PyTorch图像分类实战——基于ResNet18的RAF-DB情感识别(附完整代码和结果图)
PyTorch图像分类实战——基于ResNet18的RAF-DB情感识别(附完整代码和结果图)
关于作者
作者:小白熊
作者简介:精通python、matlab、c#语言,擅长机器学习,深度学习,机器视觉,目标检测,图像分类,姿态识别,语义分割,路径规划,智能优化算法,数据分析,各类创新融合等等。
联系邮箱:xbx3144@163.com
科研辅导、知识付费答疑、个性化定制以及其他合作需求请联系作者~
前言
在本文中,我们将详细介绍如何使用PyTorch框架,结合ResNet18模型,进行图像分类任务。这里我们选择了一个情感识别数据集——RAF-DB(Real-world Affective Faces Database),来进行实验。通过本文,你将学习到如何准备数据、构建模型、训练模型、评估模型,并可视化训练过程中的损失曲线。
1 模型理论
1.1 深度学习基础
深度学习是机器学习的一个分支,它通过使用深层神经网络来模拟人脑的学习过程。在图像分类任务中,卷积神经网络(Convolutional Neural Network, CNN)是最常用的模型之一。CNN通过卷积层、池化层、全连接层等结构,能够自动提取图像中的特征,并进行分类。
1.2 ResNet模型
ResNet(Residual Network)是一种深度卷积神经网络,它通过引入残差块(Residual Block)来解决深度神经网络中的梯度消失和梯度爆炸问题。残差块通过引入一个恒等映射(Identity Mapping),使得网络在训练过程中能够更容易地学习到特征。ResNet有多个版本,如ResNet18、ResNet34、ResNet50等,其中数字表示网络的层数。ResNet18作为ResNet系列中的一个轻量级模型,具备较好的性能和较低的计算复杂度,非常适合用于图像分类任务
1.3 交叉熵损失函数
在分类任务中,交叉熵损失函数(Cross Entropy Loss)是最常用的损失函数之一。它衡量的是模型输出的概率分布与真实标签的概率分布之间的差异。交叉熵损失函数越小,表示模型的预测结果越接近真实标签。
1.4 优化器
优化器用于更新模型的权重,以最小化损失函数。常用的优化器有SGD(随机梯度下降)、Adam等。SGD是最基础的优化器,它通过计算梯度来更新权重,但容易陷入局部最小值。Adam优化器结合了动量(Momentum)和RMSprop的思想,能够在训练过程中自适应地调整学习率,通常能够取得更好的效果。
2 代码解析
2.1 数据准备
首先,我们需要准备数据集。这里使用的是RAF-DB数据集,它是一个情感识别数据集,包含了多种情感标签的图像。
image_path = './data/RAF-DB' # 数据集路径,需修改
labels_num = 7 # 标签类别数量,需修改
我们使用datasets.ImageFolder来加载数据集,它会自动根据文件夹名称来划分标签。然后,我们定义了数据转换(data_transform),包括随机裁剪、随机水平翻转、归一化等操作。
data_transform = { "train": transforms.Compose([transforms.RandomResizedCrop(224), transforms.RandomHorizontalFlip(), transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]), "val": transforms.Compose([transforms.Resize((224, 224)), transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])}
2.2 模型构建
我们选择了ResNet18作为基模型,并修改了最后一层全连接层的输出维度,以适应我们的分类任务。
net = models.resnet18()
fc_input_feature = net.fc.in_features
net.fc = nn.Linear(fc_input_feature, labels_num)
然后,我们加载了预训练的权重,并删除了最后一层的权重,因为我们需要重新训练这一层。
pretrained_weight = torch.hub.load_state_dict_from_url( url='https://download.pytorch.org/models/resnet18-5c106cde.pth', progress=True)
del pretrained_weight['fc.weight']
del pretrained_weight['fc.bias']
net.load_state_dict(pretrained_weight, strict=False)
2.3 训练过程
在训练过程中,我们使用了交叉熵损失函数和SGD优化器。同时,我们还设置了学习率调度器(scheduler),它会在每10个epoch后,将学习率乘以0.1。
criterion = nn.CrossEntropyLoss()
LR = 0.01
optimizer = optim.SGD(net.parameters(), lr=LR, momentum=0.9)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.1)
训练过程包括前向传播、计算损失、反向传播和更新权重。我们还使用了tqdm库来显示训练进度。
for epoch in range(epochs): # train net.train() running_loss = 0.0 train_bar = tqdm(train_loader, file=sys.stdout) acc1 = 0 for step, data in enumerate(train_bar): images, labels = data images = images.to(device) labels = labels.to(device) output = net(images) optimizer.zero_grad() loss = criterion(output, labels) loss.backward() optimizer.step() running_loss += loss.item() train_bar.desc = "train epoch[{}/{}] loss:{:.3f}".format(epoch + 1, epochs, loss) predicted = torch.max(output, dim=1)[1] acc1 += torch.eq(predicted, labels).sum().item() train_accurate = acc1 / train_num # validate net.eval() with torch.no_grad(): val_bar = tqdm(validate_loader, file=sys.stdout) val_loss = 0.0 acc = 0 for val_data in val_bar: val_images, val_labels = val_data val_images = val_images.to(device) val_labels = val_labels.to(device) output = net(val_images) loss = criterion(output, val_labels) val_loss += loss.item() predict_y = torch.max(output, dim=1)[1] acc += torch.eq(predict_y, val_labels).sum().item() val_accurate = acc / val_num print('[epoch %d] train_loss: %.3f val_accuracy: %.3f train_accuracy: %.3f' % (epoch + 1, running_loss / train_steps, val_accurate, train_accurate)) train_losses.append(running_loss / train_steps) if val_accurate > best_acc: best_acc = val_accurate save_path_epoch = os.path.join(save_path, f"resnet_{epoch + 1}_{val_accurate}.pth") torch.save(net.state_dict(), save_path_epoch)
2.4 损失曲线绘制
最后,我们绘制了训练过程中的损失曲线,以便观察模型的训练效果。
plt.figure(figsize=(10, 8))
plt.plot(range(1, epochs + 1), train_losses, label='train')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('resnet')
plt.legend()
plt.savefig('./runs/loss.jpg')
plt.show()

3 文件夹结构
为了使代码更加清晰和易于管理,建议使用以下文件夹结构:
project_root/
│
├── data/
│ └── RAF-DB/
│ ├── train/
│ │ ├── class1/
│ │ ├── class2/
│ │ ...
│ └── val/
│ ├── class1/
│ ├── class2/
│ ...
│
├── runs/ # 保存训练好的模型权重和损失曲线图
│ ├── loss.jpg
│ ├── resnet_1_xxx.pth
│ ...
│
├── train.py # 训练脚本
│
├── class_indices.json # 类别索引映射文件
│
├── requirements.txt # 项目依赖包
│
└── README.md # 项目说明文档
在这个结构中,data文件夹用于存放数据集,数据划分参考图像分类模型数据集划分教程:如何划分训练集和验证集
本文的class_indices.json类别索引映射文件如下:
{"0": "anger","1": "disgust","2": "fear","3": "happiness","4": "neutral","5": "sadness","6": "surprise"
}
4 完整代码
import os
import sys
import json
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import torch.nn as nn
from torchvision import transforms, datasets
import torch.optim as optim
from tqdm import tqdm
import torch
from torch.utils.data import DataLoader
import torchvision.models as modelsdef main():device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")print("using {} device.".format(device))data_transform = {"train": transforms.Compose([transforms.RandomResizedCrop(224),transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),"val": transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])}image_path = './RAF-DB/RAF-DB' # 数据集路径,需修改labels_num = 7 # 标签类别数量,需修改assert os.path.exists(image_path), "{} path does not exist.".format(image_path)train_dataset = datasets.ImageFolder(root=os.path.join(image_path, "train"),transform=data_transform["train"])train_num = len(train_dataset)flower_list = train_dataset.class_to_idxcla_dict = dict((val, key) for key, val in flower_list.items())# write dict into json filejson_str = json.dumps(cla_dict, indent=4)with open('./class_indices.json', 'w') as json_file: # json文件路径,需修改json_file.write(json_str)batch_size = 64 # 批处理大小,可修改nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) # number of workersprint('Using {} dataloader workers every process'.format(nw))train_loader = torch.utils.data.DataLoader(train_dataset,batch_size=batch_size, shuffle=True,num_workers=nw)validate_dataset = datasets.ImageFolder(root=os.path.join(image_path, "val"),transform=data_transform["val"])val_num = len(validate_dataset)validate_loader = torch.utils.data.DataLoader(validate_dataset,batch_size=batch_size, shuffle=False,num_workers=nw)print("using {} images for training, {} images for validation.".format(train_num,val_num))# 初始化模型net = models.resnet18()fc_input_feature = net.fc.in_featuresnet.fc = nn.Linear(fc_input_feature, labels_num)# load权重pretrained_weight = torch.hub.load_state_dict_from_url(url='https://download.pytorch.org/models/resnet18-5c106cde.pth', progress=True)del pretrained_weight['fc.weight']del pretrained_weight['fc.bias']net.load_state_dict(pretrained_weight, strict=False)net.to(device)criterion = nn.CrossEntropyLoss() # 交叉熵损失函数LR = 0.01optimizer = optim.SGD(net.parameters(), lr=LR, momentum=0.9)scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.1)epochs = 100 # 训练轮数,可修改best_acc = 0.0save_path = './runs'train_steps = len(train_loader)train_losses = [] # 存储每个epoch的训练损失for epoch in range(epochs):# trainnet.train()running_loss = 0.0train_bar = tqdm(train_loader, file=sys.stdout)acc1 = 0for step, data in enumerate(train_bar):images, labels = dataimages = images.to(device)labels = labels.to(device)output = net(images)optimizer.zero_grad()loss = criterion(output, labels)loss.backward()optimizer.step()running_loss += loss.item()train_bar.desc = "train epoch[{}/{}] loss:{:.3f}".format(epoch + 1,epochs,loss)predicted = torch.max(output, dim=1)[1]acc1 += torch.eq(predicted, labels).sum().item()train_accurate = acc1 / train_num# validatenet.eval()with torch.no_grad():val_bar = tqdm(validate_loader, file=sys.stdout)for val_data in val_bar:val_images, val_labels = val_dataval_images = val_images.to(device)val_labels = val_labels.to(device)output = net(val_images)loss = criterion(output, val_labels)val_loss += loss.item()predict_y = torch.max(output, dim=1)[1]acc += torch.eq(predict_y, val_labels).sum().item()val_accurate = acc / val_numprint('[epoch %d] train_loss: %.3f val_accuracy: %.3f train_accuracy: %.3f' %(epoch + 1, running_loss / train_steps, val_accurate, train_accurate))train_losses.append(running_loss / train_steps)if val_accurate > best_acc:best_acc = val_accuratesave_path_epoch = os.path.join(save_path, f"resnet_{epoch + 1}_{val_accurate}.pth")torch.save(net.state_dict(), save_path_epoch)# 绘制损失曲线plt.figure(figsize=(10, 8))plt.plot(range(1, epochs + 1), train_losses, label='train')plt.xlabel('Epoch')plt.ylabel('Loss')plt.title('resnet')plt.legend()plt.savefig('./runs/loss.jpg')plt.show()print('Finished Training')if __name__ == '__main__':main()
5 结语
在本文中,我们深入探讨了如何使用PyTorch框架和ResNet18模型,结合RAF-DB数据集来实现图像情感识别。通过系统的数据预处理、模型构建、训练与优化,以及评估等步骤,我们成功地训练出了一个能够识别图像中人物情感的模型。
RAF-DB数据集作为本文的核心数据资源,展现出了其独特的价值。它是一个大规模、高质量的面部表情数据库,包含了数千张精挑细选的高分辨率面部图像,每张图像都配备了精确的表情标签。这些图像覆盖了高兴、悲伤、愤怒、惊讶等多种基本及复合表情,为模型训练提供了丰富的数据支持。此外,RAF-DB数据集还具备真实性、完整性、易用性和研究驱动等特点,确保了研究的普适性和可靠性,为情感分析、人脸识别以及表情识别等领域的研究者提供了宝贵的资源。
在模型选择方面,我们采用了ResNet18模型。ResNet(Residual Network,残差网络)是一种由微软亚洲研究院提出的深度神经网络结构,其核心在于通过残差连接(residual connections)解决了深层网络训练中的梯度消失和梯度爆炸问题。在本文中,我们利用ResNet18模型对RAF-DB数据集进行了训练,并成功地构建了一个情感识别模型。
相关文章:
PyTorch图像分类实战——基于ResNet18的RAF-DB情感识别(附完整代码和结果图)
PyTorch图像分类实战——基于ResNet18的RAF-DB情感识别(附完整代码和结果图) 关于作者 作者:小白熊 作者简介:精通python、matlab、c#语言,擅长机器学习,深度学习,机器视觉,目标检测…...

【OccNeRF: Advancing 3D Occupancy Prediction in LiDAR-Free Environments】阅读笔记
【OccNeRF: Advancing 3D Occupancy Prediction in LiDAR-Free Environments】阅读笔记 1. 论文概述Abstract1. Introduction2. Related work2.1 3D Occupancy Prediction2.2 Neural Radiance Fields2.3 Self-supervised Depth Estimation 3. Method3.1 Parameterized Occupanc…...

DDRPHY数字IC后端设计实现系列专题之后端设计导入,IO Ring设计
本章详细分析和论述了 LPDDR3 物理层接口模块的布图和布局规划的设计和实 现过程,包括设计环境的建立,布图规划包括模块尺寸的确定,IO 单元、宏单元以及 特殊单元的摆放。由于布图规划中的电源规划环节较为重要, 影响芯片的布线资…...
EDA --软件开发之路
之前一直在一家做数据处理的公司,从事c开发,公司业务稳定,项目有忙有闲,时而看下c,数据库,linux相关书籍,后面跳槽到了家eda公司,开始了一段eda开发之路。 eda 是 electric design …...
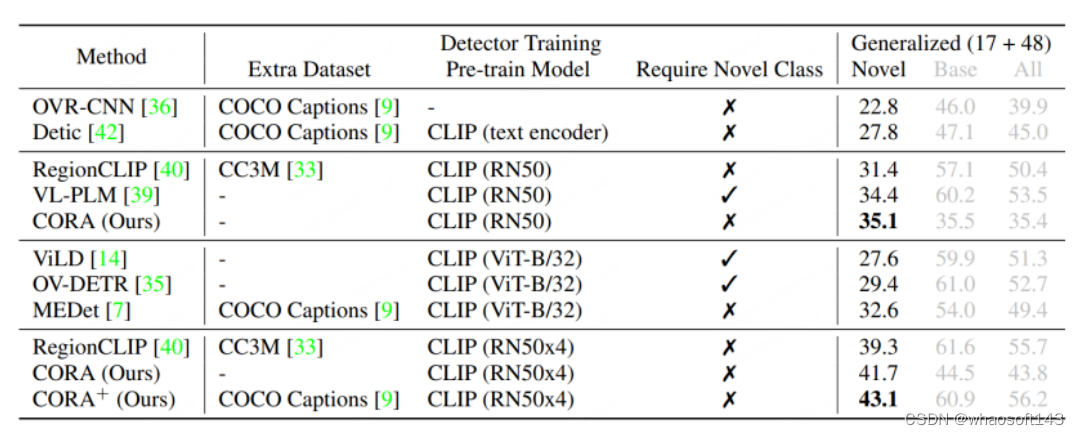
51c~目标检测~合集2
我自己的原文哦~ https://blog.51cto.com/whaosoft/12377509 一、总结 这里概述了基于深度学习的目标检测器的最新发展。同时,还提供了目标检测任务的基准数据集和评估指标的简要概述,以及在识别任务中使用的一些高性能基础架构,其还涵盖了…...

计算机低能儿从0刷leetcode | 33.搜索旋转排列数组
题目:33. 搜索旋转排序数组 思路:看到时间复杂度要求是O(log N)很容易想到二分查找,普通的二分查找我们已经掌握,本题中的数组可以看作由两个分别升序的数组拼成,在完全升序的部分中进行二分查找是容易的,…...
SpringBoot+VUE2完成WebSocket聊天(数据入库)
下载依赖 <!-- websocket --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-websocket</artifactId></dependency><!-- MybatisPlus --><dependency><groupId>com.ba…...
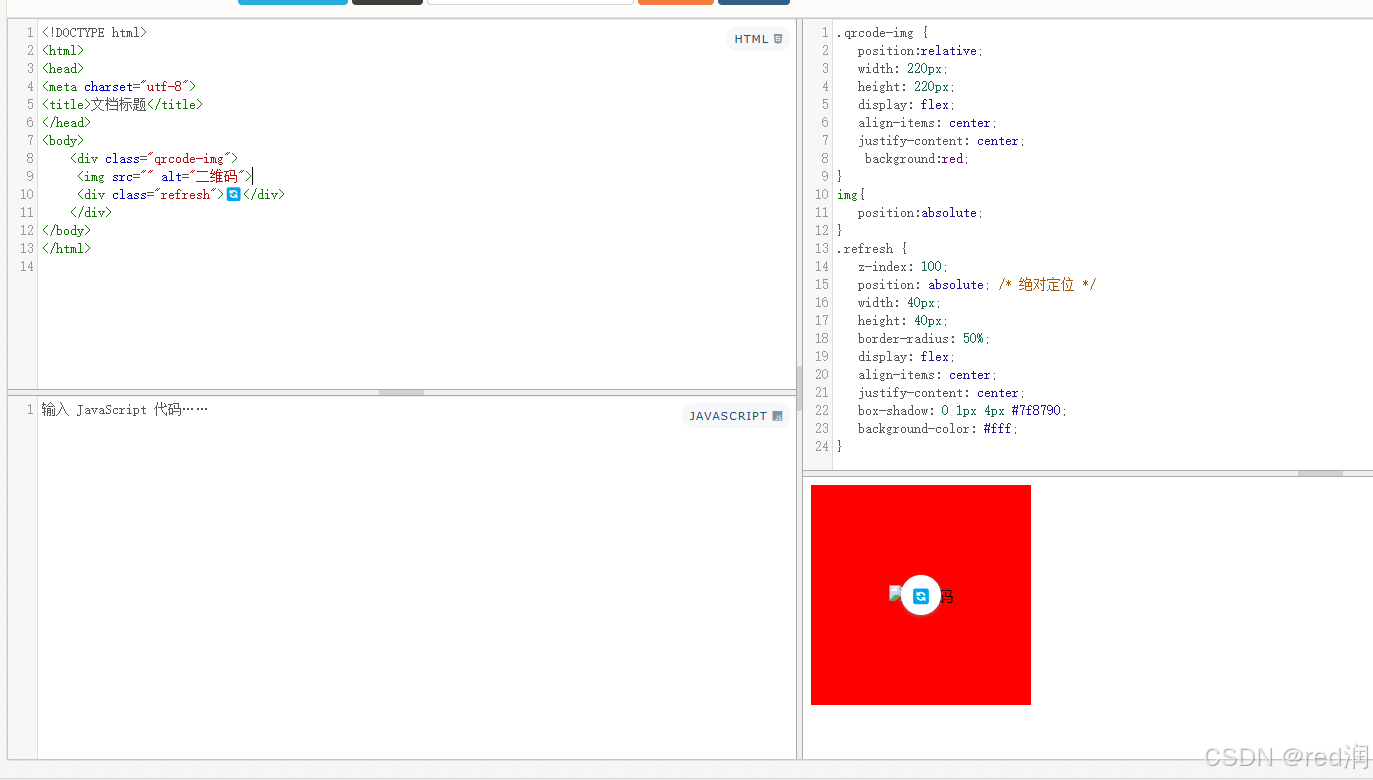
理解 CSS 中的绝对定位与 Flex 布局混用
理解 CSS 中的绝对定位与 Flex 布局混用 在现代网页设计中,CSS 布局技术如 flex 和绝对定位被广泛使用。然而,这两者结合使用时,可能会导致一些意想不到的布局问题。本文将探讨如何正确使用绝对定位元素,避免它们受到 flex 布局的…...

Redis 事务 问题
前言 相关系列 《Redis & 目录》《Redis & 事务 & 源码》《Redis & 事务 & 总结》《Redis & 事务 & 问题》 参考文献 《Redis事务详解》 Redis事务是什么? 标准的事务是指执行时具备原子性/一致性/隔离性/持久性的一系列操作。…...

Cpp学习手册-进阶学习
C标准库和C20新特性 C标准库概览: 核心库组件介绍: 容器: C 标准库提供了多种容器,它们各有特点,适用于不同的应用场景。 std::vector: vector:动态数组,支持快速随机访问。 #in…...

代码随想录-字符串-反转字符串中的单词
题目 题解 法一:纯粹为了做出本题,暴力解 没有技巧全是感情 class Solution {public String reverseWords(String s) {//首先去除首尾空格s s.trim();String[] strs s.split("\\s");StringBuilder sb new StringBuilder();//定义一个公共的字符反转…...
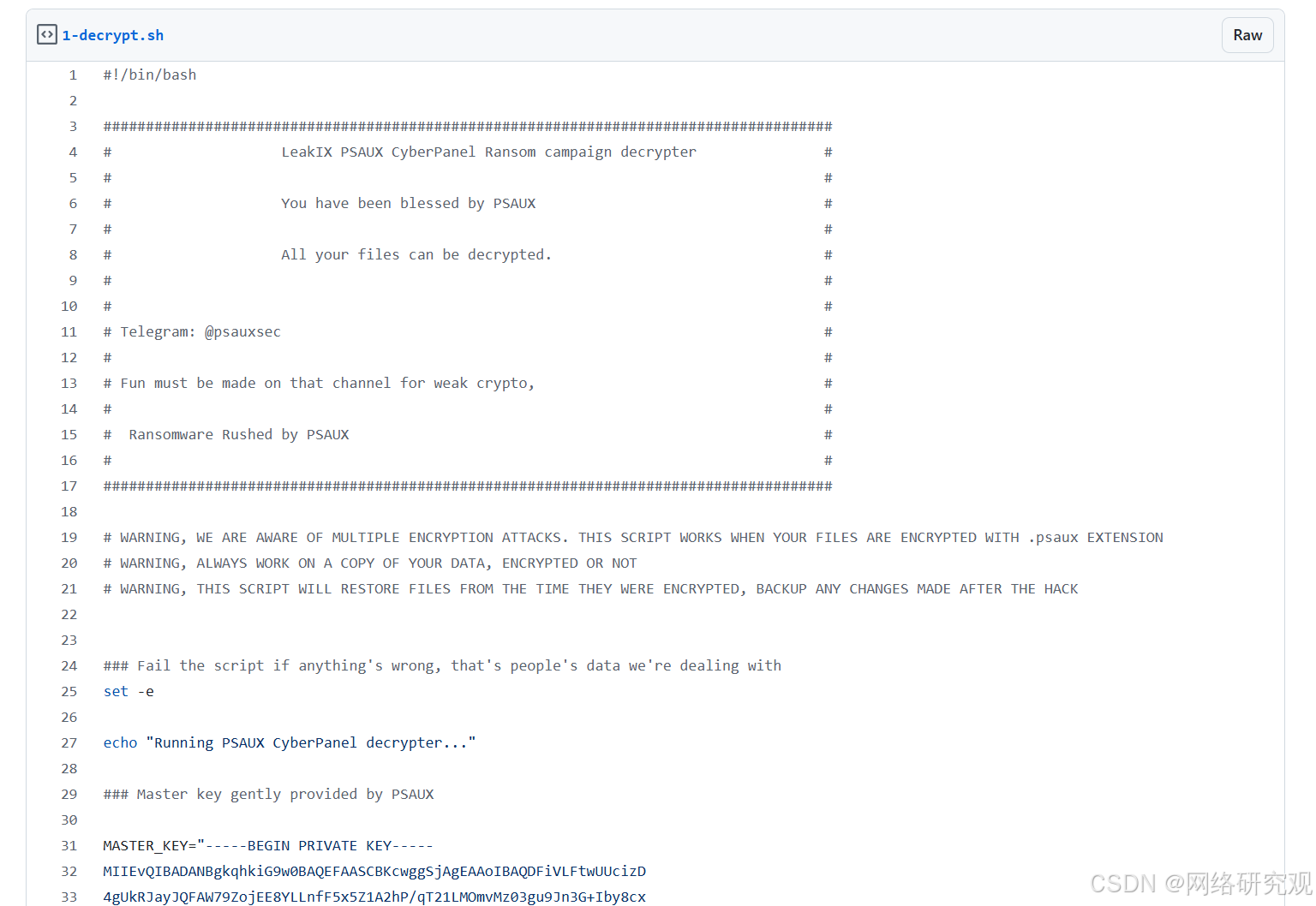
勒索软件通过易受攻击的 CyberPanel 实例攻击网络托管服务器
一个威胁行为者(或可能多个)使用 PSAUX 和其他勒索软件攻击了大约 22,000 个易受攻击的 CyberPanel 实例以及运行该实例的服务器上的加密文件。 PSAUX 赎金记录(来源:LeakIX) CyberPanel 漏洞 CyberPane…...

Open WebUI + openai API / vllm API ,实战部署教程
介绍Open WebUI + Ollama 的使用: https://www.dong-blog.fun/post/1796 介绍vllm 的使用:https://www.dong-blog.fun/post/1781 介绍 Ollama 的使用: https://www.dong-blog.fun/post/1797 本篇博客玩个花的,Open WebUI 本身可以兼容openai 的api, 那来尝试一下。 仅供…...

InsuranceclaimsController
目录 1、 InsuranceclaimsController 1.1、 保险理赔结算 1.2、 生成预约单号 1.3、 保存索赔表 InsuranceclaimsController using QXQPS.Models; using QXQPS.Vo; using System; using System.Collections; using System.Collections.Generic; using System.Li…...
如何成为开源代码库Dify的contributor:解决issue并提交PR
前言 Dify 是一个开源的大语言模型(LLM)应用开发平台,它融合了后端即服务(Backend as Service)和LLMOps的理念,旨在简化和加速生成式AI应用的创建和部署。Dify提供了一个用户友好的界面和一系列强大的工具…...
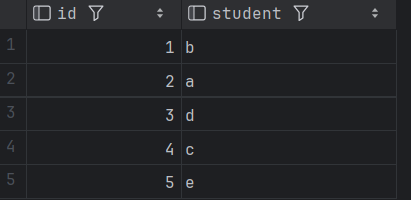
SQL进阶技巧:巧用异或运算解决经典换座位问题
目录 0 问题描述 1 数据准备 2 问题分析 2.1 什么是异或 2.2异或有什么特性? 2.3 异或应用 2.4 本问题采用异或SQL解决方案 3 小结 0 问题描述 表 seat中有2个字段id和student id 是该表的主键(唯一值)列,student表示学生姓名。 该表的每一行都表示学生的姓名和 ID。…...
进行监控)
【MySQL】 运维篇—数据库监控:使用MySQL内置工具(如SHOW命令、INFORMATION_SCHEMA)进行监控
随着应用程序的增长,数据库的性能和稳定性变得至关重要。监控数据库的状态和性能可以帮助数据库管理员(DBA)及时发现问题,进行故障排查,并优化数据库的运行效率。通过监控工具,DBA可以获取实时的性能指标、…...
【温酒笔记】DMA
参考文档:野火STM32F103 1. Direct Memory Access-直接内存访问 DMA控制器独立于内核 是一个单独的外设 DMA1有7个通道DMA2有5个通道DMA有四个等级,非常高,高,中,低四个优先级如果优先等级相同,通道编号越…...

力扣判断字符是否唯一(位运算)
文章目录 给一个数n,判断它的二进制位中第x位是0还是1(从0开始计数)将一个数n的二进制位第X位修改为1(从0开始计数)将一个数n的二进制第x位修改为0(从0开始计数)提取一个数n二进制中最右侧的1去掉一个数n二进制表示中最右侧的1 今天我们通过判断字符是否唯一这个题来了解位运算…...
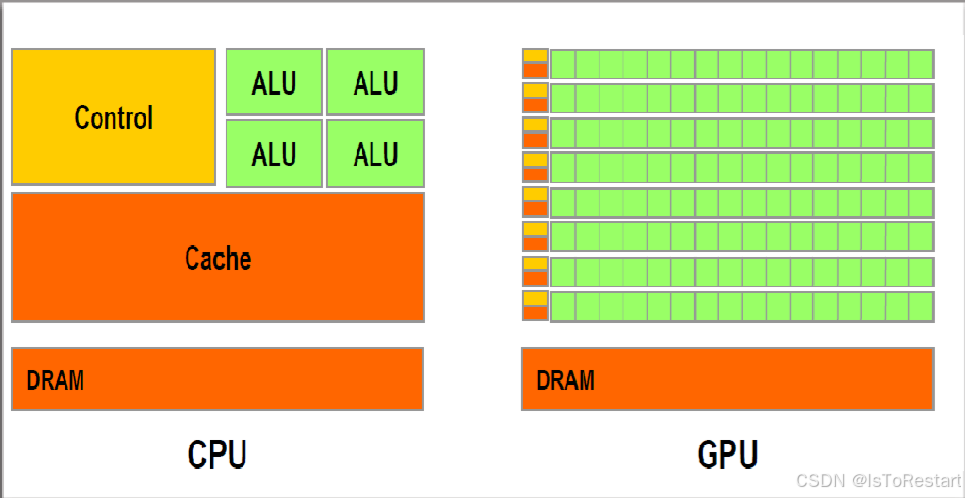
GPU和CPU区别?为什么挖矿、大模型都用GPU?
GPU(图形处理单元)和CPU(中央处理单元)是计算机中两种不同类型的处理器,它们在设计和功能上有很大的区别。 CPU是计算机的大脑,专门用于执行各种通用任务,如操作系统管理、数据处理、多任务处理等。它的架构设计旨在适应多种任务,…...

多云管理“拦路虎”:深入解析网络互联、身份同步与成本可视化的技术复杂度
一、引言:多云环境的技术复杂性本质 企业采用多云策略已从技术选型升维至生存刚需。当业务系统分散部署在多个云平台时,基础设施的技术债呈现指数级积累。网络连接、身份认证、成本管理这三大核心挑战相互嵌套:跨云网络构建数据…...

[2025CVPR]DeepVideo-R1:基于难度感知回归GRPO的视频强化微调框架详解
突破视频大语言模型推理瓶颈,在多个视频基准上实现SOTA性能 一、核心问题与创新亮点 1.1 GRPO在视频任务中的两大挑战 安全措施依赖问题 GRPO使用min和clip函数限制策略更新幅度,导致: 梯度抑制:当新旧策略差异过大时梯度消失收敛困难:策略无法充分优化# 传统GRPO的梯…...

服务器硬防的应用场景都有哪些?
服务器硬防是指一种通过硬件设备层面的安全措施来防御服务器系统受到网络攻击的方式,避免服务器受到各种恶意攻击和网络威胁,那么,服务器硬防通常都会应用在哪些场景当中呢? 硬防服务器中一般会配备入侵检测系统和预防系统&#x…...

spring:实例工厂方法获取bean
spring处理使用静态工厂方法获取bean实例,也可以通过实例工厂方法获取bean实例。 实例工厂方法步骤如下: 定义实例工厂类(Java代码),定义实例工厂(xml),定义调用实例工厂ÿ…...
:邮件营销与用户参与度的关键指标优化指南)
精益数据分析(97/126):邮件营销与用户参与度的关键指标优化指南
精益数据分析(97/126):邮件营销与用户参与度的关键指标优化指南 在数字化营销时代,邮件列表效度、用户参与度和网站性能等指标往往决定着创业公司的增长成败。今天,我们将深入解析邮件打开率、网站可用性、页面参与时…...

Linux nano命令的基本使用
参考资料 GNU nanoを使いこなすnano基础 目录 一. 简介二. 文件打开2.1 普通方式打开文件2.2 只读方式打开文件 三. 文件查看3.1 打开文件时,显示行号3.2 翻页查看 四. 文件编辑4.1 Ctrl K 复制 和 Ctrl U 粘贴4.2 Alt/Esc U 撤回 五. 文件保存与退出5.1 Ctrl …...

C语言中提供的第三方库之哈希表实现
一. 简介 前面一篇文章简单学习了C语言中第三方库(uthash库)提供对哈希表的操作,文章如下: C语言中提供的第三方库uthash常用接口-CSDN博客 本文简单学习一下第三方库 uthash库对哈希表的操作。 二. uthash库哈希表操作示例 u…...

【p2p、分布式,区块链笔记 MESH】Bluetooth蓝牙通信 BLE Mesh协议的拓扑结构 定向转发机制
目录 节点的功能承载层(GATT/Adv)局限性: 拓扑关系定向转发机制定向转发意义 CG 节点的功能 节点的功能由节点支持的特性和功能决定。所有节点都能够发送和接收网格消息。节点还可以选择支持一个或多个附加功能,如 Configuration …...

系统掌握PyTorch:图解张量、Autograd、DataLoader、nn.Module与实战模型
本文较长,建议点赞收藏,以免遗失。更多AI大模型应用开发学习视频及资料,尽在聚客AI学院。 本文通过代码驱动的方式,系统讲解PyTorch核心概念和实战技巧,涵盖张量操作、自动微分、数据加载、模型构建和训练全流程&#…...

Unity中的transform.up
2025年6月8日,周日下午 在Unity中,transform.up是Transform组件的一个属性,表示游戏对象在世界空间中的“上”方向(Y轴正方向),且会随对象旋转动态变化。以下是关键点解析: 基本定义 transfor…...