深度学习-图像评分实验(TensorFlow框架运用、读取处理图片、模型建构)
目录
0、实验准备
①实验环境
②需要下载的安装包
③注意事项(很关键,否则后面内容看不懂)
④容易出现的问题
1、查看数据并读取数据。
2、PIL库里的Image包进行读取(.resize更改图片尺寸,并将原始数据归一化处理,用索引方式进行提取)
3、切分实验数据集(train_test_split进行切分)
4、线性回归构建模型。(Dense、Flatten、Input和Model模块。利用Model类方法构建模型)
5、模型编译。利用keras的compile实现编译过程
6、模型拟合。利用fit进行拟合,并观察循环过程中,参数的变化
7、模型预测。利用predict使用训练好的模型在未知的数据上做预测,得到一个预测值
8、绘制损失函数曲线变化图
9、完整代码
0、实验准备
①实验环境
python3.7.4
Spyder(anaconda3.7)
下载链接:anaconda3.7安装(清华开源软件镜像)
因为有些安装包有版本要求,最好直接下载anaconda3.7版本的Spyder直接使用。

②需要下载的安装包
一定下载安装包哈,不然运行会报错哦。

conda install pandas numpy pillow scikit-learn keras matplotlib③注意事项(很关键,否则后面内容看不懂)
→本文提到的X变量代表各种美食图像,因变量Y表示每张图片的评分。(图片数据可以大家自己去网上找,也可以使用我给大家分享的图片材料哈,注意要改文件地址【最好全是英语命名,不要有中文,否则可能会有报错】)
→需要下载一个Y数据文件:
通过百度网盘分享的文件:实验数据(图片材料+Y数据csv文件)
链接:https://pan.baidu.com/s/1xksDeusttovDfs2ncMYOcA?pwd=6688
提取码:6688

④容易出现的问题
有些下载可能会出一点问题:版本不兼容(所以建议大家直接下载anaconda3.7,因为这个是兼容scikit-learn包的,大部分不兼容这个)、找不到文件(改文件路径!!!不要有中文!!!)
1、查看X、Y数据并读取X、Y数据。

2、针对X图片数据,利用PIL库里的Image包进行读取。利用.resize更改图片尺寸,并将原始数据归一化处理。针对Y数值数据,用索引方式进行提取。


3、切分实验数据集。利用train_test_split进行切分。

4、线性回归构建模型。用到的模块:Dense、Flatten、Input和Model模块。利用Model类方法构建模型。

5、模型编译。利用keras的compile实现编译过程。注意:三种参数值的设定。

6、模型拟合。利用fit进行拟合,并观察循环过程中,参数的变化。(这个最好多模拟几次,不低于六次,不然精确度不高)



7、模型预测。利用predict使用训练好的模型在未知的数据上做预测,得到一个预测值。

8、绘制损失函数曲线变化图。

9、完整代码
import pandas as pd
MasterFile=pd.read_csv("E:\All_demo\DEEp\FoodScore.csv")
print(MasterFile.shape)
MasterFile[0:5]
MasterFile.hist()import numpy as np
FileNames=MasterFile['ID']
N=len(FileNames)
Y=np.array(MasterFile['score']).reshape([N,1])from PIL import Image
IMSIZE=128
X=np.zeros([N,IMSIZE,IMSIZE,3])
for i in range(N): MyFile=FileNames[i]Im=Image.open(r'E:\All_demo\DEEp\data_foodscore/'+MyFile+'.jpg')Im=Im.resize([IMSIZE,IMSIZE])Im=np.array(Im)/255X[i,]=Imfrom matplotlib import pyplot as plt
plt.figure()
fig,ax=plt.subplots(2,5)
fig.set_figheight(7.5)
fig.set_figheight(15)
ax=ax.flatten()
for i in range(10):ax[i].imshow(X[i,:,:,:])ax[i].set_title(np.round(Y[i],2))from sklearn.model_selection import train_test_split
X0,X1,Y0,Y1=train_test_split(X,Y,test_size=0.5,random_state=0)from keras.layers import Dense,Flatten,Input
from keras import Model
input_layer=Input([IMSIZE,IMSIZE,3])
x=input_layer
x=Flatten()(x)
x=Dense(1)(x)
output_layer=x
model=Model(input_layer,output_layer)
model.summary()from keras.optimizers import Adam
model.compile(loss='mse',optimizer=Adam(lr=0.001),metrics=['mse'])history=model.fit(X0,Y0,validation_data=[X1,Y1],batch_size=100,epochs=100)MyPic=Image.open("E:\All_demo\DEEp\data_foodscore\pic1.jpg")
MyPic
MyPic=MyPic.resize((IMSIZE,IMSIZE))
MyPic=np.array(MyPic)/255
MyPic=MyPic.reshape((1,IMSIZE,IMSIZE,3))
model.predict(MyPic)import matplotlib.pyplot as plt
plt.plot(history.history['loss'], label='train loss')
plt.plot(history.history['val_loss'], label='validation loss')
plt.title('Model Loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend()
plt.show()
相关文章:
深度学习-图像评分实验(TensorFlow框架运用、读取处理图片、模型建构)
目录 0、实验准备 ①实验环境 ②需要下载的安装包 ③注意事项(很关键,否则后面内容看不懂) ④容易出现的问题 1、查看数据并读取数据。 2、PIL库里的Image包进行读取(.resize更改图片尺寸,并将原始数据归一化处…...

羲和数据集收集器0.9
为了进一步完善代码,增强其文字抓取能力和文件读取能力,我们做以下改进: 增强 DOCX 文档的文本提取:不仅提取段落和文本框内容,还提取表格中的文本。 增强 PDF 文档的文本提取:不仅提取页面文本和注释,还提取表格中的文本。 优化文本清理:确保文本清理更加彻底,避免不…...

哈尔滨等保测评常见误区破解:避免陷入安全盲区
在当今信息化社会,网络安全已成为各行各业不可忽视的重要议题。等级保护(简称“等保”)作为我国网络安全的基本制度,旨在通过划分不同安全保护等级,对信息系统实施分等级的安全保护。然而,在实施等保测评的…...

Python学习------第四天
Python的判断语句 一、布尔类型和比较运算符 二、 if语句的基本格式 if语句注意空格缩进!!! if else python判断语句的嵌套用法:...

【Django】配置文件 settings.py
【Django】配置文件 settings.py 和Flask框架不同,Django框架项目在创建的时会默认生成配置文件settings.py,在深入学习Django框架前,我们先简单了解settings.py文件内非注释代码, from pathlib import Path BASE_DIR Path(__f…...

量化交易系统开发-实时行情自动化交易-Okex K线数据
19年创业做过一年的量化交易但没有成功,作为交易系统的开发人员积累了一些经验,最近想重新研究交易系统,一边整理一边写出来一些思考供大家参考,也希望跟做量化的朋友有更多的交流和合作。 接下来聊聊基于Okex交易所API获取K线数…...

【基于轻量型架构的WEB开发】课程 12.5 数据回写 Java EE企业级应用开发教程 Spring+SpringMVC+MyBatis
12.5 数据回写 12.5.1 普通字符串的回写 接下来通过HttpServletResponse输出数据的案例,演示普通字符串的回写,案例具体实现步骤如下。 1 创建一个数据回写类DataController,在DataController类中定义 showDataByResponse()方法ÿ…...

apache-seata-2.1.0 AT模式使用篇(配置简单)
最近在研究seata的AT模式,先在本地搭建了一个演示demo,看看seata是如何使用的。在网上搜的demo,配置相对来说都比较多。我最终搭建的版本,配置较少,所以写篇文章分享下,希望能帮到对seata感兴趣的小伙伴。先…...

(金蝶云星空)客户端追踪SQL
快捷键 ShitfCtryAltM 点击开始、最后操作功能、然后查看报告 SQL报告...

OAK相机:纯视觉SLAM在夜晚的应用
哈喽,OAK的朋友们,大家好啊,今天这个视频主要想分享一下袁博士团队用我们的OAK相机产出的新成果 在去年过山车SLAM的演示中,袁博士团队就展示了纯视觉SLAM在完全黑暗的环境中的极高鲁棒性。 现在袁博士团队进一步挖掘了纯视觉的潜…...

发送方确认
在使用RabbitMQ的时候,可以通过消息持久化来解决因为服务器的异常而导致的消息就是,但是还有一个问题,当消息的生产者将消息发送出去之后,消息到底有没有正确地到达服务器呢?如果消息在到达服务器之前已经丢失…...

如何使用HighBuilder前端开发神器
一,前言 前端开发是网页和应用程序设计与开发中的一个重要分支,直接涉及用户界面的构建和用户与网页的交互。前端是用户在浏览器中看到的部分,负责为用户提供良好的体验。 二,前段介绍 1. 前端的组成 前端开发主要由三个核心技…...

发现了NitroShare的一个bug
NitroShare 是一个跨平台的局域网开源网络文件传输应用程序,它利用广播发现机制在本地网络中找到其他安装了 NitroShare 的设备,从而实现这些设备之间的文件和文件夹发送。 NitroShare 支持 Windows、macOS 和 Linux 操作系统。 NitroShare允许我们为…...
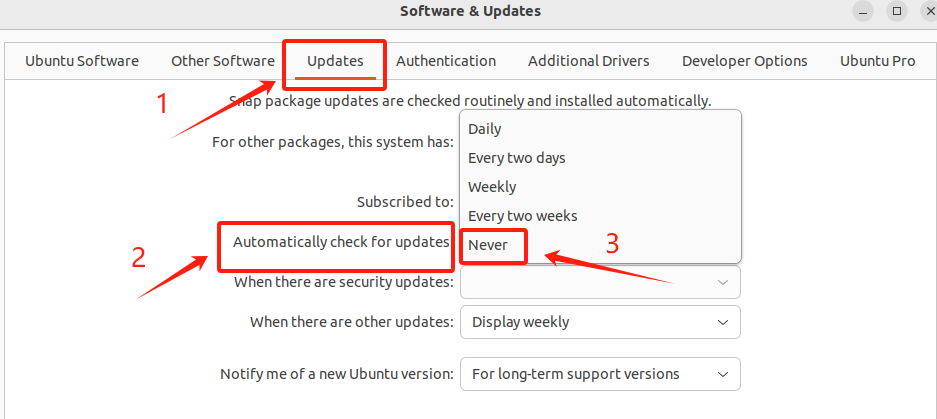
如何关闭 Ubuntu22.04 LTS 的更新提醒
引言 众所周知,Ubuntu 的软件更新和版本更新提醒是又多又烦,如果不小心更新到了最新的 Ubuntu 还可能面临各种各样的问题,这里提供一个解决方法 步骤 首先按照下面步骤打开 Software & Updates 然后按照下面步骤依次点击 最后关闭即可…...

美术资源规范
很多项目都没有重视资源规范,而是不断追求更高的运行效率。然而资源规范在项目中是非常重要的,资源规范才是高效运行的前提。 在有的项目中,一个人物模型几万个面、一个建筑模型就几十万个面,贴图也不规范,1024、2048…...

UE5.4 PCG 获取地形Layer
使用AttributeFilter:属性过滤器 节点 设置地形Layer名称和权重 效果:...

用 cURL 控制 OpenSIPS3.4
opensips-cli -x mi reload_routes,重读脚本路由opensips-cli -x mi ds_list,就是 dispatcher list 的缩写,简单明了opensips-cli -x mi ds_reload,修改 OpenSIPS 数据库的 dispatcher 表之后,用此命令读到内存opensip…...

【LuatOS】基于WebSocket的同步请求框架
0x00 缘起 由于使用LuatOS PC模拟器发起快速且海量HTTP请求(1000 次/秒)时,会耗尽PC的TCP连接资源,而无法进行继续进行访问请求。故使用WebSocket搭建类似于HTTP的“同步请求相应”的通信框架,以实现与HTTP类似的功能…...
论文专题:信息系统安全设计)
架构师考试系列(8)论文专题:信息系统安全设计
摘要 2021年4月,我公司承接了一款健康养老系统项目,旨在提供以健康养老为核心的管理平台。本文探讨了如何在系统开发中贯彻安全优先原则,保障系统的安全性和保密性。系统包括健康档案、照护计划、服务审计、健康状况跟踪、费用管理等功能模块。我作为系统架构设计师,负责了…...

浙大一附院就医:分享给大家工作久了关节疼的就医经验,腱鞘炎
症状描述:日常生活不影响,但左手手腕往前或者往后扭曲力度过大时会有痛感。 医嘱详情:腱鞘炎,可能是工作键盘打字久了导致,开了三盒药贴,一盒三片,一共9片,另外再买一个比较硬的护腕…...

网络六边形受到攻击
大家读完觉得有帮助记得关注和点赞!!! 抽象 现代智能交通系统 (ITS) 的一个关键要求是能够以安全、可靠和匿名的方式从互联车辆和移动设备收集地理参考数据。Nexagon 协议建立在 IETF 定位器/ID 分离协议 (…...

多模态2025:技术路线“神仙打架”,视频生成冲上云霄
文|魏琳华 编|王一粟 一场大会,聚集了中国多模态大模型的“半壁江山”。 智源大会2025为期两天的论坛中,汇集了学界、创业公司和大厂等三方的热门选手,关于多模态的集中讨论达到了前所未有的热度。其中,…...

超短脉冲激光自聚焦效应
前言与目录 强激光引起自聚焦效应机理 超短脉冲激光在脆性材料内部加工时引起的自聚焦效应,这是一种非线性光学现象,主要涉及光学克尔效应和材料的非线性光学特性。 自聚焦效应可以产生局部的强光场,对材料产生非线性响应,可能…...
)
React Native 开发环境搭建(全平台详解)
React Native 开发环境搭建(全平台详解) 在开始使用 React Native 开发移动应用之前,正确设置开发环境是至关重要的一步。本文将为你提供一份全面的指南,涵盖 macOS 和 Windows 平台的配置步骤,如何在 Android 和 iOS…...

从WWDC看苹果产品发展的规律
WWDC 是苹果公司一年一度面向全球开发者的盛会,其主题演讲展现了苹果在产品设计、技术路线、用户体验和生态系统构建上的核心理念与演进脉络。我们借助 ChatGPT Deep Research 工具,对过去十年 WWDC 主题演讲内容进行了系统化分析,形成了这份…...

在鸿蒙HarmonyOS 5中实现抖音风格的点赞功能
下面我将详细介绍如何使用HarmonyOS SDK在HarmonyOS 5中实现类似抖音的点赞功能,包括动画效果、数据同步和交互优化。 1. 基础点赞功能实现 1.1 创建数据模型 // VideoModel.ets export class VideoModel {id: string "";title: string ""…...

Frozen-Flask :将 Flask 应用“冻结”为静态文件
Frozen-Flask 是一个用于将 Flask 应用“冻结”为静态文件的 Python 扩展。它的核心用途是:将一个 Flask Web 应用生成成纯静态 HTML 文件,从而可以部署到静态网站托管服务上,如 GitHub Pages、Netlify 或任何支持静态文件的网站服务器。 &am…...

使用Spring AI和MCP协议构建图片搜索服务
目录 使用Spring AI和MCP协议构建图片搜索服务 引言 技术栈概览 项目架构设计 架构图 服务端开发 1. 创建Spring Boot项目 2. 实现图片搜索工具 3. 配置传输模式 Stdio模式(本地调用) SSE模式(远程调用) 4. 注册工具提…...
HybridVLA——让单一LLM同时具备扩散和自回归动作预测能力:训练时既扩散也回归,但推理时则扩散
前言 如上一篇文章《dexcap升级版之DexWild》中的前言部分所说,在叠衣服的过程中,我会带着团队对比各种模型、方法、策略,毕竟针对各个场景始终寻找更优的解决方案,是我个人和我司「七月在线」的职责之一 且个人认为,…...

Linux--vsFTP配置篇
一、vsFTP 简介 vsftpd(Very Secure FTP Daemon)是 Linux 下常用的 FTP 服务程序,具有安全性高、效率高和稳定性好等特点。支持匿名访问、本地用户登录、虚拟用户等多种认证方式,并可灵活控制权限。 二、安装与启动 1. 检查是否已…...