指标+AI+BI:构建数据分析新范式丨2024袋鼠云秋季发布会回顾
10月30日,袋鼠云成功举办了以“AI驱动,数智未来”为主题的2024年秋季发布会。大会深度探讨了如何凭借 AI 实现新的飞跃,重塑企业的经营管理方式,加速数智化进程。
作为大会的重要环节之一,袋鼠云数栈产品经理潮汐带来了题为《指标+AI+BI:构建数据分析新范式》的精彩演讲,深入剖析了当前企业在进行数据分析时所面临的挑战,并分享了袋鼠云数栈在此领域内的最新成果和解决方案。
一、传统数据分析方案的局限性
会议伊始,潮汐首先回顾了传统数据分析方案的架构。传统方案通常采用“数仓+BI”的方式,即业务方提出数据需求后,经过数据产品经理的分析和排期,由数据开发人员将数据从业务系统中统一抽取到数仓进行分层加工。加工后的表吐出到业务库,由BI分析师在BI工具中进行数据接入、数据模型搭建,并基于这些模型通过组件配置和分析交互设置形成数据报表。最终,业务方可以直接通过这些报表共享或嵌入到业务系统中来进行数据分析与监控。

然而,这种模式存在几个显著的问题:
高成本与长周期:BI工具往往具有一定的上手门槛,对于不熟悉技术或工具的业务用户来说,很难深入使用。复杂的分析任务严重依赖于数据开发人员和分析师的专业技能,导致需求交付时间周期长,沟通调整的成本也随之增加。
数据一致性难以保证:传统的BI工具是一个封闭且中心化的平台,其中的数据模型定义(包括度量和维度)与其他数据应用之间缺乏互通性。所有数据分析活动都必须在这个平台上完成,这造成了跨应用分析时指标管理不统一、口径不一致以及流程不规范的问题。虽然很多企业在数仓层面实现了统一的数据管理和开发,但在应用层面仍然面临着“烟囱式”开发的困境。
灵活性不足:基于传统BI工具的数据分析很大程度上依赖于分析师在创建报表时预先设定好的图表类型、交互方式及分析配置。这意味着,在不同场景下分析数据波动的原因时往往没有办法直观快速地得到结论。
因此,当前的市场环境下,企业需要一种更高效、低成本的数据分析方案。
二、指标+AI,赋能数据分析
针对上述痛点,潮汐介绍了当前较为流行且有效的解决方案:在数仓和BI中间架设配备AI能力的指标层。

数仓处理后的数据在指标层进行统一的数据模型构建,生成原子指标、派生指标、复合指标和衍生指标。这些指标成为后续包括BI在内的所有上层数据应用的基础。基于这种架构,数据分析不仅兼容传统BI工具,还衍生出更智能灵活的方式,如指标数据智能问答和将指标封装成API对业务系统提供即时数据分析服务(即Headless BI)。这样的架构总共有四个方面的优点:
缩短开发链路:指标体系消除了数据结果的二义性问题,不同业务使用同一指标时无需重复开发或校对口径,从而大大缩短了整体开发链路。
轻量级数据分析:通过指标API,可以将数据分析结果轻松集成到任意业务系统中,使业务端能够以轻量级方式实现个性化的数据分析。
实现快速决策:在AI的辅助下结合行业和企业知识库可以对数据异常情况进行快速精准的定位,帮助业务方缩短问题排查链路,加速决策过程。
低门槛使用:Headless BI几乎零门槛,适用于大多数不太复杂的分析场景,让业务方能够主动愿意形成业务分析与数据决策的习惯,让数据价值更加普及。
三、从指标设计到数据分析实践全流程
从对新数据分析方案的架构及优势分析中,可以看出指标体系的搭建是其中最为关键的一环。袋鼠云之前接触到的很多企业客户其实都已经做过指标体系搭建的尝试,但是实践下来碰到很多问题,如指标管理成本高、重复建设、流程不规范等。
针对这些问题,袋鼠云数栈提出了完整的解决方案,基于该解决方案,企业可以构建一套从规范建立到数据分析应用的完整流程。

|01 指标管理规范的建立
首先,在企业内部需构建指标管理与加工的流程制度及组织规范,指标管理规范主要包括指标生命周期管理、指标层次与分类管理、指标定义标准化及指标使用管理规范。
指标全生命周期需要确保从业务方提出需求开始,到指标下线的全过程得到有效管控,整个流程每个环节需要定义好输入输出物和负责人员。
接下来是指标层次与分类管理,根据企业战略目标、组织及业务进行自上而下的指标分级,可以分为三个等级,指标类型可以按加工方式和程度分为原子指标、派生指标、衍生指标、复合指标和自定义指标,通过多种类型指标的定义,构建起有序的指标体系。
然后是指标元数据的定义,指标元数据一般包括指标名称、编码、所属业务目录、计算频度、计量单位、负责人、业务口径等信息,定义好每种元数据的填写要求规范,发布前专人审核确保不出现定义内容不准确或不清晰的情况。
最后是指标使用管理,设置公司内指标共享和权限管理机制,让指标的使用更加合规安全。

|02 指标开发
在建立规范后,我们来关注指标的开发过程。

首先是业务分析。指标管理方要在了解业务的基础上分析需求、拆解指标主题和分类。以零售行业为例,其数据围绕人、货、场展开,通过调研人员、盘点场景,可划分员工销售、采购库存、采购供应商等主题,在这些主题下再细分指标,如员工管理主题下有员工流失率、成效率,销售价格体系中有销售金额、销售利润,由此梳理出存量指标和指标缺口。
指标缺口确定后,开发人员开始工作。比如开发统计各城市在微信和支付宝近 7 日电商业务销售金额的指标时,先创建电商订单数据模型,找到主表订单表及关联表,生成电商业务销售明细原子指标(计算逻辑是订单金额求和,存于电商产品目录下),再由此生成各城市电商销售额派生指标(派生维度为城市和商品类型、时间维度为近 7 天、业务限定为微信和支付宝渠道),配置好离线任务的调度周期和上游依赖,指标数据就可定时产出。

|03 指标应用
指标完成开发及数据产出后就到了最关键的一环——指标的应用。袋鼠云指标管理平台已将 AI 深度融入指标多方面多层次的应用中。在介绍应用前,先看 AI 基础能力是如何搭建的。数栈有自己的AI平台,负责所有产品模块中AI能力的搭建,AI 平台支持多种主流大模型部署,并对接行业和企业知识库,结合指标平台业务库的指标属性、指标血源等元数据构成了大模型的数据基础,然后我们就可以在AI平台上搭建应用工作流,来定制指标AI应用。
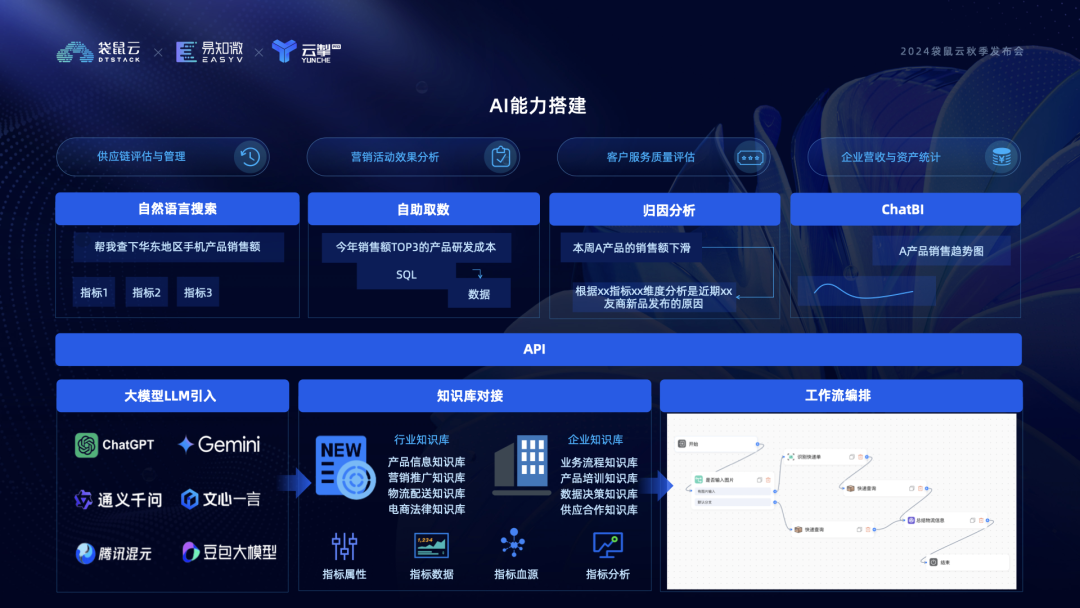
目前主要实现的是基于自然语言的指标搜索、自然语言转化SQL进行自助取数、指标异常归因分析以及指标智能问答及图表分析这4个方面。
一是智能分析。可以在指标取数模块中输入自然语言,如 “查询近 10 天用户对各等级产品的支付金额和支付订单数,支付金额≥15”,平台调 AI 接口解析转换为取数规则,执行后可得结果表,用户可下载分析。在指标看板页面,可以按业务主题新建看板,输入自然语言描述想看到的指标内容,平台经过分析就可以自动生成预制格式的图表,然后在预生成的图表上进行微调得到一张完整的看板,从而缩短看板配置时间。
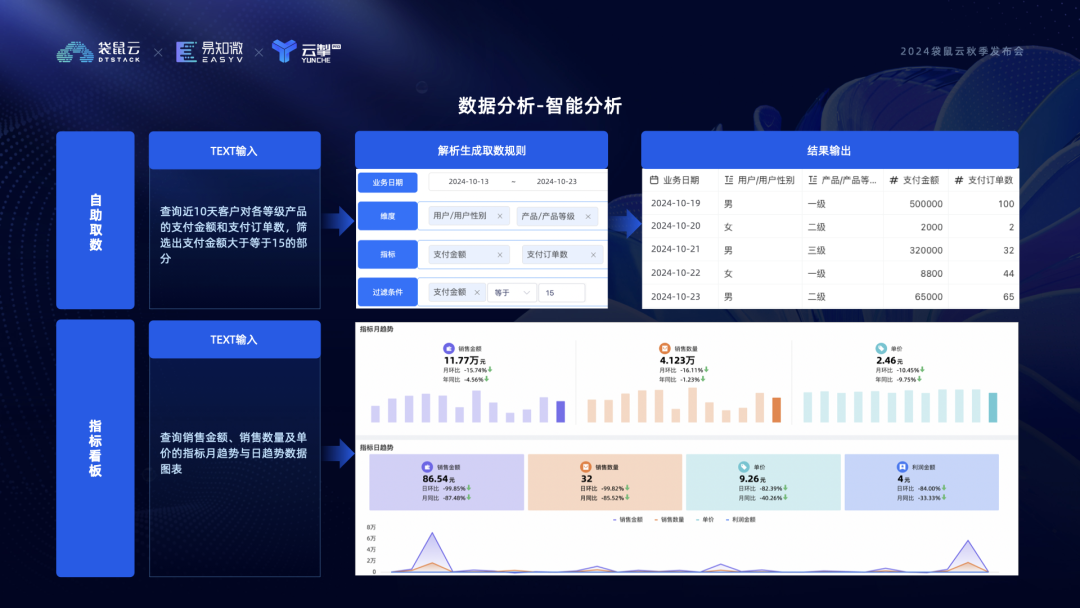
二是归因分析。基于指标目标树或看板异常数据,可层层挖掘异常根因并制订策略。如公司收入下滑,从指标树层层展开发现是销售额下滑的原因,7 月数据下降明显,进一步下钻得到7 月第二周到第三周波动异常,平台结合商品类型、城市和渠道维度计算归因值,发现商品类型的关联值较大,对商品类型中的值进行分析看到手机类销售额下滑比较明显,结合市场情况可知竞品友商活动影响。
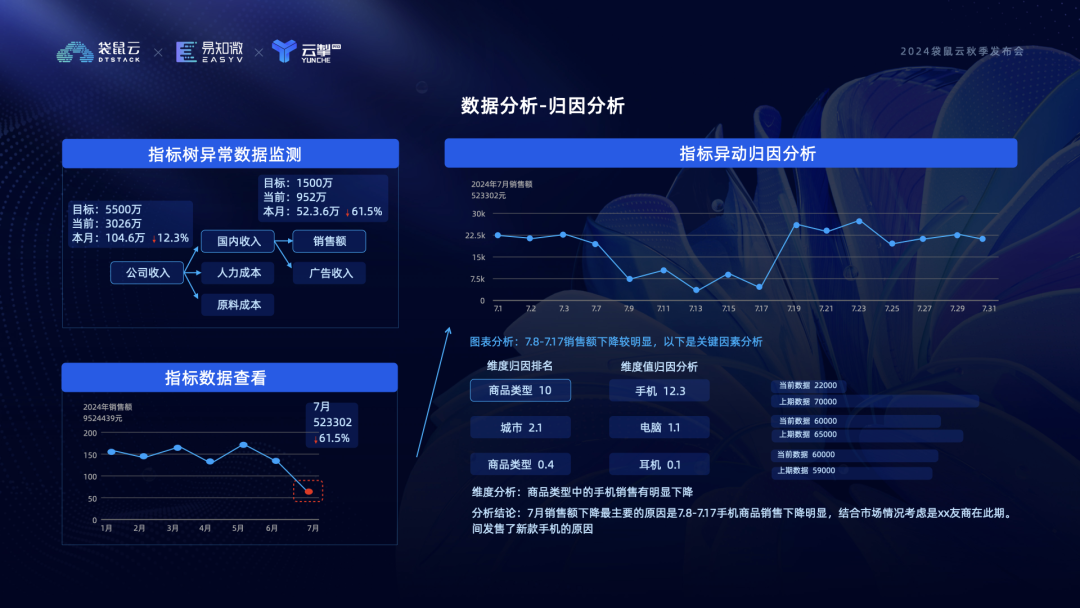
三是智能搜索及对话式指标分析 ChatBI。在指标的智能问答界面用户可以用自然语言进行指标搜索,智能助理会根据你的描述给出最匹配的指标清单以及每个指标的基础信息,点击指标可查看关键数据,对异常点进一步分析可得到原因和关联指标排查方向。这种以用户问题为导向,围绕问题给出答案,并进行关键因素分析和引导的数据分析方式,与传统让用户在预制报表里自行寻找答案的方式相比,无疑能够大幅缩短问题排查路径,使问题的解决更加聚焦、高效。
四、某银行指标管理分析实践案例
某大型银行在购买数栈指标平台前,已经进行了指标体系的梳理和搭建,但在实际应用中遇到了以下几个主要问题:
指标定义不一致:不同业务线存在很多指标名称相同但定义不同的情况。例如,“一般性存款”指标在监管口径中不包括财政性存款,但在人行口径中则包括;绩效考核中不包含保险公司存放款项,而人行口径则包含。这导致了数据解释和应用上的混乱。
指标重复构建:多个金融业务中存在相同的指标重复构建,如“客户人行征信指标”在零售金融、公司金融和普惠金融业务中都有独立构建,没有实现共享,导致资源浪费。
指标应用薄弱:指标构建后主要用于基本信息和口径的检索,没有进一步应用于更深层次的数据分析和决策支持。
针对客户梳理出适用于全行的新指标体系,彻底消除指标的多义性,实现指标在全域范围内的合规共享,并全面加强指标的应用建设的需求,袋鼠云为其量身定制了一套建设方案。
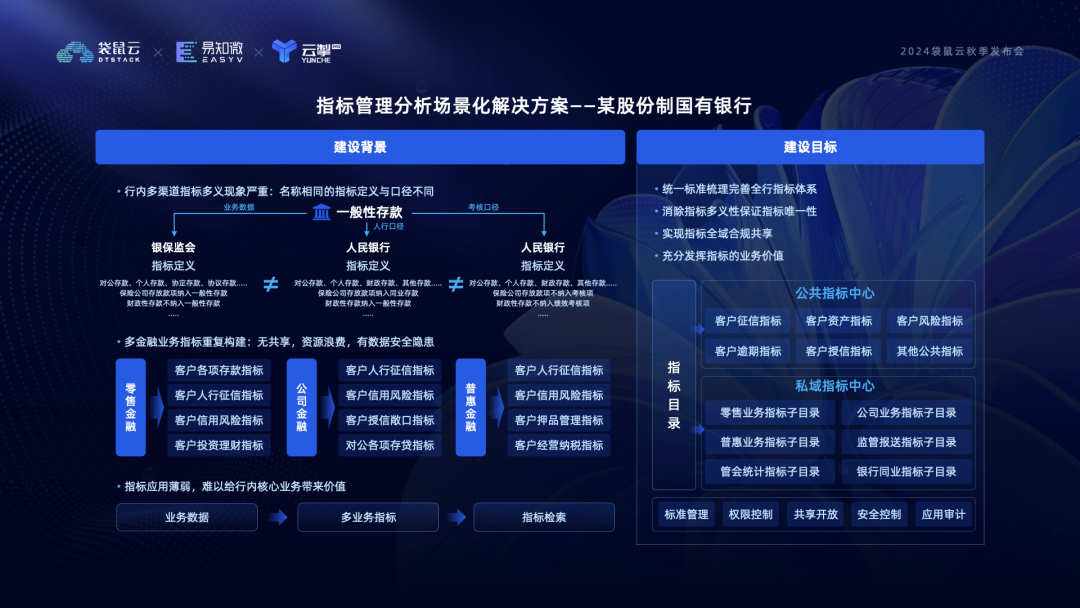
首先,将底层的存贷、风控等业务数据统一抽取到数栈平台,在此基础上进行离线和实时的加工处理,从而构建出基础数仓。接着,借助 Trino 引擎开展指标计算,经过分类分层的精细操作,得到不同业务的原子、派生、复合等各类指标,以这些指标为基石,在业绩考核、风险监管、企业存贷等指标体系中形成可以充分共享的指标目录。
在这个完备的指标体系之上,进一步开展一系列基于指标的深度应用建设,包括智能取数、指标看板的自动生成与归因分析、智能问题的智能问答、目标管理以及指标 API 的构建。
经过一年的落地实施,客户指标管理取得了显著成效:
全行 80 家分行中的 5000 + 指标得到了重新改造,个人银行与公司银行业务的指标实现了统一编目和标准化管理。
依据指标开发规范,利用指标相似度分析对 1100 多个指标进行了治理,有效减少了多义性情况的发生。
同时,在严格的数据安全管理规范下,对公考核、普惠金融、基金理财代销等业务的指标共享使用十分活跃。
基于指标的智能数据分析应用,使得开发人员在企业信贷、投行、理财等业务中能够迅速完成数据的分析工作,并快速做出决策,大大提升了银行业务的整体效能。
想了解更多,欢迎点击:https://www.dtstack.com/resources/1080?src=szcsdn
《行业指标体系白皮书》下载地址:https://www.dtstack.com/resources/1057?src=szsm
《数栈产品白皮书》下载地址:https://www.dtstack.com/resources/1004?src=szsm
《数据治理行业实践白皮书》下载地址:https://www.dtstack.com/resources/1001?src=szsm
想了解或咨询更多有关大数据产品、行业解决方案、客户案例的朋友,浏览袋鼠云官网:https://www.dtstack.com/?src=szcsdn
相关文章:
指标+AI+BI:构建数据分析新范式丨2024袋鼠云秋季发布会回顾
10月30日,袋鼠云成功举办了以“AI驱动,数智未来”为主题的2024年秋季发布会。大会深度探讨了如何凭借 AI 实现新的飞跃,重塑企业的经营管理方式,加速数智化进程。 作为大会的重要环节之一,袋鼠云数栈产品经理潮汐带来了…...

2024年第四届“网鼎杯”网络安全比赛---朱雀组Crypto- WriteUp
2024年第四届“网鼎杯”网络安全比赛---朱雀组Crypto-WriteUp Crypto:Crypto-2:Crypto-3: 前言:本次比赛已经结束,用于赛后复现,欢迎大家交流学习! Crypto: Crypto-2: …...

关于Markdown的一点疑问,为什么很多人说markdown比word好用?
markdown和word压根不是一类工具,不存在谁比谁好,只是应用场景不一样。 你写博客、写readme肯定得markdown,但写合同、写简历肯定word更合适。 markdown和word类似邮箱和微信的关系,这两者都可以通信,但微信因为功能…...
绪论)
NoSQL大数据存储技术测试(1)绪论
写在前面:未完成测试的同学,请先完成测试,此博文供大家复习使用,(我的答案)均为正确答案,大家可以放心复习 单项选择题 第1题 以下不属于云计算部署模型的是( ) 公…...

Linux命令学习,git命令
Linux系统,Git是一个强大的版本管理系统,允许用户跟踪代码的更改、管理项目历史以及与他人协作。 Linux Git命令: 初始化仓库:当前目录创建一个Git仓库,生成.git隐藏目录存储版本历史和其他Git相关的元数据。 git init 克隆仓库…...

【AI大模型】Transformer中的编码器详解,小白必看!!
前言 Transformer中编码器的构造和运行位置如下图所示,其中编码器内部包含多层,对应下图encoder1…encoder N,每个层内部又包含多个子层:多头自注意力层、前馈神经网络层、归一化层,而最关键的是多头自注意力层。 自注…...

PostgreSQL 字段按逗号分隔成多条数据的技巧与实践 ️
全文目录: 开篇语前言 📚1. PostgreSQL 字段拆分的基本概念 🎯2. 使用 string_to_array 函数拆分字段 💬示例:使用 string_to_array 拆分字段结果: 3. 使用 unnest 和 string_to_array 结合拆分 ǵ…...
)
设计模式学习总结(一)
设计模式学习笔记 面向对象、设计原则、设计模式、编程规范、重构之间的关系 面向对象、设计原则、设计模式、编程规范、重构之间的关系 面向对象 现在,主流的编程范式或者是编程风格有三种:面向过程、面向对象和函数式编程。 需要掌握七大知识点&#…...

软考中级 软件设计师 上午考试内容笔记(个人向)Part.1
软考上午考试内容 1. 计算机系统 计算机硬件通过高/低电平来模拟1/0信息;【p进制】: K n K n − 1 . . . K 2 K 1 K 0 K − 1 K − 2... K − m K n r n . . . K 1 r 1 K 0 r 0 K − 1 r − 1 . . . K − m r − m K_nK_{n-1}...K_2K_1K_0K…...

PHP API的数据交互类型设计
PHP API的数据交互类型设计涉及多个方面,包括请求方法、数据格式、安全性考虑等。以下是对PHP API数据交互类型设计的详细探讨: 一、请求方法 在PHP API中,常见的请求方法包括GET、POST、PUT、DELETE等。这些方法在数据交互中各有其用途和特…...

【EFK】Linux集群部署Elasticsearch最新版本8.x
【EFK】Linux集群部署Elasticsearch最新版本8.x 摘要环境准备环境信息系统初始化启动先决条件 下载&安装修改elasticsearch.yml控制台启动Linux服务启动访问验证查看集群信息查看es健康状态查看集群节点查询集群状态 生成service token验证service tokenIK分词器下载 摘要 …...

【大数据测试 Elasticsearch — 详细教程及实例】
大数据测试 Elasticsearch — 详细教程及实例 1. Elasticsearch 基础概述核心概念 2. 搭建 Elasticsearch 环境2.1 安装 Elasticsearch2.2 配置 Elasticsearch 3. 大数据测试的常见方法3.1 使用 Logstash 导入大数据3.2 使用 Elasticsearch 的 Bulk API3.3 使用 Benchmark 工具…...
用ArkTS写一个登录页面(实现简单的逻辑)
登录页面 1.登录页面编码 Extend(TextInput) function customStyle(){.backgroundColor(#fff).border({width:{bottom:0.5},color:#e4e4e4}).borderRadius(1) //让圆角不明显.placeholderColor(#c3c3c5).caretColor(#fa711d) //input获取焦点样式 }Entry Component struct Log…...

matlab将INCA采集的dat文件多个变量批量读取到excel中
参考资料: MATLAB处理INCA采集数据(mdf,dat等)一 使用matlab处理INCF采集数据,mdf(.dat)格式文件,并将将其写入excel文件 这个资料只能一个变量一个变量的提取,本对其进…...

list集合常见去重方式以及效率对比
1.概述 list集合去重是开发中比较常用的操作,在面试中也会经常问到,那么list去重都有哪些方式?他们之间又该如何选择呢? 本文将通过LinkedHashSet、for循环、list流toSet、list流distinct等4种方式分别做1W数据到1000W数据单元测试…...

JavaWeb——Web入门(7/9)-Tomcat-介绍(Tomcat 的简介:轻量级Web服务器,支持Servlet/JSP少量JavaEE规范)
目录 Web服务器的作用 三个方面的讲解 Tomcat 的简介 小结 Web服务器的作用 封装 HTTP 协议操作:Web服务器是一个软件程序,对 HTTP 协议的操作进行了封装。这样开发人员就不需要再直接去操作 HTTP 协议,使得外部应用程序的开发更加便捷、…...

【SpringBoot】19 文件/图片下载(MySQL + Thymeleaf)
Git仓库 https://gitee.com/Lin_DH/system 介绍 从 MySQL 中,下载保存的 blob 格式的文件。 代码实现 第一步:配置文件 application.yml spring:jackson:date-format: yyyy-MM-dd HH:mm:sstime-zone: GMT8datasource:driver-class-name: com.mysql.…...

陪诊问诊APP开发实战:基于互联网医院系统源码的搭建详解
时下,开发一款功能全面、用户体验良好的陪诊问诊APP成为了医疗行业的一大热点。本文将结合互联网医院系统源码,详细解析陪诊问诊APP的开发过程,为开发者提供实用的开发方案与技术指导。 一、陪诊问诊APP的背景与功能需求 陪诊问诊APP核心目…...

Spark 中 RDD 的诞生:原理、操作与分区规则
Spark 的介绍与搭建:从理论到实践-CSDN博客 Spark 的Standalone集群环境安装与测试-CSDN博客 PySpark 本地开发环境搭建与实践-CSDN博客 Spark 程序开发与提交:本地与集群模式全解析-CSDN博客 Spark on YARN:Spark集群模式之Yarn模式的原…...

c++构造与析构
构造函数特性 名称与类名相同:构造函数的名称必须与类名完全相同,并且不能有返回值类型(包括void)。 自动调用:构造函数在对象实例化时自动调用,不需要手动调用。 初始化成员变量:构造函数的主…...

超短脉冲激光自聚焦效应
前言与目录 强激光引起自聚焦效应机理 超短脉冲激光在脆性材料内部加工时引起的自聚焦效应,这是一种非线性光学现象,主要涉及光学克尔效应和材料的非线性光学特性。 自聚焦效应可以产生局部的强光场,对材料产生非线性响应,可能…...

RocketMQ延迟消息机制
两种延迟消息 RocketMQ中提供了两种延迟消息机制 指定固定的延迟级别 通过在Message中设定一个MessageDelayLevel参数,对应18个预设的延迟级别指定时间点的延迟级别 通过在Message中设定一个DeliverTimeMS指定一个Long类型表示的具体时间点。到了时间点后…...

系统设计 --- MongoDB亿级数据查询优化策略
系统设计 --- MongoDB亿级数据查询分表策略 背景Solution --- 分表 背景 使用audit log实现Audi Trail功能 Audit Trail范围: 六个月数据量: 每秒5-7条audi log,共计7千万 – 1亿条数据需要实现全文检索按照时间倒序因为license问题,不能使用ELK只能使用…...
)
【HarmonyOS 5 开发速记】如何获取用户信息(头像/昵称/手机号)
1.获取 authorizationCode: 2.利用 authorizationCode 获取 accessToken:文档中心 3.获取手机:文档中心 4.获取昵称头像:文档中心 首先创建 request 若要获取手机号,scope必填 phone,permissions 必填 …...

Spring Cloud Gateway 中自定义验证码接口返回 404 的排查与解决
Spring Cloud Gateway 中自定义验证码接口返回 404 的排查与解决 问题背景 在一个基于 Spring Cloud Gateway WebFlux 构建的微服务项目中,新增了一个本地验证码接口 /code,使用函数式路由(RouterFunction)和 Hutool 的 Circle…...

HDFS分布式存储 zookeeper
hadoop介绍 狭义上hadoop是指apache的一款开源软件 用java语言实现开源框架,允许使用简单的变成模型跨计算机对大型集群进行分布式处理(1.海量的数据存储 2.海量数据的计算)Hadoop核心组件 hdfs(分布式文件存储系统)&a…...

Yolov8 目标检测蒸馏学习记录
yolov8系列模型蒸馏基本流程,代码下载:这里本人提交了一个demo:djdll/Yolov8_Distillation: Yolov8轻量化_蒸馏代码实现 在轻量化模型设计中,**知识蒸馏(Knowledge Distillation)**被广泛应用,作为提升模型…...

Web后端基础(基础知识)
BS架构:Browser/Server,浏览器/服务器架构模式。客户端只需要浏览器,应用程序的逻辑和数据都存储在服务端。 优点:维护方便缺点:体验一般 CS架构:Client/Server,客户端/服务器架构模式。需要单独…...
ZYNQ学习记录FPGA(一)ZYNQ简介
一、知识准备 1.一些术语,缩写和概念: 1)ZYNQ全称:ZYNQ7000 All Pgrammable SoC 2)SoC:system on chips(片上系统),对比集成电路的SoB(system on board) 3)ARM:处理器…...

2025年低延迟业务DDoS防护全攻略:高可用架构与实战方案
一、延迟敏感行业面临的DDoS攻击新挑战 2025年,金融交易、实时竞技游戏、工业物联网等低延迟业务成为DDoS攻击的首要目标。攻击呈现三大特征: AI驱动的自适应攻击:攻击流量模拟真实用户行为,差异率低至0.5%,传统规则引…...