【OccNeRF: Advancing 3D Occupancy Prediction in LiDAR-Free Environments】阅读笔记
【OccNeRF: Advancing 3D Occupancy Prediction in LiDAR-Free Environments】阅读笔记
- 1. 论文概述
- Abstract
- 1. Introduction
- 2. Related work
- 2.1 3D Occupancy Prediction
- 2.2 Neural Radiance Fields
- 2.3 Self-supervised Depth Estimation
- 3. Method
- 3.1 Parameterized Occupancy Fields
- 3.2 Multi-frame Depth Estimation
- 3.3 Semantic Supervision
1. 论文概述
Abstract
- 现有的基于Occupancy的重建环境方法严重依赖于LiDAR点云,在纯视觉的系统中不可用。
- 本文提出的OccNeRF用于在没有3d监督情况下训练占用网络
- 与之前考虑有界场景的工作不同,OccNeRF参数化重建的占用场并重新组织采样策略以与相机的无限感知范围保持一致。
- 采用神经渲染将占用场转换为多相机深度图,并通过多帧光度一致性进行监督。
- 对于语义占用预测,OccNeRF设计了几种策略来完善提示并过滤预训练的开放词汇 2D 分割模型的输出。
- 在nuScenes 和 SemanticKITTI 数据集上进行实验
1. Introduction
****
近年来自动驾驶发展迅猛。尽管激光雷达提供了一种捕获几何数据的直接方法,但其采用受到传感器费用和扫描点稀疏性的阻碍。因此以视觉为中心的方法得到了广泛关注。在3D场景理解任务中,多相机的3d目标检测在自动化系统中发挥着重要作用,但是遇到了目标来自于无限类别与长尾问题
OCC预测是3d目标检测的补充,它直接重建周围场景的几何结构,自然就缓解了上述的问题。一些方法认为它具有重建被遮挡部分的潜力。现有的方法大多需要监督或者激光雷达,因此本文研究不使用激光雷达以及无监督的方法。
OccNeRF目标是在没有 3D 监督的情况下训练多摄像机占用网络。其pipeline如下图所示。首先利用 2D backbone来提取多摄像机 2D 特征。为了节省内存,我们直接插值 2D 特征来获得 3D 体积特征,而不是使用heavy的cross-view attention。在以前的工作中,体积特征由有界占用标签来监督(例如50m 范围),他们只需要以有限的分辨率(例如 200 × 200 × 16)来预测占用情况。不同的是,对于无 LiDAR 的训练,我们应该考虑无界场景,因为 RGB 图像感知无限范围。(为什么RGB图像感知无限的范围??)为此,我们参数化占用字段来表示无界环境。具体来说,我们将整个 3D 空间分为内部区域和外部区域。里面的坐标保持原来的坐标,外面的坐标采用收缩后的坐标。设计了一种特定的采样策略,通过神经渲染算法将参数化的占用场传输到 2D 深度图。

监督预测占用率的一种直接方法是计算渲染图像和训练图像之间的损失,这与 NeRF [17] 中使用的损失函数相同。然而,我们的实验表明,由于周围视图的稀疏性,这种方法是无效的,最小的图像重叠无法提供足够的几何信息。作为替代方案,我们通过渲染序列中的多个帧并采用相邻帧之间的光度一致性作为主要监督信号来充分利用时间信息。对于语义占用,我们提出了三种策略将类名映射到prompt,这些prompt被馈送到预训练的开放词汇分割模型 [18]、[19] 以获取 2D 语义标签。然后采用额外的语义头来渲染语义图像并由这些标签进行监督。为了验证我们方法的有效性,我们对自监督多摄像头深度估计和 3D 占用预测任务进行了实验。实验结果表明,我们的 OccNeRF 大幅优于其他深度估计方法,并且在 nuScenes [20] 和 SemanticKITTI [21] 数据集上使用更强监督的一些方法实现了可比的性能。
总之,我们的主要贡献包括:
- 我们开发了一个无需激光雷达数据即可训练占用网络的系统,通过集成时间信息以获取更多几何信息,解决稀疏周围视图的挑战。
- 我们引入了参数化的占用场,使以视觉为中心的系统能够有效地表示无界场景,与相机的广泛感知能力相结合。
- 我们设计了一个pipeline,通过预训练的开放词汇分割模型生成高质量的伪标签,并采用三种提示策略来提高准确性。
2. Related work
本节研究计算机视觉中的三个相互关联的领域:3D 占用预测、神经辐射场和自监督深度估计。我们强调了关键的进展和持续的挑战,提供了重要的概述,以确定当前研究中的差距并提出进一步研究的途径。
2.1 3D Occupancy Prediction
由于以视觉为中心的自动驾驶系统的重要性,越来越多的研究人员开始关注3D占用预测任务[16]、[22]、[3]、[13]、[23]、[14]、[15]、[24]、[25]、[26]、[27]、[28 ],[29]。在行业界,3D占用被视为LiDAR感知的替代方案。作为开创性工作之一,MonoScene [16]提取视线投影生成的体素特征来从单个图像重建场景。 TPVFormer [22] 进一步将其扩展到具有三视角视图表示的多摄像头时尚。除了 TPVFormer 之外,SurroundOcc [3] 还设计了一个管道来生成密集的占用标签,而不是使用稀疏的 LiDAR 点作为地面实况。此外,还提出了具有跨视图注意层的 2D-3D UNet 来预测密集占用。 RenderOcc [30] 使用 2D 深度图和语义标签来训练模型,减少对昂贵的 3D 占用注释的依赖。与这些方法相比,我们的方法不需要任何带注释的 3D 或 2D 标签。 Occ3D [13] 建立了 CVPR 2023 占用预测挑战赛中使用的占用基准,并提出了从粗到细的占用网络。 SimpleOccupancy [31] 提出了一个简单而有效的占用率估计框架。尽管 SimpleOccupancy [31] 和 SelfOcc [?] 研究了以视觉为中心的设置,但他们没有考虑相机的无限感知范围。
2.2 Neural Radiance Fields
作为3D领域最热门的主题之一,神经辐射场(NeRF)[17]近年来取得了巨大的成就。 NeRF [17] 通过使用多视图图像优化连续体积场景函数来学习场景的几何形状。为了获得新颖的视图,执行体积渲染以将辐射场转换为 RGB 图像。作为后续,mip-NeRF [32] 以连续值表示场景,并将光线替换为抗锯齿截头圆锥体。除了 mip-NeRF 之外,Zip-NeRF [33] 将 mipNeRF 与基于网格的模型集成,以实现更快的训练和更好的质量。原始NeRF有多种扩展,包括动态场景[34]、[35]、[36]、[37]、[38]、[39]、[40]、3D重建[41]、[42]、[ 43]、[44]、[45],模型加速[46]、[47]、[48]、[49]、[50]、[51]、[52]、[53]等。作为其中之一这些扩展中,一些作品旨在描述无界场景[54],[55]。 NeRF++ [54] 将 3D 空间分割为内部单位球体和外部体积,并提出倒置球体参数化来表示外部区域。此外,mip-NeRF 360 [55]将此想法嵌入到 mip-NeRF 中,并将平滑参数化应用于体积。受这些方法的启发,我们还设计了一种参数化方案来为占用预测任务建模无界场景。
2.3 Self-supervised Depth Estimation
虽然早期的作品[56]、[57]、[58]、[59]、[60]需要密集的深度注释,但最近的深度估计方法[61]、[62]、[63]、[64]、[65] ,[66],[67],[68],[69],[70],[71],[72],[73]以自我监督的方式设计。这些方法大多数同时预测深度图和自我运动,采用连续帧之间的光度约束[74]、[75]作为监督信号。作为该领域的经典工作,Monodepth2 [76]提出了一些技术来改进深度预测的质量,包括最小重投影损失、全分辨率多尺度采样和自动掩蔽损失。由于现代自动驾驶车辆通常配备多个摄像头来捕捉周围的景色,研究人员开始专注于多摄像头自监督深度估计任务[77],[78],[79],[80],[ 81],[82]。 FSM [77] 是第一个通过利用时空上下文并提出一致性约束将单目深度估计扩展到完整周围视图的工作。为了预测真实世界的尺度,SurroundDepth [78] 使用 Structurefrom-motion 生成尺度感知伪深度来预训练模型。此外,它提出了交叉视图变换器和联合姿态估计来合并多摄像机信息。最近,R3D3 [79] 将特征相关性与捆绑调整算子相结合,以实现稳健的深度和姿态估计。与这些方法不同,我们的方法直接提取 3D 空间中的特征,实现多摄像机一致性和更好的重建质量。
3. Method
下图是OccNeRF的流程。以多摄像头图像 {Ii}N i=1 作为输入,我们首先利用 2D 主干来提取 N 个摄像头的特征 {Xi}Ni=1。然后将2D特征插值到3D空间以获得已知内在{Ki}N i=1和外在{T i}N i=1的体积特征。正如第 III-A 节中所讨论的,为了表示无界场景,我们提出了一种坐标参数化,将无限范围收缩到有限的占用区域。执行体积渲染以将占用场转换为多帧深度图,并通过光度损失进行监督。第 III-B 节详细介绍了这一部分。最后,第 III-C 节展示了我们如何使用预训练的开放词汇分割模型来获取 2D 语义标签。

3.1 Parameterized Occupancy Fields
与之前的工作[3]、[14]不同,我们需要考虑无激光雷达设置中的无界场景。一方面,我们应该保留内部区域的高分辨率(例如[-40m,-40m,-1m,40m,40m,5.4m]),因为这部分覆盖了大多数感兴趣的区域。另一方面,外部区域是必要的,但信息较少,应该在收缩的空间内表示以减少内存消耗。受[55]的启发,我们提出了一个具有可调整感兴趣区域和收缩阈值的变换函数来参数化每个体素网格的坐标r = (x, y, z):

其中 α ∈ [0, 1] 表示感兴趣区域在参数化空间中的比例。 α 越高表示我们使用更多的空间来描述内部区域。 r′ = r/rb 表示基于输入 r 和预定义内部区域边界 rb 的归一化坐标。引入参数a和b是为了保持一阶导数的连续性(这样做为什么保持了一阶倒数的连续性?)。
这些参数的确定是通过求解以下方程来实现的:

导出的解决方案表示为:

为了从 2D 视图获取 3D 体素特征,我们首先为参数化坐标系中的每个体素生成对应点 Ppc = [xpc, ypc, zpc]T 并将它们映射回 ego 坐标系:

然后我们将这些点投影到2D图像特征平面并使用双线性插值来获得2D特征:

其中 proj 是将 3D 点 P 投影到由相机外在 Ti 和内在 Ki 定义的 2D 图像平面的函数,⟨⟩ 是双线性插值算子,Fi 是插值结果。为了简化聚合过程并降低计算成本,我们直接对多相机2D特征进行平均以获得体积特征,这与[31]、[83]中使用的方法相同。最后,采用 3D 卷积网络 [84] 来提取特征并预测最终的占用输出。
3.2 Multi-frame Depth Estimation
为了将占用场投影到多摄像机深度图,我们采用体积渲染[85],它广泛用于基于 NeRF 的方法[17]、[54]、[32]。为了渲染给定像素的深度值,我们从相机中心 o 沿着指向该像素的方向 d 投射一条光线。射线用 v(t) = o + td 表示,t ∈ [tn, tf ]。然后,我们沿 3D 空间中的射线采样 L 个点 {tk}L k=1 以获得密度 σ(tk)。对于选定的 L 个正交点,相应像素的深度计算如下:

其中 T (tk) = exp − Pk−1 k′=1 σ(tk)δk 和 δk = tk+1 − tk 是采样点之间的间隔。
这里的一个重要问题是如何在我们提出的坐标系中采样 {tk}L k=1。深度空间或视差空间中的均匀采样将导致参数化网格的外部或内部区域中的点系列不平衡,这不利于优化过程。假设o围绕坐标系原点,我们直接从参数化坐标中的U [0, 1]中采样L®个点,并使用方程1的反函数来计算{tk}L(v) k=自我坐标中的1。射线的特定 L(v) 和 rb(v) 计算如下:

其中 i、j、k 是 x、y、z 方向的单位向量,lx、ly、lz 是内部区域的长度,dv 是体素大小。为了更好地适应占用表示,我们直接预测渲染权重而不是密度。
传统的监督方法是计算渲染图像和原始图像之间的差异,NeRF [17]采用了这种方法。然而,我们的实验结果表明它效果不佳。可能的原因是场景规模大、视图监督少,导致NeRF收敛困难。为了更好地利用时间信息,我们采用了[76]、[74]中提出的光度损失。具体来说,我们根据渲染的深度和给定的相对姿势将相邻帧投影到当前帧。然后我们计算投影图像和原始图像之间的重建误差:

其中 ˆ Ii 是投影图像,β = 0.85。此外,我们采用[76]中介绍的技术,即每像素最小重投影损失和自动掩蔽固定像素。对于每个相机视图,我们渲染一个短序列而不是单个帧,并执行多帧光度损失。
3.3 Semantic Supervision
为了增强占用体素信息的丰富性并便于与现有方法进行比较,我们引入了 2D 标签来提供语义监督。之前的工作 [13]、[86] 将带有分割标签的 3D LiDAR 点投影到图像空间,以避免注释密集 3D 占用的昂贵成本。然而,我们的目标是在完全以视觉为中心的系统中预测语义占用率,并且仅使用 2D 数据。为此,我们利用预先训练的开放词汇模型 Grounded-SAM [18]、[19]、[87] 来生成 2D 语义分割标签。在没有任何 2D 或 3D 地面实况数据的情况下,预训练的开放词汇模型使我们能够获得与给定类别名称的语义紧密匹配的 2D 标签。该方法可以轻松扩展到任何数据集,使我们的方法高效且可推广。
具体来说,在处理 c 类别时,我们采用三种策略来确定向接地恐龙提供的提示。这些策略包括同义替换,即我们用同义词替换单词(例如,将“汽车”更改为“轿车”,以使模型能够将其与“卡车”和“公共汽车”区分开来);将单个词拆分为多个实体(例如,“人造”分为“建筑”、“广告牌”和“桥梁”等,以增强差异化);并纳入附加信息(例如,引入“骑自行车者”以方便检测骑自行车的人)。更多详情请参见表 I。随后,我们获得检测边界框及其相应的逻辑和短语,将其馈送到 SAM [18] 以生成 M 个精确分割二进制掩码。将 Grounding DINO logits 与二进制掩码相乘后,每个像素都有 {li}M i=1 logits。我们使用以下方法获取每像素标签 Spix:

其中ψ(·)是根据短语将li的索引映射到类别标签的函数。如果一个像素不属于任何类别并获得 M 个零 logits,我们将给它一个“不确定”标签。生成的检测边界框和语义标签如图4所示。
为了利用 2D 语义监督,我们最初利用具有 c 个输出通道的语义头将提取的体积特征映射到语义输出,表示为 S(x)。与第 III-B 节中概述的方法类似,我们使用以下方程再次进行体渲染:

其中 ˆ Spix 表示每像素语义渲染输出。为了节省内存并提高效率,我们不会渲染分配有“不确定”标签的像素。此外,我们只渲染中心帧而不是多个帧,并将采样率降低到 Ls = L/4。我们的整体损失函数表示为:

其中 Lsem 是交叉熵损失函数,λ 是语义损失权重。
相关文章:
【OccNeRF: Advancing 3D Occupancy Prediction in LiDAR-Free Environments】阅读笔记
【OccNeRF: Advancing 3D Occupancy Prediction in LiDAR-Free Environments】阅读笔记 1. 论文概述Abstract1. Introduction2. Related work2.1 3D Occupancy Prediction2.2 Neural Radiance Fields2.3 Self-supervised Depth Estimation 3. Method3.1 Parameterized Occupanc…...

DDRPHY数字IC后端设计实现系列专题之后端设计导入,IO Ring设计
本章详细分析和论述了 LPDDR3 物理层接口模块的布图和布局规划的设计和实 现过程,包括设计环境的建立,布图规划包括模块尺寸的确定,IO 单元、宏单元以及 特殊单元的摆放。由于布图规划中的电源规划环节较为重要, 影响芯片的布线资…...
EDA --软件开发之路
之前一直在一家做数据处理的公司,从事c开发,公司业务稳定,项目有忙有闲,时而看下c,数据库,linux相关书籍,后面跳槽到了家eda公司,开始了一段eda开发之路。 eda 是 electric design …...
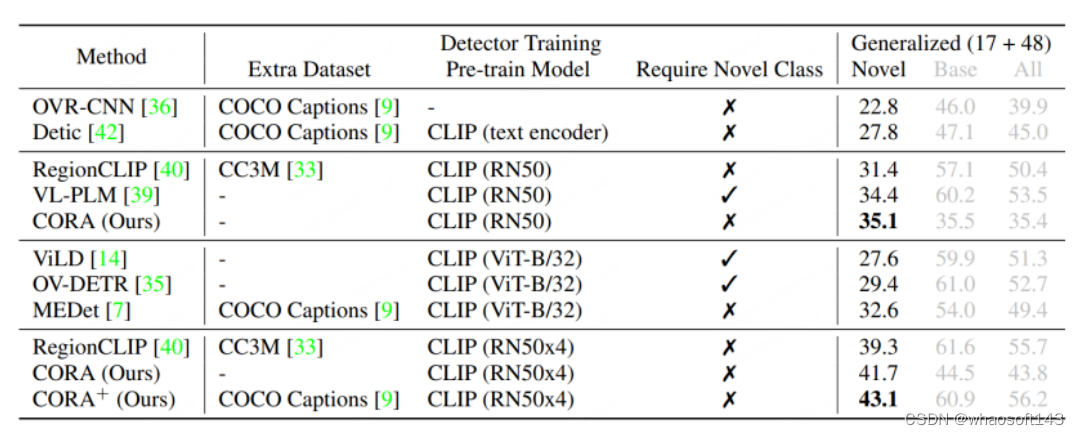
51c~目标检测~合集2
我自己的原文哦~ https://blog.51cto.com/whaosoft/12377509 一、总结 这里概述了基于深度学习的目标检测器的最新发展。同时,还提供了目标检测任务的基准数据集和评估指标的简要概述,以及在识别任务中使用的一些高性能基础架构,其还涵盖了…...

计算机低能儿从0刷leetcode | 33.搜索旋转排列数组
题目:33. 搜索旋转排序数组 思路:看到时间复杂度要求是O(log N)很容易想到二分查找,普通的二分查找我们已经掌握,本题中的数组可以看作由两个分别升序的数组拼成,在完全升序的部分中进行二分查找是容易的,…...
SpringBoot+VUE2完成WebSocket聊天(数据入库)
下载依赖 <!-- websocket --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-websocket</artifactId></dependency><!-- MybatisPlus --><dependency><groupId>com.ba…...
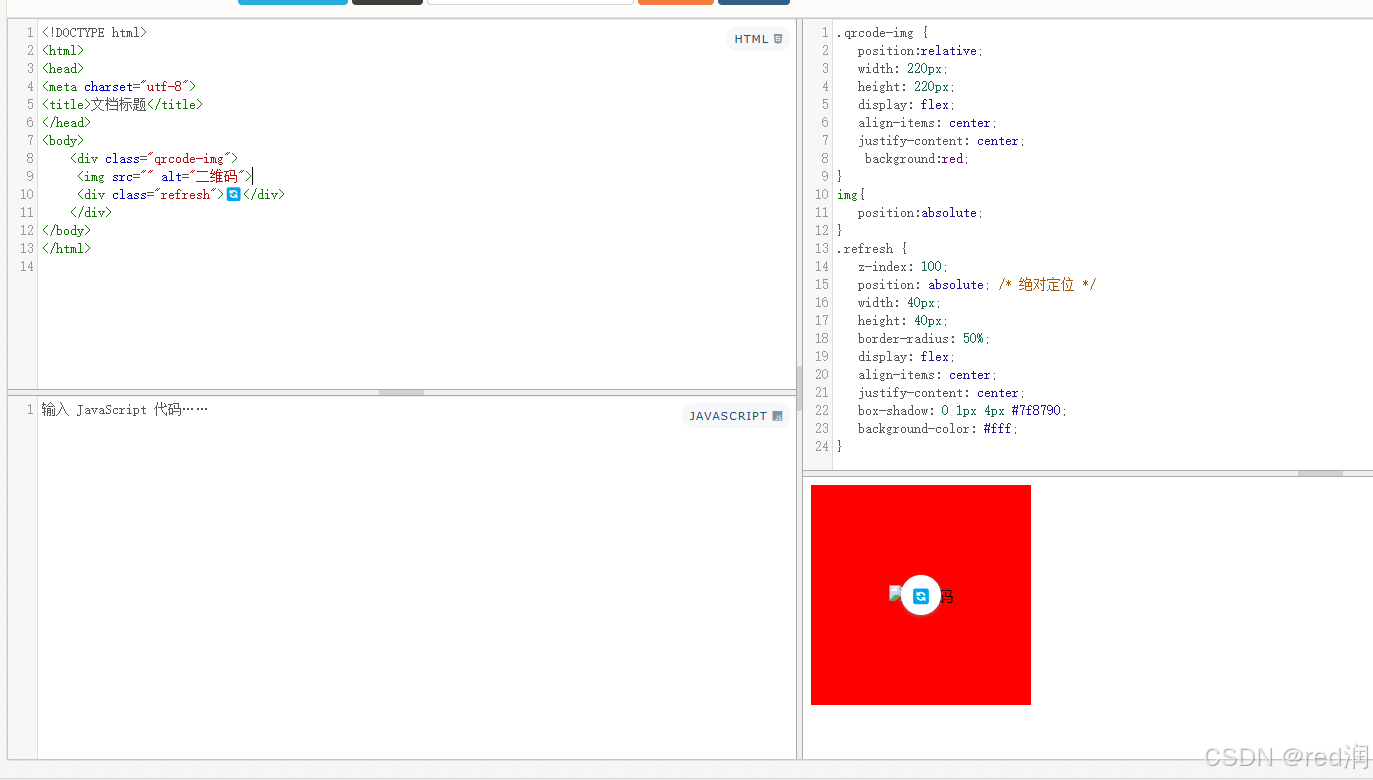
理解 CSS 中的绝对定位与 Flex 布局混用
理解 CSS 中的绝对定位与 Flex 布局混用 在现代网页设计中,CSS 布局技术如 flex 和绝对定位被广泛使用。然而,这两者结合使用时,可能会导致一些意想不到的布局问题。本文将探讨如何正确使用绝对定位元素,避免它们受到 flex 布局的…...

Redis 事务 问题
前言 相关系列 《Redis & 目录》《Redis & 事务 & 源码》《Redis & 事务 & 总结》《Redis & 事务 & 问题》 参考文献 《Redis事务详解》 Redis事务是什么? 标准的事务是指执行时具备原子性/一致性/隔离性/持久性的一系列操作。…...

Cpp学习手册-进阶学习
C标准库和C20新特性 C标准库概览: 核心库组件介绍: 容器: C 标准库提供了多种容器,它们各有特点,适用于不同的应用场景。 std::vector: vector:动态数组,支持快速随机访问。 #in…...

代码随想录-字符串-反转字符串中的单词
题目 题解 法一:纯粹为了做出本题,暴力解 没有技巧全是感情 class Solution {public String reverseWords(String s) {//首先去除首尾空格s s.trim();String[] strs s.split("\\s");StringBuilder sb new StringBuilder();//定义一个公共的字符反转…...
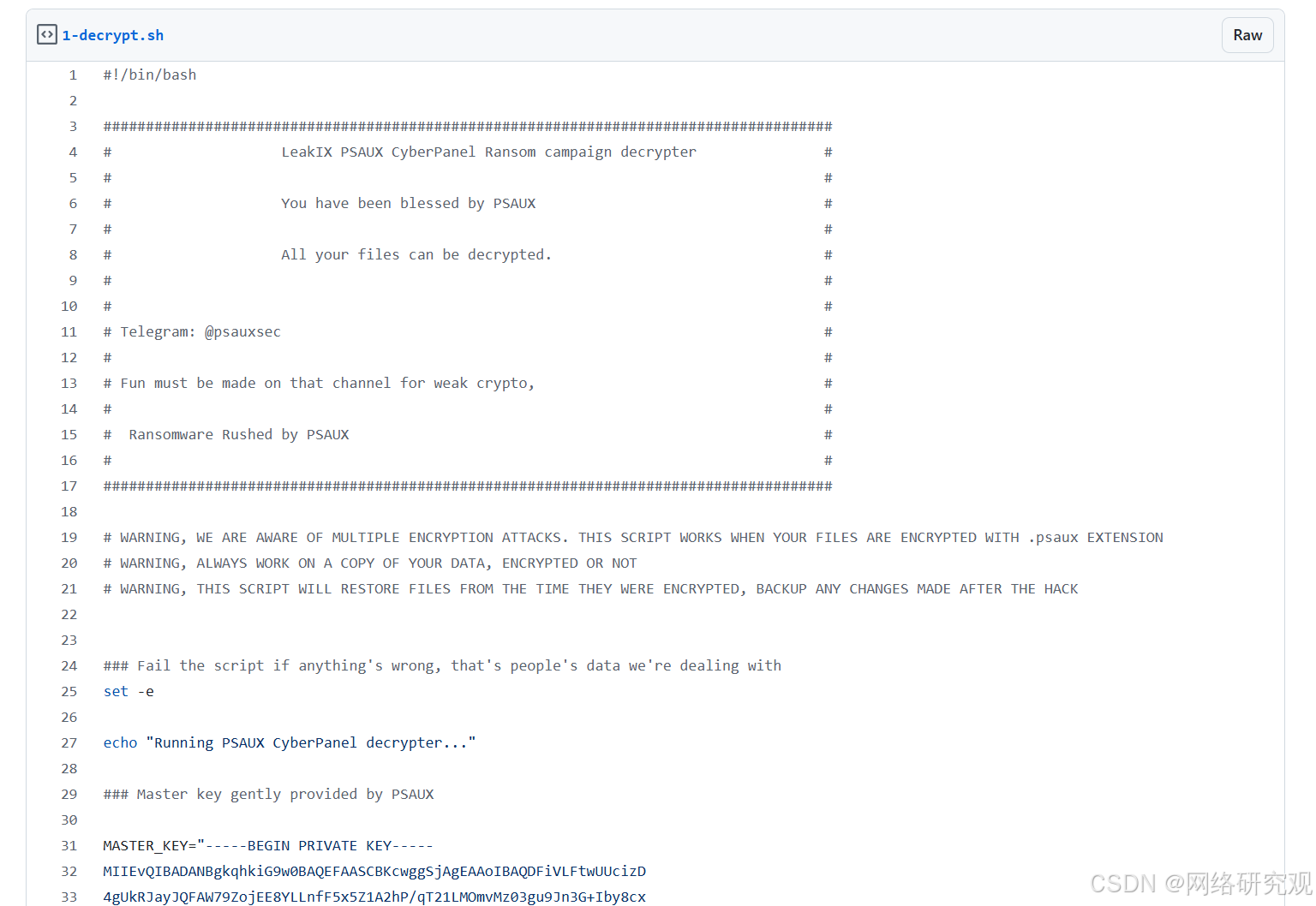
勒索软件通过易受攻击的 CyberPanel 实例攻击网络托管服务器
一个威胁行为者(或可能多个)使用 PSAUX 和其他勒索软件攻击了大约 22,000 个易受攻击的 CyberPanel 实例以及运行该实例的服务器上的加密文件。 PSAUX 赎金记录(来源:LeakIX) CyberPanel 漏洞 CyberPane…...

Open WebUI + openai API / vllm API ,实战部署教程
介绍Open WebUI + Ollama 的使用: https://www.dong-blog.fun/post/1796 介绍vllm 的使用:https://www.dong-blog.fun/post/1781 介绍 Ollama 的使用: https://www.dong-blog.fun/post/1797 本篇博客玩个花的,Open WebUI 本身可以兼容openai 的api, 那来尝试一下。 仅供…...

InsuranceclaimsController
目录 1、 InsuranceclaimsController 1.1、 保险理赔结算 1.2、 生成预约单号 1.3、 保存索赔表 InsuranceclaimsController using QXQPS.Models; using QXQPS.Vo; using System; using System.Collections; using System.Collections.Generic; using System.Li…...
如何成为开源代码库Dify的contributor:解决issue并提交PR
前言 Dify 是一个开源的大语言模型(LLM)应用开发平台,它融合了后端即服务(Backend as Service)和LLMOps的理念,旨在简化和加速生成式AI应用的创建和部署。Dify提供了一个用户友好的界面和一系列强大的工具…...
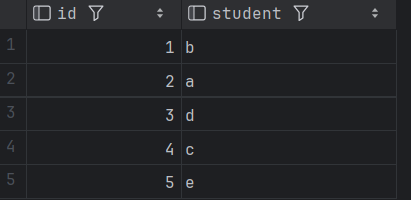
SQL进阶技巧:巧用异或运算解决经典换座位问题
目录 0 问题描述 1 数据准备 2 问题分析 2.1 什么是异或 2.2异或有什么特性? 2.3 异或应用 2.4 本问题采用异或SQL解决方案 3 小结 0 问题描述 表 seat中有2个字段id和student id 是该表的主键(唯一值)列,student表示学生姓名。 该表的每一行都表示学生的姓名和 ID。…...
进行监控)
【MySQL】 运维篇—数据库监控:使用MySQL内置工具(如SHOW命令、INFORMATION_SCHEMA)进行监控
随着应用程序的增长,数据库的性能和稳定性变得至关重要。监控数据库的状态和性能可以帮助数据库管理员(DBA)及时发现问题,进行故障排查,并优化数据库的运行效率。通过监控工具,DBA可以获取实时的性能指标、…...
【温酒笔记】DMA
参考文档:野火STM32F103 1. Direct Memory Access-直接内存访问 DMA控制器独立于内核 是一个单独的外设 DMA1有7个通道DMA2有5个通道DMA有四个等级,非常高,高,中,低四个优先级如果优先等级相同,通道编号越…...

力扣判断字符是否唯一(位运算)
文章目录 给一个数n,判断它的二进制位中第x位是0还是1(从0开始计数)将一个数n的二进制位第X位修改为1(从0开始计数)将一个数n的二进制第x位修改为0(从0开始计数)提取一个数n二进制中最右侧的1去掉一个数n二进制表示中最右侧的1 今天我们通过判断字符是否唯一这个题来了解位运算…...
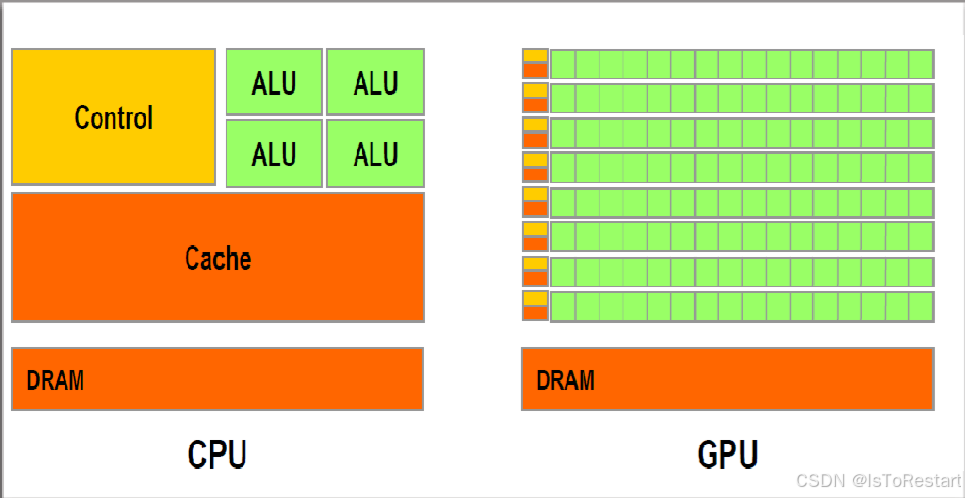
GPU和CPU区别?为什么挖矿、大模型都用GPU?
GPU(图形处理单元)和CPU(中央处理单元)是计算机中两种不同类型的处理器,它们在设计和功能上有很大的区别。 CPU是计算机的大脑,专门用于执行各种通用任务,如操作系统管理、数据处理、多任务处理等。它的架构设计旨在适应多种任务,…...
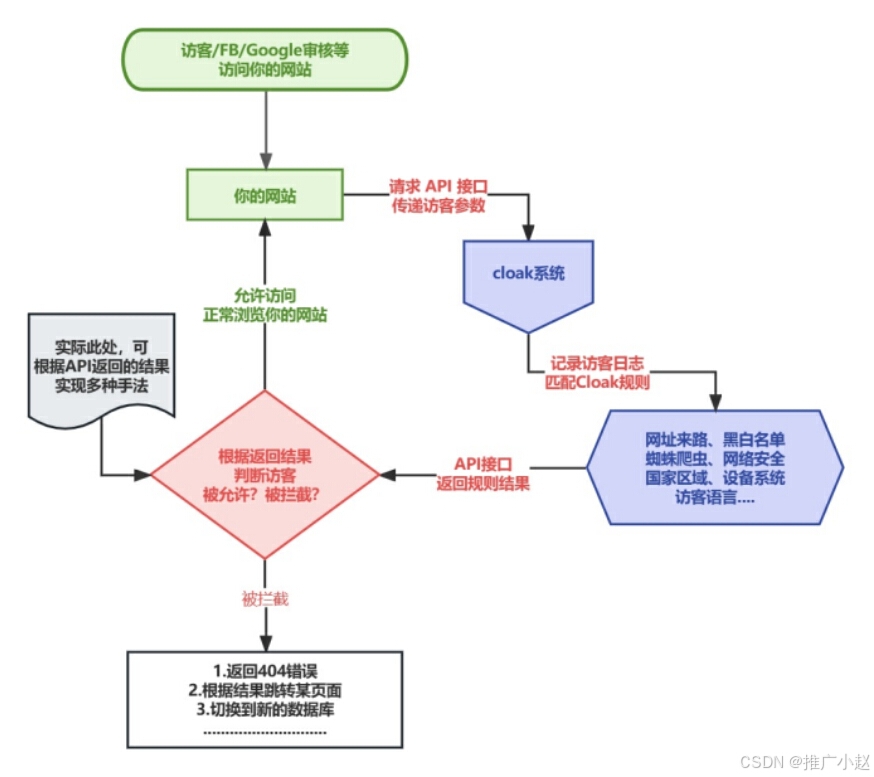
新兴斗篷cloak技术,你了解吗?
随着互联网技术的飞速发展,网络营销领域也经历了翻天覆地的变革。 从最早的网络横幅广告到如今主流的搜索引擎和社交媒体营销,广告形式变得越来越多样。 其中,搜索引擎广告一直以其精准投放而备受青睐,但近年来,一项名…...

Prompt Tuning、P-Tuning、Prefix Tuning的区别
一、Prompt Tuning、P-Tuning、Prefix Tuning的区别 1. Prompt Tuning(提示调优) 核心思想:固定预训练模型参数,仅学习额外的连续提示向量(通常是嵌入层的一部分)。实现方式:在输入文本前添加可训练的连续向量(软提示),模型只更新这些提示参数。优势:参数量少(仅提…...

SciencePlots——绘制论文中的图片
文章目录 安装一、风格二、1 资源 安装 # 安装最新版 pip install githttps://github.com/garrettj403/SciencePlots.git# 安装稳定版 pip install SciencePlots一、风格 简单好用的深度学习论文绘图专用工具包–Science Plot 二、 1 资源 论文绘图神器来了:一行…...

sqlserver 根据指定字符 解析拼接字符串
DECLARE LotNo NVARCHAR(50)A,B,C DECLARE xml XML ( SELECT <x> REPLACE(LotNo, ,, </x><x>) </x> ) DECLARE ErrorCode NVARCHAR(50) -- 提取 XML 中的值 SELECT value x.value(., VARCHAR(MAX))…...

【开发技术】.Net使用FFmpeg视频特定帧上绘制内容
目录 一、目的 二、解决方案 2.1 什么是FFmpeg 2.2 FFmpeg主要功能 2.3 使用Xabe.FFmpeg调用FFmpeg功能 2.4 使用 FFmpeg 的 drawbox 滤镜来绘制 ROI 三、总结 一、目的 当前市场上有很多目标检测智能识别的相关算法,当前调用一个医疗行业的AI识别算法后返回…...

React---day11
14.4 react-redux第三方库 提供connect、thunk之类的函数 以获取一个banner数据为例子 store: 我们在使用异步的时候理应是要使用中间件的,但是configureStore 已经自动集成了 redux-thunk,注意action里面要返回函数 import { configureS…...

Qt 事件处理中 return 的深入解析
Qt 事件处理中 return 的深入解析 在 Qt 事件处理中,return 语句的使用是另一个关键概念,它与 event->accept()/event->ignore() 密切相关但作用不同。让我们详细分析一下它们之间的关系和工作原理。 核心区别:不同层级的事件处理 方…...
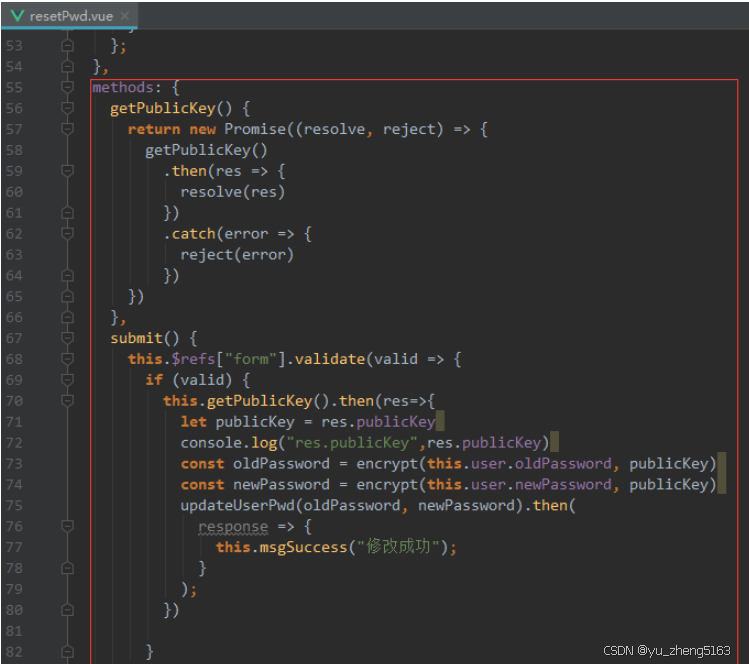
若依登录用户名和密码加密
/*** 获取公钥:前端用来密码加密* return*/GetMapping("/getPublicKey")public RSAUtil.RSAKeyPair getPublicKey() {return RSAUtil.rsaKeyPair();}新建RSAUti.Java package com.ruoyi.common.utils;import org.apache.commons.codec.binary.Base64; im…...
【1】跨越技术栈鸿沟:字节跳动开源TRAE AI编程IDE的实战体验
2024年初,人工智能编程工具领域发生了一次静默的变革。当字节跳动宣布退出其TRAE项目(一款融合大型语言模型能力的云端AI编程IDE)时,技术社区曾短暂叹息。然而这一退场并非终点——通过开源社区的接力,TRAE在WayToAGI等…...

盲盒一番赏小程序:引领盲盒新潮流
在盲盒市场日益火爆的今天,如何才能在众多盲盒产品中脱颖而出?盲盒一番赏小程序给出了答案,它以创新的玩法和优质的服务,引领着盲盒新潮流。 一番赏小程序的最大特色在于其独特的赏品分级制度。赏品分为多个等级,从普…...

第6章:Neo4j数据导入与导出
在实际应用中,数据的导入与导出是使用Neo4j的重要环节。无论是初始数据加载、系统迁移还是数据备份,都需要高效可靠的数据传输机制。本章将详细介绍Neo4j中的各种数据导入与导出方法,帮助读者掌握不同场景下的最佳实践。 6.1 数据导入策略 …...