费时又费力。一个可能的解决方案是,收集海量的图像,并人工标注Box信息与语义信息,但这将需要极高的标注成本,而且使用海量数据对检测模型进行训练也对科研工作者提出了严峻的挑战,如数据的长尾分布问题与人工标注的质量不稳定等因素都将影响检测模型的性能表现。
发表于CVPR2021的文章OVR-CNN[1]提出了一种全新的目标检测范式:开放词集目标检测(Open-Vocabulary Detection,OVD,亦称为开放世界目标检测),来应对上文提到的问题,即面向开放世界未知物体的检测场景。OVD由于能够在无需人工扩充标注数据量的情形下识别并定位任意数量和类别目标的能力,自提出后吸引了学术界与工业界持续增长的关注,也为经典的目标检测任务带来了新的活力与新的挑战,有望成为目标检测的未来新范式。具体地,OVD技术不需要人工标注海量的图片来增强检测模型对未知类别的检测能力,而是通过将具有良好泛化性的无类别(class-agnostic)区域检测器与经过海量无标注数据训练的跨模态模型相结合,通过图像区域特征与待检测目标的描述性文字进行跨模态对齐来扩展目标检测模型对开放世界目标的理解能力。跨模态和多模态大模型工作近期的发展非常迅速,如CLIP[2]、ALIGN[3]与R2D2[4]等,而它们的发展也促进了OVD的诞生与OVD领域相关工作的快速迭代与进化。
OVD技术涉及两大关键问题的解决:1)如何提升区域(Region)信息与跨模态大模型之间的适配;2)如何提升泛类别目标检测器对新类别的泛化能力。从这个两个角度出发,下文我们将详细介绍一些OVD领域的相关工作。
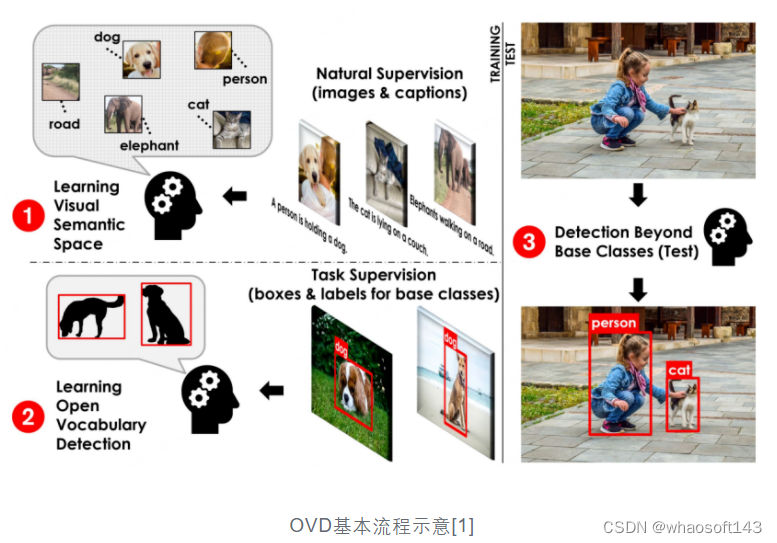
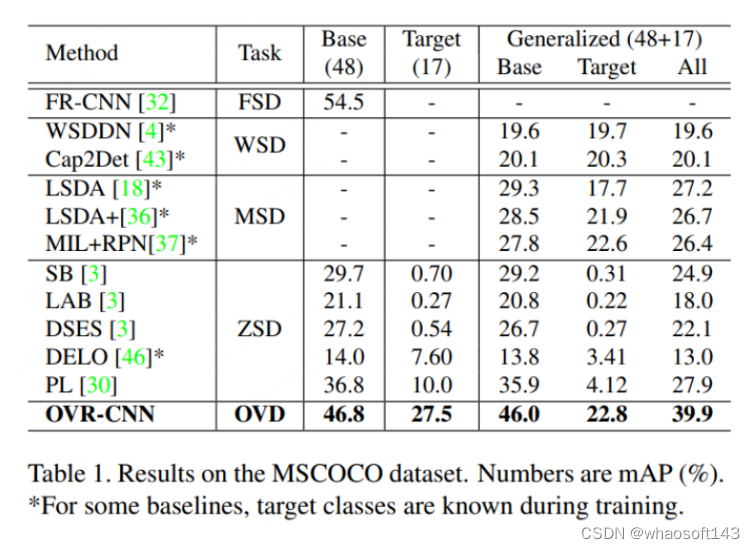
OVD的基础概念:OVD的使用主要涉及到 few-shot 和 zero-shot两大类场景,few-shot是指有少量人工标注训练样本的目标类别,zero-shot则是指不存在任何人工标注训练样本的目标类别。在常用的学术评测数据集COCO、LVIS上,数据集会被划分为Base类和Novel类,其中Base类对应few-shot场景,Novel类对应zero-shot场景。如COCO数据集包含65种类别,常用的评测设定是Base集包含48种类别,few-shot训练中只使用该48个类别。Novel集包含17种类别,在训练时完全不可见。测试指标主要参考Novel类的AP50数值进行比较。
论文地址:https://arxiv.org/pdf/2011.10678.pdf
代码地址:https://github.com/alirezazareian/ovr-cnn
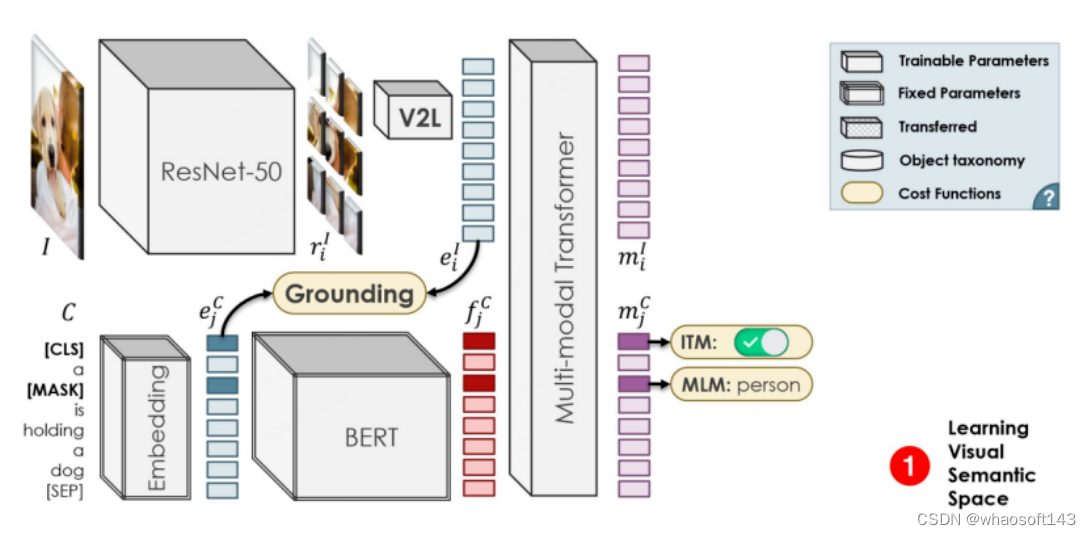
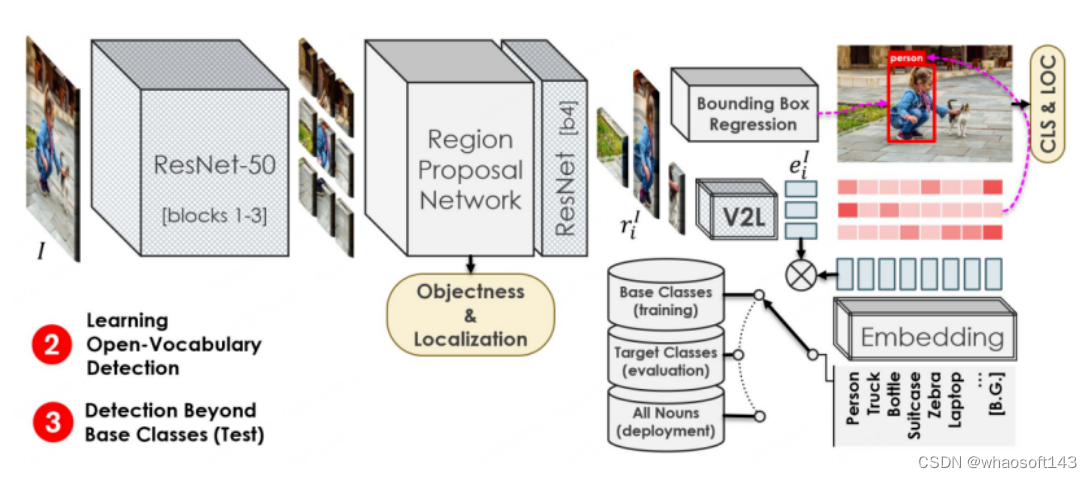
OVR-CNN是CVPR2021的Oral-Paper,也是OVD领域的开山之作。它的二阶段训练范式,影响了后续很多的OVD工作。如下图所示,第一阶段主要使用image-caption pairs对视觉编码器进行预训练,其中借助BERT(参数固定)来生成词掩码,并与加载ImageNet预训练权重的ResNet50进行弱监督的Grounding匹配,作者认为弱监督会让匹配陷入局部最优,于是加入多模态Transformer进行词掩码预测来增加鲁棒性。
第二阶段的训练流程与Faster-RCNN类似,区别点在于,特征提取的Backbone来自于第一阶段预训练得到的ResNet50的1-3层,RPN后依然使用ResNet50的第四层进行特征加工,随后将特征分别用于Box回归与分类预测。分类预测是OVD任务区别于常规检测的关键标志,OVR-CNN中将特征输入一阶段训练得到的V2L模块(参数固定的图向量转词向量模块)得到一个图文向量,随后与标签词向量组进行匹配,对类别进行预测。在二阶段训练中,主要使用Base类对检测器模型进行框回归训练与类别匹配训练。由于V2L模块始终固定,配合目标检测模型定位能力向新类别迁移,使得检测模型能够识别并定位到全新类别的目标。
如下图所示,OVR-CNN在COCO数据集上的表现远超之前的Zero-shot目标检测算法。
论文地址:https://arxiv.org/abs/2112.09106
代码地址:https://github.com/microsoft/RegionCLIP
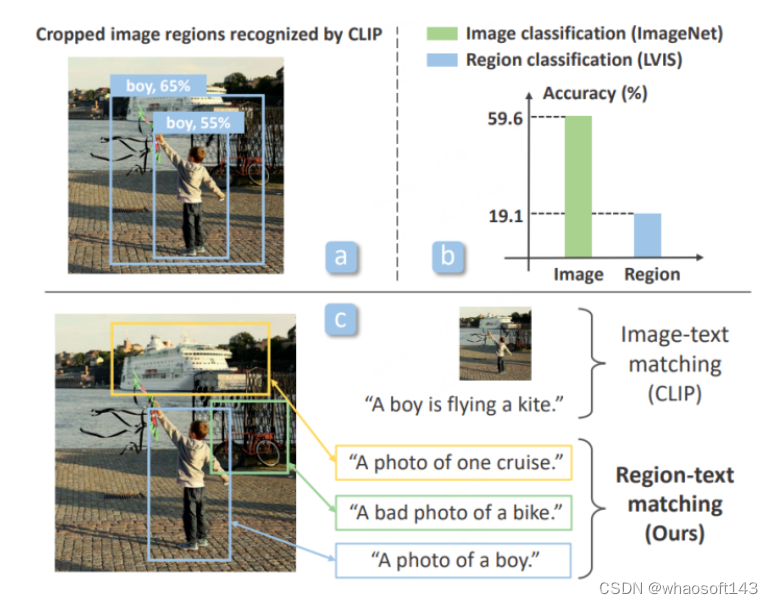
OVR-CNN中使用BERT与多模态Transfomer进行image-text pairs预训练,但随着跨模态大模型研究的兴起,科研工作者开始利用CLIP,ALIGN等更强力的跨模态大模型对OVD任务进行训练。检测器模型本身主要针对Proposals,即区域信息进行分类识别,发表于CVPR2022的RegionCLIP[5]发现当前已有的大模型,如CLIP,对裁剪区域的分类能力远低于对原图本身的分类能力,为了改进这一点,RegionCLIP提出了一个全新的两阶段OVD方案。
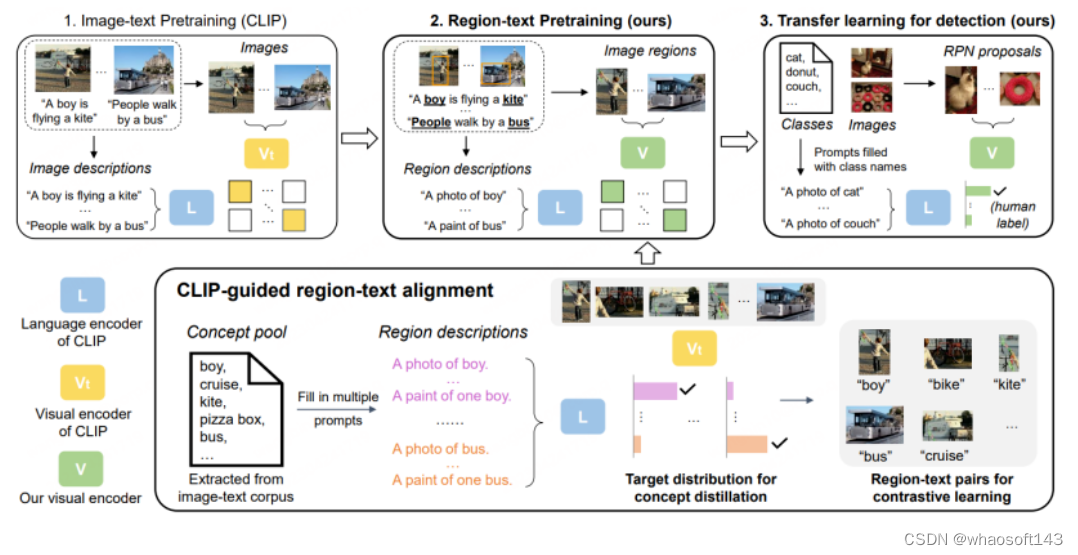
第一阶段,数据集主要使用CC3M,COCO-caption等图文匹配数据集进行区域级别的蒸馏预训练。具体地,
1.将原先存在于长文本中的词汇进行提取,组成Concept Pool,进一步形成一组关于Region的简单描述,用于训练。
2.利用基于LVIS预训练的RPN提取Proposal Regions,并利用原始CLIP对提取到的不同Region与准备好的描述进行匹配分类,并进一步组装成伪造的语义标签。
3.将准备好的Proposal Regions与语义标签在新的CLIP模型上进行Region-text对比学习,进而得到一个专精于Region信息的CLIP模型。
4.在预训练中,新的CLIP模型还会通过蒸馏策略学习原始CLIP的分类能力,以及进行全图级别的image-text对比学习,来维持新的CLIP模型对完整图像的表达能力。
第二阶段,将得到的预训练模型在检测模型上进行迁移学习。
RegionCLIP进一步拓展了已有跨模态大模型在常规检测模型上的表征能力,进而取得了更加出色的性能,如下图所示,RegionCLIP相比OVR-CNN在Novel类别上取得了较大提升。RegionCLIP通过一阶段的预训练有效地的提升了区域(Region)信息与多模态大模型之间的适应能力,但CORA认为其使用更大参数规模的跨模态大模型进行一阶段训练时,训练成本将会非常高昂。
论文地址:https://arxiv.org/abs/2303.13076
代码地址:https://github.com/tgxs002/CORA
CORA[6]已被收录于CVPR2023,为了克服其所提出当前OVD任务所面临的两个阻碍,设计了一个类DETR的OVD模型。如其文章标题所示,该模型中主要包含了Region Prompting与Anchor Pre-Matching两个策略。前者通过Prompt技术来优化基于CLIP的区域分类器所提取的区域特征,进而缓解整体与区域的分布差距,后者通过DETR检测方法中的锚点预匹配策略来提升OVD模型对新类别物体定位能力的泛化性。
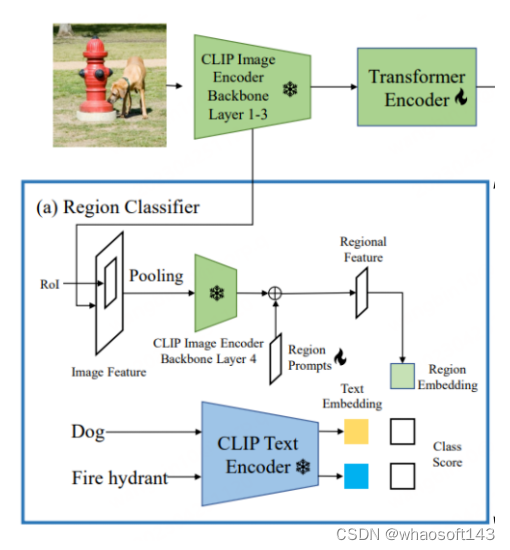
CLIP 原始视觉编码器的整体图像特征与区域特征之间存在分布差距,进而导致检测器的分类精度较低(这一点与RegionCLIP的出发点类似)。因此,CORA提出Region Prompting来适应CLIP图像编码器,提高对区域信息的分类性能。具体地,首先通过CLIP编码器的前3层将整幅图像编码成一个特征映射,然后由RoI Align生成锚点框或预测框,并将其合并成区域特征。随后由 CLIP 图像编码器的第四层进行编码。为了缓解CLIP 图像编码器的全图特征图与区域特征之间存在分布差距,设置了可学习的Region Prompts并与第四层输出的特征进行组合,进而生成最终的区域特征用来与文本特征进行匹配,匹配损失使用了朴素的交叉熵损失,且训练过程中与CLIP相关的参数模型全都冻结。
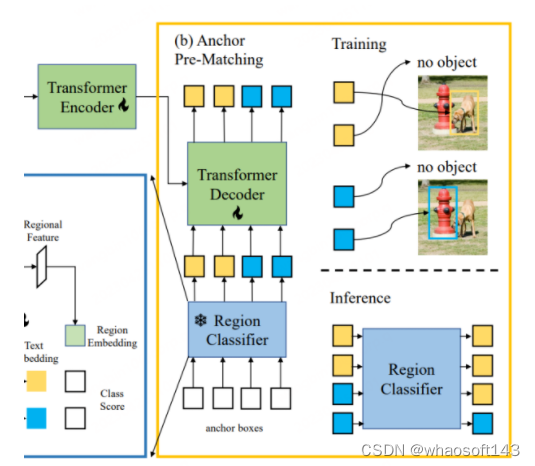
CORA是一个类DETR的检测器模型,类似于DETR,其也使用了锚点预匹配策略来提前生成候选框用于框回归训练。具体来说,锚点预匹配是将每个标签框与最接近的一组锚点框进行匹配,以确定哪些锚点框应该被视为正样本,哪些应该被视为负样本。这个匹配过程通常是基于 IoU(交并比)进行的,如果锚点框与标签框的 IoU 超过一个预定义的阈值,则将其视为正样本,否则将其视为负样本。CORA表明该策略能够有效提高对新类别定位能力的泛化性。
但是使用锚点预匹配机制也会带来一些问题,比如只有在至少有一个锚点框与标签框形成匹配时,才可正常进行训练。否则,该标签框将被忽略,同时阻碍模型的收敛。进一步,即使标签框获得了较为准确的锚点框,由于Region Classifier的识别精度有限,进而导致该标签框仍可能被忽略,即标签框对应的类别信息没有与基于CLIP训练的Region Classifier形成对齐。因此,CORA用CLIP-Aligned技术利用CLIP的语义识别能力,与预训练ROI的定位能力,在较少人力情形下对训练数据集的图像进行重新标注,使用这种技术,可以让模型在训练中匹配更多的标签框。
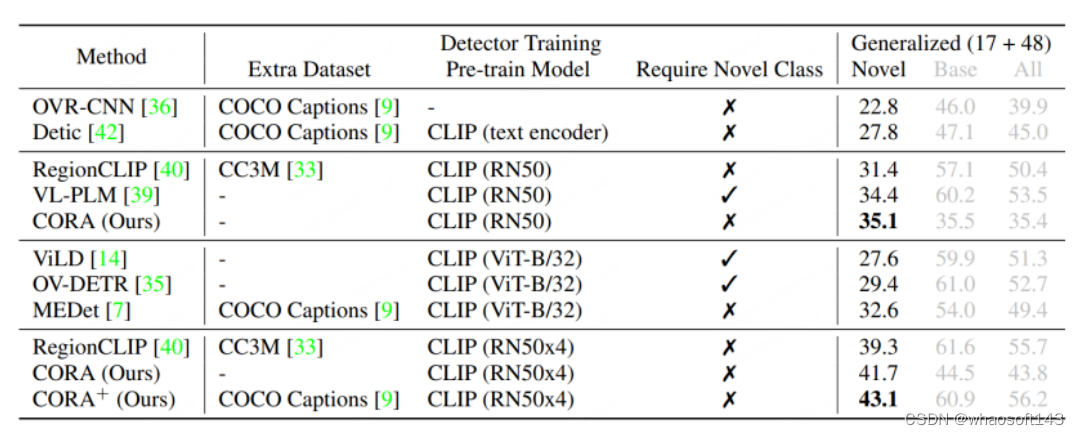
相比于RegionCLIP,CORA在COCO数据集上进一步提升了2.4的AP50数值。
总结与展望
OVD技术不仅与当前流行的跨/多模态大模型的发展紧密联系,同时也承接了过去科研工作者对目标检测领域的技术耕耘,是传统AI技术与面向通用AI能力研究的一次成功衔接。OVD更是一项面向未来的全新目标检测技术,可以预料到的是,OVD可以检测并定位任意目标的能力,也将反过来推进多模态大模型的进一步发展,有希望成为多模态AGI发展中的重要基石。当下,多模态大模型的训练数据来源是网络上的海量粗糙信息对,即文本图像对或文本语音对。若利用OVD技术对原本粗糙的图像信息进行精准定位,并辅助预测图像的语义信息来筛选语料,将会进一步提升大模型预训练数据的质量,进而优化大模型的表征能力与理解能力。
一个很好的例子便是SAM(Segment Anything)[7],SAM不仅让科研工作者们看到了通用视觉大模型未来方向,也引发了很多思考。值得注意的是,OVD技术可以很好地接入SAM,来增强SAM的语义理解能力,自动地生成SAM需要的box信息,从而进一步解放人力。同样的对于AIGC(人工智能生成内容),OVD技术同样可以增强与用户之间的交互能力,如当用户需要指定一张图片的某一个目标进行变化,或对该目标生成一句描述的时候,可以利用OVD的语言理解能力与OVD对未知目标检测的能力实现对用户描述对象的精准定位,进而实现更高质量的内容生成。当下OVD领域的相关研究蓬勃发展,OVD技术对未来通用AI大模型能够带来的改变值得期待。
相关文章:
51c~目标检测~合集2
我自己的原文哦~ https://blog.51cto.com/whaosoft/12377509 一、总结 这里概述了基于深度学习的目标检测器的最新发展。同时,还提供了目标检测任务的基准数据集和评估指标的简要概述,以及在识别任务中使用的一些高性能基础架构,其还涵盖了…...

计算机低能儿从0刷leetcode | 33.搜索旋转排列数组
题目:33. 搜索旋转排序数组 思路:看到时间复杂度要求是O(log N)很容易想到二分查找,普通的二分查找我们已经掌握,本题中的数组可以看作由两个分别升序的数组拼成,在完全升序的部分中进行二分查找是容易的,…...
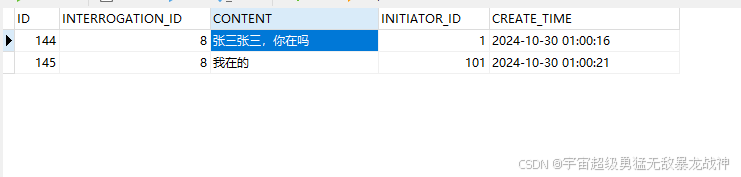
SpringBoot+VUE2完成WebSocket聊天(数据入库)
下载依赖 <!-- websocket --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-websocket</artifactId></dependency><!-- MybatisPlus --><dependency><groupId>com.ba…...
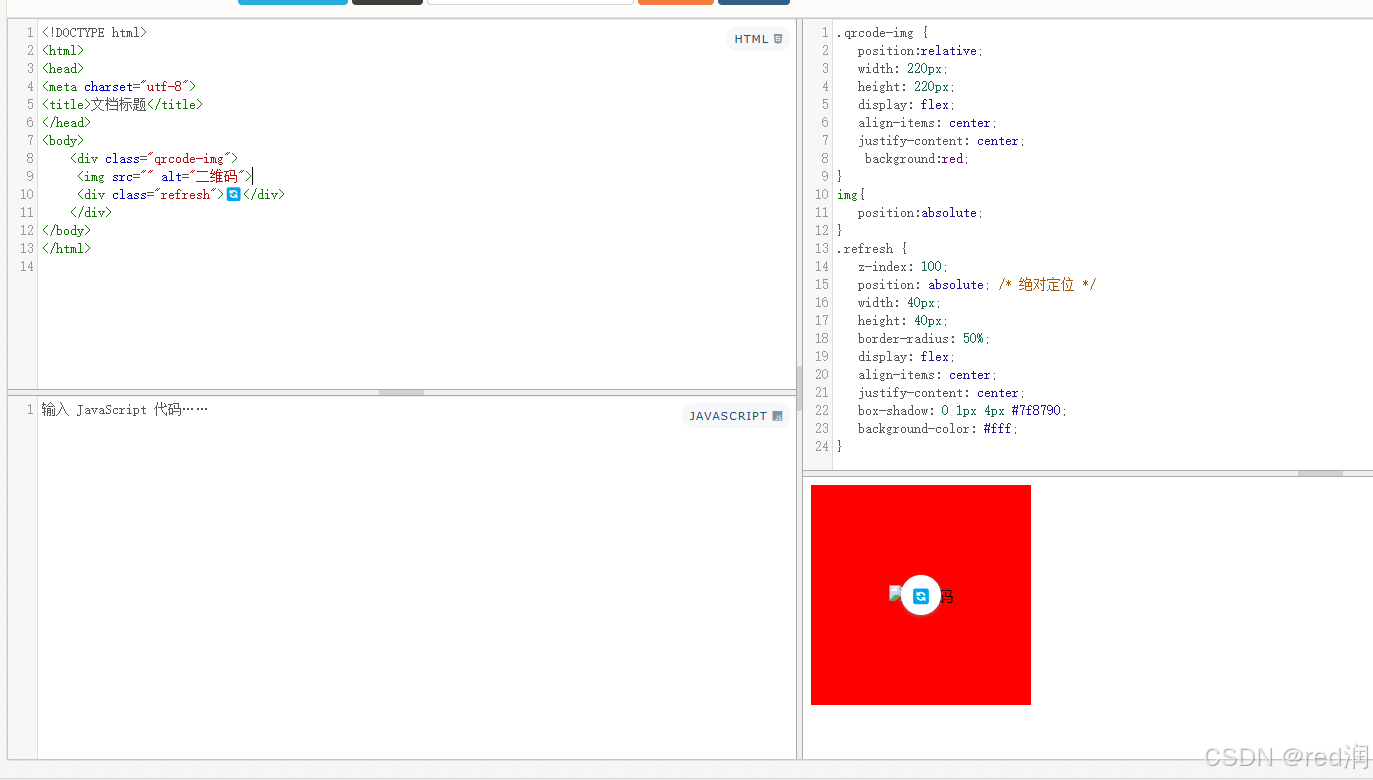
理解 CSS 中的绝对定位与 Flex 布局混用
理解 CSS 中的绝对定位与 Flex 布局混用 在现代网页设计中,CSS 布局技术如 flex 和绝对定位被广泛使用。然而,这两者结合使用时,可能会导致一些意想不到的布局问题。本文将探讨如何正确使用绝对定位元素,避免它们受到 flex 布局的…...

Redis 事务 问题
前言 相关系列 《Redis & 目录》《Redis & 事务 & 源码》《Redis & 事务 & 总结》《Redis & 事务 & 问题》 参考文献 《Redis事务详解》 Redis事务是什么? 标准的事务是指执行时具备原子性/一致性/隔离性/持久性的一系列操作。…...

Cpp学习手册-进阶学习
C标准库和C20新特性 C标准库概览: 核心库组件介绍: 容器: C 标准库提供了多种容器,它们各有特点,适用于不同的应用场景。 std::vector: vector:动态数组,支持快速随机访问。 #in…...

代码随想录-字符串-反转字符串中的单词
题目 题解 法一:纯粹为了做出本题,暴力解 没有技巧全是感情 class Solution {public String reverseWords(String s) {//首先去除首尾空格s s.trim();String[] strs s.split("\\s");StringBuilder sb new StringBuilder();//定义一个公共的字符反转…...
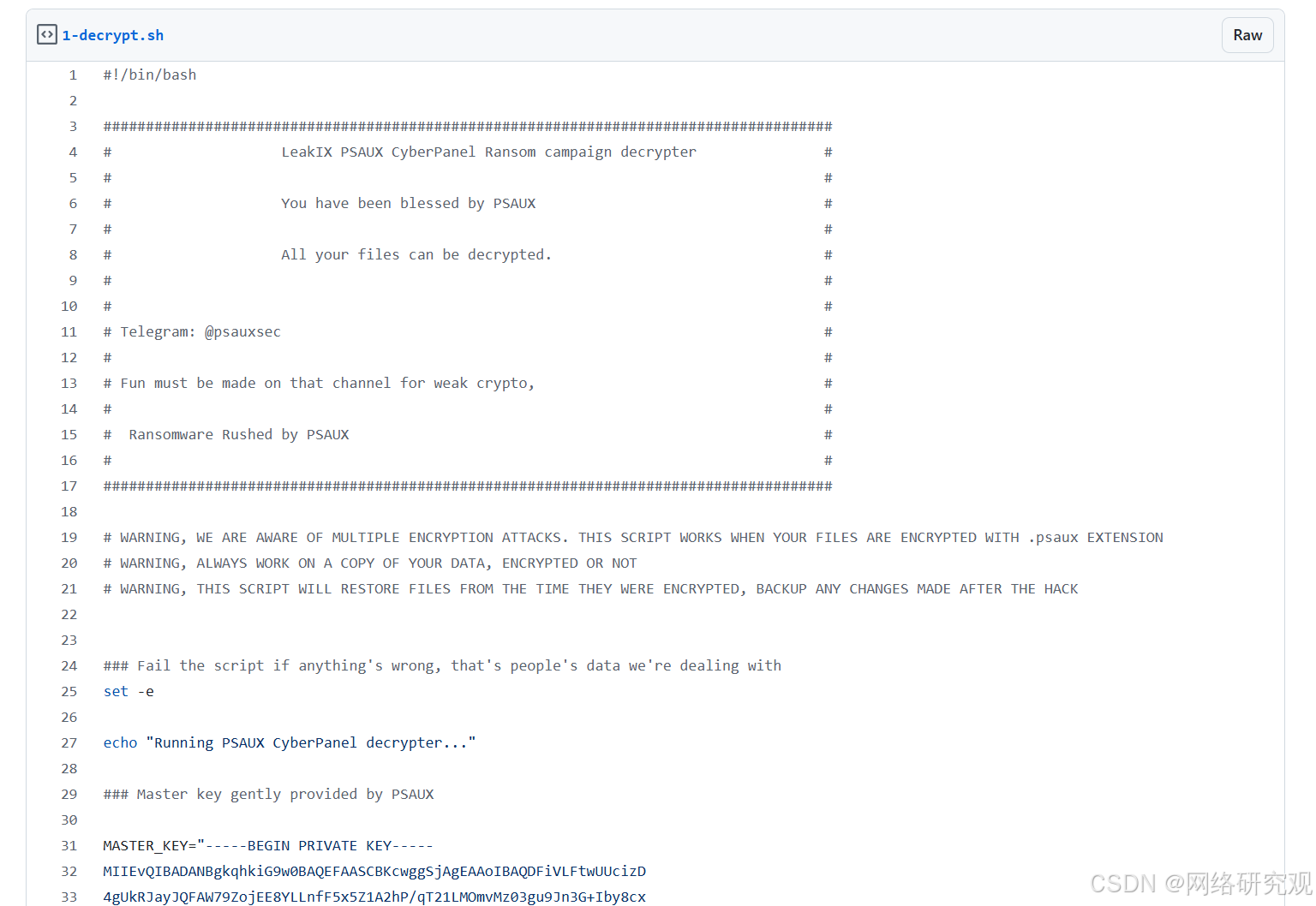
勒索软件通过易受攻击的 CyberPanel 实例攻击网络托管服务器
一个威胁行为者(或可能多个)使用 PSAUX 和其他勒索软件攻击了大约 22,000 个易受攻击的 CyberPanel 实例以及运行该实例的服务器上的加密文件。 PSAUX 赎金记录(来源:LeakIX) CyberPanel 漏洞 CyberPane…...

Open WebUI + openai API / vllm API ,实战部署教程
介绍Open WebUI + Ollama 的使用: https://www.dong-blog.fun/post/1796 介绍vllm 的使用:https://www.dong-blog.fun/post/1781 介绍 Ollama 的使用: https://www.dong-blog.fun/post/1797 本篇博客玩个花的,Open WebUI 本身可以兼容openai 的api, 那来尝试一下。 仅供…...

InsuranceclaimsController
目录 1、 InsuranceclaimsController 1.1、 保险理赔结算 1.2、 生成预约单号 1.3、 保存索赔表 InsuranceclaimsController using QXQPS.Models; using QXQPS.Vo; using System; using System.Collections; using System.Collections.Generic; using System.Li…...
如何成为开源代码库Dify的contributor:解决issue并提交PR
前言 Dify 是一个开源的大语言模型(LLM)应用开发平台,它融合了后端即服务(Backend as Service)和LLMOps的理念,旨在简化和加速生成式AI应用的创建和部署。Dify提供了一个用户友好的界面和一系列强大的工具…...
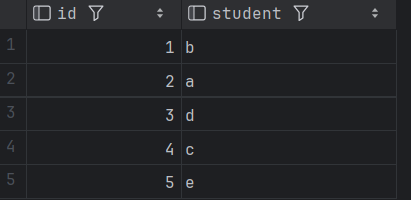
SQL进阶技巧:巧用异或运算解决经典换座位问题
目录 0 问题描述 1 数据准备 2 问题分析 2.1 什么是异或 2.2异或有什么特性? 2.3 异或应用 2.4 本问题采用异或SQL解决方案 3 小结 0 问题描述 表 seat中有2个字段id和student id 是该表的主键(唯一值)列,student表示学生姓名。 该表的每一行都表示学生的姓名和 ID。…...
进行监控)
【MySQL】 运维篇—数据库监控:使用MySQL内置工具(如SHOW命令、INFORMATION_SCHEMA)进行监控
随着应用程序的增长,数据库的性能和稳定性变得至关重要。监控数据库的状态和性能可以帮助数据库管理员(DBA)及时发现问题,进行故障排查,并优化数据库的运行效率。通过监控工具,DBA可以获取实时的性能指标、…...
【温酒笔记】DMA
参考文档:野火STM32F103 1. Direct Memory Access-直接内存访问 DMA控制器独立于内核 是一个单独的外设 DMA1有7个通道DMA2有5个通道DMA有四个等级,非常高,高,中,低四个优先级如果优先等级相同,通道编号越…...

力扣判断字符是否唯一(位运算)
文章目录 给一个数n,判断它的二进制位中第x位是0还是1(从0开始计数)将一个数n的二进制位第X位修改为1(从0开始计数)将一个数n的二进制第x位修改为0(从0开始计数)提取一个数n二进制中最右侧的1去掉一个数n二进制表示中最右侧的1 今天我们通过判断字符是否唯一这个题来了解位运算…...
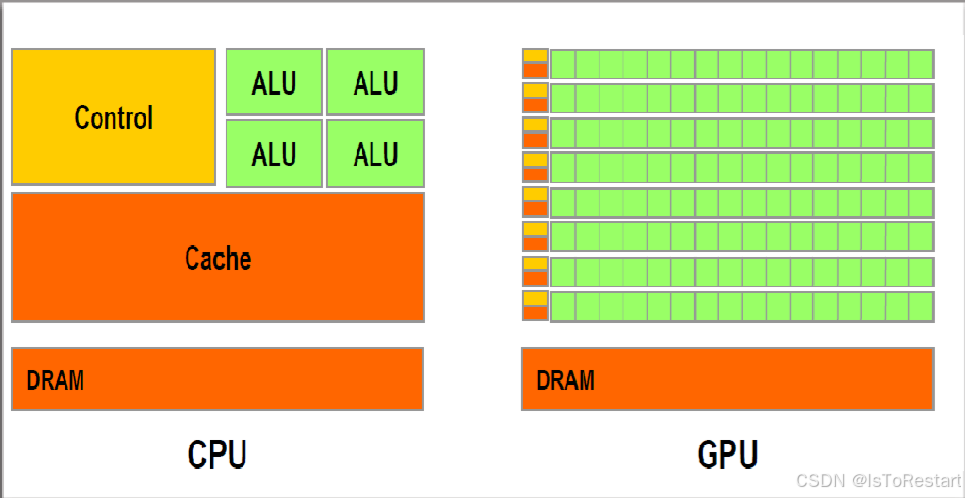
GPU和CPU区别?为什么挖矿、大模型都用GPU?
GPU(图形处理单元)和CPU(中央处理单元)是计算机中两种不同类型的处理器,它们在设计和功能上有很大的区别。 CPU是计算机的大脑,专门用于执行各种通用任务,如操作系统管理、数据处理、多任务处理等。它的架构设计旨在适应多种任务,…...
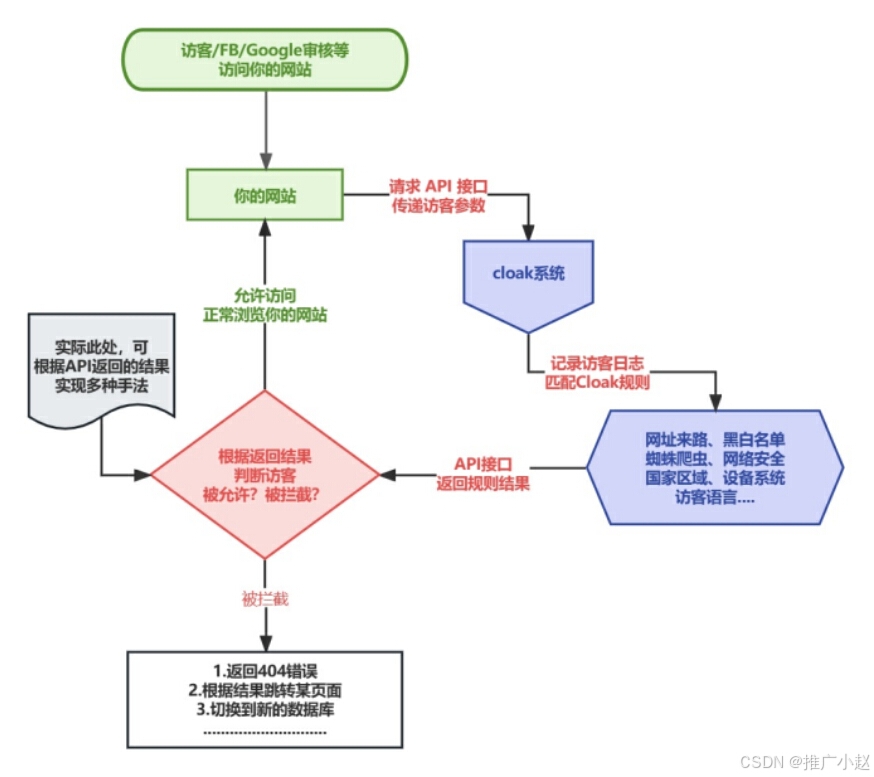
新兴斗篷cloak技术,你了解吗?
随着互联网技术的飞速发展,网络营销领域也经历了翻天覆地的变革。 从最早的网络横幅广告到如今主流的搜索引擎和社交媒体营销,广告形式变得越来越多样。 其中,搜索引擎广告一直以其精准投放而备受青睐,但近年来,一项名…...
:不变子群的几道例题)
【抽代复习笔记】34-群(二十八):不变子群的几道例题
例1:证明,交换群的任何子群都是不变子群。 证:设(G,o)是交换群,H≤G, 对任意的a∈G,显然都有aH {a o h|h∈H} {h o a|h∈H} Ha。 所以H⊿G。 【注:规范的不变子群符号是一个顶角指向左边…...
Chrome和Firefox如何保护用户的浏览数据
在当今数字化时代,保护用户的浏览数据变得尤为重要。浏览器作为我们日常上网的主要工具,其安全性直接关系到个人信息的保密性。本文将详细介绍Chrome和Firefox这两款主流浏览器如何通过一系列功能来保护用户的浏览数据。(本文由https://chrom…...

CentOS 7镜像下载
新版本系统镜像下载(当前最新是CentOS 7.4版本) CentOS官网 官网地址 http://isoredirect.centos.org/centos/7.4.1708/isos/x86_64/ http://mirror.centos.org/centos/7/isos/ 国内的华为云,超级快:https://mirrors.huaweiclou…...

KubeSphere 容器平台高可用:环境搭建与可视化操作指南
Linux_k8s篇 欢迎来到Linux的世界,看笔记好好学多敲多打,每个人都是大神! 题目:KubeSphere 容器平台高可用:环境搭建与可视化操作指南 版本号: 1.0,0 作者: 老王要学习 日期: 2025.06.05 适用环境: Ubuntu22 文档说…...

简易版抽奖活动的设计技术方案
1.前言 本技术方案旨在设计一套完整且可靠的抽奖活动逻辑,确保抽奖活动能够公平、公正、公开地进行,同时满足高并发访问、数据安全存储与高效处理等需求,为用户提供流畅的抽奖体验,助力业务顺利开展。本方案将涵盖抽奖活动的整体架构设计、核心流程逻辑、关键功能实现以及…...

《Playwright:微软的自动化测试工具详解》
Playwright 简介:声明内容来自网络,将内容拼接整理出来的文档 Playwright 是微软开发的自动化测试工具,支持 Chrome、Firefox、Safari 等主流浏览器,提供多语言 API(Python、JavaScript、Java、.NET)。它的特点包括&a…...

为什么需要建设工程项目管理?工程项目管理有哪些亮点功能?
在建筑行业,项目管理的重要性不言而喻。随着工程规模的扩大、技术复杂度的提升,传统的管理模式已经难以满足现代工程的需求。过去,许多企业依赖手工记录、口头沟通和分散的信息管理,导致效率低下、成本失控、风险频发。例如&#…...

Auto-Coder使用GPT-4o完成:在用TabPFN这个模型构建一个预测未来3天涨跌的分类任务
通过akshare库,获取股票数据,并生成TabPFN这个模型 可以识别、处理的格式,写一个完整的预处理示例,并构建一个预测未来 3 天股价涨跌的分类任务 用TabPFN这个模型构建一个预测未来 3 天股价涨跌的分类任务,进行预测并输…...

【Java_EE】Spring MVC
目录 Spring Web MVC 编辑注解 RestController RequestMapping RequestParam RequestParam RequestBody PathVariable RequestPart 参数传递 注意事项 编辑参数重命名 RequestParam 编辑编辑传递集合 RequestParam 传递JSON数据 编辑RequestBody …...

自然语言处理——Transformer
自然语言处理——Transformer 自注意力机制多头注意力机制Transformer 虽然循环神经网络可以对具有序列特性的数据非常有效,它能挖掘数据中的时序信息以及语义信息,但是它有一个很大的缺陷——很难并行化。 我们可以考虑用CNN来替代RNN,但是…...

10-Oracle 23 ai Vector Search 概述和参数
一、Oracle AI Vector Search 概述 企业和个人都在尝试各种AI,使用客户端或是内部自己搭建集成大模型的终端,加速与大型语言模型(LLM)的结合,同时使用检索增强生成(Retrieval Augmented Generation &#…...

【学习笔记】erase 删除顺序迭代器后迭代器失效的解决方案
目录 使用 erase 返回值继续迭代使用索引进行遍历 我们知道类似 vector 的顺序迭代器被删除后,迭代器会失效,因为顺序迭代器在内存中是连续存储的,元素删除后,后续元素会前移。 但一些场景中,我们又需要在执行删除操作…...

日常一水C
多态 言简意赅:就是一个对象面对同一事件时做出的不同反应 而之前的继承中说过,当子类和父类的函数名相同时,会隐藏父类的同名函数转而调用子类的同名函数,如果要调用父类的同名函数,那么就需要对父类进行引用&#…...