C#网络爬虫开发
1前言
爬虫一般都是用Python来写,生态丰富,动态语言开发速度快,调试也很方便
但是
我要说但是,动态语言也有其局限性,笔者作为老爬虫带师,几乎各种语言都搞过,现在这个任务并不复杂,用我最喜欢的C#做小菜一碟~
2开始
之前做onecat项目的时候,最开始的数据采集模块,就是用 C# 做的,同时还集成了 Chloe 作为 ORM,用 Nancy 做 HTTP 接口,结合 C# 强大的并发功能,做出来的效果不错。
这次是要爬一些壁纸,很简单的场景,于是沿用了之前 OneCat 项目的一些工具类,并且做了一些改进。
3HttpHelper
网络请求直接使用 .Net Core 标准库的 HttpClient,这个库要求使用单例,在 AspNetCore 里一般用依赖注入,不过这次简单的爬虫直接用 Console 程序就行。
把 HTML 爬下来后,还需要解析,在Python中一般用 BeautifulSoup,在C#里可以用 AngleSharp ,也很好用~
为了使用方便,我又封装了一个工具类,把 HttpClient 和 AngleSharp 集成在一起。
public static class HttpHelper {public const string UserAgent ="Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36";public static HttpClientHandler Handler { get; }public static HttpClient Client { get; }static HttpHelper() {Handler = new HttpClientHandler();Client = new HttpClient(Handler);Client.DefaultRequestHeaders.Add("User-Agent", UserAgent);}public static async Task<IHtmlDocument> GetHtmlDocument(string url) {var html = await Client.GetStringAsync(url);// todo 这个用法有内存泄漏问题,得优化一下return new HtmlParser().ParseDocument(html);}public static async Task<IHtmlDocument> GetHtmlDocument(string url, string charset) {var res = await Client.GetAsync(url);var resBytes = await res.Content.ReadAsByteArrayAsync();var resStr = Encoding.GetEncoding(charset).GetString(resBytes);// todo 这个用法有内存泄漏问题,得优化一下return new HtmlParser().ParseDocument(resStr);}
}这段代码里面有俩 todo ,这个内存泄漏的问题在简单的爬虫中影响不大,所以后面有大规模的需求再来优化吧~
4搞HTML
大部分爬虫是从网页上拿数据
如果网页是后端渲染出来的话,没有js动态加载数据,基本上用CSS选择器+正则表达式就可以拿到任何想要的数据。
经过前面的封装,请求网页+解析HTML只需要一行代码
IHtmlDocument data = await HttpHelper.GetHtmlDocument(url);拿到 IHtmlDocument 对象之后,用 QuerySelector 传入css选择器,就可以拿到各种元素了。
例如这样,取出 <li> 元素下所有链接的地址
var data = await HttpHelper.GetHtmlDocument(url);
foreach (var item in data.QuerySelectorAll(".pagew li")) {var link = item.QuerySelector("a");var href = link?.GetAttribute("href");if (href != null) await CrawlItem(href);
}或者结合正则表达式
var data = await HttpHelper.GetHtmlDocument(url);
var page = data.QuerySelector(".pageinfo");
Console.WriteLine("拿到分页信息:{0}", page?.TextContent);
var match = Regex.Match(page?.TextContent ?? "", @"共\s(\d+)页(\d+)条");
var pageCount = int.Parse(match.Groups[1].Value);
for (int i = 1; i <= pageCount; i++) {await CrawlPage(i);
}正则表达式非常好用,爬虫必备~
5JSON 处理
老生常谈的问题了
JSON 在 web 开发中很常见,无论是接口交互,还是本地保存数据,这都是一种很好的格式
.Net Core 自带的 System.Text.Json 还不错,不需要手动安装依赖,没有特殊需求的话,直接用这个就好了
这里的场景是要把采集的数据存到 JSON 里,即序列化,用以下的配置代码一把梭即可,可以应付大多数场景
var jsonOption = new JsonSerializerOptions {WriteIndented = true,Encoder = JavaScriptEncoder.UnsafeRelaxedJsonEscaping
};写入文件
await File.WriteAllTextAsync("path", JsonSerializer.Serialize(data, jsonOption));6下载文件
最简单就是直接用 HttpClient 获取 Response,然后 CopyToAsync 写到文件流里面
这个用法拿来下载几个小文件还可以,但多线程下载、断点重连、失败重试等方法就得自己实现了,比较繁琐。
所以这次我直接用了第三方库 Downloader,这个库看起来很猛,功能很多,我就不翻译了
同样的,我把下载的功能也封装到 HttpHelper中
增加这部分代码
public static IDownloadService Downloader { get; }public static DownloadConfiguration DownloadConf => new DownloadConfiguration {BufferBlockSize = 10240, // 通常,主机最大支持8000字节,默认值为8000。ChunkCount = 8, // 要下载的文件分片数量,默认值为1// MaximumBytesPerSecond = 1024 * 50, // 下载速度限制,默认值为零或无限制MaxTryAgainOnFailover = 5, // 失败的最大次数ParallelDownload = true, // 下载文件是否为并行的。默认值为falseTimeout = 1000, // 每个 stream reader 的超时(毫秒),默认值是1000RequestConfiguration = {Accept = "*/*",AutomaticDecompression = DecompressionMethods.GZip | DecompressionMethods.Deflate,CookieContainer = new CookieContainer(), // Add your cookiesHeaders = new WebHeaderCollection(), // Add your custom headersKeepAlive = true,ProtocolVersion = HttpVersion.Version11, // Default value is HTTP 1.1UseDefaultCredentials = false,UserAgent = UserAgent}
};static HttpHelper() {// ...Downloader = new DownloadService(DownloadConf);
}使用方法依然是一行代码
await HttpHelper.Downloader.DownloadFileTaskAsync(url, filepath);不过这次没有直接封装一个下载的方法,而是把 IDownloadService 对象做成属性,因为下载的时候往往要加一些“buff”
比如监听下载进度,看下面的代码
HttpHelper.Downloader.DownloadStarted += DownloadStarted;
HttpHelper.Downloader.DownloadFileCompleted += DownloadFileCompleted;
HttpHelper.Downloader.DownloadProgressChanged += DownloadProgressChanged;
HttpHelper.Downloader.ChunkDownloadProgressChanged += ChunkDownloadProgressChanged;这个库提供了四个事件,分别是:
下载开始
下载完成
下载进度变化
分块下载进度变化
7进度条
有了这些事件,就可以实现下载进度条展示了,接下来介绍的进度条,也是 Downloader 这个库官方例子中使用的
首先,把官网上的例子忘记吧,那几个例子实际作用不大。
Tick模式
这个进度条有两种模式,一种是它自己的 Tick 方法,先定义总任务数量,执行一次表示完成一个任务,比如这个:
using var bar = new ProgressBar(10, "正在下载所有图片", BarOptions);上面代码定义了10个任务,每执行一次 bar.Tick() 就表示完成一次任务,执行10次后就整个完成~
IProgress<T> 模式
这个 IProgress<T> 是C#标准库的类型,用来处理进度条的。
ProgressBar 对象可以使用 AsProgress<T> 方法转换称 IProgress<T> 对象,然后调用 IProgress<T> 的 Report 方法,报告进度。
这个就很适合下载进度这种非线性的任务,每次更新时,完成的进度都不一样
Downloader的下载进度更新事件,用的是百分比,所以用这个 IProgress<T> 模式就很合适。
进度条嵌套
本爬虫项目是要采集壁纸,壁纸的形式是按图集组织的,一个图集下可能有多个图片
为了应对这种场景,可以用一个进度条显示总进度,表示当前正在下载某个图集
然后再嵌套子进度条,表示正在下载当前图集的第n张图片
然后的然后,再套娃一个孙子进度条,表示具体图片的下载进度(百分比)
这里用到的是 ProgressBar 的 Spawn 方法,会生成一个 ChildProgressBar 对象,此时更新子进度条对象的值就好了。
直接看代码吧
var list = // 加载图集列表using var bar = new ProgressBar(list.Count, "正在下载所有图片", BarOptions);foreach (var item in list) {bar.Message = $"图集:{item.Name}";bar.Tick();foreach (var imgUrl in item.Images) {using (var childBar = bar.Spawn(item.ImageCount,$"图片:{imgUrl}",ChildBarOptions)) {childBar.Tick();// 具体的下载代码}}
}这样就实现了主进度条显示下载了第几个图集,子进度条显示下载到第几张图片。
然后具体下载代码中,使用 Downloader 的事件监听,再 Spawn 一个新的进度条显示单张图片的下载进度。
代码如下:
private async Task Download(IProgressBar bar, string url, string filepath) {var percentageBar = bar.Spawn(100, $"正在下载:{Path.GetFileName(url)}", PercentageBarOptions);HttpHelper.Downloader.DownloadStarted += DownloadStarted;HttpHelper.Downloader.DownloadFileCompleted += DownloadFileCompleted;HttpHelper.Downloader.DownloadProgressChanged += DownloadProgressChanged;await HttpHelper.Downloader.DownloadFileTaskAsync(url, filepath);void DownloadStarted(object? sender, DownloadStartedEventArgs e) {Trace.WriteLine($"图片, FileName:{Path.GetFileName(e.FileName)}, TotalBytesToReceive:{e.TotalBytesToReceive}");}void DownloadFileCompleted(object? sender, AsyncCompletedEventArgs e) {Trace.WriteLine($"下载完成, filepath:{filepath}");percentageBar.Dispose();}void DownloadProgressChanged(object? sender, DownloadProgressChangedEventArgs e) {percentageBar.AsProgress<double>().Report(e.ProgressPercentage);}
}注意所有的 ProgressBar 对象都需要用完释放,所以这里在 DownloadFileCompleted 事件里面 Dispose 了。
上面的是直接用 using 语句,自动释放。
进度条配置
这个东西的自定义功能还不错。
可以配置颜色、显示字符、显示位置啥的
var barOptions = new ProgressBarOptions {ForegroundColor = ConsoleColor.Yellow,BackgroundColor = ConsoleColor.DarkYellow,ForegroundColorError = ConsoleColor.Red,ForegroundColorDone = ConsoleColor.Green,BackgroundCharacter = '\u2593',ProgressBarOnBottom = true,EnableTaskBarProgress = RuntimeInformation.IsOSPlatform(OSPlatform.Windows),DisplayTimeInRealTime = false,ShowEstimatedDuration = false
};EnableTaskBarProgress 这个选项可以同时更新Windows任务状态栏上的进度
具体配置选项可以直接看源码,里面注释很详细。
如果 Spawn 出来的子进度条没配置选项,那就会继承上一级的配置。
8小结
用 C# 来做爬虫还是舒服的,至少比 Java 好很多
做控制台应用,打包成exe也方便分发
相关文章:

C#网络爬虫开发
1前言爬虫一般都是用Python来写,生态丰富,动态语言开发速度快,调试也很方便但是我要说但是,动态语言也有其局限性,笔者作为老爬虫带师,几乎各种语言都搞过,现在这个任务并不复杂,用我…...

Fastjson 总结
0x00 前言 这一篇主要是针对已经完成的fastjson系列做一个知识点总结,一来是为了更加有条理的梳理已经存在的内容,二来是为了更好的复习和利用。 0x01 Fastjson基础知识点 1.常见问题: 问:fastjson的触发点是什么?…...

文件路径模块os.path
文件路径模块os.path 文章目录文件路径模块os.path1.概述2.解析路径2.1.拆分路径和文件名split2.2.获取文件名称basename2.3.返回路径第一部分dirname2.4.扩展名称解析路径splitext2.5.返回公共前缀路径commonprefix3.创建路径3.1.拼接路径join3.2.获取家目录3.3.规范化路径nor…...
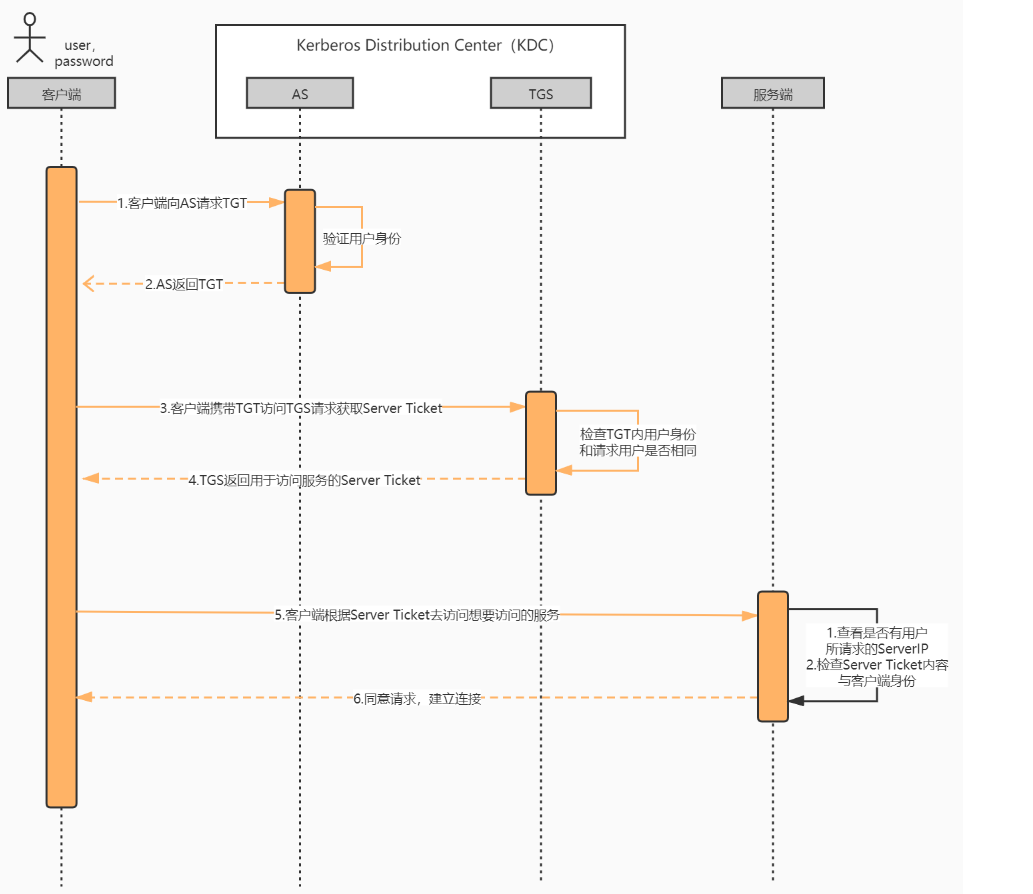
Kerberos简单介绍及使用
Kerberos作用 简单来说安全相关一般涉及以下方面:用户认证(Kerberos的作用)、用户授权、用户管理.。而Kerberos功能是用户认证,通俗来说解决了证明A是A 的问题。 认证过程(时序图) 核心角色/概念 KDC&…...

DOM编程-全选、全不选和反选
<!DOCTYPE html> <html> <head> <meta charset"utf-8"> <title>全选、全不选和反选</title> </head> <body bgcolor"antiquewhite"> <script type"text/jav…...

C++11可变模板参数
C11可变模板参数一、简介二、语法三、可变模版参数函数3.1、递归函数方式展开参数包3.2、逗号表达式展开参数包一、简介 C11的新特性–可变模版参数(variadic templates)是C11新增的最强大的特性之一,它对参数进行了高度泛化,它能…...

Linux多线程
目录 一、认识线程 1.1 线程概念 1.2 页表 1.3 线程的优缺点 1.3.1 优点 1.3.2 缺点 1.4 线程异常 二、进程 VS 线程 三、Linux线程控制 3.1 POSIX线程库 3.1 线程创建 3.3 线程等待 3.4 线程终止 3.4.1 return退出 3.4.2 pthread_exit() 3.4.3 pthread_cancel…...
Webpack5 环境下 Openlayers 标注(Icon) require 引入图片问题
Webpack5 环境下 Openlayers 标注(Icon) require 引入图片问题环境版本Openlayers 使用 require 问题Webpack5 正确配置构建新环境的时候,偶然发现 Openlayers 使用 require 的方式加载图片(Icon)报错,开始…...

Zookeeper安装部署
文章目录Zookeeper安装部署Zookeeper安装部署 将Zookeeper安装包解压缩, [rootlocalhost opt]# ll 总用量 14032 -rw-r--r--. 1 root root 12392394 10月 13 11:44 apache-zookeeper-3.6.0-bin.tar.gz drwxrwxr-x. 6 root root 4096 10月 18 01:44 redis-5.0.4 …...
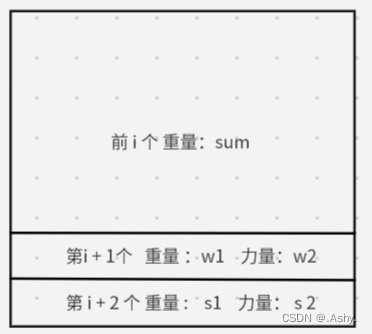
Cow Acrobats ( 临项交换贪心 )
题目大意: N 头牛 , 每头牛有一个重量(Weight)和一个力量(Strenth) , N头牛进行排列 , 第 i 头牛的风险值为其上所有牛总重减去自身力量 , 问如何排列可以使最大风险值最小 , 求出这个最小的最大风险值&am…...

MySQL:为什么说应该优先选择普通索引,尽量避免使用唯一索引
前言 在使用MySQL的过程中,随着表数据的逐渐增多,为了更快的查询我们需要的数据,我们会在表中建立不同类型的索引。 今天我们来聊一聊,普通索引和唯一索引的使用场景, 以及为什么说推荐大家优先使用普通索引…...

Spring Cloud alibaba之Feign
JAVA项目中如何实现接口调用?HttpclientHttpclient是Apache Jakarta Common下的子项目,用来提供高效的、最新的、功能丰富的支持Http协议的客户端编程工具包,并且它支持HTTP协议最新版本和建议。HttpClient相比传统JDK自带的URL Connection&a…...
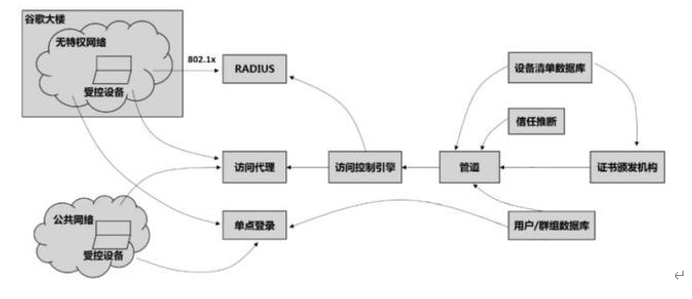
零信任-Google谷歌零信任介绍(3)
谷歌零信任的介绍? "Zero Trust" 是一种网络安全模型,旨在通过降低网络中的信任级别来防止安全威胁。在零信任模型中,不论请求来自内部网络还是外部网络,系统都将对所有请求进行详细的验证和审核。这意味着每次请求都需…...
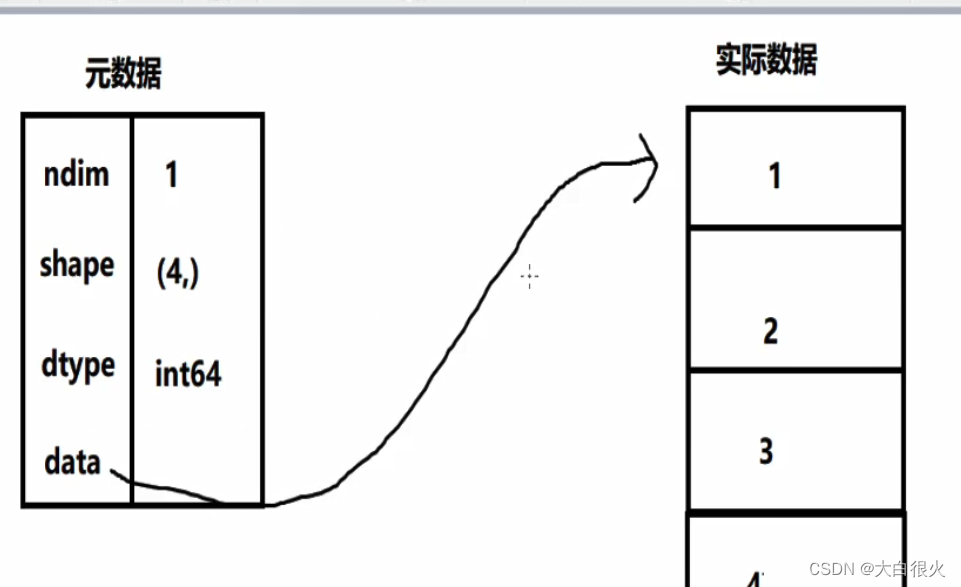
Numpy基础——人工智能基础
文章目录一、Numpy概述1.优势2.numpy历史3.Numpy的核心:多维数组4.numpy基础4.1 ndarray数组4.2 内存中的ndarray对象一、Numpy概述 1.优势 Numpy(Nummerical Python),补充了Python语言所欠缺的数值计算能力;Numpy是其它数据分析及机器学习库的底层库&…...

电商仓储与配送云仓是什么?
仓库是整个供给链的关键局部。它们是产品暂停和触摸的点,耗费空间和时间(工时)。空间和时间反过来也是费用。经过开发数学和计算机模型来微调仓库的规划和操作,经理能够显著降低与产品分销相关的劳动力本钱,进步仓库空间应用率,并…...

【零基础入门前端系列】—HTML介绍(一)
【零基础入门前端系列】—HTML介绍(一) 一、什么是HTML HTML是用来描述网页的一种语言HTML指的是超文本标记语言:HyperText Markup LanguageHTML不是一种编程语言,而是一种超文本标记语言,标记语言是一套标记标签(ma…...

Elasticsearch索引库和文档的相关操作
前言:最近一直在复习Elasticsearch相关的知识,公司搜索相关的技术用到了这个,用公司电脑配了环境,借鉴网上的课程进行了总结。希望能够加深自己的印象以及帮助到其他的小伙伴儿们😉😉。 如果文章有什么需要…...

使用Python,Opencv检测图像,视频中的猫
使用Python,Opencv检测图像,视频中的猫🐱 这篇博客将介绍如何使用Python,OpenCV库附带的默认Haar级联检测器来检测图像中的猫。同样的技术也可以应用于视频流。这些哈尔级联由约瑟夫豪斯(Joseph Howse)训练…...

浅谈域名和服务器集约化管理的误区
一个正常的网站通常由域名、网站程序、服务器三个部分组成,网站程序由单位开发设计,而域名和服务器则需要租用购买,那么域名和服务器之间的关系是什么?如何实现域名和服务器的有效管理呢? 服务器和域名的关系 服务器…...

迪赛智慧数——柱状图(正负条形图):20212022人才求职最关注的因素
效果图从近两年职场跳槽方向看,相比此前人们对高薪大厂趋之若鹜,如今职场人更关注业务前景。根据相关数据显示,职场人求职最关注的因素中,“薪资福利”权重下降,“个人发展”权重上升,“业务前景”首次进入…...

【Oracle APEX开发小技巧12】
有如下需求: 有一个问题反馈页面,要实现在apex页面展示能直观看到反馈时间超过7天未处理的数据,方便管理员及时处理反馈。 我的方法:直接将逻辑写在SQL中,这样可以直接在页面展示 完整代码: SELECTSF.FE…...

【WiFi帧结构】
文章目录 帧结构MAC头部管理帧 帧结构 Wi-Fi的帧分为三部分组成:MAC头部frame bodyFCS,其中MAC是固定格式的,frame body是可变长度。 MAC头部有frame control,duration,address1,address2,addre…...

LLM基础1_语言模型如何处理文本
基于GitHub项目:https://github.com/datawhalechina/llms-from-scratch-cn 工具介绍 tiktoken:OpenAI开发的专业"分词器" torch:Facebook开发的强力计算引擎,相当于超级计算器 理解词嵌入:给词语画"…...

CMake 从 GitHub 下载第三方库并使用
有时我们希望直接使用 GitHub 上的开源库,而不想手动下载、编译和安装。 可以利用 CMake 提供的 FetchContent 模块来实现自动下载、构建和链接第三方库。 FetchContent 命令官方文档✅ 示例代码 我们将以 fmt 这个流行的格式化库为例,演示如何: 使用 FetchContent 从 GitH…...

蓝桥杯3498 01串的熵
问题描述 对于一个长度为 23333333的 01 串, 如果其信息熵为 11625907.5798, 且 0 出现次数比 1 少, 那么这个 01 串中 0 出现了多少次? #include<iostream> #include<cmath> using namespace std;int n 23333333;int main() {//枚举 0 出现的次数//因…...

Python ROS2【机器人中间件框架】 简介
销量过万TEEIS德国护膝夏天用薄款 优惠券冠生园 百花蜂蜜428g 挤压瓶纯蜂蜜巨奇严选 鞋子除臭剂360ml 多芬身体磨砂膏280g健70%-75%酒精消毒棉片湿巾1418cm 80片/袋3袋大包清洁食品用消毒 优惠券AIMORNY52朵红玫瑰永生香皂花同城配送非鲜花七夕情人节生日礼物送女友 热卖妙洁棉…...

安宝特方案丨船舶智造的“AR+AI+作业标准化管理解决方案”(装配)
船舶制造装配管理现状:装配工作依赖人工经验,装配工人凭借长期实践积累的操作技巧完成零部件组装。企业通常制定了装配作业指导书,但在实际执行中,工人对指导书的理解和遵循程度参差不齐。 船舶装配过程中的挑战与需求 挑战 (1…...

基于Java+MySQL实现(GUI)客户管理系统
客户资料管理系统的设计与实现 第一章 需求分析 1.1 需求总体介绍 本项目为了方便维护客户信息为了方便维护客户信息,对客户进行统一管理,可以把所有客户信息录入系统,进行维护和统计功能。可通过文件的方式保存相关录入数据,对…...

Matlab实现任意伪彩色图像可视化显示
Matlab实现任意伪彩色图像可视化显示 1、灰度原始图像2、RGB彩色原始图像 在科研研究中,如何展示好看的实验结果图像非常重要!!! 1、灰度原始图像 灰度图像每个像素点只有一个数值,代表该点的亮度(或…...
Linux-进程间的通信
1、IPC: Inter Process Communication(进程间通信): 由于每个进程在操作系统中有独立的地址空间,它们不能像线程那样直接访问彼此的内存,所以必须通过某种方式进行通信。 常见的 IPC 方式包括&#…...