机器学习课程总结(个人向)
前言
通过看课件PPT整理的笔记,没有截图
由于大部分内容已经耳熟能详了,故记录比较简略,只记录了一些概念和需要记忆的地方。
里面有较多的个人观点,未必正确。如有错误,还请各位大佬指正
正文
绪论
机器学习的定义:程序在任务T上通过经验E对目标P进行优化
TPE
任务 性能指标 训练经验
目标函数:状态->评价/行动
模型复杂度(函数描述能力)<--权衡-->数据量
##########LMS算法:均方误差+梯度下降
delta = Σ(y'-y)^2
w <- w+ n*(y'-y)*X
n:学习率
执行系统、鉴定器、泛化器、实验生成器??
执行系统:输入问题、输出解决方案
鉴定器:输入解决方案、输出训练样例
泛化器:输入训练样例、输出假设(也就是拟合的结果分布)
实验生成器:输入假设、输出问题
概念是什么、假设是什么
概念:对象或事件集合的子集,用布尔函数表示
假设:我们对这个概念的拟合,可以用布尔函数表示,也可以用对属性约束的合取范式来表示。
例如<A1,B2,C1,?>,表示满足A1、B2、C1的任意实例都属于该假设
---------------------------------------------
概念学习
X、H、c、D
X实例集:样本空间
H假设集:在该样本空间上的任意一个布尔函数,概念空间
c目标概念(布尔函数):X->{0,1}
D训练样例集:{<xi,c(xi)>},其中xi∈X
学习目标:找到h∈H,使得任意x∈X有h(x)=c(x)
归纳学习假设:
由于样本空间X过大,我们假设:
任意<x,c(x)>∈D都有h(x)=c(x),且D足够大时,
那么我们就认为,h可以使得大部分x∈X有h(x)=c(x)
搜索空间:搜索概念空间中的元素,样本空间中的概念边界
##########偏序关系:more_general_than_or_queal_to
hk(x)=1 -> hj(x)=1
记作hj > hk
##########Find-S算法
从最特殊假设开始,枚举D中正例,哪个属性不满足就取哪个并集加入当前假设,不管负例
##########候选消除算法
Find-S的升级版,输出所有满足条件的假设集合,给出偏序集合的上下界
一致:同时满足D中正例和负例的h
变型空间:所有与D一致的h的集合,记为VS(H,D)
列表后消除算法:暴力枚举出H中的所有假设,一一验证
求出极大一般成员G集合和极小特殊成员S集合,作为上下界,VS(H,D)中所有元素必定位于该上下界之间
步骤:
若为正例,去除G中的不一致假设,泛化S中不一致的假设
若为反例,去除S中的不一致假设,泛化G中不一致的假设
若包含错误的概念数据,最终会收敛到一个空集
无偏学习的无用性,有偏性更强,归纳能力更强
---------------------------------------------
决策树
合取、析取、异或的决策树画法
ID3和C4.5,Splitinfo:划分后每个类别的占比的-plogp之和
错误率降低剪枝(后剪枝,修剪后在训练集上的性能不能低于原树)
规则剪枝(把每条路径的错误率算出来,单独剪枝,而不是统计子树中的总错误率)
还可以引入属性划分代价,把Gain^2/Cost作为划分依据
---------------------------------------------
ANN
感知器训练法则
w=w+Δw
Δw=n*(y'-y)*x
这里的输出是被二值化之后的y‘和y
delta法则=LMS法则(规则)
和感知器训练法则类似,但输出是没有加二值化的(阈值单元)
感知器训练法则是加入了阈值单元的输出,直接进行梯度下降
梯度下降:对整个训练数据进行计算(真实梯度)
随机梯度下降:一个一个数据的计算梯度(引入了扰动,避免梯度下降被局部极小值干扰)
输出单元δ值计算:y'*(1-y')*(y-y')(本质上是一层传递,最初δ为(y-y')即残差)
(这里的y'*(1-y')其实是链式法则求导到sigmoid的特征)
隐藏单元δ值计算:o*(1-o)*Σwi*δi
Δwi->j = n * δj * xi->j(其实大部分神经网络的xi->j都是xi吧?)
链式求导法则
增加冲量(叠加上次的梯度)
sigmoid、relu、tanh、leaky relu
在误差函数中添加L2正则化项,增加对目标函数的偏导(斜率)
交叉熵损失函数
---------------------------------------------
贝叶斯推理
(从观测到预测,从看得见的现象到内在本质的推理)
后验=似然*先验/全概率
先验P(h):在对概念进行观测之前,各个假设成立的概率,具有主观色彩
先验P(D):观测结果D的先验概率(一般认为是等概率吧)
似然P(D|h):在假设h成立的条件下,观测到数据D的概率
后验P(h|D):在已知观测D的情况下,假设h成立的概率
极大后验假设hMAP、极大似然假设hML:就是使得后验、似然概率最大的假设
Brute-Force贝叶斯概念学习(求hMAP)
枚举每个h,P(h)=1/|H|,似然:一致=1,不一致=0
计算出来的全概率先验为|VS(H,D)|/|H|
一致学习器:在训练集上正确率100%
(证明题)使用误差平方的损失函数会使得输出为极大似然假设
(主要思路:似然概率为每个样本的似然概率乘积累积,因为di服从正态分布,里面具有误差平方项,取argmax操作后,可以化简为最小误差平方和的形式)
贝叶斯学习器:L(X,H,D),D中标签具有噪声
选用正态分布来描述噪声
把预测离散的标签{0,1},改为预测概率[0,1]
暴力法:收集每种x值的概率,直接输出
梯度搜索,用损失函数G(h,D),计算预测结果的交叉熵,然后反向传播
但预测分类时并不能直接用极大似然假设h进行分类,需要通过后验概率加权合并所有假设ΣP(cls|hi)*P(hi|D)
由于合并过程代价过大,提出了Gibbs算法
Gibbs算法
按照P(h|D)的分布对H进行采样,用采集的h来预测h(x)
最差错误率为全部合并的两倍
朴素贝叶斯分类器
目标函数为离散
设x=(a1,a2,a3...,an),ai为样本x的第i个属性
求P(y|x)最大的y
使用贝叶斯公式转换后:求P(x|y)*P(y)
此时若x各个属性相互独立,则P(x|y)=ΠP(ai|y)
也就是说,我们只需要拟合P(ai|y)这n个函数,极大的削减了搜索空间
直接使用频率估计概率,拟合这些函数即可
m-估计(应该是马尔可夫估计?)
在样本数据少时,P(ai|y)=(n(ai)+mp)/(n(y)+m),p为先验估计,m为等效样本大小(呃,本质上就是直接加上m个分布为p的样本来补足)
文本分类问题:
预处理计算P(wi|tagj),空间复杂度O(vocabulary*tag_nums),扫描一遍数据集即可得出
---------------------------------------------
遗传算法
GA(fit,fit_thresh,p,r,m):
p:种群规模,r:产生杂交后代占比,m:突变概率
维护假设全集H的子集P(population)
使用fit函数计算每个h∈P的适应度(fit值),
当最大的fit值都无法满足fit_thresh时,进行遗传算法
1、根据适应度加权概率抽取样本p*(1-r)个,保留到下一代
2、选取r*p/2对样本,杂交得到后代,添加进来
3、再对下一代的m*p个样本进行突变
4、更新,计算每个样本的适应度
主要算法设计:适应度评估、选择算法、杂交操作、变异操作
目的是保留更多样性的群体,削弱局部极小值的影响
无需使用梯度计算,但需要大量适应度计算,编码定义较为困难
---------------------------------------------
无监督学习
聚类Kmeans,每个点找离他最近的中心点,然后中心点迭代为他所管辖点的中心,劣势:异常值、k值敏感、初始种子敏感、非线性边界聚类
SSE指标计算,每个中心到它所管辖的所有节点的距离
聚类结果的表示:聚类中心、每个点的分类、使用众数来表示聚类、使用聚类树表示
层次聚类:自上而下(分裂)、自下而上(合并)
合并法:类似并查集,需要计算两个聚类之间的距离(最近(单连接)、最远(全连接)、平均链接(多个点对距离和的均值)、聚类中心法)
样本距离计算:欧几里得、曼哈顿、闵可夫斯基、切比雪夫
混合矩阵:两个样本a、b(一般只有布尔属性)中,枚举所有属性,统计a=0/1且b=0/1的个数,写成矩阵形式
样本匹配距离:
(n01+n10)/(n00+n01+n10+n11)(简单匹配距离)(对称布尔属性,两类别概念对称)
(n01+n10)/(n01+n10+n11) (Jaccard距离)(当状态1出现较少时,非对称布尔属性)
推广:不匹配数/总数
相似度衡量:
向量夹角余弦相似度a·b/(|a||b|)
数据标准化:
范围标准化:把数据限制到[0,1]
Z-score:(x-μ)/s,这里s是所有样本到均值的绝对值的平均数,不是标准差σ
各类数据的通用处理方式:
比例度量属性,将非线性的数据进行线性化后,再进行处理
符号属性(标签)->转换为独热编码
顺序属性->连续化,作为连续属性处理
混合属性->找一个主导全部转换过去 || 所有一起做加权平均
聚类评估:
使用一组有标签的数据,利用训练好的聚类模型对其进行分类,评判各个类下的信息熵、纯度、SSE、中心间差异、混淆矩阵(就是多分类评价的那一套AUC、 Acc、 Precision、 Recall、 F1)
---------------------------------------------
基于实例的学习
KNN找最邻近的k个点,KD树实现
优化:对距离进行加权,使用全部样本进行查询
维度灾难:降维,(x,y)->x+ky或者y+kx,然后选取最佳的k(把分类问题维度转换为优化维度),剔除无关属性(留一法,去除一个观察效果),坐标轴伸展
KNN分类与回归
局部加权线性回归
(取局部进行拟合、取全局进行加权、取局部进行加权拟合)
径向基函数RBF
把加权的函数换成高斯函数
每个邻域中的参考值x,都需要对应一个核函数
消极学习:KNN和局部加权线性回归
积极学习:RBF(需要训练,损失函数为训练集中的每个数据预测的平方误差)
关于积极学习和消极学习还可以参考以下博客:
https://blog.csdn.net/m0_38103546/article/details/81229290
---------------------------------------------
回归学习
线性回归
最小二乘法h(x) = w0+w1x1+...+wnxn=W·X
W = (Xt*X)^(-1)*Xt*y
(作业)使用梯度下降推导线性回归、逻辑回归、softmax回归
逻辑回归就是在线性回归的输出加入一个sigmoid,采用交叉熵
sofmax回归就是多个线性回归的基础上,把所有输出加一个softmax操作,采用交叉熵
正则化
应该主要考梯度计算
---------------------------------------------
线性分类器
线性判别函数(分类时计算量小,比朴素贝叶斯快,但错误率可能更高)
线性可分与线性不可分
SVM证明(略)
线性多分类器的建立
一对其余:wi/wi'法
一条边界划分某一个类和其余类
时间复杂度O(cls_num)
存在不确定区域
一对一:wi/wj法
任意两个类之间都有边界划分
时间复杂度O(cls_num^2)
存在不确定区域
但比wi/wi'更容易线性可分
多对多:
同时求解cls_num个线性函数,将他们的最大值作为分类结果
不存在不确定区
一般采用这种方案
最小距离准则
分完类之后,查询x与各类均值点的距离,最小的就是最近的
可证明也是一种线性分类器(在采用欧氏距离时)
但分类效果不理想
感知器准则
样本规范化:
x->增广(1,x1,x2,x3)->把负类进行取相反向量
这样目的就转换为,找一个平面,使得所有点都在一侧
解区:能正确分割两类数据的w向量(分割面的法向量)取值范围,越大说明解越可靠
有了解区,我们就可以进一步限制线性分类器的精度,使用余量来控制法向量的范围
感知器准则函数
求和所有错误分类的计算结果 Σ-wTx,记为Jp(w),最小化该值
假设所有样本都正确分类(或在边界上),则Jp(w)=0,否则该值会大于0
然后我们就可以愉快地求dJp(w)/dw的偏导,进行梯度下降,直到错误分类集合为空,停止。
而这个偏导恰好等于Σ-x,也就是所有错误分类的向量之和
我们把它乘以学习率,然后叠加到w上,就可以使用梯度下降训练线性分类器了
*但是,这个方法只适用于线性可分的情况,不可分的话则永远不会停止
最小平方误差准则(SVM使用的准则)
X增广且规范化之后
Xw=b
根据一系列推导,最优MSE的w解为(Xt*X)^(-1)*Xt*b(Xt表示X的转置)
但由于计算量较大,Xt*X可能不可逆,因此实践中并不采用
Widrow-Hoff算法:
发现,如果将梯度下降的步骤增量改为:w_{k+1}=w_{k}-ρk*Xt*(X*w_{k}-b)
并且取ρk=ρ1/k,无论Xt*X是否可逆,w均能收敛到一个很好的解
---------------------------------------------
特征选择与稀疏学习
贪心选择特征子集:
前向搜索,一轮一轮的选,看当前加入哪个特征最优就选哪个
后向搜索,看当前哪个特征拿走后变得更优就删除哪个特征
双向搜索,结合上述两种,直到找到一个公共元素
选出来的特征子集的评价手段:
信息增益等指标
三类特征选择方法
过滤式
relief算法,调整每个特征的权重
每次随机一个样本x,找到最近的同类样本a和最近的不同类样本b,调大(a-x)中小于(b-x)的特征权重,调小(a-x)中大于(b-x)的特征权重。
relief-F,推广到多分类问题,假设类别有k类,每次找1个同类邻近和k-1个不同类邻近样本(每个类都找一个最近的),最后根据每个类别的样本占比加权进行权重调整
包裹式
LVW算法
直接随机特征子集,然后训练,交叉验证,评估
多次取最优的。(怪不得叫Las Vegas Wrapper)
嵌入式选择
把特征选择和学习器训练融为一体,学习器自动选择特征
稀疏表示(行表示样本、列表示属性)???
字典学习
对一个数据集X
学习字典B和表示α
最小化 Σ|x-Bα|^2+λΣ|α|
有点意思,就是纯将数据集的特征进行变换,并且使得变换后的属性比较稀疏
相关文章:
)
机器学习课程总结(个人向)
前言 通过看课件PPT整理的笔记,没有截图 由于大部分内容已经耳熟能详了,故记录比较简略,只记录了一些概念和需要记忆的地方。 里面有较多的个人观点,未必正确。如有错误,还请各位大佬指正 正文 绪论 机器学习的定…...

数据分析-43-时间序列预测之深度学习方法GRU
文章目录 1 时间序列1.1 时间序列特点1.1.1 原始信号1.1.2 趋势1.1.3 季节性和周期性1.1.4 噪声1.2 时间序列预测方法1.2.1 统计方法1.2.2 机器学习方法1.2.3 深度学习方法2 GRU2.1 模拟数据2.2 数据归一化2.3 生成滞后特征2.4 切分训练集和测试集2.5 模型训练2.6 模型预测3 参…...

Pandas | 数据分析时将特定列转换为数字类型 float64 或 int64的方法
类型转换 传统方法astype使用value_counts统计通过apply替换并使用astype转换 pd.to_numericx对连续变量进行转化⭐参数:返回值:示例代码: isnull不会检查空字符串 数据准备 有一组数据信息如下,其中主要将TotalCharges、MonthlyC…...
Elasticsearch的自定义查询方法到底是啥?
Elasticsearch主要的目的就是查询,默认提供的查询方法是查询全部,不满足我们的需求,可以定义查询方法 自定义查询方法 单条件查询 我们查询的需求:从title中查询所有包含"鼠标"这个分词的商品数据 SELECT * FROM it…...

Jenkins找不到maven构建项目
有的可能没有出现maven这个选项 解决办法:需要安装Maven项目插件 输入Maven Integration plugin...

怎么更换IP地址 改变IP归属地的三种方法
要更换自己的IP地址,您可以按照以下步骤进行操作: 1. 了解IP地址类型:首先,您需要了解您当前使用的IP地址类型。IP地址分为静态IP和动态IP两种。静态IP地址是固定的,使用第三方软件比如S深度IP转换器;而使用…...

C#-异步查询示例
文章速览 CancellationTokenSource 概述代码示例 坚持记录实属不易,希望友善多金的码友能够随手点一个赞。 共同创建氛围更加良好的开发者社区! 谢谢~ CancellationTokenSource 概述 使用System.Threading下的CancellationTokenSource类,进…...

设计模式之适配器模式(从多个MQ消息体中,抽取指定字段值场景)
前言 工作到3年左右很大一部分程序员都想提升自己的技术栈,开始尝试去阅读一些源码,例如Spring、Mybaits、Dubbo等,但读着读着发现越来越难懂,一会从这过来一会跑到那去。甚至怀疑自己技术太差,慢慢也就不愿意再触碰这…...

vue+exceljs前端下载、导出xlsx文件
首先安装插件 npm install exceljs file-saver第一种 简单导出 //页面引入 import ExcelJS from exceljs; import {saveAs} from file-saver; export default {methods: { /** 导出操作 */async handleExportFun() {let that this// 获取当前年月日 用户下载xlsx的文件名称设…...

算法定制LiteAIServer摄像机实时接入分析平台烟火检测算法的主要功能
在现代社会,随着人工智能技术的飞速发展,智能监控系统在公共安全领域的应用日益广泛。其中,烟火检测作为预防火灾的重要手段,其准确性和实时性对于减少火灾损失、保障人民生命财产安全具有重要意义。而算法定制LiteAIServer烟火检…...

用 Python 从零开始创建神经网络(二)
用 Python 从零开始创建神经网络(二) 引言1. Tensors, Arrays and Vectors:2. Dot Product and Vector Additiona. Dot Product (点积)b. Vector Addition (向量加法) 3. A Single Neuron with …...

嘉吉连续第七年亮相进博会
以“新质绿动,共赢未来”为主题,嘉吉连续第七年亮相进博会舞台。嘉吉带来了超过120款产品与解决方案,展示嘉吉在农业、食品、金融和工业等领域以客户为中心的创新成果。这些产品融合了嘉吉在相关领域的前瞻性思考,以及对本土市场的…...

设计模式之单列模式(7种单例模式案例,Effective Java 作者推荐枚举单例模式)
前言 在设计模式中按照不同的处理方式共包含三大类;创建型模式、结构型模式和行为模式,其中创建型模式目前已经介绍了其中的四个;工厂方法模式、抽象工厂模式、生成器模式和原型模式,除此之外还有最后一个单例模式。 单列模式介绍…...

多个服务器共享同一个Redis Cluster集群,并且可以使用Redisson分布式锁
Redisson 是一个高级的 Redis 客户端,它支持多种分布式 Java 对象和服务。其中之一就是分布式锁(RLock),它可以跨多个应用实例在多个服务器上使用同一个 Redis 集群,为这些实例提供锁服务。 当你在不同服务器上运行的…...

100种算法【Python版】第59篇——滤波算法之扩展卡尔曼滤波
本文目录 1 算法步骤2 算法示例2.1 示例描述2.2 python代码3 算法应用:机器人位姿估计扩展卡尔曼滤波(EKF)是一种处理非线性系统的状态估计算法。它通过线性化非线性系统来实现类似于线性卡尔曼滤波的效果。 1 算法步骤 (1)初始化 初始状态: x ^ 0 ∣ 0 \hat{x}_{0|0}...

制造业数字化转型的强大赋能平台:盘古信息IMS OS工软技术底座
在制造业数字化转型的浪潮中,技术底座的选择与实施至关重要。它不仅决定了企业数字化转型的深度与广度,还影响着企业的生产效率、成本控制和市场竞争力。盘古信息IMS OS作为一款强大的工软技术底座,凭借其高度模块化、可配置的设计理念&#…...

域名+服务器+Nginx+宝塔使用SSL证书配置HTTPS
前言 在我的前面文章里,有写过一篇文章 linux服务器宝塔从头部署别人可访问的网站 在这篇文章,有教学怎么使用宝塔和买的服务器的公网IP,以及教怎么打包vue和springboot去部署不用域名的网站让别人访问 那么,这篇文章将在这个…...
UnityAssetsBundle字体优化解决方案
Unity开发某个项目,打包后的apk包体已经高达1.25G了,这是非常离谱的。为了不影响用户体验,需要将apk包体缩小。因为项目本身不包含很多模型以及其他大型资源,排除法将AB包删除,发现app本身就100多M。 由此可以锁定是AB…...
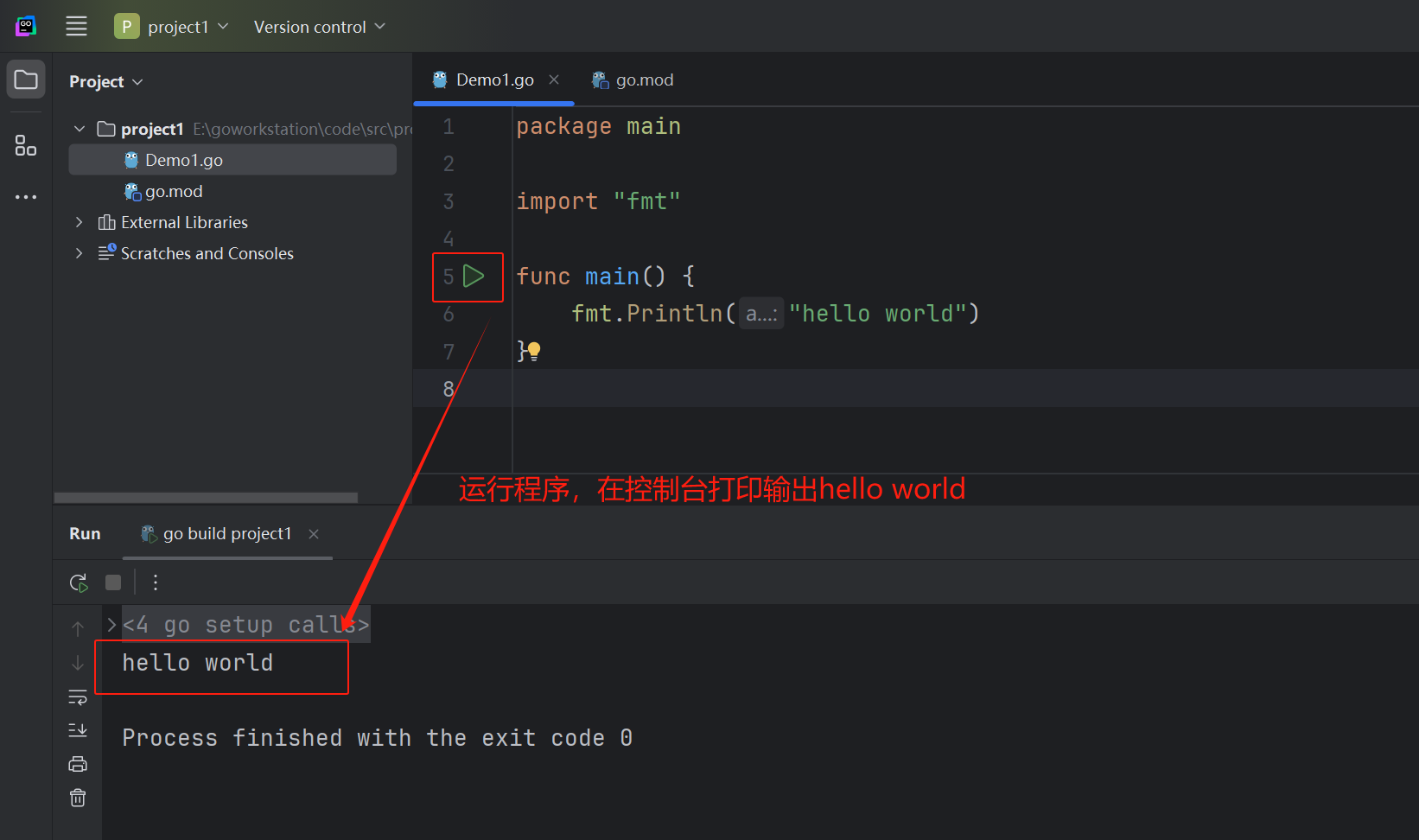
Go的环境搭建以及GoLand安装教程
目录 一、开发环境Golang安装 二、配置环境变量 三、GoLand安装 四、Go 语言的 Hello World 一、开发环境Golang安装 官方网址: The Go Programming Language 1. 首先进入官网,点击Download,选择版本并进行下载: 2. …...

git clone,用https还是ssh
前言 在使用Git去克隆项目时,会遇到https和ssh等形式,这两种又有何种区别呢,本文将重点讨论在具体使用中的问题。 注:第一次使用Git 时,需要先设置全局用户名和邮箱,否则后续使用命令时会报错,也是提醒先添…...

UE5 学习系列(二)用户操作界面及介绍
这篇博客是 UE5 学习系列博客的第二篇,在第一篇的基础上展开这篇内容。博客参考的 B 站视频资料和第一篇的链接如下: 【Note】:如果你已经完成安装等操作,可以只执行第一篇博客中 2. 新建一个空白游戏项目 章节操作,重…...

线程同步:确保多线程程序的安全与高效!
全文目录: 开篇语前序前言第一部分:线程同步的概念与问题1.1 线程同步的概念1.2 线程同步的问题1.3 线程同步的解决方案 第二部分:synchronized关键字的使用2.1 使用 synchronized修饰方法2.2 使用 synchronized修饰代码块 第三部分ÿ…...

蓝桥杯 2024 15届国赛 A组 儿童节快乐
P10576 [蓝桥杯 2024 国 A] 儿童节快乐 题目描述 五彩斑斓的气球在蓝天下悠然飘荡,轻快的音乐在耳边持续回荡,小朋友们手牵着手一同畅快欢笑。在这样一片安乐祥和的氛围下,六一来了。 今天是六一儿童节,小蓝老师为了让大家在节…...

React Native在HarmonyOS 5.0阅读类应用开发中的实践
一、技术选型背景 随着HarmonyOS 5.0对Web兼容层的增强,React Native作为跨平台框架可通过重新编译ArkTS组件实现85%以上的代码复用率。阅读类应用具有UI复杂度低、数据流清晰的特点。 二、核心实现方案 1. 环境配置 (1)使用React Native…...

MMaDA: Multimodal Large Diffusion Language Models
CODE : https://github.com/Gen-Verse/MMaDA Abstract 我们介绍了一种新型的多模态扩散基础模型MMaDA,它被设计用于在文本推理、多模态理解和文本到图像生成等不同领域实现卓越的性能。该方法的特点是三个关键创新:(i) MMaDA采用统一的扩散架构…...
)
python爬虫:Newspaper3k 的详细使用(好用的新闻网站文章抓取和解析的Python库)
更多内容请见: 爬虫和逆向教程-专栏介绍和目录 文章目录 一、Newspaper3k 概述1.1 Newspaper3k 介绍1.2 主要功能1.3 典型应用场景1.4 安装二、基本用法2.2 提取单篇文章的内容2.2 处理多篇文档三、高级选项3.1 自定义配置3.2 分析文章情感四、实战案例4.1 构建新闻摘要聚合器…...

有限自动机到正规文法转换器v1.0
1 项目简介 这是一个功能强大的有限自动机(Finite Automaton, FA)到正规文法(Regular Grammar)转换器,它配备了一个直观且完整的图形用户界面,使用户能够轻松地进行操作和观察。该程序基于编译原理中的经典…...

接口自动化测试:HttpRunner基础
相关文档 HttpRunner V3.x中文文档 HttpRunner 用户指南 使用HttpRunner 3.x实现接口自动化测试 HttpRunner介绍 HttpRunner 是一个开源的 API 测试工具,支持 HTTP(S)/HTTP2/WebSocket/RPC 等网络协议,涵盖接口测试、性能测试、数字体验监测等测试类型…...

从 GreenPlum 到镜舟数据库:杭银消费金融湖仓一体转型实践
作者:吴岐诗,杭银消费金融大数据应用开发工程师 本文整理自杭银消费金融大数据应用开发工程师在StarRocks Summit Asia 2024的分享 引言:融合数据湖与数仓的创新之路 在数字金融时代,数据已成为金融机构的核心竞争力。杭银消费金…...

Spring Security 认证流程——补充
一、认证流程概述 Spring Security 的认证流程基于 过滤器链(Filter Chain),核心组件包括 UsernamePasswordAuthenticationFilter、AuthenticationManager、UserDetailsService 等。整个流程可分为以下步骤: 用户提交登录请求拦…...